

Dans ce tutoriel, vous apprendrez
- Pourquoi vous avez besoin d’une solution personnalisée de surveillance de la marque en premier lieu.
- Comment en créer une à l’aide du SDK Bright Data, d’OpenAI et de SendGrid.
- Comment mettre en œuvre un flux de travail d’IA de surveillance de la réputation de la marque en Python.
Vous pouvez consulter le dépôt GitHub pour tous les fichiers du projet. Maintenant, plongeons dans le vif du sujet !
Pourquoi créer une solution personnalisée de surveillance de la marque ?
Lasurveillance de la marque est l’une des tâches les plus importantes du marketing, et il existe plusieurs services en ligne pour l’aider. Le problème de ces solutions est qu’elles ont tendance à être chères et qu’elles peuvent ne pas être adaptées à vos besoins spécifiques.
C’est pourquoi il est judicieux de créer une solution personnalisée de surveillance de la réputation de la marque. À première vue, cela peut sembler intimidant, car l’objectif est complexe. Cependant, avec les bons outils (comme vous allez le voir), c’est tout à fait réalisable.
Workflow d’IA pour la réputation de la marque Workflow expliqué
Tout d’abord, vous ne pouvez pas créer un outil de surveillance de la marque efficace sans disposer d’informations externes fiables sur votre marque. Google News est une excellente source à cet égard. En comprenant ce qui est dit sur votre marque dans les articles de presse quotidiens et le sentiment qui les sous-tend, vous pouvez prendre des décisions éclairées. L’objectif final est de réagir, de protéger ou de promouvoir votre marque.
Le problème, c’est qu’il est difficile de récupérer des articles d’actualité. Google News, en particulier, est protégé par de multiples mesures anti-bots. En outre, chaque source d’information dispose de son propre site web avec des protections uniques, ce qui rend difficile la collecte programmatique de données d’actualité de manière cohérente.
C’est là que Bright Data intervient. Grâce à ses capacités de recherche et d’extraction sur le web, il vous offre de nombreux produits et intégrations pour accéder de manière programmatique à des données web publiques prêtes pour l’IA à partir de n’importe quel site web.
Plus précisément, avec le nouveau SDK de Bright Data, vous pouvez exploiter les solutions les plus utiles de Bright Data de manière simplifiée, en quelques lignes de code Python seulement !
Une fois que vous disposez des données d’actualité, vous pouvez compter sur l’IA pour sélectionner les articles les plus pertinents et les analyser pour en tirer des informations sur les sentiments et les marques. Vous pouvez ensuite utiliser un service comme Twilio SendGrid pour envoyer le rapport résultant à l’ensemble de votre équipe marketing. À un niveau élevé, c’est exactement ce que fait un flux de travail personnalisé d’IA sur la réputation de la marque.
Voyons maintenant de plus près comment le mettre en œuvre d’un point de vue technique !
Étapes techniques
Les étapes de la mise en œuvre du flux de travail AI de surveillance de la réputation de la marque sont les suivantes :
- Charger les variables d’environnement: Chargez les clés d’API de Bright Data, OpenAI et SendGrid dans les variables d’environnement. Ces clés sont nécessaires pour se connecter aux services tiers qui alimentent ce flux de travail.
- Charger le fichier de configuration: Lire un fichier de configuration JSON (par exemple,
config.json) contenant les requêtes de recherche initiales, le nombre d’articles d’actualité à inclure dans le rapport, ainsi que l’adresse électronique de l’expéditeur et les adresses électroniques des destinataires. - Récupérer les URL des pages Google News: Utilisez le SDK Bright Data pour récupérer les pages de résultats des moteurs de recherche (SERP) pour le terme de recherche configuré. À partir de chacune d’entre elles, accédez aux URL des pages Google Actualités.
- Récupérer les pages Google News: Utilisez le SDK Bright Data pour extraire les pages complètes de Google Actualités au format Markdown. Chacune de ces pages contient plusieurs URL d’articles d’actualité.
- Laissez l’IA identifier les meilleures nouvelles: Alimentez un modèle OpenAI avec les pages Google News récupérées et demandez-lui de sélectionner les articles d’actualité les plus pertinents pour la surveillance de la marque.
- Récupérer des articles d’actualité individuels: Utilisez le SDK Bright Data pour récupérer le contenu de chaque article d’actualité renvoyé par l’IA.
- Analyser les articles d’actualité pour évaluer la réputation de la marque: Transmettez chaque article à l’IA et demandez-lui de fournir un résumé, une analyse des sentiments et des informations clés sur la réputation de la marque.
- Générer un rapport HTML final: Transmettez les résultats de l’analyse des actualités à l’IA et demandez-lui de produire un rapport HTML bien structuré.
