

Dans cet article, vous verrez :
- Ce qu’est la plateforme xpander.ai et ce qu’elle offre pour la construction d’agents d’IA.
- Pourquoi les agents d’intelligence artificielle doivent avoir accès au web pour être vraiment efficaces.
- Comment intégrer les outils intégrés de Bright Data dans un agent xpander.ai pour lui donner une fonctionnalité de web scraping.
Plongeons dans l’aventure !
Qu’est-ce que xpander.ai ?
Xpander.ai est une plateforme Backend-as-a-Service pour la création d’agents d’intelligence artificielle autonomes. Il s’agit d’une solution sans code conçue pour aider les développeurs d’entreprise à construire, tester et déployer efficacement des agents d’IA. Elle s’accompagne également d’un SDK open-source permettant de programmer la création et l’exécution d’agents d’IA.
La plateforme fournit un environnement visuel permettant de définir des flux de travail multi-agents et de collaborer. Elle vous permet également d’attacher des outils et de les intégrer aux systèmes de l’entreprise. De plus, vous pouvez simuler et tester le comportement des agents avant de les mettre en service.
Les principales caractéristiques sont les suivantes :
- Système de graphe d’agent: Garantit une exécution fiable des agents en plusieurs étapes.
- Connecteurs agentiques: Permet aux agents de se connecter à divers systèmes et API tiers.
L’importance des données Web fraîches pour des agents d’IA précis
Quelle que soit la plateforme, la bibliothèque ou l’outil de construction d’agents d’IA que vous choisissez, il existe une limitation fondamentale. En effet, les LLM ne peuvent exécuter des tâches et répondre à des questions qu’en fonction des données sur lesquelles ils ont été formés. Il s’agit d’un obstacle majeur lors de la construction d’agents d’IA, qui sont censés effectuer des actions dépassant les capacités statiques d’un LLM typique.
Ainsi, pour être plus précis, plus opérationnels et plus efficaces, les agents d’IA doivent avoir accès au web. Ils doivent pouvoir lire les pages web et utiliser leur contenu pour fonder leurs réponses et leurs décisions. Après tout, le web est l’une des sources de données les plus riches et les plus récentes.
Toutefois, il ne suffit pas d’avoir accès au web. La plupart des sites mettent en œuvre des mesures anti-scraping et anti-bot pour bloquer les robots d’exploration de l’IA. Cela signifie que vos agents ont besoin d’outils puissants qui leur permettent d’extraire des données des pages web, dans un format optimisé pour le traitement par l’IA.
C’est précisément ce que l ‘infrastructure d’IA de Bright Data – disponibledans xpander.ai via des connecteurs intégrés – est conçue pour offrir. Parmi ses nombreuses fonctionnalités, elle permet à vos agents d’IA sans code d’extraire des données fraîches de plus de 50 plateformes populaires au format JSON structuré.
Bright Data se charge de gérer les CAPTCHA, les interdictions d’IP, les limites de taux, etc. Combiné au constructeur d’agents d’IA xpander.ai, vous pouvez intégrer tout cela sans écrire une seule ligne de code. Le résultat ? Un agent d’IA prêt pour la production avec un accès en temps réel à des données web fiables !
Comment intégrer le connecteur de données Bright pour construire un agent d’extraction xpander.ai ?
Dans ce guide, vous apprendrez à construire un agent d’IA dans xpander.ai. Plus précisément, vous utiliserez le connecteur Bright Data pour donner à votre agent la possibilité de récupérer des données sur le web.
Nous montrerons comment créer un agent de scraping web qui peut fonder ses réponses en récupérant des données en direct sur Internet. Ce n’est qu’un exemple de ce qui est possible avec l’intégration xpander.ai + Bright Data. Vous pouvez facilement adapter cette approche à de nombreux autres cas d’utilisation.
Remarque: dans un sens, cet exemple fonctionne comme un flux de travail agentique RAG. En effet, le connecteur Bright Data joue le rôle de composant d’extraction, en récupérant des données actualisées que l’agent peut utiliser.
Suivez les étapes ci-dessous pour créer votre agent de scraping d’IA sans code dans xpander !
