

Tableau est un outil de premier plan pour la visualisation des données, mais il présente une limitation majeure. Il ne peut pas extraire de manière fiable des données en temps réel à partir de sites web de manière autonome. L’ancien Web Data Connector (WDC v2), qui résolvait auparavant ce problème, a été déprécié en 2023. Sa dernière version compatible (Tableau 2022.4) a depuis atteint sa fin de vie, laissant les analystes sans solution prise en charge.
Ce guide compare 6 méthodes de Scraping web et de connexion de données en temps réel à Tableau. Il comprend également un tutoriel étape par étape pour créer un pipeline API-Tableau à l’aide de l’API Web Scraper de Bright Data.
En bref
Tableau ne peut pas extraire de données de sites web en natif, et son Web Data Connector (WDC v2) a été déprécié en 2023. Vous avez besoin d’un pipeline de données externe.
- WDC v2 est obsolète ; WDC v3 ne permet que l’extraction et est complexe à mettre en place
- Google Sheets, Excel et TabPy présentent chacun des limites critiques à grande échelle
- Les scripts Python DIY fonctionnent au départ, mais nécessitent une maintenance constante
- Une API de scraping gérée gère automatiquement les Proxys, les CAPTCHA et l’analyse des données
Suivez le tutoriel étape par étape de ce guide pour créer un pipeline fonctionnel Amazon → Bright Data → Tableau.
Pourquoi Tableau a besoin d’un pipeline de données externe
La pile de données moderne nécessite des données Web en temps réel: prix des concurrents, indicateurs des réseaux sociaux, offres d’emploi, annonces immobilières et flux financiers. Tableau n’a pas été conçu pour les collecter.
Les principaux défis sont les suivants :
- Les sites web changent constamment: les mises en page évoluent, les mesures anti-bot se perfectionnent et les exigences de rendu JavaScript augmentent
- L’évolutivité est essentielle: la surveillance quotidienne de 10 000 références de concurrents nécessite une logique de réessai, une limitation de débit et une gestion des échecs dont un script à page unique n’a pas besoin
- La conformité est obligatoire: le RGPD, le CCPA et les conditions d’utilisation des plateformes exigent des pratiques de collecte de données rigoureuses
- L’infrastructure est coûteuse: la rotation des proxys, la Résolution de CAPTCHA, la logique de réessai et la gestion des adresses IP constituent des défis techniques permanents
Les méthodes suivantes comblent cette lacune.
6 méthodes pour le Scraping web et la connexion de données en temps réel à Tableau
Chaque méthode offre un équilibre différent entre l’échelle, la maintenance et la fiabilité. Elles sont classées de la moins viable à la plus prête pour la production.
Méthode 1 : Tableau Web Data Connector v2 (obsolète)
Description : WDC v2 vous permettait de créer des connecteurs basés sur JavaScript qui extrayaient des données d’API Web directement dans Tableau.
Pourquoi cela ne fonctionne plus : obsolète depuis Tableau 2023.1. Les connecteurs WDC v2 ne sont plus pris en charge dans aucune version actuelle de Tableau, et Tableau pourrait les supprimer complètement dans une future version. La migration vers WDC v3 est obligatoire, mais la v3 repose sur une architecture fondamentalement différente.
Limitation critique : la prise en charge a pris fin. Si vous utilisez encore des connecteurs WDC v2, effectuez la migration dès maintenant, car ils pourraient cesser de fonctionner lors d’une future mise à jour de Tableau.
Méthode 2 : Google Sheets comme couche intermédiaire
Fonctionnement : extrayez les données dans Google Sheets (via Apps Script, IMPORTXML, IMPORTDATA ou des outils tiers), puis connectez Tableau à Sheets en tant que source de données en temps réel.
Pourquoi l’utiliser : c ‘est gratuit, cela ne nécessite aucun codage et Tableau se connecte à Google Sheets via son connecteur Google Drive.
Limites importantes :
- Google Sheets a une limite de 10 millions de cellules – les grands Jeux de données atteignent rapidement cette limite
- Les formules
IMPORTXMLetIMPORTHTMLcessent constamment de fonctionner en raison des modifications apportées à la structure des sites web - La fréquence de rafraîchissement n’est pas fiable. Google limite l’exécution des formules de manière imprévisible
- Pas de rendu JavaScript, les applications monopages (SPA) modernes renvoient donc des données vides (un Navigateur de scraping est nécessaire pour celles-ci)
- Les limites de débit de l’API Google Sheets provoquent des échecs de synchronisation lors des actualisations programmées
Conclusion : fonctionne pour les petits prototypes. Ne fonctionne plus à plus grande échelle. Bon choix pour les tableaux de bord personnels suivant moins de 10 000 lignes de données qui changent rarement.
Méthode 3 : Excel + OneDrive / SharePoint
Fonctionnement : utilisez la fonctionnalité Power Query ou « Obtenir des données du Web » d’Excel pour extraire des données à partir d’URL et les enregistrer sur OneDrive. Connectez ensuite Tableau au fichier Excel hébergé dans le cloud.
Limites majeures :
- Actualisation manuelle requise – Power Query ne s’actualise pas automatiquement en arrière-plan de manière fiable
- Pas de rendu JavaScript, donc impossible de gérer React, Angular ou tout site basé sur une SPA
- Analyse syntaxique limitée. Les structures HTML complexes interrompent souvent l’importation
- Les conflits de synchronisation OneDrive entraînent des problèmes d’intégrité des données
- L’absence de rotation des proxys entraîne des interdictions d’IP en cas de volume de scraping important
Conclusion : convient pour un rapport unique à partir d’une page web statique. Ne constitue pas un pipeline de données.
Méthode 4 : TabPy (Python + extensions Tableau)
Fonctionnement : TabPy est le serveur Python officiel de Tableau. Il exécute des scripts Python à l’intérieur des champs calculés de Tableau à l’aide de fonctions telles que SCRIPT_REAL et SCRIPT_STR. En théorie, la logique de Scraping web s’exécute directement dans Tableau via TabPy.
Pourquoi l’utiliser : Python dispose de bibliothèques de scraping très complètes, et TabPy est officiellement pris en charge par Tableau.
Limites importantes :
- Nécessite un serveur TabPy en fonctionnement – infrastructure supplémentaire à maintenir
- Le scraping à l’intérieur des champs calculés de Tableau est une mauvaise pratique. C’est lent, peu fiable et cela bloque le rendu du tableau de bord
- L’absence de rotation des proxys signifie que l’adresse IP de votre serveur TabPy est immédiatement bannie sur les cibles à fort volume
- Pas de résolution de CAPTCHA, pas de logique de réessai, pas de rendu JavaScript
- Les champs calculés ont des limites de temps d’exécution, ce qui entraîne l’expiration des tâches de scraping complexes
- Le débogage est extrêmement difficile car les erreurs s’affichent sous forme de messages d’erreur Tableau peu clairs
Conclusion : TabPy est idéal pour exécuter des modèles d’apprentissage automatique et des calculs statistiques dans Tableau. Il n’est pas adapté au Scraping web.
Méthode 5 : scripts Python personnalisés (requests, Scrapy, Selenium)
Fonctionnement : écrivez des scripts Python personnalisés à l’aide de bibliothèques telles que requests, BeautifulSoup, Scrapy ou Selenium. Exécutez-les selon un calendrier (par exemple via cron ou Airflow), générez des fichiers CSV/JSON, puis connectez Tableau à ces fichiers.
Pourquoi l’utiliser : flexibilité maximale. Vous contrôlez tout.
Limites majeures :
- Charge de maintenance élevée: les sites web modifient leur mise en page, ajoutent des mesures anti-bot et changent leurs structures HTML. Votre Scraper échoue sans avertissement et le tableau de bord affiche des données obsolètes.
- Blocage d’IP à grande échelle – sans réseau Proxy, les cibles bloquent votre serveur en quelques heures
- Pas de résolution de CAPTCHA – Cloudflare, reCAPTCHA et hCaptcha bloquent votre Scraper sans solution de contournement intégrée (des services comme Web Unlocker gèrent cela automatiquement)
- Coûts d’infrastructure – vous avez besoin de serveurs, d’abonnements Proxy, de surveillance et d’alertes
- Risque de non-conformité – sans infrastructure adéquate, vous risquez d’enfreindre le RGPD, le CCPA ou les conditions d’utilisation des plateformes
- Manque d’évolutivité – scraper 100 URL n’est pas la même chose que scraper 100 000. L’architecture qui fonctionne pour l’un échoue complètement pour l’autre.
Conclusion : le « DIY » est viable au départ, mais n’est pas fiable à long terme. La plupart des équipes commencent ainsi, et beaucoup réussissent au début. Mais l’effort de maintenance augmente avec le temps.
Cela fonctionne bien le premier mois, mais après plusieurs mois, vous passez plus de temps à réparer des sélecteurs défectueux et à gérer les interdictions d’IP qu’à créer des tableaux de bord. Si vous effectuez le scraping d’un ou deux sites à faible volume, des scripts DIY peuvent suffire.
Méthode 6 : API Web Scraper de Bright Data (recommandée)
Fonctionnement : l’API Web Scraper de BrightData gère l’ensemble de la couche de collecte de données : rotation des proxys, Résolution de CAPTCHA, rendu JavaScript, contournement des anti-bots et sortie de données structurées. Vous déclenchez une tâche de collecte via l’API, recevez des données JSON/CSV propres et les chargez dans Tableau.
