

Dans cet article de blog, vous découvrirez :
- Ce qu’est AutoGPT et ce qui le rend spécial en tant que framework de création d’agents IA.
- Pourquoi les agents AutoGPT tirent parti de l’accès à des fonctionnalités de recherche sur le Web, d’exploration, d’interaction et d’extraction de données.
- Comment Bright Data peut être intégré à AutoGPT pour doter les agents IA précisément de ces fonctionnalités.
C’est parti !
Qu’est-ce qu’AutoGPT ?
AutoGPT est une plateforme open source permettant de créer, de déployer et d’exécuter des agents IA autonomes.
Elle se distingue par son interface low-code basée sur des blocs, l’exécution continue des agents et la possibilité de connecter des outils, des API et des sources de données dans des pipelines d’automatisation de bout en bout.
Contrairement à de simples scripts, les agents AutoGPT peuvent fonctionner en continu, réagir à des déclencheurs et gérer des tâches en plusieurs étapes. Le projet bénéficie du soutien d’une vaste communauté open source. Il a rencontré un succès impressionnant sur GitHub, avec plus de 183 000 étoiles.
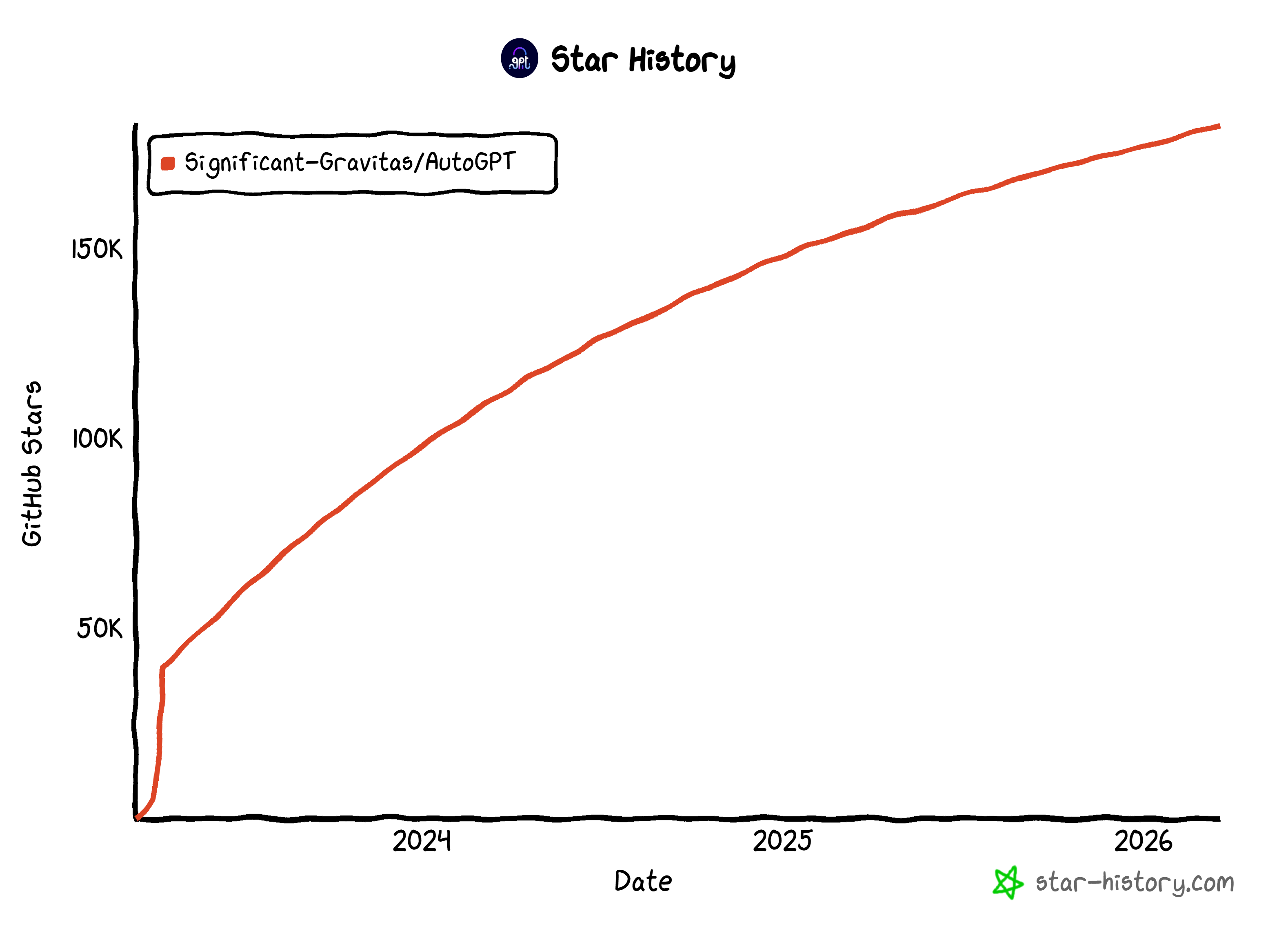
Ces statistiques en font l’un des frameworks d’agents IA les plus populaires à l’heure actuelle.
Pourquoi intégrer des capacités d’exploration Web et de récupération de données dans AutoGPT
Il ne fait aucun doute qu’AutoGPT est une solution riche en fonctionnalités. Pourtant, tous les agents IA basés sur des LLM sont confrontés à des limites inhérentes. Les modèles linguistiques standard sont entraînés sur des Jeux de données statiques, ce qui signifie que leurs connaissances sont figées à un moment précis.
Cela peut entraîner des informations obsolètes, des hallucinations ou des lacunes lorsque les agents tentent d’accomplir des tâches du monde réel nécessitant des données à jour. De plus, les LLM ne peuvent pas interagir avec le monde réel, y compris le Web. Les agents IA de base sont donc limités par ces contraintes inhérentes.
AutoGPT inclut certes des outils natifs pour la recherche sur le Web, l’exploration et d’autres interactions. Cependant, ces capacités intégrées peuvent rencontrer des difficultés en termes d’évolutivité, de fiabilité et de mesures anti-bot sophistiquées par rapport aux solutions de niveau entreprise.
C’est là qu’intervient Bright Data. S’appuyant sur l’un des plus grands réseaux de Proxies au monde — avec plus de 150 millions d’adresses IP réparties dans 195 pays —, son infrastructure offre une disponibilité de 99,99 % et une concurrence illimitée.
L’intégration de Bright Data à AutoGPT permet aux agents d’accéder au contenu web en temps réel, aux résultats de recherche et aux données structurées de n’importe quel site web. Plus précisément, les principaux produits Bright Data susceptibles d’améliorer les workflows d’AutoGPT comprennent :
- API Web Unlocker: accédez au contenu de n’importe quel site web au format HTML brut ou Markdown, en contournant les CAPTCHA et les protections anti-bot.
- API SERP: collectez les résultats de recherche de Google, Bing, Yandex et de nombreux autres moteurs de recherche.
- API Web Scraper: extraient des données structurées de plateformes telles qu’Amazon, LinkedIn, Instagram et Yahoo Finance.
- API Crawl: convertit des sites web entiers en jeux de données structurés pour le traitement IA en aval.
En combinant les capacités agentiques d’AutoGPT avec les solutions de Bright Data, les agents IA peuvent récupérer de manière autonome des informations en temps réel et exécuter des workflows complexes bien au-delà des limites des LLM standard.
Comment intégrer Bright Data dans AutoGPT : guide étape par étape
Dans cette section guidée, vous apprendrez à créer un agent IA dans AutoGPT qui s’intègre à Bright Data pour la récupération de données Web.
Cet agent agira notamment comme un assistant de mise en favoris, vous aidant à décider si un article en ligne mérite d’être enregistré pour une lecture ultérieure. Il s’agit simplement d’un exemple simple pour illustrer l’intégration, mais de nombreux autres cas d’utilisation sont possibles.
Suivez les instructions ci-dessous !
Prérequis
Pour héberger AutoGPT vous-même, assurez-vous que votre système répond aux exigences matérielles suivantes :
- Système d’exploitation: Linux (Ubuntu 20.04 ou version plus récente recommandée), macOS (10.15 ou version plus récente) ou Windows 10/11 avec WSL2.
- Processeur: 4 cœurs ou plus recommandés.
- Mémoire vive: 8 Go minimum (16 Go recommandés).
- Stockage: au moins 10 Go d’espace libre.
Vous devez également avoir installé les outils suivants localement sur votre machine :
- Docker Engine 20.10.0 ou version ultérieure
- Docker Compose 2.0.0+
- Git 2.30+
- Node.js 16.x+ (avec npm 8.x+)
- Visual Studio Code 1.60+ ou tout autre éditeur de code moderne
De plus, assurez-vous que les conditions suivantes sont remplies :
- Une connexion Internet stable.
- Accès aux ports requis (qui seront configurés via Docker).
- Possibilité d’établir des connexions HTTPS sortantes.
Pour implémenter l’agent IA dans AutoGPT, vous aurez également besoin :
- Un compte Bright Data avec une zone API Web Unlocker configurée et une clé API définie.
- Une clé API provenant de l’un des fournisseurs LLM pris en charge par AutoGPT (dans cet exemple, nous utiliserons OpenAI).
Ne vous inquiétez pas pour la configuration de votre compte Bright Data pour l’instant, car vous serez guidé tout au long de ce processus dans un chapitre dédié.
Étape n° 1 : Installer AutoGPT localement
Assurez-vous que votre système répond aux prérequis matériels, logiciels et réseau. Vérifiez également que Docker est opérationnel.
Pour simplifier le processus de configuration de l’auto-hébergement d’AutoGPT, l’approche recommandée consiste à utiliser le script d’installation officiel en une seule ligne. Celui-ci installe toutes les dépendances requises, récupère le code le plus récent et lance l’application pour vous.
Sous macOS ou Linux, exécutez le script d’installation en une ligne avec :
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.shDe même, sous Windows, exécutez la commande suivante dans PowerShell :
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"Le processus d’installation peut prendre quelques minutes, alors soyez patient. Une fois terminé, vous devriez voir un résultat similaire à celui-ci :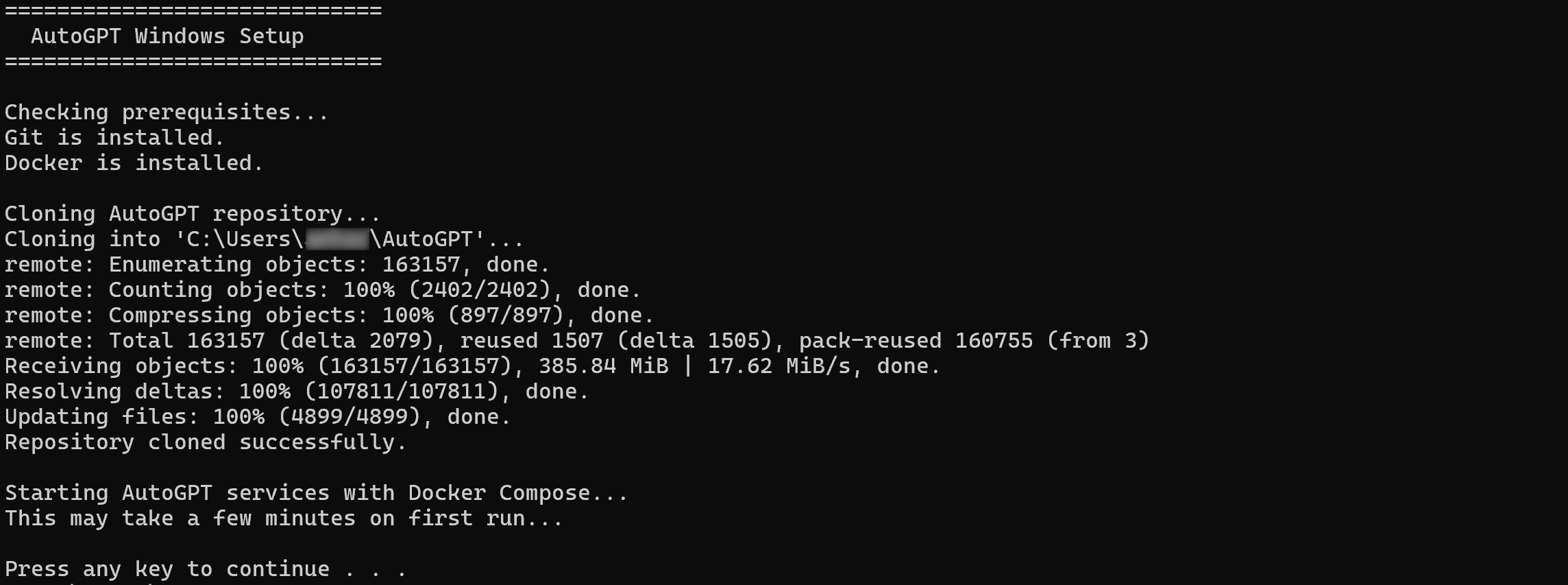
Parfait ! À ce stade, AutoGPT devrait être correctement configuré localement et prêt à fonctionner.
Étape n° 2 : Lancer la plateforme
Accédez au dossier d’installation :
cd AutoGPT/autogpt_platformEnsuite, copiez le fichier .env.default fourni avec le dépôt cloné vers .env:
cp .env.default .envCette commande crée un fichier .env dans le répertoire autogpt_platform en utilisant la configuration par défaut. Modifiez ce fichier pour définir vos propres variables d’environnement uniquement si vous avez besoin d’une configuration personnalisée. Sinon, conservez les valeurs par défaut.
Ensuite, démarrez la plateforme AutoGPT avec :
docker compose up -d --buildCette commande compile et lance tous les services backend requis définis dans le fichier docker-compose.yml en mode détaché.
