
Dans ce tutoriel, vous apprendrez
- Ce qu’est Kiro et ses capacités techniques.
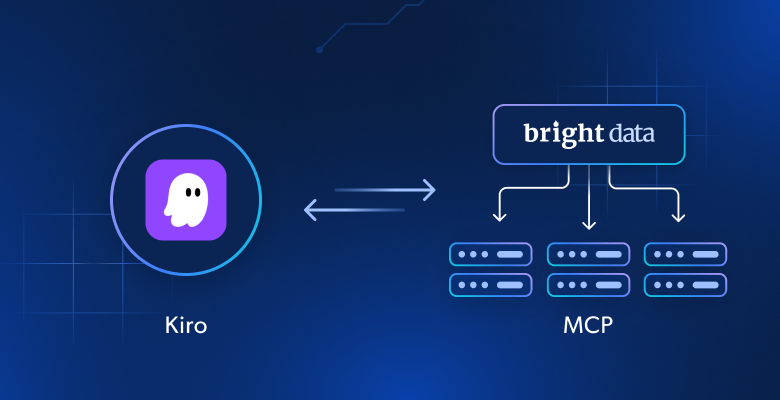
- Comment la connexion de Kiro aux serveurs Web MCP de Bright Data le transforme d’un générateur de code statique en un agent dynamique capable de récupérer des données en temps réel, de contourner les protections anti-bots et de générer des sorties structurées.
- Comment utiliser Kiro pour automatiser l’ensemble du processus de récupération des données du marché de l’emploi en temps réel, les organiser en fichiers CSV, générer des scripts d’analyse et produire des rapports perspicaces.
Visitez le projet sur GitHub.
Maintenant, commençons !
Qu’est-ce que Kiro ?
Kiro est un IDE alimenté par l’IA qui modifie la façon dont les développeurs travaillent en utilisant un développement axé sur les spécifications et des processus automatisés. Contrairement aux outils de codage IA classiques qui se contentent de générer du code, Kiro travaille de manière autonome, vérifiant les bases de code, modifiant plusieurs fichiers et construisant des fonctionnalités complètes du début à la fin.
Principales capacités techniques :
- Flux de travail axé sur les spécifications : Kiro transforme les demandes en exigences claires, en conceptions techniques et en tâches, ce qui élimine le “codage vibratoire”.
- Crochets d’agent : Tâches automatisées en arrière-plan, qui gèrent les mises à jour de la documentation, les tests et les vérifications de la qualité du code.
- Intégration MCP : La prise en charge intégrée du protocole de contexte de modèle permet d’établir des liens directs avec des outils, des bases de données et des API externes.
- Autonomie agentique : Exécution de tâches de développement en plusieurs étapes à l’aide d’un raisonnement axé sur les objectifs.
Construit sur les fondations de VS Code avec les modèles Claude d’Anthropic, Kiro conserve les flux de travail familiers tout en ajoutant une structure solide pour un développement prêt à l’emploi.
Pourquoi étendre Kiro avec les serveurs MCP de Bright Data ?
Le raisonnement agentique de Kiro est solide, mais ses LLM dépendent d’anciennes données de formation. La connexion de Kiro au serveur Web MCP de Bright Data transforme ces modèles “gelés” en agents à données vivantes. Ils peuvent accéder au contenu Web en temps réel, contourner les défenses anti-bots et fournir des résultats structurés directement dans le flux de travail de Kiro.
| Outil MCP | Utiliser |
|---|---|
moteur_de_recherche |
Récupérer les résultats des SERP de Google/Bing/Yandex pour une recherche instantanée sur la concurrence ou les tendances. |
scrape_as_markdown |
Scrape d’une page qui renvoie du Markdown lisible, parfait pour des documents/exemples rapides. |
scrape_batch |
Scrape parallèle de plusieurs URL ; idéal pour le suivi des prix ou les vérifications en vrac (revient aux outils à page unique en cas de dépassement du délai). |
web_data_amazon_product |
JSON propre avec le titre, le prix, l’évaluation et les images pour n’importe quel ASIN Amazon, aucune analyse HTML n’est nécessaire. |
En quoi cela est utile :
- Les données en temps réel (prix, documentation, tendances sociales) sont directement intégrées dans les spécifications et le code générés par Kiro.
- La gestion automatique des anti-bots permet aux agents de se concentrer sur la logique de développement, et non sur les maux de tête liés au scraping.