- Envoyez le rapport par courrier électronique: Utilisez le SDK SendGrid pour envoyer le rapport HTML généré par l’IA aux destinataires spécifiés, en fournissant une vue d’ensemble de la réputation de la marque.

Découvrez comment mettre en œuvre ce flux de travail d’IA en Python !
Création d’un flux de travail de réputation de marque alimenté par l’IA avec le SDK Bright Data
Dans cette section du tutoriel, vous apprendrez à créer un flux de travail d’IA pour surveiller la réputation de votre marque. Les données requises sur les actualités de la marque proviendront de Bright Data, par le biais du SDK Python de Bright Data. Les capacités d’IA seront fournies par OpenAI, et la livraison des courriels sera assurée par SendGrid.
À la fin de ce tutoriel, vous disposerez d’un flux de travail d’IA Python complet qui fournira des résultats directement dans votre boîte de réception. Le rapport de sortie identifiera les principales nouvelles dont votre marque devrait être consciente, vous donnant tout ce dont vous avez besoin pour répondre rapidement et maintenir une forte présence de la marque.
Construisons un flux de travail d’IA sur la réputation d’une marque !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir les éléments suivants :
- Python 3.8+ installé localement.
- Une clé API Bright Data.
- Une clé API OpenAI.
- Une clé d’API Twilio SendGrid.
Si vous n’avez pas encore de clé API Bright Data, inscrivez-vous à Bright Data et suivez le guide d’installation. De même, suivez les instructions officielles d’OpenAI pour obtenir votre clé d’API OpenAI.
Pour ce qui est de SendGrid, créez un compte, vérifiez-le, connectez une adresse électronique et vérifiez votre domaine. Créez une clé API et vérifiez que vous pouvez envoyer des courriels par programmation.
Etape #1 : Créer votre projet Python
Ouvrez un terminal et créez un nouveau répertoire pour votre flux de travail d’IA de surveillance de la réputation de votre marque :
mkdir brand-reputation-monitoring-workflowLe dossier brand-reputation-monitoring-workflow/ contiendra le code Python de votre flux de travail IA.
Ensuite, naviguez dans le répertoire du projet et mettez en place un environnement virtuel:
cd brand-reputation-monitoring-workflow
python -m venv .venvChargez ensuite le projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Dans le dossier du projet, ajoutez un nouveau fichier nommé workflow.py. Votre projet devrait maintenant contenir :
brand-reputation-monitoring-workflow/
├── .venv/
└── workflow.pyworkflow.py sera votre fichier Python principal.
Activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, exécutez :
.venv/Scripts/activateUne fois l’environnement activé, installez les dépendances nécessaires avec :
pip install python-dotenv brightdata-sdk openai sendgrid pydanticLes bibliothèques que vous venez d’installer sont :
python-dotenv: pour charger les variables d’environnement à partir d’un fichier.env, ce qui facilite la gestion sécurisée des clés d’API.brightdata-sdk: Pour vous aider à accéder aux outils et solutions de scraping de Bright Data en Python.openai: Pour interagir avec les modèles de langage d’OpenAI.sendgrid: Pour envoyer rapidement des courriels à l’aide de l’API Web Twilio SendGrid v3.pydantic: Pour définir des modèles pour les sorties de l’IA et votre configuration.
C’est fait ! Votre environnement de développement Python est prêt à construire un flux de travail d’IA de surveillance de la réputation de la marque avec OpenAI, Bright Data SDK et SendGrid.
Étape 2 : Configurer la lecture des variables d’environnement
Configurez votre script pour qu’il lise les secrets des variables d’environnement. Dans votre fichier workflow.py, importez python-dotenv et appelez load_dotenv() pour charger automatiquement les variables d’environnement :
from dotenv import load_dotenv
load_dotenv()Votre script peut désormais lire les variables d’un fichier .env local. Créez donc un fichier .env à la racine du répertoire de votre projet :
brand-reputation-monitoring-workflow/
├── .venv/
├── .env # <-----------
└─── workflow.pyOuvrez le fichier .env et ajoutez les envs OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN, et SENDGRID_API_KEY:
OPENAI_API_KEY="<VOTRE_CLÉ_OPENAI_API>"
BRIGHT_DATA_API_TOKEN="<VOTRE_BRIGHT_DATA_API_TOKEN>"
SENDGRID_API_KEY="<VOTRE_SENDGRID_API_TOKEN>"Remplacez les espaces réservés par vos identifiants réels :
<YOUR_OPENAI_API_KEY>→ Votre clé d’API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Votre clé d’API Bright Data.<YOUR_SENDGRID_API_KEY>→ Votre clé d’API SendGrid.
Génial ! Vous avez maintenant configuré en toute sécurité des secrets de tiers à l’aide de variables d’environnement.