Une fois les services opérationnels, vérifiez que tout fonctionne en vous rendant sur http://localhost dans votre navigateur.
Par défaut, les différents services AutoGPT sont disponibles à l’adresse suivante :
- Serveur d’interface utilisateur front-end:
http://localhost. - Serveur WebSocket backend:
http://localhost:8001. - Serveur REST de l’API d’exécution:
http://localhost:8006.
Voici ce que vous devriez voir :
Inscrivez-vous en créant votre compte. Une fois connecté, vous serez redirigé vers l’Agent Builder dans l’interface utilisateur d’AutoGPT:
Super ! Vous êtes désormais prêt à créer votre premier agent et à le connecter à Bright Data.
Étape n° 3 : Concevoir le workflow de l’agent IA
AutoGPT propose plusieurs blocs, chacun gérant une action ou une tâche spécifique. Dans cet exemple, vous souhaitez créer un workflow d’agent qui :
- Accepte l’URL d’un article (provenant de n’importe quel site) en entrée.
- Récupère le contenu de l’article au format Markdown à l’aide de l’API Bright Data Web Unlocker.
- Transmette le contenu à un LLM afin de générer une note de 1 à 10 indiquant dans quelle mesure l’article mérite d’être ajouté aux favoris, ainsi qu’un commentaire de type humain expliquant cette note.
- Renvoie le résultat structuré.

Dans AutoGPT, ce workflow peut être mis en œuvre à l’aide des blocs suivants :
- Entrée de l’agent: accepte l’URL de l’article fournie par l’utilisateur.
- Créer un dictionnaire: construit le corps de la requête pour l’API Bright Data Web Unlocker à l’aide de l’URL fournie.
- Envoyer une requête Web authentifiée: envoie la requête à l’API Bright Data Web Unlocker et récupère le contenu de l’article.
- Générateur de réponse structurée par IA: transmet le contenu de l’article au LLM et génère une évaluation structurée du signet (note + commentaire).
- Sortie de l’agent: renvoie le résultat structuré final.
Parfait ! Maintenant que les étapes du workflow de l’agent sont claires, la prochaine étape consiste à le mettre en œuvre. Mais avant cela, commençons par Bright Data.
Étape n° 4 : Configurer votre compte Bright Data
Comme indiqué précédemment, le workflow de l’agent IA que vous souhaitez mettre en œuvre s’appuie sur le produit Web Unlocker de Bright Data. Pour vous y connecter dans AutoGPT, vous devez disposer d’un compte Bright Data avec la configuration de la zone API Web Unlocker, ainsi que d’une clé API.
Pour obtenir des conseils rapides, consultez l’article «Guide de démarrage rapide pour l’API Web Unlocker de Bright Data». Vous pouvez également suivre les étapes ci-dessous.
Si vous n’avez pas de compte Bright Data, créez-en un. Sinon, connectez-vous simplement. Accédez au panneau de configuration et rendez-vous sur la page « Proxies & Scraping ». Consultez le tableau « My Zones » :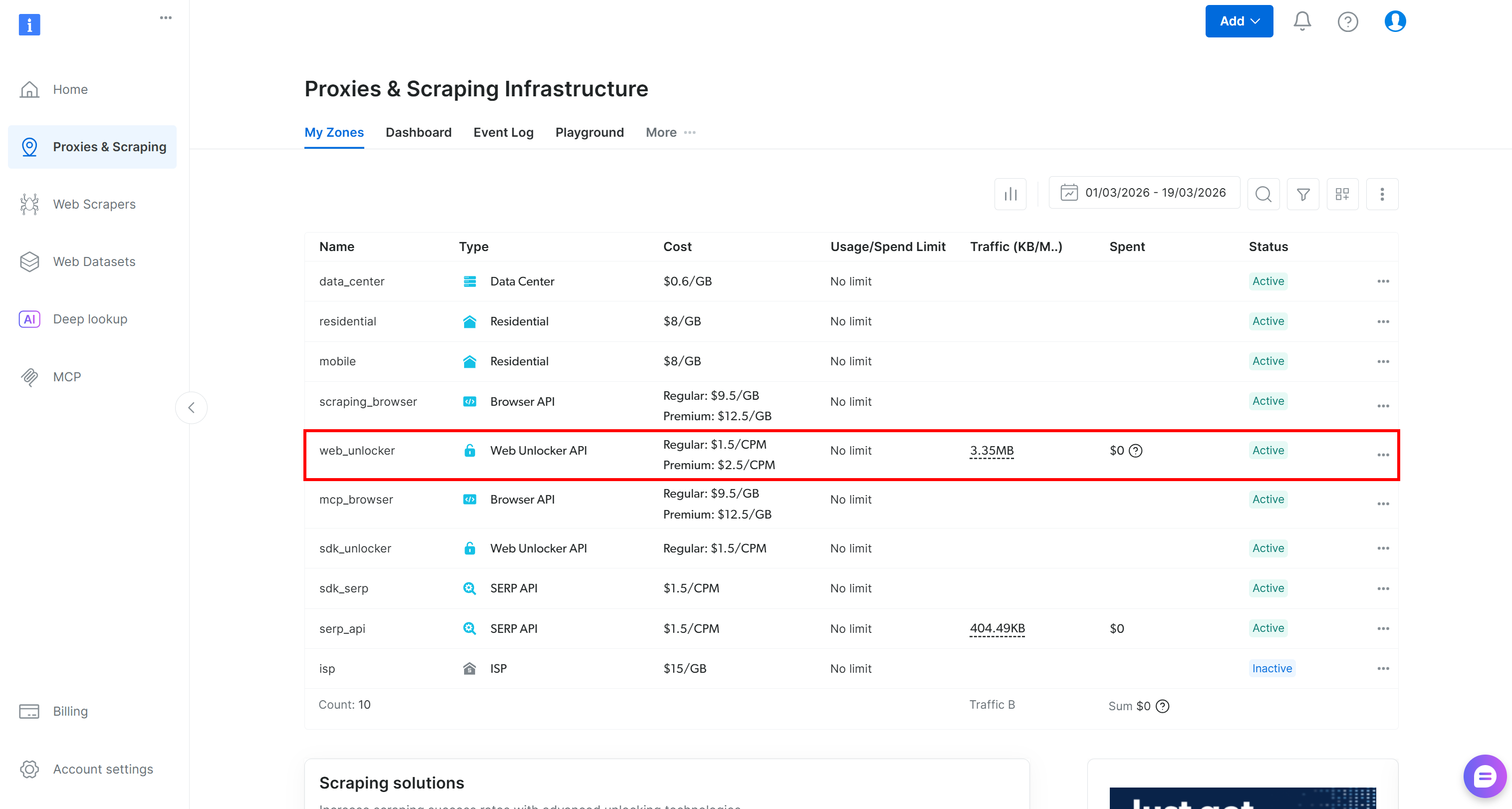
Si une zone Web Unlocker API (par exemple, web_unlocker) existe déjà dans le tableau, vous êtes prêt à commencer.
Si ce n’est pas le cas, vous devez en créer une. Faites défiler jusqu’à la fiche « Unblocker API », cliquez sur le bouton « Créer une zone » et suivez l’assistant.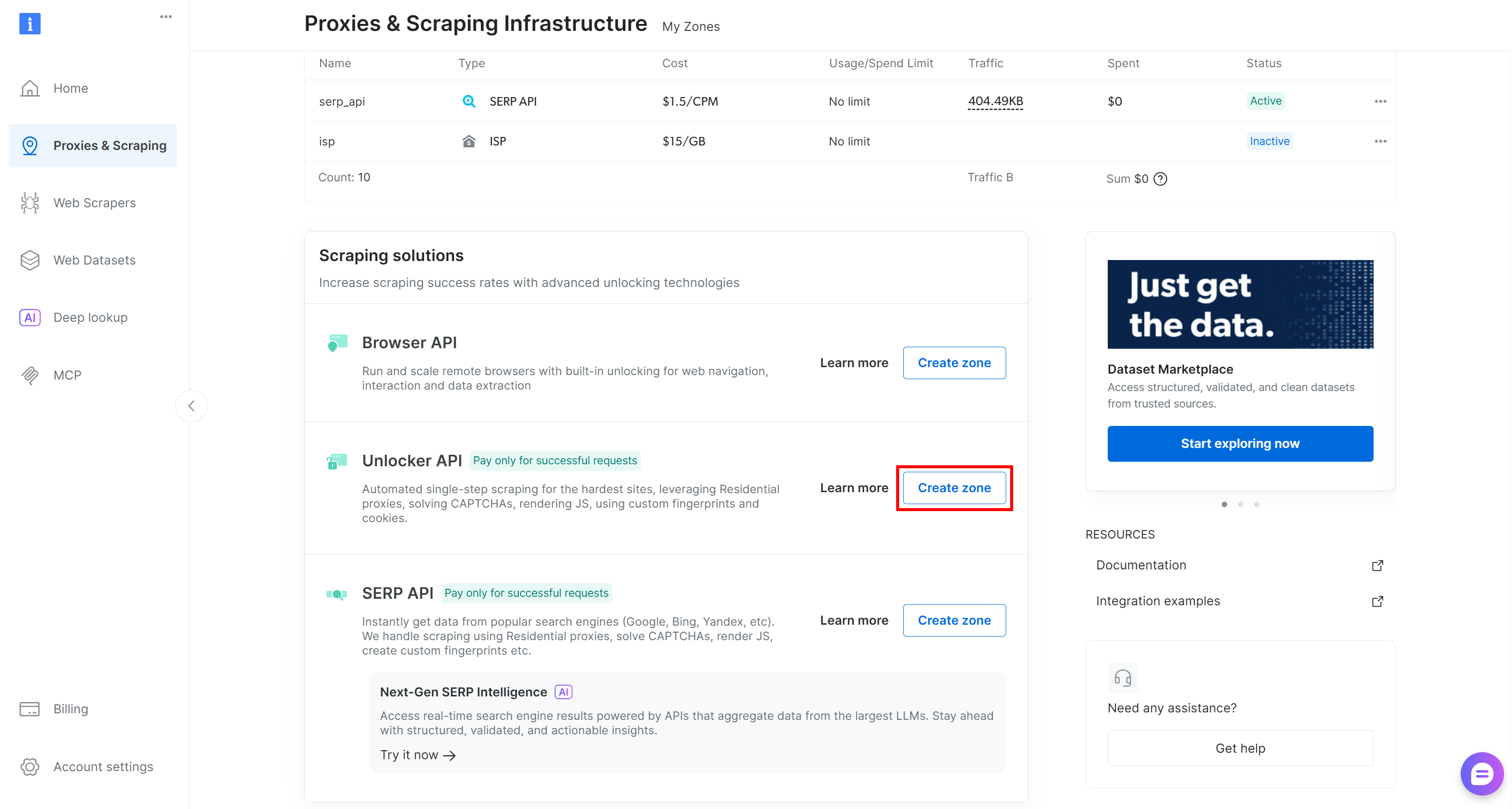
Choisissez soigneusement le nom de votre zone, car vous en aurez besoin plus tard. Dans ce guide, nous supposerons que la zone s’appelle web_unlocker.
Enfin, générez votre clé API Bright Data et conservez-la en lieu sûr. Vous en aurez besoin pour authentifier les requêtes HTTP envoyées par AutoGPT à Bright Data.
Et voilà ! Les prérequis Bright Data sont désormais remplis.