Conditions préalables
Pour reproduire ce tutoriel, vous avez besoin des éléments suivants :
- Un compte xpander.ai : Un compte gratuit est suffisant pour les tests simples. Pour des cas d’utilisation plus avancés, vous aurez besoin d’un plan payant.
- Une clé API Bright Data: vous pouvez en créer une gratuitement, comme expliqué dans le guide officiel.
Si vous ne les avez pas encore, cliquez sur les liens ci-dessus et suivez les instructions d’installation. C’est parti !
Étape 1 : Créer un nouvel agent
Connectez-vous à xpander.ai et accédez au tableau de bord de votre profil. Cliquez sur “Agent” dans le menu de gauche, puis appuyez sur le bouton “Nouvel agent” pour ajouter un nouvel agent :
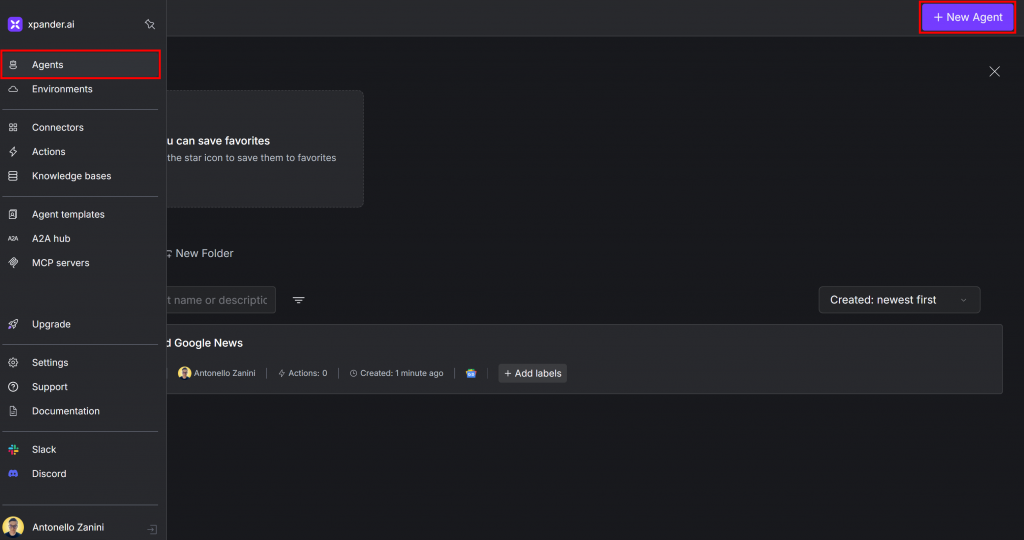
Vous arriverez à la page suivante, avec un formulaire où vous pouvez configurer votre nouvel agent. Donnez-lui un nom comme “Web Scraper Agent” :

Laissez tous les autres paramètres de l’onglet “Général” tels quels. Les valeurs par défaut sont suffisantes pour une configuration simple comme celle-ci. Par défaut, xpander.ai utilisera le GPT-4o d’OpenAI comme modèle LLM.
C’est parfait ! Vous avez maintenant un nouvel agent IA vierge prêt dans xpander.ai.
Étape 2 : Configurer les outils Bright Data pour le Web Scraping
À l’heure actuelle, votre agent ne peut effectuer que les actions proposées par le fournisseur LLM sélectionné. Il est temps de le doter de capacités de scraping web grâce à Bright Data.
