

Dans cet article, vous apprendrez :
- Ce que sont les compétences Bright Data.
- Pourquoi elles sont utiles et comment elles soutiennent les agents et assistants de codage IA.
- Quelles compétences spécifiques elles offrent pour la recherche web, le scraping, et plus encore.
- Comment les installer dans votre configuration d’agent IA via
skills, le CLI Bright Data, ou manuellement. - Comment en tirer le meilleur parti avec des exemples de prompts pratiques.
Plongeons dans le vif du sujet !
Que sont les compétences Bright Data ?
Les compétences Bright Data permettent à votre agent de codage IA d’acquérir une connaissance des produits et services de Bright Data.
Ces compétences suivent la spécification standard Agent Skills définie par Anthropic et sont prises en charge par plus de 40 solutions de codage IA. En essence, les compétences sont des dossiers structurés contenant des instructions, des scripts et des ressources que les agents peuvent découvrir et utiliser pour effectuer des tâches avec plus de précision et d’efficacité.
En détail, comme le montre le dépôt GitHub officiel, les compétences Bright Data ont cette structure de dossiers :
skills/
├── scrape/
│ ├── SKILL.md # Instructions + metadata loaded by the agent
│ └── scripts/
│ └── search.sh # Executable script that the agent can run
│
├── # other skills...
│
├── bright-data-mcp/
│ ├── SKILL.md
│ └── references/ # MCP tool reference docs
└── bright-data-best-practices/
├── SKILL.md # API selection guide + auth patterns + code examples
└── references/
├── web-unlocker.md # Full Web Unlocker API reference
├── serp-api.md # Full SERP API reference
├── scrapers.md # Full Web Scraping APIs reference
└── browser-api.md # Browser API referenceComme vous pouvez le constater, les compétences dotent votre agent de bonnes pratiques, de connaissances sur les paramètres et de scripts shell exécutables pour se connecter aux solutions de Bright Data.
À un niveau général, les compétences Bright Data permettent à votre agent de codage d’accéder aux données web via le Scraping web, de récupérer des flux de données depuis des domaines populaires, d’effectuer des recherches, d’interagir avec des pages web, et bien plus encore.
La nécessité de l’accès web dans les agents de codage
Peu importe la puissance du LLM derrière votre agent de codage IA, il est confronté à une limitation fondamentale partagée par tous les modèles de langage : des connaissances obsolètes. Un LLM ne peut générer des réponses qu’en fonction des données sur lesquelles il a été entraîné, ce qui représente un instantané figé dans le temps.
Étant donné la rapidité avec laquelle le paysage technologique évolue, cela devient un problème significatif. Il est courant que les LLM suggèrent des pratiques de codage obsolètes, s’appuient sur des méthodes dépréciées, ou ratent entièrement les fonctionnalités nouvellement publiées.
Pour surmonter cette limitation, étendez votre agent de codage IA avec un accès web en temps réel. C’est exactement ce que les compétences Bright Data fournissent. Une fois intégrées, votre agent peut :
- Identifier la bonne API pour la recherche, le scraping ou l’extraction de données structurées.
- S’authentifier et structurer correctement les requêtes lors de la connexion aux API Bright Data.
- Gérer efficacement la pagination, les erreurs et les cas limites.
- Exécuter de vrais scripts shell pour effectuer des actions telles que la recherche web et le scraping.
Grâce à elles, l’agent devient capable de manière autonome :
- De découvrir des informations à jour depuis les bonnes sources en ligne, telles que les pages de documentation, Stack Overflow et les forums.
- De récupérer des données web réelles pour enrichir vos scripts (par exemple, lors du remplissage de bases de données ou de la simulation de réponses).
- De suggérer des liens pertinents pour des lectures complémentaires ou pour enrichir vos fichiers
README.md. - De gérer de nombreux autres cas d’usage réels.
Ce qui rend Bright Data spécial, c’est que ses produits sont construits sur une infrastructure réseau robuste soutenue par plus de 400 IPs résidentielles proxy. Cela permet une scalabilité illimitée tout en atteignant 99,99 % de disponibilité et un taux de succès de 99,95 %.
N’oubliez pas que les compétences Bright Data font partie de l’écosystème ouvert Agent Skills et sont prises en charge par plus de 40 assistants de codage IA.
Compétences Bright Data : liste complète
Explorez toutes les compétences Bright Data dans le tableau suivant :
| Compétence | Description | Produit Bright Data |
|---|---|---|
search |
Recherchez sur Google et obtenez des résultats JSON structurés avec titres, liens et descriptions. Prend en charge la pagination via l’API SERP Bright Data. | API SERP |
scrape |
Scrapez n’importe quelle page web en markdown propre avec contournement automatique de la détection de bots, Résolution de CAPTCHA et rendu JavaScript via l’API Web Unlocker. | API Web Unlocker |
data-feeds |
Extrayez des données structurées de plus de 40 sites web dont Amazon, LinkedIn, Instagram, TikTok, YouTube, eBay et Walmart avec interrogation automatique. | APIs de Scraping web |
bright-data-mcp |
Orchestrez les plus de 60 outils MCP Bright Data pour la recherche, le scraping, l’extraction structurée et l’automatisation du navigateur. | Web MCP |
scraper-builder |
Guide les agents pour créer des Scrapers prêts pour la production, couvrant l’analyse du site, la sélection d’API, l’extraction de sélecteurs, la pagination et l’implémentation complète. | API Web Scraper/SDK Python |
bright-data-best-practices |
Référence intégrée pour Web Unlocker, l’API SERP, l’API Scraper et l’API Browser. Claude la consulte automatiquement lors de la génération de code Bright Data. | , |
python-sdk-best-practices |
Guide pour le package Python brightdata-sdk, incluant les clients async/sync, les Scrapers, SERP, les Jeux de données, l’API Browser, la gestion des erreurs et les modèles de codage courants. |
SDK Python |
brightdata-cli |
Instructions pour utiliser le CLI Bright Data pour scraper, rechercher, extraire des données, gérer les Proxys et surveiller l’utilisation du compte directement depuis le terminal. | CLI Bright Data |
competitive-intel |
Fournit une Intelligence compétitive en temps réel avec des instantanés concurrentiels, des comparaisons de prix, de l’exploration d’avis, des signaux de recrutement, du contenu, des insights SEO et une cartographie du marché. | CLI Bright Data |
design-mirror |
Réplique les modèles de système de design, les tokens et les composants pour aider à construire des interfaces utilisateur cohérentes et de haute qualité. | API Web Unlocker |
brd-browser-debug |
Déboguez les sessions du Navigateur de scraping Bright Data avec le triage des échecs, le suivi de la Bande passante par session, le signalement de CAPTCHA et la détection de modèles via l’API Browser Sessions. | API Browser |
Important : Pour en savoir plus sur chaque compétence, consultez le dépôt officiel. Pensez également à soutenir le projet et à rester informé en laissant une étoile !
