

Dans cet article de blog, vous découvrirez :
- Ce qu’est Convex, comment fonctionne son modèle mental et comment il se compare à d’autres bases de données.
- Comment il fonctionne en détail et les composants essentiels sur lesquels il s’appuie.
- Pourquoi Convex excelle lorsqu’il est utilisé pour stocker des données Web en temps réel.
- Les principaux obstacles et défis liés à l’extraction de données en direct sur le Web.
- Comment Bright Data aide à relever ces défis en fournissant des données Web structurées et en temps réel, prêtes à être stockées dans Convex.
- Comment se lancer avec une démonstration complète combinant Bright Data pour la récupération de données Web et Convex pour le stockage des données et les mises à jour transparentes de l’interface utilisateur.
C’est parti !
Présentation de Convex
La première étape consiste à découvrir Convex pour comprendre ce que c’est, ce qu’il apporte et le modèle conceptuel qui le sous-tend.
Qu’est-ce que Convex ?
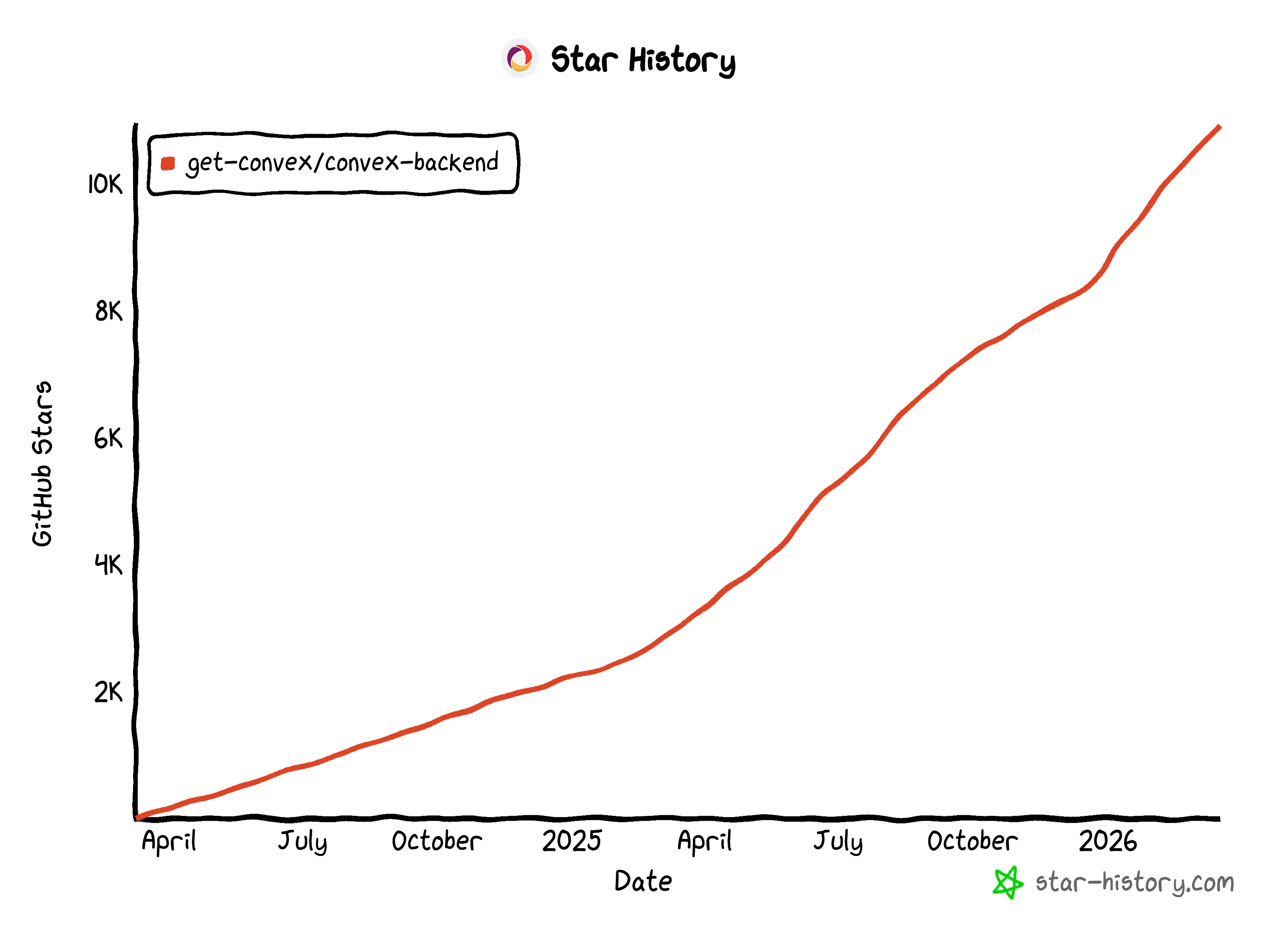
Convex est une plateforme backend réactive open source conçue pour synchroniser vos applications web et mobiles.
En coulisses, elle combine une base de données, des fonctions sans serveur, l’authentification et des bibliothèques clientes au sein d’un seul système. À l’instar des composants React qui réagissent aux changements d’état, les requêtes Convex réagissent automatiquement aux mises à jour de la base de données, ce qui en fait la solution idéale pour les applications dynamiques en temps réel.
Les requêtes sont écrites en TypeScript et exécutées directement dans la base de données, ce qui simplifie le développement tout en permettant des applications rapides et réactives avec une charge d’infrastructure minimale. La solution prend également en charge les composants modulaires, la synchronisation des données en temps réel, la planification et la génération de code assistée par l’IA. Elle s’intègre à des frameworks tels que React, Next.js, Vue, Svelte et Nuxt, tout en étant interopérable avec les applications Python, Swift (pour iOS), Kotlin (pour Android) et Rust.
Sa flexibilité l’a rendu populaire auprès des développeurs, lui valant plus de 10 900 étoiles sur GitHub et plus de 400 000 téléchargements hebdomadaires sur npm.
L’idée centrale derrière Convex : comprendre son modèle mental
Contrairement aux bases de données traditionnelles, Convex traite la base de données comme un système vivant et réactif plutôt que comme un simple stockage passif de données. Chaque fois que des données sont ajoutées, mises à jour ou supprimées, la modification est enregistrée dans un journal des transactions immuable. Il s’agit d’un historique permanent et horodaté de toutes les opérations. Parallèlement, les requêtes ne se contentent pas de récupérer des données. Elles suivent automatiquement les données qu’elles ont lues, ce que l’on appelle leurs « ensembles de lecture ».
Cela permet à Convex de détecter immédiatement toute modification des données sur lesquelles une requête s’appuie, ce qui permet au système de mettre à jour les résultats en temps réel. Cette architecture prend en charge les abonnements en temps réel et maintient une forte cohérence grâce à des transactions déterministes et à un mécanisme de contrôle de concurrence optimiste. Grâce à ces caractéristiques, plusieurs utilisateurs peuvent interagir simultanément avec la base de données sans conflit.
Convex par rapport aux autres bases de données
Pour mieux comprendre comment Convex se positionne par rapport aux autres bases de données populaires, consultez le tableau comparatif ci-dessous :
| Fonctionnalité | Convex | Firebase | Supabase | Bases de données SQL traditionnelles |
|---|---|---|---|---|
| Type de base de données | Stockage de documents transactionnel | NoSQL / Firestore | PostgreSQL | SQL relationnel |
| En temps réel | ✔️ (Intégré, abonnements automatiques) | ✔️ (Intégré) | ➖ (En option, via un serveur distinct) | ❌ (Non natif) |
| Transactions | Toujours transactionnel | Limité | Prise en charge | Prise en charge |
| Schéma | Facultatif, progressif, généré automatiquement à partir de TypeScript | Flexible / sans schéma | Appliqué (Postgres) | Strict, manuel |
| Prise en charge SQL | ❌ | ❌ | ✔️ | ✔️ |
| Intégration de TypeScript | Complète | Limité | Partielle, côté serveur | Dépend de l’ORM |
| Auth/OAuth | Standard + natif | Standard + Auth Firebase | Standard + natif | Configuration personnalisée |
| Responsabilité de la base de données | Entièrement gérée par Convex | Partagée | Partagée | Entièrement gérée par le développeur |
Fonctionnement de Convex : architecture, composants et flux de données
L’architecture de Convex repose sur une plateforme backend full-stack composée de trois éléments principaux :
- Base de données: un magasin réactif de type document-relationnel où les objets de type JSON sont organisés en tables. La base de données Convex est automatiquement provisionnée dans le cloud pour chaque projet, ne nécessitant aucune configuration manuelle de connexion ni gestion de cluster.
- Fonctions serveur: les requêtes et les mutations sont écrites sous forme de fonctions TypeScript, éliminant ainsi le besoin de SQL ou d’ORM. Les requêtes sont pures et en lecture seule, tandis que les mutations s’exécutent dans des transactions entièrement gérées avec des garanties ACID, un isolement sérialisable et un contrôle de concurrence optimiste.
- Bibliothèques client: bibliothèques spécifiques à chaque framework (Next.js, React, Vue, Svelte, etc.) qui s’abonnent aux fonctions serveur, synchronisant automatiquement les résultats et gérant les files d’attente de mutations. Elles garantissent des mises à jour cohérentes et en temps réel de l’interface utilisateur sans abonnement manuel ni gestion de l’état.
