

Dans ce tutoriel, vous apprendrez
- Comment un assistant de recherche d’emploi LinkedIn alimenté par l’IA pourrait fonctionner.
- Comment le construire en intégrant les données d’emploi de LinkedIn provenant de Bright Data avec un flux de travail alimenté par OpenAI.
- Comment améliorer et étendre ce flux de travail pour en faire un assistant de recherche d’emploi robuste.
Vous pouvez consulter les fichiers du projet final ici.
Plongeons dans l’aventure !
Explication du flux de travail de l’assistant IA pour la recherche d’emploi sur LinkedIn
Tout d’abord, vous ne pouvez pas créer un assistant IA pour la recherche d’emploi sur LinkedIn sans avoir accès aux données des listes d’offres d’emploi de LinkedIn. C’est là que Bright Data entre en jeu !
Grâce à LinkedIn Jobs Scraper, vous pouvez récupérer les données des offres d’emploi publiques de LinkedIn via le web scraping. L’expérience que vous obtenez est la même que celle d’une recherche sur le portail LinkedIn Jobs. Mais au lieu d’une page web, vous recevez les données structurées de l’emploi directement au format JSON ou CSV.
À partir de ces données, vous pouvez demander à une IA d’évaluer chaque emploi en fonction de vos compétences et du poste que vous recherchez. À un niveau élevé, c’est ce que l’assistant LinkedIn Job AI fait pour vous.
Étapes techniques
Les étapes nécessaires pour mettre en œuvre le flux de travail de l’IA pour l’emploi sur LinkedIn sont les suivantes :
- Charger les arguments CLI: Analyser les arguments de la ligne de commande pour obtenir les paramètres d’exécution. Cela permet une exécution flexible et une personnalisation facile sans modifier le code.
- Charger les variables d’environnement : Charger les clés d’OpenAI et de Bright Data API dans les variables d’environnement. Celles-ci sont nécessaires pour se connecter aux intégrations tierces qui alimentent ce flux de travail d’IA.
- Charger le fichier de configuration: Lire un fichier de configuration JSON contenant les paramètres de recherche d’emploi, les détails du profil du candidat et la description de l’emploi souhaité. Ces informations de configuration guident la recherche d’emploi et l’évaluation par l’IA.
- Récupérer les offres d’emploi sur LinkedIn: Récupérer les offres d’emploi filtrées en fonction de la configuration à partir de l’API LinkedIn Jobs Scraper.
- Noter les offres d’emploi via l’IA: envoyer chaque lot d’offres d’emploi à OpenAI. L’IA leur attribue une note de
0à100en fonction de votre profil et de l’emploi souhaité. Elle ajoute également un bref commentaire expliquant chaque score pour vous aider à comprendre la qualité de la correspondance. - Développez les offres d’emploi avec les notes et les commentaires de l’IA: ****Merge les notes et les commentaires générés par l’IA dans les offres d’emploi originales, enrichissant ainsi chaque enregistrement d’emploi avec ces nouveaux champs générés par l’IA.
- Exportez les données relatives aux offres d’emploi notées: Exportez les données enrichies sur les offres d’emploi vers un fichier CSV en vue d’une analyse et d’un traitement ultérieurs.
- Imprimer les meilleures offres d’emploi: Affichez les meilleures offres d’emploi directement dans la console avec les principaux détails, afin d’avoir un aperçu immédiat des opportunités les plus pertinentes.
Découvrez comment mettre en œuvre ce flux de travail d’IA en Python !
Comment utiliser OpenAI et Bright Data pour construire un flux de travail d’IA pour la recherche d’emploi sur LinkedIn
Dans ce tutoriel, vous apprendrez à construire un flux de travail d’IA pour vous aider à trouver des emplois sur LinkedIn. Les données d’emploi de LinkedIn proviendront de Bright Data, tandis que les capacités d’IA seront fournies par OpenAI. Notez que vous pouvez également utiliser n’importe quel autre LLM.
À la fin de cette section, vous disposerez d’un flux de travail d’IA Python complet que vous pourrez exécuter à partir de la ligne de commande. Il identifiera les meilleures offres d’emploi sur LinkedIn, ce qui vous permettra d’économiser du temps et des efforts dans la tâche éreintante et énergivore de la recherche d’emploi.
Construisons un assistant IA pour la recherche d’emploi sur LinkedIn !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.8 ou supérieur installé localement (nous recommandons d’utiliser la dernière version).
- Une clé API Bright Data.
- Une clé API OpenAI.
Si vous n’avez pas encore de clé API Bright Data, créez un compte Bright Data et suivez le guide d’installation officiel. De même, suivez les instructions officielles d’OpenAI pour obtenir votre clé d’API OpenAI.
Étape n° 0 : Configurer votre projet Python
Ouvrez un terminal et créez un nouveau répertoire pour votre assistant IA de recherche d’emploi LinkedIn :
mkdir linkedin-job-hunting-ai-assistant/Le dossier linkedin-job-hunting-ai-assistant contiendra tout le code Python pour votre flux de travail AI.
Ensuite, naviguez dans le répertoire du projet et initialisez un environnement virtuel à l’intérieur de celui-ci:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvMaintenant, ouvrez le projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Dans le dossier du projet, créez un nouveau fichier nommé assistant.py. La structure de votre répertoire devrait ressembler à ceci :
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.pyActivez l’environnement virtuel dans votre terminal. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, lancez cette commande :
venv/Scripts/activateDans les étapes suivantes, vous serez guidé dans l’installation des paquets Python requis. Si vous préférez les installer tous maintenant, dans l’environnement virtuel activé, exécutez la commande suivante
pip install python-dotenv requests openai pydanticEn particulier, les bibliothèques requises sont les suivantes
python-dotenv: Charge les variables d’environnement à partir d’un fichier.env, ce qui facilite la gestion sécurisée des clés d’API.pydantic: Aide à valider et à analyser le fichier de configuration en objets Python structurés.requests: Gère les requêtes HTTP pour appeler des API comme Bright Data et récupérer des données.openai: Fournit le client OpenAI pour interagir avec les modèles de langage d’OpenAI pour l’évaluation des tâches d’IA.