- Les réponses JSON structurées tombent directement dans TypeScript/Python sans manipulation de regex.
Avec Bright Data MCP connecté, chaque invite Kiro peut utiliser des ” données en direct ” comme élément clé, transformant la génération de code statique en une automatisation complète et prête à l’emploi.
Comment connecter Kiro au MCP de Bright Data ?
Dans cette section guidée, vous apprendrez à installer et à configurer Kiro avec le serveur Web MCP de Bright Data. Le résultat final sera un environnement de développement d’IA capable d’accéder aux données Web en temps réel et de les traiter directement dans votre flux de travail de codage.
Plus précisément, vous construirez une configuration Kiro améliorée avec des capacités de données Web et l’utiliserez pour :
- Récupérer des données en temps réel à partir de plusieurs sites
- Générer des spécifications structurées basées sur les informations actuelles du marché
- Traiter et analyser les données collectées dans votre environnement de développement.
Suivez les étapes ci-dessous pour commencer !
Conditions préalables
Pour suivre ce tutoriel, vous avez besoin de
- Node.js 18+ installé localement (nous recommandons la dernière version LTS)
- Accès à Kiro (nécessite de s’inscrire sur la liste d’attente et de recevoir une confirmation)
- Un compte Bright Data
Ne vous inquiétez pas si vous n’avez pas encore de compte Bright Data. Nous allons vous aider à le configurer dans les étapes suivantes.
Étape 1 : Installer et configurer Kiro
Avant d’installer Kiro, vous devez vous inscrire sur la liste d’attente à kiro.dev et recevoir une confirmation d’accès. Une fois l’accès obtenu, suivez le guide d’installation officiel.
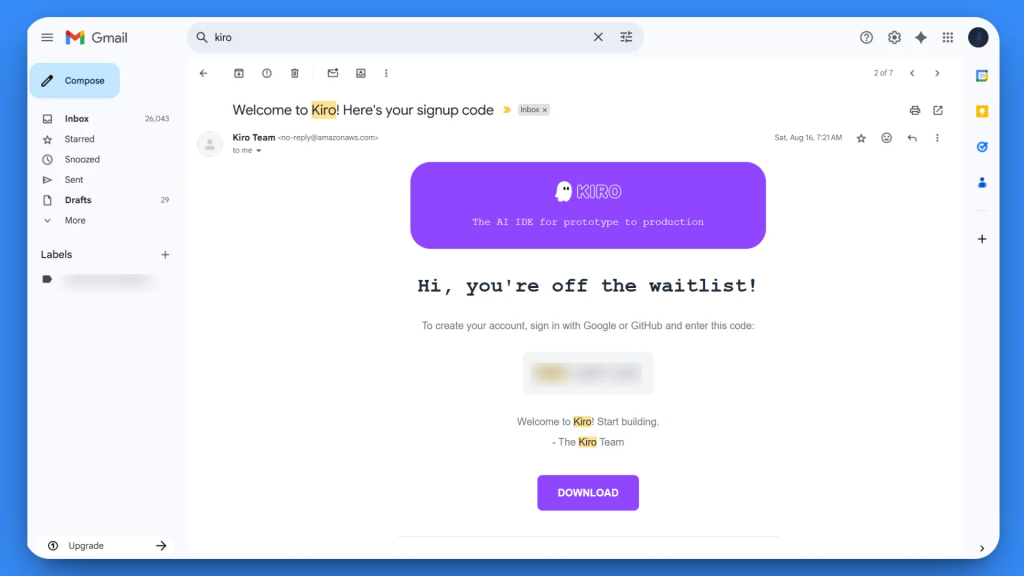
Au premier lancement, vous verrez l’écran de bienvenue. Suivez l’assistant d’installation pour configurer votre IDE.
Etape #2 : Configurer votre serveur MCP Bright Data
Rendez-vous sur le site de Bright Data et créez un compte Bright Data ou connectez-vous à votre compte existant.