Grâce à ces trois composants, les données circulent de manière réactive de la base de données vers le client via des fonctions serveur. Les requêtes suivent automatiquement les dépendances, se réexécutent lorsque les données changent et poussent les mises à jour en temps réel. Les mutations s’exécutent sous forme de transactions entièrement gérées, mettant à jour la base de données et les requêtes dépendantes, garantissant ainsi que les clients voient toujours l’état à jour sans synchronisation manuelle.
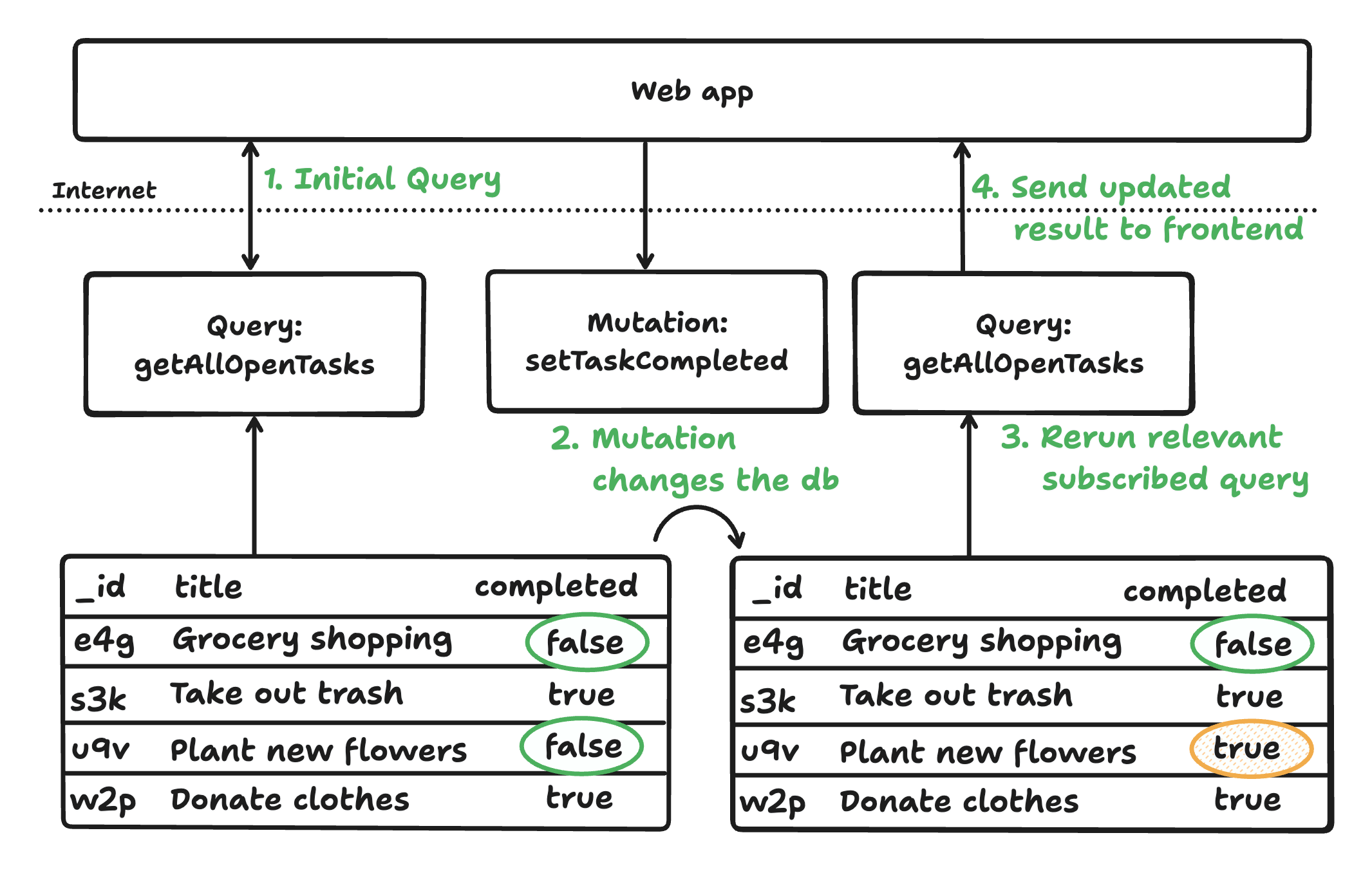
L’architecture cohérente de Convex garantit des applications réactives, cohérentes et sans risque de type, avec un minimum de code standard. Elle prend en charge le développement rapide tant pour le code généré par l’homme que par l’IA, en faisant abstraction du réglage et de la synchronisation de la base de données. Convex offre également des fonctionnalités d’authentification, de planification et bien plus encore.
Pourquoi Convex et les données Web en temps réel forment le duo parfait
Une base de données en temps réel comme Convex n’atteint son plein potentiel que lorsque la source de données elle-même est en temps réel. En d’autres termes, son architecture réactive est parfaite pour les applications qui doivent refléter des conditions en direct (par exemple, les cours de la bourse, les flux des réseaux sociaux, les actualités ou les stocks du commerce électronique).
Mais quelle est la plus grande source de données dynamiques et en constante évolution sur la planète ? Le Web ! Les données Web proviennent de millions de sources en temps réel, ce qui en fait l’entrée idéale pour une application réactive basée sur Convex.
En connectant Convex à des flux de données Web en temps réel, votre application peut réagir immédiatement aux mises à jour sans avoir recours à des interrogations complexes, à une synchronisation manuelle ou à la gestion d’état. Cela élimine la latence entre les informations et l’interface utilisateur, créant ainsi une expérience utilisateur fluide et toujours à jour.
Les défis liés à la connexion des données Web à une application Convex
Vous comprenez désormais pourquoi les données Web en temps réel sont parfaitement adaptées à une solution comme Convex. La question suivante est : comment les récupérer concrètement ? La réponse est le Scraping web, le processus consistant à extraire des informations de pages Web par programmation.
Le scraping web est une approche puissante, mais elle s’accompagne de plusieurs défis. Ceux-ci vont des obstacles techniques à la complexité opérationnelle, notamment :
- Contenu dynamique: les sites modernes s’appuient sur JavaScript, AJAX et des modèles de navigation et d’interaction complexes, ce qui rend l’extraction de données structurées plus difficile.
- Mesures anti-bot: de nombreux sites web utilisent des CAPTCHA, des limites de débit, des empreintes digitales et d’autres moyens de défense pour détecter et bloquer les accès automatisés.
- Changements fréquents: les mises en page, les structures HTML et les URL changent souvent, ce qui rend les Scrapers inopérants et nécessite une surveillance et une maintenance continues.
- Évolutivité: la collecte de données à grande échelle nécessite une infrastructure solide, une intégration avec un fournisseur de Proxy fiable pour la rotation des adresses IP et une gestion robuste des erreurs.
- Cohérence des données: garantir l’exactitude, l’exhaustivité et l’actualité des données est un défi, en particulier pour les données fréquemment mises à jour.
En conséquence, la création d’une application Convex entièrement réactive à partir de données Web est une tâche ardue. Plutôt que de surmonter ces obstacles vous-même, la meilleure approche consiste à faire appel à un fournisseur de données Web en temps réel adapté aux entreprises, tel que Bright Data.
Bright Data + Convex pour des applications réactives basées sur des données Web en temps réel
Lors du développement d’applications réactives alimentées par des données Web en temps réel, la combinaison de Bright Data et de Convex se démarque. Ensemble, ils établissent une séparation claire des responsabilités : Bright Data se concentre sur la collecte de données à grande échelle, tandis que Convex gère la synchronisation de l’état en temps réel et les mises à jour de l’interface utilisateur.
Bright Data vous permet de rechercher et d’extraire des informations du Web en temps réel par programmation. Les données collectées sont renvoyées sous forme de JSON structuré, qui peut être facilement intégré à Convex. Ce dernier se charge ensuite de les propager instantanément à tous les clients connectés via des requêtes réactives.
Ce qui rend Bright Data particulièrement attractif, c’est son infrastructure de niveau entreprise. Elle fonctionne sur l’un des plus grands réseaux de Proxies au monde, avec plus de 150 millions d’adresses IP réparties dans 195 pays, permettant une concurrence illimitée. Cette base garantit une fiabilité élevée, avec un temps de disponibilité de 99,99 %, un taux de réussite de 99,95 % et une assistance 24 h/24, 7 j/7.
Toutes les solutions de récupération de données en temps réel de Bright Data s’appuient sur cette infrastructure. Les principales offres comprennent :
- API Web Scraper: des points de terminaison API prêts à l’emploi pour extraire des données structurées en direct à partir de sites Web populaires.
- API Unlocker: gère automatiquement les CAPTCHA, les mécanismes de blocage et les systèmes anti-bot, vous donnant accès au contenu des pages débloquées.
- API SERP: fournit des résultats de recherche en temps réel provenant de plusieurs moteurs, avec des temps de réponse inférieurs à une seconde.
- API Crawl: convertit des sites web entiers en Jeux de données structurés.
La configuration Convex + Bright Data permet un flux continu de données fraîches provenant du Web vers vos utilisateurs, sans les coûts opérationnels habituels liés au Scraping web. Il en résulte un système évolutif, facile à maintenir et entièrement réactif, basé sur des données Web en temps réel.
Exemple d’architecture
Vous trouverez ci-dessous un exemple d’architecture pour une application web ou mobile réactive construite avec Convex, avec des données web en temps réel fournies par Bright Data :
- Déclenchement de la récupération des données (Bright Data): lorsqu’un utilisateur effectue une action spécifique (par exemple, cliquer sur un bouton), le frontend envoie une requête à votre backend. Le serveur appelle alors une API Bright Data pour récupérer des données fraîches sur le Web. Les données extraites peuvent être des prix de produits, des articles d’actualité, des offres d’emploi, etc.