Étape 3 : Initialiser les SDK
Commencez par ajouter les importations requises :
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClientEnsuite, initialisez les clients SDK :
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()Les trois lignes ci-dessus initialisent les éléments suivants :
- SDK Python Bright Data
- SDK Python OpenAI
- SDK Python SendGrid
Notez que vous n’avez pas besoin de charger manuellement les variables d’environnement de la clé API dans votre code et de les transmettre aux constructeurs. En effet, les SDK OpenAI, Bright Data et SendGrid recherchent automatiquement OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN et SENDGRID_API_KEY dans votre environnement, respectivement. En d’autres termes, une fois que ces envs sont définis dans .env, les SDKs gèrent le chargement pour vous.
En particulier, les SDK utiliseront les clés API configurées pour authentifier les appels API sous-jacents vers leurs serveurs à l’aide de votre compte.
Important: Pour plus de détails sur le fonctionnement du SDK Bright Data et sur la manière de le connecter aux zones requises dans votre compte Bright Data, consultez la page GitHub officielle ou la documentation.
Parfait ! Les éléments constitutifs de l’élaboration de votre flux de travail d’IA de surveillance de la réputation de votre marque sont maintenant prêts.
Étape 4 : Récupérer les URL de Google News
La première étape de la logique du flux de travail consiste à récupérer les SERP pour les requêtes de recherche liées à la marque que vous souhaitez surveiller. Pour ce faire, utilisez la méthode search() du SDK Bright Data, qui appelle l’API SERP en coulisses.
Analysez ensuite la réponse textuelle JSON obtenue à partir de search() pour accéder aux URL des pages Google News, qui ressembleront à ceci :
https://www.google.com/search ?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQegQIPhABRéalisez tout cela avec cette fonction :
def get_google_news_page_urls(search_queries) :
# Récupère les SERPs pour les requêtes de recherche données
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Pour obtenir le résultat de la SERP sous forme de chaîne JSON analysée
)
news_page_urls = []
for serp_result in serp_results :
# Chargement de la chaîne JSON dans un dictionnaire
serp_data = json.loads(serp_result)
# Extraire l'URL de Google News de chaque SERP analysé
if serp_data.get("navigation") :
for item in serp_data["navigation"] :
si item["title"] == "News" :
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urlsLorsque vous passez un tableau de requêtes à search() (comme dans ce cas), la méthode renvoie un tableau de SERPs, un pour chaque requête, respectivement. Comme parse vaut True, chaque résultat est renvoyé sous la forme d’une chaîne JSON, que vous devez ensuite analyser à l’aide du module json intégré à Python.
N’oubliez pas d’importer json à partir de la bibliothèque standard de Python :
import jsonGénial ! Vous pouvez désormais récupérer par programme une liste d’URL de pages Google News en rapport avec votre marque.
Étape 5 : Récupérer les pages Google News et les meilleures URL d’actualités
Gardez à l’esprit qu’une seule page Google News contient plusieurs articles d’actualité :
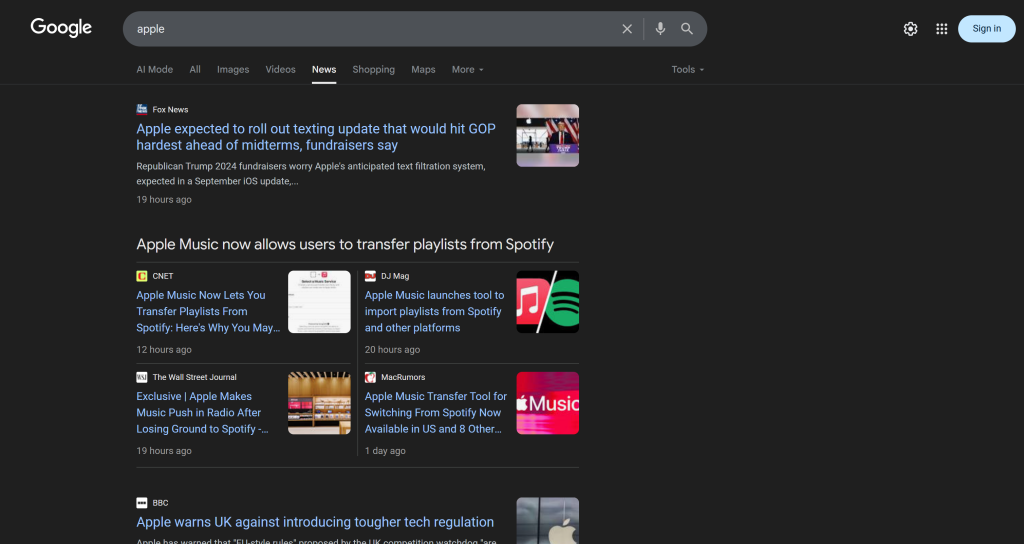
L’idée est donc la suivante :
- Scraper le contenu des pages Google News et obtenir les résultats au format Markdown.