Avantages :
| Capacité | Bright Data | Scripts DIY |
|---|---|---|
| Réseau de proxies | Plus de 150 millions d’adresses IP dans 195 pays | Achetez les vôtres (coûteux) |
| Scrapers prêts à l’emploi | Plus de 120 pour les principales plateformes | Créez-le de zéro |
| Résolution de CAPTCHA | Automatique | Non inclus |
| Rendu JavaScript | Intégré | Nécessite Selenium/Playwright |
| Contournement anti-bot | Automatique | Nécessite des mises à jour manuelles constantes |
| Temps de disponibilité | 99,99 | Dépend de votre infrastructure |
| Conformité | RGPD, CCPA, ISO 27001 | Votre responsabilité |
| Maintenance | Minimale – Bright Data gère les mises à jour des Scrapers | Constante |
| Évolutivité | Des millions de pages par jour | Limité par vos serveurs |
| Tarification | À partir de 1,50 $ pour 1 000 enregistrements | Variable (serveurs + Proxies + maintenance) |
Conclusion : vous vous concentrez sur les tableaux de bord Tableau ; Bright Data gère l’infrastructure de collecte des données.
Compromis : Bright Data est un service tiers payant. Vous dépendez de son infrastructure et de son modèle tarifaire. Pour un scraping occasionnel d’un ou deux sites à faible volume, un script DIY (méthode 5) coûte moins cher et vous offre un contrôle total.
Quelle méthode de connexion aux données Tableau choisir ?
Ce tableau compare les six méthodes en fonction des capacités les plus importantes pour les pipelines de production.
| Méthode | Rendu JS | Rotation de proxy | Résolution de CAPTCHA | Actualisation automatique | Mise à l’échelle | Maintenance | État |
|---|---|---|---|---|---|---|---|
| WDC v2 | Non | Non | Non | Oui | Faible | N/A | Obsolète |
| Google Sheets | Non | Non | Non | Peu fiable | Très faible | Faible | Limites de cellules |
| Excel + OneDrive | Non | Non | Non | Manuel | Très faible | Moyen | Processus manuel |
| TabPy | Manuel/À faire soi-même | Non | Non | Oui | Faible | Élevé | Interdictions d’IP |
| Python DIY | Via Selenium | À faire soi-même | Non | Via cron | Moyen | Très élevé | Pannes à grande échelle |
| API Bright Data | Oui | Oui (plus de 150 millions d’adresses IP) | Oui | Oui | Élevé | Minimale | Prêt pour la production |
Tutoriel : connecter une API de Scraping web à Tableau
Ce tutoriel permet de créer un pipeline complet : prix des produits Amazon → API Bright Data → CSV → tableau de bord Tableau à l’aide de l’API Amazon Scraper. Il aborde le cas d’utilisation « Surveillance des prix des concurrents », la raison la plus courante pour laquelle les équipes connectent des données Web à Tableau.
Architecture
Le pipeline suit le flux suivant :
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ Votre script │────▶│ Bright Data Scraper │────▶ │ CSV/JSON │────▶│ Tableau de bord │
│ (Python/cron) │ │ API │ │ Sortie │ │ Tableau de bord │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
Déclencheur avec Gère les Proxy, Visualise les prix,
mots-clés/URLs les CAPTCHA, le rendu les notes, les tendancesPrérequis
Vous devez disposer des éléments suivants avant de commencer :
- Python 3.8+
- Un compte Bright Data (essai gratuit disponible, aucune carte de crédit requise)
- Votre jeton API depuis le tableau de bord Bright Data (instructions à l’étape 0)
- Tableau Desktop (essai gratuit de 14 jours), Tableau Cloud ou Tableau Public (gratuit, les tableaux de bord sont publics)
Une fois ces outils prêts, commencez par générer votre jeton API Bright Data.
Étape 0 : Obtenez votre jeton API Bright Data
Suivez ces étapes pour générer votre jeton API :
- Inscrivez-vous ou connectez-vous sur brightdata.com/cp
- Accédez à Paramètres du compte → Utilisateurs et clés API
- Sélectionnez « Ajouter une clé API » (en haut à droite de la section Clés API)
- Définissez les autorisations et la date d’expiration, puis sélectionnez Enregistrer
- Copiez le jeton
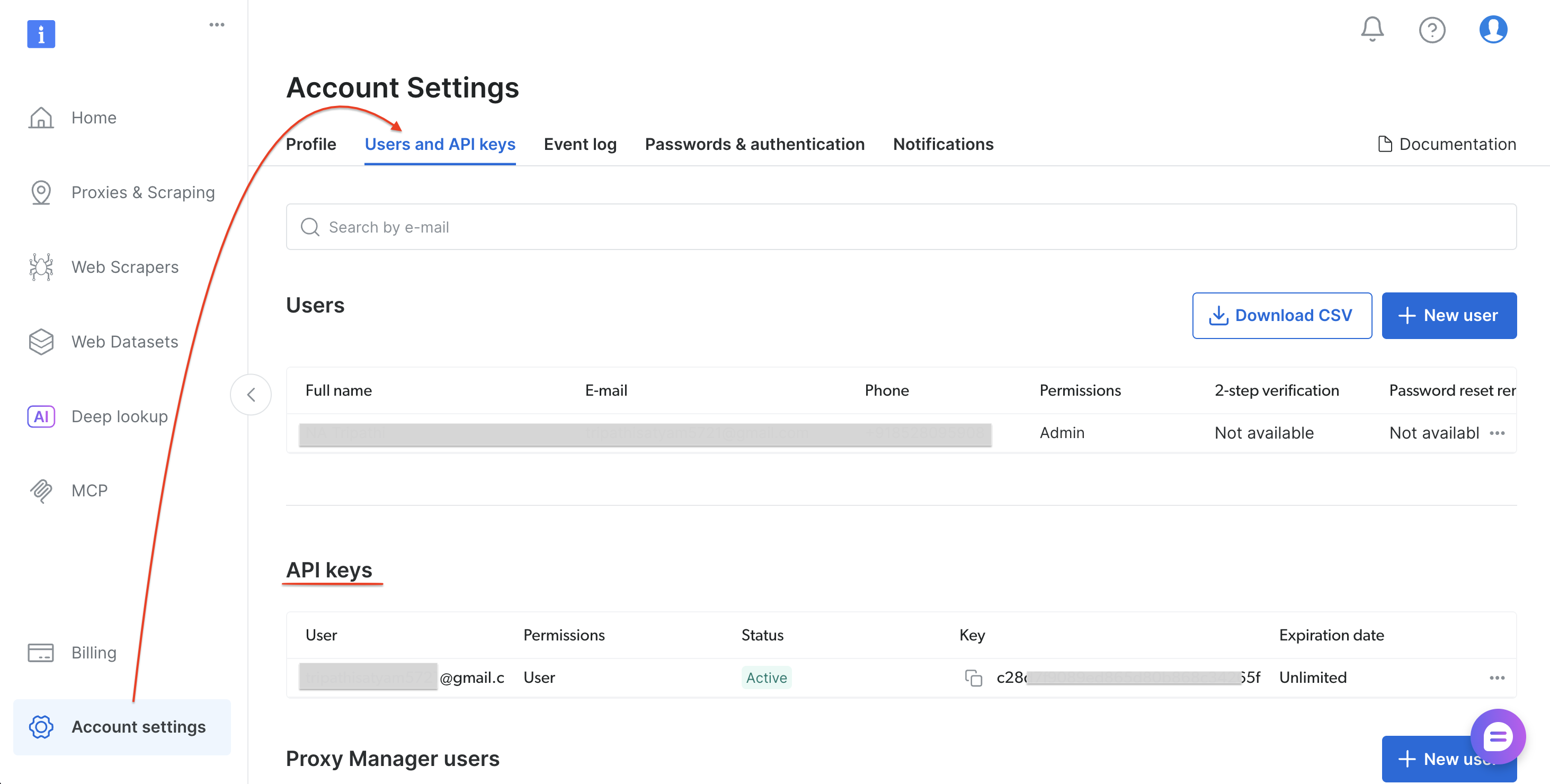
Une fois votre jeton API enregistré, installez les dépendances Python.
Étape 1 : Installer les dépendances
Installez les paquets Python requis :
pip install requests pandasUne fois requests et pandas installés, créez le script de pipeline.
Étape 2 : Le script de pipeline
Créez un fichier nommé bright_data_to_tableau.py:
"""
Pipeline Bright Data → Tableau
Récupère les données sur les produits Amazon via l'API Web Scraper de Bright Data
et génère un fichier CSV prêt à être utilisé dans Tableau.