- Traitement backend (Convex): Une fois les données JSON structurées reçues, elles sont transmises à Convex via une mutation. À ce stade, les données sont ingérées, normalisées, validées et stockées dans la base de données Convex. Vous pouvez également enrichir ou transformer les données ici en fonction de la logique de votre application.
- Mises à jour en direct de l’interface utilisateur (réactivité Convex): le front-end s’abonne aux requêtes dans Convex. Dès que la base de données est mise à jour, les requêtes concernées sont automatiquement réexécutées. Les résultats mis à jour sont instantanément transmis au client, et l’interface utilisateur s’actualise en temps réel sans aucune intervention manuelle.
Comment créer un terminal d’étude de marché IA en temps réel avec Convex et Bright Data
Pour illustrer les possibilités offertes par l’intégration Convex + Bright Data, prenons l’exemple d’une démonstration concrète : le terminal d’étude de marché IA de Bright Data.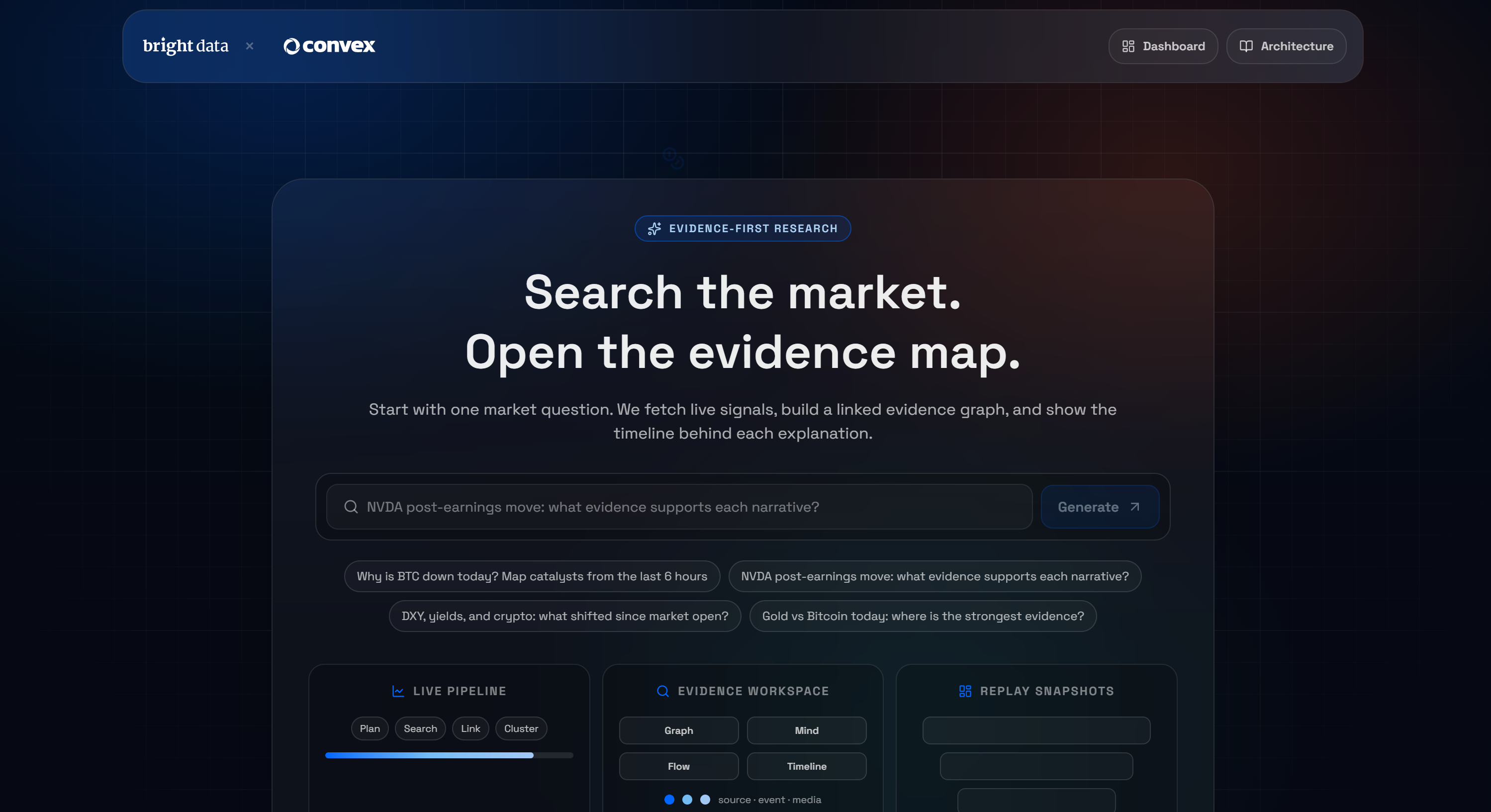
Il s’agit d’une application Next.js construite sur Convex qui vous permet de poser une question et de recevoir un graphe de preuves en direct, extrait du Scraping web. Si vous n’êtes pas familier avec ce concept, un graphe de preuves est une représentation structurée montrant les relations entre les données, les affirmations et les preuves à l’appui.
En coulisses, l’application suit un pipeline composé de huit étapes :
- Plan: un LLM crée 4 à 6 requêtes de recherche ciblées en fonction de votre sujet.
- Recherche: envoie simultanément 4 à 6 requêtes à l’API SERP de Bright Data.
- Extraction: extrait les URL les plus pertinentes au format Markdown à l’aide de l’API Web Unlocker de Bright Data.
- Extraction: combine les extraits SERP et le Markdown en éléments de preuve structurés.
- Résumés: le LLM extrait les points clés, les entités, les catalyseurs et le sentiment pour chaque élément.
- Artefacts: Crée des nœuds et des arêtes de graphe de connaissances avec des scores de confiance.
- Lien: Applique un enrichissement heuristique, comprenant des corrections de connectivité, le balisage de domaine et des événements de bande.
- Rendu → Prêt: Transmet les artefacts finaux au client tout en conservant la session dans Convex.
Il est temps d’explorer cette démo et de la tester localement ! Découvrez comment une application Convex + Bright Data réelle collecte, traite et fournit des données Web en temps réel dans un workflow réactif.
Prérequis
Pour suivre cette section du tutoriel, assurez-vous de disposer des éléments suivants :
- Node.js 20+ installé localement.
- Une clé API OpenRouter.
- Un compte Bright Data avec les zones SERP et Web Unlocker configurées.
- Un projet Convex configuré (la version gratuite suffit).
- Git installé localement.
Ne vous inquiétez pas pour la configuration de Bright Data et Convex pour l’instant. Vous serez guidé à travers ces deux étapes dans deux sous-chapitres dédiés.
