Dans cet article, vous apprendrez :
- Ce qu’est Azure Synapse Analytics et ce qu’il offre.
- Pourquoi l’intégration de l’API SERP de Bright Data dans Azure Synapse Analytics est une stratégie gagnante.
- Comment créer un pipeline Azure Synapse qui collecte, transforme et analyse les données de recherche Web à l’aide de l’API SERP de Bright Data.
C’est parti !
Qu’est-ce qu’Azure Synapse Analytics ?
Azure Synapse Analytics est une plateforme d’analyse basée sur le cloud qui regroupe l’intégration des données, le stockage des données d’entreprise et le traitement des mégadonnées dans un seul espace de travail. Elle fournit une orchestration de pipeline, des pools Apache Spark et des pools SQL dédiés et sans serveur, vous permettant d’ingérer, de transformer et d’interroger des données à grande échelle à partir d’un environnement unifié unique.
Son objectif principal est de vous aider à passer des données brutes à des informations commerciales. Pour ce faire, elle combine un moteur de pipeline (basé sur Azure Data Factory) pour l’ingestion de données, des notebooks Apache Spark pour les transformations basées sur du code et des pools SQL pour interroger et fournir des Jeux de données prêts à être analysés à des tableaux de bord, des modèles ML et des applications en aval.
Azure Synapse Analytics vs Azure IA Foundry : quelle est la différence ?
Si vous avez déjà lu notre guide sur l’intégration de l’API SERP avec Azure AI Foundry, vous vous demandez peut-être en quoi Synapse Analytics est différent. Les deux ont des objectifs fondamentalement différents :
- Azure AI Foundry est une plateforme de développement IA unifiée axée sur la création, le déploiement et la gestion d’applications IA, d’agents et de flux de prompt. Elle donne accès à un catalogue de LLM (provenant d’Azure OpenAI, Meta, Mistral, etc.) et est conçue pour le développement axé sur l’IA impliquant l’ingénierie de prompt, le réglage fin des modèles et les workflows RAG.
- Azure Synapse Analytics est une plateforme d’analyse et d’entreposage de données axée sur l’ingestion de grands volumes de données, l’exécution de transformations complexes et la fourniture d’analyses structurées à grande échelle. Elle excelle dans les pipelines ETL/ELT, le traitement des mégadonnées avec Spark et la veille économique basée sur SQL.
En bref, Azure AI Foundry est l’endroit où vous créez des applications alimentées par l’IA et des flux de prompt, tandis qu’Azure Synapse Analytics est l’endroit où vous créez des pipelines de données qui collectent, transforment et stockent les données à des fins d’analyse et de reporting.
En réalité, ces deux solutions se complètent parfaitement. Vous pouvez utiliser Synapse pour créer la base de données, collecter et stocker des données web à grande échelle, puis alimenter AI Foundry avec ces données sélectionnées pour une analyse alimentée par LLM. Dans ce tutoriel, vous découvrirez comment Synapse Analytics peut s’intégrer à l’API SERP de Bright Data pour créer un pipeline de données web complet qui collecte les résultats de recherche, les transforme avec Spark et fournit des analyses via SQL.
Pourquoi intégrer l’API SERP de Bright Data à Azure Synapse Analytics
Azure Synapse Analytics fournit un puissant connecteur REST dans son moteur de pipeline qui vous permet d’appeler n’importe quelle API REST et d’enregistrer les résultats directement dans Azure Data Lake Storage. Cela vous ouvre la possibilité d’intégrer des sources de données externes dans vos workflows d’analyse. Cependant, pour injecter des données de recherche web en temps réel dans votre entrepôt de données, vous avez besoin d’une source de données fiable, évolutive et structurée.
C’est là qu’intervient l’API SERP de Bright Data. L’API SERP vous permet de rechercher par programmation des requêtes sur les moteurs de recherche, notamment Google, Bing, DuckDuckGo, Yandex et bien d’autres, et de récupérer l’intégralité du contenu SERP. Elle renvoie des données dans plusieurs formats, notamment JSON analysé, HTML brut et Markdown prêt pour l’IA, vous offrant ainsi une source fiable de données fraîches et vérifiables.
Cette approche est particulièrement utile pour :
- Les pipelines de suivi des mots-clés SEO pour surveiller quotidiennement votre classement dans les résultats de recherche pour des milliers de mots-clés et identifier les tendances au fil du temps.
- Les entrepôts d’intelligence compétitive pour collecter des données sur la visibilité des concurrents et les associer à des mesures internes à des fins d’analyse stratégique.
- Les jeux de données d’études de marché afin d’agréger les tendances des résultats de recherche dans différents secteurs, régions et périodes pour établir des rapports à grande échelle.
- L’analyse des performances de contenu pour suivre le classement de votre contenu pour les mots-clés cibles et mesurer l’impact des efforts de référencement.
En combinant les capacités d’orchestration de pipelines et de stockage de données d’Azure Synapse avec l’API SERP de Bright Data, vous pouvez créer des pipelines de données qui collectent, transforment et analysent en continu les données de recherche Web à grande échelle, sans avoir à maintenir une Infrastructure de scraping.
Comment créer un pipeline de données SERP dans Azure Synapse avec Bright Data
Dans cette section guidée, vous découvrirez comment intégrer l’API SERP de Bright Data dans un pipeline Azure Synapse dans le cadre d’un outil quotidien de suivi du classement des mots-clés. Ce pipeline comprend cinq étapes principales :
- Configuration de l’espace de travail: vous créez un espace de travail Azure Synapse avec un compte Data Lake Storage lié.
- Configuration de la source de données: vous créez un service lié REST pointant vers l’API SERP de Bright Data, avec un stockage sécurisé des informations d’identification.
- Pipeline d’ingestion: un pipeline Synapse appelle l’API SERP pour un ensemble de mots-clés suivis et enregistre les résultats JSON bruts dans votre lac de données.
- Transformation Spark: un notebook Apache Spark aplatit et normalise les données SERP brutes en tables Delta prêtes à être analysées.
- Analyses SQL: des requêtes SQL sans serveur analysent les tendances de classement et des vues sont créées pour les tableaux de bord Power BI.
Remarque : il ne s’agit que d’un exemple, et vous pouvez tirer parti de l’API SERP dans de nombreux autres scénarios et cas d’utilisation. Par exemple, vous pouvez également créer des pipelines pour la Surveillance des prix concurrentiels ou alimenter des modèles d’apprentissage automatique avec des données SERP.
Suivez les instructions ci-dessous pour créer un pipeline de données web alimenté par l’API SERP de Bright Data dans Azure Synapse Analytics !
Prérequis
Pour suivre cette section du tutoriel, assurez-vous de disposer des éléments suivants :
- Un compte Microsoft.
- Un abonnement Azure (même la version d’essai gratuite suffit).
- Un compte Bright Data avec une zone API SERP active et une clé API (avec des autorisations d’administrateur).
Suivez la documentation officielle de Bright Data pour configurer votre zone API SERP et obtenir votre clé API. Conservez votre clé API et le nom de votre zone dans un endroit sûr, car vous en aurez besoin sous peu.
Étape 1 : Créer un espace de travail Azure Synapse
Les pipelines Azure Synapse ne sont disponibles que dans un espace de travail Synapse. La première étape consiste donc à en créer un.