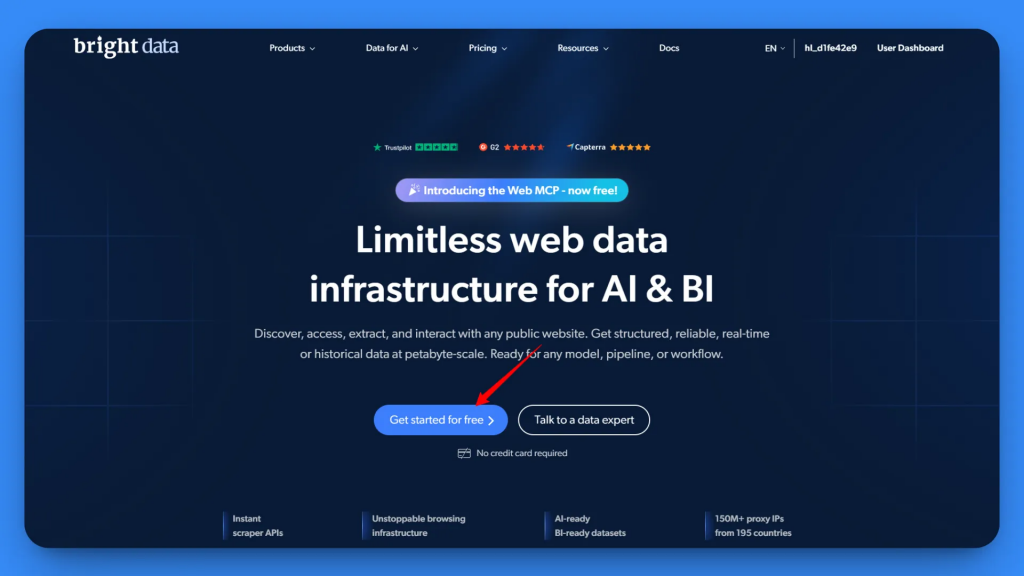
Après vous être connecté, vous arriverez sur la page d’accueil. Dans la barre latérale gauche, accédez à la section MCP.
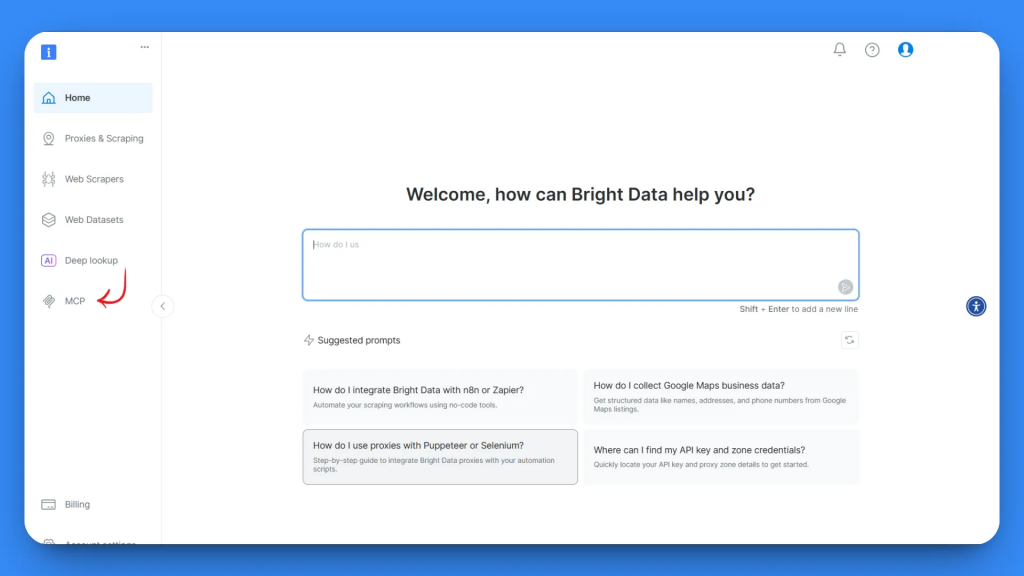
Dans la page de configuration MCP, vous trouverez deux options : Auto-hébergé et Hébergé. Pour ce tutoriel, nous utiliserons l’option auto-hébergé, qui offre un contrôle maximal.