Pour ce faire, allez dans l’onglet “Outils” de la page de votre agent, puis cliquez sur le bouton “Ajouter des outils” :
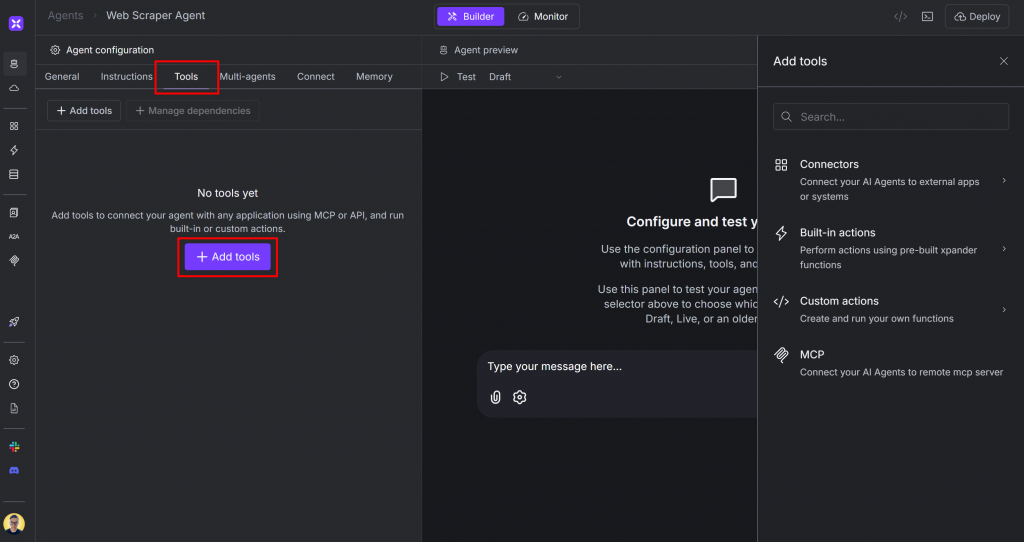
Un panneau intitulé “Add tools” (Ajouter des outils) apparaît sur la droite. Recherchez “bright data” et sélectionnez l’intégration Bright Data :
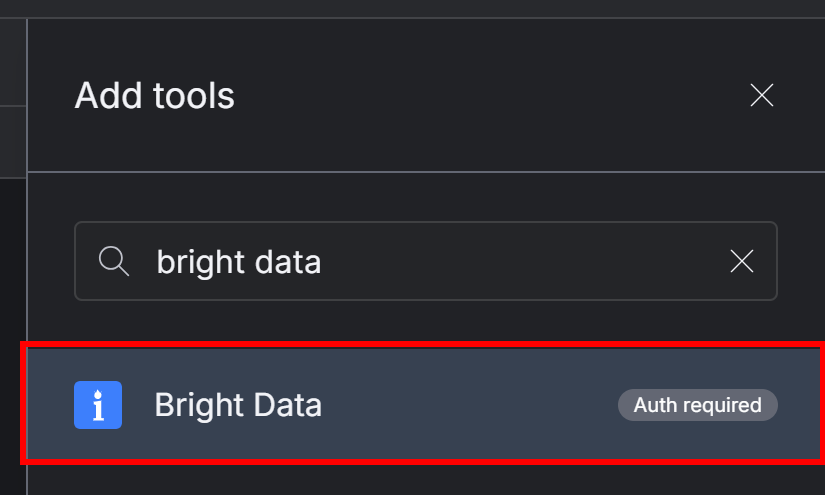
La fenêtre modale suivante s’affiche :
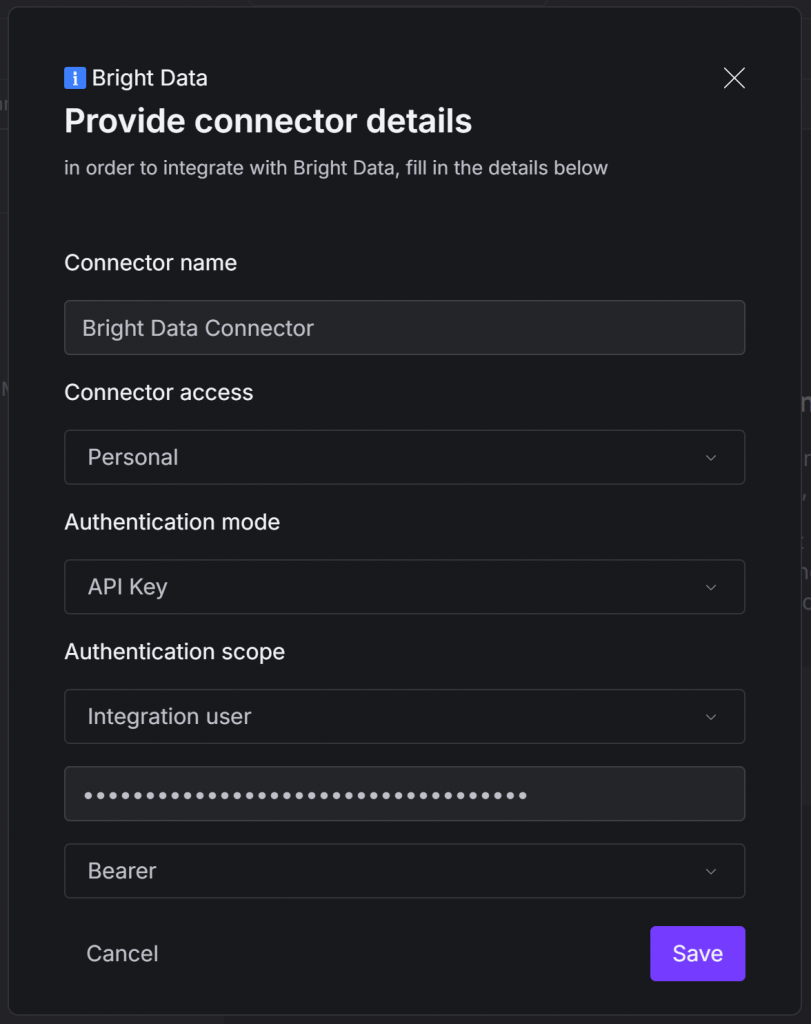
Remplissez-le comme suit :
- Nom du connecteur: donnez un nom à votre connecteur Bright Data (par exemple, ” Bright Data Connector “).
- Mode d’authentification: Sélectionnez l’option “API Key”.
- Portée de l’authentification:
- Sélectionnez l’option “Utilisateur d’intégration”.
- Collez votre clé API Bright Data.