Remarque: nous installons la bibliothèque openai ici parce que ce tutoriel s’appuie sur OpenAI en tant que fournisseur de modèle de langage. Si vous prévoyez d’utiliser un autre fournisseur de LLM, assurez-vous d’installer le SDK ou les dépendances correspondantes.
Vous êtes prêts ! Votre environnement de développement Python est maintenant prêt à construire un flux de travail d’IA en utilisant OpenAI et Bright Data.
Étape 1 : Charger les arguments CLI
Le script d’IA pour la recherche d’emploi sur LinkedIn nécessite quelques arguments. Pour qu’il reste réutilisable et personnalisable sans modifier le code, vous devez les lire via le CLI.
En détail, vous aurez besoin des arguments CLI suivants :
--config_file: Le chemin vers le fichier de configuration JSON contenant vos paramètres de recherche d’emploi, les détails du profil du candidat et la description de l’emploi souhaité. La valeur par défaut estconfig.json.--batch_size: Le nombre de travaux à envoyer à l’IA pour évaluation à la fois. La valeur par défaut est5.--jobs_number: Le nombre maximum d’entrées d’offres d’emploi que Bright Data LinkedIn Jobs Scraper doit renvoyer. La valeur par défaut est20.--output_csv: Le nom du fichier CSV de sortie contenant les données d’emploi enrichies avec les notes et les commentaires de l’IA. La valeur par défaut estjobs_scored.csv.
Ces arguments sont lus à partir de l’interface de ligne de commande à l’aide de la fonction suivante :
def parse_cli_args() :
# Analyse les arguments de la ligne de commande pour les options de configuration et d'exécution
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Chemin vers le fichier JSON de configuration")
parser.add_argument("--jobs_number", type=int, default=20, help="Limiter le nombre de jobs renvoyés par l'API Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Nombre de travaux à noter dans chaque lot")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nom de fichier CSV de sortie")
return parser.parse_args()N’oubliez pas d’importer argparse depuis la bibliothèque standard de Python :
import argparseC’est génial ! Vous avez maintenant accès aux arguments depuis l’interface de programmation.
Etape 2 : Charger les variables d’environnement
Configurez votre script pour qu’il lise les secrets des variables d’environnement. Pour simplifier le chargement des variables d’environnement, utilisez le paquet python-dotenv. Avec votre environnement virtuel activé, installez-le en exécutant :
pip install python-dotenvEnsuite, dans votre fichier assistant.py, importez la bibliothèque et appelez load_dotenv() pour charger vos variables d’environnement :
from dotenv import load_dotenv
load_dotenv()Votre assistant peut désormais lire les variables d’un fichier .env local. Ajoutez donc un fichier .env à la racine du répertoire de votre projet :
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└── assistant.pyOuvrez le fichier .env et ajoutez-y les envs OPENAI_API_KEY et BRIGHT_DATA_API_KEY:
OPENAI_API_KEY="<VOTRE_CLÉ_OPENAI_API>"
BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_DONNÉES_BRILLANTES>"Remplacez l’espace réservé <YOUR_OPENAI_API_KEY> par votre véritable clé d’API OpenAI. De même, remplacez l’espace réservé <YOUR_BRIGHT_DATA_API_KEY> par votre clé d’API Bright Data.
Ensuite, ajoutez cette fonction à votre script pour charger ces deux variables d’environnement :
def load_env_vars() :
# Lire les clés d'API requises dans l'environnement et vérifier leur présence
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key :
missing.append("OPENAI_API_KEY")
if not brightdata_api_key :
missing.append("BRIGHT_DATA_API_KEY")
si manquant :
raise EnvironmentError(
f "Variables d'environnement requises manquantes : {', '.join(missing)}n"
"Veuillez les définir dans votre .env ou votre environnement."
)
return openai_api_key, brightdata_api_keyAjoutez l’importation requise à partir de la bibliothèque standard de Python :
import osC’est formidable ! Vous avez maintenant chargé en toute sécurité des secrets d’intégration de tiers à l’aide de variables d’environnement.
Étape n° 3 : charger le fichier de configuration
Il vous faut maintenant un moyen programmatique d’indiquer à votre assistant les emplois qui vous intéressent. Pour que ses résultats soient précis, l’assistant doit également connaître votre expérience professionnelle et le type d’emploi que vous recherchez.
Pour éviter de coder ces informations en dur directement dans votre code, il est judicieux de les lire à partir d’un fichier de configuration JSON. Plus précisément, ce fichier doit contenir les éléments suivants
- l
'emplacement: L’emplacement géographique où vous souhaitez rechercher des emplois. Il définit la zone principale où les offres d’emploi seront collectées. mot-clé: mots ou phrases spécifiques liés à l’intitulé de l’emploi ou au rôle que vous recherchez, tels que “développeur Python”. Utilisez des guillemets pour obtenir des correspondances exactes.pays: Un code de pays à deux lettres (par exemple,USpour les États-Unis,FRpour la France) pour restreindre la recherche d’emploi à un pays spécifique.time_range: La période au cours de laquelle les offres d’emploi ont été publiées, afin de filtrer les offres récentes ou pertinentes (par exemple,la semaine écoulée, lemois écoulé, etc.).job_type: Le type d’emploi à filtrer, par exempletemps plein,temps partiel, etc.experience_level: Le niveau d’expérience professionnelle requis, tel queniveau d'entrée,associé, etc.remote: Filtre les offres d’emploi en fonction du mode de travail (par exemple,à distance,sur siteouhybride).entreprise: Concentre la recherche sur les offres d’emploi d’une entreprise ou d’un employeur spécifique.selective_search: Lorsque cette option est activée, elle exclut les offres d’emploi dont le titre ne contient pas les mots-clés spécifiés afin de produire des résultats plus ciblés.jobs_to_not_include: Une liste d’identifiants d’offres d’emploi spécifiques à exclure des résultats de la recherche, utile pour supprimer les doublons ou les offres d’emploi non souhaitées.location_radius: Définit la distance autour de l’emplacement spécifié sur laquelle la recherche doit s’étendre, y compris les zones avoisinantes.profile_summary: Résumé de votre profil professionnel. Ces informations sont utilisées par l’IA pour évaluer dans quelle mesure chaque emploi vous correspond.résumé_emploi_désiré: brève description du type d’emploi que vous recherchez, afin d’aider l’IA à classer les offres d’emploi en fonction de leur adéquation.