Connectez-vous à votre compte Azure et recherchez Azure Synapse Analytics dans la barre de recherche en haut du portail Azure :
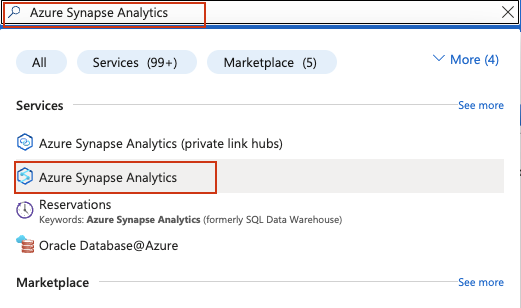
Sur la page de gestion Synapse Analytics, cliquez sur Créer. Remplissez le formulaire de création :
- Sélectionnez votre abonnement Azure.
- Sélectionnez un groupe de ressources existant ou créez-en un nouveau.
- Donnez un nom à votre espace de travail, par exemple
bright-data-serp-pipeline. - Choisissez une région proche de chez vous.
- Pour Data Lake Storage Gen2, sélectionnez Créer nouveau et indiquez un nom de compte de stockage (qui doit être entièrement en minuscules, comporter entre 3 et 24 caractères, être unique au niveau mondial, par exemple
serppipelinelake). Créez un nouveau système de fichiers nomméraw.
Cliquez sur Vérifier + Créer, puis sur Créer pour lancer le déploiement.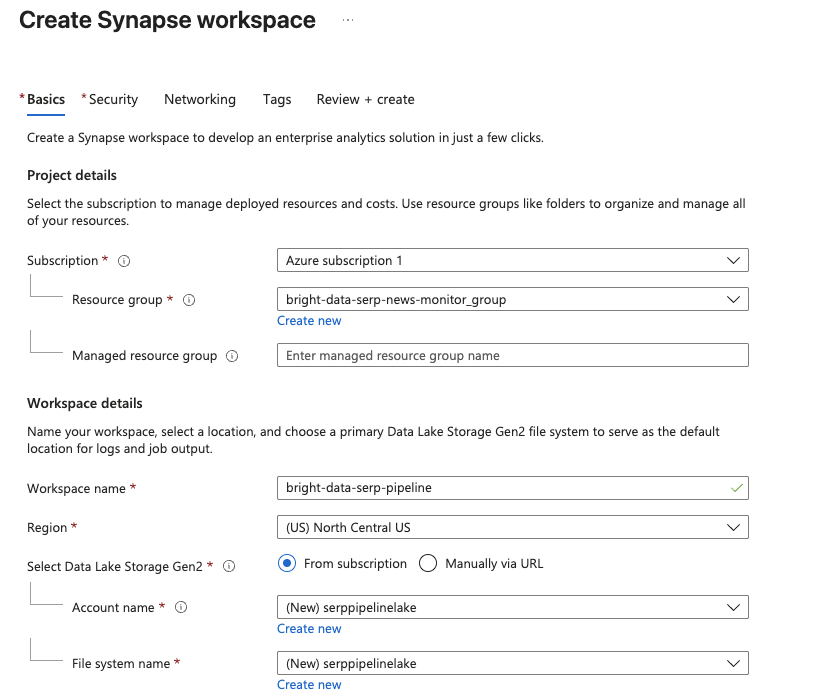
Le processus d’initialisation peut prendre quelques minutes. Une fois terminé, une page de confirmation s’affiche. Cliquez sur Accéder à la ressource, puis sur Ouvrir Synapse Studio pour lancer l’environnement de développement Web.
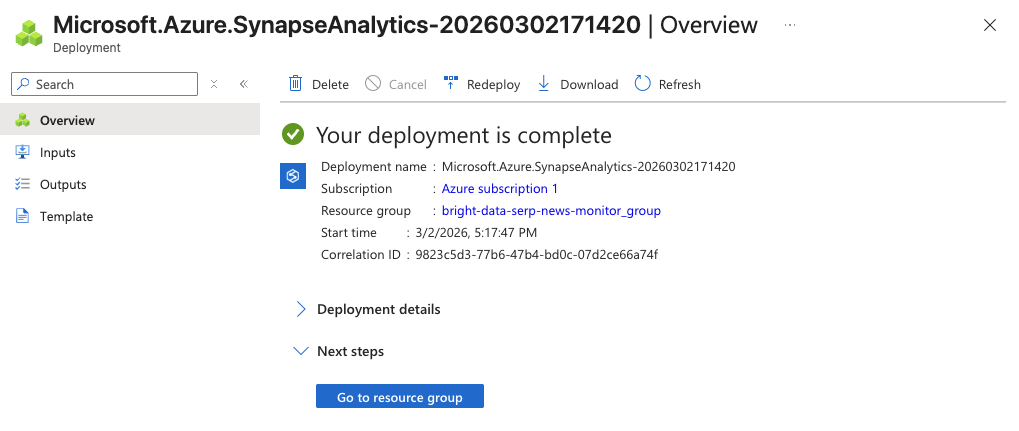
Vous disposez désormais d’un espace de travail Synapse dans lequel vous pouvez créer des pipelines, rédiger des notebooks Spark et exécuter des requêtes SQL.
Étape 2 : Créer un pool Apache Spark
Pour exécuter les notebooks de transformation plus tard dans ce tutoriel, vous avez besoin d’un pool Apache Spark dans votre espace de travail.
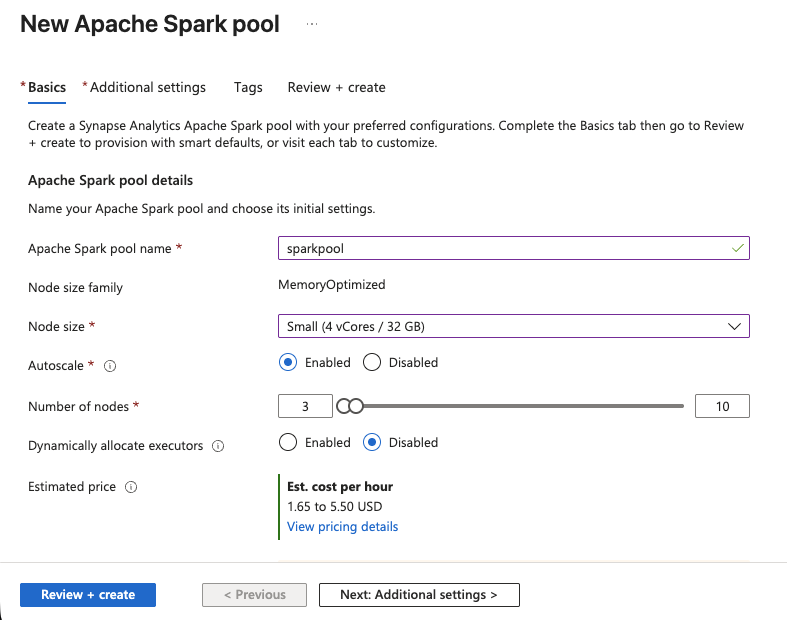
- Dans Synapse Studio, accédez à Manage > Apache Spark pools > New.
- Donnez un nom au pool, par exemple
sparkpool. - Définissez la taille du nœud sur Petite (4 vCores / 32 Go), ce qui est suffisant pour les transformations de données SERP.
- Activez l’option Autoscale et définissez la plage sur 3 à 5 nœuds.
- Cliquez sur Vérifier + Créer, puis sur Créer.
Le pool Spark sera prêt dans quelques instants. Vous disposez désormais de la puissance de calcul nécessaire pour exécuter des notebooks PySpark.
Étape 3 : créer le pipeline d’ingestion
Vous allez maintenant créer un pipeline Synapse qui appelle l’API SERP de Bright Data pour un ensemble de mots-clés suivis et enregistre les résultats dans votre lac de données.