Étape n° 5 : Initialiser l’agent
Chaque workflow d’agent AutoGPT nécessite une entrée et une sortie. Commencez par vous rendre dans la section « Build » pour accéder à la page Agent Builder :
Appuyez sur le bouton « Save », donnez un nom à votre agent, par exemple « Bookmark Likelihood Evaluator », puis cliquez sur « Save Agent » :
Dans la page Agent Builder, cliquez sur le bouton « Blocks » à gauche et ajoutez un bloc « Agent Input » :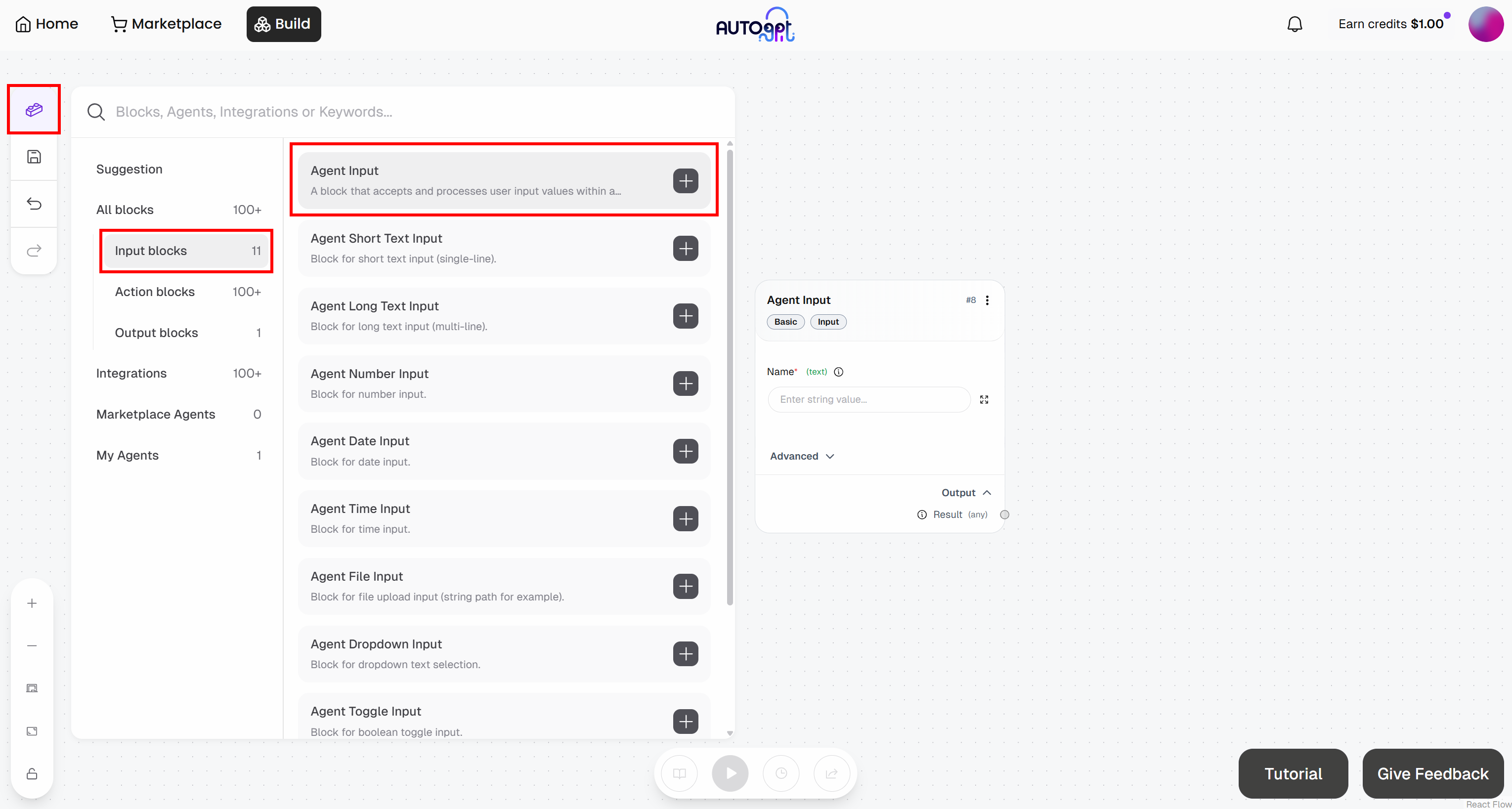
De la même manière, ajoutez un bloc « Agent Output » :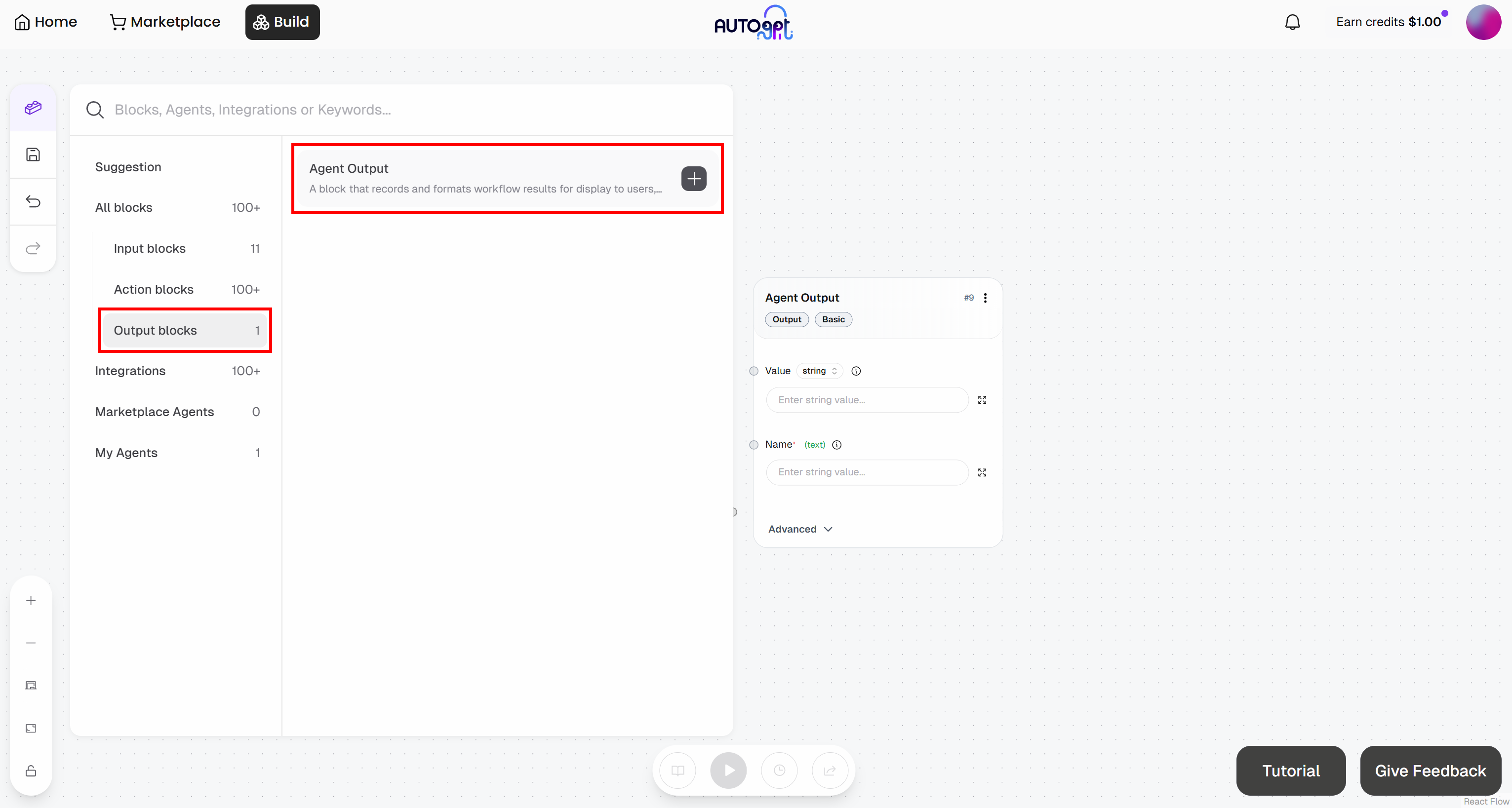
Configurez les blocs comme suit :
- Entrée de l’agent: nommez-le « Article URL »
- Bloc Agent Output: nommez-le « Probabilité de mise en favori »
À ce stade, votre workflow agentique initial devrait ressembler à ceci :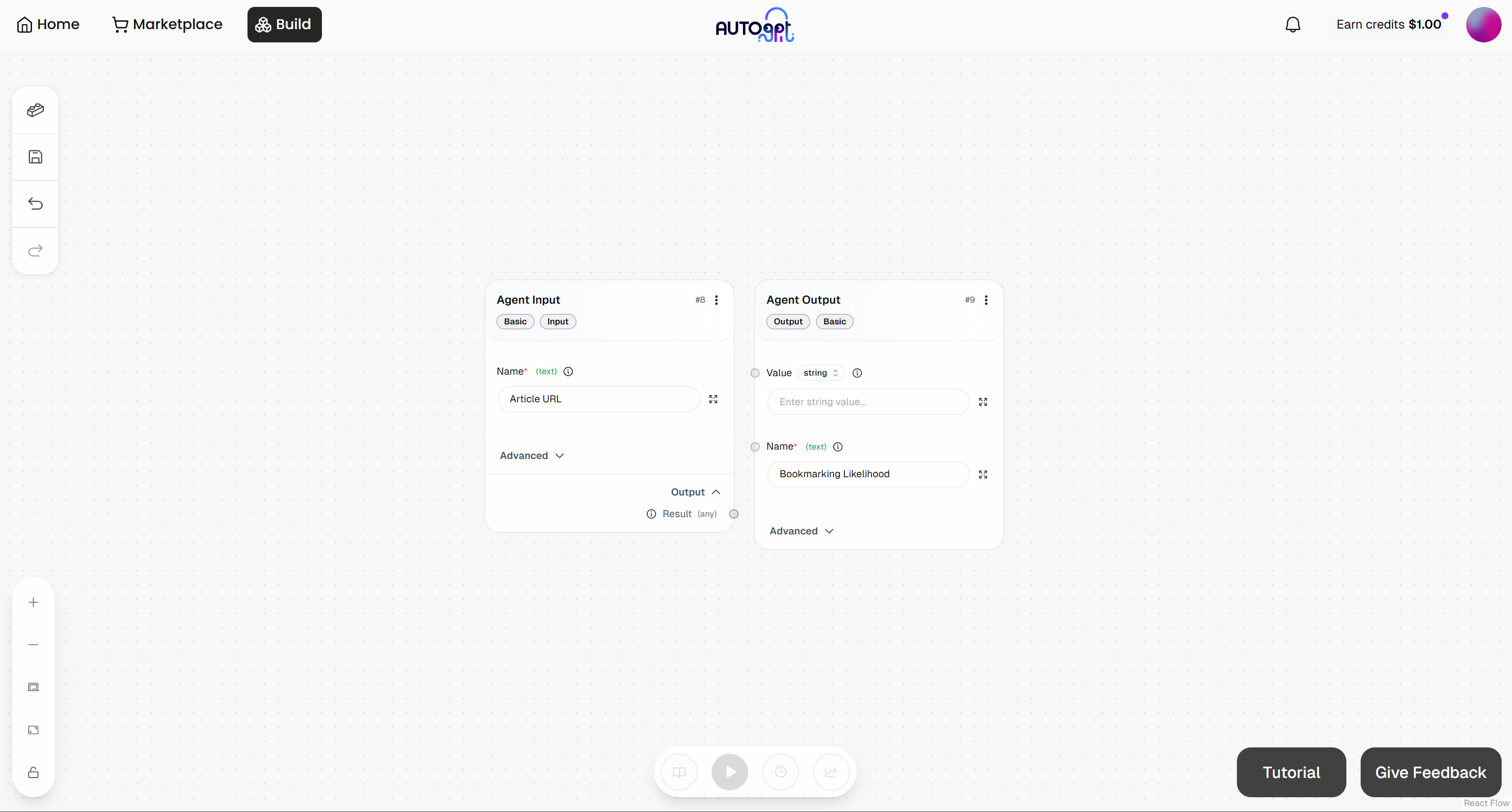
Parfait ! Il est temps de poursuivre la définition du reste de votre workflow agentique.
Étape n° 6 : Effectuer la requête de scraping
Pour effectuer la requête HTTP vers l’API Bright Data Web Unlocker, vous avez besoin de deux blocs :
- Créer un dictionnaire: définit le corps de la requête.
- Envoyer une requête Web authentifiée: envoie la requête authentifiée au point de terminaison Web Unlocker des API Bright Data.