Étape n° 1 : Préparez votre compte Bright Data
Comme mentionné dans l’introduction, l’application de démonstration s’appuie sur deux produits Bright Data :
- API SERP
- API Web Unlocker
Vous trouverez ci-dessous des instructions pour les configurer dans votre compte. Pour des instructions plus détaillées, vous pouvez également consulter la documentation officielle de Bright Data :
Si vous n’avez pas encore de compte, créez-en un. Sinon, connectez-vous. Une fois connecté, accédez à la page « Proxies & Scraping » dans le panneau de configuration. Dans la section « Mes zones », recherchez une ligne intitulée « API SERP » et une autre intitulée « API Web Unlocker » :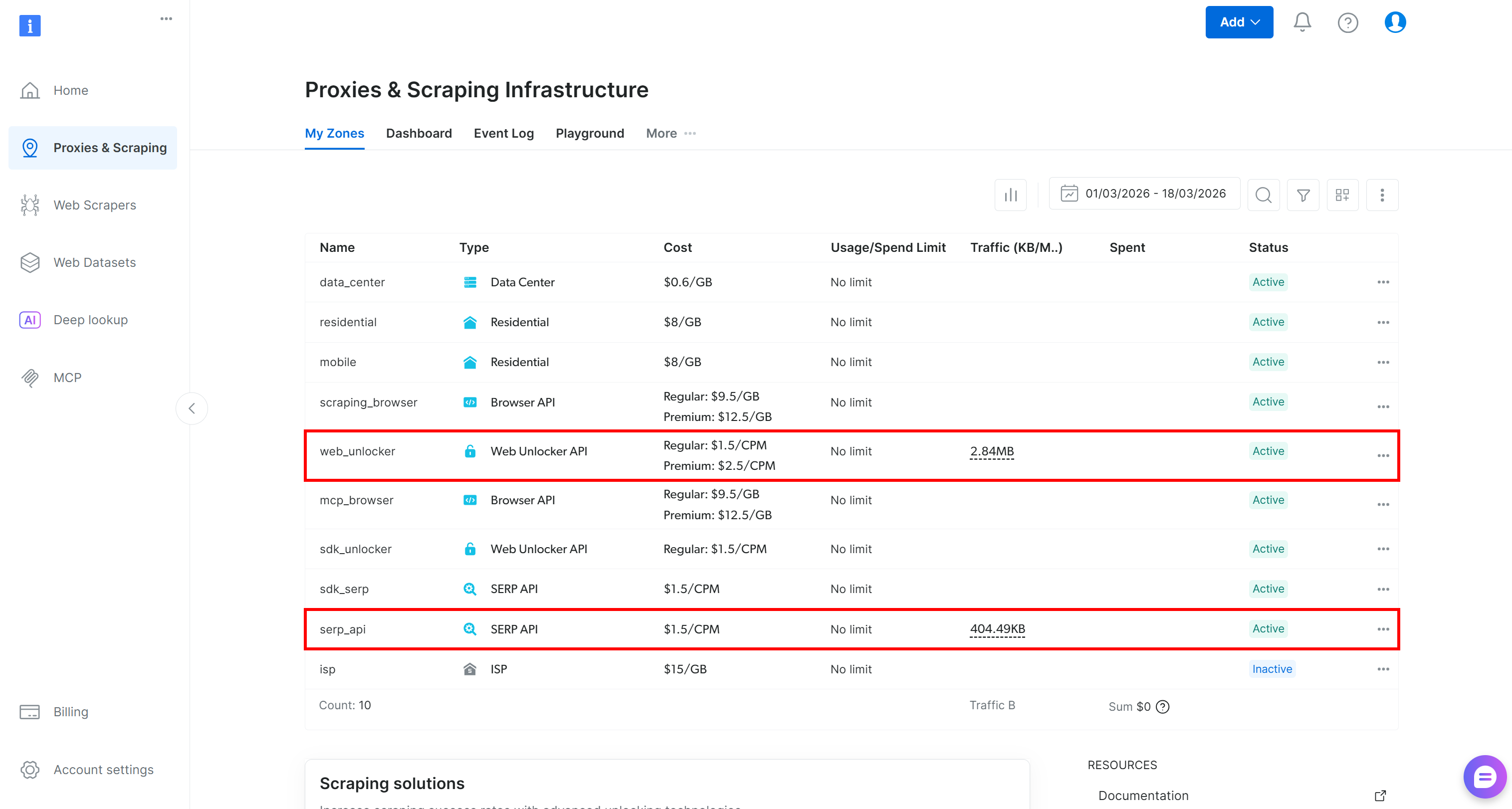
Si l’une de ces lignes est manquante, cela signifie que la zone correspondante n’a pas encore été configurée. Par exemple, pour créer une zone API SERP, faites défiler vers le bas jusqu’à la section « API SERP » et cliquez sur « Create Zone » :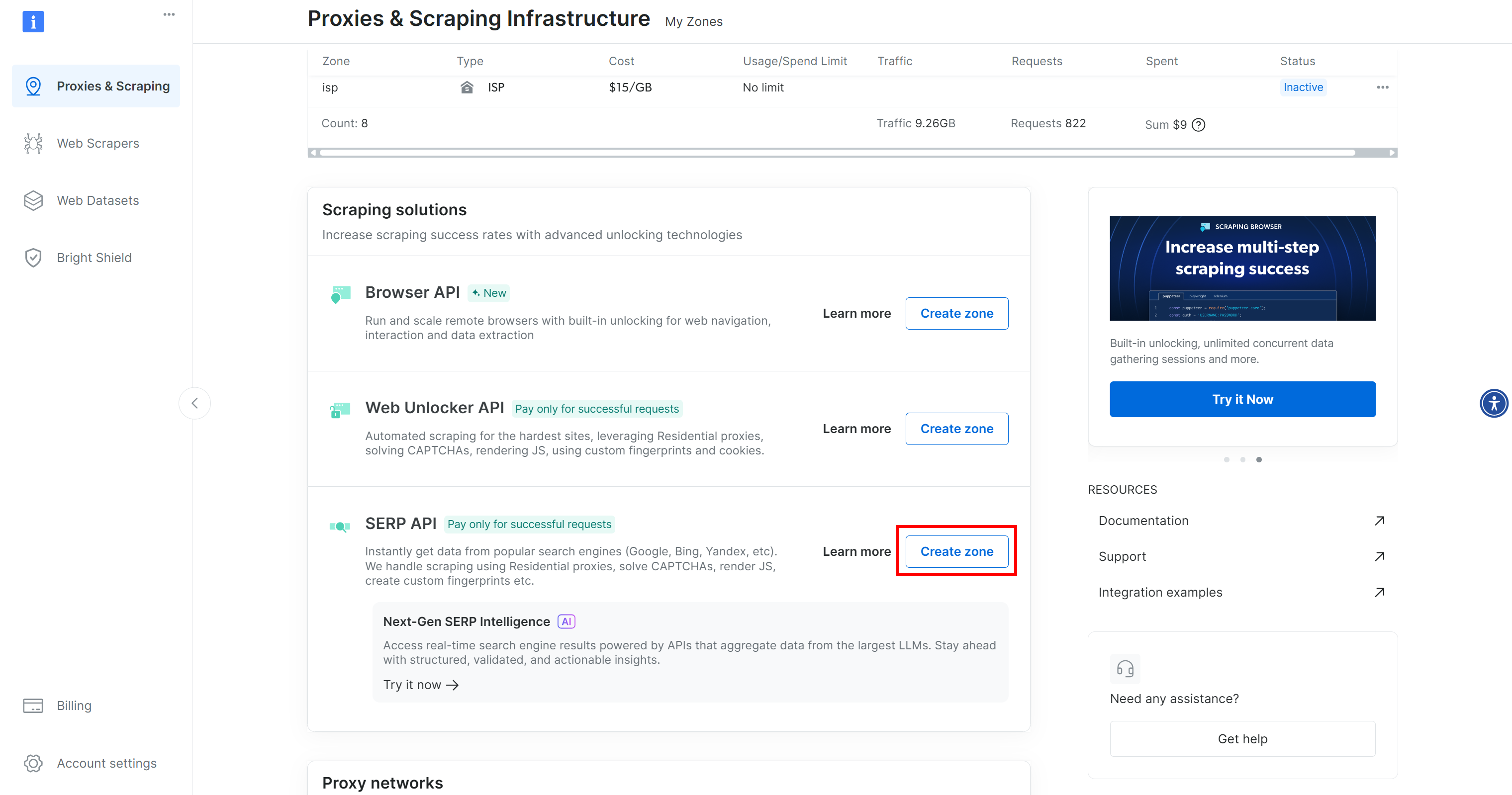
Créez une zone API SERP et donnez-lui un nom, tel que serp_api (ou tout autre nom de votre choix). Notez le nom de la zone, car vous en aurez besoin plus tard.
Répétez la même procédure pour l’API Web Unlocker. Pour ce tutoriel, nous supposerons que votre zone Web Unlocker s’appelle web_unlocker.
Enfin, suivez le tutoriel officiel pour générer votre clé API Bright Data. Conservez-la en lieu sûr, car elle sera nécessaire pour authentifier les requêtes API de l’application Next.js optimisée par Convex vers l’API SERP et Web Unlocker.
Génial ! Votre compte Bright Data est désormais entièrement configuré et prêt à être intégré à la démo du terminal d’étude de marché IA.