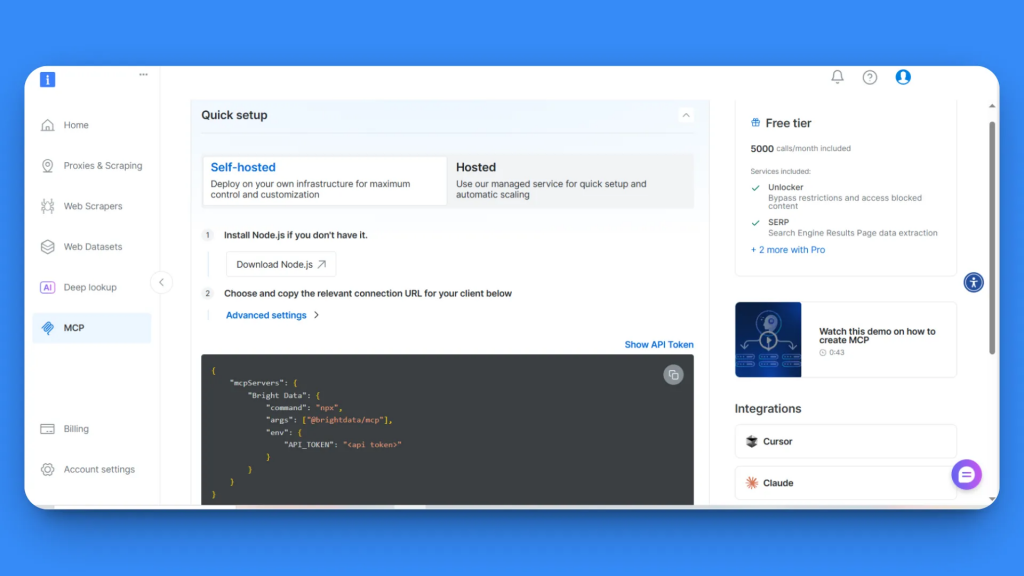
À l’étape 2, vous verrez votre clé API et un bloc de code de configuration MCP. Copiez l’intégralité du code de configuration MCP :
{
"mcpServers" : {
"Bright Data" : {
"command" : "npx",
"args" : ["@brightdata/mcp"],
"env" : {
"API_TOKEN" : "<api token>"
}
}
}
}Ceci contient tous les détails de connexion nécessaires et votre jeton API.
Étape 3 : Configurer MCP dans Kiro
Ouvrez Kiro et créez un nouveau projet ou ouvrez un dossier existant.
Dans la barre latérale gauche, naviguez jusqu’à l’onglet Kiro. Vous verrez quatre sections :
- SPECS
- CROCHETS DE L’AGENT
- DIRECTION DE L’AGENT
- SERVEURS MCP
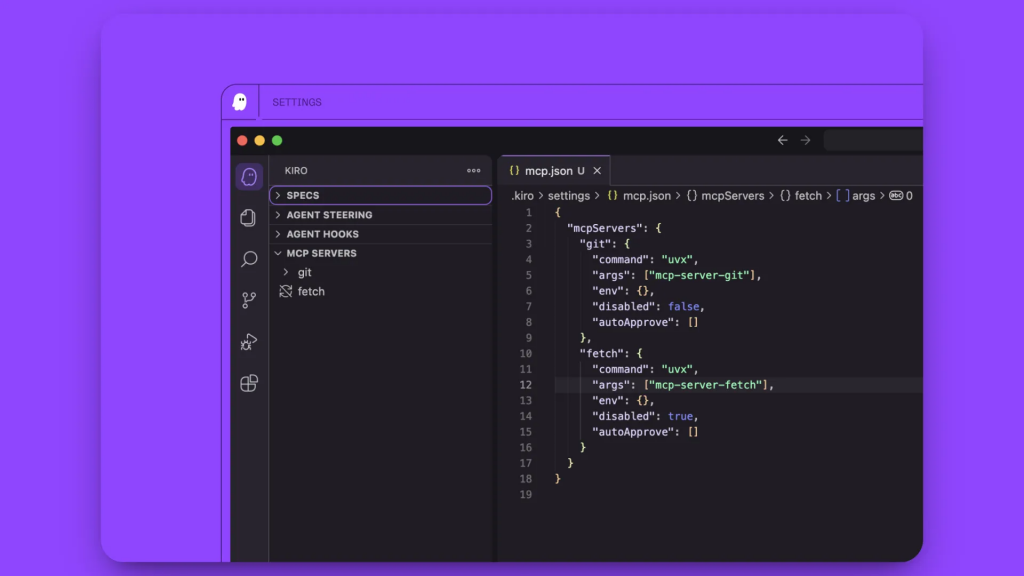
Cliquez sur la section SERVEURS MCP. Vous verrez un serveur préconfiguré déjà présent, supprimez cette configuration de serveur par défaut.
Ajoutez le code de configuration MCP que vous avez copié de Bright Data en le collant dans la zone de configuration.
Kiro commence à traiter la configuration. Au début, il peut afficher l’état “Connecting…” ou “Not Connected” pendant qu’il établit la connexion.