Commencez par ajouter le bloc « Créer un dictionnaire » :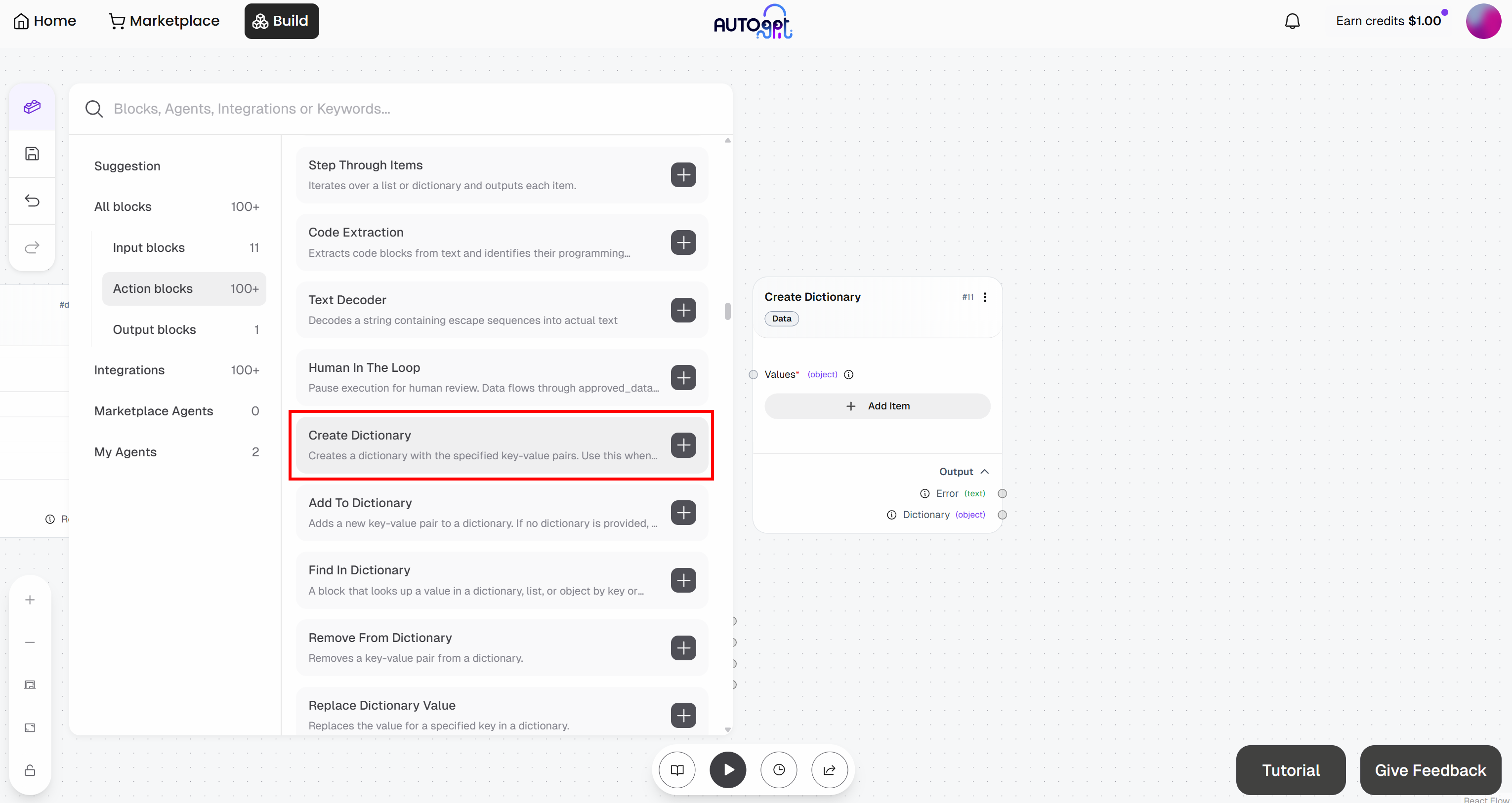
Ajoutez ensuite le bloc « Envoyer une requête Web authentifiée » :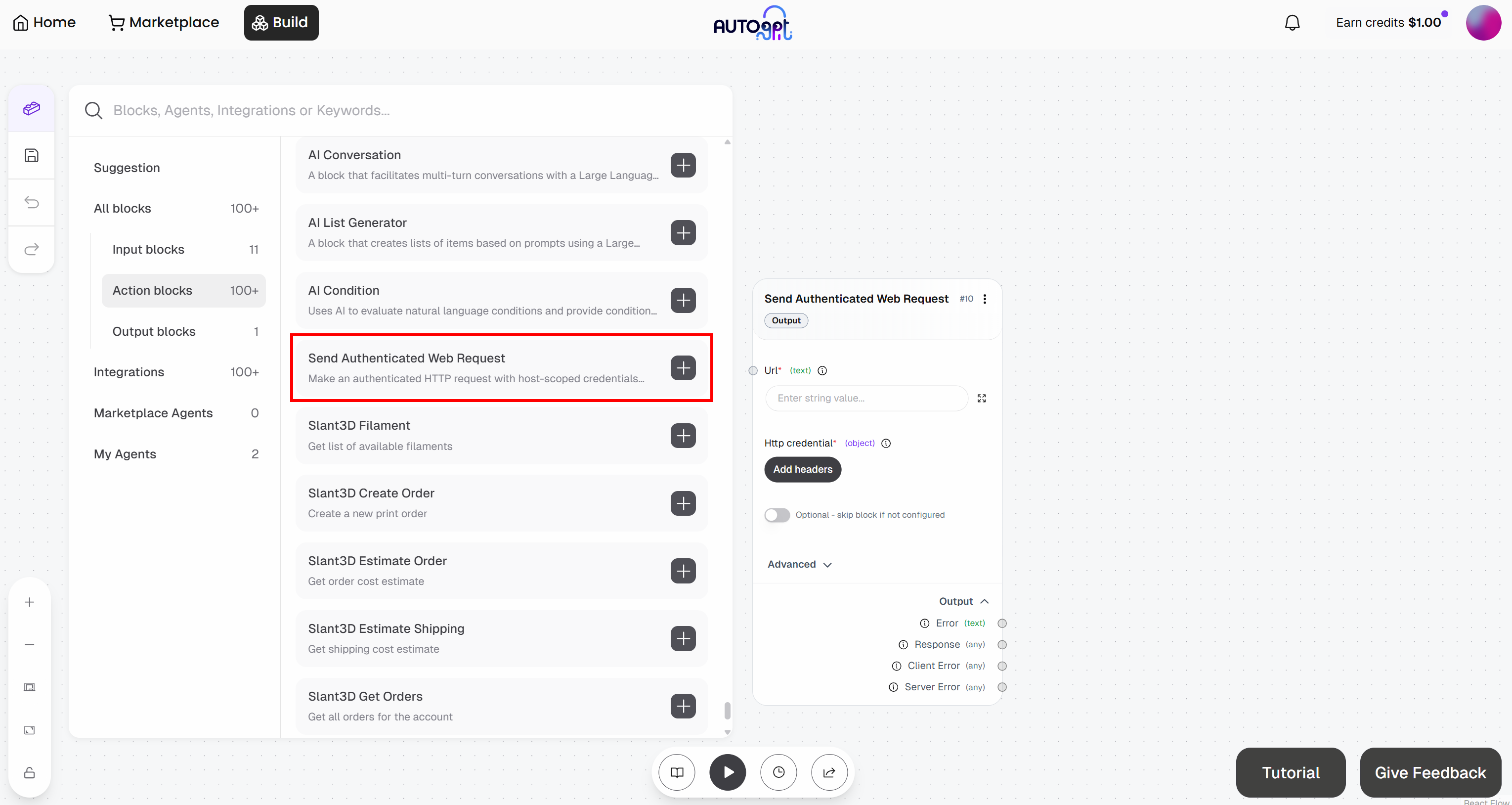
Préparez-vous à configurer le bloc « Envoyer une requête Web authentifiée ». Cela enverra une requête à l’API Web Unlocker. Pour plus de détails sur le fonctionnement de ce point de terminaison et sur la manière de l’appeler, consultez la documentation officielle.
Développez le menu déroulant « Avancé » et remplissez l’ensemble du bloc comme suit :
- URL:
https://api.brightdata.com/request. - Méthode HTTP:
POST
Ensuite, cliquez sur le bouton « Ajouter des en-têtes » sous « Informations d’identification HTTP » :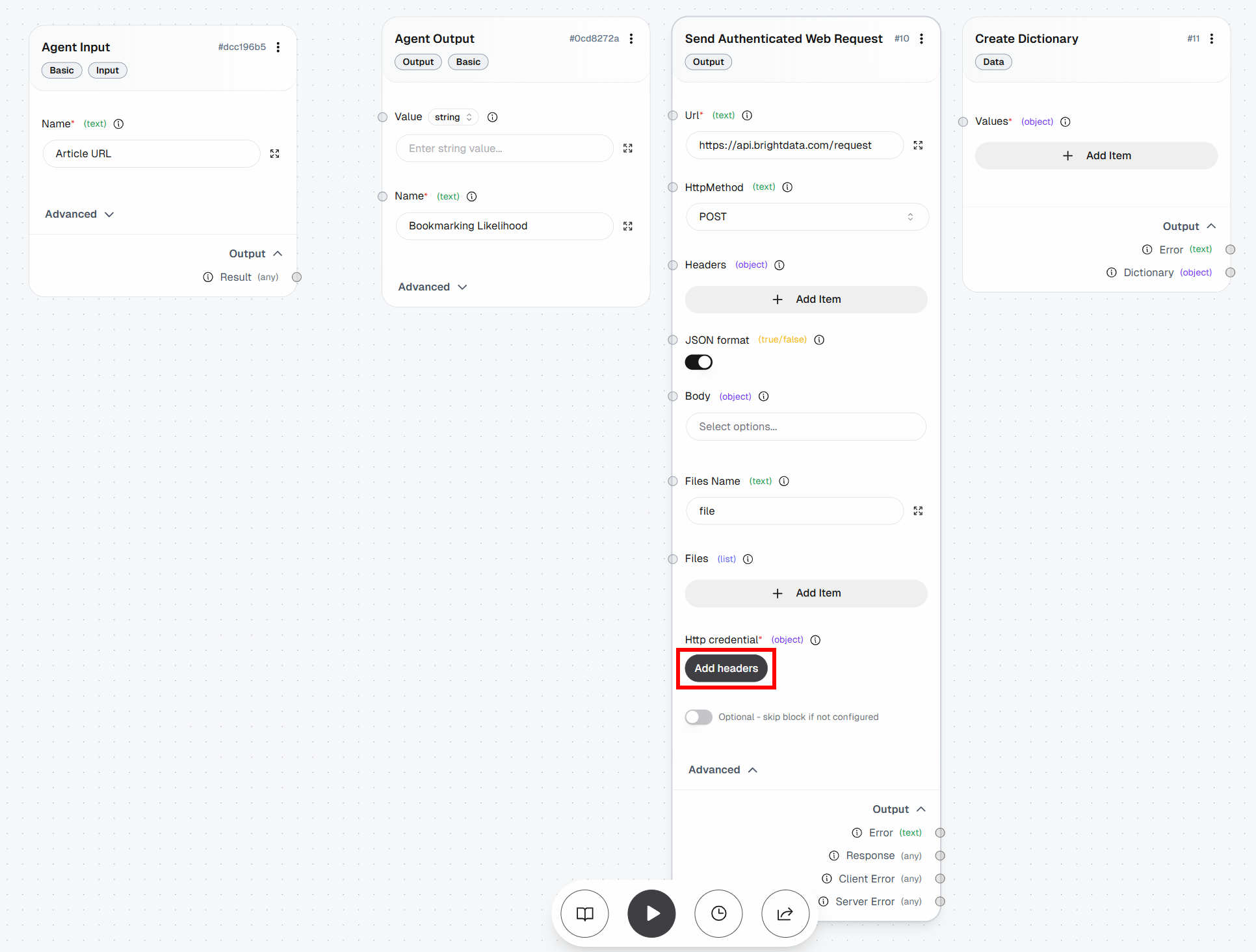
Configurez l’authentification par en-tête comme suit :
- Nom de l’en-tête:
Authorization - Valeur de l’en-tête:
Bearer <VOTRE_CLÉ_API_BRIGHT_DATA>
N’oubliez pas de remplacer le paramètre <YOUR_BRIGHT_DATA_API_KEY> par votre clé API Bright Data.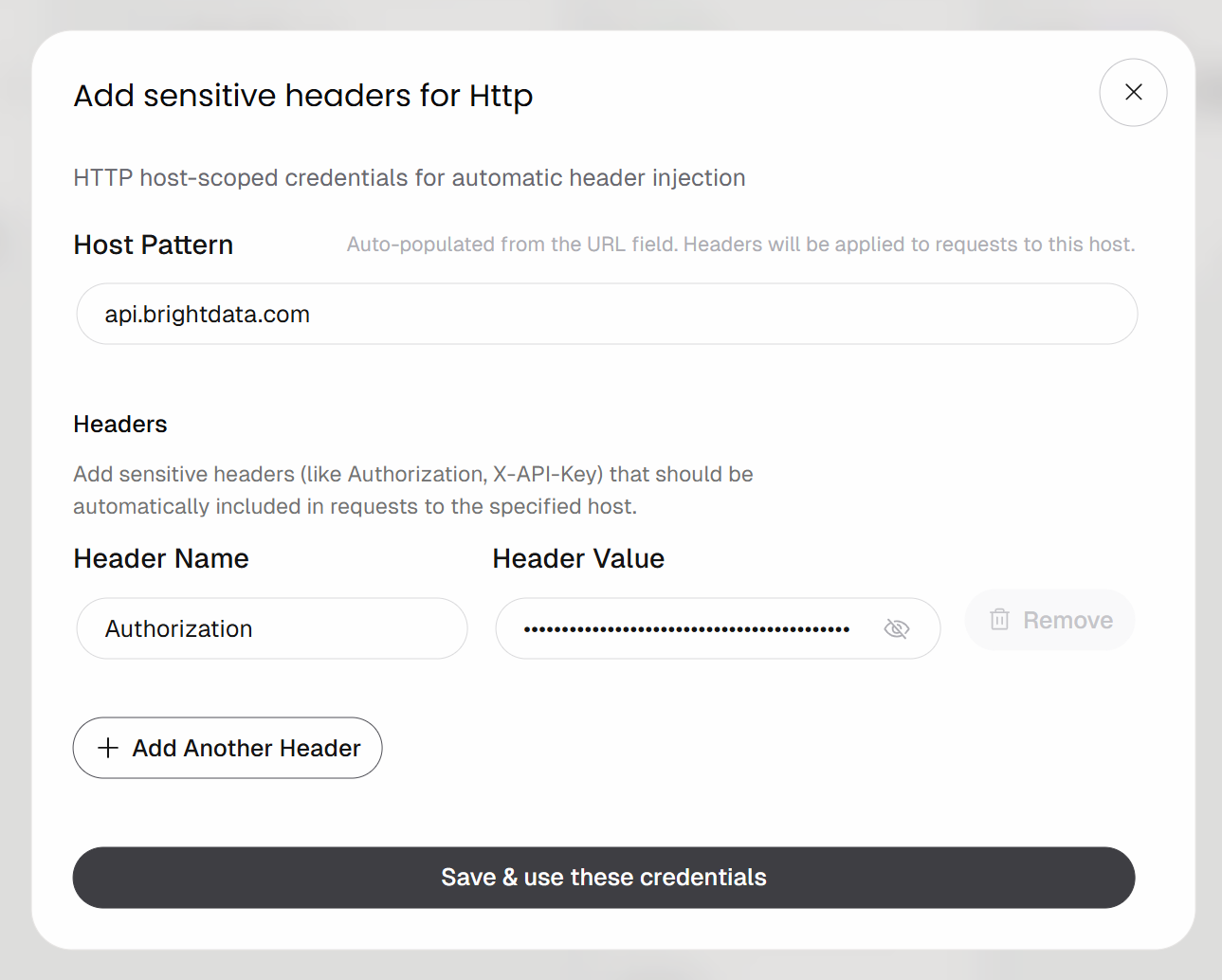
Cliquez sur le bouton « Enregistrer et utiliser ces informations d’identification » pour confirmer.
La requête POST sera authentifiée à l’aide de l’en-tête Authorization. Il s’agit de la méthode d’authentification recommandée pour appeler les API Bright Data.
Vous devez maintenant définir le corps de la requête. Dans ce cas, vous souhaitez une charge utile JSON comme suit :
{
"zone": "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}Cela indique à l’API Bright Data d’utiliser votre zone Web Unlocker API (par exemple, web_unlocker) sur une URL cible, qui sera fournie par le bloc « Agent Input ». Le paramètre format: "raw" garantit que l’API renvoie le résultat directement dans le corps de la réponse, plutôt que sous forme de structure JSON. Le paramètre data_format: "markdown" configure l’API pour extraire le contenu de l’article au format Markdown, qui est un format idéal pour l’ingestion par un agent IA.