Ces arguments correspondent exactement à ceux requis par l’API Bright Data LinkedIn pour la recherche d’offres d’emploi par mot-clé (qui fait partie de la solution LinkedIn Jobs Scraper) :
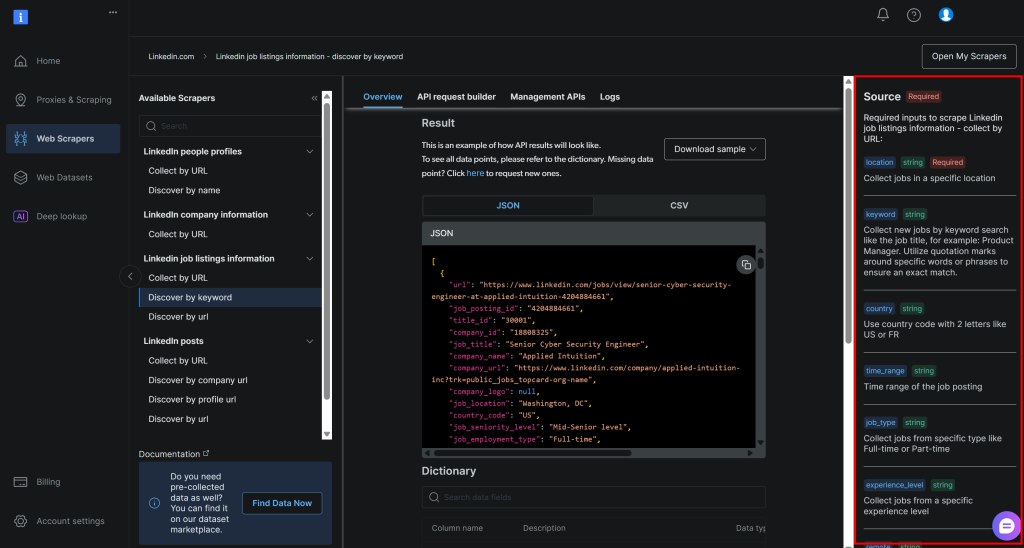
Pour plus d’informations sur ces champs et les valeurs qu’ils peuvent prendre, consultez la documentation officielle.
Les deux derniers champs(profile_summary et desired_job_summary) décrivent qui vous êtes professionnellement et ce que vous recherchez. Ils seront transmis à l’IA pour évaluer chaque offre d’emploi renvoyée par Bright Data.
Pour faciliter la manipulation du fichier de configuration dans le code, il est conseillé de le faire correspondre à un modèle Pydantic. Tout d’abord, installez Pydantic dans votre environnement virtuel :
pip install pydanticEnsuite, définissez le modèle Pydantic en mappant le fichier de configuration JSON comme ci-dessous :
class JobSearchConfig(BaseModel) :
location : str
mot-clé : Optional[str] = None
pays : Facultatif[str] = Aucun
time_range : Facultatif[str] = Aucun
job_type : Facultatif[str] = Aucun
experience_level : Facultatif[str] = Aucun
remote : Facultatif[str] = Aucun
entreprise : Facultatif[str] = Aucun
selective_search : Facultatif[bool] = Champ (par défaut=False)
jobs_to_not_include : Optional[List[str]] = Field(default_factory=list)
location_radius : Facultatif[str] = Aucun
# Champs supplémentaires
profile_summary : str # Résumé du profil du candidat pour la notation AI
desired_job_summary : str # Description de l'emploi souhaité pour l'évaluation de l'IANotez que seuls les deux premiers et derniers champs de configuration sont obligatoires.
Ensuite, créez une fonction pour lire les configurations JSON à partir du chemin du fichier --config_file. Désérialisez-les dans une instance de JobSearchConfig:
def load_and_validate_config(filename : str) -> JobSearchConfig :
# Chargement du fichier de configuration JSON
try :
avec open(filename, "r", encoding="utf-8") as f :
data = json.load(f)
except FileNotFoundError :
raise FileNotFoundError(f "Fichier de configuration '{nom de fichier}' introuvable.")
try :
# Désérialise les données JSON d'entrée en une instance de JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e :
raise ValueError(f "Erreur de désérialisation de la configuration:n{e}")
return configCette fois, vous aurez besoin de ces importations :
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import jsonGénial ! Maintenant votre fichier de configuration est correctement lu et désérialisé comme prévu.
Etape 4 : Récupérer les offres d’emploi de LinkedIn
Il est temps d’utiliser la configuration que vous avez chargée précédemment pour appeler l’API Bright Data LinkedIn Jobs Scraper.
Si vous n’êtes pas familier avec le fonctionnement des API Web Scraper de Bright Data, nous vous conseillons de consulter la documentation au préalable.
En bref, les API Web Scraper fournissent des points d’extrémité d’API qui vous permettent d’extraire des données publiques à partir de domaines spécifiques. En coulisses, Bright Data initialise et exécute une tâche de raclage prête à l’emploi sur ses serveurs. Ces API gèrent la rotation des adresses IP, les CAPTCHA et d’autres mesures permettant de collecter efficacement et éthiquement des données publiques à partir de pages web. Une fois la tâche terminée, les données récupérées sont analysées dans un format structuré et mises à votre disposition sous forme d’instantané.
Le flux de travail général est donc le suivant :
- Déclencher l’appel de l’API pour lancer une tâche d’extraction de données sur le web.
- Vérifier périodiquement si l’instantané contenant les données scannées est prêt.
- Récupérer les données de l’instantané une fois qu’elles sont disponibles.