Créer un nouveau pipeline
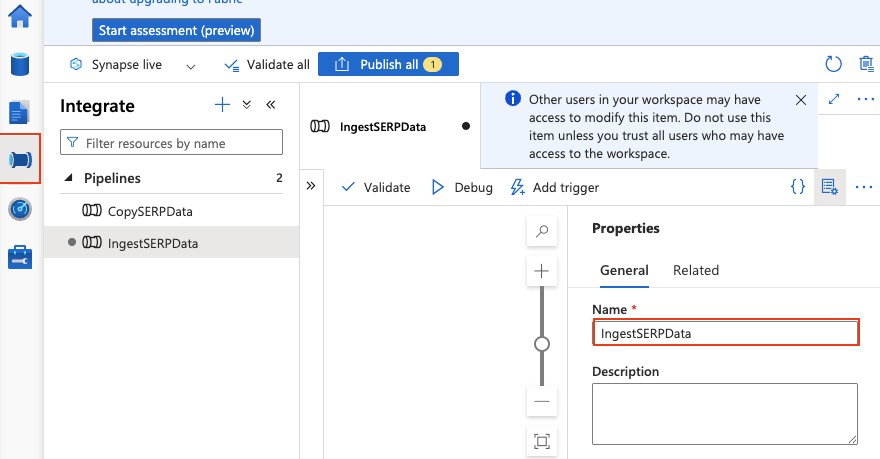
- Accédez à Intégrer > + > Pipeline.
- Nommez-le
IngestSERPData.
Ajoutez les paramètres du pipeline
Cliquez sur l’arrière-plan du canevas du pipeline pour ouvrir les propriétés du pipeline. Allez dans l’onglet Paramètres et ajoutez :
| Nom | Type | Valeur par défaut |
|---|---|---|
Mots-clés |
Tableau | ["outils de Scraping web", "service Proxy", "API d'extraction de données"] |
Ce sont les mots-clés pour lesquels vous souhaitez suivre les classements. Vous pouvez modifier cette liste à tout moment.
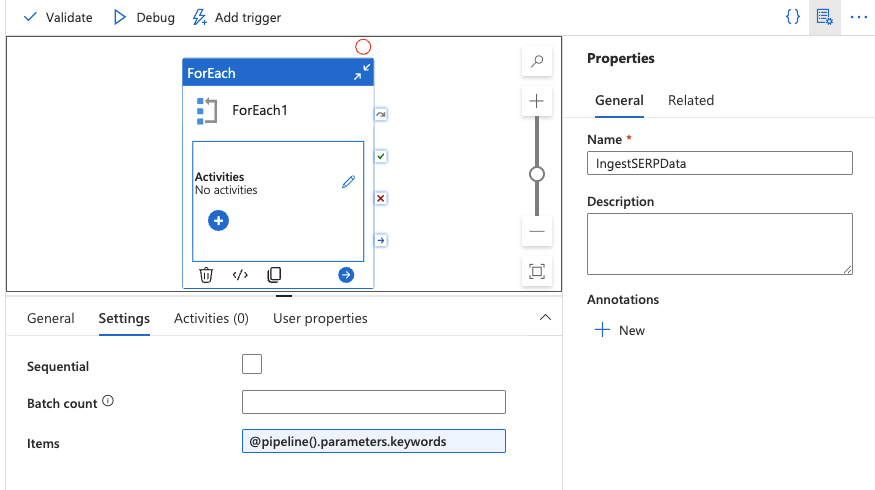
Ajouter une activité ForEach
- Faites glisser une activité ForEach depuis le panneau Activités vers le canevas.
- Dans l’onglet Paramètres, définissez le champ Éléments sur :
@pipeline().parameters.keywords
Cela permettra d’itérer sur chaque mot-clé de votre tableau.
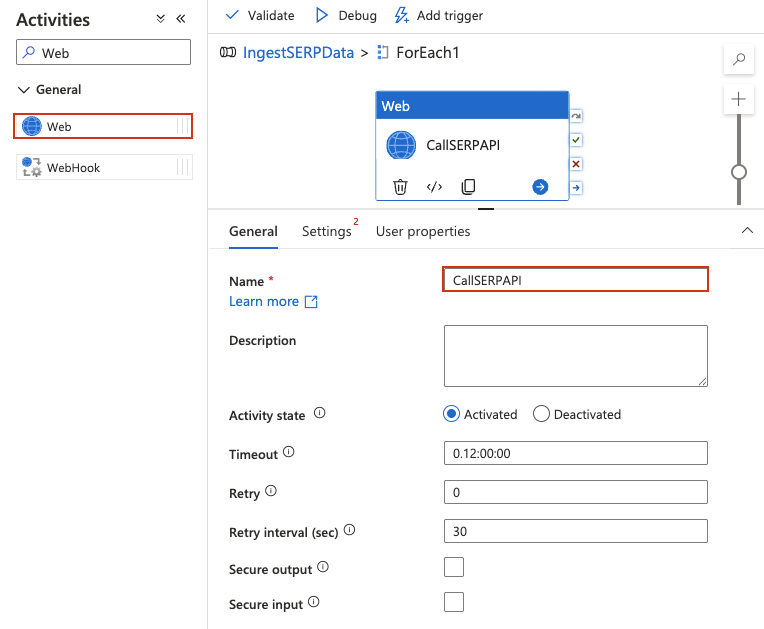
Ajoutez une activité Web à l’intérieur de ForEach
Une activité Web appelle directement une API REST, sans nécessiter de Jeux de données ou de services liés pour la requête elle-même.
- Double-cliquez sur l’activité ForEach pour ouvrir son canevas interne. Vous devriez voir l’en-tête du concepteur changer pour indiquer que vous êtes dans la portée ForEach (fil d’Ariane
IngestSERPData > ForEach1). - Dans le panneau Activités à gauche, développez Général et faites glisser une activité Web sur le canevas interne.
- Donnez-lui un nom, tel que
CallSERPAPI.
Configurer l’activité Web
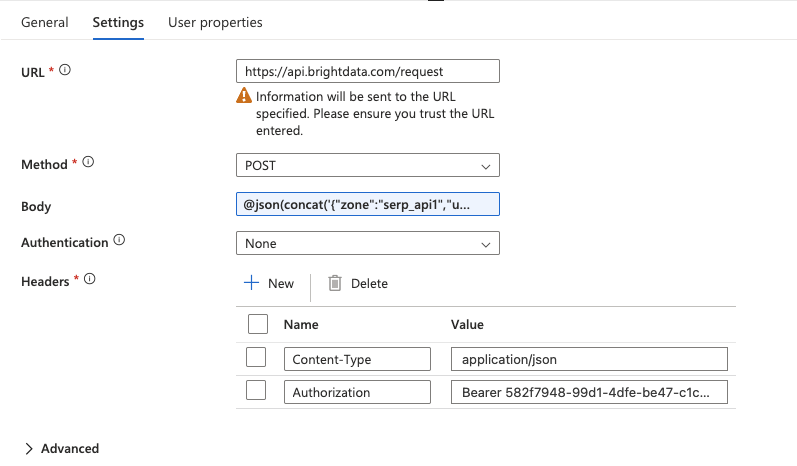
Cliquez sur l’activité Web pour la sélectionner, puis accédez à l’onglet Paramètres et configurez :
- URL: saisissez le point de terminaison API complet directement dans le champ :
https://api.brightdata.com/request- Méthode: sélectionnez
POSTdans le menu déroulant. - En-têtes: cliquez deux fois sur + Ajouter un en-tête pour ajouter : Nom Valeur
Type de contenuapplication/jsonAutorisationBearer VOTRE_CLÉ_API_BRIGHT_DATA - Corps: c’est ici que vous transmettez la requête API SERP avec le mot-clé actuel de la boucle ForEach. Saisissez l’expression suivante directement dans le champ Corps (n’utilisez pas la fenêtre contextuelle « Ajouter du contenu dynamique ») :
@concat('{"zone":"VOTRE_ZONE_API_SERP","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')Remplacez YOUR_SERP_API_ZONE par le nom réel de votre zone dans le tableau de bord Bright Data.