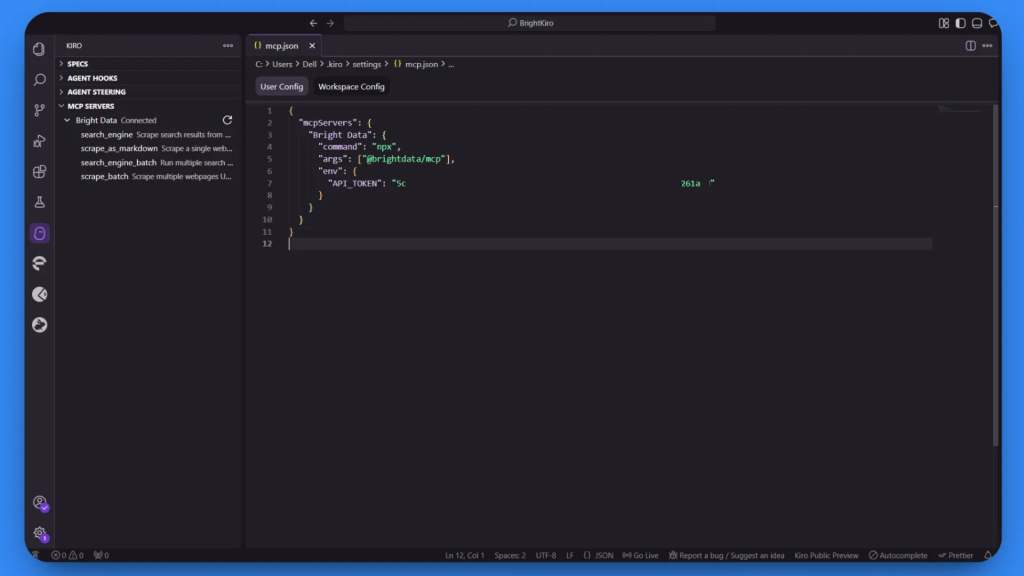
Une fois le traitement terminé avec succès, l’état passe à “Connecté” et quatre outils MCP deviennent disponibles :
moteur_de_recherchescrape_as_markdownmoteur_de_recherche_lotsscrape_batch
Étape 4 : Vérifier la connexion MCP
Pour tester l’intégration, cliquez sur l’un des outils MCP disponibles dans la barre latérale. Cela ajoutera automatiquement l’outil à l’interface de chat de Kiro.
Appuyez sur Entrée pour exécuter le test. Kiro traitera la demande via le serveur MCP de Bright Data et renverra des résultats correctement formatés, confirmant que l’intégration fonctionne correctement.
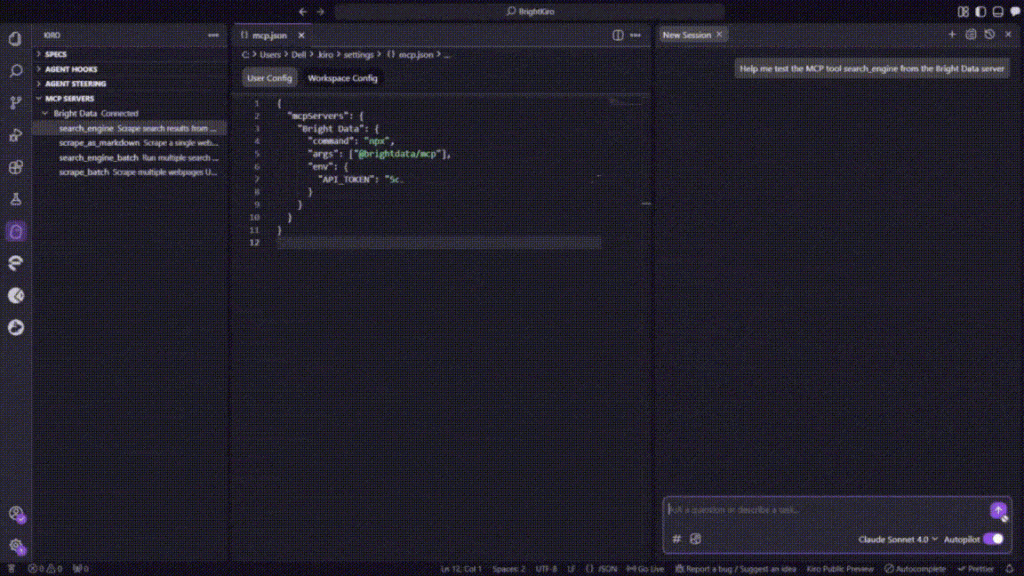
C’est parfait ! Votre installation Kiro a maintenant accès aux capacités de balayage Web de Bright Data par le biais de l’intégration MCP. Vous pouvez maintenant utiliser des invites en langage naturel pour extraire des données de n’importe quel site Web public directement dans votre développement.
