
Dans ce tutoriel, vous apprendrez
- Ce qu’est Flyte et ce qui le rend spécial pour les flux de travail d’IA, de données et d’apprentissage automatique.
- Pourquoi les flux de travail Flyte deviennent encore plus puissants lorsque vous y incorporez des données web.
- Comment intégrer Flyte avec le SDK Bright Data pour construire un flux de travail alimenté par l’IA pour l’analyse SEO.
Plongeons dans le vif du sujet !
Qu’est-ce que Flyte ?
Flyte est une plateforme d’orchestration de flux de travail moderne et open-source qui vous aide à créer des pipelines d’IA, de données et d’apprentissage automatique de niveau de production. Sa principale force réside dans l’unification des équipes et des piles technologiques, favorisant la collaboration entre les data scientists, les ingénieurs ML et les développeurs.
Construit sur Kubernetes, Flyte est conçu pour l’évolutivité, la reproductibilité et le traitement distribué. Vous pouvez l’utiliser pour définir des flux de travail via son SDK Python. Ensuite, déployez-les dans des environnements cloud ou sur site, ouvrant la voie à une utilisation efficace des ressources et à une gestion simplifiée des flux de travail.
À l’heure où nous écrivons ces lignes, le dépôt GitHub de Flyte compte plus de 6,5k étoiles !
Fonctionnalités principales
Les principales fonctionnalités prises en charge par Flyte sont les suivantes :
- Interfaces fortement typées: Définir les types de données à chaque étape pour assurer la correction et appliquer les garde-fous de données.
- Immutabilité: Les exécutions immuables garantissent la reproductibilité en empêchant les changements de l’état d’un flux de travail.
- Lignage des données: Suivez le mouvement et la transformation des données tout au long du cycle de vie du flux de travail.
- Tâches de mappage et parallélisme: Exécutez des tâches en parallèle de manière efficace avec une configuration minimale.
- Réexécutions granulaires et reprise sur panne: Réessayer uniquement les tâches qui ont échoué ou réexécuter des tâches spécifiques sans modifier les états antérieurs du flux de travail.
- Mise en cache : mettre en cache les résultats des tâches afin d’optimiser les exécutions répétées.
- Flux de travail dynamiques et ramifications: créez des flux de travail adaptables qui évoluent en fonction des besoins et exécutez des ramifications de manière sélective.
- Flexibilité linguistique: Développez des flux de travail à l’aide de Python, Java, Scala, des SDK JavaScript ou des conteneurs bruts dans n’importe quel langage.
- Déploiement cloud-natif: Déployez Flyte sur AWS, GCP, Azure ou d’autres fournisseurs de cloud.
- Simplicité du développement à la production: Déplacez les flux de travail du développement ou de la mise en scène vers la production sans effort.
- Gestion des entrées externes : Pause de l’exécution jusqu’à ce que les entrées requises soient disponibles.
Pour découvrir toutes les fonctionnalités, consultez la documentation officielle de Flyte.
Pourquoi les workflows d’IA ont besoin de données Web fraîches
La puissance des workflows d’IA dépend des données qu’ils traitent. Certes, les données ouvertes sont précieuses, mais c’est l’accès aux données en temps réel qui fait la différence d’un point de vue commercial. Et quelle est la plus grande et la plus riche source de données? Le web !
En incorporant des données web en temps réel dans vos flux de travail d’IA, vous pouvez obtenir des informations plus approfondies, améliorer la précision des prédictions et prendre des décisions plus éclairées. Par exemple, des tâches telles que l’analyse SEO, l’étude de marché ou le suivi du sentiment d’appartenance à une marque reposent toutes sur des informations actualisées, qui changent constamment en ligne.
Le problème est qu’il est difficile d’obtenir des données web fraîches. Les sites web ont des structures différentes, nécessitent des approches de scraping différentes et sont soumis à des mises à jour fréquentes. C’est là qu’intervient une solution telle que le SDK Python de Bright Data!
Le SDK vous permet de rechercher, d’extraire et d’interagir avec le contenu web en direct de manière programmatique. Plus précisément, il permet d’accéder aux produits les plus utiles de l’infrastructure Bright Data par le biais de quelques appels de méthode simples. L’accès aux données web est ainsi à la fois fiable et évolutif.
En combinant les capacités web de Flyte et de Bright Data, vous pouvez créer des flux de travail d’IA automatisés qui restent en phase avec l’évolution constante du web. Découvrez comment dans le chapitre suivant !