Important : le
caractère @doit être le tout premier caractère du champ, sans espace devant. Cela indique à Synapse d’évaluer le texte comme une expression. Si vous l’avez saisi correctement, le champ mettra l’expression en surbrillance. Si elle apparaît sous forme de texte brut, supprimez-la et retapez-la en vous assurant quele caractère @se trouve en position zéro.Fonctionnement : la fonction
item()renvoie le mot-clé actuel de la boucle ForEach (par exemple,« outils de Scraping web »). La fonctionreplace()remplace les espaces par des caractères+afin de former un paramètre de requête URL valide. La fonctionconcat()construit le corps complet de la requête JSON sous la forme d’une chaîne unique.
- Authentification: définissez sur
Aucune(l’authentification est déjà gérée via l’en-tête Authorization).
Ajouter un déclencheur de planification
- De retour sur le canevas principal du pipeline, cliquez sur Ajouter un déclencheur > Nouveau/Modifier.
- Sélectionnez Nouveau et définissez une récurrence quotidienne (par exemple, 6 h 00 UTC).
- Cliquez sur OK, puis sur Publier tout pour enregistrer et déployer le pipeline.
Pour le tester immédiatement, cliquez sur Déclencher maintenant > OK. Accédez à Moniteur > Exécutions du pipeline pour observer l’exécution. Vous devriez voir le pipeline réussir et trouver des fichiers JSON dans votre lac de données sous le chemin raw/serp/.
Revenez à l’écran principal du pipeline
Cliquez sur le nom du pipeline (IngestSERPData) dans le fil d’Ariane en haut du concepteur pour revenir au canevas principal. Vous devriez voir l’activité ForEach avec un indicateur montrant qu’elle contient des activités enfants.
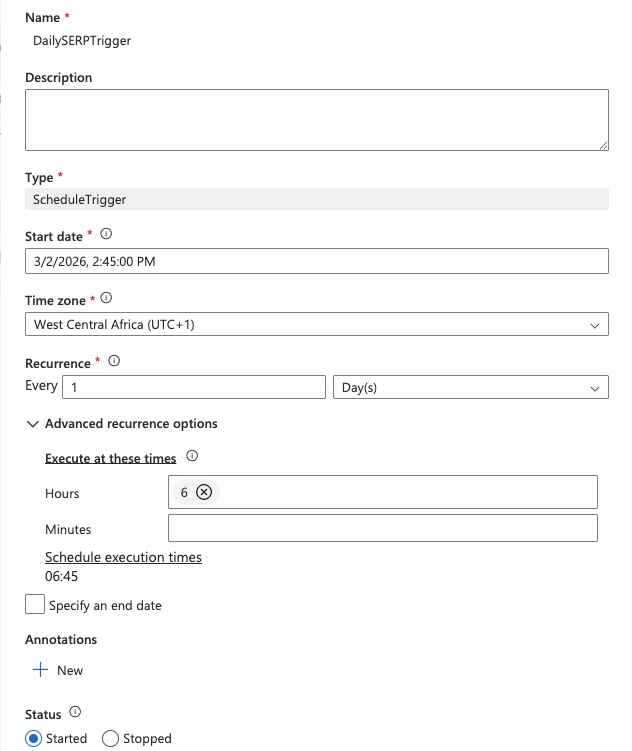
Ajoutez un déclencheur de planification
- Cliquez sur Ajouter un déclencheur > Nouveau/Modifier en haut du concepteur de pipeline.
- Dans le menu déroulant, sélectionnez Nouveau.
- Donnez un nom au déclencheur (par exemple,
DailySERPTrigger), définissez le type sur Planifié et configurez :
- Date de début: date du jour
- Récurrence: Tous les
1jour - À ces heures:
6(pour 6 h 00 UTC)
- Cliquez sur OK, puis confirmez les paramètres du déclencheur.
- Cliquez sur Publier tout en haut de Synapse Studio pour tout enregistrer et déployer.
Testez le pipeline
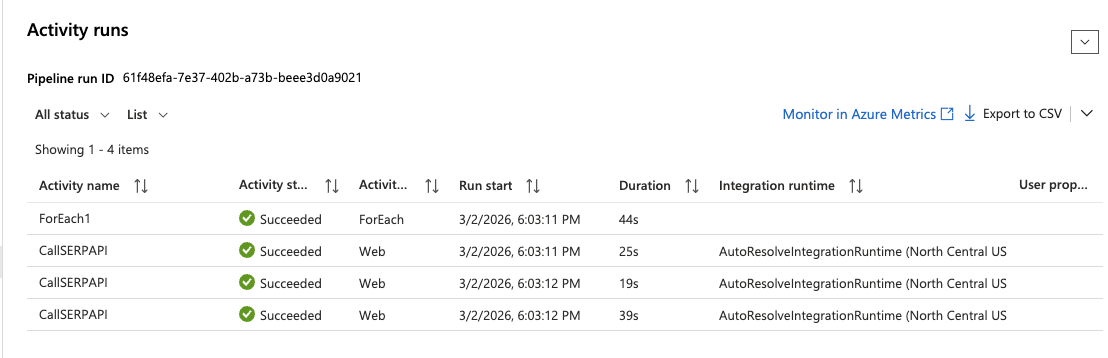
Pour exécuter immédiatement le pipeline sans attendre le déclencheur programmé :
- Cliquez sur Déclencher maintenant > OK en haut du concepteur de pipeline.
- Accédez à Moniteur > Exécutions du pipeline dans le menu de gauche.
- Attendez que l’exécution soit terminée. Vous devriez voir un statut vert Réussi.
- Cliquez sur l’exécution et développez l’activité ForEach pour inspecter chaque exécution d’activité Web. Cliquez sur n’importe quelle itération
CallSERPAPIpour voir la réponse API complète dans la section Sortie.
Étape 4 : Collecte et transformation des données avec Apache Spark
L’activité Web de l’étape 3 a validé le fonctionnement de l’intégration de l’API SERP et démontré l’orchestration du pipeline avec planification. Pour l’étape de collecte et de transformation des données, vous utiliserez un notebook Apache Spark qui appelle directement l’API SERP à l’aide de Python, enregistre les réponses brutes dans votre lac de données et les transforme en tables Delta prêtes à être analysées.
Cette approche est courante en ingénierie des données : les pipelines gèrent l’orchestration et la planification, tandis que les notebooks gèrent la logique de traitement des données proprement dite.
Créer un notebook Spark
- Accédez à Develop > + > Notebook.
- Nommez-le
TransformSERPData. - Attachez-le à votre pool Apache Spark
sparkpool. - Assurez-vous que PySpark (Python) est sélectionné comme langage.