- Sélectionnez l’option “Bearer”. La clé de l’API sera transmise dans l’en-tête
Authorizationvia le motifBearer, qui est une méthode d’authentification prise en charge par les API de Bright Data.
Une fois que tout est rempli, appuyez sur le bouton “Enregistrer”.
Vous serez alors invité à sélectionner les outils Bright Data spécifiques que vous souhaitez activer dans votre agent :
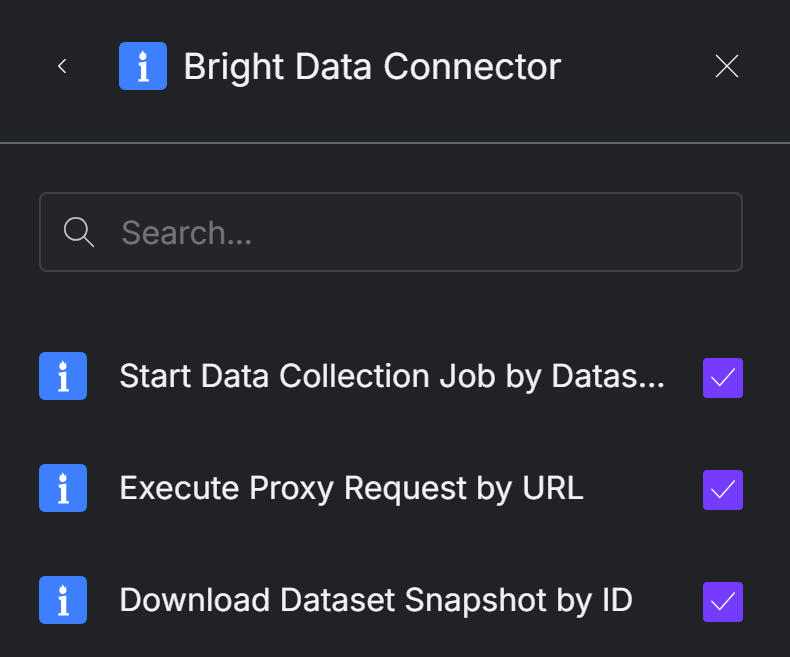
Nous vous recommandons de sélectionner tous les outils afin de bénéficier de toutes les fonctionnalités du web scraping. À l’heure où nous écrivons ces lignes, les outils disponibles sont les suivants :
- Lancer un travail de collecte de données par ID de jeu de données: Lance un travail de scraping pour un jeu de données spécifié à l’aide des API Web Scraper.