Étape 5 : Exécution de la première tâche MCP dans Kiro
Testons maintenant l’intégration MCP de Kiro + Bright Data avec une tâche pratique de collecte de données. Cet exemple montre comment recueillir des données sur le marché de l’emploi et les traiter automatiquement.
Invite de test :
Recherchez "remote React developer jobs" sur Google, récupérez les 5 premiers sites d'offres d'emploi, extrayez les titres des postes, les entreprises, les fourchettes de salaires et les compétences requises. Créez un fichier CSV avec ces données et générez un script Python qui analyse les salaires moyens et les exigences les plus courantes.Ceci simule un cas d’utilisation réel pour :
- l’étude de marché et l’étalonnage des salaires
- Analyse des tendances en matière de compétences pour la planification des carrières
- Veille concurrentielle pour les équipes de recrutement
Collez cette invite dans l’interface de discussion de Kiro et appuyez sur Entrée.
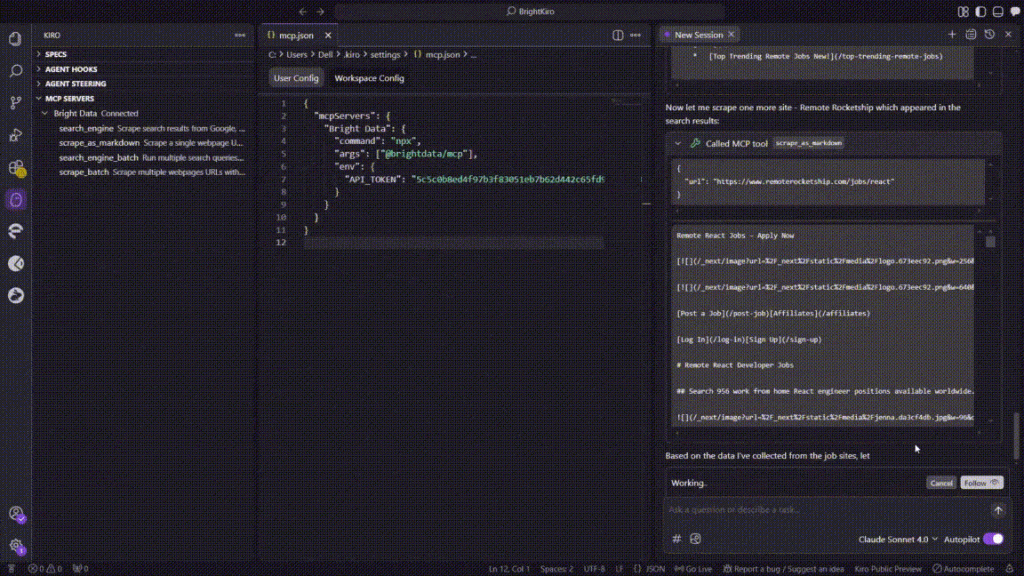
Vous trouverez ci-dessous la séquence exacte suivie par Kiro pendant l’exécution de cette tâche :
- Phase de recherche
- Kiro a appelé l’outil MCP
search_enginepour demander “remote React developer jobs” sur Google. - L’appel a renvoyé une liste des meilleures URL de job-board en ~3s.
- Kiro a appelé l’outil MCP
- Tentative de grattage par lots
- Kiro a invoqué
scrape_batchpour obtenir les cinq URL en une seule fois. - La requête par lot s’est arrêtée après ~60s, Kiro a donc enregistré une erreur MCP
(32001 Request timed out).
- Kiro a invoqué
- Retour au scraping d’une seule page
- Kiro est passé à
scrape_as_markdown, en scrappant chaque site séquentiellement :
- En effet
- ZipRecruiter
- Wellfound
- Nous travaillons à distance
- Chaque scrape s’est terminé en 4-10 s et a retourné du Markdown lisible.
- Kiro est passé à
- Structuration des données
- Une routine d’analyse a extrait les champs titre du poste, société, salaire, compétences et source.