Vous pouvez mettre en œuvre la logique ci-dessus en quelques lignes de code seulement :
def trigger_and_poll_linkedin_jobs(config : JobSearchConfig, brightdata_api_key : str, jobs_number : int, polling_timeout=10) :
# Déclenche la recherche d'emploi LinkedIn de Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization" : f "Bearer {brightdata_api_key}",
"Content-Type" : "application/json",
}
params = {
"dataset_id" : "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors" : "true",
"type" : "discover_new",
"discover_by" : "keyword",
"limit_per_input" : str(jobs_number),
}
# Préparer la charge utile pour l'API Bright Data en fonction de la configuration de l'utilisateur
data = [{
"location" : config.location,
"keyword" : config.keyword ou "",
"country" : config.country ou "",
"time_range" : config.time_range ou "",
"job_type" : config.job_type ou "",
"experience_level" : config.experience_level ou "",
"remote" : config.remote ou "",
"company" : config.company ou "",
"selective_search" : config.selective_search,
"jobs_to_not_include" : config.jobs_to_not_include ou "",
"location_radius" : config.location_radius ou "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
si response.status_code != 200 :
raise RuntimeError(f "Échec de la demande de déclenchement : {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id :
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "Recherche d'emploi LinkedIn déclenchée ! ID de l'instantané : {snapshot_id}")
# Interroger le point de terminaison de l'instantané jusqu'à ce que les données soient prêtes ou que le délai soit dépassé
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization" : f "Bearer {brightdata_api_key}"}
print(f "Interrogation de l'instantané pour l'ID : {snapshot_id}")
while True :
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200 :
# L'instantané est prêt : retour des données JSON des offres d'emploi
print("L'instantané est prêt")
return snap_resp.json()
elif snap_resp.status_code == 202 :
# L'instantané n'est pas encore prêt : attendre et réessayer
print(f "L'instantané n'est pas encore prêt. Réessai dans {polling_timeout} secondes...")
time.sleep(polling_timeout)
sinon :
raise RuntimeError(f "L'interrogation de l'instantané a échoué : {snap_resp.status_code} - {snap_resp.text}")Cette fonction déclenche le scraper d’emplois LinkedIn de Bright Data à l’aide des paramètres de recherche du fichier de configuration, ce qui garantit que vous n’obtenez que les listes qui correspondent à vos critères. Elle interroge ensuite jusqu’à ce que l’instantané de données soit prêt et, une fois disponible, renvoie les offres d’emploi au format JSON. Notez que l ‘authentification est gérée à l’aide de la clé API de Bright Data chargée précédemment dans vos variables d’environnement.
L’instantané récupéré avec LinkedIn Jobs Scraper contiendra des offres d’emploi au format JSON comme ceci :
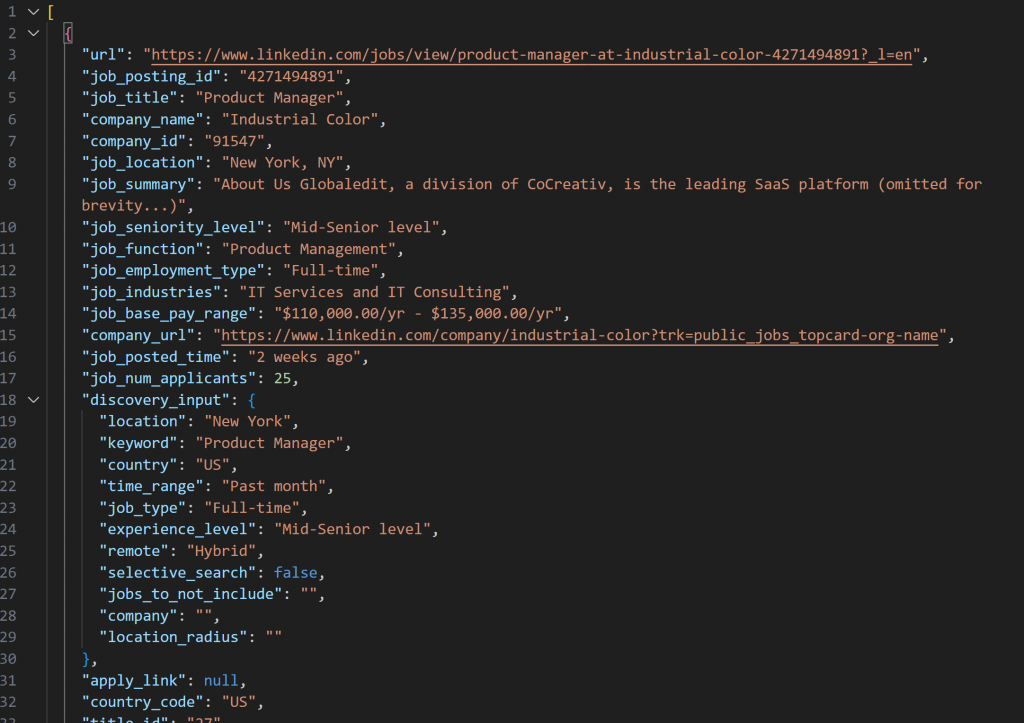
Remarque: l’instantané JSON produit contient exactement jusqu’à --jobs_number emplois. Dans ce cas, il contient 20 emplois.
Pour que la fonction ci-dessus fonctionne, vous devez installer requests:
pip install requestsPour plus d’informations sur son fonctionnement, reportez-vous à notre guide avancé sur les requêtes HTTP Python.
Ensuite, n’oubliez pas de l’importer avec time depuis la bibliothèque standard de Python :
import requests
import timeGénial ! Vous venez de vous intégrer à Bright Data pour recueillir des données fraîches et spécifiques sur les offres d’emploi de LinkedIn.
Étape 5 : Noter les offres d’emploi grâce à l’IA
Il est maintenant temps de demander à un LLM (tel que les modèles d’OpenAI) d’évaluer chaque offre d’emploi récupérée.
L’objectif est d’attribuer une note de 0 à 100, accompagnée d’un bref commentaire, en fonction de l’adéquation de l’offre d’emploi :
- votre expérience professionnelle
(profil_summary) - au poste que vous souhaitez occuper
(desired_job_summary).
Pour réduire les allers-retours dans l’API et accélérer les choses, il est judicieux de traiter les offres par lots. En particulier, vous évaluerez un certain nombre --batch_size d’offres à la fois.
Commencez par installer le paquet openai:
pip install openaiEnsuite, importez OpenAI et initialisez le client :
from openai import OpenAI
# ...
# Initialiser le client OpenAI
client = OpenAI()Notez que vous n’avez pas besoin de transmettre manuellement votre clé d’API au constructeur d’OpenAI. La bibliothèque la lit automatiquement à partir de la variable d’environnement OPENAI_API_KEY, que vous avez déjà définie.