Utilisation :
1. Remplacez YOUR_API_TOKEN par votre jeton API Bright Data
2. Exécutez : python bright_data_to_tableau.py
3. Ouvrez le fichier CSV généré dans Tableau Desktop
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── Configuration ───────────────────────────────────────────────────────────
API_TOKEN = "VOTRE_JETON_API" # Remplacez par votre jeton API Bright Data
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Recherche de produits Amazon (par mot-clé)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # Intervalle en secondes entre les vérifications d'état
POLL_TIMEOUT = 300 # Temps d'attente maximal en secondes
# ─── Points de terminaison API ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/datasets/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/datasets/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Déclenche une tâche de collecte de données sur Bright Data."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] Déclenchement de la collecte pour le mot-clé : '{keyword}'...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERREUR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" ID du snapshot : {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""Interroge le point de terminaison du snapshot jusqu'à ce que les données soient prêtes."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] En attente des résultats...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" Prêt ! {len(data)} enregistrements reçus.")
return data
elif response.status_code == 202:
print(f" Traitement en cours... ({elapsed}s / {POLL_TIMEOUT}s)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" ERREUR {response.status_code}: {response.text}")
sys.exit(1)
print(f" DÉLAI D'ATTENTE : instantané non prêt après {POLL_TIMEOUT}s.")
print(f" Essayez d'augmenter POLL_TIMEOUT ou consultez le tableau de bord Bright Data.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""Transforme les données brutes de l'API en un fichier CSV propre et optimisé pour Tableau."""
df = pd.DataFrame(data)
# Mappage des noms de champs de l'API → noms compatibles avec Tableau
column_mapping = {
"title": "Nom du produit",
"seller_name": "Vendeur",
"brand": "Marque",
"initial_price": "Prix d'origine",
"final_price": "Prix actuel",
"currency": "Devise",
"rating": "Note",
"reviews_count": "Nombre d'avis",
"availability": "Disponibilité",
"url": "URL du produit",
"asin": "ASIN",
"categories": "Catégories",
"delivery": "Informations de livraison",
}
# Ne conserver que les colonnes présentes dans les données
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Ajouter des métadonnées pour le filtrage et le suivi dans Tableau
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] {len(df)} lignes enregistrées → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""Affiche un résumé des données extraites."""
print(f"n{'─'*50}")
print(f" Résumé")
print(f"{'─'*50}")
print(f" Nombre total de produits : {len(df)}")
if "Prix actuel" in df.columns:
prices = pd.to_numeric(df["Prix actuel"], errors="coerce")
print(f" Fourchette de prix : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" Prix moyen : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" Marques uniques : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" Note moyenne : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""Exécuter le pipeline complet : Déclencheur → Sondage → CSV → Résumé."""
print(f"n{'='*50}")
print(f" Bright Data → Pipeline Tableau")
print(f" Mot-clé : '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# Mot-clé par défaut — modifiez-le ou passez-le en argument CLI
keyword = sys.argv[1] if len(sys.argv) > 1 else "écouteurs sans fil"
run_pipeline(keyword)Étape 3 : Exécuter le script
Exécutez le script du pipeline :
python bright_data_to_tableau.pyRésultat attendu :
==================================================
Pipeline Bright Data → Tableau
Mot-clé : « wireless headphones »
==================================================
[1/3] Déclenchement de la collecte pour le mot-clé : « wireless headphones »...
ID de l'instantané : sd_mmlan9p51yycmmkd7d
[2/3] En attente des résultats...
Traitement en cours... (0 s / 300 s)
Prêt ! 43 enregistrements reçus.