- Transmettre le contenu Markdown à une IA (un modèle OpenAI, dans ce cas), en lui demandant de sélectionner les 5 meilleurs articles d’actualité pour le suivi de la réputation de la marque.
Réalisez la première micro-étape avec cette fonction :
def scrape_news_pages(news_page_urls) :
# Scrape chaque page d'actualités en parallèle et renvoie son contenu en Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
) Sous le capot, la méthode scrape() du SDK Bright Data fait appel à l’API Web Unlocker. Lorsque vous transmettez un tableau d’URL, scrape() exécute la tâche d’extraction en parallèle, en récupérant toutes les pages simultanément. Dans ce cas, l’API est configurée pour renvoyer des données en Markdown, ce qui est idéal pour l’ingestion LLM (comme le prouve notre benchmark de format de données sur Kaggle).
Ensuite, complétez la deuxième micro-étape avec :
def get_best_news_urls(news_pages, num_news) :
# Utiliser GPT pour extraire les URL de nouvelles les plus pertinentes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role" : "system",
"content" : f "Extraire du texte les {num_news} nouvelles les plus pertinentes pour la surveillance de la réputation de la marque et les renvoyer sous la forme d'une liste de chaînes d'URL."
},
{
"role" : "utilisateur",
"content" : "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urlsCette fonction concatène simplement les sorties de texte Markdown de la fonction précédente et les transmet au modèle GPT-5-mini OpenAI, en lui demandant d’extraire les URL les plus pertinentes.
La sortie est censée suivre le modèle URLList, qui est un modèle pydantique défini comme suit :
classe URLList(BaseModel) :
urls : List[str]Grâce à l’optiontext_format de la méthode parse(), vous demandez à l’API OpenAI de renvoyer le résultat sous la forme d’une instance d’URLList. En fait, vous obtenez une liste de chaînes de caractères, où chaque chaîne représente une URL.
Importez les classes nécessaires de pydantic:
from pydantic import BaseModel
from typing import ListGénial ! Vous disposez maintenant d’une liste structurée d’URL d’actualités, prête à être scrappée et analysée pour la réputation de la marque.
Étape n° 6 : Récupérer les pages d’actualités et les analyser pour surveiller la réputation de la marque
Maintenant que vous avez une liste des meilleures URLs de news, utilisez à nouveau scrape() pour récupérer leur contenu en Markdown :
def scrape_news_articles(news_urls) :
# Récupère chaque URL d'information et renvoie une liste de dicts avec l'URL et le contenu
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list) :
news_list.append({
"url" : url,
"content" : contenu
})
return news_listPeu importe le domaine sur lequel ces articles sont hébergés ou les mesures anti-scraping mises en place, l’API Web Unlocker s’en chargera et renverra le contenu de chaque article en Markdown. En détail, les articles d’actualité seront scrappés en parallèle. Pour savoir quelle URL correspond à quelle sortie Markdown, utilisez zip().
Ensuite, envoyez chaque contenu Markdown à OpenAI pour qu’il analyse la réputation de la marque. Pour chaque article, extraire
- le titre
- L’URL
- Un court résumé
- Une étiquette de sentiment rapide (par exemple, “positif”, “négatif” ou “neutre”)
- 3 à 5 informations exploitables, courtes et faciles à comprendre
Pour y parvenir, utilisez la fonction suivante :
def process_news_list(news_list) :
# Où stocker les articles de presse analysés
news_analysis_list = []
# Analyser chaque article de presse avec GPT pour obtenir des informations sur la surveillance de la réputation de la marque
pour news dans news_list :
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role" : "system",
"content" : f"""
Étant donné le contenu de la nouvelle :
1. Extraire le titre.
2. Extraire l'URL.
3. Rédigez un résumé en 30 mots maximum.
4. Extrayez le sentiment de la nouvelle en choisissant l'une des réponses suivantes : "positif", "négatif" ou "neutre".
5. Extraire de l'actualité 3 à 5 idées courtes (pas plus de 10/12 mots) sur la réputation de la marque et les présenter dans un langage clair, concis et direct.
"""
},
{
"role" : "user",
"content" : f "NEWS URL : {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Obtenir l'objet news analysé en sortie et l'ajouter à la liste
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_listCette fois, le modèle pydantique défini dans text_format est :
class NewsAnalysis(BaseModel) :
title : str
url : str
résumé : str
sentiment_analysis : str
insights : List[str]Ainsi, le résultat de la fonction process_news_list() sera une liste d’objets NewsAnalysis.
C’est génial ! Le traitement des actualités par l’IA pour la surveillance de la réputation des marques est terminé.