Comment ajouter des compétences Bright Data aux agents et assistants de codage
Chaque agent de codage peut charger les compétences différemment, mais il existe des moyens de simplifier le processus d’installation. Les trois principales approches pour ajouter les compétences Bright Data sont :
- Via l’outil Vercel
skills(recommandé) :skillsest un CLI développé par Vercel pour installer et gérer les compétences. Il fournit une configuration guidée et prend en charge plus de 40 frameworks d’agents IA. - Via le CLI Bright Data : Inclut des commandes dédiées pour simplifier l’installation et la configuration des compétences dans les outils de codage IA pris en charge.
- Via la configuration manuelle : Copiez les dossiers de compétences Bright Data dans le répertoire requis par votre agent de codage IA.
Les deux premières approches sont guidées et automatisées, ce qui les rend plus faciles à utiliser mais offrant moins de contrôle. L’approche manuelle demande plus d’efforts mais vous donne un contrôle total sur la configuration.
Dans les sections suivantes, vous verrez comment utiliser chaque méthode dans Claude Code ! (Remarque : Les mêmes instructions fonctionneront également pour tout autre agent de codage IA prenant en charge les compétences.)
Prérequis communs
Quelle que soit l’approche choisie pour ajouter des compétences Bright Data à votre agent de codage IA, il y a quelques étapes communes à suivre. Passons-les en revue !
Exigences
Pour que les compétences Bright Data fonctionnent dans votre agent IA choisi, vous devez avoir :
- Un système d’exploitation basé sur Unix capable d’exécuter des scripts
.sh(Linux, macOS, ou WSL). - Un compte Bright Data avec les Zones requises et une clé API configurée. (Vous serez guidé à travers cela à l’étape suivante.)
- L’accès à l’un des 40+ agents IA qui prennent en charge Agent Skills.
- Le package
jqinstallé localement.
Pour installer jq (un outil de traitement JSON, similaire à sed) sur les systèmes basés sur Debian, exécutez :
sudo apt-get install curl jqOu, de manière équivalente, sur macOS :
brew install curl jqConfigurer votre compte Bright Data
Les scripts Shell utilisés par les compétences Bright Data nécessitent ces deux variables d’environnement :
BRIGHTDATA_API_KEY: Utilisée pour authentifier les requêtes HTTP vers l’infrastructure API Bright Data.BRIGHTDATA_UNLOCKER_ZONE: Utilisée pour se connecter à votre Zone API Web Unlocker Bright Data, qui active les capacités de Scraping web (ainsi que la recherche web, car elle peut également agir comme une API SERP).
En termes simples, pour commencer, vous avez besoin d’un compte Bright Data, d’une Zone API Web Unlocker et d’une clé API. Cette section vous guidera à travers leur configuration.
Pour une configuration rapide, référez-vous au guide “Créer votre première API Unlocker” dans la documentation. Alternativement, suivez les instructions ci-dessous.
Si vous n’avez pas de compte Bright Data, créez-en un. Sinon, connectez-vous simplement. Accédez au panneau de contrôle, naviguez vers la page « Proxies & Scraping » et vérifiez le tableau « My Zones » :
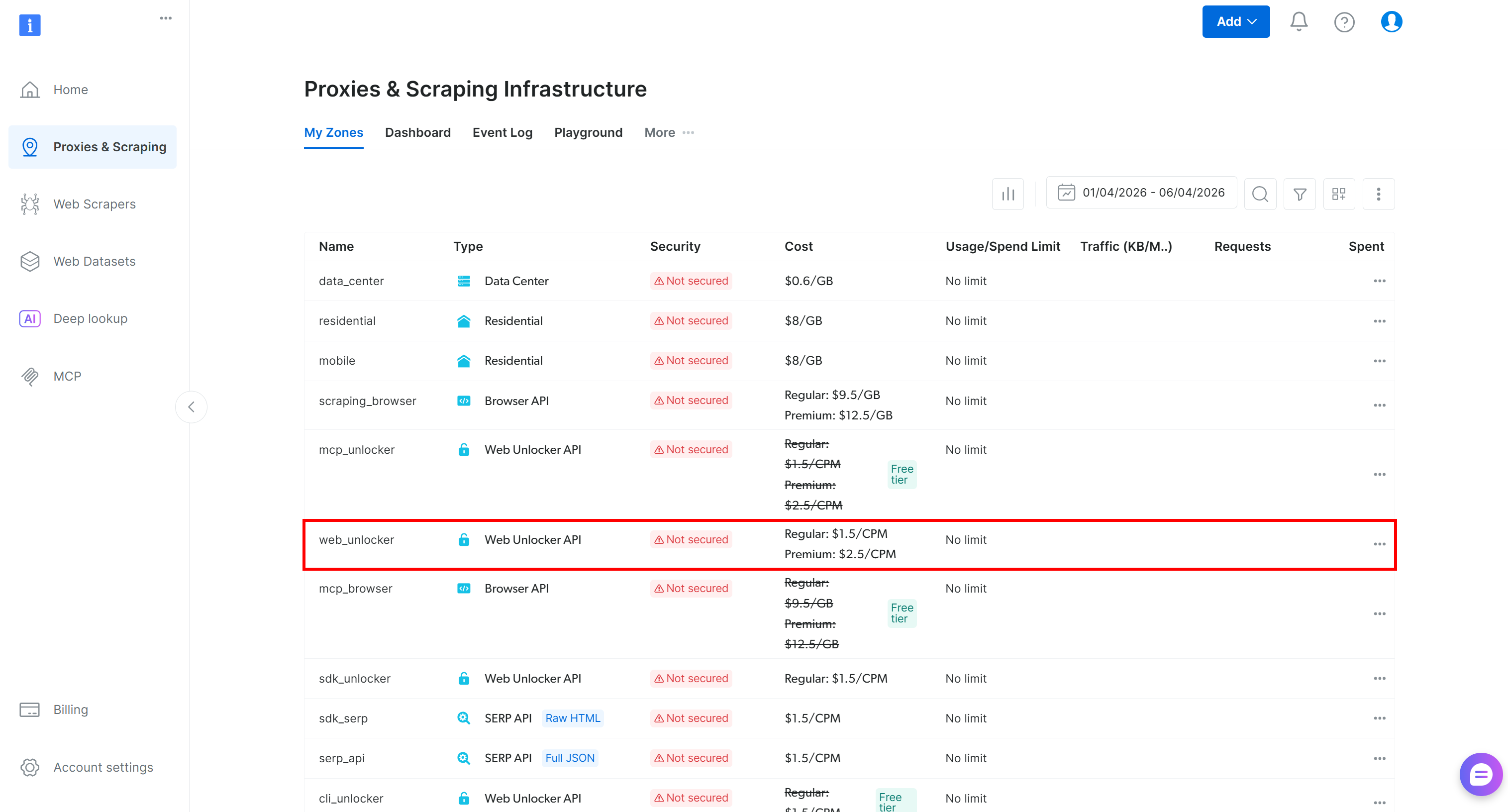
Si une Zone API Web Unlocker (par exemple, web_unlocker, dans ce cas) existe déjà, vous êtes prêt à passer à la création de la clé API.