[3/3] 43 lignes enregistrées → amazon_products_tableau.csv
──────────────────────────────────────────────────
Résumé
──────────────────────────────────────────────────
Nombre total de produits : 43
Fourchette de prix : 0,00 $ – 169,95 $
Prix moyen : 45,98 $
Marques uniques : 4
Note moyenne : 4,4 / 5,0
──────────────────────────────────────────────────Le fichier CSV est prêt. Ouvrez-le dans Tableau pour commencer à créer des tableaux de bord.
Étape 4 : Se connecter à Tableau
Chargez le fichier CSV dans Tableau et vérifiez les types de données :
- Ouvrez Tableau Desktop, Tableau Cloud ou Tableau Public
- Connectez-vous au fichier CSV : dans Desktop, sélectionnez Connecter → Fichier texte. Dans Cloud, sélectionnez Nouveau → Classeur → onglet Fichiers et téléchargez le fichier
- Vérifiez que les champs «
Prix actuel» et «Note» sont détectés comme des nombres et non comme des chaînes de caractères - Sélectionnez la feuille 1 pour commencer la création
Vues de tableau de bord recommandées :
- Répartition des prix – Histogramme du
prix actuelpour identifier le positionnement sur le marché - Analyse de la baisse des prix – Diagramme à barres côte à côte du
prix d'origineetdu prix actuelpour identifier les remises - Note vs prix – Nuage de points pour trouver les produits à forte valeur ajoutée
- Comparaison des marques – Diagramme à barres regroupant les produits par
marquepour comparer les prix et les notes
Étape 5 : Automatiser l’actualisation
Pour que votre tableau de bord reste à jour, planifiez l’exécution du script avec cron (Linux/Mac) ou le Planificateur de tâches (Windows) :
# Exécuter toutes les 6 heures — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.pyActualisation de Tableau pour afficher les nouvelles données :
- Tableau Desktop. Une fois que la tâche cron a mis à jour le fichier CSV, appuyez sur F5 (Windows) ou Commande+R (Mac) pour recharger. Vous pouvez également sélectionner la source de données dans le menu Données et choisir Actualiser. Tableau Desktop n’actualise pas automatiquement les sources basées sur des fichiers, vous devrez donc actualiser manuellement ou rouvrir le classeur.
- Tableau Server. Depuis Tableau Desktop, publiez via Serveur → Publier le classeur. Dans la boîte de dialogue de publication, définissez un calendrier de rafraîchissement de l’extrait (par exemple, toutes les 6 heures pour correspondre à votre tâche cron). Tableau Server rafraîchira automatiquement l’extrait selon ce calendrier.
- Tableau Cloud. Les fichiers CSV téléchargés via un navigateur ne peuvent pas être actualisés automatiquement. Pour automatiser les actualisations, installez Tableau Bridge sur la machine exécutant votre tâche cron. Bridge connecte votre fichier CSV local à Tableau Cloud et prend en charge les actualisations planifiées des extraits. Sans Bridge, vous devrez retélécharger le fichier CSV manuellement après chaque exécution du pipeline.
- Tableau Public. Ne prend pas en charge les actualisations planifiées pour les sources basées sur des fichiers. Pour les pipelines basés sur des fichiers CSV, vous devrez republier le classeur à chaque mise à jour des données.
Étape 6 : Utilisez n’importe quel Scraper (recherche des ID de Jeux de données)
Ce tutoriel utilise l’ensemble de données Amazon Products Search (gd_lwdb4vjm1ehb499uxs). Pour extraire les données d’un autre site web, remplacez l’ID de l’ensemble de données. Voici comment le trouver :
- Connectez-vous au panneau de configuration de Bright Data
- Sélectionnez « Scrapers » dans la barre latérale pour ouvrir la bibliothèque de scrapers Web
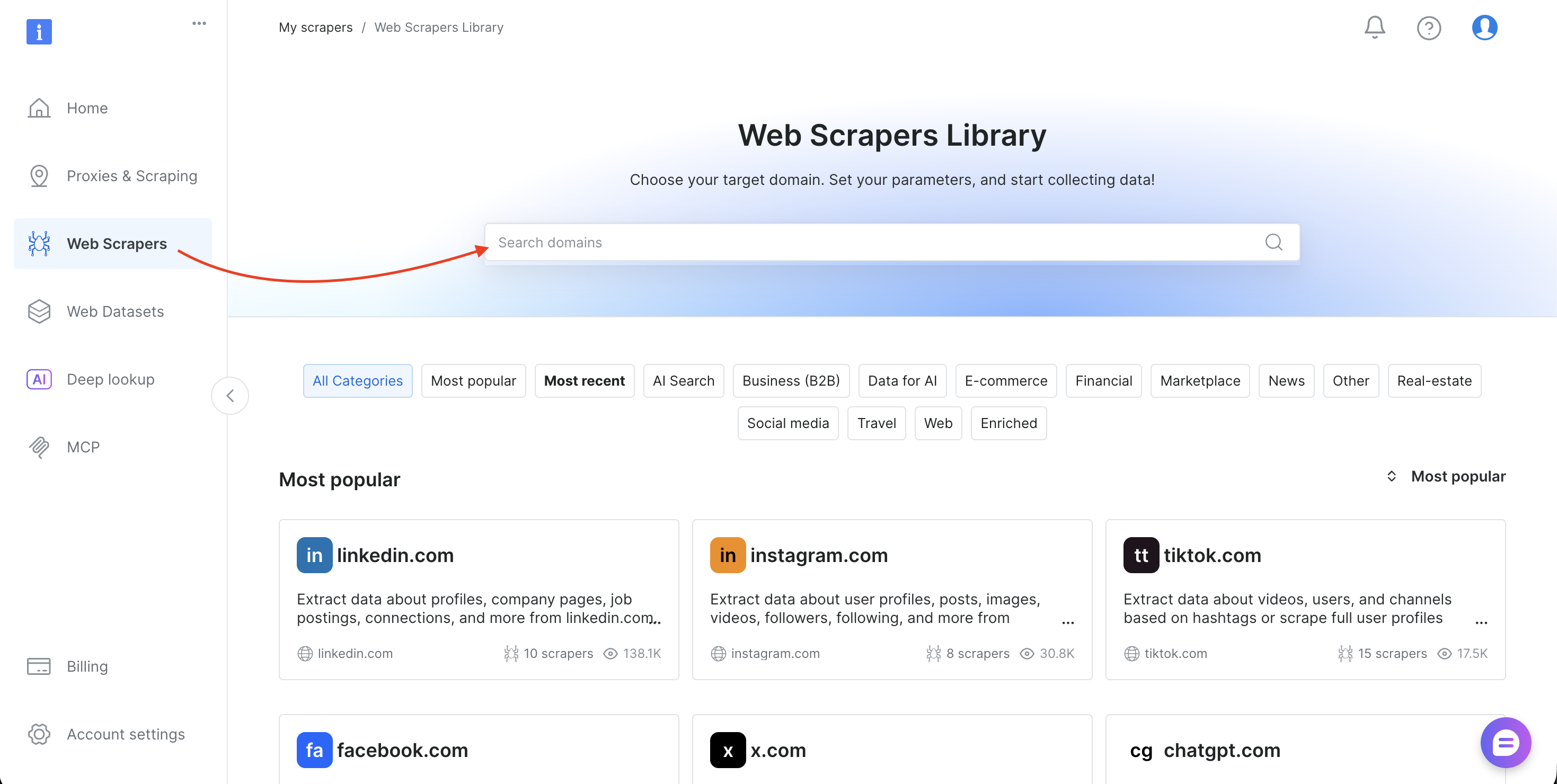
- Recherchez votre domaine cible (tel que amazon.com, zillow.com ou linkedin.com) et sélectionnez-le
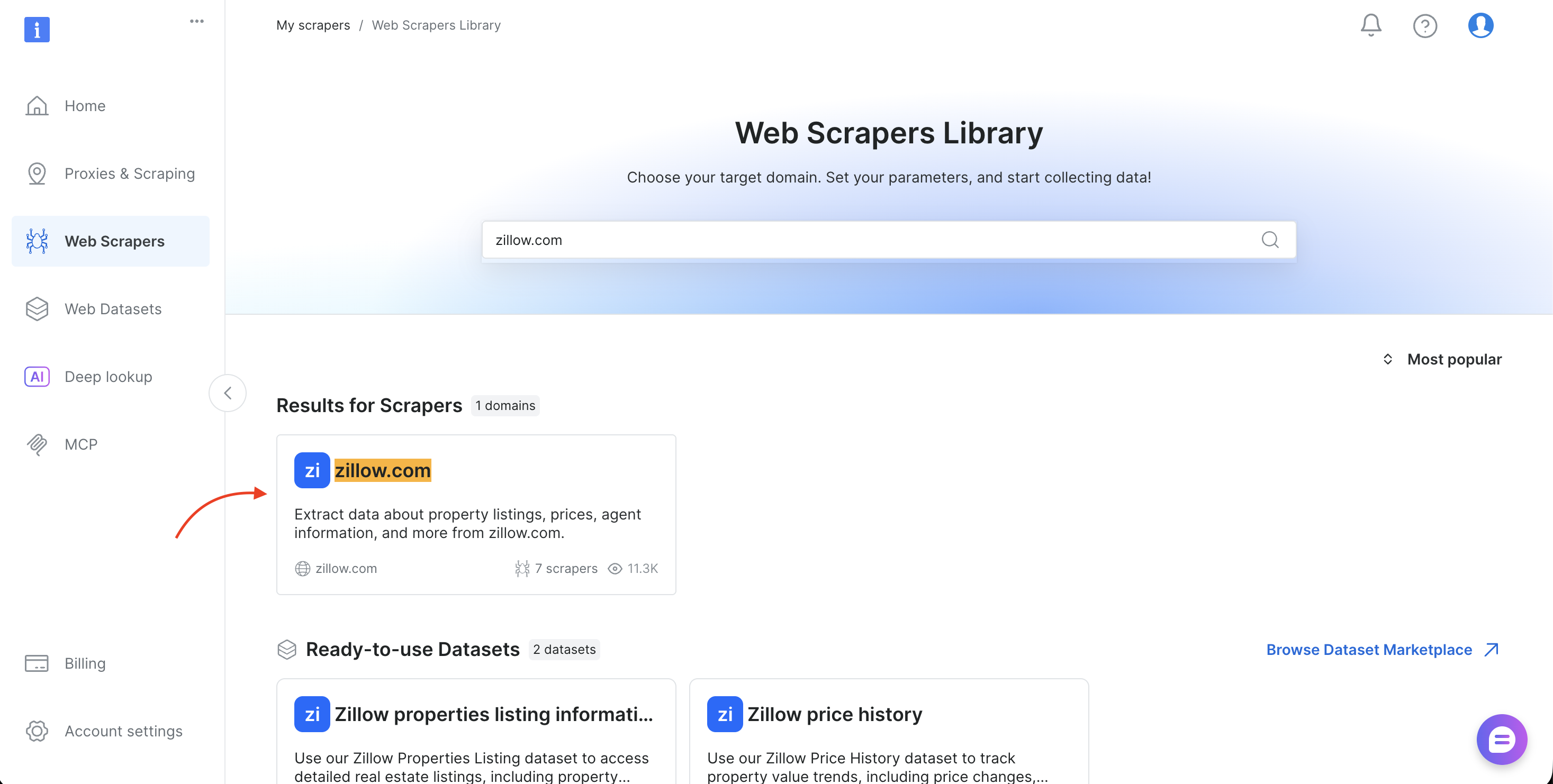
- Choisissez la méthode de collecte (Collecter par URL ou Découvrir par mot-clé)
- Copiez
l'identifiant du jeu de donnéesdans la barre d’adresse du navigateur (par exemple,brightdata.com/cp/scrapers/gd_lfqkr8wm13ixtbd8f5) ou dans le panneau « Code examples »
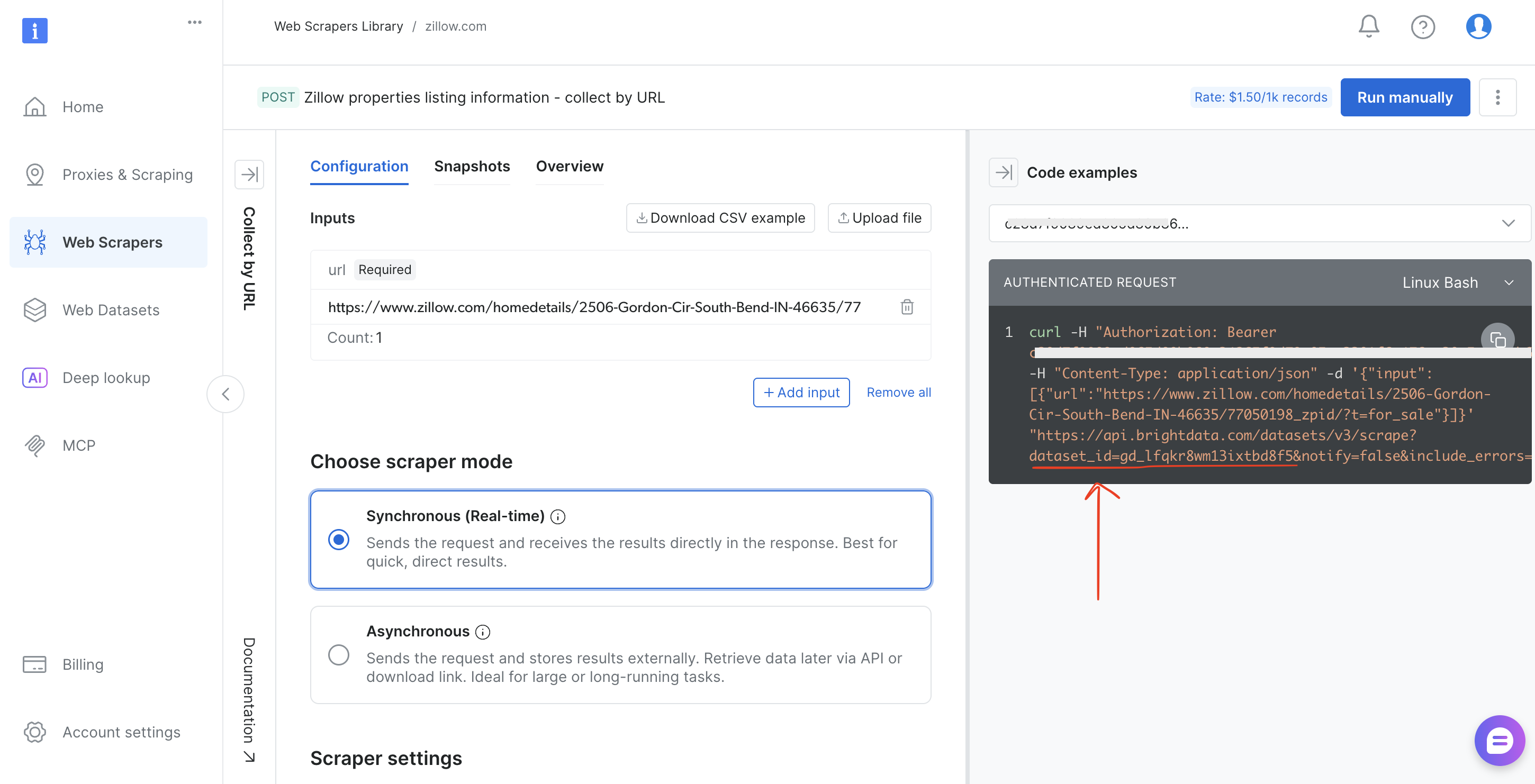
Remplacez DATASET_ID dans le script, ajustez la charge utile, et ce même pipeline fonctionne pour n’importe lequel des plus de 120 Scrapers de Bright Data.