Pour ce faire, accédez au bloc « Create Dictionary » et cliquez sur « Add Item ». Définissez les champs suivants :
Zone:<YOUR_WEB_UNLOCKER_API_ZONE_NAME>(par exemple,« web_unlocker »)url: (laissez vide pour l’instant, car ce champ sera renseigné dynamiquement)format:« raw »data_format:« markdown »
Ensuite, connectez la sortie « Dictionnaire » du bloc « Créer un dictionnaire » à l’entrée « Corps » du bloc « Envoyer une requête Web authentifiée » :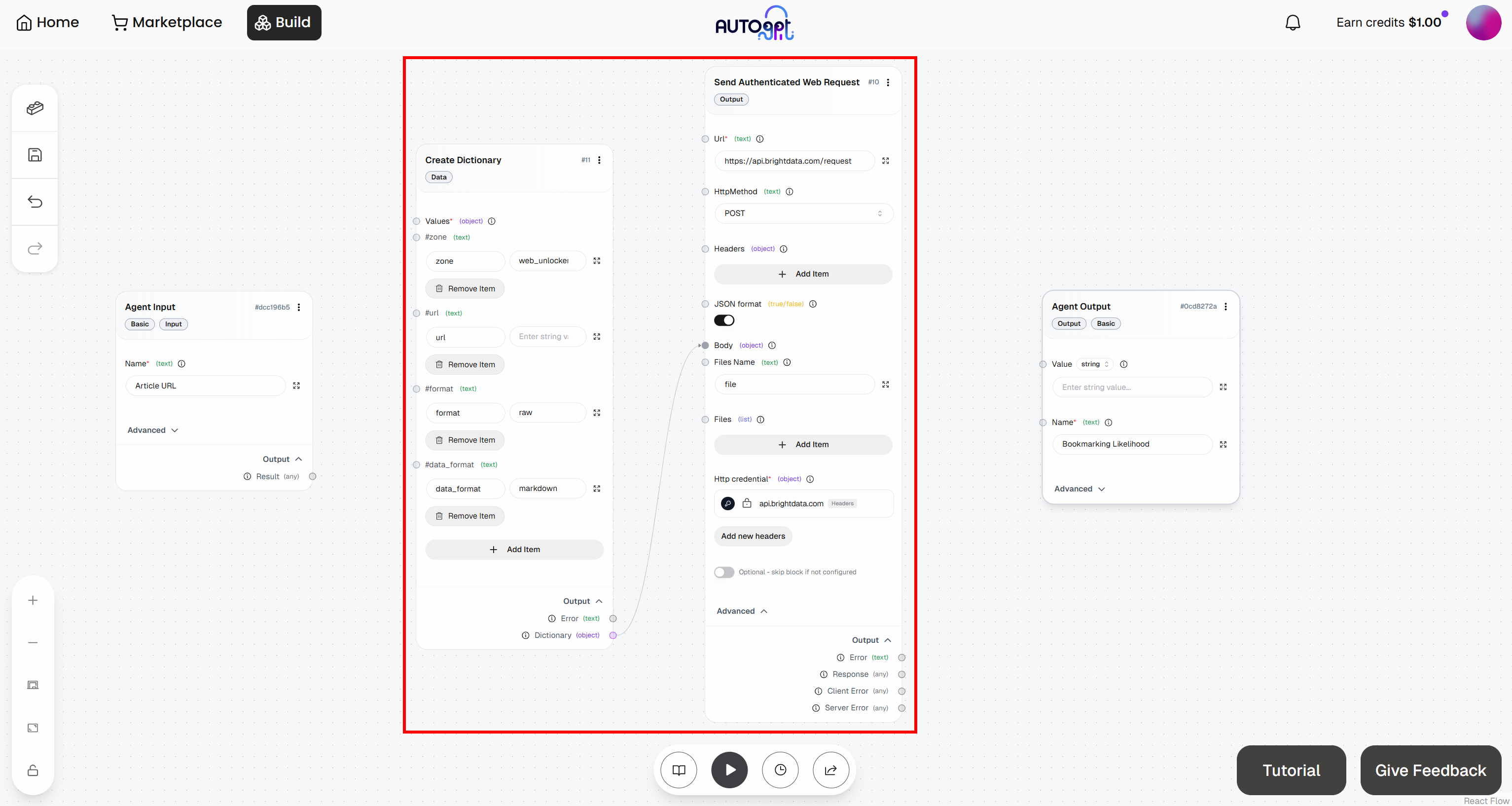
Parfait ! L’intégration de Bright Data dans votre workflow AutoGPT est désormais terminée.
Étape n° 7 : Ajouter le moteur LLM
Le dernier bloc manquant est le moteur LLM chargé d’analyser le contenu Markdown récupéré via le Scraping web grâce à l’API Web Unlocker et de lui attribuer un score de bookmark.
Comme vous souhaitez que ce workflow évalue différents articles au fil du temps, il doit produire un résultat cohérent et structuré.
Pour atteindre cet objectif, utilisez le bloc « IA Structured Response Generator ». Cela vous permet de demander à un LLM d’effectuer une tâche et de renvoyer les résultats dans un format prédéfini.
Commencez par ajouter ce bloc à votre workflow :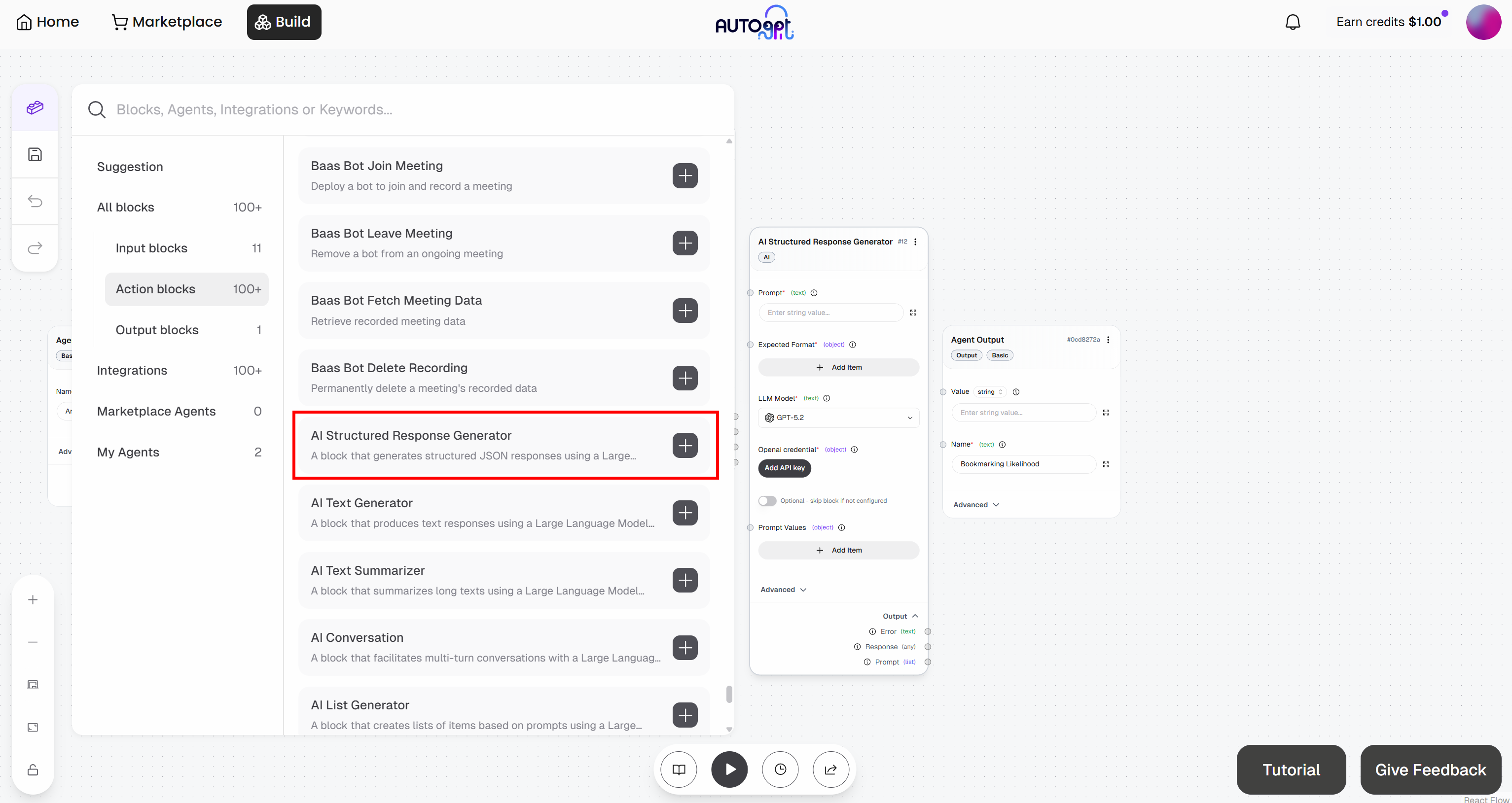
Connectez le bloc à votre compte OpenAI en cliquant sur le bouton « Add API Key ». Donnez un nom à votre clé, collez votre clé API OpenAI, puis cliquez sur « Add API Key » :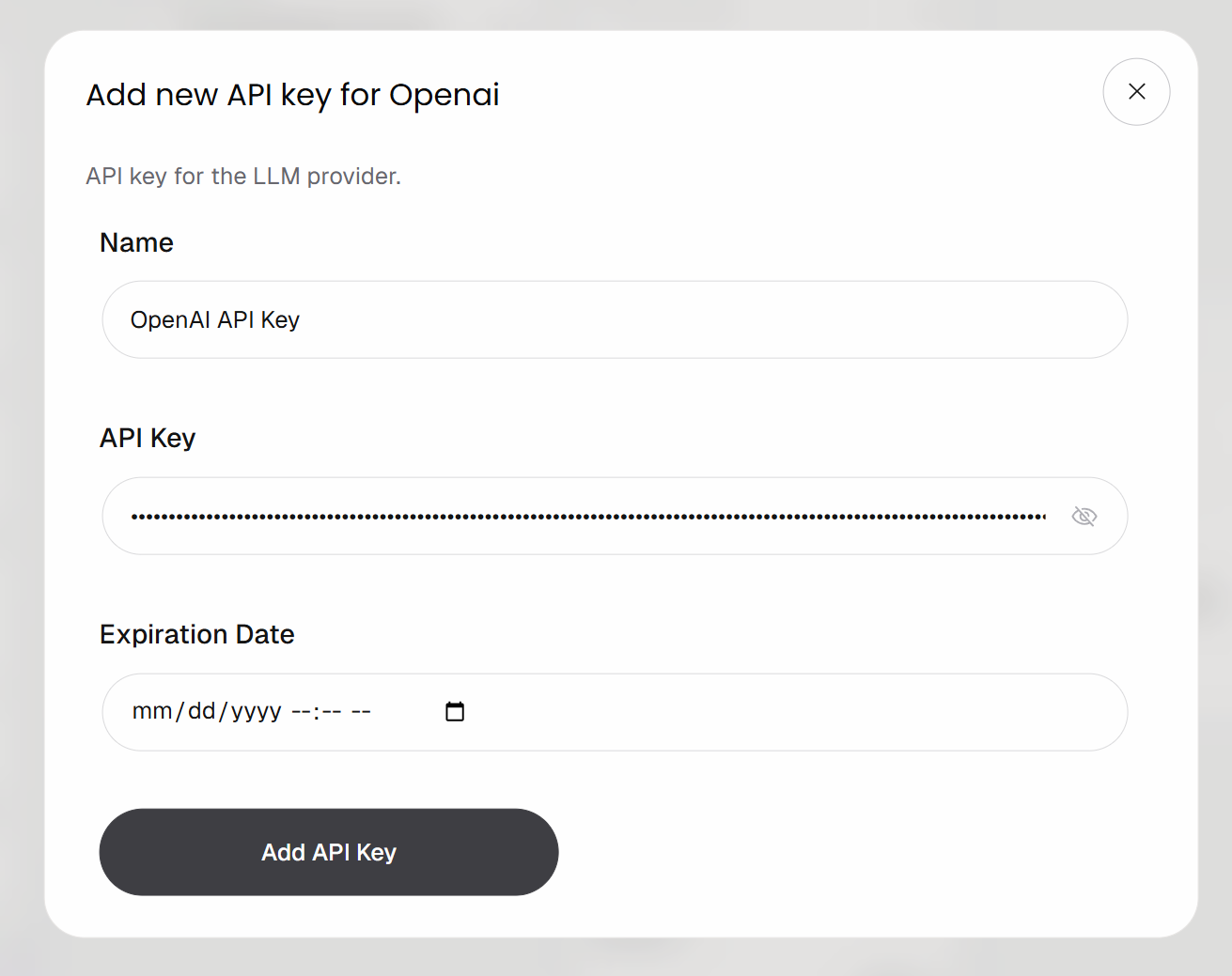
Votre bloc « IA Structured Response Generator » est désormais authentifié et prêt à appeler le modèle OpenAI configuré.
Remplissez maintenant le bloc avec les éléments suivants :
- Invite:
Vous êtes un évaluateur de contenu expert.
Votre tâche consiste à analyser l'article suivant et à déterminer s'il vaut la peine d'être ajouté à vos favoris pour référence future.
Article :
« {{article}} »
Évaluez l'article en fonction des critères suivants :
- Utilité pratique (fournit-il des informations exploitables ?)
- Profondeur (est-il superficiel ou approfondi ?)
- Rapport signal/bruit (est-il concis ou rempli de détails superflus ?)
- Réutilisabilité (vaut-il la peine d'y revenir plus tard ?)