Si elle n’existe pas, créez-en une. Faites défiler jusqu’à la section « Unblocker API », cliquez sur le bouton « Create zone » :
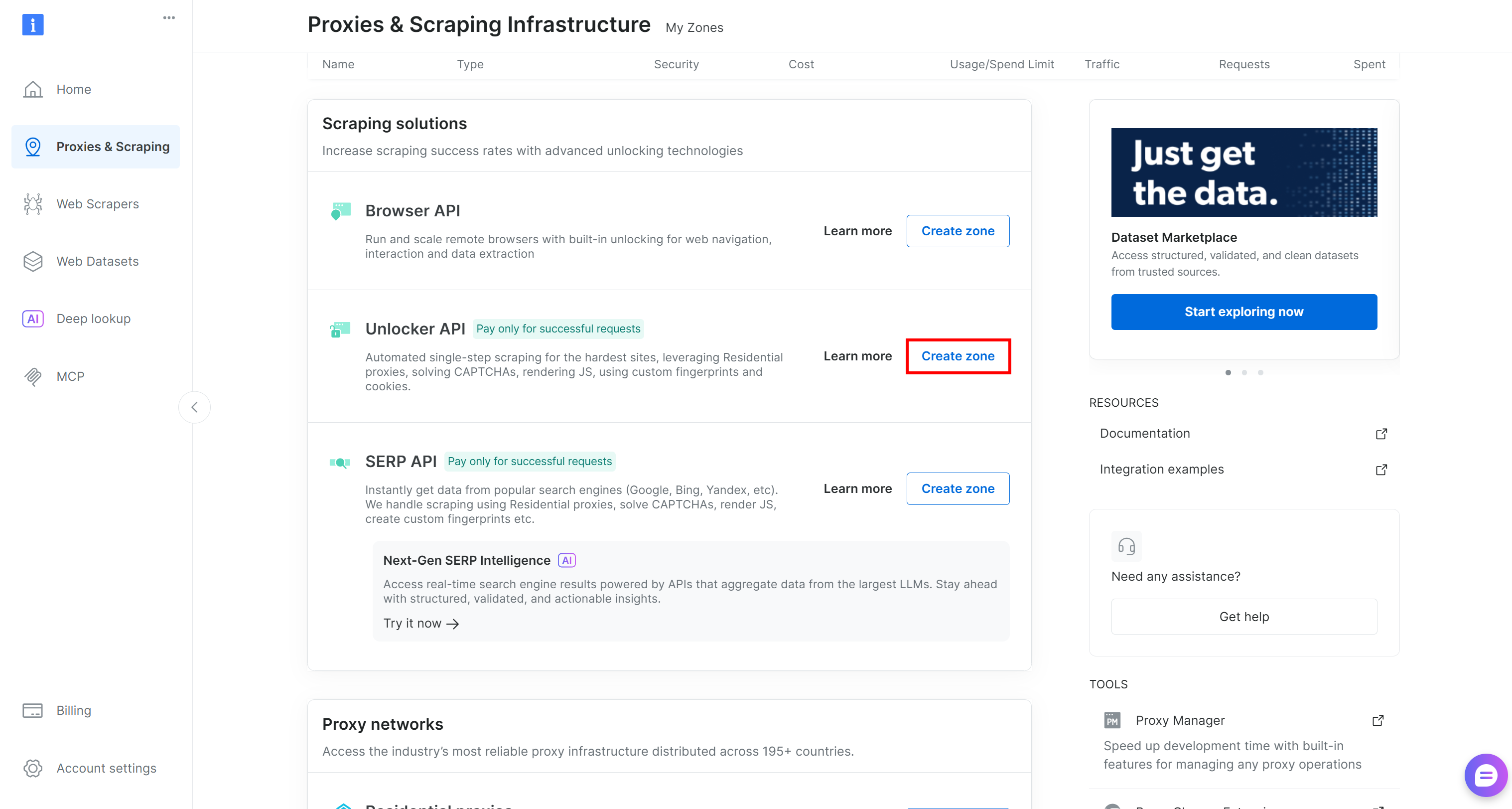
Choisissez un nom clair pour votre Zone et complétez l’assistant jusqu’à ce que la Zone devienne active.
Enfin, générez votre clé API Bright Data en suivant le guide officiel.
Une fois que vous avez le nom de la Zone et la clé API, définissez les variables d’environnement requises dans votre système basé sur Unix :
export BRIGHTDATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>"Remplacez les espaces réservés par les valeurs que vous venez de récupérer ou de configurer, et vous êtes prêt à partir !
Approche n°1 : Via l’outil Vercel skills
L’approche recommandée pour ajouter des compétences Bright Data à vos agents de codage IA (parmi les 40+ pris en charge) est via le package Vercel skills. Voyez comment en tirer parti !
Prérequis
Pour suivre cette section, assurez-vous d’avoir :
Étape n°1 : Installer les compétences
Déplacez-vous dans le répertoire de votre projet. Lancez la commande ci-dessous pour démarrer l’assistant d’ajout des compétences Bright Data à votre agent de codage IA local :
npx skills add brightdata/skillsCela exécute le package npm skills, l’installant si nécessaire, et récupère les compétences spécifiées depuis le Répertoire Agent Skills.
Remarque : brightdata/skills est le nom des compétences Bright Data dans le Répertoire Agent Skills.