Comment construire un workflow SEO AI avec Flyte et Bright Data Python SDK
Dans cette section guidée, vous apprendrez comment construire un agent d’IA dans Flyte qui :
- Prend un mot-clé (ou une phrase-clé) en entrée et utilise le SDK de Bright Data pour rechercher des résultats pertinents sur le Web.
- Utilise le SDK Bright Data pour extraire les 3 premières pages pour le mot-clé donné.
- Transmet le contenu des pages résultantes à OpenAI pour générer un rapport Markdown contenant des informations sur le référencement.
En d’autres termes, grâce à l’intégration Flyte + Bright Data, vous créerez un véritable flux de travail d’IA pour l’analyse SEO. Cela permet d’obtenir des informations exploitables sur le contenu, basées sur ce que font les pages les plus performantes pour bien se classer.
C’est parti !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir :
- Python installé localement
- Une clé API Bright Data (avec des droits d’administrateur )
- Une clé API OpenAI
Vous serez guidé dans la configuration de votre compte Bright Data pour l’utilisation du SDK Python de Bright Data, vous n’avez donc pas à vous en préoccuper pour le moment. Pour plus d’informations, consultez la documentation.
Le guide d’installation officiel de Flyte recommande d’installer via uv. Donc, installez/mettez à jour uv globalement avec :
pip install -U uvEtape #1 : Configuration du projet
Ouvrez un terminal et créez un nouveau répertoire pour votre projet d’analyse SEO AI :
mkdir flyte-seo-workflowLe dossier flyte-seo-workflow/ contiendra le code Python pour votre workflow Flyte.
Ensuite, naviguez dans le répertoire du projet :
cd flyte-seo-workflowA ce jour, Flyte ne supporte que les versions de Python >=3.9 et <3.13 (la version 3.12 est recommandée).
Configurez un environnement virtuel pour Python 3.12 avec :
uv venv --python 3.12Activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, exécutez : source .venv/Scripts/activate
.venv/Scripts/activateAjoutez un nouveau fichier appelé workflow.py. Votre projet devrait maintenant contenir :
flyte-seo-workflow/
├── .venv/
└── workflow.pyworkflow.py représente votre fichier Python principal.
L’environnement virtuel étant activé, installez les dépendances nécessaires :
uv pip install flytekit brightdata-sdk openai.Les bibliothèques que vous venez d’installer sont
flytekit: Pour créer des flux de travail et des tâches Flyte.brightdata-sdk: Pour vous aider à accéder aux solutions de Bright Data en Python.openai: Pour interagir avec les LLM d’OpenAI.
Remarque: Flyte fournit un connecteur ChatGPT officiel(ChatGPTTask), mais celui-ci repose sur une ancienne version des API OpenAI. Il comporte également certaines limitations, telles que des délais d’attente stricts. Pour ces raisons, il est généralement préférable de procéder à une intégration personnalisée.
Chargez le projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
C’est fait ! Vous avez maintenant un environnement Python prêt pour le développement de flux de travail d’IA dans Flyte.
Etape #2 : Concevoir votre workflow d’IA
Avant de se lancer directement dans le codage, il est utile de prendre du recul et de réfléchir à ce que votre flux de travail d’IA doit faire.
Tout d’abord, rappelez-vous qu’un flux de travail Flyte se compose de :
- Tâches: Fonctions marquées de l’annotation
@task. Ce sont les unités fondamentales de calcul dans Flyte. Les tâches sont des blocs de construction exécutables indépendamment, fortement typés et conteneurisés qui constituent les flux de travail. - Flux de travail: Marqués par
@workflow, les flux de travail sont construits en enchaînant les tâches, la sortie d’une tâche alimentant l’entrée de la suivante pour former un graphe acyclique dirigé (DAG).
Dans ce cas, vous pouvez atteindre votre objectif avec les trois tâches simples suivantes :
get_seo_urls: À partir d’un mot-clé ou d’une phrase-clé, utilisez le SDK Bright Data pour extraire les trois premières URL de la SERP (page de résultats des moteurs de recherche) de Google.get_content_pages: Reçoit les URL en entrée et utilise le SDK de Bright Data pour récupérer les pages, en renvoyant leur contenu au format Markdown(idéal pour le traitement par l’IA).generate_seo_report: Récupère la liste du contenu des pages et la transmet à une invite, en lui demandant de produire un rapport Markdown contenant des informations sur le référencement, telles que les approches courantes, les statistiques clés (nombre de mots, paragraphes, H1, H2, etc.) et d’autres mesures pertinentes.