Résultats concrets : à quoi ressemblent les données extraites
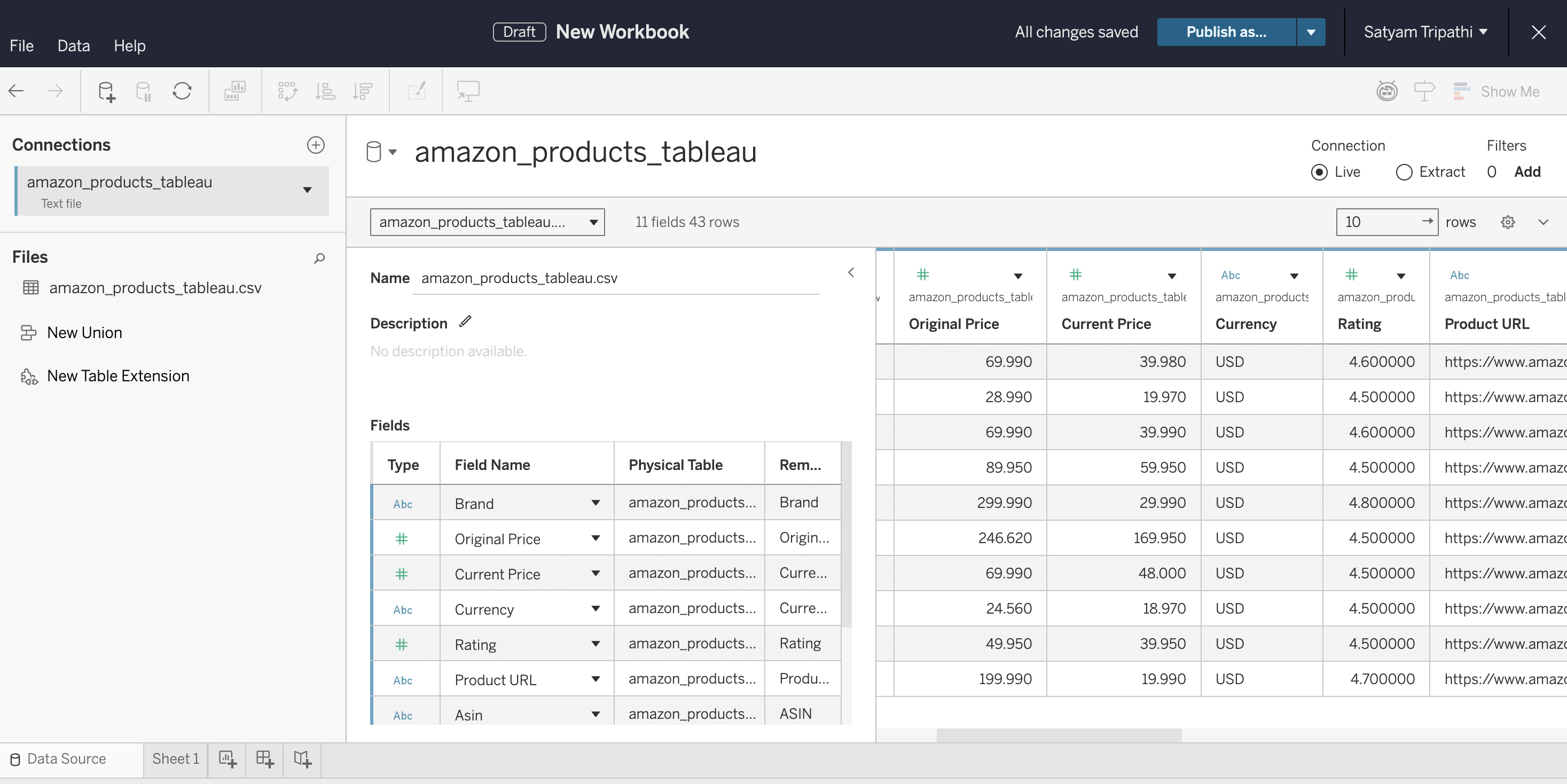
La capture d’écran suivante montre le fichier CSV brut généré par le pipeline, soit exactement ce que l’API de Bright Data a renvoyé pour le mot-clé « wireless headphones » :
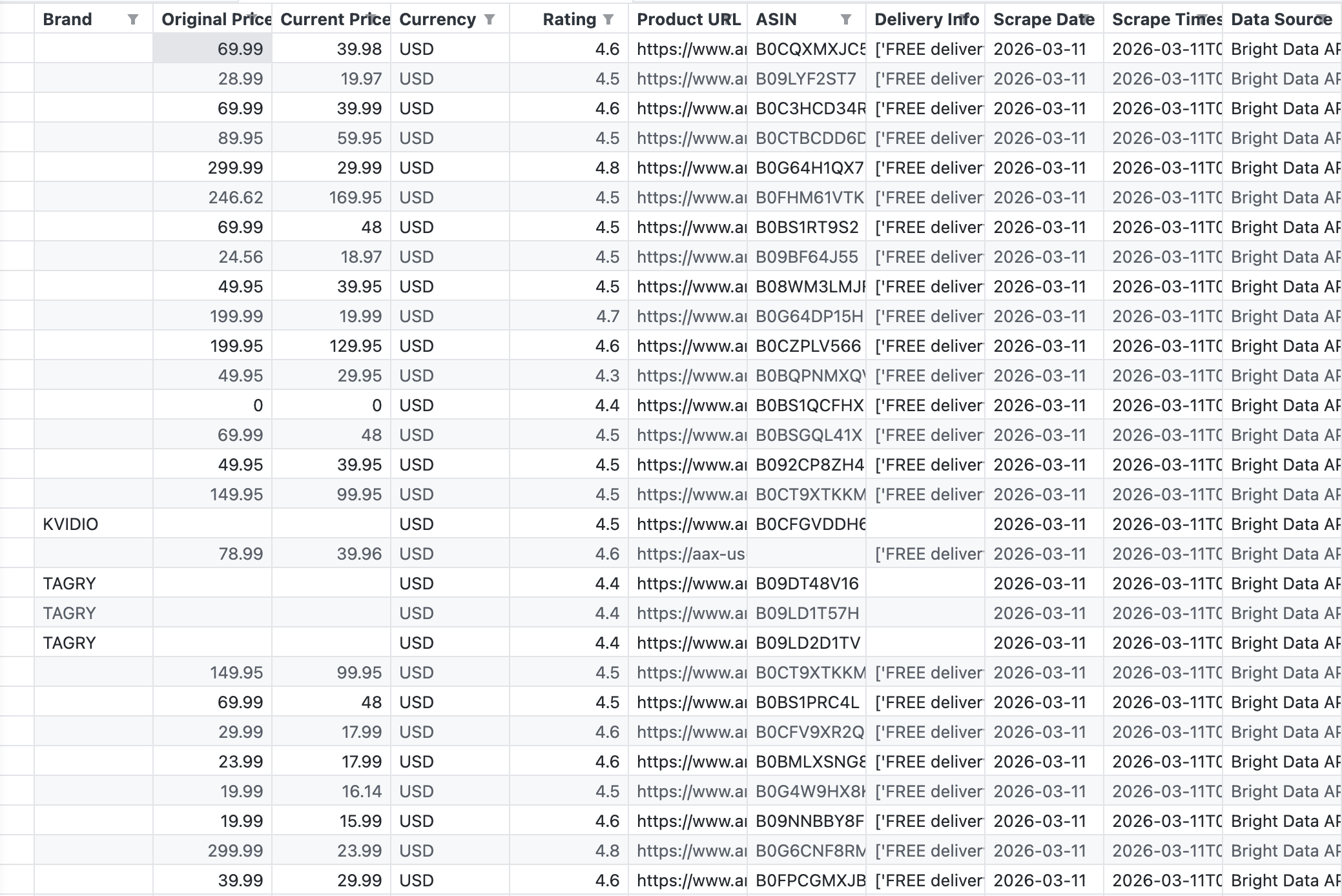
L’API a renvoyé 43 enregistrements avec des champs tels que Marque, Prix d'origine, Prix actuel, Note, ASIN, URL du produit et Informations de livraison.
L’API a renvoyé 43 produits en un seul appel. Les données sont structurées et prêtes à être utilisées dans Tableau. Pas d’analyse HTML, pas de sélecteurs défectueux, pas de défis CAPTCHA. Pour plus de détails sur les options de scraping d’Amazon, consultez Comment extraire les données sur les produits Amazon.
Visualisation des données : du CSV aux informations
Ces quatre visualisations montrent ce que produit le pipeline. Chaque vue est construite à partir du fichier CSV exact généré par le script :
Répartition des prix entre les produits
Ce graphique classe 31 produits (ceux dont les noms peuvent être analysés à partir de leurs URL Amazon) par prix actuel, du plus bas au plus élevé :
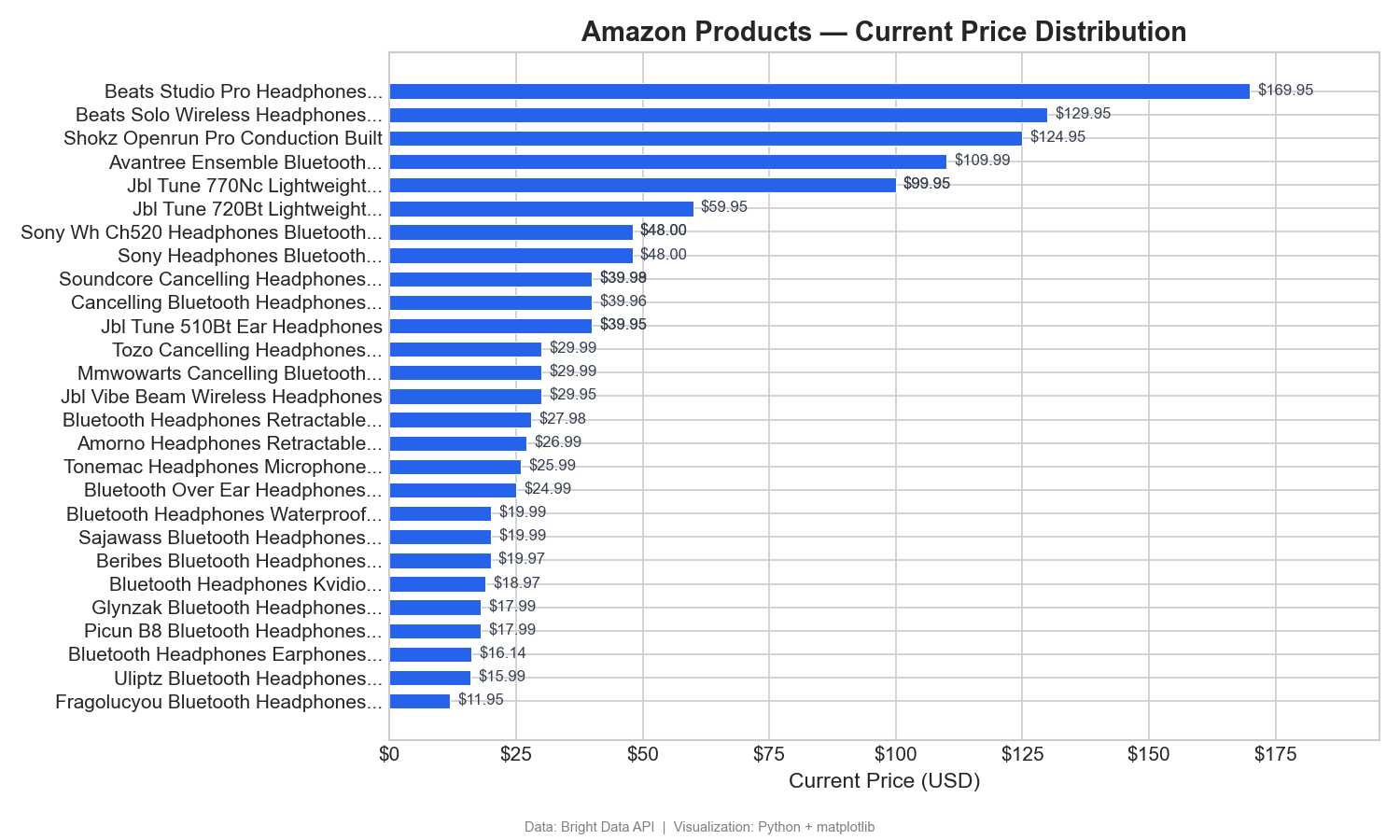
Ce graphique à barres horizontales montre clairement la fourchette de prix : Beats domine le segment haut de gamme (125–170 $), tandis que la plupart des casques sans fil se situent dans la fourchette 12–60 $. Dans Tableau, vous créeriez cela sous la forme d’un graphique à barres trié avec le prix actuel dans les colonnes et le nom du produit dans les lignes.