Étape n° 2 : Configurez votre compte Convex
Commencez par vous connecter à Convex, ou créez un nouveau compte si vous ne l’avez pas encore fait. Vous arriverez sur votre tableau de bord Convex :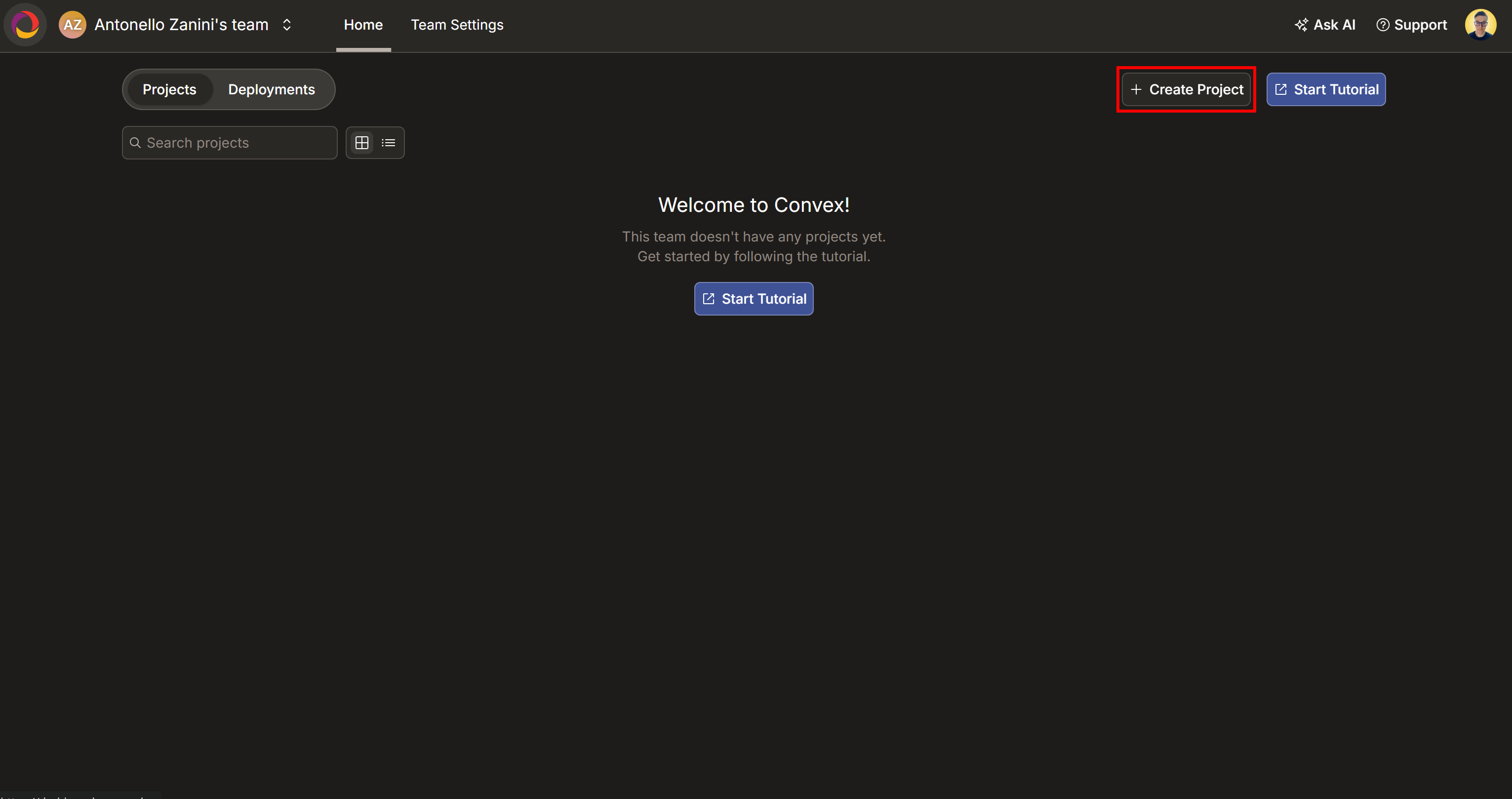
Cliquez ici sur le bouton « Create Project ». Nommez votre projet « IA Etude de marché Terminal » (ou tout autre nom de votre choix), puis cliquez sur « Create » :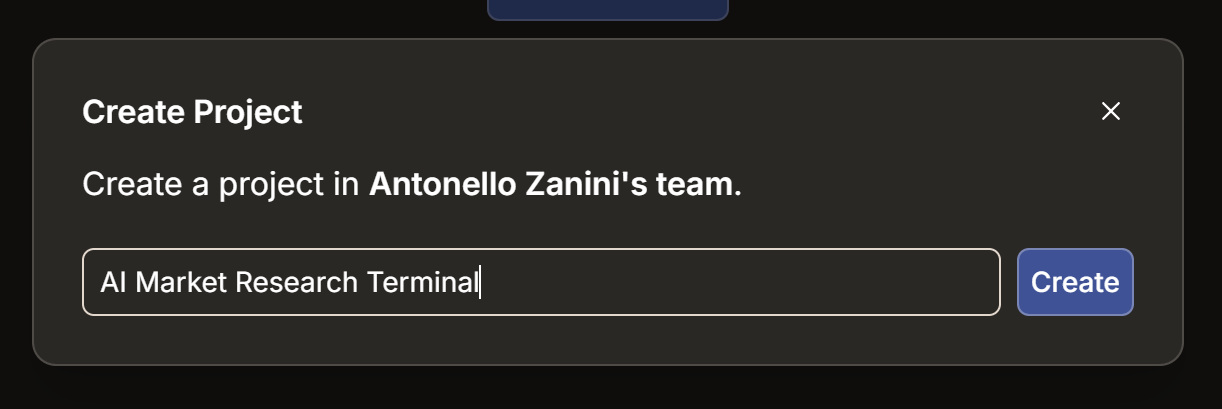
Attendez que le projet s’initialise, puis sélectionnez une région de déploiement :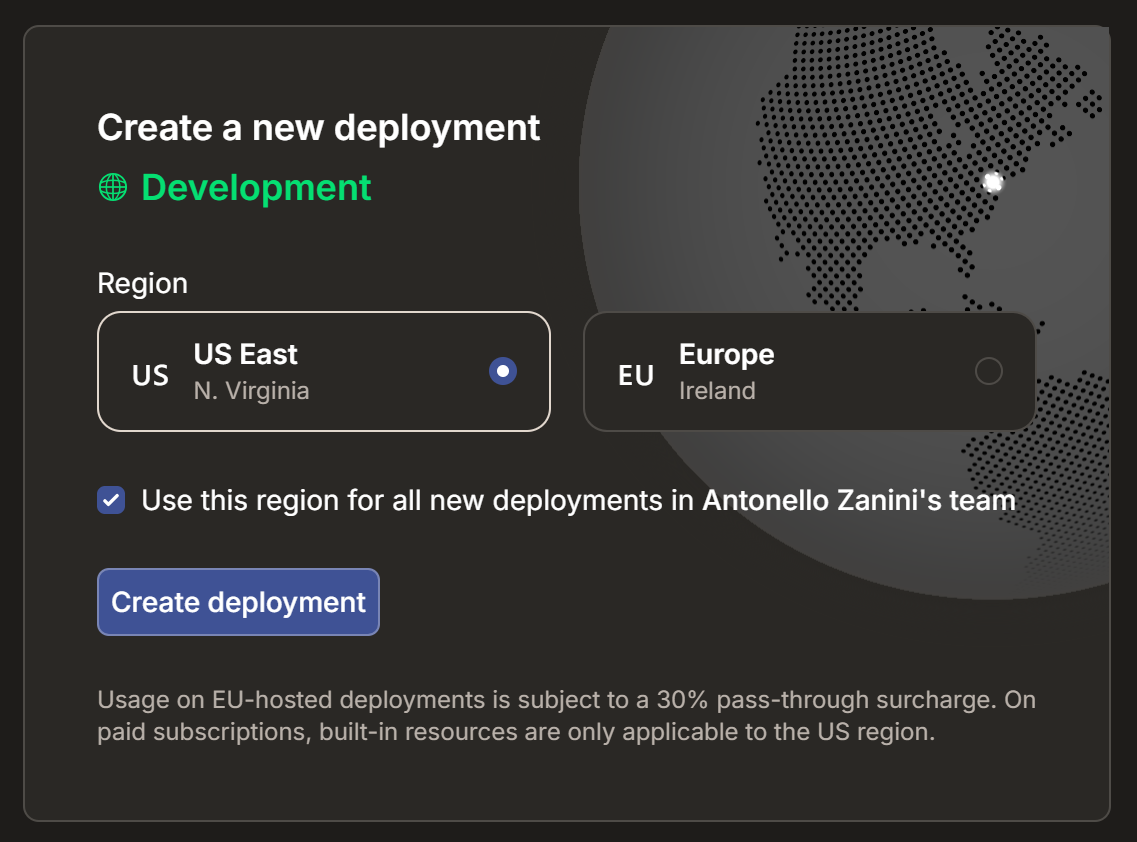
Confirmez en cliquant sur « Configurer le déploiement ». Après quelques secondes, votre projet devrait être prêt :
Parfait ! Vous disposez désormais de tous les éléments nécessaires pour cloner et exécuter le projet localement.
Étape n° 3 : Configurer le projet
Commencez par cloner le référentiel de démonstration dans un dossier local nommé ai-market-research-terminal/:
git clone https://github.com/brightdata/market-terminal IA-market-research-terminalVotre dossier de projet pour l’étude de marché ai-market-research-terminal/ devrait désormais contenir tous les fichiers répertoriés dans le dépôt officiel.
Accédez au répertoire du projet :
cd ai-terminal d'étude de marchéEnsuite, installez les dépendances du projet :
npm installParfait ! Vous pouvez désormais ouvrir le projet dans votre IDE JavaScript préféré, tel que Visual Studio Code. Explorez-le et familiarisez-vous avec son fonctionnement. Pour plus d’informations et pour découvrir les coulisses du projet, consultez l’article détaillé dédié sur DEV.
Étape n° 4 : Configurer l’application
L’application lit l’ensemble de sa configuration à partir d’un fichier .env.local. Le référentiel comprend un fichier d’exemple nommé .env.local.example. Copiez-le pour créer votre propre fichier .env.local:
cp .env.local.example .env.local
Ensuite, configurez le connecteur Convex en exécutant la commande suivante dans le dossier racine de votre projet :
npx convex devSuivez les instructions, connectez votre appareil à votre compte Convex dans le navigateur. Sélectionnez ensuite le projet « IA Etude de marché » existant que vous avez créé à l’étape n° 2. Convex mettra automatiquement à jour votre fichier .env.local avec les variables d’environnement nécessaires. Dans ce cas, il ajoutera :
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.siteCes valeurs permettent à votre application de se connecter à votre projet Convex.