Préparez la mise en œuvre des tâches et du flux de travail Flyte en les important depuis flytekit:
from flytekit import task, workflowC’est parfait ! Il ne reste plus qu’à mettre en œuvre le flux de travail proprement dit.
Étape 3 : Gérer les clés API
Avant d’implémenter les tâches, vous devez vous occuper de la gestion des clés API pour les intégrations OpenAI et Bright Data.
Flyte est livré avec un système de gestion des secrets dédié, qui vous permet de gérer en toute sécurité les secrets dans vos scripts, tels que les clés d’API et les informations d’identification. En production, s’appuyer sur le système de gestion des secrets de Flyte est la meilleure pratique et est fortement recommandé.
Pour ce tutoriel, puisque nous travaillons avec un script simple, nous pouvons simplifier les choses en définissant les clés API directement dans le code :
import os
os.environ["OPENAI_API_KEY"] = "<Votre_CLÉ_API_OPENAI>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<Votre_BRIGHTDATA_API_TOKEN>"Remplacez les caractères de remplacement par les valeurs réelles de votre clé d’API :
<YOUR_OPENAI_API_KEY>→ Votre clé d’API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Votre clé d’API Bright Data (récupérez-la comme expliqué dans le guide officiel de Bright Data).
Gardez à l’esprit qu’il est recommandé d’utiliser une clé d’API Bright Data avec des droits d’administrateur. Cela permet au SDK Python de Bright Data de se connecter automatiquement à votre compte et de configurer les produits requis lors de l’initialisation du client.
En d’autres termes, le SDK Python de Bright Data avec une clé API administrateur configurera automatiquement votre compte avec tout ce dont il a besoin pour fonctionner.
N’oubliez pas: Ne jamais coder en dur des secrets dans des scripts de production ! Utilisez toujours un gestionnaire de secrets dans Flyte.
Etape #4 : Implémenter la tâche get_seo_urls
Définissez une fonction get_seo_urls() qui accepte un mot clé en tant que chaîne, et annotez-la avec @task pour qu’elle devienne une tâche Flyte valide. Dans la fonction, utilisez la méthodesearch() du SDK Python de Bright Data pour effectuer une recherche sur le Web.
En coulisses, search() appelle l’API SERP de Bright Data, qui renvoie les résultats de la recherche sous la forme d’une chaîne JSON au format suivant :
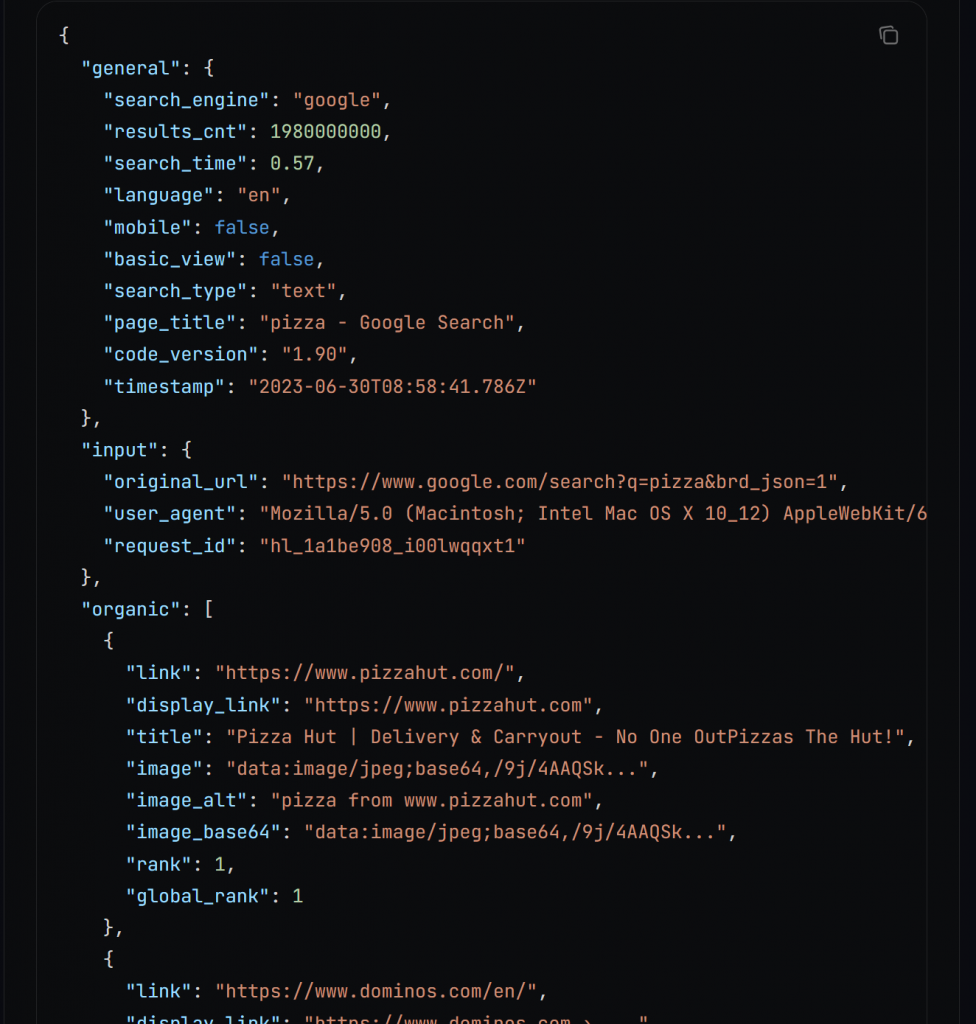
Pour en savoir plus sur la fonction de sortie JSON , consultez la documentation.