- Exécuter une requête proxy par URL: Envoie une requête HTTP via le réseau proxy de Bright Data pour accéder au contenu de n’importe quelle page web.
- Télécharger un instantané d’un ensemble de données par ID: Télécharge un instantané d’un ensemble de données dans différents formats et transmet les données à l’IA.
Une fois que vous avez sélectionné les outils souhaités, cliquez sur le bouton “Ajouter à l’agent” dans le coin inférieur droit :

L’onglet “Outils” de votre agent affichera désormais le connecteur Bright Data avec les outils que vous avez configurés :
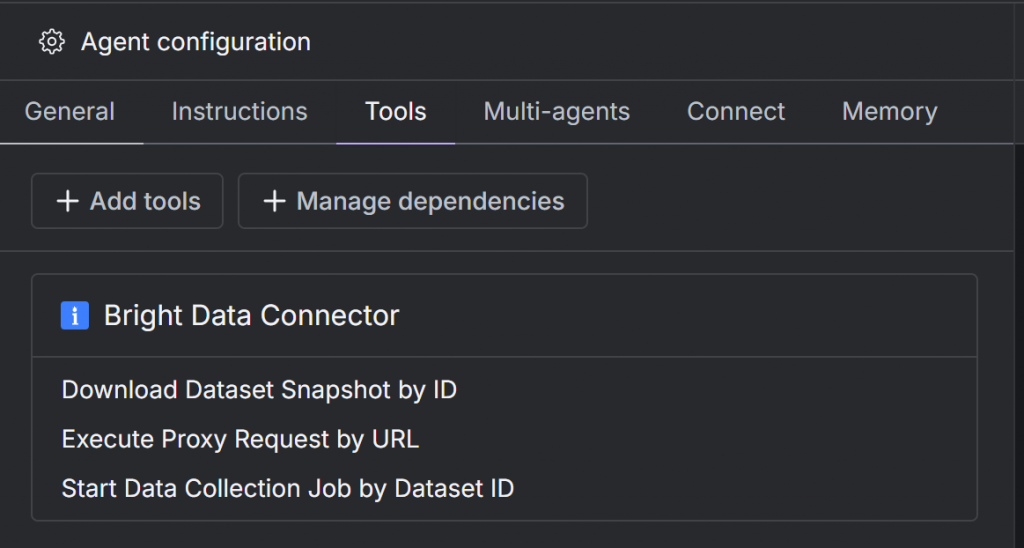
Notez que vous pouvez cliquer sur n’importe quel outil pour afficher ou ajuster sa configuration.
Fantastique ! Votre agent d’intelligence artificielle est désormais entièrement intégré aux outils Bright Data et prêt à explorer le web.
Étape 3 : Spécialiser votre agent d’extraction d’IA
Maintenant que votre agent a accès aux outils Bright Data pour l’exploration du Web, donnez-lui une invite système personnalisée. Celle-ci indique à l’agent ce qu’il est et comment il doit fonctionner.