Par défaut, deux nouvelles tables (sessionEnvts et session) seront ajoutées à votre projet Convex :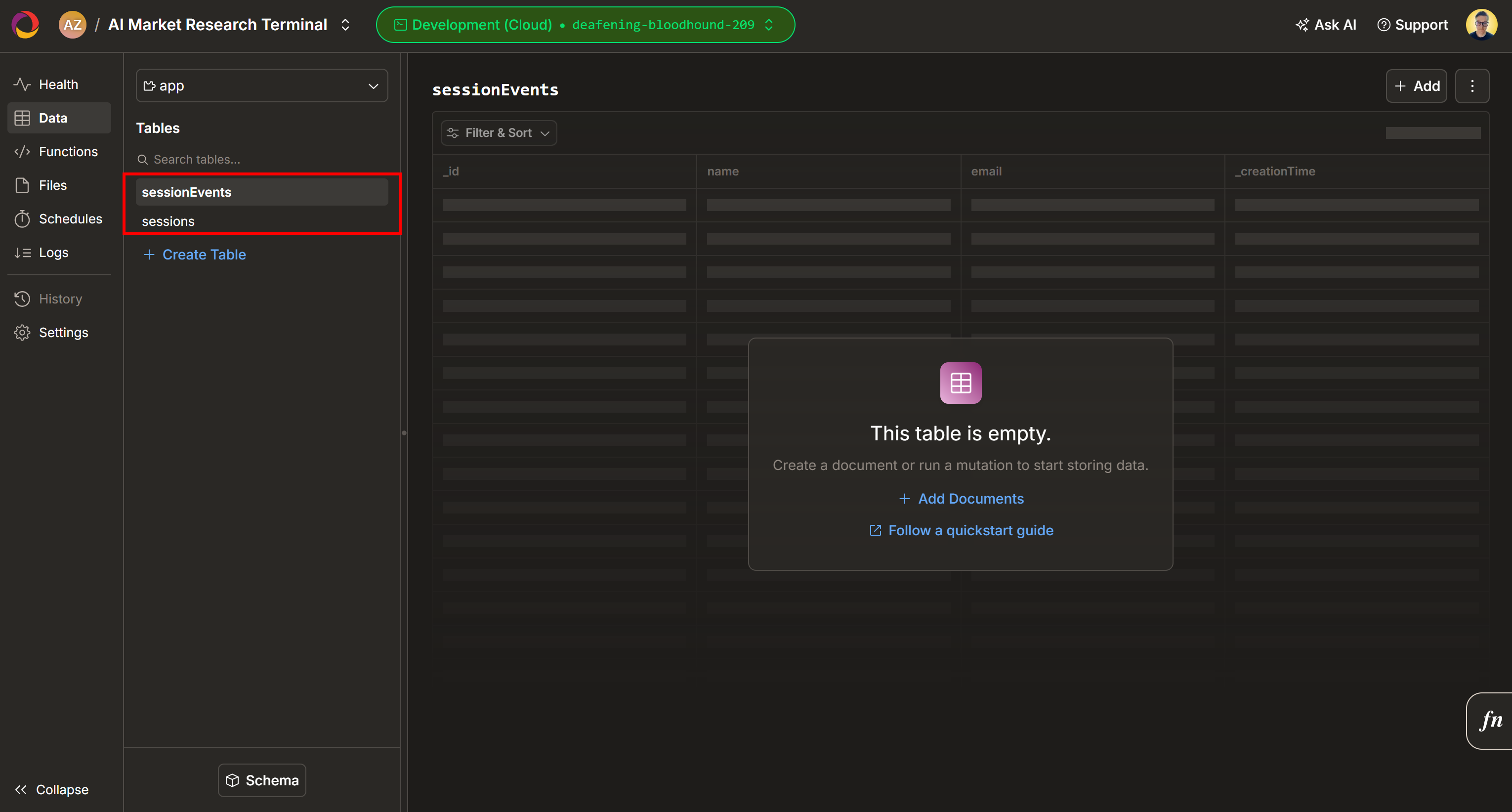
Ensuite, remplissez les variables d’environnement restantes dans .env.local:
BRIGHTDATA_API_TOKEN=<VOTRE_CLÉ_API_BRIGHTDATA>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<VOTRE_NOM_D'API_WEB_UNLOCKER_BRIGHTDATA> # par ex., « web_unlocker »
BRIGHTDATA_SERP_ZONE=<VOTRE_NOM_D'API_SERP_BRIGHTDATA> # par exemple, « serp_api »
OPENROUTER_API_KEY=<VOTRE_CLÉ_D'API_OPENROUTER>
OPENROUTER_MODEL=google/gemini-3-flash-previewRemplacez les espaces réservés par votre jeton API Bright Data, le nom de la zone Web Unlocker, le nom de la zone API SERP et la clé API OpenRouter. Notez que le LLM par défaut est Gemini 3 Flash, mais vous pouvez utiliser n’importe quel autre modèle pris en charge si vous le souhaitez.
Super ! Votre démo est désormais entièrement configurée et prête à être exécutée localement.
Étape n° 5 : Exécuter l’application localement
Lancez la démo localement avec :