Analysez la chaîne JSON dans un dictionnaire et extrayez un nombre donné d’URL de référencement. Ces URL correspondent aux X premiers résultats que vous obtiendriez normalement sur Google en recherchant le mot-clé saisi.
Implémenter la tâche avec :
@task()
def get_seo_urls(kw : str, num_links : int = 3) -> List[str] :
import json
# Initialisation du client SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtenir la SERP de Google pour le mot-clé donné sous forme de chaîne JSON analysée
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"]
data = json.loads(json_response)
# Extraire de la SERP les URL des pages SEO les plus importantes en termes de "num_links".
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urlsN’oubliez pas l’importation requise pour le typage :
from typing import ListRemarque: vous vous demandez peut-être pourquoi le client SDK Python de Bright Data est importé à l’intérieur de la tâche plutôt que globalement. C’est intentionnel, car les tâches Flyte doivent être exécutables de manière indépendante. En d’autres termes, chaque tâche doit inclure tout ce dont elle a besoin pour s’exécuter seule, sans dépendre de dépendances globales.
Étape 5 : Mettre en œuvre la tâche get_content_pages
Maintenant que vous avez récupéré les URL SEO, vous pouvez les passer à la méthodescrape() du SDK Python de Bright Data. Cette méthode scrape toutes les pages en parallèle et renvoie leur contenu. Pour recevoir la sortie au format Markdown, il suffit de définir l’argument data_format="markdown":
@task()
def get_content_pages(page_urls:List[str]) -> List[str] :
# Initialisation du client SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Récupère le contenu Markdown de chaque page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list sera une liste de chaînes, où chaque chaîne est la représentation Markdown de la page d’entrée correspondante.
Sous le capot, scrape() appelle l’API Bright Data Web Unlocker. Il s’agit d’une API de scraping polyvalente capable d’accéder à n’importe quelle page web, indépendamment de ses protections anti-bots.
Quelles que soient les URL obtenues dans la tâche précédente, get_content_pages() récupérera avec succès leur contenu et le convertira du HTML brut en Markdown optimisé et prêt pour l’IA.
Étape 6 : Mettre en œuvre la tâche generate_seo_report
Appelez l’API OpenAI avec l’invite appropriée pour générer un rapport SEO basé sur le contenu de la page récupérée :
def generate_seo_report(page_content_list : List[str]) -> str :
# Initialiser le client OpenAI pour appeler les API OpenAI
from openai import OpenAI
openai_client = OpenAI()
# L'invite pour générer le rapport SEO désiré
prompt = f"""
# Étant donné le contenu ci-dessous pour quelques pages web,
# produire un rapport structuré au format Markdown contenant des informations SEO obtenues en analysant le contenu de chaque page.
# Le rapport devrait inclure :
# - Les sujets et éléments communs à toutes les pages
# - Les principales différences entre les pages
# Un tableau récapitulatif comprenant des statistiques telles que le nombre de mots, le nombre de paragraphes, le nombre de titres H2 et H3, etc.
# CONTENU :
# {"nPAGE :".join(page_content_list)}
# """
# Exécuter l'invite sur le modèle d'IA sélectionné
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_textLe résultat de cette tâche sera le rapport SEO Markdown souhaité.