Pour ce faire, cliquez sur l’onglet “Instructions” et collez le texte suivant dans la zone de texte “Invite système” :
You are an AI agent capable of grounding your responses by scraping data from the web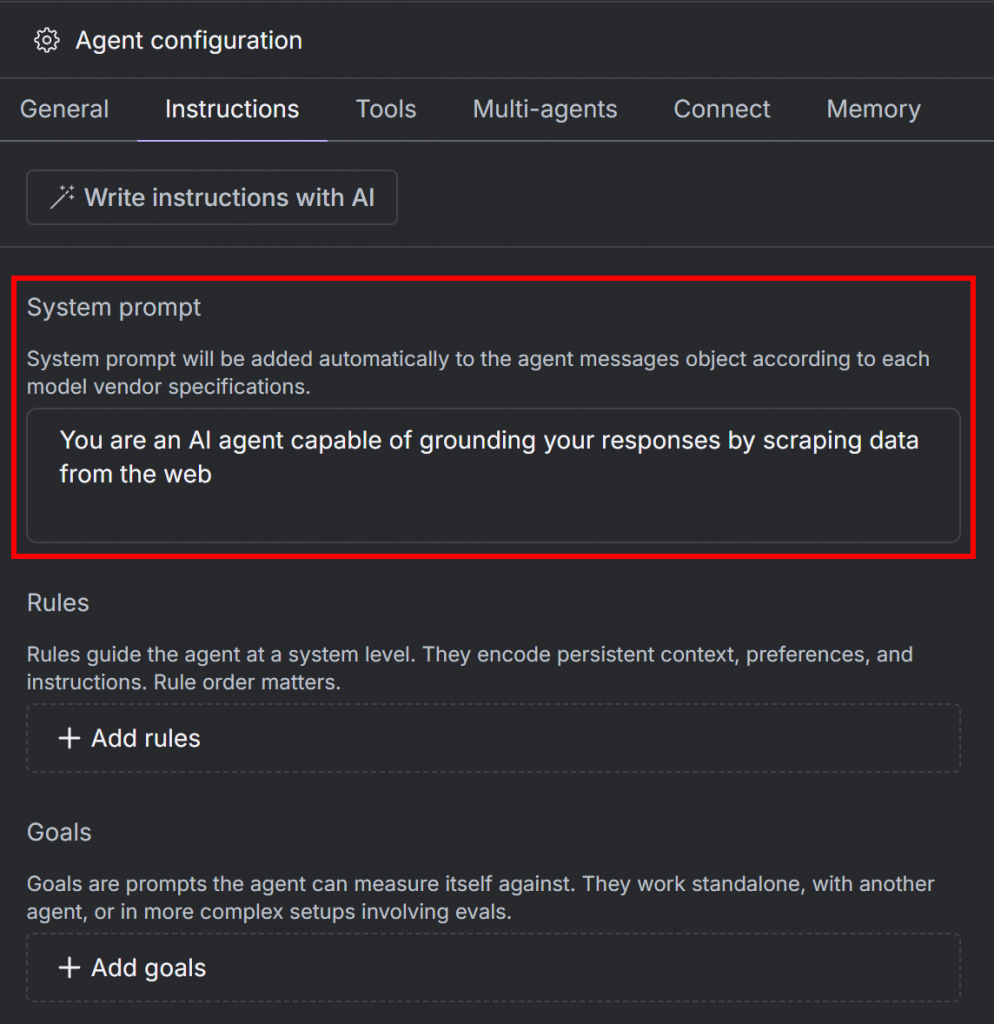
Pour les agents plus spécialisés, vous pouvez également ajouter des règles et des objectifs personnalisés.
C’est incroyable ! Votre agent racleur xpander est prêt.