Il vous sera demandé de sélectionner les compétences spécifiques que vous souhaitez installer :
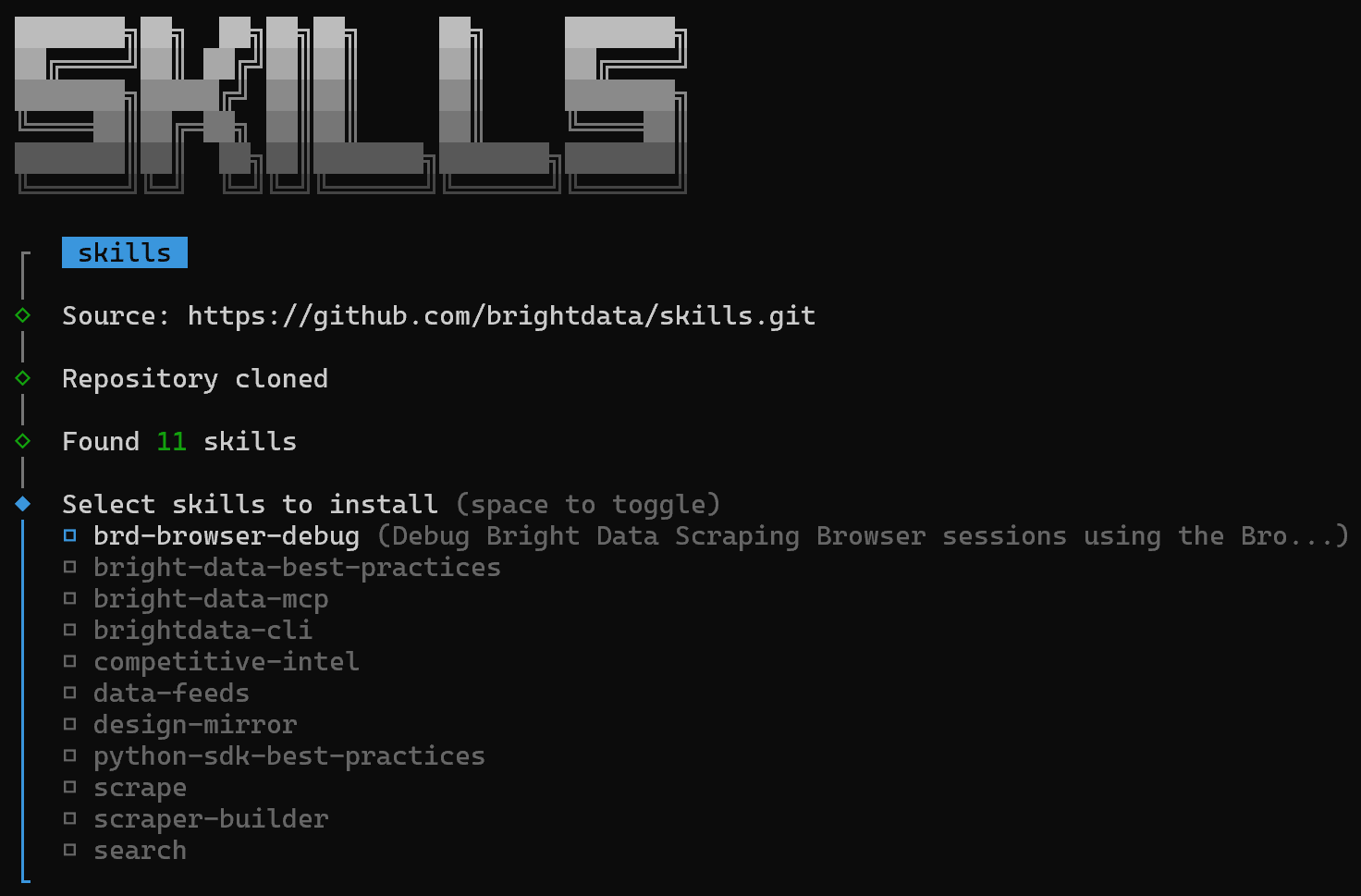
Appuyez sur la barre d’espace pour basculer toutes les compétences une par une, puis appuyez sur Entrée :
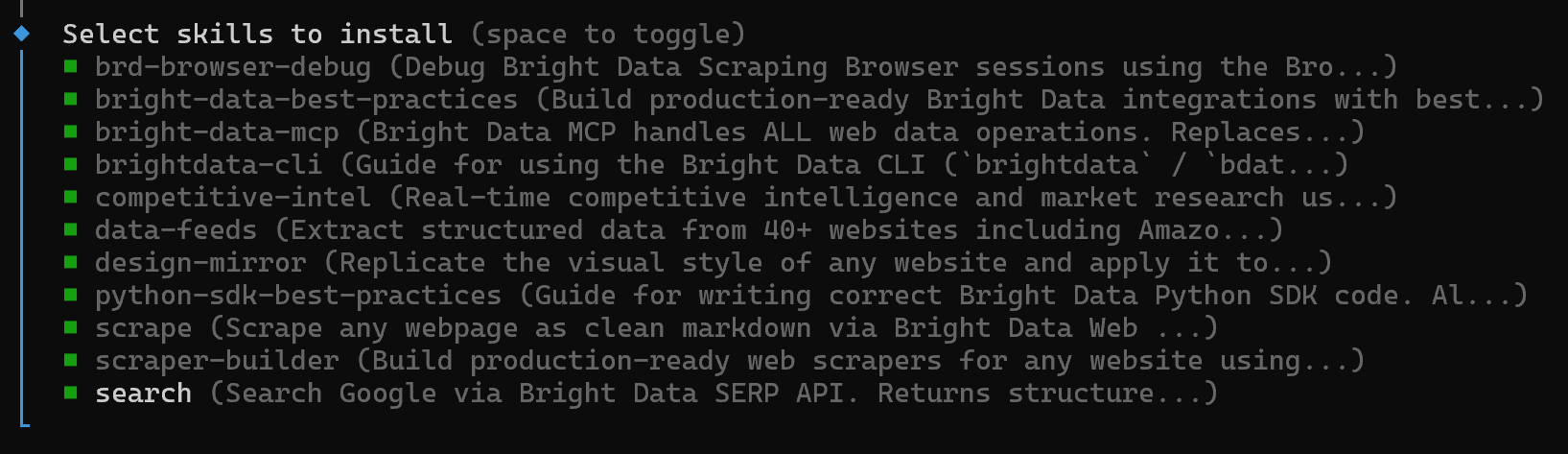
Ensuite, vous serez invité à sélectionner les agents IA où vous souhaitez installer les compétences :
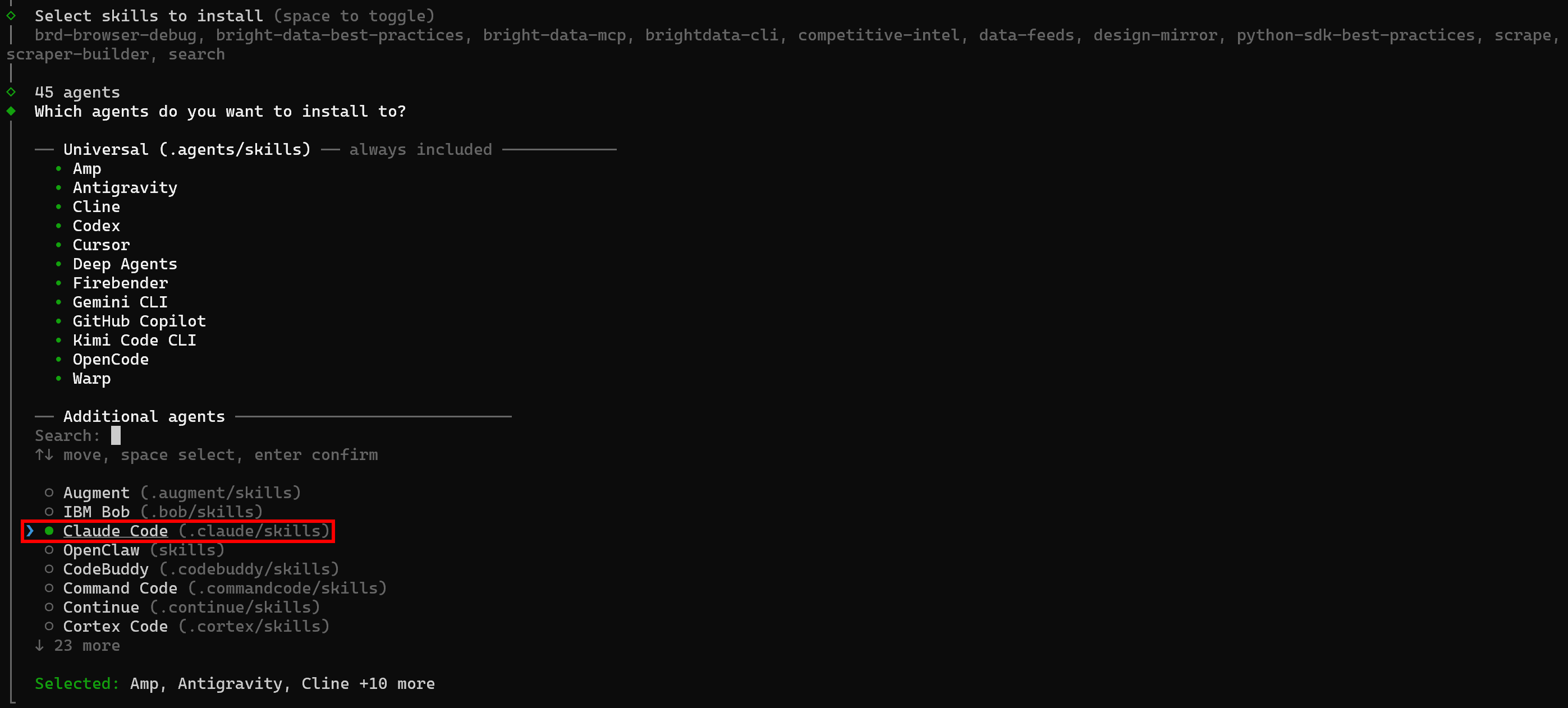
Par défaut, des agents comme Amp, Antigravity, Cline, Codex et d’autres sont sélectionnés. Puisque vous souhaitez installer sur Claude Code, activez-le avec la barre d’espace et appuyez sur Entrée.