Note: Le modèle OpenAI utilisé ci-dessus était GPT-5-mini, mais vous pouvez le remplacer par n’importe quel autre modèle OpenAI. De même, vous pouvez remplacer l’intégration OpenAI par n’importe quel autre fournisseur LLM.
Fantastique ! Les tâches sont prêtes et il est maintenant temps de les combiner dans un flux de travail Flyte AI.
Étape 7 : Définir le flux de travail d’IA
Créez une fonction @workflow qui orchestre les tâches en séquence :
@workflow
def seo_ai_workflow() -> str :
input_kw = "best llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return reportDans ce flux de travail :
- La tâche
get_seo_urlsrécupère les 3 premières URL de référencement pour la phrase clé “best llms”. - La tâche
get_content_pagesrécupère et convertit le contenu de ces URL en Markdown. - La tâche
generate_seo_reportprend ce contenu Markdown et produit un rapport final d’analyse SEO au format Markdown.
La mission est terminée !
Étape n° 8 : Assembler le tout
Votre fichier workflow.py final doit contenir les éléments suivants
from flytekit import task, workflow
import os
from typing import List
# Définissez les secrets requis (remplacez-les par vos clés d'API)
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<Votre_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw : str, num_links : int = 3) -> List[str] :
import json
# Initialisation du client SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtenir la SERP de Google pour le mot-clé donné sous forme de chaîne JSON analysée
res = bright_data_client.search(kw, response_format="json", parse=True)
# Analyse la chaîne JSON pour la convertir en dictionnaire
json_response = res["body"]
data = json.loads(json_response)
# Extraire les URLs de la page SEO "num_links" les plus importantes de la SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@task()
def get_content_pages(page_urls : List[str]) -> List[str] :
# Initialisation du client SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Récupère le contenu Markdown de chaque page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@task
def generate_seo_report(page_content_list : List[str]) -> str :
# Initialiser le client OpenAI pour appeler les API OpenAI
from openai import OpenAI
openai_client = OpenAI()
# L'invite pour générer le rapport SEO désiré
prompt = f"""
# Étant donné le contenu ci-dessous pour quelques pages web,
# produire un rapport structuré au format Markdown contenant des informations SEO obtenues en analysant le contenu de chaque page.
# Le rapport devrait inclure :
# - Les sujets et éléments communs à toutes les pages
# - Les principales différences entre les pages
# Un tableau récapitulatif comprenant des statistiques telles que le nombre de mots, le nombre de paragraphes, le nombre de titres H2 et H3, etc.
# CONTENU :
# {"nPAGE :".join(page_content_list)}
# """
# Exécuter l'invite sur le modèle d'IA sélectionné
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text
@workflow
def seo_ai_workflow() -> str :
input_kw = "best llms" # Changez-le pour qu'il corresponde à vos objectifs d'analyse SEO
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
Retourner le rapport
si __name__ == "__main__" :
seo_ai_workflow()Ouah ! En moins de 80 lignes de code Python, vous venez de construire un flux de travail SEO AI complet. Cela n’aurait pas été possible sans Flyte et le SDK Bright Data.
Vous pouvez exécuter votre workflow depuis le CLI avec :
pyflyte run workflow.py seo_ai_workflowCette commande lancera la fonction @workflow seo_ai_workflow à partir du fichier workflow.py.
Remarque: Les résultats peuvent prendre un certain temps à apparaître, car la recherche sur le web, le scraping et le traitement de l’IA prennent du temps.