Étape 7 : Générer le rapport par courriel et l’envoyer
Vous êtes-vous déjà demandé comment les e-mails sont structurés et apparaissent joliment dans la boîte de réception de votre client ? C’est parce que la plupart des corps d’emails ne sont en fait que des pages HTML structurées. Après tout, le protocole de courrier électronique permet d’envoyer des documents HTML.
À partir de la liste d’objets d’analyse de l’actualité générée précédemment, convertissez-la en JSON, transmettez-la à AI et demandez-lui de produire un document HTML prêt à être envoyé par courrier électronique :
def create_html_email_body(news_analysis_list) :
# Génère un corps de message HTML structuré à partir des nouvelles analysées
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
À partir du contenu ci-dessous, générez un corps d'e-mail HTML structuré, bien formaté, réactif et prêt à être envoyé.
Veillez à utiliser correctement les titres, les paragraphes, les étiquettes de couleur et les liens, le cas échéant.
N'incluez pas de section d'en-tête ou de pied de page, et n'incluez que ces informations, rien d'autre.
CONTENU :
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]} }.
"""
)
return response.output_textEnfin, utilisez le SDK Twilio SendGrid pour envoyer l’e-mail par programmation :
def send_email(sender, recipients, html_body) :
# Envoi de l'e-mail HTML à l'aide de SendGrid
message = Mail(
from_email=sender,
to_emails=récipients,
sujet="Rapport hebdomadaire sur la surveillance de la marque",
html_content=html_body
)
sendgrid_client.send(message)Cela nécessite l’importation suivante :
from sendgrid.helpers.mail import MailNous y voilà ! Toutes les fonctions permettant de mettre en œuvre ce flux de travail AI de surveillance de la réputation de la marque ont maintenant été implémentées.
Étape n° 8 : Chargement des préférences et des configurations
Certaines des fonctions définies dans les étapes précédentes acceptent des arguments spécifiques (par exemple, search_queries, num_news, sender, recipients). Ces valeurs peuvent changer d’une exécution à l’autre, vous ne devez donc pas les coder en dur dans votre script Python.
Au lieu de cela, lisez-les à partir d’un fichier config.json contenant les champs suivants :
search_queries: La liste des requêtes de réputation de marque pour lesquelles des nouvelles doivent être récupérées.num_news: Le nombre d’articles d’actualité à inclure dans le rapport final.sender: Une adresse électronique approuvée par SendGrid à partir de laquelle le rapport sera envoyé.destinataires: La liste des adresses électroniques auxquelles envoyer le rapport HTML.
Modélisez l’objet de configuration à l’aide de la classe Pydantic suivante :
class Config(BaseModel) :
search_queries : List[str] = Field(..., min_items=1)
num_news : int = Field(..., gt=0)
sender : str = Field(..., min_length=1)
recipients : List[str] = Field(..., min_items=1)Les définitions des champs précisent les règles de validation qui garantissent que les configurations respectent le format attendu. Importez-les avec :
from pydantic import FieldEnsuite, lisez les configurations du flux de travail à partir d’un fichier local config.json et analysez-le dans un objet Config:
avec open("config.json", "r", encoding="utf-8") as f :
raw_config = json.load(f)
config = Config.model_validate(raw_config) Ajoutez un fichier config.json au répertoire de votre projet :
brand-reputation-monitoring-workflow/
├── .venv/
├── .env
├── config.json # <-----------
└─── workflow.pyEt le remplir avec quelque chose comme ceci :
{
"search_queries" : ["apple", "iphone", "ipad"],
"sender" : "[email protected]",
"recipients" : ["[email protected]", "[email protected]", "[email protected]"],
"num_news" : 5
}Adaptez les valeurs à vos objectifs spécifiques. N’oubliez pas non plus que le champ de l’expéditeur doit être une adresse électronique vérifiée dans votre compte SendGrid. Sinon, la fonction send_email() échouera avec une erreur 403 Forbidden.
C’est parti ! Une étape de plus et le flux de travail est terminé.
Étape 9 : Définir la fonction principale
Il est temps de tout composer. Appelez chaque fonction prédéfinie dans le bon ordre, en donnant les bonnes entrées de la configuration :
search_queries = config.search_queries
print(f "Récupération des URL des pages Google News pour les requêtes de recherche suivantes : {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(s) de page(s) d'actualités Google récupérée(s)!n")
print("Récupération du contenu de chaque page Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Pages d'actualités Google scrappées!N")
print("Extraction des URLs d'actualités les plus pertinentes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} articles d'actualité trouvés:N" + "N".join(f"- {news}" for news in news_urls) + "N")
print("Scrapeing the selected news articles...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} articles d'actualité récupérés !")
print("Analyse de chaque nouvelle pour la surveillance de la réputation de la marque...")
news_analysis_list = process_news_list(news_list)
print("Analyse de l'actualité terminée!n")
print("Génération du corps de l'e-mail en HTML...")
html = create_html_email_body(news_analysis_list)
print("Le corps de l'e-mail HTML est généré!n")
print("Envoi de l'e-mail contenant le rapport HTML sur la surveillance de la réputation de la marque...")
send_email(config.sender, config.recipients, html)
print("Courriel envoyé !")Note: Le processus peut prendre un certain temps, il est donc utile d’ajouter des journaux pour suivre la progression dans le terminal. Mission terminée !