Baisse des prix : prix d’origine vs prix actuel
Ce graphique à barres groupées compare les prix affichés et les prix actuels des 10 produits les plus soldés :
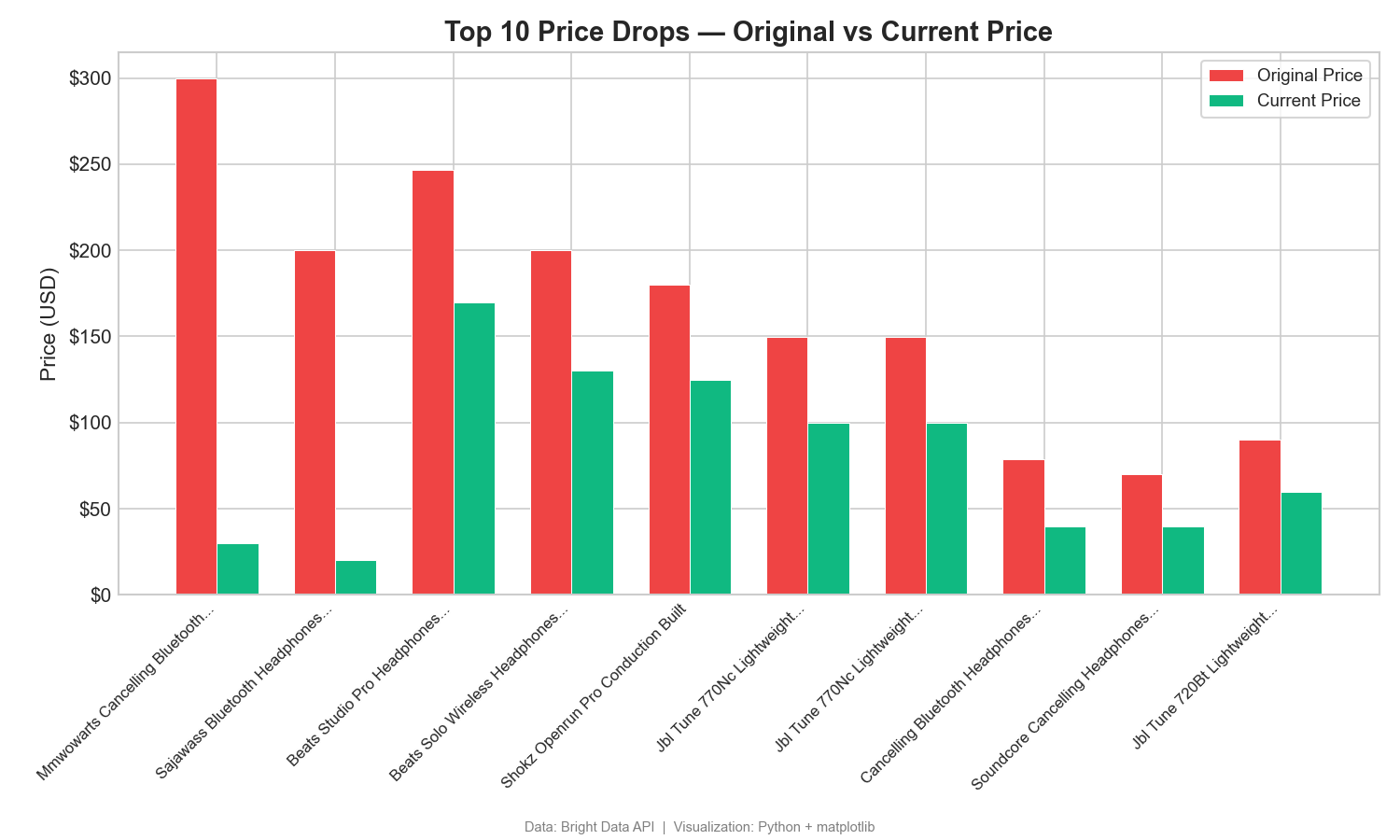
L’écart entre le prix d’origine et le prix actuel met en évidence d’importantes réductions. Un produit affiche une baisse de 270 $ par rapport à son prix d’origine (299,99 $ → 29,99 $). De tels écarts reflètent les stratégies promotionnelles et tarifaires. Dans Tableau, utilisez un graphique à barres côte à côte avec les noms de mesures sur la couleur.
Note vs prix : déterminer la valeur
Ce nuage de points met en correspondance les notes des clients et les prix afin d’identifier les produits à forte valeur ajoutée :
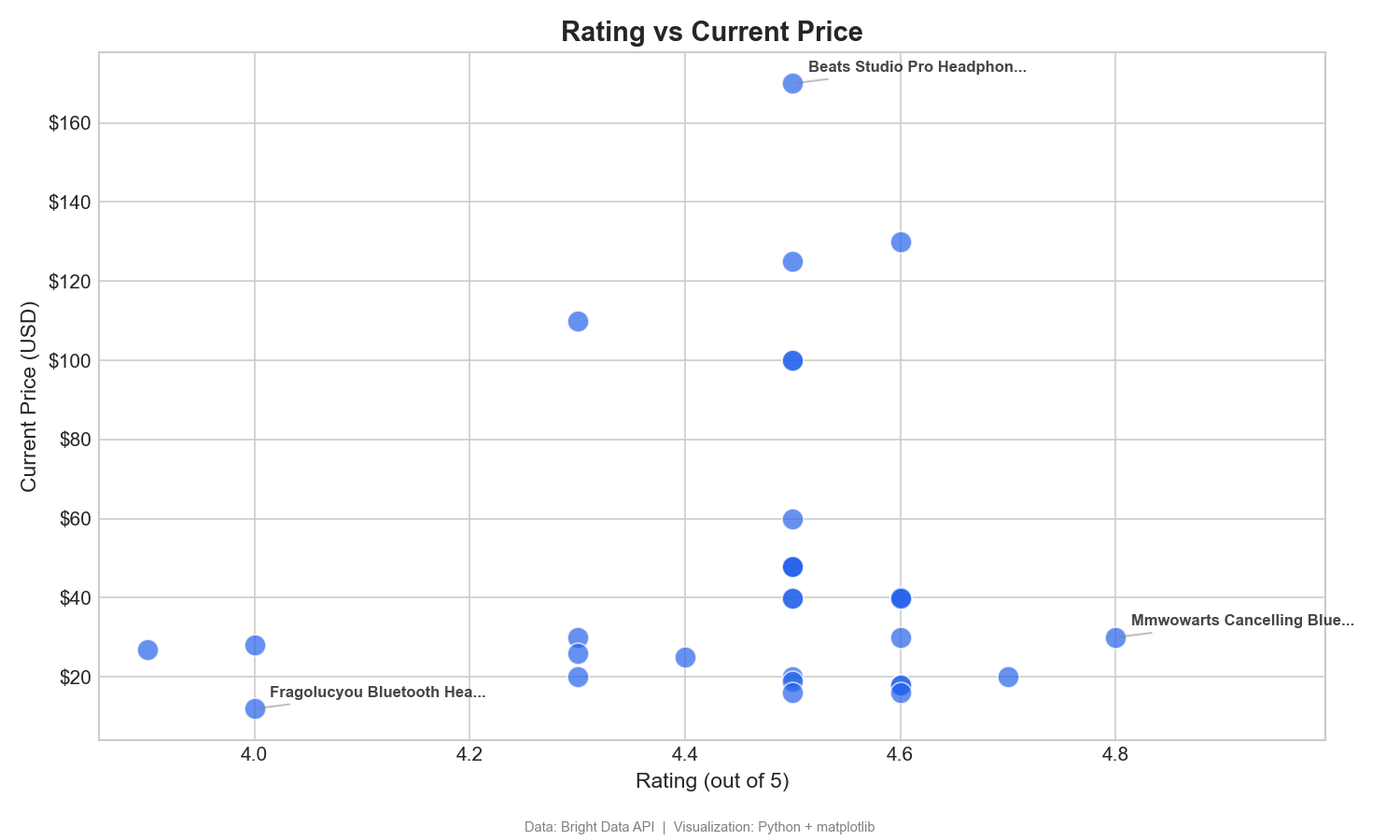
Ce nuage de points permet d’identifier les produits à forte valeur ajoutée, c’est-à-dire ceux qui ont des notes élevées et des prix bas (quadrant inférieur droit). Le casque MMWOWARTS à 29,99 $ avec une note de 4,8 en est un exemple clair. Dans Tableau, faites glisser « Note » vers les colonnes, « Prix actuel » vers les lignes et « Nom du produit » vers les détails.