Renvoyez un objet JSON contenant :
- « score » : un nombre entier compris entre 1 et 10 (1 = ne vaut pas la peine d'être mis en favori, 10 = doit être mis en favori)
- « comment » : une explication concise et accessible (1 à 2 phrases maximum)
Consignes :
- Faites preuve d'esprit critique et évitez de surévaluer
- Ne donnez des notes élevées qu'aux contenus présentant une valeur à long terme
- Évitez les commentaires génériques
- *Modèle* : GPT-5.1 Mini (ou tout autre modèle OpenAI à usage général)Dans la prompt, notez l’espace réservé {{article}}. Il s’agit d’une variable qui sera remplacée dynamiquement par une « valeur de prompt ». Plus précisément, elle sera remplacée par le contenu Markdown renvoyé par le bloc « Envoyer une requête Web authentifiée ».
Pour configurer une « valeur de prompt », cliquez sur « Ajouter un élément » et définissez une variable nommée article. Ensuite, connectez la sortie « Réponse » du bloc « Envoyer une requête Web authentifiée » à la valeur de prompt article: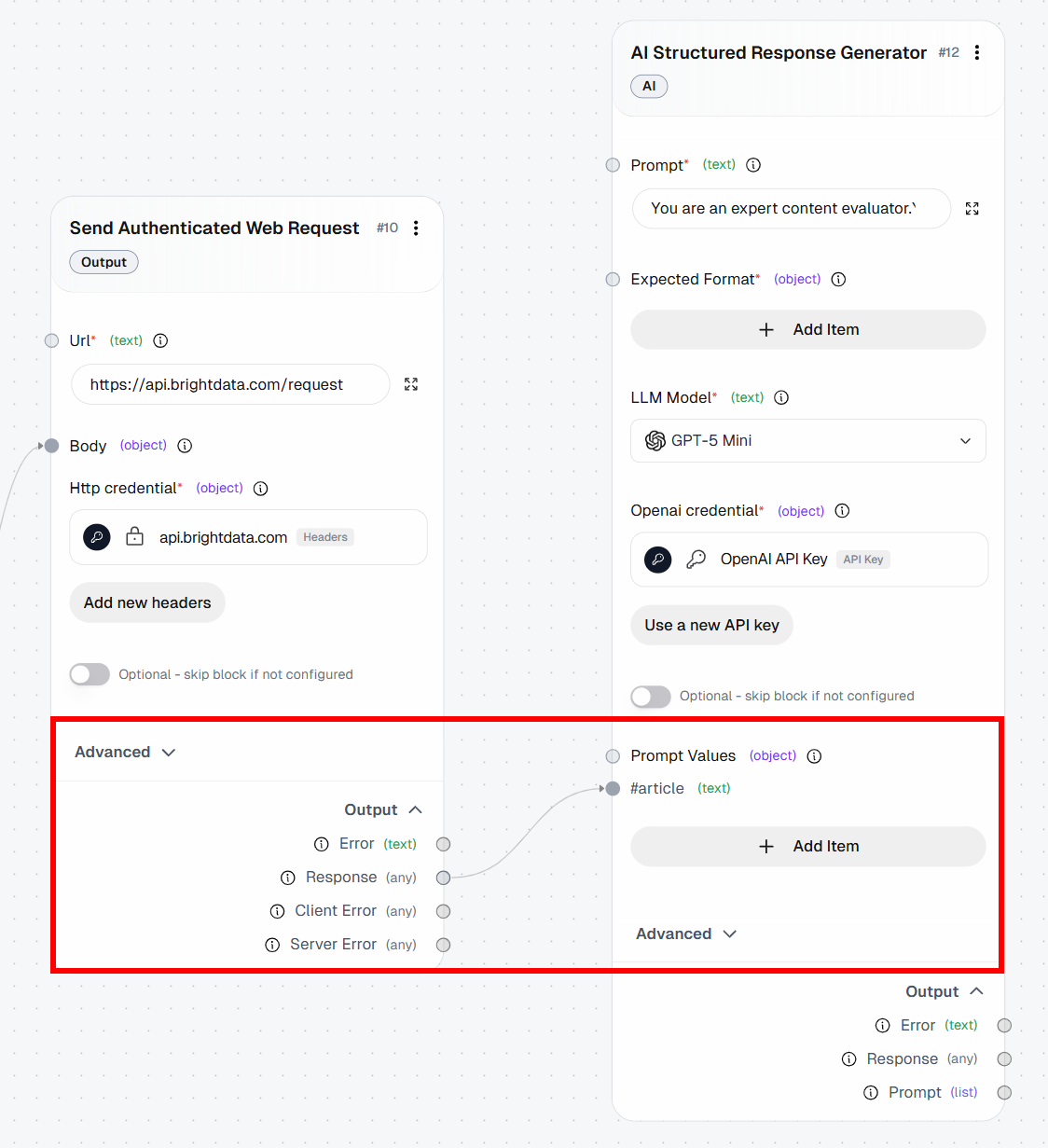
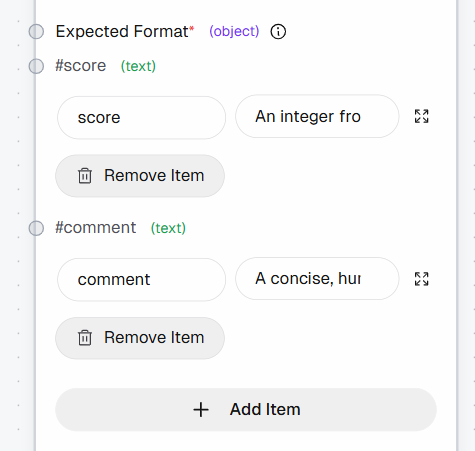
Ensuite, définissez la sortie structurée en ajoutant les champs suivants à la section « Format attendu » :