Remarque : Gardez à l’esprit que vous pouvez installer les compétences directement dans Claude Code en utilisant :
npx skills list -a claude-codeskills vous demandera si vous souhaitez installer les compétences localement dans votre projet ou globalement :

Sélectionnez l’option qui correspond à votre cas d’usage.
Pour la méthode d’installation, l’approche recommandée est via un lien symbolique :
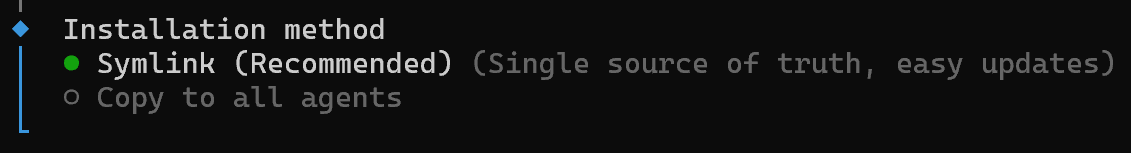
Cette option ajoute les compétences dans un dossier général et les lie à vos projets, gardant le dossier original comme source unique de vérité.
Enfin, vous verrez les sections « Résumé d’installation » et « Évaluation des risques de sécurité ». Examinez-les et tapez « Yes » pour continuer. Vous devriez alors recevoir la confirmation suivante :

Félicitations ! Les compétences Bright Data ont maintenant été ajoutées aux agents et assistants de codage IA sélectionnés.
Étape n°2 : Vérifier l’installation des compétences
Pour vérifier que les compétences ont été ajoutées avec succès à votre configuration locale de Claude Code, exécutez :
npx skills list -a claude-codeVous devriez voir une liste comme celle-ci :
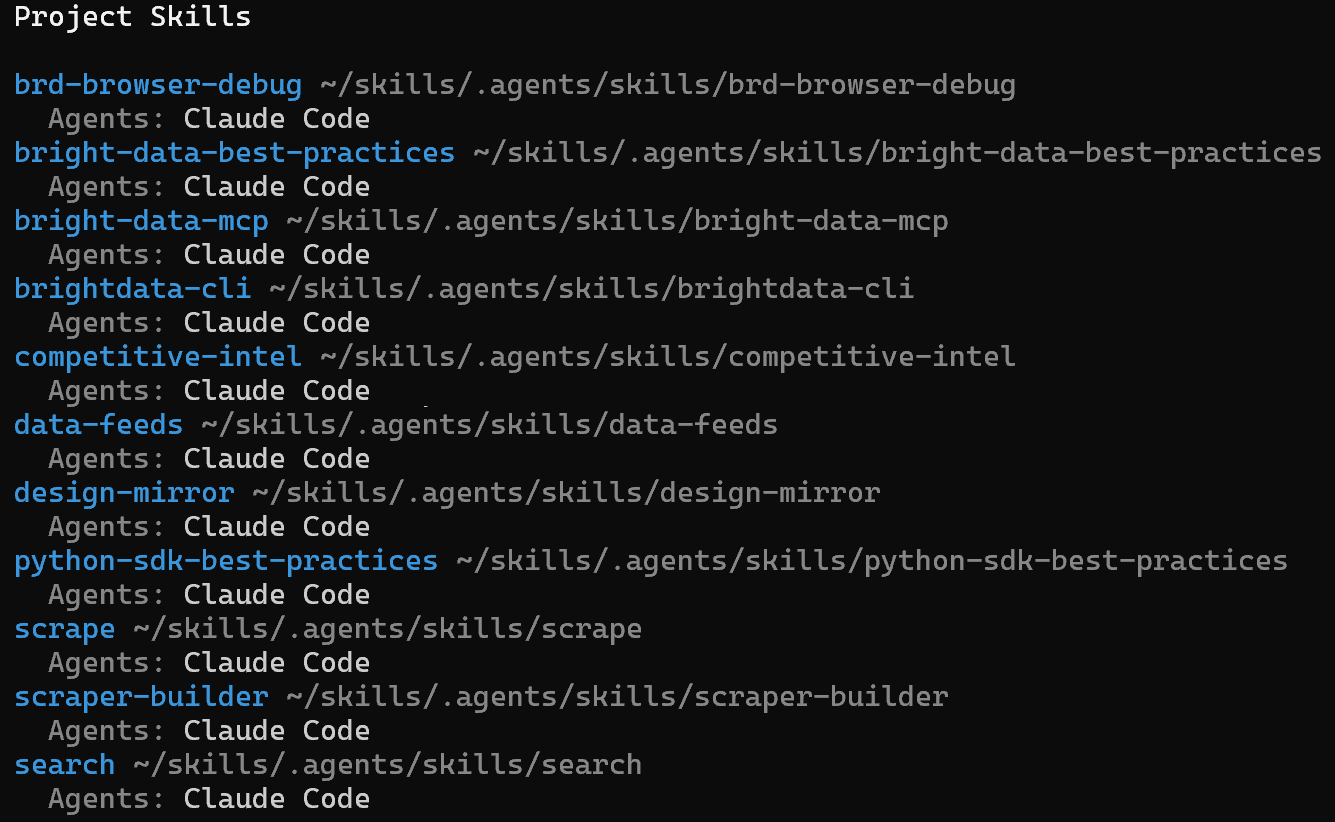
Notez que cela contient toutes les compétences Bright Data sélectionnées précédemment.