Segmentation du marché par fourchette de prix
Ce graphique en anneau répartit les produits par fourchette de prix :
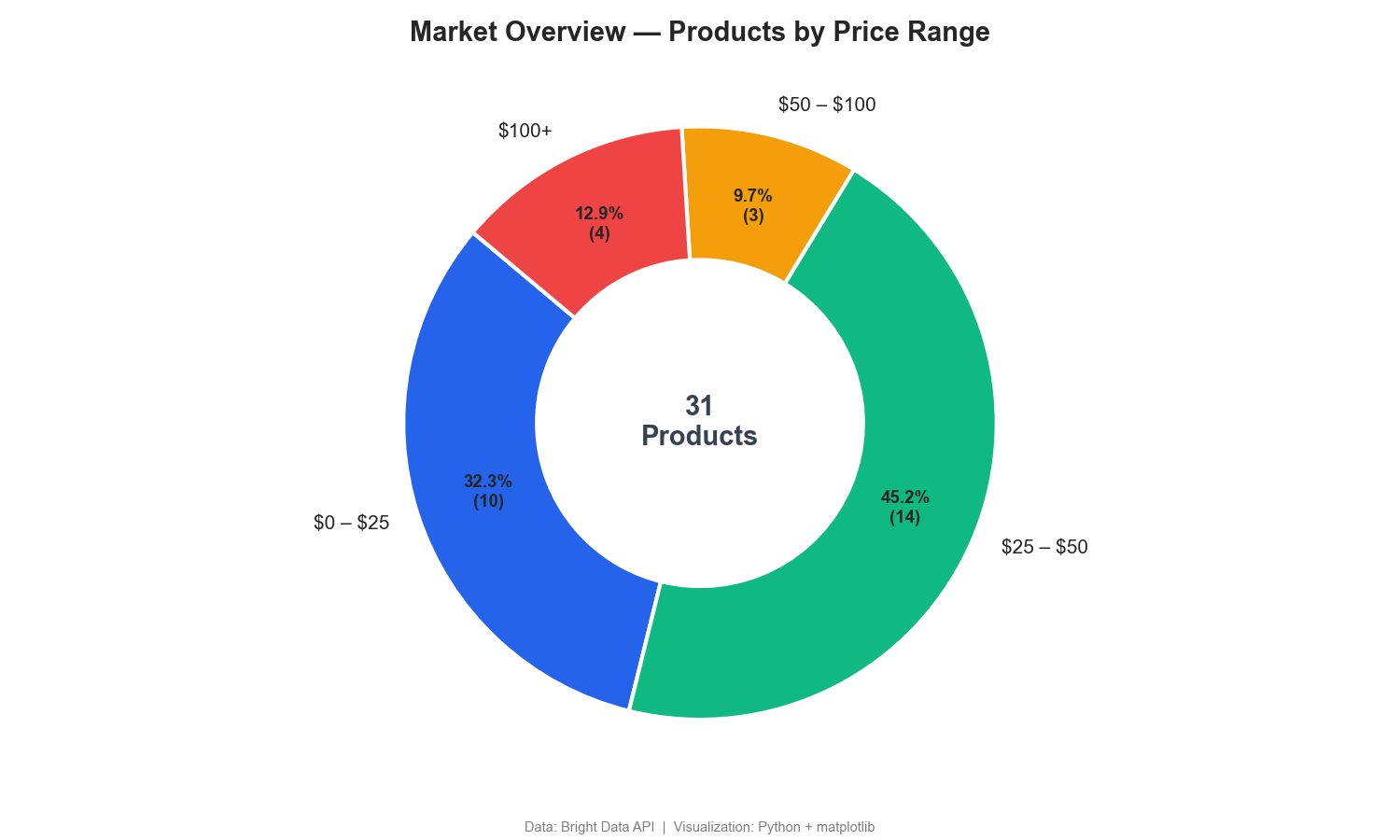
Le graphique en anneau montre que 77 % des casques sans fil se vendent à moins de 50 $, tandis que seulement 13 % se situent dans le segment haut de gamme à plus de 100 $. Les tableaux de bord de Surveillance des prix des concurrents incluent souvent une segmentation similaire.
Bonus : pipeline immobilier avec Zillow
Le même modèle de pipeline fonctionne avec n’importe lequel des plus de 120 Scrapers de Bright Data. L’exemple suivant utilise l’API Zillow Scraper (référentiel GitHub). Mettez à jour deux variables dans bright_data_to_tableau.py et le reste du pipeline s’exécute sans modification :
# Remplacez l'ID du jeu de données Amazon par l'ID du jeu de données Zillow
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Propriétés ZillowMettez ensuite à jour la charge utile dans trigger_collection() pour utiliser une URL de localisation à la place d’un mot-clé :
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]Exécutez le script de la même manière. La logique d’interrogation et d’exportation CSV fonctionne sans modification.
Les champs Zillow comprennent : l’adresse du bien, le prix, le nombre de chambres, le nombre de salles de bains, la superficie, la taille du terrain, l’année de construction, le type de bien, le statut de l’annonce et le Zestimate.
Idées de tableaux de bord Tableau :
- Carte thermique du prix au m² par code postal
- Analyse des écarts entre le prix de l’annonce et le Zestimate
- Répartition des types de logements par ville ou code postal
- Diagramme de dispersion année de construction/prix pour identifier les opportunités de rénovation
L’avantage principal : vous apprenez le modèle une fois, puis vous l’appliquez à n’importe quelle source de données. Amazon, Zillow, les offres d’emploi LinkedIn : tous utilisent la même infrastructure Bright Data pour envoyer des données vers les tableaux de bord Tableau.
Les 6 principaux cas d’utilisation des données Web en temps réel dans Tableau
Voici les raisons les plus courantes pour lesquelles les équipes intègrent des pipelines de données Web dans Tableau.
1. Surveillance des prix des concurrents
Suivez les prix de la concurrence sur Amazon, Walmart, Target ou toute autre plateforme de commerce électronique. Créez des tableaux de bord Tableau qui affichent les fluctuations quotidiennes des prix, les tendances historiques et le positionnement tarifaire sur votre marché. Configurez des alertes lorsque les concurrents descendent en dessous de votre prix minimum.
Surveillez des milliers de références sur plusieurs places de marché grâce aux plus de 120 Scrapers prêts à l’emploi de Bright Data. Aucun Scraper personnalisé n’est nécessaire.
Vues Tableau : graphiques en cascade des prix, tendances chronologiques par référence, cartes thermiques des prix des concurrents.
2. Suivi de la marque sur les réseaux sociaux
Extrayez les mentions, les indicateurs d’engagement, le nombre d’abonnés et les données de commentaires depuis Instagram, Twitter/X, TikTok et LinkedIn. Créez des tableaux de bord qui suivent la visibilité de la marque sur toutes les plateformes et mesurent les performances des campagnes au fil du temps. Le Navigateur de scraping gère les plateformes sociales riches en JavaScript que les requêtes HTTP standard ne peuvent pas afficher.
Vues Tableau : tendances du taux d’engagement, volume de mentions au fil du temps, graphiques à barres comparatifs entre plateformes.
3. Analyse du marché de l’emploi
Agrégation des offres d’emploi provenant d’Indeed, de Glassdoor, de LinkedIn (référentiel GitHub) et de sites d’emploi spécialisés. Analyse des tendances de recrutement, des références salariales, des compétences requises et des évolutions de la demande selon les secteurs et les zones géographiques. Les équipes RH et les recruteurs utilisent ces tableaux de bord pour comparer les rémunérations et identifier les évolutions du marché des talents avant leurs concurrents.
Vues Tableau : cartes géographiques à bulles des postes à pourvoir, histogrammes de répartition des salaires, treemaps de la demande de compétences.
4. Tableaux de bord immobiliers
Suivez les annonces immobilières, les variations de prix, les niveaux de stock et les tendances des quartiers à partir de Zillow, Realtor.com, Redfin et Airbnb. Les investisseurs et analystes immobiliers créent des cartes thermiques géographiques dans Tableau pour identifier les marchés sous-évalués et suivre les tendances des rendements locatifs dans différentes villes.
Vues Tableau : cartes thermiques par code postal, nuages de points représentant le prix au m², séries chronologiques du volume d’annonces.
5. Flux de données financières
Collectez les cours boursiers, les rapports sur les résultats, les notations des analystes, les données sur les délits d’initiés et les actualités financières provenant de Yahoo Finance, Bloomberg et d’autres plateformes financières. Les analystes quantitatifs et les gestionnaires de portefeuille créent des tableaux de bord financiers avec actualisation automatique des données pour suivre la performance des portefeuilles et les signaux du marché.