Lorsque le flux de travail est terminé, vous devriez obtenir un résultat Markdown similaire à celui-ci :
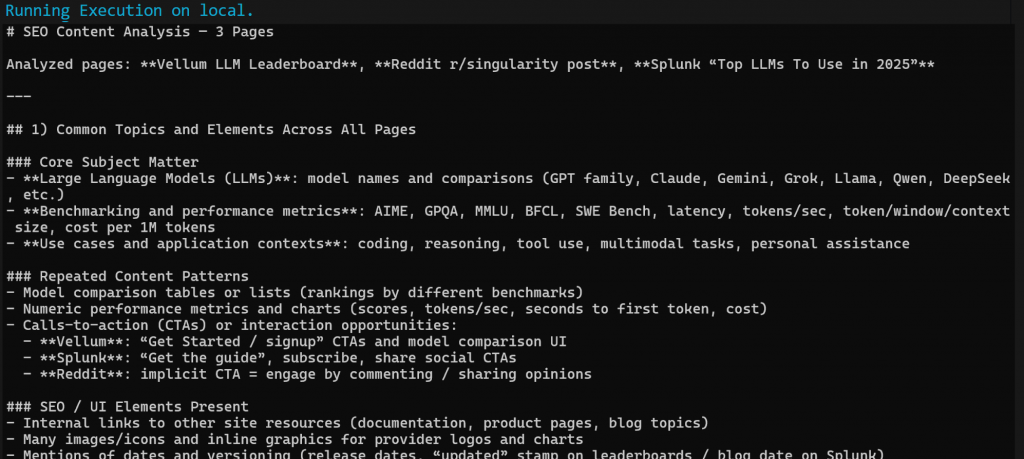
Collez la sortie Markdown dans n’importe quelle visionneuse Markdown pour la faire défiler et l’explorer. Il devrait ressembler à ce qui suit :
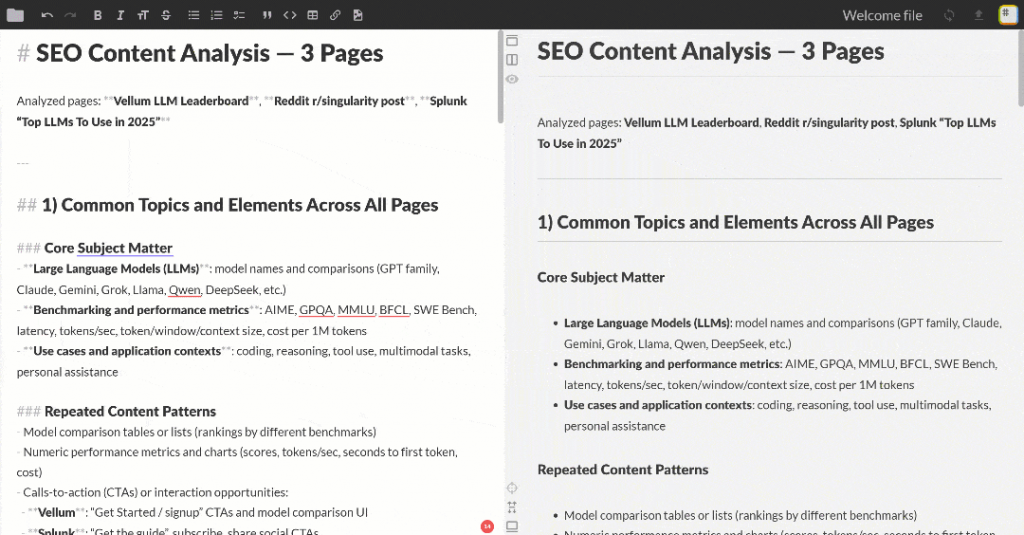
Le résultat contient plusieurs informations sur le référencement et un tableau récapitulatif, exactement comme demandé par OpenAI. Ceci n’était qu’un simple exemple de la puissance de l’intégration Flyte + Bright Data !
Et voilà ! N’hésitez pas à définir d’autres tâches et à essayer différents LLM pour mettre en œuvre d’autres cas d’utilisation utiles de flux de travail agentique et d’IA.
Prochaines étapes
La mise en œuvre du flux de travail d’IA de Flyte fournie ici n’est qu’un exemple. Pour le rendre prêt à la production, ou pour procéder à une mise en œuvre correcte, les prochaines étapes sont les suivantes :
- Intégrer un système de gestion des secrets supporté par Flyte: Éviter de coder en dur les clés API dans le code. Utilisez les secrets de tâches Flyte ou d’autres systèmes supportés pour gérer les informations d’identification de manière sécurisée et élégante.
- Gestion des invites: Générer des invites à l’intérieur d’une tâche est acceptable, mais pour la reproductibilité, envisagez de versionner vos invites ou de les stocker à l’extérieur.
- Déployez le flux de travail: Suivez les instructions officielles pour dockeriser votre flux de travail et le préparer au déploiement en utilisant les capacités de Flyte.
Conclusion
Dans cet article de blog, vous avez appris à utiliser les capacités de recherche et de scraping web de Bright Data dans Flyte pour créer un flux de travail d’analyse SEO alimenté par l’IA. Le processus de mise en œuvre a été simplifié grâce au SDK de Bright Data, qui permet d’accéder facilement aux produits Bright Data par le biais d’appels de méthode directs.
Pour créer des flux de travail plus sophistiqués, explorez l’ensemble des solutions de l’infrastructure d’IA de Bright Data pour récupérer, valider et transformer les données Web en direct.
Ouvrez un compte Bright Data gratuitement et commencez à expérimenter nos solutions de données Web prêtes pour l’IA !