Cellule 1 : collecter les données SERP et les enregistrer dans le lac de données
Dans la première cellule, ajoutez le code suivant. Cela appelle l’API SERP de Bright Data pour chaque mot-clé et enregistre les réponses JSON brutes dans votre lac de données :
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Configuration
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
ZONE = « VOTRE_ZONE_API_SERP »
STORAGE_ACCOUNT = « VOTRE_COMPTE_STOCKAGE »
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Collecter les données SERP pour chaque mot-clé
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Appeler l'API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zone": Zone,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# Enregistrer le JSON brut dans le lac de données
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"Saved: {path}")Remplacez YOUR_BRIGHT_DATA_API_KEY, YOUR_SERP_API_ZONE et YOUR_STORAGE_ACCOUNT par vos valeurs réelles.
Conseil de sécurité: en production, stockez votre clé API dans Azure Key Vault et récupérez-la à l’aide de
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")au lieu de la coder en dur.
Exécutez la cellule en appuyant sur Maj + Entrée. Vous devriez voir un résultat confirmant que chaque fichier a été enregistré dans le lac de données.
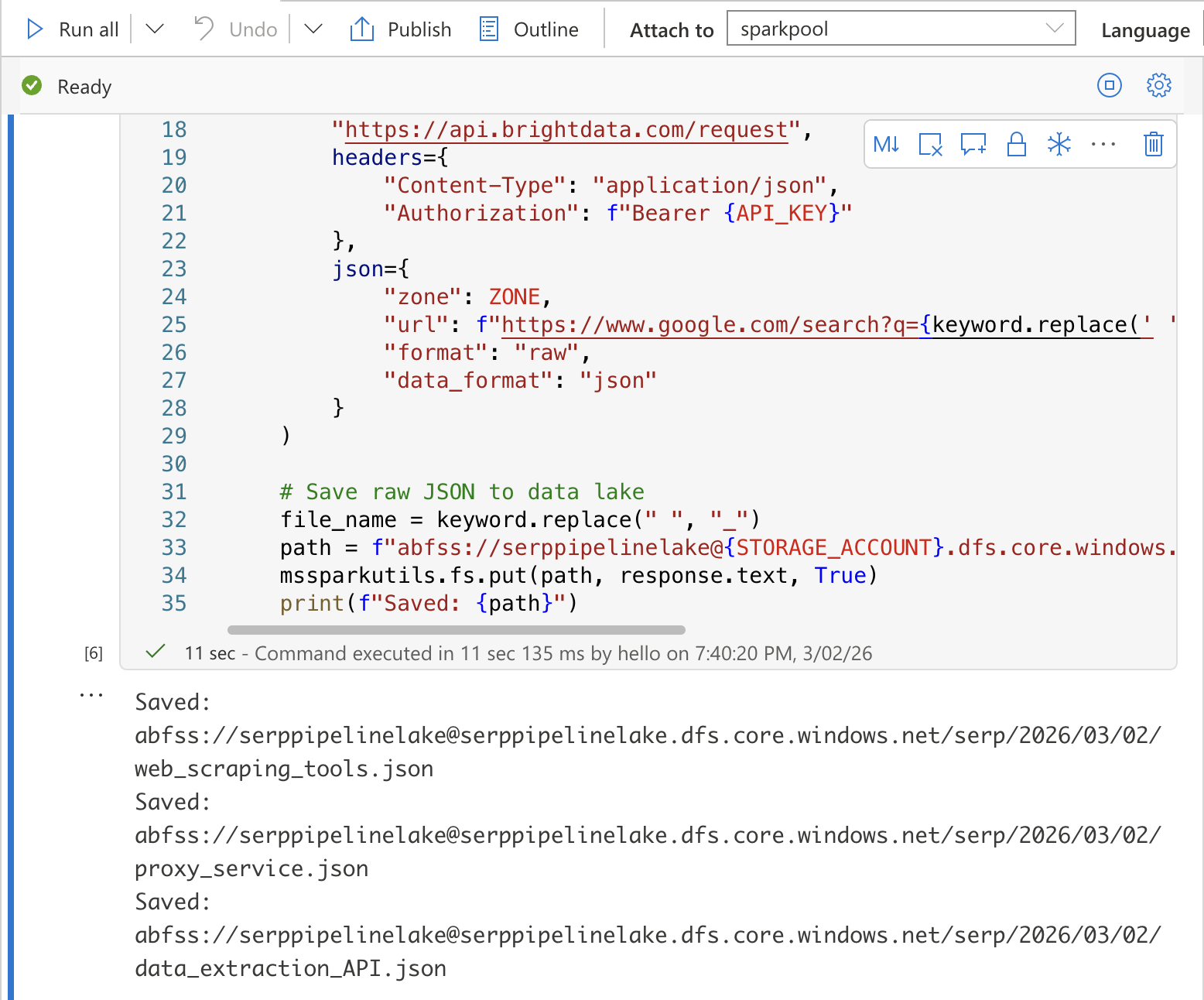
Cellule 2 : Transformez et aplatissez les données SERP
Dans une nouvelle cellule, ajoutez le code de transformation qui lit le JSON brut et l’aplatit en un tableau structuré :