score: « Un nombre entier compris entre 1 et 10 (1 = ne vaut pas la peine d’être ajouté aux favoris, 10 = doit être ajouté aux favoris) »commentaire: « Une explication concise, rédigée dans un style naturel (1 à 2 phrases maximum) »
Super ! Votre workflow agentique AutoGPT alimenté par Bright Data comprend désormais tous les éléments de base. Il ne reste plus qu’à les connecter tous.
Étape n° 8 : Connecter tous les blocs
Pour finaliser le workflow, connectez tous les blocs afin de créer un pipeline complet.
Commencez par connecter la sortie « Result » du bloc « Agent Input » au champ url du bloc « Create Dictionary ». Cela garantit que l’URL d’entrée passe de l’entrée du workflow à la requête API Web Unlocker, qui va extraire le contenu de la page et transmettre le résultat au LLM pour analyse.
Enfin, connectez la sortie « Response » du bloc « IA Structured Response Generator » au bloc « Agent Output ». Cela clôt le workflow et achève le flux de données.
Voici à quoi devrait ressembler votre workflow AutoGPT final, enrichi de capacités de Scraping web grâce à Bright Data :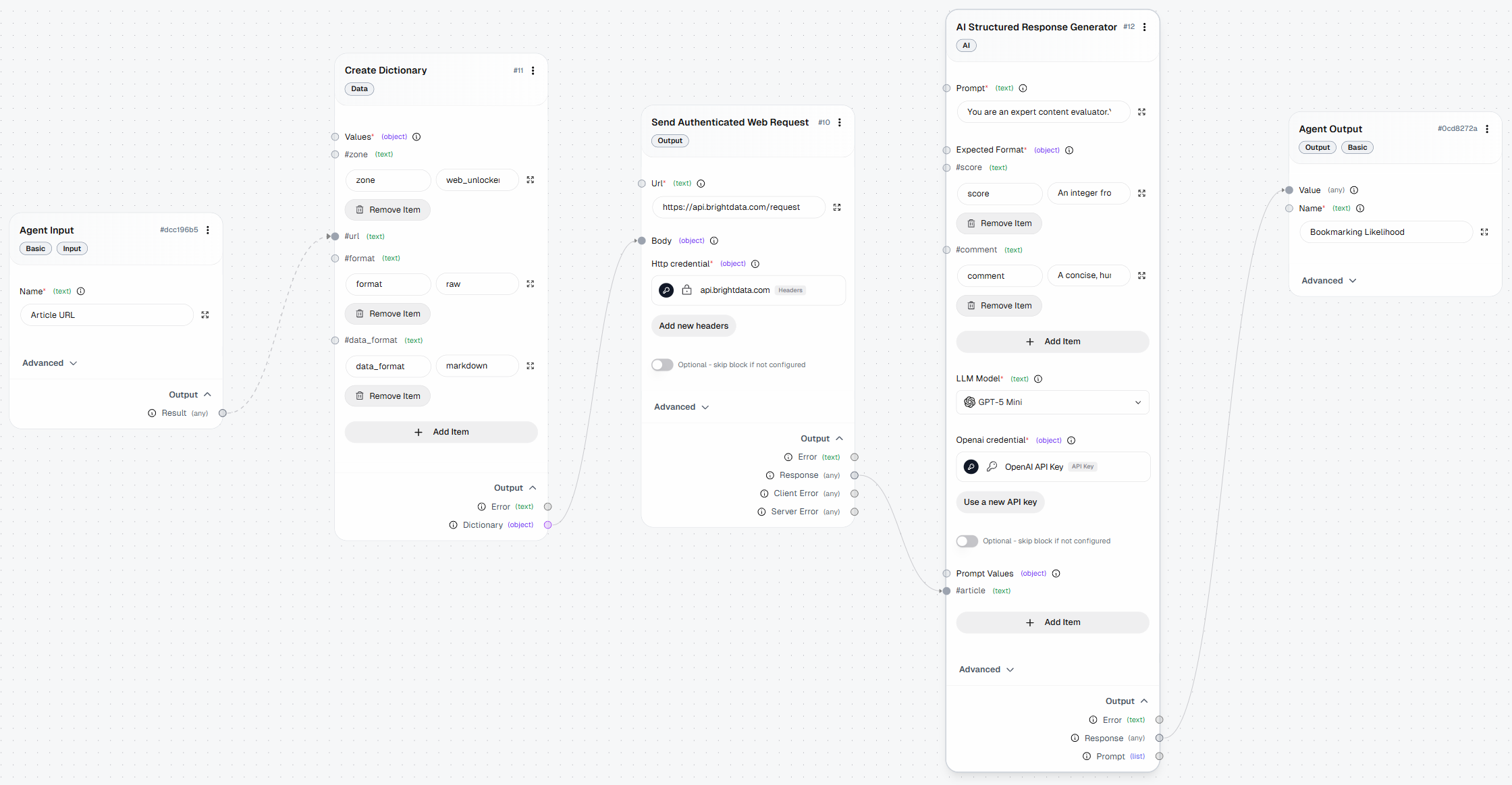