Alternativement, ouvrez Claude Code et tapez la commande :
/skillsLe résultat affichera à nouveau la liste des compétences Bright Data que vous avez sélectionnées auparavant :
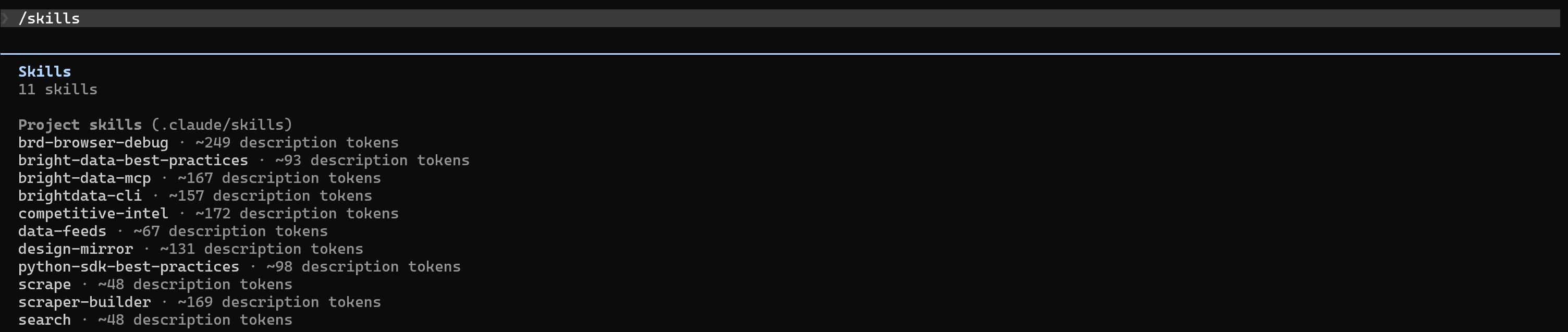
Excellent ! Les compétences Bright Data sont maintenant disponibles dans Claude Code (ou votre agent de codage IA préféré).
Prochaines étapes : Mettre à jour les compétences
Les compétences Bright Data sont susceptibles de recevoir des mises à jour à l’avenir. Pour vérifier les mises à jour, exécutez :
npx skills checkSi des mises à jour sont disponibles (c’est-à-dire que le dépôt des compétences Bright Data a changé depuis que vous l’avez cloné via npx skills add brightdata/skills), récupérez les mises à jour avec :
npx skills updateParfait ! Vos compétences Bright Data seront maintenant à jour avec la dernière version.
Approche n°2 : Via le CLI Bright Data
Le CLI Bright Data est un outil terminal tout-en-un qui offre un accès simplifié à toute la surface Bright Data. Parmi ses nombreuses commandes, il inclut également une commande pour l’installation des compétences. Apprenez à l’utiliser !
Prérequis
Avant de continuer, assurez-vous de remplir l’exigence ci-dessous :
- CLI Bright Data installé localement et connecté à votre compte.
Installer les compétences
Pour sélectionner et installer des compétences de manière interactive via le CLI Bright Data, exécutez :
brightdata skill addCela lance un sélecteur interactif où vous pouvez choisir les compétences à installer :
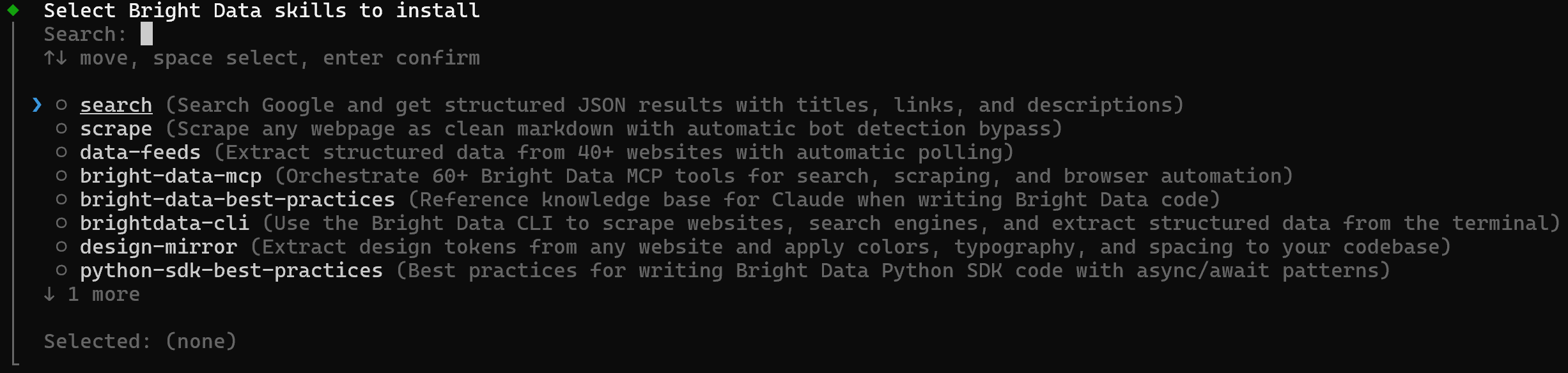
Sélectionnez toutes les compétences en les activant avec la barre d’espace :
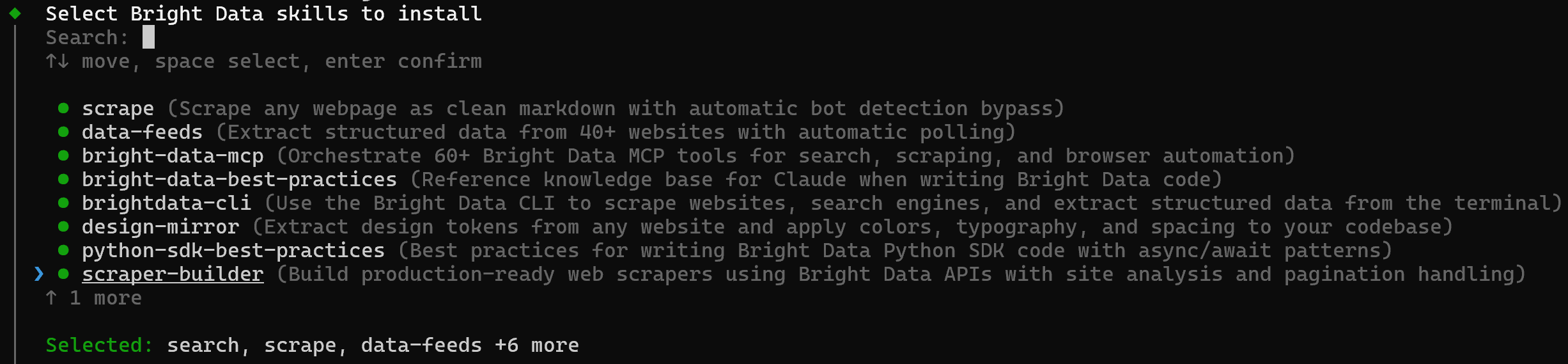
Ensuite, choisissez les agents IA où vous souhaitez installer les compétences. Dans ce cas, sélectionnez Claude Code :
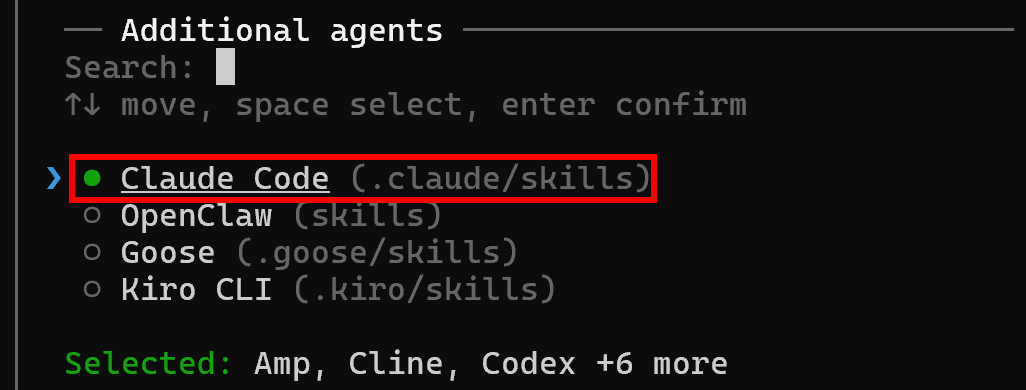
Une par une, les compétences activées seront ensuite récupérées et installées dans l’agent de codage sélectionné :
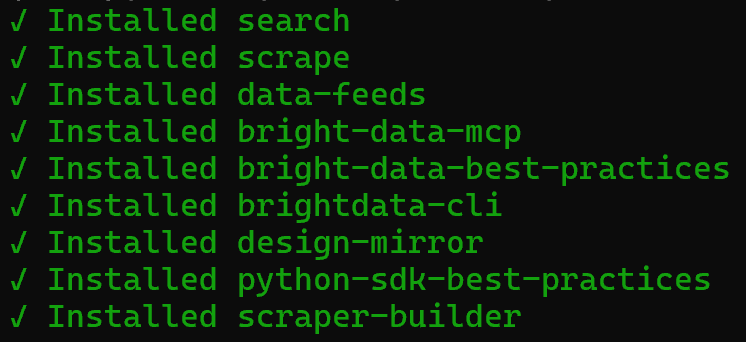
Fantastique ! Votre configuration locale de Claude Code inclut désormais les compétences Bright Data.
Approche n°3 : Via la configuration manuelle
Les compétences sont simplement des dossiers. Ainsi, pour la configuration, vous pouvez les copier-coller manuellement dans le répertoire requis de votre agent de codage IA.
Commencez par cloner le dépôt GitHub des compétences Bright Data :
git clone https://github.com/brightdata/skillsLe dossier skills/ contiendra maintenant :
skills/
├── .claude-plugin/
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdEnsuite, copiez les dossiers de compétences (tels que bright-data-best-practices/, bright-data-mcp/, etc.) depuis skills/skills/ dans le répertoire requis pour la configuration de votre agent IA.
Par exemple, pour les copier dans un projet Claude Code, exécutez :
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/Si vous utilisez un agent de codage IA différent, référez-vous à sa documentation officielle pour trouver le dossier correct où les compétences Bright Data doivent être placées. Mission accomplie !
Les compétences Bright Data en action