Étape n° 10 : Assembler le tout
Le code final du fichier workflow.py est le suivant :
from dotenv import load_dotenv
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Field
de typing import List
import json
from sendgrid.helpers.mail import Mail
# Chargement des variables d'environnement à partir du fichier .env
load_dotenv()
# Initialisation du client SDK Bright Data
brightdata_client = bdclient()
# Initialiser le client OpenAI SDK
openai_client = OpenAI()
# Initialiser le client SendGrid SDK
sendgrid_client = SendGridAPIClient()
# Modèles pydantiques
classe Config(BaseModel) :
search_queries : List[str] = Field(..., min_items=1)
num_news : int = Field(..., gt=0)
sender : str = Field(..., min_length=1)
recipients : List[str] = Field(..., min_items=1)
classe URLList(BaseModel) :
urls : List[str]
class NewsAnalysis(BaseModel) :
title : str
url : str
résumé : str
sentiment_analysis : str
insights : Liste[str]
def get_google_news_page_urls(search_queries) :
# Récupère les SERP pour les requêtes de recherche données
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Pour obtenir le résultat de la SERP sous forme de chaîne JSON analysée
)
news_page_urls = []
for serp_result in serp_results :
# Chargement de la chaîne JSON dans un dictionnaire
serp_data = json.loads(serp_result)
# Extraire l'URL de Google News de chaque SERP analysé
if serp_data.get("navigation") :
for item in serp_data["navigation"] :
si item["title"] == "News" :
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urls
def scrape_news_pages(news_page_urls) :
# Scrape chaque page d'actualités en parallèle et renvoie son contenu en Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
)
def get_best_news_urls(news_pages, num_news) :
# Utilise GPT pour extraire les URL de news les plus pertinentes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role" : "system",
"content" : f "Extraire du texte les {num_news} nouvelles les plus pertinentes pour la surveillance de la réputation de la marque et les renvoyer sous la forme d'une liste de chaînes d'URL."
},
{
"role" : "utilisateur",
"content" : "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urls
def scrape_news_articles(news_urls) :
# Scrape chaque URL de news et renvoie une liste de dicts avec l'URL et le contenu
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list) :
news_list.append({
"url" : url,
"content" : contenu
})
return news_list
def process_news_list(news_list) :
# Où stocker les articles analysés
news_analysis_list = []
# Analyser chaque article de presse avec GPT pour obtenir des informations sur la surveillance de la réputation de la marque
pour news dans news_list :
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role" : "system",
"content" : f"""
Étant donné le contenu de la nouvelle :
1. Extraire le titre.
2. Extraire l'URL.
3. Rédigez un résumé en 30 mots maximum.
4. Extrayez le sentiment de la nouvelle en choisissant l'une des réponses suivantes : "positif", "négatif" ou "neutre".
5. Extraire de l'actualité 3 à 5 idées courtes (pas plus de 10/12 mots) sur la réputation de la marque et les présenter dans un langage clair, concis et direct.
"""
},
{
"role" : "user",
"content" : f "NEWS URL : {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Obtenir l'objet news analysé en sortie et l'ajouter à la liste
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list
def create_html_email_body(news_analysis_list) :
# Génère un corps d'e-mail HTML structuré à partir des nouvelles analysées
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
À partir du contenu ci-dessous, générez un corps d'e-mail HTML structuré, bien formaté, réactif et prêt à être envoyé.
Veillez à utiliser correctement les titres, les paragraphes, les étiquettes de couleur et les liens, le cas échéant.
N'incluez pas de section d'en-tête ou de pied de page, et n'incluez que ces informations, rien d'autre.
CONTENU :
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]} }.