- Kiro a agrégé les lignes nettoyées dans une table en mémoire.
- Création d’un fichier CSV
- Kiro a enregistré le tableau sous le nom
remote_react_jobs.csvdans l’espace de travail.
- Kiro a enregistré le tableau sous le nom
- Transfert de session (continuation du contexte)
- Le chat original a dépassé la fenêtre de contexte de Kiro.
- Kiro a ouvert une nouvelle session de discussion, en important automatiquement le contexte précédent pour éviter la perte de données.
- Génération de scripts d’analyse Python
- Dans la nouvelle session, Kiro a créé le
fichier analyze_react_jobs.py, qui comprend les éléments suivants :- Chargement et nettoyage du fichier CSV
- Logique de résumé des salaires/compétences
- Code graphique Matplotlib + Seaborn
- Le script se termine par
print("Analyse terminée").
- Dans la nouvelle session, Kiro a créé le
Les outils MCP de BrightData ont aidé Kiro à gérer automatiquement :
- la résolution desCAPTCHA et la détection des robots sur les sites d’emploi
- l’extraction de données à partir de différentes mises en page de sites Web
- Standardisation des formats de salaires et des listes de compétences
- Création d’une structure CSV appropriée avec des en-têtes
- Stratégie de scraping adaptative lorsque les opérations par lots se heurtent à des dépassements de temps.
Étape 6 : Explorer et utiliser les résultats
Une fois que Kiro a terminé la tâche, vous aurez deux fichiers principaux dans votre répertoire de projet :
remote_react_jobs.csv: Contient des données structurées sur le marché de l’emploianalyze_react_jobs.py: Script Python pour l’analyse et la compréhension des données
Ouvrez le fichier remote_react_jobs.csv pour voir les données collectées :
Le fichier CSV contient des informations réelles sur le marché de l’emploi avec des colonnes telles que :
- Titre du poste
- Nom de l’entreprise
- Fourchette de salaire
- Compétences requises
- Source de l’offre d’emploi
Ces données proviennent d’offres d’emploi réelles, et non d’un contenu de type placeholder. Le serveur MCP de Bright Data s’est chargé de la tâche complexe d’extraction d’informations structurées à partir de plusieurs sites d’emploi ayant des mises en page et des formats différents.
Examinez ensuite le script analyze_react_jobs.py généré.
Ce script comprend des fonctions permettant de
- charger et nettoyer les données CSV
- Calculer les fourchettes de salaires moyens
- Identifier les compétences requises les plus courantes
- Générer des statistiques sommaires
- Créer des visualisations et des rapports détaillés