Procédez à la création de la fonction d’évaluation des emplois par l’IA :
def score_jobs_batch(jobs_batch : List[dict], profile_summary : str, desired_job_summary : str) -> List[JobScore] :
# Construit une invite pour que l'IA évalue les correspondances d'emploi en fonction du profil du candidat
prompt = f"""
"Vous êtes un recruteur expert. Étant donné le profil de candidat suivant:N"
"{profile_summary}nn"
"Description du poste souhaité:n{desired_job_summary}nn"
"Attribuez à chaque offre d'emploi une note précise de 0 à 100 en fonction de son adéquation avec le profil et l'emploi souhaité.N"
"Pour chaque offre d'emploi, ajoutez un bref commentaire (50 mots maximum) expliquant le score et la qualité de l'adéquation.n"
"Return an array of objects with keys 'job_posting_id', 'score', and 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role" : "system", "content" : "You are a helpful job scoring assistant."},
{"rôle" : "user", "content" : prompt},
]
# Utiliser l'API OpenAI pour analyser la réponse structurée dans le modèle JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Retourne la liste des emplois notés
return response.output_parsed.scoresCeci utilise le nouveau modèle gpt-5-mini pour que OpenAI note chaque offre d’emploi scrapée de 0 à 100, avec un court commentaire explicatif.
Pour s’assurer que la réponse est toujours renvoyée dans le format exact dont vous avez besoin, la méthode parse() est appelée. Cette méthode applique un modèle de sortie structuré, défini ici avec les modèles Pydantic suivants :
classe JobScore(BaseModel) :
job_posting_id : str
score : int = Field(..., ge=0, le=100)
commentaire : str
classe JobScoresResponse(BaseModel) :
scores : List[JobScore]Fondamentalement, l’IA renverra des données JSON structurées comme suit :
{
"scores" : [
{
"job_posting_id" : "4271494891",
"score" : 80,
"commentaire" : "Vous êtes en charge de la mise en place d'un système de gestion de l'information et de la communication (GED). Le rôle vise 2-4 ans, donc c'est légèrement junior pour vos 7 ans."
},
// omis par souci de concision...
{
"job_posting_id" : "4273328527",
"score" : 65,
"commentaire" : "Product role with heavy data/technical emphasis ; agile and cross-functional responsibilities align, but it prefers quantitative/technical domain experience (finance/stat modeling) which may be a weak fit."
}
]
}La méthode parse() convertit alors la réponse JSON en une instance JobScoresResponse. Vous pourrez alors accéder par programme aux notes et aux commentaires dans votre code.
Remarque: si vous préférez utiliser un autre fournisseur LLM, veillez à adapter le code ci-dessus pour qu’il fonctionne avec le fournisseur de votre choix.
Nous y voilà ! L’évaluation des emplois par l’IA est terminée.
Étape n° 6 : Développer les travaux avec les acores et les commentaires de l’IA
Jetez un coup d’œil à la sortie JSON brute renvoyée par l’IA présentée plus haut. Vous pouvez voir que chaque score d’emploi contient un champ job_posting_id. Ce champ correspond à l’identifiant utilisé par LinkedIn pour identifier les offres d’emploi.
Comme ces ID apparaissent également dans les données instantanées produites par le Bright Data LinkedIn Jobs Scraper, vous pouvez les utiliser pour :
- Trouver les objets d’offre d’emploi originaux à partir du tableau des offres d’emploi scrappées.
- Enrichir cet objet d’offre d’emploi en ajoutant la note et le commentaire générés par l’IA.
Pour ce faire, utilisez la fonction suivante :
def extend_jobs_with_scores(jobs : List[dict], all_scores : List[JobScore]) -> List[dict] :
# Où stocker les données enrichies
extended_jobs = []
# Combinez les emplois originaux avec les scores et les commentaires de l'IA
pour score_obj dans all_scores :
matched_job = None
pour job dans jobs :
si job.get("job_posting_id") == score_obj.job_posting_id :
matched_job = job
break
if matched_job :
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Trier les emplois étendus par score d'IA (le plus élevé en premier)
extended_jobs.sort(key=lambda j : j["ai_score"], reverse=True)
return extended_jobsComme vous pouvez le constater, quelques boucles for suffisent pour accomplir la tâche. Avant de renvoyer les données enrichies, triez la liste par ordre décroissant de ai_score. De cette façon, les emplois les mieux assortis apparaissent en haut de la liste, ce qui permet de les repérer rapidement et facilement.
Cool ! Votre assistant IA pour la recherche d’emploi sur LinkedIn est maintenant presque prêt à fonctionner !
Étape 7 : Exporter les données relatives aux emplois notés
Utilisez le paquetage csv intégré à Python pour exporter les données d’emploi scannées et enrichies dans un fichier CSV.
def export_extended_jobs(extended_jobs : List[dict], output_csv : str) :
# Obtenir dynamiquement les noms des champs à partir du premier élément du tableau
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile :
# Écriture des données de travail étendues avec les scores AI au format CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
pour job dans extended_jobs :
writer.writerow(job)
print(f "Exported {len(extended_jobs)} jobs to {output_csv}") La fonction ci-dessus sera appelée en remplaçant output_csv par l’argument CLI --output_csv.
N’oubliez pas d’importer csv:
import csvC’est parfait ! L’assistant IA de recherche d’emploi de LinkedIn exporte maintenant les données enrichies par l’IA vers un fichier CSV.