npm run devOuvrez http://localhost/market-terminal dans votre navigateur pour accéder à l’application locale IA Etude de marché Terminal. Vous devriez voir :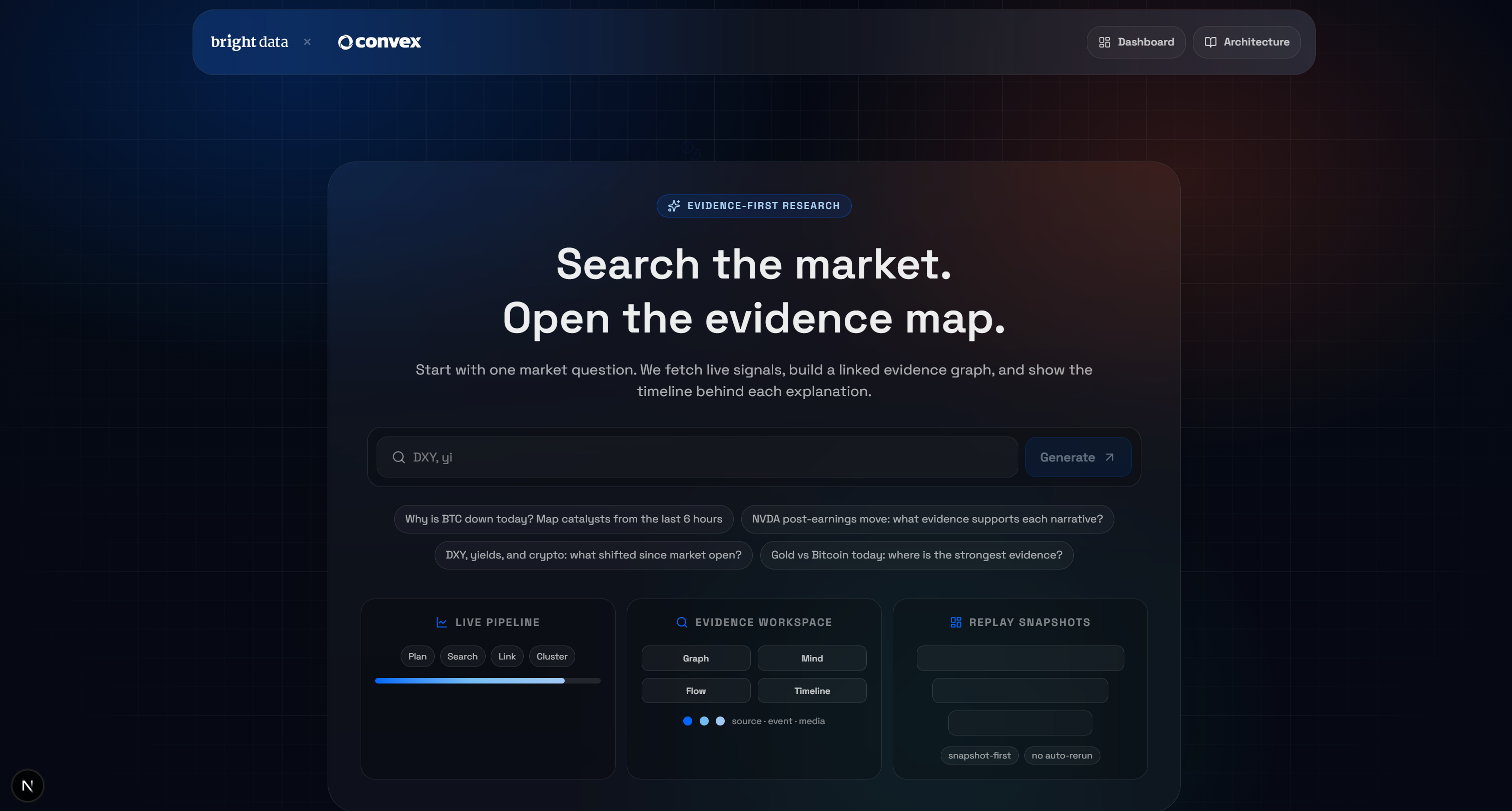
Testez l’application en saisissant une requête, par exemple :
Pourquoi le BTC est-il en baisse aujourd'hui ?Cliquez sur le bouton « Générer » et vous obtiendrez un résultat comme celui-ci :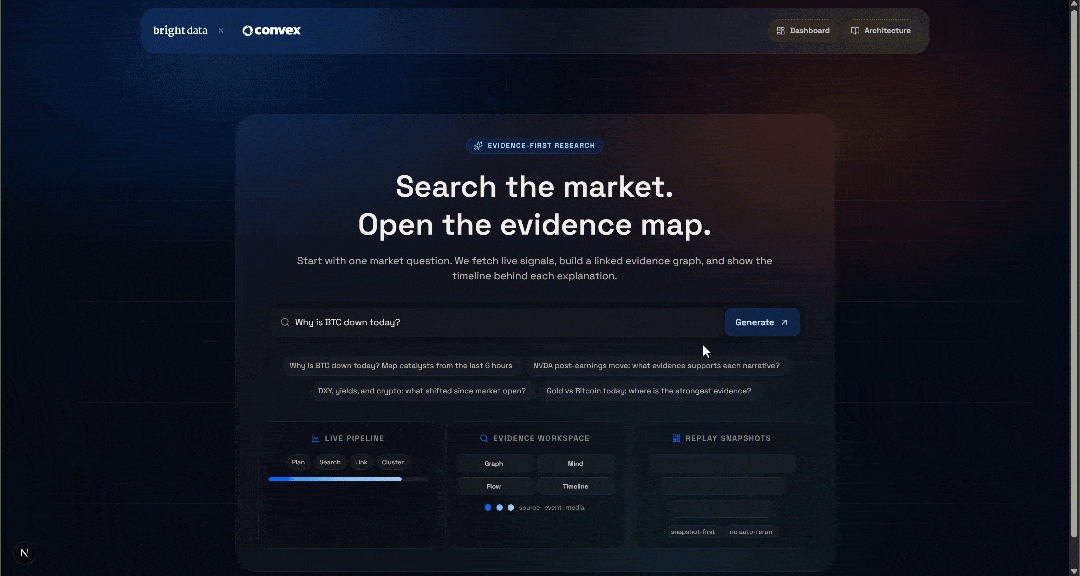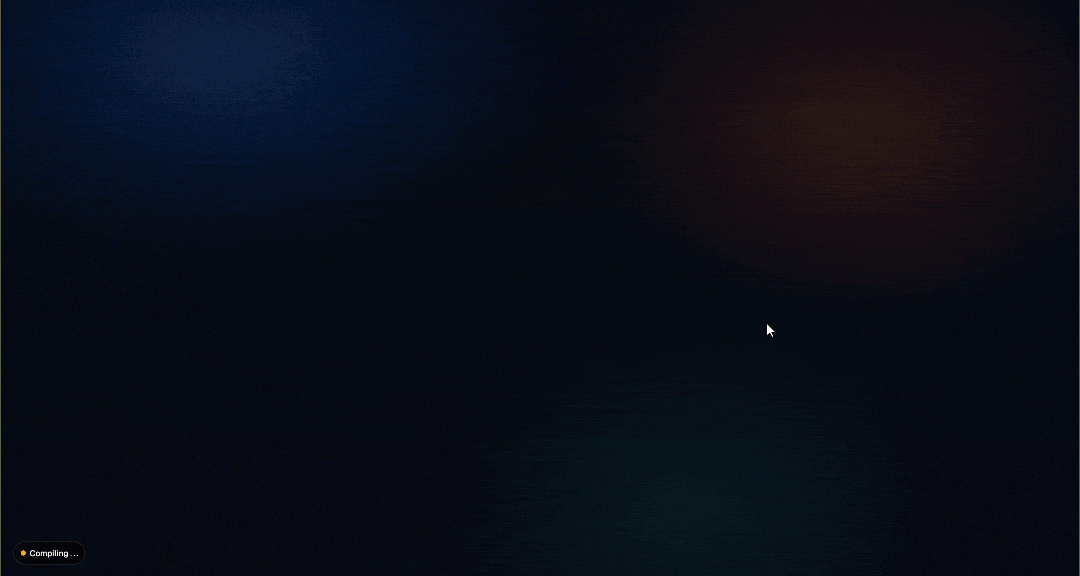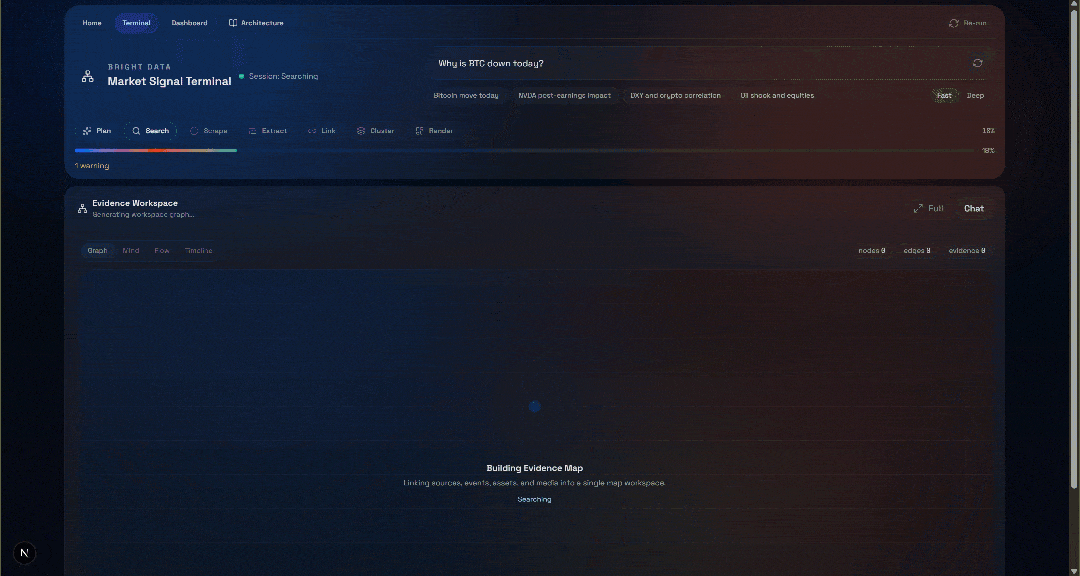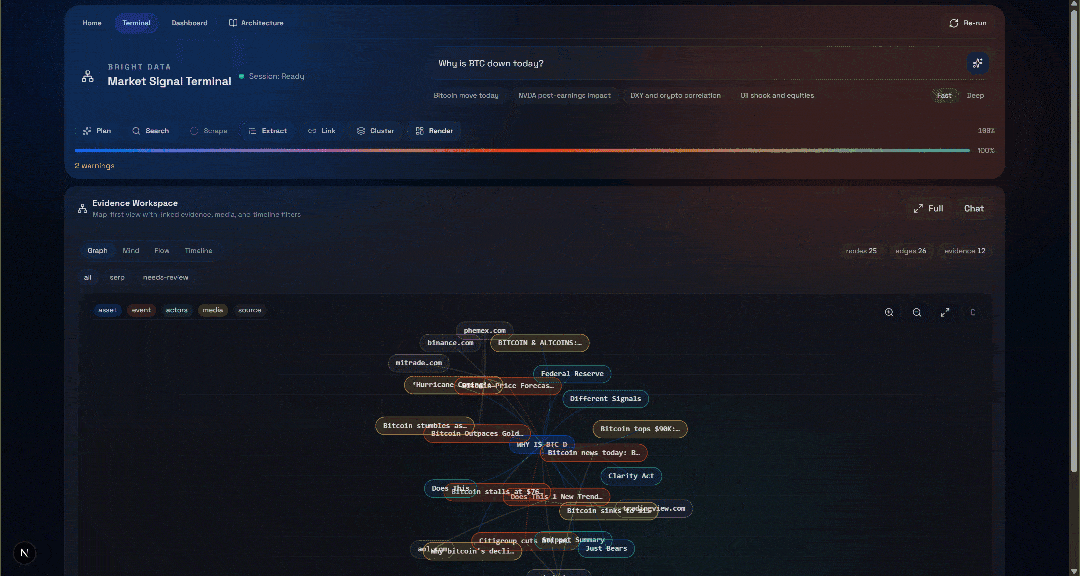
Consultez maintenant la section « Evidence Workspace ». Cette vue contient toutes les données récupérées en temps réel via le Scraping web, agrégées, traitées et stockées dans Convex. Votre base de données Convex contiendra désormais les données de cette exécution :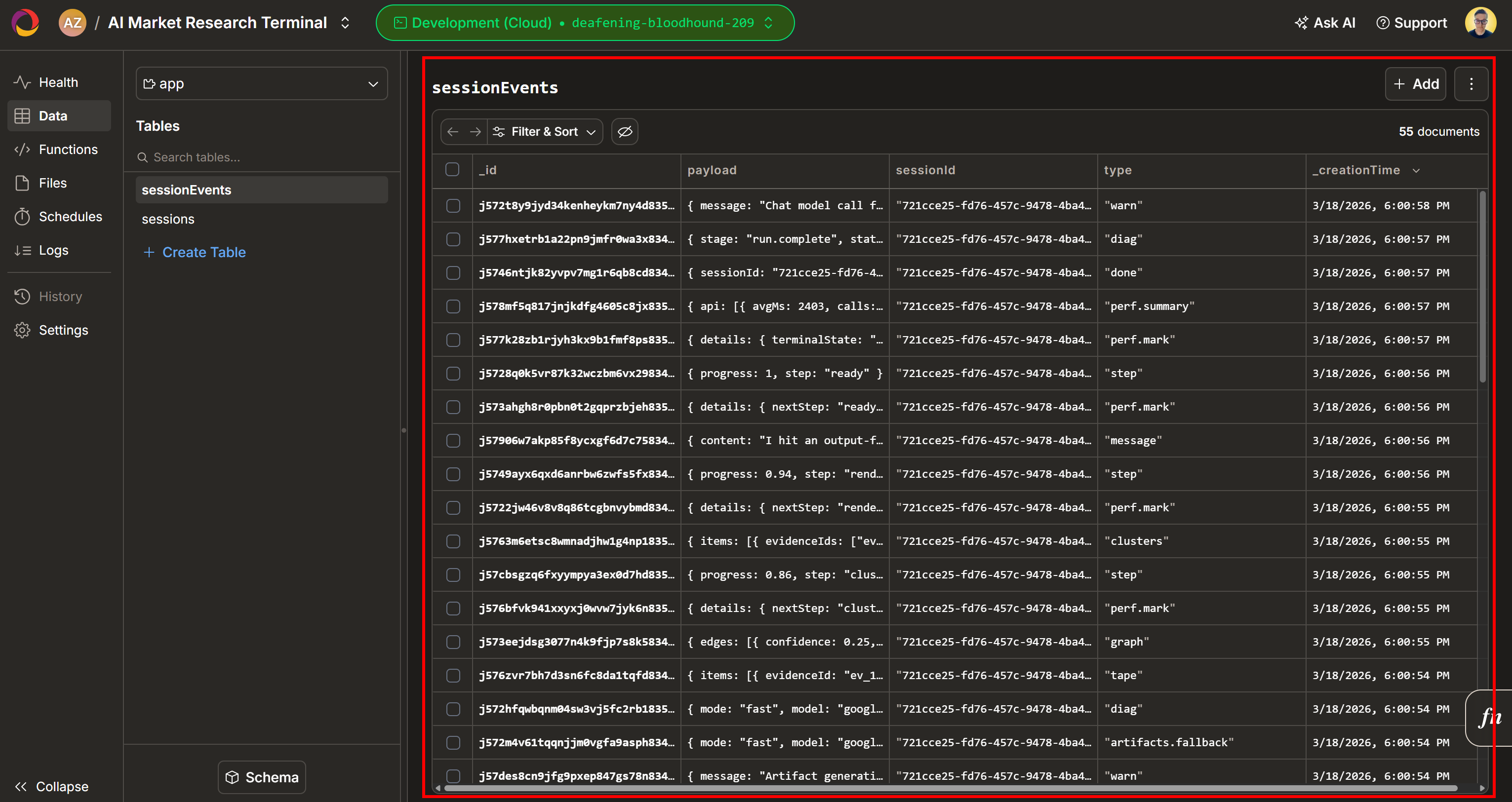
Ensuite, explorez les vues « Graph », « Mind », « Flow » et « Timeline » :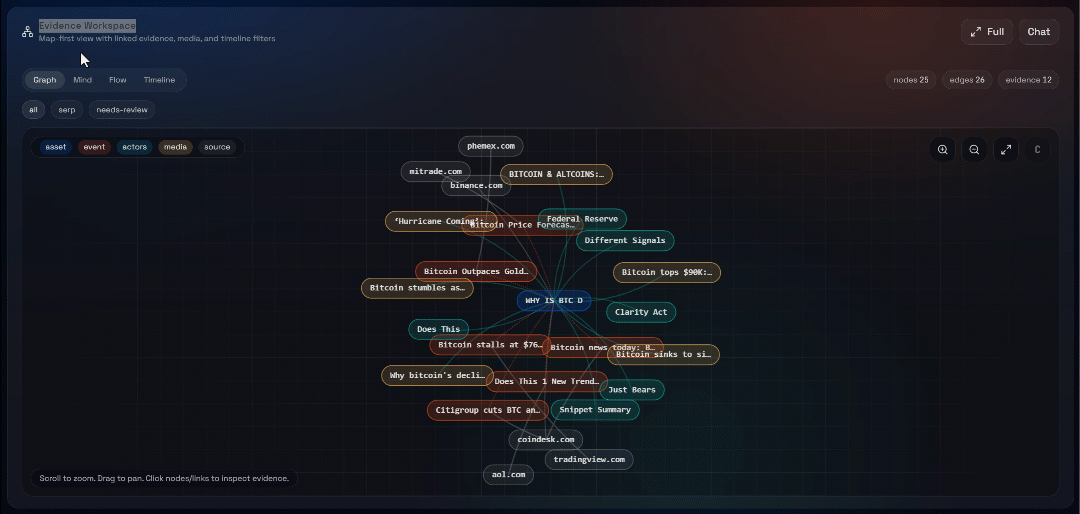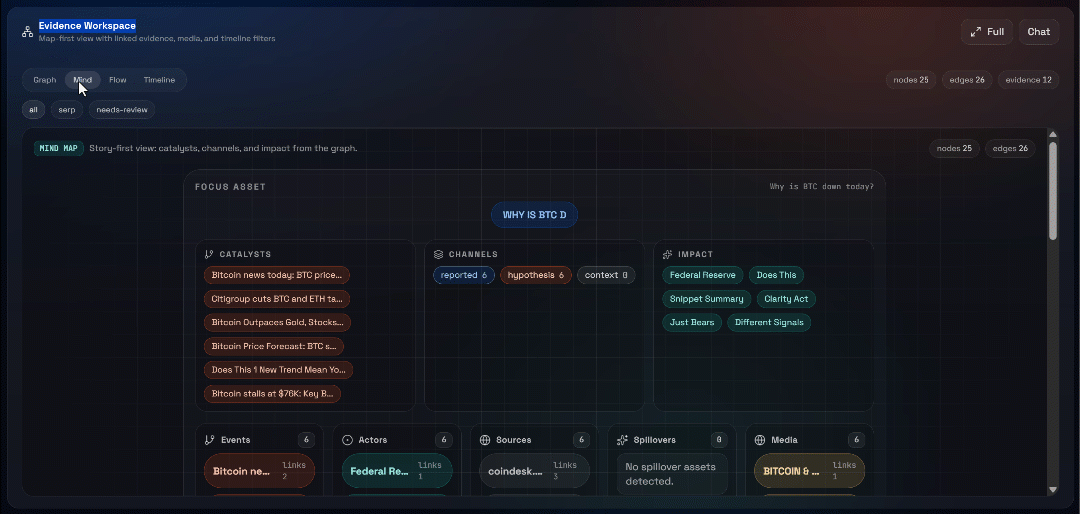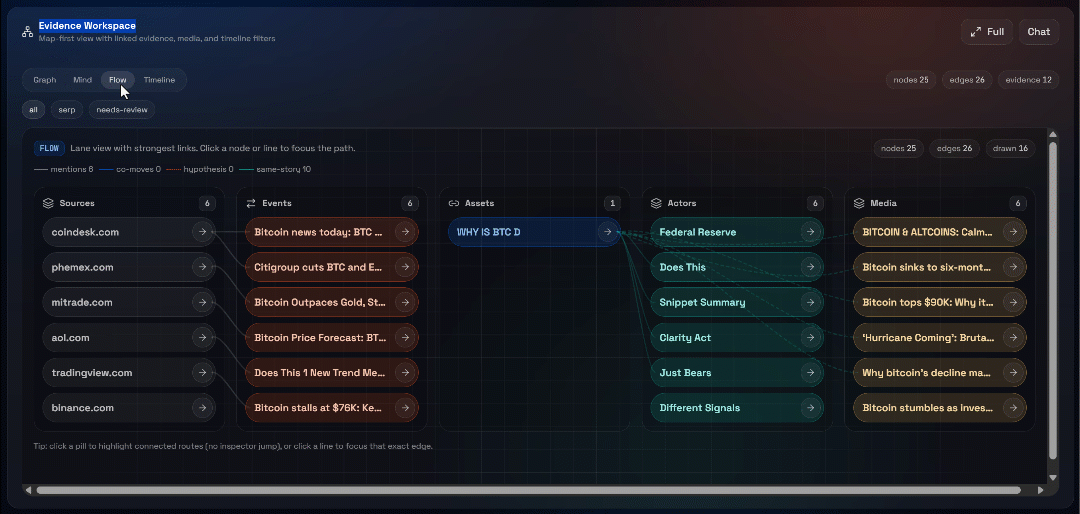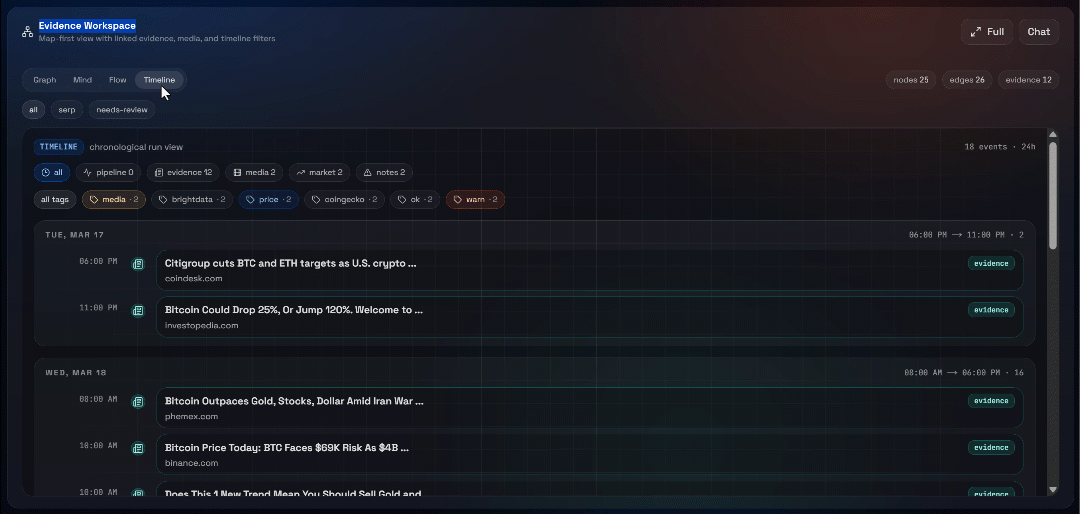
Vous pouvez y voir les sources récupérées, les filtrer et explorer les données plus en détail pour obtenir des informations plus approfondies.
Et voilà ! Vous disposez désormais d’une application IA pour l’étude de marché entièrement fonctionnelle, optimisée par Bright Data et utilisant Convex comme base de données backend. Il s’agit d’une application en direct et réactive qui achemine des données Web en temps réel directement vers votre espace de travail.
Conclusion
Dans cet article, vous avez découvert ce qu’est Convex, comment cela fonctionne et comment cela contribue à alimenter des applications réactives. Cette solution devient encore plus puissante lorsqu’elle est utilisée pour stocker des données fraîches extraites en direct du Web.
Bright Data permet le scraping web en temps réel grâce à une infrastructure de niveau entreprise. Cela sert de base à une large gamme de services de scraping web, vous permettant de collecter des données sur le Web rapidement et de manière fiable sans être bloqué.
Inscrivez-vous gratuitement à Bright Data dès aujourd’hui et découvrez nos solutions de collecte de données Web en temps réel !