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# Lire les données SERP brutes à partir du lac de données
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# Aplatir : extraire le mot-clé de general.query et explorer les résultats organiques
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
# Afficher un aperçu
display(serp_flattened)Exécutez la cellule. Vous devriez voir un tableau d’aperçu affichant les résultats SERP aplatis avec des colonnes pour le mot-clé, le classement, le titre, l’URL, l’extrait et l’horodatage de la collecte.
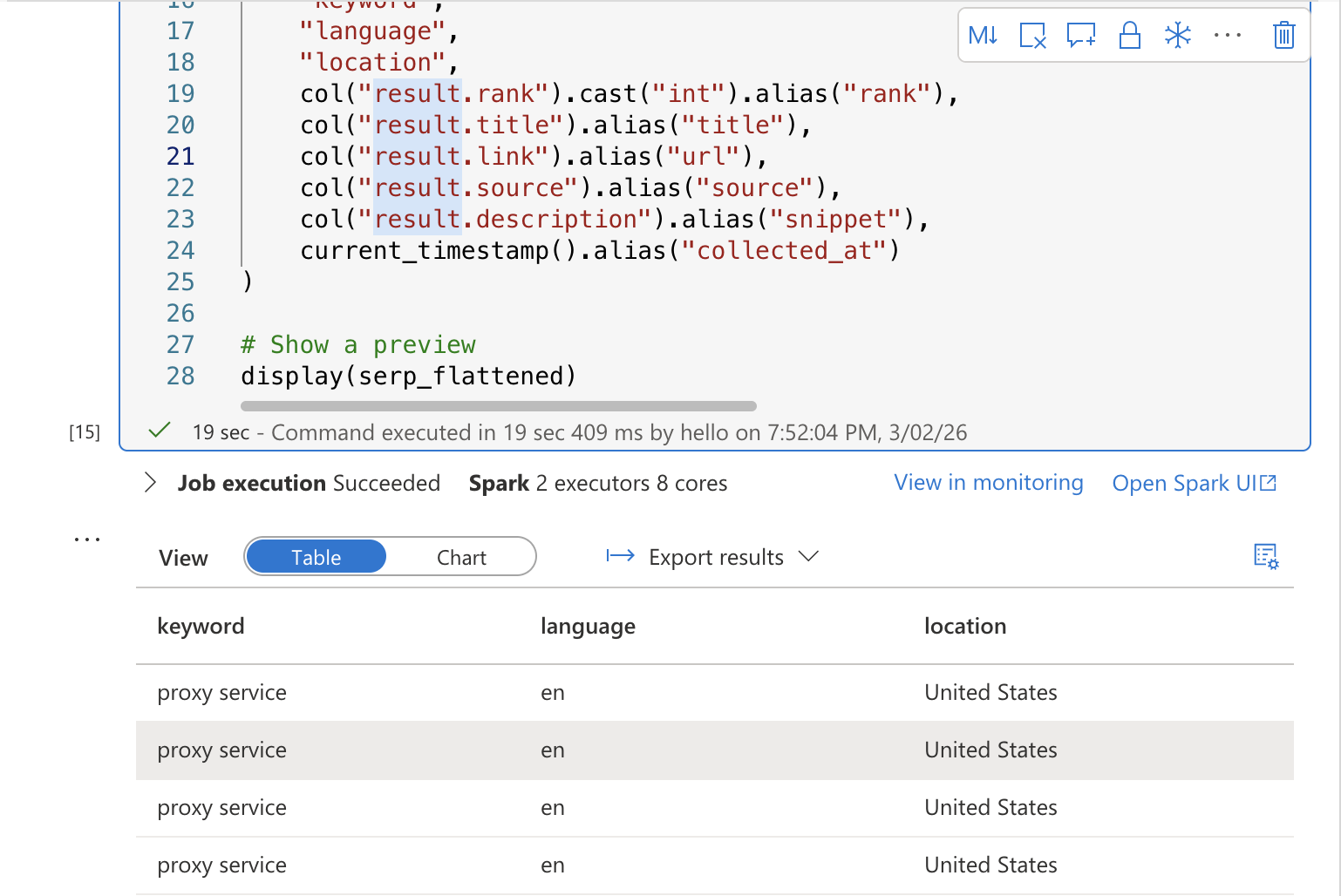
Cellule 3 : enregistrer dans une table Delta
Dans une troisième cellule, écrivez les données transformées dans une table Delta pour l’analyse SQL :
# Écrire les données transformées sous forme de table Delta dans votre lac de données
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("Données écrites dans curated/serp_rankings") 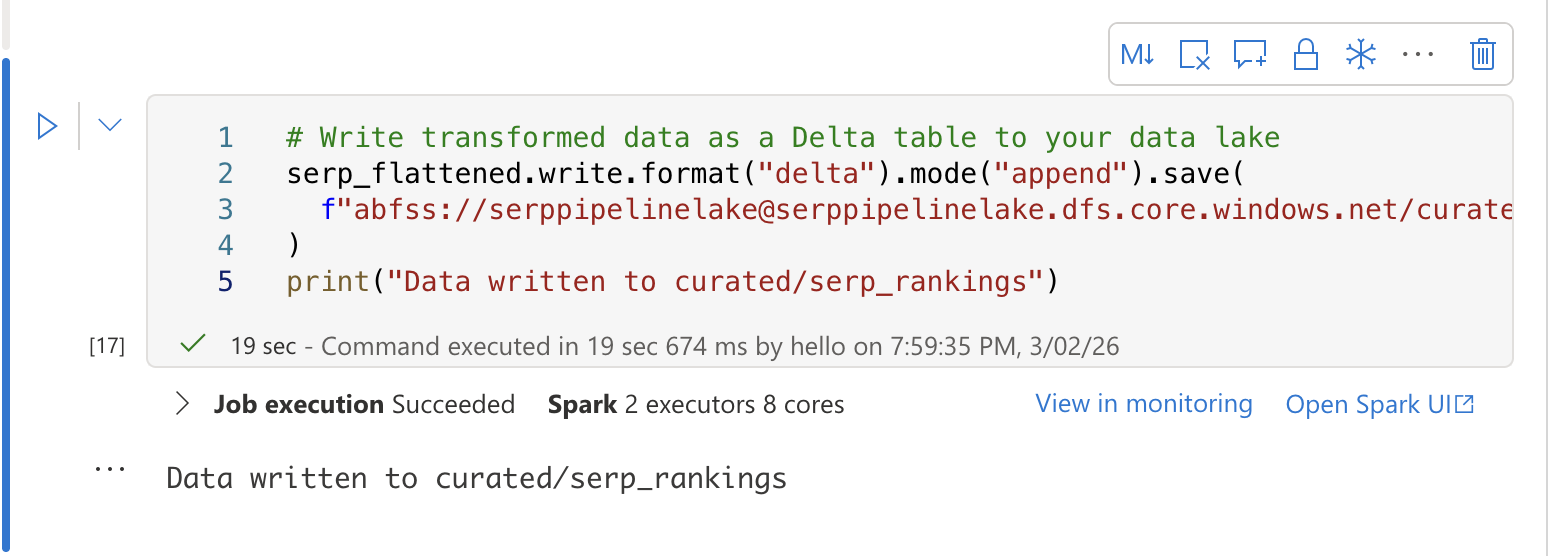
Ajoutez le notebook à votre pipeline
- Revenez à votre pipeline
IngestSERPDatadans le hub Integrate. - Faites glisser une activité Notebook sur le canevas, à l’extérieur et après l’activité ForEach.
- Dans l’onglet Settings, sélectionnez votre notebook
TransformSERPDataet associez-le àsparkpool. - Connectez l’activité ForEach à l’activité Notebook avec une dépendance Success (faites glisser la flèche verte).
- Cliquez sur Publier tout pour enregistrer.
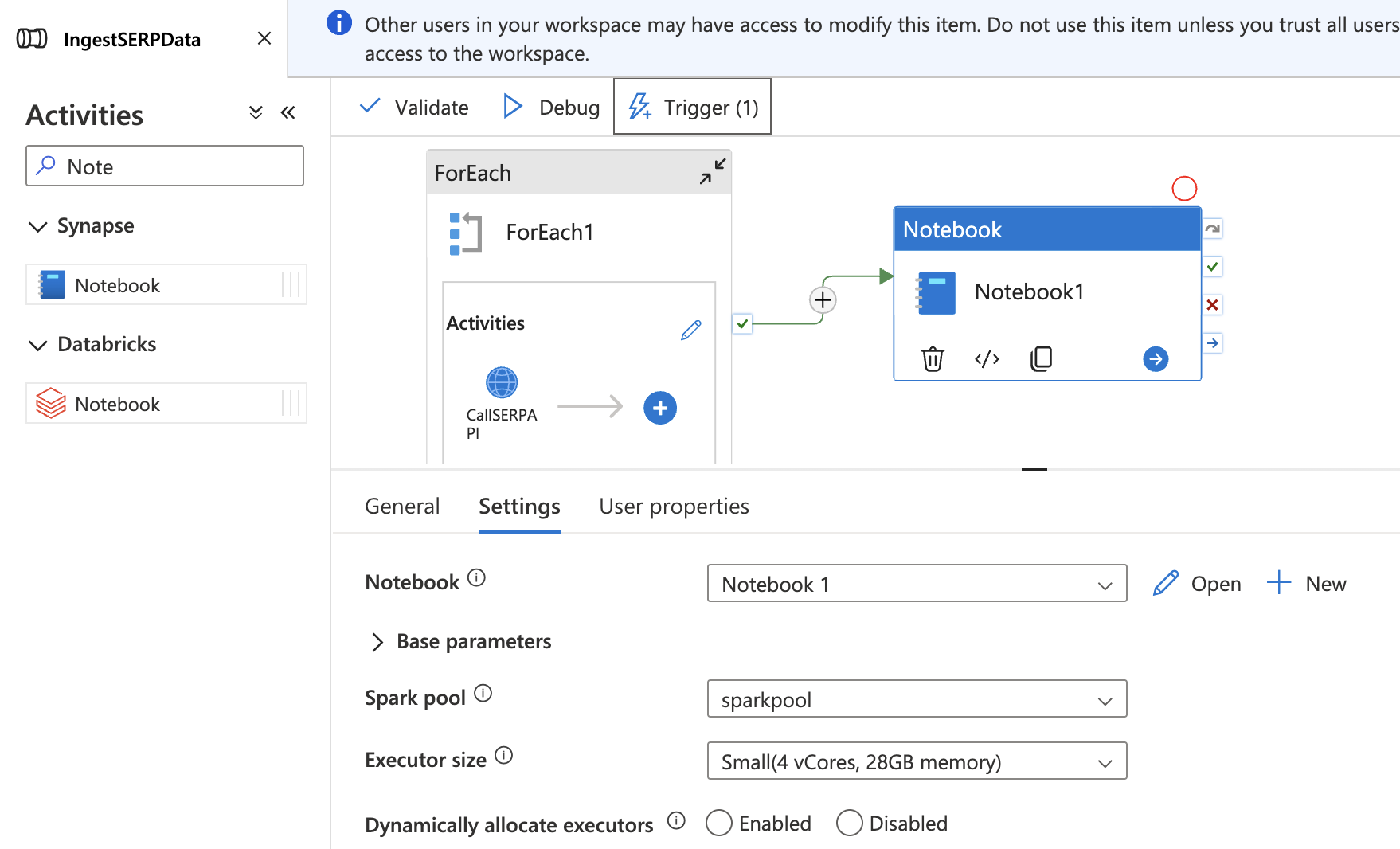
Le pipeline complet s’exécute désormais de bout en bout : collecte des données SERP → transfert vers le lac de données → transformation en table Delta.