Étape 4 : Assembler le tout
Cliquez sur le bouton “Graphique de l’agent” pour visualiser le flux de travail actuel de l’agent d’IA :
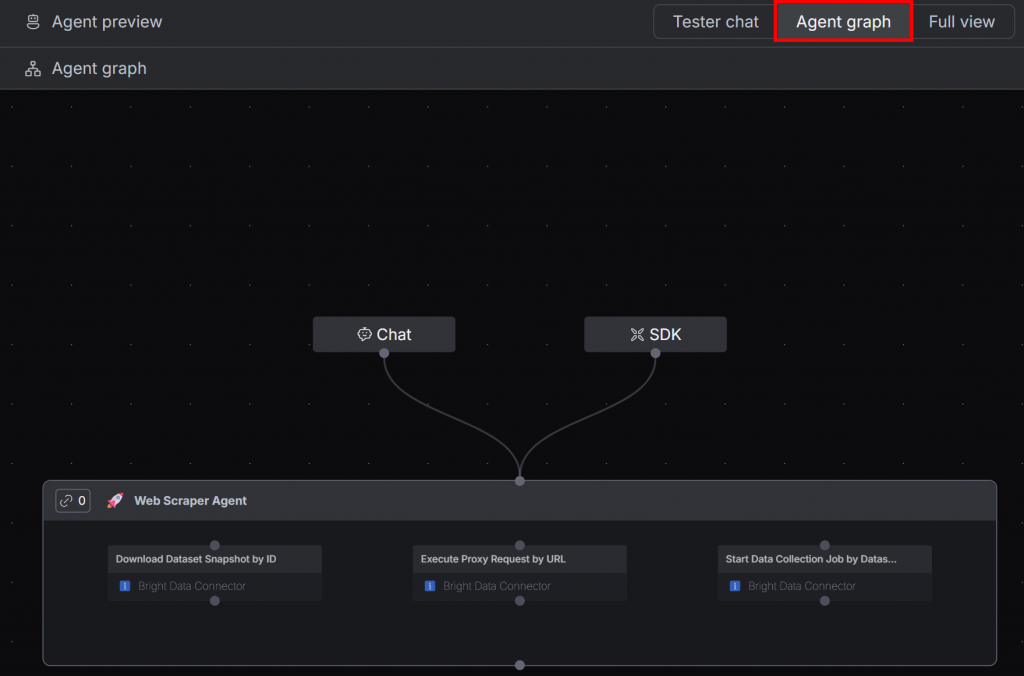
Vous verrez un agent unique ayant accès aux trois outils Bright Data configurés pour l’exploration du Web.
C’est fait ! Il ne reste plus qu’à tester l’agent et à le voir à l’œuvre.
Étape 5 : Tester l’agent Web Scraper
Retournez à l’onglet “Tester Chat” et essayez votre agent avec une invite comme celle-ci :
Search for top 3 headphones under $100 and provide me info from their PDP'sCela demande à votre agent de scraping web de rechercher dynamiquement en ligne les trois meilleurs casques d’écoute vendus à moins de 100 $ et de récupérer des informations directement à partir de leurs pages détaillées de produits (PDP).
Comme vous pouvez l’imaginer, un LLM standard serait capable de gérer ce type de tâche sans avoir accès à des outils de scraping dédiés tels que ceux fournis par Bright Data.
Collez l’invite dans l’entrée du chat et envoyez-la à votre agent :
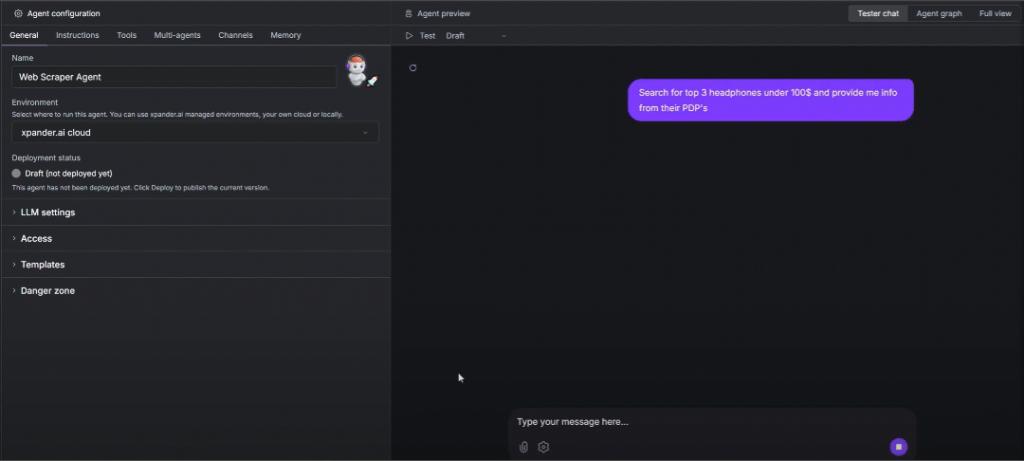
L’agent utilise les outils LLM et Bright Data pour :
- Effectuez une recherche sur le web et trouvez les trois premiers écouteurs.
- Pour chaque produit, lancez une tâche de collecte de données et téléchargez les données d’Amazon.
- Résumez les informations dans une réponse courte et précise, accompagnée de liens réels vers les pages détaillées des produits Amazon.