Étape #8 : Imprimer les meilleurs résultats de recherche d’emploi
Pour obtenir un retour d’information immédiat dans le terminal sans ouvrir le fichier CSV de sortie, écrivez une fonction pour imprimer les détails clés des 3 meilleurs emplois :
def print_top_jobs(extended_jobs : List[dict], top : int = 3) :
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3] :
print(f "URL : {job.get('url', 'N/A')}")
print(f "Titre : {job.get('job_title', 'N/A')}")
print(f "Score AI : {job.get('ai_score')}")
print(f "Commentaire AI : {job.get('ai_comment', 'N/A')}")
print("-" * 40)Étape n° 9 : Rassembler le tout
Combinez toutes les fonctions des étapes précédentes dans la logique principale de l’assistant de recherche d’emploi de LinkedIn :
# Obtenir les paramètres d'exécution du CLI
args = parse_cli_args()
try :
# Charger les clés API de l'environnement
_, brightdata_api_key = load_env_vars()
# Chargement du fichier de configuration de la recherche d'emploi
config = load_and_validate_config(args.config_file)
# Récupérer les emplois
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs trouvés !")
except Exception as e :
print(f"[Erreur] {e}")
return
all_scores = []
# Traiter les jobs par lots pour éviter de surcharger l'API et pour gérer les grands ensembles de données
for i in range(0, len(jobs_data), args.batch_size) :
batch = jobs_data[i : i + args.batch_size]
print(f "Notation du lot {i // args.batch_size + 1} avec {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Pour éviter de déclencher les limites de débit de l'API
# Fusionner les scores dans les jobs scrappés
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Sauvegarde des résultats au format CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimer les meilleurs résultats avec des informations clés pour une révision rapide
print_top_jobs(extended_jobs)Incroyable ! Il ne reste plus qu’à examiner le code complet de l’assistant et à vérifier qu’il fonctionne comme prévu.
Etape #10 : Code complet et première exécution
Votre fichier assistant.py final devrait contenir
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
import os
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import json
import requêtes
import time
from openai import OpenAI
import csv
# Chargement des variables d'environnement à partir du fichier .env
load_dotenv()
# Modèles pydantiques supportant le projet
classe JobSearchConfig(BaseModel) :
# Source : https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
location : str
mot-clé : Facultatif[str] = Aucun
pays : Facultatif[str] = Aucun
time_range : Facultatif[str] = Aucun
job_type : Facultatif[str] = Aucun
experience_level : Facultatif[str] = Aucun
remote : Facultatif[str] = Aucun
entreprise : Facultatif[str] = Aucun
selective_search : Facultatif[bool] = Champ (par défaut=False)
jobs_to_not_include : Optional[List[str]] = Field(default_factory=list)
location_radius : Facultatif[str] = Aucun
# Champs supplémentaires
profile_summary : str # Résumé du profil du candidat pour la notation AI
desired_job_summary : str # Description de l'emploi souhaité pour l'évaluation de l'IA
classe JobScore(BaseModel) :
job_posting_id : str
score : int = Field(..., ge=0, le=100)
commentaire : str
classe JobScoresResponse(BaseModel) :
scores : List[JobScore]
def parse_cli_args() :
# Analyse les arguments de la ligne de commande pour les options de configuration et d'exécution
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Chemin vers le fichier JSON de configuration")
parser.add_argument("--jobs_number", type=int, default=20, help="Limiter le nombre de jobs renvoyés par l'API Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Nombre de travaux à noter dans chaque lot")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nom de fichier CSV de sortie")
return parser.parse_args()
def load_env_vars() :
# Lire les clés d'API requises dans l'environnement et vérifier leur présence
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key :
missing.append("OPENAI_API_KEY")
if not brightdata_api_key :
missing.append("BRIGHT_DATA_API_KEY")
si manquant :
raise EnvironmentError(
f "Variables d'environnement requises manquantes : {', '.join(missing)}n"
"Veuillez les définir dans votre .env ou votre environnement."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename : str) -> JobSearchConfig :
# Chargement du fichier de configuration JSON
try :
avec open(filename, "r", encoding="utf-8") as f :
data = json.load(f)
except FileNotFoundError :
raise FileNotFoundError(f "Fichier de configuration '{nom de fichier}' introuvable.")
try :
# Désérialisation des données JSON d'entrée en une instance de JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e :
raise ValueError(f "Erreur de désérialisation de la configuration:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config : JobSearchConfig, brightdata_api_key : str, jobs_number : int, polling_timeout=10) :
# Déclenche la recherche d'emploi LinkedIn de Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization" : f "Bearer {brightdata_api_key}",
"Content-Type" : "application/json",
}
params = {
"dataset_id" : "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors" : "true",
"type" : "discover_new",
"discover_by" : "keyword",
"limit_per_input" : str(jobs_number),
}
# Préparer la charge utile pour l'API Bright Data en fonction de la configuration de l'utilisateur
data = [{
"location" : config.location,
"keyword" : config.keyword ou "",
"country" : config.country ou "",
"time_range" : config.time_range ou "",
"job_type" : config.job_type ou "",
"experience_level" : config.experience_level ou "",
"remote" : config.remote ou "",
"company" : config.company ou "",
"selective_search" : config.selective_search,
"jobs_to_not_include" : config.jobs_to_not_include ou "",
"location_radius" : config.location_radius ou "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
si response.status_code != 200 :
raise RuntimeError(f "Échec de la demande de déclenchement : {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id :
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "Recherche d'emploi LinkedIn déclenchée ! ID de l'instantané : {snapshot_id}")
# Interroger le point de terminaison de l'instantané jusqu'à ce que les données soient prêtes ou que le délai soit dépassé
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization" : f "Bearer {brightdata_api_key}"}
print(f "Interrogation de l'instantané pour l'ID : {snapshot_id}")
while True :
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200 :
# L'instantané est prêt : retour des données JSON des offres d'emploi
print("L'instantané est prêt")
return snap_resp.json()
elif snap_resp.status_code == 202 :
# L'instantané n'est pas encore prêt : attendre et réessayer
print(f "L'instantané n'est pas encore prêt. Réessai dans {polling_timeout} secondes...")