"""
)
return response.output_text
def send_email(sender, recipients, html_body) :
# Envoi d'un e-mail HTML à l'aide de SendGrid
message = Mail(
from_email=sender,
to_emails=récipients,
sujet="Rapport hebdomadaire sur la surveillance de la marque",
html_content=html_body
)
sendgrid_client.send(message)
def main() :
# Lire le fichier de configuration et le valider
avec open("config.json", "r", encoding="utf-8") as f :
raw_config = json.load(f)
config = Config.model_validate(raw_config)
search_queries = config.search_queries
print(f "Récupération des URL des pages Google News pour les requêtes de recherche suivantes : {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(s) de page(s) d'actualités Google récupérée(s)!n")
print("Récupération du contenu de chaque page Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Pages d'actualités Google scrappées!N")
print("Extraction des URLs d'actualités les plus pertinentes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} articles d'actualité trouvés:N" + "N".join(f"- {news}" for news in news_urls) + "N")
print("Scrapeing the selected news articles...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} articles d'actualité récupérés !")
print("Analyse de chaque nouvelle pour la surveillance de la réputation de la marque...")
news_analysis_list = process_news_list(news_list)
print("Analyse de l'actualité terminée!n")
print("Génération du corps de l'e-mail en HTML...")
html = create_html_email_body(news_analysis_list)
print("Le corps de l'e-mail HTML est généré!n")
print("Envoi de l'e-mail contenant le rapport HTML sur la surveillance de la réputation de la marque...")
send_email(config.sender, config.recipients, html)
print("Email envoyé !")
# Exécuter la fonction principale
if __name__ == "__main__" :
main()Et voilà ! Grâce au SDK Bright Data, à l’API OpenAI et au SDK Twilio SendGrid, vous avez pu créer un flux de travail de surveillance de la réputation de la marque alimenté par l’IA en moins de 200 lignes de code.
Étape n° 11 : tester le flux de travail
Supposez que vos search_queries sont "nike" et "nike shoes". num_news est fixé à 5, et le rapport est configuré pour être envoyé à votre email personnel (notez que vous pouvez utiliser la même adresse email à la fois pour l’expéditeur et pour le premier élément des destinataires).
Dans votre environnement virtuel activé, lancez votre flux de travail avec :
python workflow.pyLe résultat dans le terminal ressemblera à quelque chose comme :
Récupération des URL des pages Google News pour les requêtes de recherche suivantes : nike, chaussures nike
2 URL de page(s) Google News récupérée(s) !
Récupération du contenu de chaque page Google News...
Pages de Google Actualités récupérées !
Extraction des URL d'actualités les plus pertinentes...
5 articles d'actualité trouvés :
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
Récupération des articles de presse sélectionnés...
5 articles d'actualité récupérés !
Analyse de chaque article de presse pour le suivi de la réputation de la marque...
Analyse de l'actualité terminée !
Génération du corps de l'e-mail en HTML...
Le corps de l'e-mail HTML est généré !
Envoi de l'e-mail contenant le rapport HTML de surveillance de la réputation de la marque...
Courriel envoyé !Remarque: les résultats changeront en fonction des nouvelles disponibles. Ils ne seront donc jamais les mêmes que ceux présentés ci-dessus au moment où vous lirez ce tutoriel.
Après le message “Email envoyé !”, vous devriez voir un email “Brand Monitoring Weekly Report” dans votre boîte de réception :

Ouvrez-le, et il contiendra quelque chose comme :
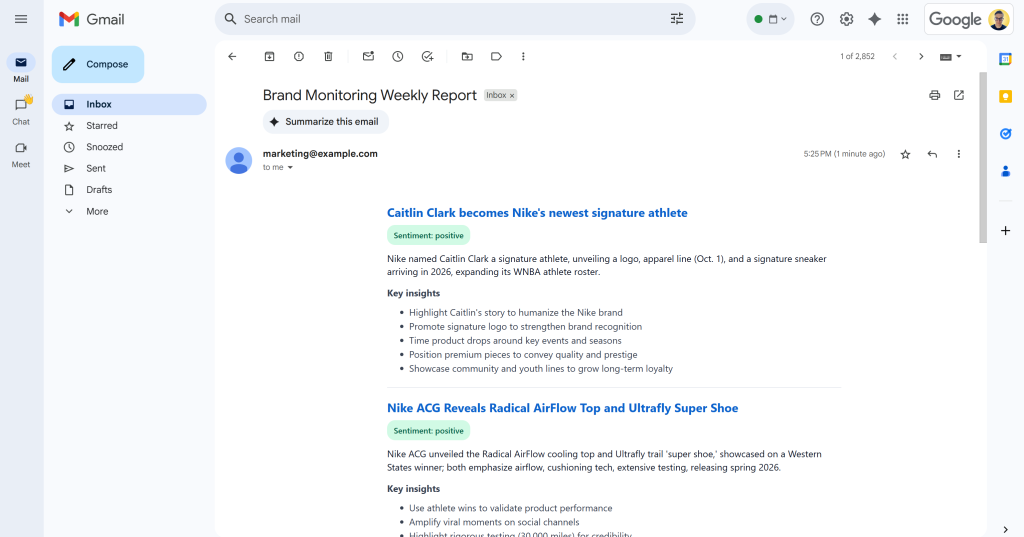
Comme vous pouvez le constater, l’IA a été en mesure de produire un rapport de suivi de la marque visuellement attrayant avec toutes les données demandées.