Il est temps d’observer les capacités que votre agent de codage IA acquiert grâce à l’intégration des compétences Bright Data. Parmi les nombreux cas d’usage pris en charge, nous nous concentrerons sur les principaux et présenterons des prompts réels que vous pourriez exécuter dans vos projets.
Recherche web
L’agent IA peut désormais rechercher sur le web en temps réel et récupérer des résultats structurés grâce à la compétence search.
Exemples de prompts :
"Trouvez les derniers tutoriels Python sur la visualisation de données avec Matplotlib et utilisez-les pour améliorer les graphiques dans le notebook data-analysis.ipynb"."Recherchez des articles récents sur les meilleures pratiques d'authentification API en Python et résumez les étapes clés pour la couche d'authentification actuelle"."Trouvez les nouveaux frameworks JavaScript pour créer des tableaux de bord interactifs et fournissez des exemples de code intégrables dans le projet".
Scraping web
Votre assistant de codage peut désormais scraper n’importe quelle page web et obtenir du contenu Markdown propre via la compétence scrape.
Exemples de prompts :
"Scrapez les listes de produits de cette page e-commerce 'https://www.gucci.com/us/en/ca/women/handbags-c-women-handbags' et générez une requête SQL pour remplir la table 'products' avec les données extraites"."Scrapez les publications récentes de cette page officielle du forum Python 'https://python-forum.io/forum-44.html' et résumez les discussions clés".
Flux de données web
L’agent IA peut récupérer des données JSON structurées depuis plus de 40 domaines grâce à la compétence data-feeds. C’est idéal pour remplir des bases de données, définir des réponses simulées ou soutenir des pipelines d’analyse de données.
Exemples de prompts :
"Récupérez les données de cette page de produit Amazon 'https://www.amazon.com/Apple-Bluetooth-Headphones-Personalized-Effortless/dp/B0DGHMNQ5Z/' et utilisez-les pour simuler la réponse du endpoint /api/v1/products/B0DGHMNQ5Z"."Récupérez les statistiques vidéo et les commentaires de cette vidéo YouTube '<YOUTUBE_VIDEO_URL>' et utilisez-les pour calculer des métriques d'engagement et effectuer une analyse de sentiment".
Miroir de design
L’agent IA peut répliquer les modèles de système de design, les tokens et les composants UI depuis des sources pour maintenir une qualité d’interface cohérente grâce à la compétence design-mirror.
Exemples de prompts :
"Reproduisez la palette de couleurs, la typographie et les styles de boutons de ce site web '<WEBSITE_URL>' dans une bibliothèque de composants CSS/React réutilisable".Extrayez les tokens de design du projet Figma donné '<PUBLIC_FIGMA_PROJECT_URL>' et générez une configuration JSON réutilisable dans mon application web".
Construction de Scraper web
L’agent IA peut générer des Scrapers prêts pour la production grâce à la compétence scraper-builder.
Exemples de prompts :
"Construisez un Scraper pour ce site e-commerce '<WEBSITE_URL>' qui extrait les noms de produits, les prix et la disponibilité en stock de tous les produits"."Générez un script pour scraper tous les articles de ce blog '<BLOG_URL>' et extraire le titre, l'auteur, le contenu et la date".
Cas d’usage avancé
L’agent IA peut combiner plusieurs compétences (par exemple, search + scrape) pour prendre en charge des prompts complexes à plusieurs étapes.