Étape 5 : analyser les classements avec SQL
Une fois vos données dans une table Delta, vous pouvez les interroger directement à l’aide du pool SQL sans serveur de Synapse, sans provisionnement supplémentaire. Le pool SQL sans serveur lit les fichiers Delta directement à partir de votre lac de données à l’aide de la fonction OPENROWSET.
Créer une base de données
Accédez à Développer > + > Script SQL. Assurez-vous que Intégré (sans serveur) est sélectionné comme pool SQL en haut de l’éditeur de script. Exécutez la commande suivante pour créer une base de données dédiée à l’analyse SERP :
CREATE DATABASE serp_analytics;Une fois la base de données créée, passez à celle-ci en sélectionnant serp_analytics dans le menu déroulant des bases de données en haut de l’éditeur de script.
Suivre l’évolution du classement au fil du temps
Créez un nouveau script SQL (ou effacez le précédent) et exécutez la requête suivante. Celle-ci lit la table Delta directement à partir de votre lac de données à l’aide de OPENROWSET:
-- Observez l'évolution quotidienne du classement pour chaque mot-clé et URL
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = 'Scraping web tools'
ORDER BY collected_at DESC, rank ASC;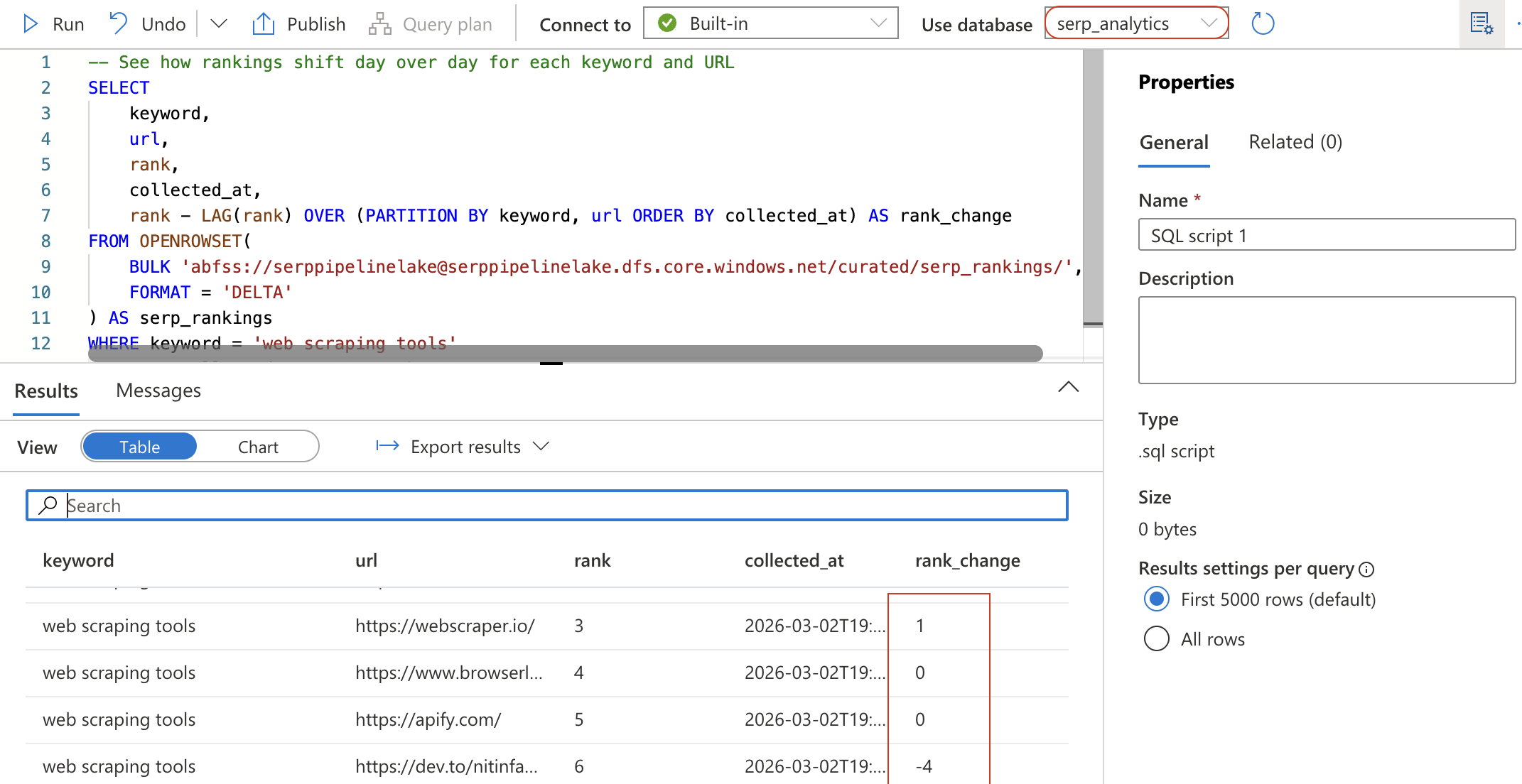
Cette requête utilise la fonction de fenêtre LAG pour calculer l’évolution de la position de chaque URL depuis la collecte précédente. Une valeur négative pour rank_change signifie que l’URL a progressé dans le classement.