time.sleep(polling_timeout)
sinon :
raise RuntimeError(f "L'interrogation de l'instantané a échoué : {snap_resp.status_code} - {snap_resp.text}")
# Initialisation du client OpenAI
client = OpenAI()
def score_jobs_batch(jobs_batch : List[dict], profile_summary : str, desired_job_summary : str) -> List[JobScore] :
# Construire une invite pour que l'IA évalue les correspondances d'emploi en fonction du profil du candidat
prompt = f"""
"Vous êtes un recruteur expert. Étant donné le profil de candidat suivant:N"
"{profile_summary}nn"
"Description du poste souhaité:n{desired_job_summary}nn"
"Attribuez à chaque offre d'emploi une note précise de 0 à 100 en fonction de son adéquation avec le profil et l'emploi souhaité.N"
"Pour chaque offre d'emploi, ajoutez un bref commentaire (50 mots maximum) expliquant le score et la qualité de l'adéquation.n"
"Return an array of objects with keys 'job_posting_id', 'score', and 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role" : "system", "content" : "You are a helpful job scoring assistant."},
{"rôle" : "user", "content" : prompt},
]
# Utiliser l'API OpenAI pour analyser la réponse structurée dans le modèle JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Retourne la liste des emplois notés
return response.output_parsed.scores
def extend_jobs_with_scores(jobs : List[dict], all_scores : List[JobScore]) -> List[dict] :
# Où stocker les données enrichies
extended_jobs = []
# Combinez les emplois originaux avec les scores de l'IA et les commentaires
pour score_obj dans all_scores :
matched_job = None
pour job dans jobs :
si job.get("job_posting_id") == score_obj.job_posting_id :
matched_job = job
break
if matched_job :
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Trier les emplois étendus par score d'IA (le plus élevé en premier)
extended_jobs.sort(key=lambda j : j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs : List[dict], output_csv : str) :
# Obtient dynamiquement les noms des champs à partir du premier élément du tableau
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile :
# Écriture des données de travail étendues avec les scores AI au format CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
pour job dans extended_jobs :
writer.writerow(job)
print(f "Exported {len(extended_jobs)} jobs to {output_csv}")
def print_top_jobs(extended_jobs : List[dict], top : int = 3) :
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3] :
print(f "URL : {job.get('url', 'N/A')}")
print(f "Titre : {job.get('job_title', 'N/A')}")
print(f "Score AI : {job.get('ai_score')}")
print(f "Commentaire AI : {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main() :
# Obtenir les paramètres d'exécution à partir de la CLI
args = parse_cli_args()
try :
# Chargement des clés d'API depuis l'environnement
_, brightdata_api_key = load_env_vars()
# Chargement du fichier de configuration de la recherche d'emploi
config = load_and_validate_config(args.config_file)
# Récupérer les emplois
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs trouvés !")
except Exception as e :
print(f"[Erreur] {e}")
return
all_scores = []
# Traiter les jobs par lots pour éviter de surcharger l'API et pour gérer les grands ensembles de données
for i in range(0, len(jobs_data), args.batch_size) :
batch = jobs_data[i : i + args.batch_size]
print(f "Notation du lot {i // args.batch_size + 1} avec {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Pour éviter de déclencher les limites de débit de l'API
# Fusionner les scores dans les jobs scrappés
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Sauvegarde des résultats au format CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimer les meilleures correspondances avec des informations clés pour un examen rapide
print_top_jobs(extended_jobs)
if __name__ == "__main__" :
main()Supposons que vous êtes un chef de produit avec 7 ans d’expérience à la recherche d’un emploi hybride à New York. Configurez votre fichier config.json comme suit :
{
"location" : "New York",
"keyword" : "Product Manager",
"country" : "US",
"time_range" : "Past month",
"job_type" : "Temps plein",
"experience_level" : "Niveau moyen-supérieur",
"remote" : "Hybride",
"profile_summary" : "Chef de produit expérimenté avec 7 ans dans des startups technologiques, spécialisé dans les méthodologies agiles et la direction d'équipes interfonctionnelles",
"desired_job_summary" : "Je recherche un poste de chef de produit à temps plein axé sur les produits SaaS et le développement centré sur le client."
}Ensuite, vous pouvez exécuter l’assistant de recherche d’emploi de LinkedIn avec :
python assistant.pyFacultatif: Pour une exécution personnalisée, écrivez quelque chose comme :
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvCette commande lance l’assistant en utilisant le fichier config.json spécifié. Elle traite les offres par lots de 10, récupère jusqu’à 40 listes d’offres d’emploi de Bright Data et enregistre les résultats enrichis avec les scores AI et les commentaires dans le fichier results.csv.
Maintenant, si vous exécutez l’assistant avec les arguments CLI par défaut, vous devriez voir quelque chose comme ceci dans le terminal :
Recherche d'emploi LinkedIn déclenchée ! ID de l'instantané : s_me6x0s3qldm9zz0wv
Interrogation de l'instantané pour l'ID : s_me6x0s3qldm9zz0wv
L'instantané n'est pas encore prêt. Réessai dans 10 secondes...
# Omis par souci de concision...
L'instantané n'est pas encore prêt. Réessai dans 10 secondes...
L'instantané est prêt
20 travaux trouvés !
Noter le lot 1 avec 5 travaux...
Le lot 2 est noté avec 5 travaux...
Cotation du lot 3 avec 5 travaux...
Notation du lot 4 avec 5 travaux...
Exportation de 20 travaux vers jobs.csvEnsuite, la sortie avec les 3 meilleurs résultats sera quelque chose comme :
*** Les 3 meilleures offres d'emploi ***
URL : https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Titre : Chef de produit, croissance
Score AI : 92
Commentaire AI : Excellente adéquation : PM de croissance axé sur le SaaS avec des objectifs centrés sur le client, une croissance dirigée par le produit, l'expérimentation et la collaboration interfonctionnelle - une correspondance directe avec l'expérience du candidat et le rôle qu'il souhaite occuper.
----------------------------------------
URL : https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Titre : Chef de produit
Score AI : 90
Commentaire AI : Très bonne adéquation : Produit SaaS, API/intégrations, agile et leadership interfonctionnel mis en avant. La seule différence mineure est l'objectif de 2 à 4 ans (vous en avez 7), ce qui vous rend probablement surqualifié mais très applicable.
----------------------------------------
URL : https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Titre : Chef de produit
Score AI : 88
Commentaire AI : Un rôle très similaire dans le domaine du SaaS/des intégrations avec des pratiques agiles et une itération axée sur le client. Le recruteur cible 2 à 4 ans, mais vos 7 ans d'expérience en tant que PM dans une startup et votre leadership interfonctionnel correspondent bien à ce poste.