Exemples de prompts :
"Recherchez des articles récents sur la sécurité des modèles IA, scrapez leurs résumés et proposez des meilleures pratiques pour améliorer le projet actuel"."Collectez des listes de produits d'Amazon et d'eBay, fusionnez les données et mettez en évidence les différences de prix pour une analyse concurrentielle"."Trouvez les packages Python tendance sur GitHub, récupérez leurs fichiers README et résumez les modèles d'utilisation".
Conclusion
Dans cet article de blog, vous avez appris ce que les compétences Bright Data apportent, pourquoi elles sont importantes et comment les installer. Grâce à ce que vous avez vu ici, vous savez maintenant comment étendre vos agents et assistants de codage IA avec des outils d’accès aux données web prêts pour l’entreprise. Ceux-ci les aideront à surmonter les limitations des connaissances statiques des LLM.
Les compétences Bright Data vous permettent de connecter vos agents à la gamme complète des produits et services Bright Data pour les cas d’usage alimentés par l’IA. Laissez une étoile sur le dépôt officiel pour recevoir des notifications lors de la publication d’une nouvelle mise à jour !
Créez un compte Bright Data gratuitement aujourd’hui et commencez l’intégration avec nos solutions d’accès aux données web prêtes pour l’IA !
FAQ
Quels agents et assistants de codage sont pris en charge par les compétences Bright Data ?
Les compétences Bright Data peuvent être utilisées avec toute technologie d’agent IA prenant en charge le standard Agent Skills d’Anthropic. Celles-ci incluent Amp, Kimi Code CLI, Replit, Universal, Antigravity, Augment, IBM Bob, Claude Code, OpenClaw, Cline, Warp, CodeBuddy, Codex, Command Code, Continue, Cortex Code, Crush, Cursor, Deep Agents, Droid, Firebender, Gemini CLI, GitHub Copilot, Goose, Junie, iFlow CLI, Kilo Code, Kiro CLI, Kode, MCPJam, Mistral Vibe, Mux, OpenCode, OpenHands, Pi, Qoder, Qwen Code, Roo Code, Trae, Trae CN, Windsurf, Zencoder, Neovate, Pochi, et AdaL.
Puis-je combiner des compétences avec MCP dans le même agent ?
Bien sûr ! Un agent IA peut se connecter au serveur Web MCP Bright Data tout en étant étendu avec des compétences Bright Data. Voyez comment configurer cette configuration dans Claude Desktop pour utiliser les deux capacités ensemble. Gardez à l’esprit que les compétences Bright Data incluent une compétence bright-data-mcp spécifique pour orchestrer les outils Web MCP afin d’obtenir de meilleurs résultats avec eux.
Est-il possible d’utiliser les compétences Bright Data en dehors des agents de codage IA ?
Oui ! Certaines compétences (telles que scrape, search et data-feeds) sont accompagnées de scripts shell dédiés que vous pouvez appeler directement. Clonez le dépôt GitHub, naviguez dans le dossier cloné (cd skills/) et assurez-vous que tous les prérequis sont remplis. Testez ensuite les scripts dans votre terminal.
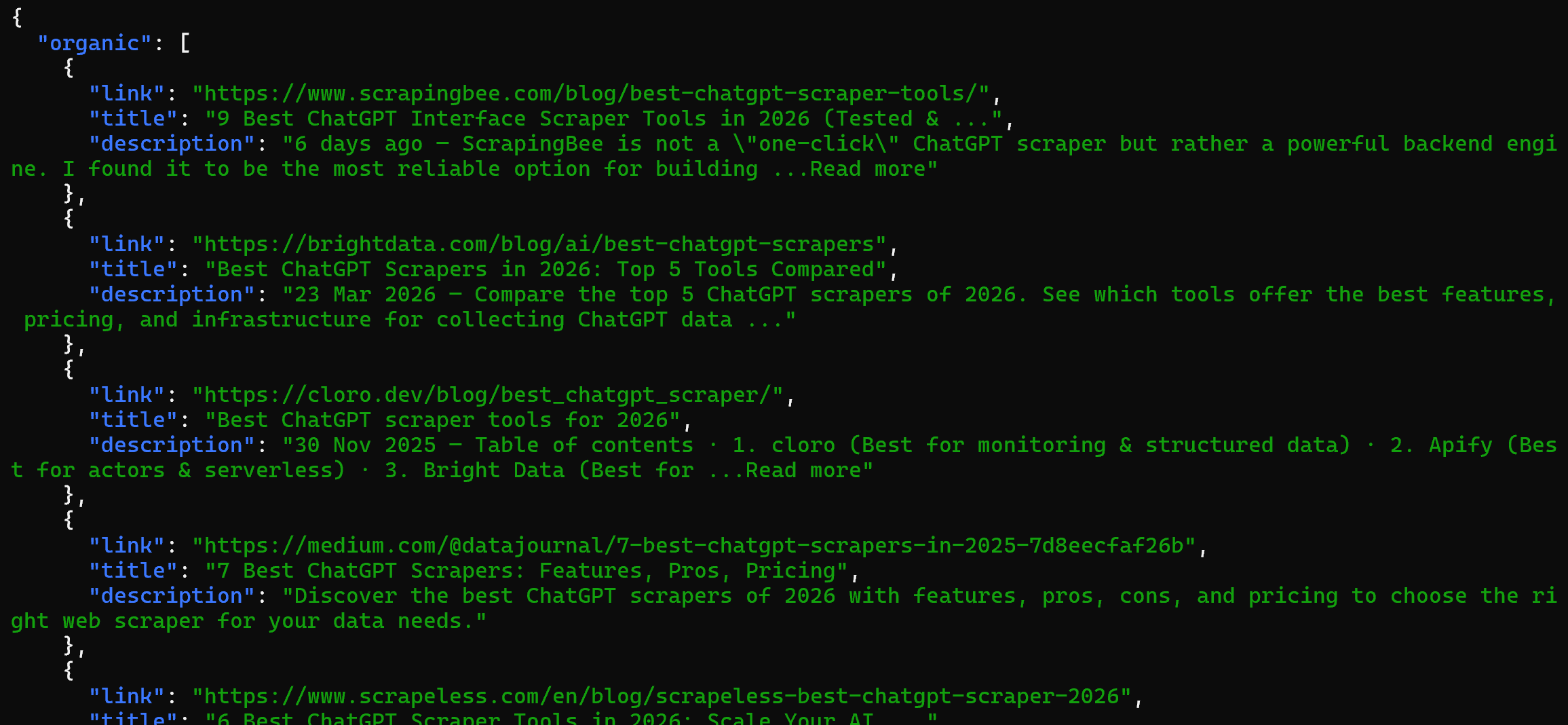
Par exemple, vous pouvez exécuter la compétence search directement avec :
bash skills/search/scripts/search.sh "best chatgpt scrapers"Le résultat sera des données SERP structurées scrapées depuis Google via l’API SERP :
Explorez des exemples supplémentaires dans la documentation officielle.