Créer une vue récapitulative pour Power BI
Pour que les données soient facilement exploitables par Power BI, créez une vue qui résume les classements quotidiens par mot-clé :
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
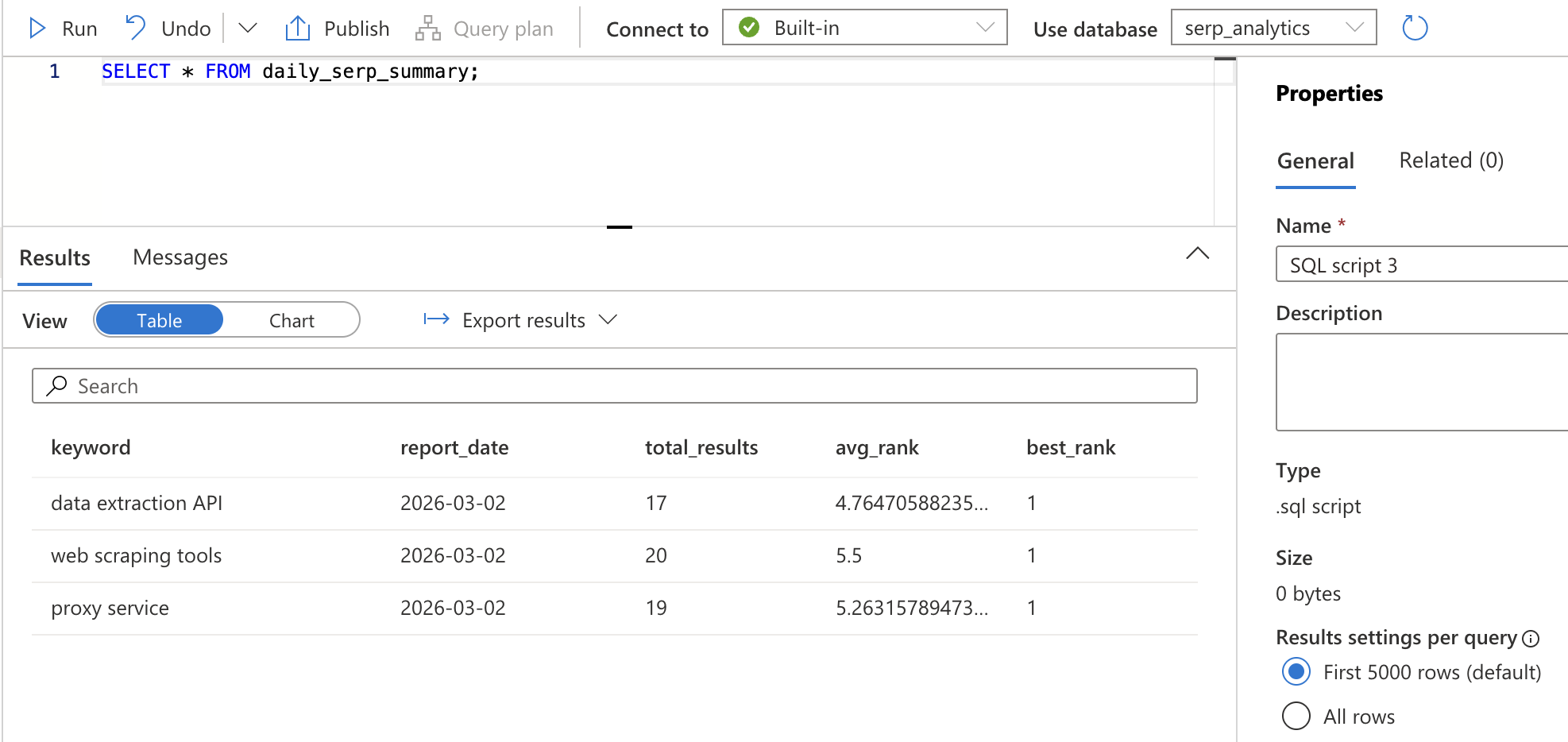
GROUP BY keyword, CAST(collected_at AS DATE);Cliquez sur Exécuter. Cela crée une vue, c’est-à-dire une requête enregistrée qui peut être référencée par son nom. Vérifiez qu’elle fonctionne en exécutant :
SELECT * FROM daily_serp_summary;Vous devriez voir une ligne par mot-clé et par jour, avec le nombre total de résultats, le classement moyen et le meilleur classement.
Étape 6 : inspecter les résultats
Une fois le pipeline complet exécuté, vous pouvez inspecter chaque étape à partir de Synapse Studio.
Accédez à Monitor > Pipeline runs (Moniteur > Exécutions du pipeline) et cliquez sur la dernière exécution pour l’inspecter. Vous verrez une représentation visuelle de chaque étape, indiquant :
- L’activité ForEach avec chaque itération de mot-clé et les résultats de l’activité Web.
- L’activité Notebook avec les détails d’exécution de la tâche Spark.
Développez l’activité ForEach pour vérifier que les données SERP ont été récupérées avec succès pour chaque mot-clé. Cliquez sur n’importe quelle exécution de l’activité Web CallSERPAPI pour afficher les détails de la requête/réponse dans les sections Input et Output.
Accédez à Données > Lié > votre compte de stockage pour parcourir les fichiers JSON bruts dans le dossier raw/serp/. Vous devriez voir des dossiers partitionnés par date avec un fichier JSON par mot-clé.
Enfin, ouvrez le hub Develop, accédez à votre notebook TransformSERPData et vérifiez la table Delta en exécutant :
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;Vous devriez voir des lignes structurées avec le mot-clé, le classement, le titre, l’URL, l’extrait et l’horodatage de la collecte, des données propres et prêtes à être analysées, construites à partir des résultats SERP bruts. L’API SERP de Bright Data s’est chargée de la partie difficile : récupérer de manière fiable les résultats de recherche Google à grande échelle, contourner les mesures anti-bot et les limiteurs de débit, et renvoyer des données structurées prêtes pour votre pipeline.
Aller plus loin
Cet exemple montre un outil de suivi du classement des mots-clés, mais vous pouvez étendre votre pipeline Synapse dans de nombreuses directions :
- Remplacez l’appel API SERP par l’API Web Scraper de Bright Data pour collecter les prix des produits, les avis ou les offres d’emploi, et créer des tableaux de bord d’intelligence compétitive sur les prix.
- Ajoutez un deuxième notebook Spark pour effectuer une analyse des sentiments sur les extraits SERP, en attribuant à chaque résultat une note positive ou négative.
- Connectez les tables Delta organisées à Azure Machine Learning pour effectuer des analyses prédictives, telles que la prévision des changements de classement ou l’identification des nouvelles tendances de recherche.
- Créez une architecture cloud hybride où les données SERP sont stockées dans Azure Data Lake tandis que les données internes sensibles restent sur site, Synapse interrogeant les deux via des requêtes fédérées.
- Transférez les données transformées vers un flux Azure AI Foundry pour une analyse alimentée par LLM, combinant l’ingénierie des données de Synapse avec les capacités d’IA d’AI Foundry.
- Intégrez des outils tels que LangChain ou CrewAI pour créer des workflows agents qui utilisent vos données SERP sélectionnées.
Les possibilités sont pratiquement infinies !
Conclusion
Dans cet article de blog, vous avez appris à utiliser l’API SERP de Bright Data pour récupérer les derniers résultats de recherche de Google et les intégrer dans un pipeline de données complet dans Azure Synapse Analytics.
Le pipeline présenté ici est idéal pour tous ceux qui souhaitent créer un outil automatisé de suivi du classement des mots-clés qui collecte en continu les données SERP, les transforme en tableaux prêts à être analysés et fournit des informations via des requêtes SQL et des tableaux de bord Power BI. Contrairement à l’approche Azure AI Foundry, qui est idéale pour l’ingénierie de prompt IA-first et les workflows RAG, Azure Synapse Analytics excelle dans l’ingestion, la transformation et le stockage de données à grande échelle pour la veille économique et l’analyse.
Pour créer des pipelines de données plus avancés, explorez la suite complète d’outils de Scraping web de Bright Data pour récupérer, valider et transformer des données web en temps réel. Pour en savoir plus sur les modèles d’architecture de pipelines de données, consultez le blog Bright Data qui en présente les principes fondamentaux.
Inscrivez-vous dès aujourd’hui pour obtenir un compte Bright Data gratuit et commencez à tester nos solutions de données web prêtes pour l’IA !