Faites défiler le rapport et vous verrez :
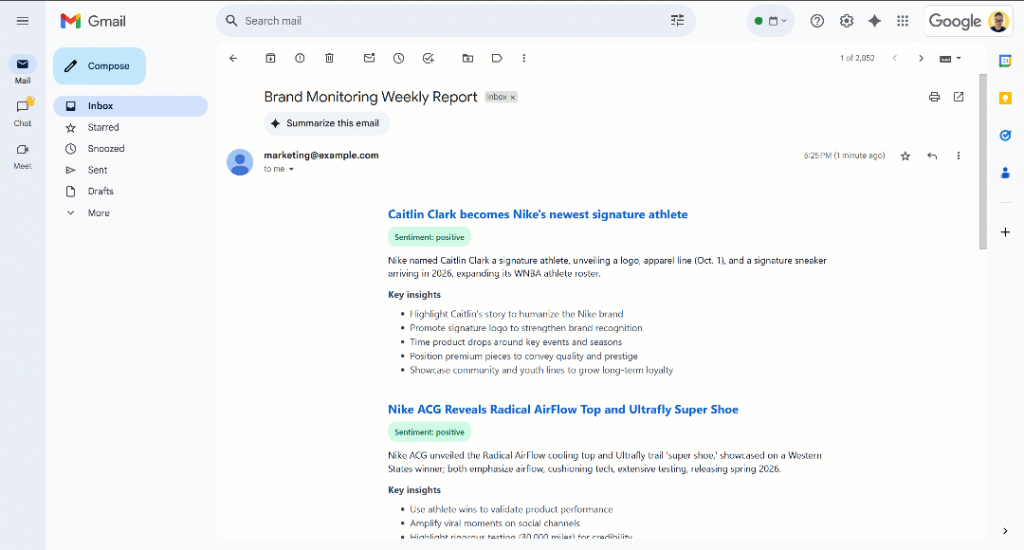
Remarquez que les étiquettes de sentiment sont codées par couleur pour vous aider à comprendre rapidement le sentiment. De même, les titres des actualités sont en bleu, car il s’agit de liens vers les articles originaux.
Et voilà ! Vous avez commencé par quelques requêtes de recherche et vous avez obtenu un courriel contenant un rapport de suivi de la marque bien structuré.
Tout cela a été possible grâce à la puissance des solutions de scraping de données web disponibles dans le SDK Bright Data. N’oubliez pas que les pages scannées sont renvoyées dans des formats Markdown optimisés par LLM afin que n’importe quel modèle d’IA puisse les analyser pour vos besoins. Explorez d’autres cas d’utilisation de flux de travail agentiques et d’IA pris en charge !
Prochaines étapes
Le flux de travail actuel de l’IA pour la surveillance de la réputation des marques est déjà assez sophistiqué, mais vous pourriez l’améliorer encore davantage grâce à ces idées :
- Ajouter une couche de mémoire pour les actualités déjà couvertes: Pour éviter d’analyser plusieurs fois les mêmes articles, améliorer la précision des rapports tout en réduisant les doublons.
- Introduire le modèle SendGrid pour la standardisation: L’IA peut produire des rapports HTML légèrement différents avec des structures variées à chaque exécution. Pour rendre la mise en page cohérente, définissez un modèle SendGrid, remplissez-le avec les données d’analyse de l’actualité générées et envoyez-le via le SDK SendGrid. Pour en savoir plus , consultez la documentation officielle.
- Stockez le rapport HTML généré dans le nuage: Sauvegardez le rapport sur S3 pour vous assurer qu’il est archivé et disponible pour une analyse historique de la surveillance de la marque.
Conclusion
Dans cet article, vous avez appris à tirer parti des capacités de recherche et d’exploration du Web de Bright Data pour créer un flux de travail sur la réputation de la marque alimenté par l’IA. Ce processus a été rendu encore plus facile grâce au nouveau SDK de Bright Data, qui permet d’accéder aux produits de Bright Data par de simples appels de méthode.
Le flux de travail d’IA présenté ici est idéal pour les équipes marketing qui souhaitent surveiller leur marque et recevoir des informations exploitables à faible coût. Il permet d’économiser du temps et des efforts en fournissant des instructions contextuelles pour soutenir la protection de la marque et la prise de décision.
Pour créer des flux de travail plus avancés, explorez la gamme complète de solutions de l’infrastructure d’IA de Bright Data pour la récupération, la validation et la transformation des données Web en direct.
Créez un compte Bright Data gratuit et commencez à expérimenter nos solutions de données Web prêtes pour l’IA !