Si vous développez l’une des sections d’outils dans l’interface, vous verrez quelque chose comme ceci :
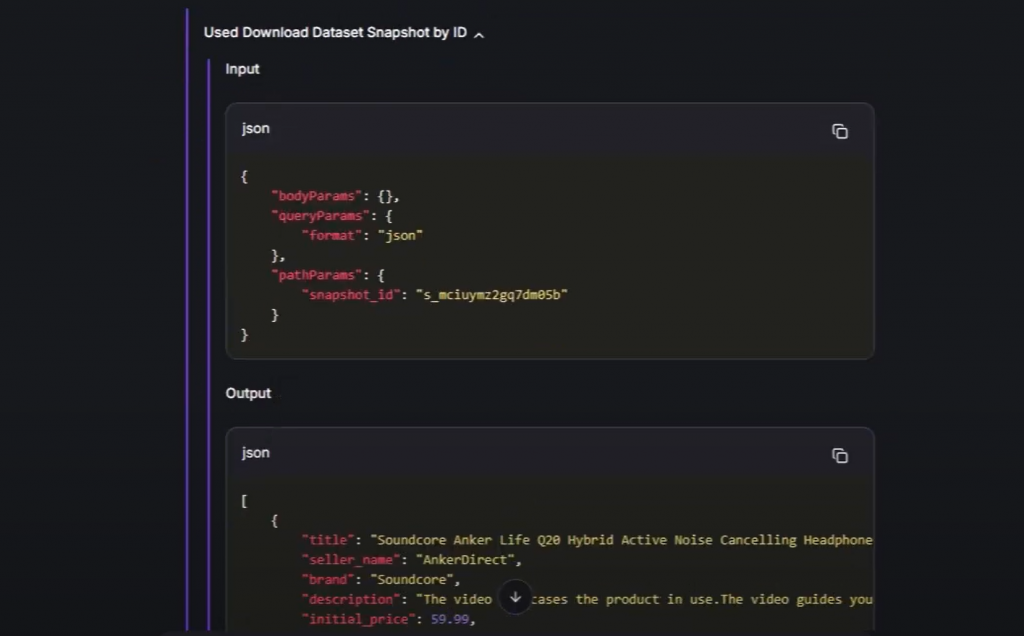
Cela prouve qu’en coulisses, l’agent d’IA a automatiquement détecté les outils Bright Data à utiliser pour mener à bien la tâche. En détail, il les a appelés avec les bons paramètres pour récupérer des données fraîches (dans ce cas, directement à partir des pages de produits Amazon).
Et voilà ! Vous disposez désormais d’un agent de scraping entièrement fonctionnel sur xpander.ai, alimenté par l’infrastructure de données d’IA de Bright Data.
Prochaines étapes
Maintenant que vous avez mis en place un agent de raclage xpander alimenté par Bright-Data, vous pouvez.. :
- Déployez votre agent: Exécutez votre agent d’IA directement sur la plateforme xpander.ai, ou déployez-le sur votre propre infrastructure pour un meilleur contrôle.
- Appelez votre agent via l’API avec le
XpanderClient: Utilisez le SDK xpander pour gérer les agents et accéder aux fonctions utilitaires pour travailler avec les réponses LLM. - Explorez les ateliers officiels de xpander: Participez à des ateliers pratiques qui vous guideront dans la création de solutions complètes d’agents d’IA à l’aide de la plateforme xpander.ai.
Conclusion
Dans cet article, vous avez appris à utiliser xpander.ai pour construire un agent de scraping d’IA sans code. Cela a été rendu possible grâce au connecteur Bright Data, qui expose des outils de scraping avancés pour l’intégration dans les agents xpander.
Il ne s’agit là que d’un exemple simple, mais il se peut que vous souhaitiez créer des agents d’intelligence artificielle plus sophistiqués. Pour cela, vous avez besoin de solutions fiables pour récupérer, valider et transformer le contenu Web. C’est exactement ce que vous trouverez dans l’infrastructure d’agents d’IA de Bright Data.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à explorer nos outils de données prêts pour l’IA !