Vues Tableau : graphiques de cours de type chandeliers, graphiques à barres sur les surprises de résultats, tableaux de bord de rotation sectorielle.
6. Suivi de la chaîne d’approvisionnement
Suivez la disponibilité des produits, les estimations de livraison, les niveaux de stock des vendeurs et les prix sur les places de marché mondiales. Les équipes opérationnelles créent des tableaux de bord Tableau qui détectent les perturbations de l’approvisionnement, telles que les ruptures de stock soudaines ou les pics de délais de livraison, avant qu’elles n’affectent le reste de la chaîne d’approvisionnement.
Vues Tableau : matrices de disponibilité, courbes de tendance des délais de livraison, tableaux de bord de notation des risques fournisseurs.
Chacun de ces cas d’utilisation suit la même architecture : API Bright Data → Données structurées → Tableau de bord Tableau. Les seuls éléments qui changent sont l’ID du jeu de données et les visualisations Tableau que vous créez.
Fonctionnement du pipeline de l’API Bright Data
Le script du tutoriel gère le déclenchement et l’interrogation. Voici ce qui se passe tout au long du pipeline, de l’appel de l’API au tableau de bord Tableau.
Flux de données étape par étape
- Déclenchement. Votre script Python envoie une requête POST au point de terminaison
/triggerde Bright Data. Incluez soit un mot-clé (pour la découverte), soit une liste d’URL (pour la collecte ciblée). L’API renvoie immédiatement unsnapshot_id. - Collecte. L’infrastructure de Bright Data achemine les requêtes via plus de 150 millions de Proxys résidentiels. Elle gère automatiquement les défis CAPTCHA, exécute le JavaScript si nécessaire et réessaie les requêtes ayant échoué.
- Analyse. Bright Data analyse le code HTML brut pour le transformer en champs de données structurés. Pour les produits Amazon, cela peut inclure le titre, le prix, la note, les avis, les informations sur le vendeur et la disponibilité – bien que les champs exacts renvoyés dépendent des Jeux de données et du type de recherche.
- Instantané. Une fois la collecte et l’analyse terminées, Bright Data stocke les données sous forme d’instantané. Votre script interroge le point de terminaison
/snapshotjusqu’à ce que le statut passe de202 (traitement en cours)à200 (prêt). - Livraison. Vous récupérez l’instantané au format JSON ou CSV. Vous pouvez également configurer la livraison vers Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP ou un webhook. La livraison automatique est utile pour les pipelines de production qui stockent les données dans un entrepôt.
- Transformation. Votre script (ou un outil tel que pandas) renomme les colonnes, filtre les champs et formate les données pour qu’elles puissent être lues par Tableau. C’est à ce stade que vous ajoutez des colonnes de métadonnées telles que la date de collecte et la source des données.
- Visualisation. Tableau lit le fichier de sortie (ou se connecte à une base de données si vous y avez chargé les données) et affiche votre tableau de bord avec les données les plus récentes.
Mise à l’échelle du pipeline
Pour une utilisation en production, envisagez les améliorations suivantes :
- Mots-clés multiples. Parcourez une liste de mots-clés ou de catégories de produits dans votre script pour créer des Jeux de données complets.
- Stockage en base de données. Au lieu du format CSV, enregistrez les données dans PostgreSQL ou MySQL. Tableau se connecte nativement à ces deux bases, et les données historiques s’accumulent au fil du temps pour permettre l’analyse des tendances.
- Orchestration. Utilisez Apache Airflow, Prefect ou une tâche cron pour planifier des exécutions à la fréquence requise par votre entreprise (toutes les heures, tous les jours, toutes les semaines).
- Livraison via webhook. Évitez complètement l’interrogation en configurant Bright Data pour qu’il envoie les résultats à votre serveur via une requête POST dès qu’ils sont prêts.
Liste de contrôle de production
Avant de déployer le pipeline dans un environnement de production, traitez les points opérationnels suivants :
- Gestion des erreurs. Encadrez les appels API dans des blocs try/except avec une logique de réessai. Consignez les échecs dans un fichier ou un service de surveillance afin de détecter rapidement les données obsolètes.
- Déduplication des données. Ajoutez une clé unique (telle que l’ASIN + la date de collecte) et dédupliquez les données avant de les charger dans Tableau. Les lignes en double faussent les agrégations.
- Validation du schéma. Vérifiez que la réponse de l’API contient les champs attendus avant d’écrire dans un fichier CSV. Les modifications apportées au site web peuvent altérer la structure des données sans avertissement.
- Surveillance et alertes. Configurez des alertes (e-mail, Slack ou PagerDuty) en cas d’échecs d’exécution, de Jeux de données vides ou de baisses inattendues du nombre de lignes.
- Sauvegardes des données. Archivez chaque instantané CSV avec un horodatage. Si un scraping défectueux corrompt votre fichier de travail, revenez à la version précédente.
Pourquoi choisir Bright Data pour les pipelines Tableau
Pour les workflows Tableau en production, les facteurs suivants sont importants :
- Livraison flexible. Obtenez les résultats au format JSON, CSV ou NDJSON via API, webhook, Amazon S3, Google Cloud, Azure ou SFTP. Chargez les données dans votre entrepôt de données Tableau.
- Sur mesure ou prêts à l’emploi. Utilisez Serverless Functions pour créer des scrapers personnalisés, Scraper Studio pour créer des scrapers générés par l’IA, ou utilisez des Jeux de données prêts à l’emploi pour un accès instantané sans écrire de code.
- Rentabilité. Payez 1,50 $ par 1 000 enregistrements en paiement à l’utilisation, avec des remises sur volume pouvant aller jusqu’à 0,75 $/1 000 pour les niveaux supérieurs.
Construisez votre pipeline de données Web en temps réel
L’écart entre les données disponibles et les données requises ne cesse de se creuser, en particulier lorsque ces données se trouvent sur le Web ouvert sans API ni connecteur.
WDC v2 est obsolète et n’est plus pris en charge. Google Sheets atteint ses limites de cellules. Excel nécessite un travail manuel. TabPy ne prend pas en charge la rotation des proxys. Les scripts DIY tombent en panne à grande échelle.
L’API Web Scraper de Bright Data fournit la couche d’infrastructure qui fait défaut à ces approches. L’API comprend plus de 120 Scrapers prêts à l’emploi, plus de 150 millions de Proxys répartis dans 195 pays, la Résolution de CAPTCHA automatique et une sortie de données structurées dans des formats pris en charge nativement par Tableau. Les tarifs commencent à 1,50 $ pour 1 000 enregistrements, avec une disponibilité de 99,99 % et une conformité totale au RGPD, au CCPA et à la norme ISO 27001.
Au lieu de mettre en place une infrastructure de collecte de données, concentrez-vous sur la création de tableaux de bord.
Commencez votre essai gratuit →
Foire aux questions
Tableau WDC est-il obsolète ?
Oui. Le Web Data Connector v2 de Tableau a été officiellement abandonné dans la version 2023.1. Tableau 2022.4, la dernière version à prendre en charge WDC v2, a atteint sa fin de vie. Les connecteurs WDC v2 ne sont plus pris en charge dans aucune version actuelle de Tableau et pourraient être supprimés lors d’une future mise à jour.
Qu’est-ce qui a remplacé Tableau WDC ?
Tableau a publié WDC v3, mais celui-ci est réservé à l’extraction et n’est pas pris en charge par Tableau Bridge. Pour les données Web en temps réel, un pipeline d’API de scraping (Bright Data → CSV/JSON → Tableau) constitue une alternative pratique. Le tutoriel de ce guide explique comment créer ce pipeline.
Tableau peut-il se connecter directement à une API de Scraping web ?
Pas en natif. Tableau se connecte à des bases de données, des fichiers et des services cloud spécifiques. Pour utiliser une API de scraping, vous avez besoin d’un script léger en Python ou Node.js qui appelle l’API et reçoit les données. Le script génère ensuite un format lisible par Tableau : CSV, JSON ou une insertion dans une base de données.
Comment maintenir à jour les données de mon tableau de bord Tableau ?
Planifiez votre script de collecte de données à l’aide de cron (Linux/Mac), du Planificateur de tâches (Windows) ou d’un orchestrateur de flux de travail tel qu’Apache Airflow. Le script extrait les données les plus récentes de l’API de Bright Data et écrase le fichier CSV. Tableau charge les données mises à jour lors de son prochain cycle d’actualisation.
Combien coûte le chargement de données Web dans Tableau ?
L’API Web Scraper de Bright Data est proposée à partir de 1,50 $ pour 1 000 enregistrements en paiement à l’utilisation, avec des remises sur volume pouvant aller jusqu’à 0,75 $/1 000. Pour un tableau de bord de veille concurrentielle type suivant 5 000 produits par jour, cela représente environ 7,50 $/jour ou ~225 $/mois.
Quels formats de données Bright Data fournit-il pour Tableau ?
Bright Data fournit des données au format JSON, CSV ou NDJSON via l’API. Pour Tableau, le format CSV est l’option la plus directe. Tableau le lit en natif sans qu’aucune transformation ne soit nécessaire. Vous pouvez également configurer la livraison automatique vers Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP ou un webhook pour les pipelines de production.
Puis-je utiliser Bright Data avec Tableau Public ?
Oui. Bright Data génère des fichiers CSV standard que Tableau Public lit en natif. La limitation vient de Tableau Public : il ne prend pas en charge les actualisations programmées pour les sources basées sur des fichiers. Vous devez réexécuter votre script de collecte de données et republier le classeur à chaque mise à jour des données.