----------------------------------------Ouvrez le fichier jobs_scored.csv généré. Dans les colonnes principales, vous verrez :
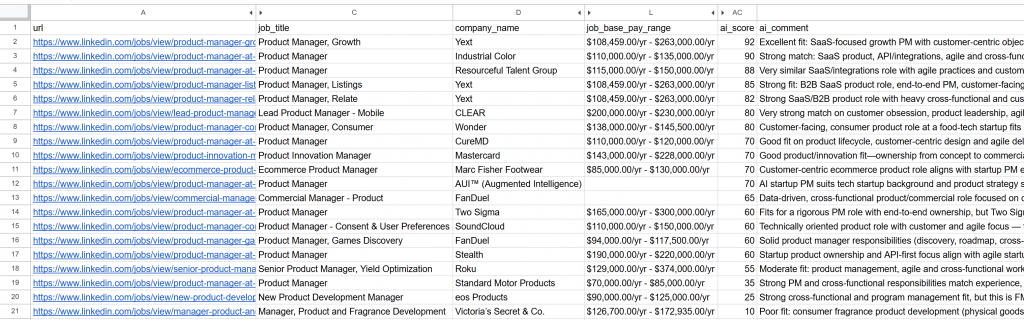
Remarquez que chaque poste a été noté et commenté par l’IA. Cela vous permet de vous concentrer uniquement sur les postes pour lesquels vous avez de réelles chances de réussite !
Et voilà ! Grâce à ce workflow de recherche d’emploi LinkedIn alimenté par l’IA, trouver votre prochain emploi n’a jamais été aussi facile.
Prochaines étapes
L’assistant de recherche d’emploi LinkedIn développé ici fonctionne comme un chat, mais il y a quelques améliorations qui méritent d’être explorées :
- Éviter d’évaluer les mêmes emplois à plusieurs reprises : Pour évaluer des offres différentes à chaque fois que vous exécutez le script, définissez le tableau
jobs_to_not_includedans votre fichierconfig.json. Ce tableau doit contenir lesjobs_posting_idsdes jobs que l’assistant a déjà analysés. Par exemple, pour exclure les travaux actuellement analysés, votre configuration pourrait ressembler à ceci :
{
"location" : "New York",
"mot-clé" : "Chef de produit",
"country" : "US",
"time_range" : "Past month",
"job_type" : "Temps plein",
"experience_level" : "Niveau moyen-supérieur",
"remote" : "Hybride",
"jobs_to_not_include" : ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- NOTE : Les ID des jobs à exclure
"profile_summary" : "Chef de produit expérimenté avec 7 ans dans des startups technologiques, spécialisé dans les méthodologies agiles et la direction d'équipes transversales",
"desired_job_summary" : "Je recherche un poste de chef de produit à temps plein axé sur les produits SaaS et le développement centré sur le client."
}- Automatiser l’exécution périodique des scripts: Planifiez l’exécution régulière du script (par exemple, tous les jours) à l’aide d’outils tels que Cron. Dans ce cas, n’oubliez pas de définir le bon argument d’
intervalle de temps(par exemple, “24 dernières heures”) et de mettre à jour la listejobs_to_not_includeafin d’exclure les offres que vous avez déjà évaluées. Cela vous permet de vous concentrer sur les nouvelles offres. - Utilisez un modèle de juge d’intelligence artificielle spécifique: Au lieu d’un modèle GPT-5 général, envisagez d’utiliser un modèle d’IA spécialisé , adapté à l’appariement et à l’évaluation des offres d’emploi. Ce simple changement peut considérablement améliorer la précision et la pertinence des évaluations d’emploi.
Conclusion
Dans cet article, vous avez appris à exploiter les capacités de grattage d’offres d’emploi de LinkedIn de Bright Data pour créer un assistant de recherche d’emploi alimenté par l’IA.
Le flux de travail de l’IA construit ici est parfait pour toute personne à la recherche d’un nouvel emploi et souhaitant maximiser ses chances en se concentrant uniquement sur les meilleures opportunités. Il permet d’économiser du temps et de l’énergie en postulant à des emplois qui correspondent réellement aux objectifs de carrière et qui ont plus de chances d’être embauchés.
Pour créer des flux de travail plus avancés, explorez la gamme complète de solutions pour la récupération, la validation et la transformation des données Web en direct dans l’infrastructure AI de Bright Data.
Créez un compte Bright Data gratuit et commencez à expérimenter nos outils de données prêts pour l’IA !
FAQ
L’exemple ci-dessus utilise LinkedIn comme source de données, mais vous pouvez facilement étendre le script pour qu’il fonctionne avec Indeed ou toute autre source d’offres d’emploi disponible via Bright Data. Pour plus de détails sur l’intégration avec Indeed, reportez-vous au scraper d’offres d’emploi d’Indeed.
Ce flux de travail d’IA s’appuie sur OpenAI en raison de sa large adoption et de sa popularité. Cependant, vous pouvez facilement l’adapter pour qu’il fonctionne avec d’autres fournisseurs de LLM tels que Gemini, Anthropic, Cohere ou tout modèle de langage étendu disponible dans l’API.
Les données renvoyées par LinkedIn Jobs Scraper sont de si bonne qualité et si bien structurées que vous pouvez les traiter pour le scoring en utilisant directement un LLM. Pour cette raison, vous n’avez pas nécessairement besoin de la complexité d’un agent autonome avec des capacités de raisonnement et de prise de décision.
Néanmoins, si vous souhaitez construire un agent IA de recherche d’emploi LinkedIn plus avancé, vous pouvez envisager l’architecture multi-agents suivante :
Job fetcher agent: Un agent IA intégré à l’infrastructure Bright Data (via l’outillage ou le MCP) qui appelle l’API LinkedIn Jobs Scraper pour récupérer et mettre à jour en permanence les listes d’offres d’emploi.
Job scorer agent: Agent spécialisé dans l’évaluation et la notation des offres d’emploi en fonction du profil et des préférences du candidat à l’aide d’un LLM.
Agent orchestrateur: Un agent de haut niveau qui coordonne les deux autres agents, en déclenchant de manière répétée des cycles de récupération et de notation des données jusqu’à ce qu’un nombre souhaité d’offres d’emploi pertinentes et bien notées soit obtenu.
Vous pouvez même programmer l’agent pour qu’il postule automatiquement à ces offres d’emploi à votre place. Si vous envisagez de créer un tel système de recherche d’emploi sur LinkedIn, nous vous recommandons d’utiliser une plateforme multi-agents comme CrewAI.