Avant d’exécuter le script d’analyse, installez les dépendances requises :
pip install -r requirements.txtExécutez ensuite le script d’analyse pour obtenir des informations détaillées :
python analyze_react_jobs.pyLorsque vous exécutez le script, il génère automatiquement deux fichiers supplémentaires:
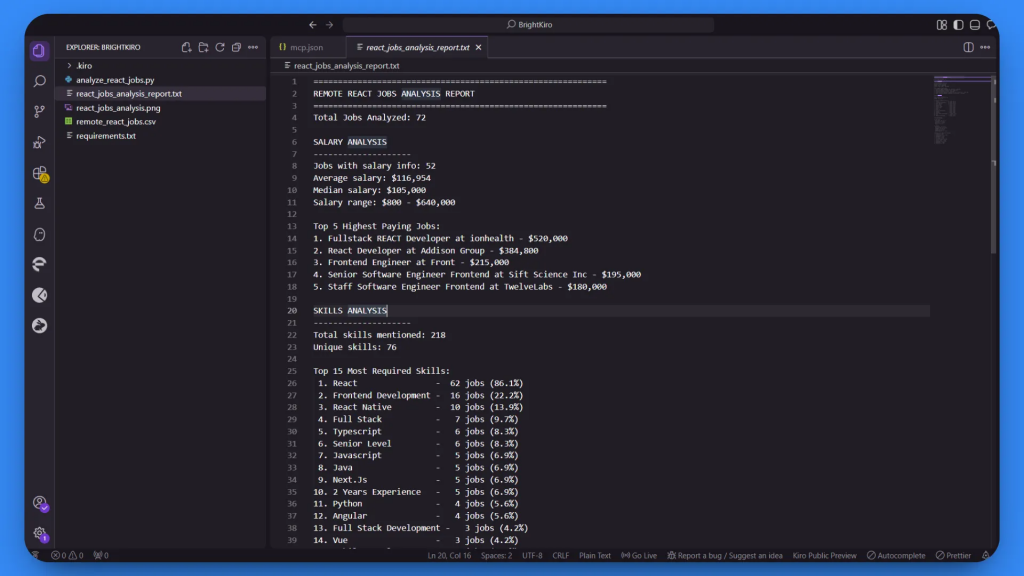
1. Rapport textuel détaillé (react_jobs_analysis_report.txt) :
2. Graphique d’analyse visuelle (react_jobs_analysis.png) :
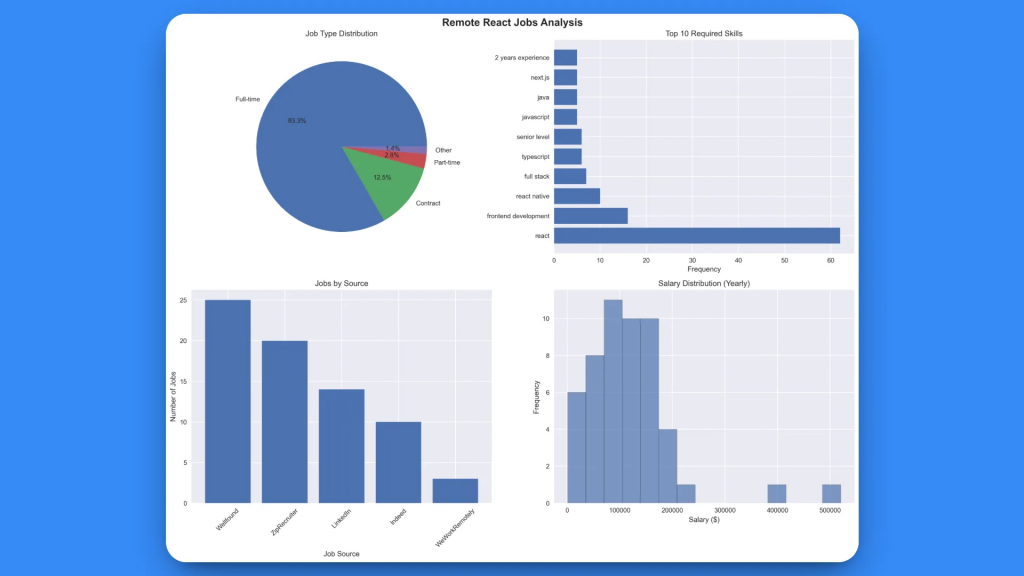
L’analyse complète est basée sur 72 jobs collectés avec succès.
La visualisation générée fournit quatre informations clés :
- Distribution des types d’emploi: Répartition claire des emplois à temps plein, des emplois contractuels et des emplois à temps partiel
- Les 10 compétences les plus demandées: Représentation visuelle de la fréquence de la demande de compétences
- Emplois par source: Volumes d’offres d’emploi spécifiques aux plates-formes
- Répartition des salaires: Histogramme montrant les fourchettes de salaires pour tous les postes
Cet exemple montre comment Kiro transforme une simple demande en langage naturel en un processus complet de collecte et d’analyse de données. L’intégration traite automatiquement les problèmes liés au web scraping, comme l’ajustement en cas d’interruption des opérations par lots, tout en créant un code prêt à l’emploi, des rapports détaillés et des visuels professionnels pour les études de marché en cours.
Conclusion
C’est tout pour ce tutoriel. Dans ce blog, vous avez appris à améliorer Kiro en le connectant aux serveurs Web MCP de Bright Data. Cela vous permet de récupérer des données Web en direct et de traiter des informations en temps réel directement dans votre configuration de développement d’IA.
Nous l’avons montré avec un exemple pratique de récupération, de nettoyage, d’analyse et de visualisation de travaux de développeurs React distants provenant de différentes sources. Cette automatisation complète démontre la force de la combinaison de l’IA de Kiro avec les outils de scraping de premier ordre de Bright Data.
En utilisant cette intégration, les développeurs peuvent aller au-delà de la génération de code statique et passer à des flux de travail entièrement automatisés et axés sur les données qui accélèrent le développement de produits et améliorent la précision.
Créez votre compte Bright Data dès aujourd’hui et commencez à utiliser l’intelligence Web en temps réel pour alimenter vos agents d’IA.