Étape n° 9 : Tester l’agent
Cliquez sur le bouton « Run agent » pour lancer votre workflow agentique et le tester :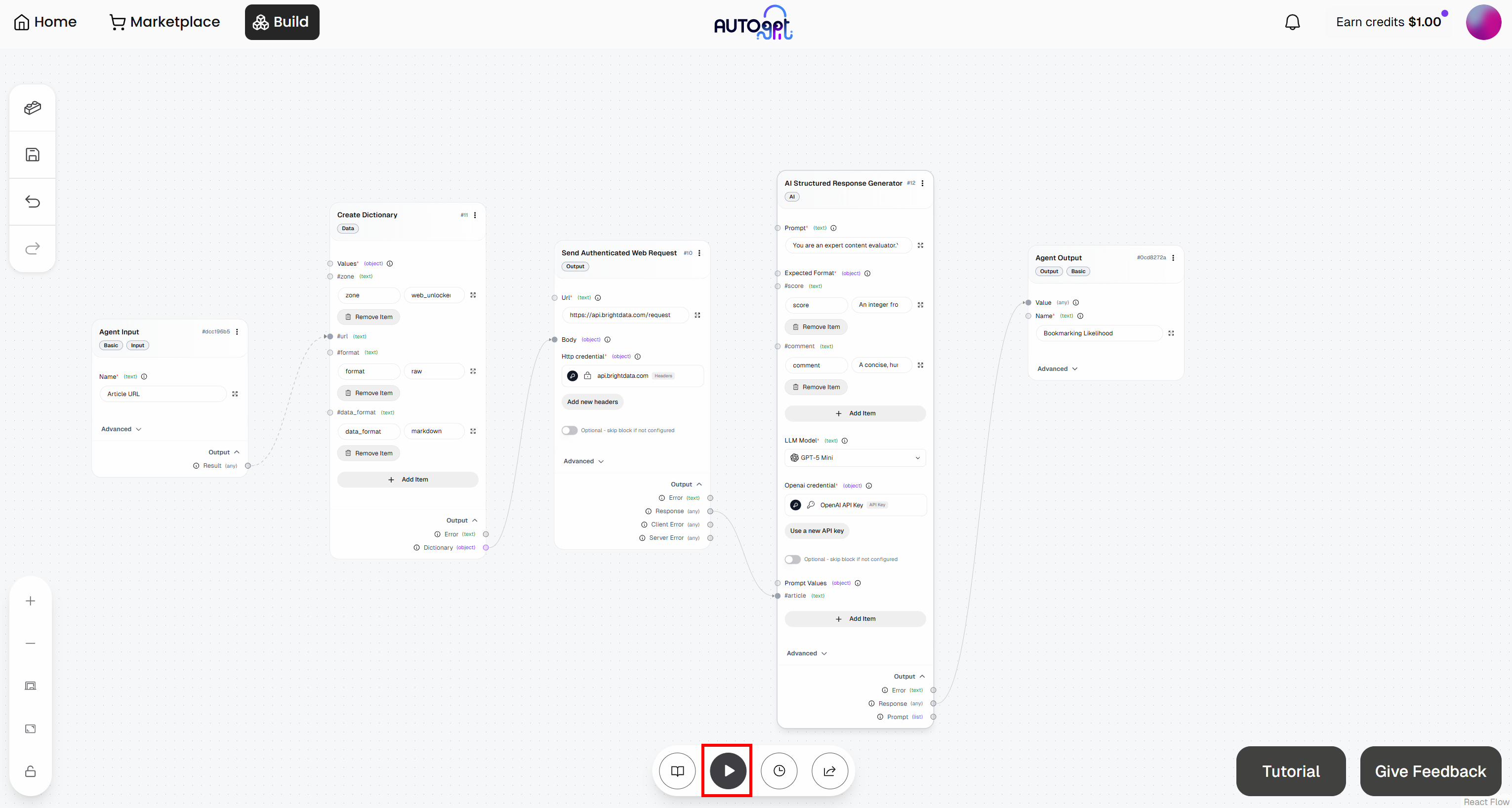
Vous serez invité à fournir l’URL d’entrée du workflow (c’est-à-dire l’URL de l’article). Collez un article de blog comme celui-ci :
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/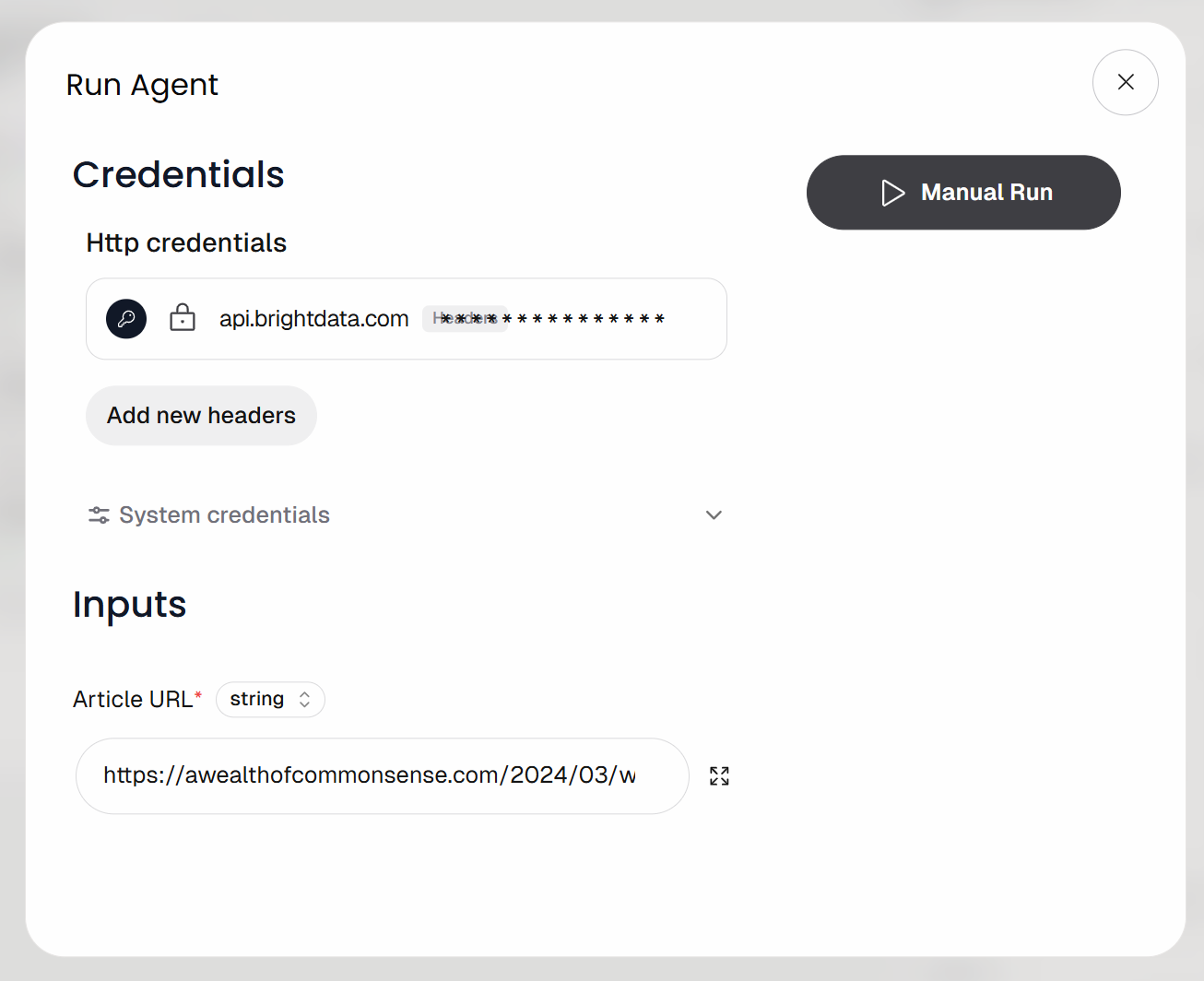
Lancez ensuite le workflow en cliquant sur le bouton « Exécution manuelle ». Voici ce que vous devriez voir :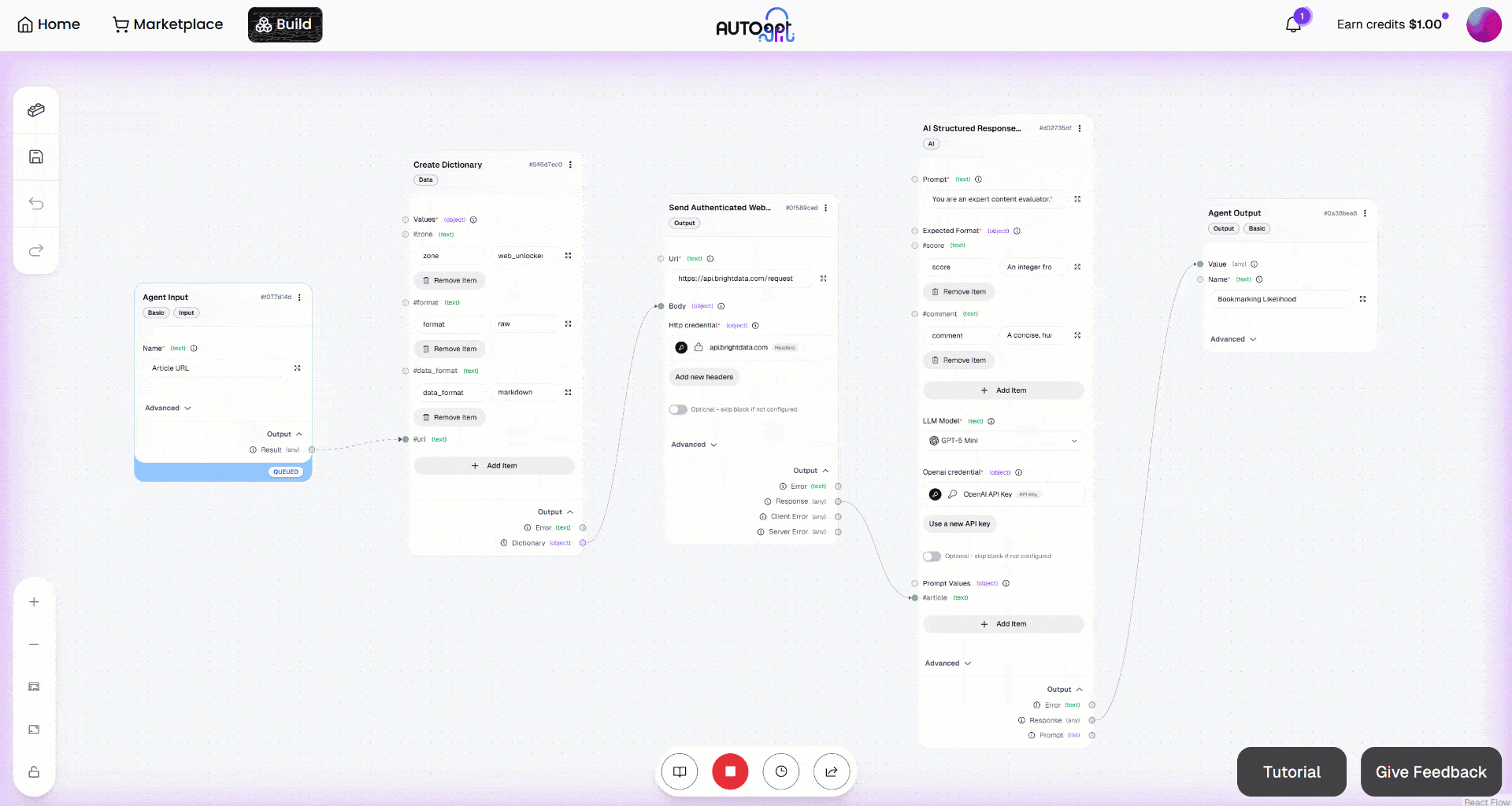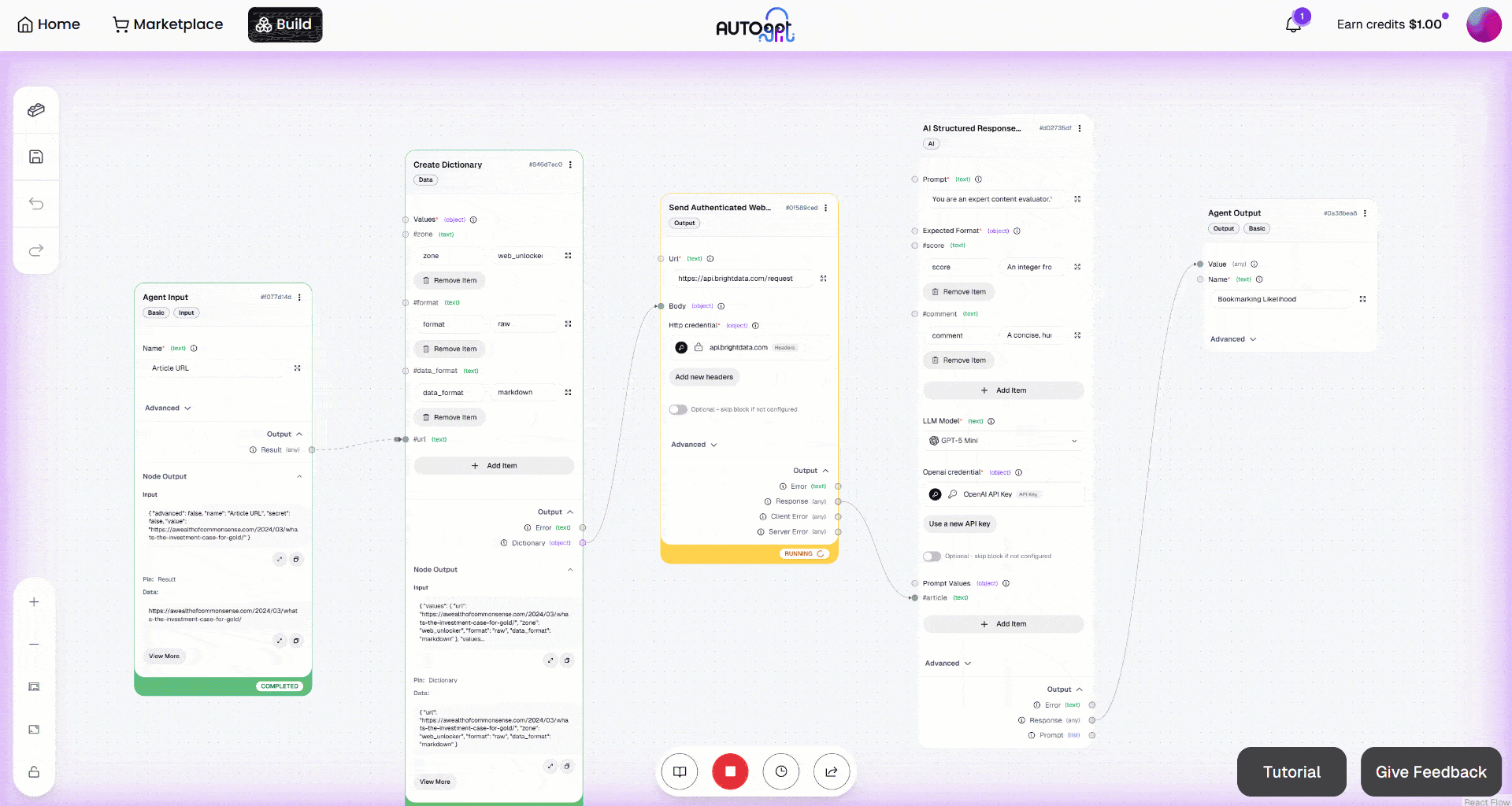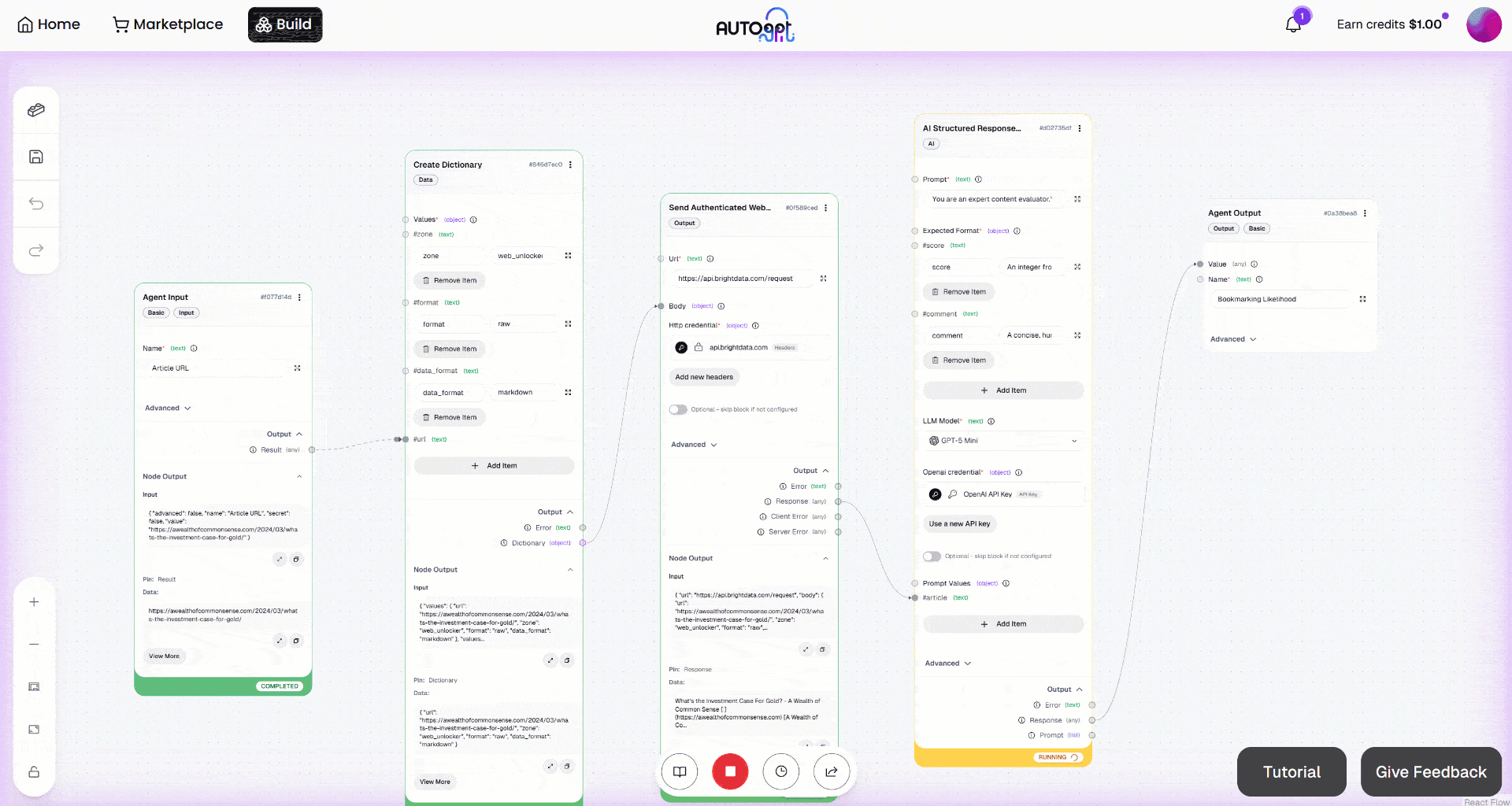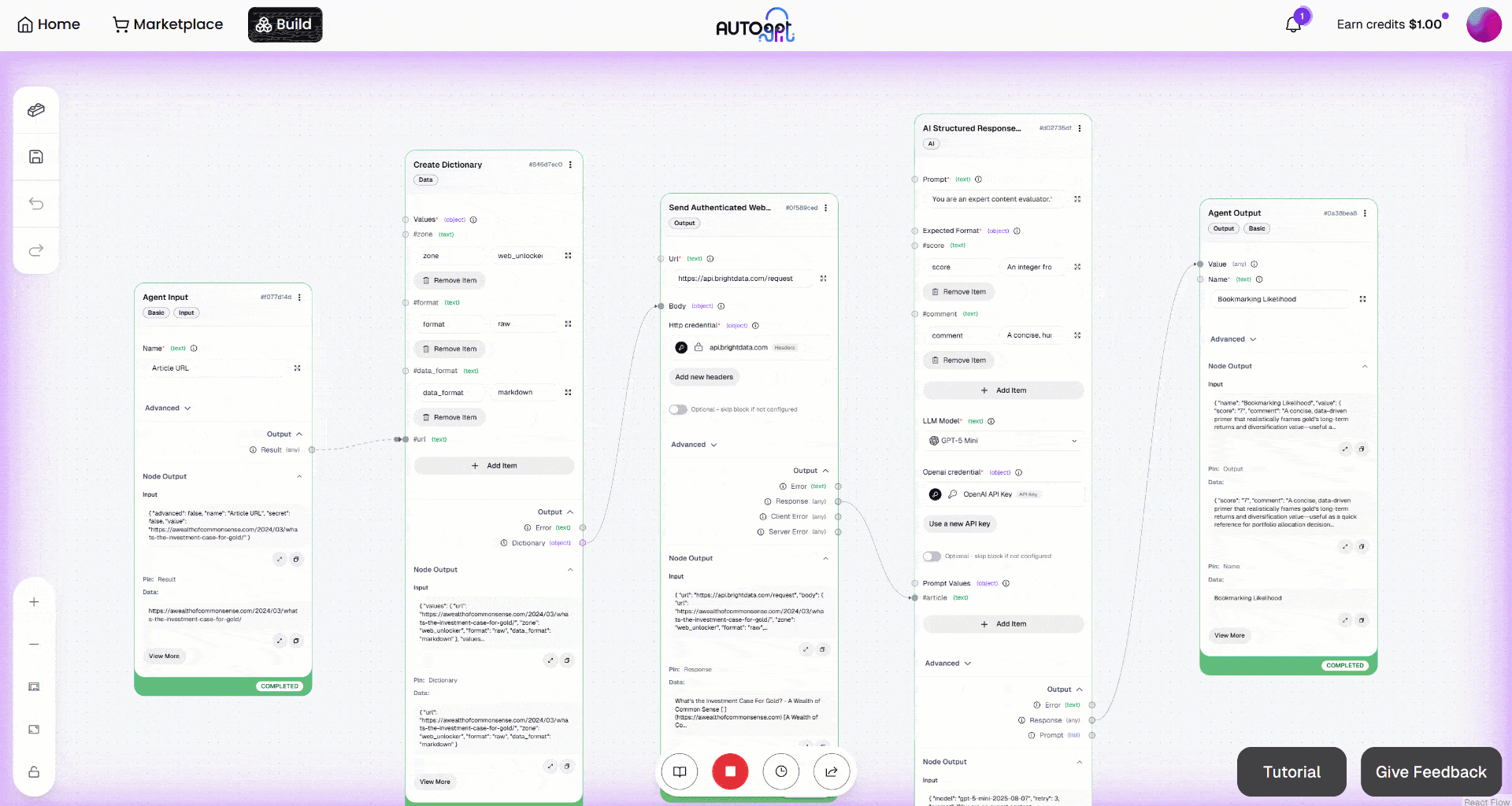
Développez la sortie dans le bloc « Sortie de l’agent ». Vous remarquerez que l’agent IA a produit un résultat comme celui-ci :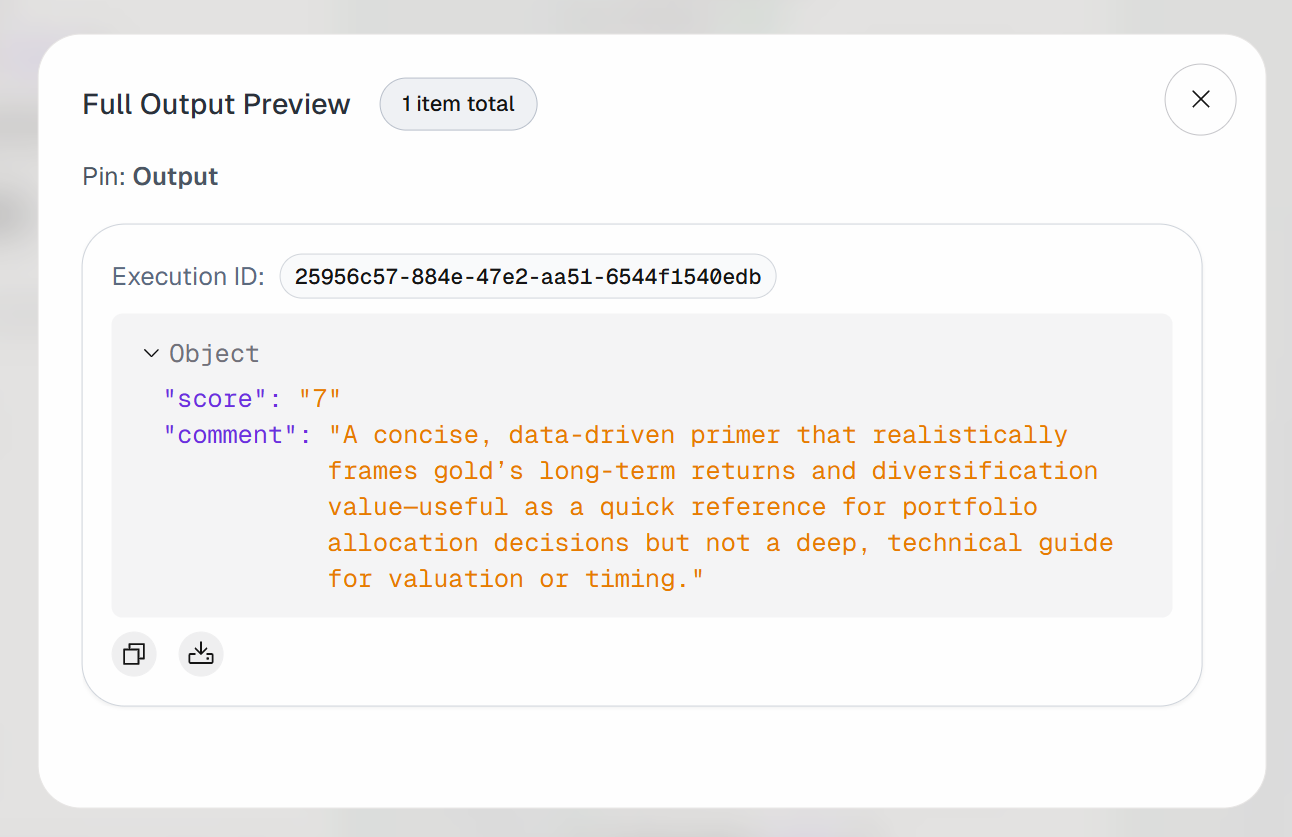
Ainsi, l’article d’entrée est jugé suffisamment intéressant pour être ajouté aux favoris en vue d’une lecture ultérieure.
Si vous examinez la sortie du bloc « Send Authenticated Web Request », vous observerez :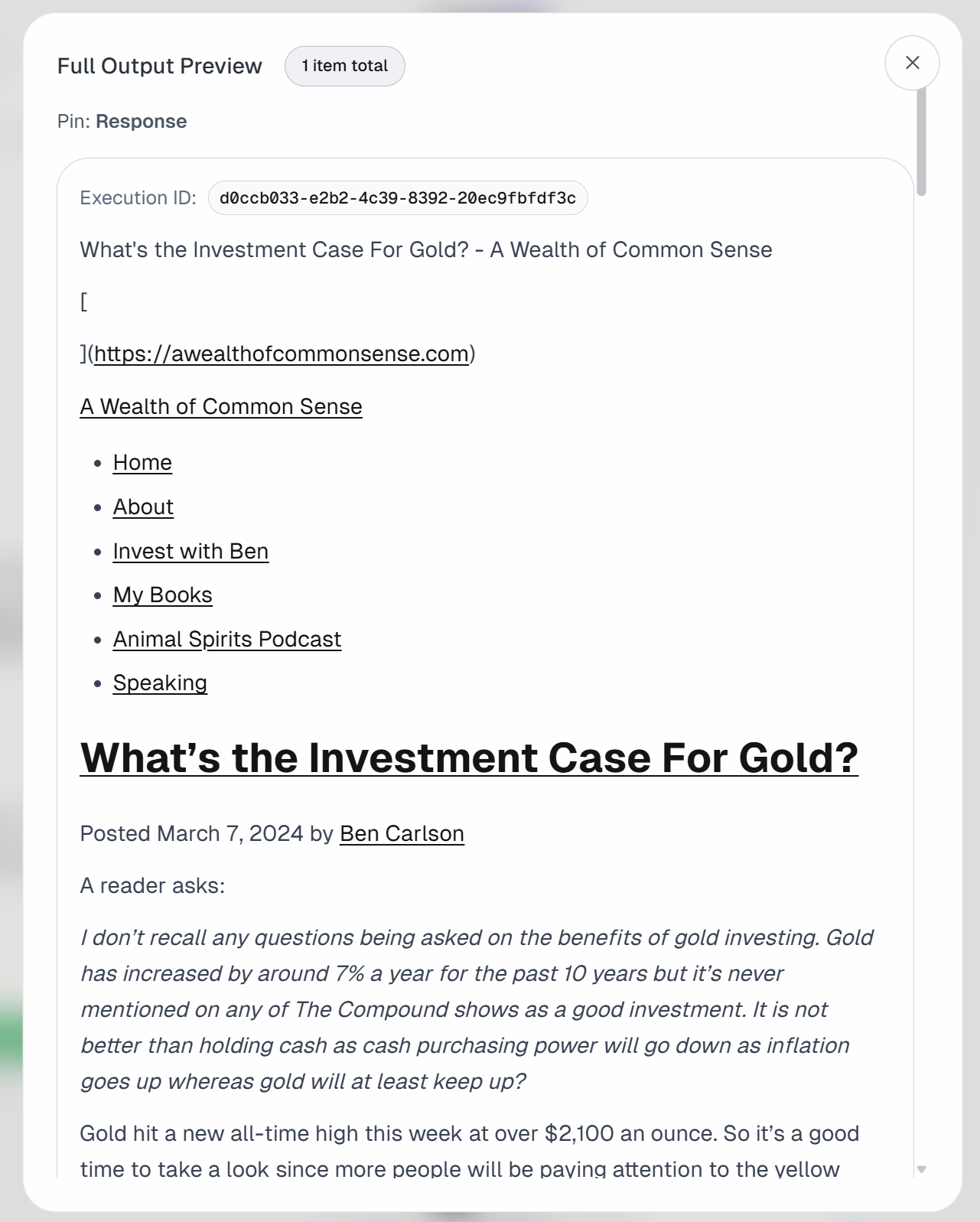
Cela correspond à la version Markdown de l’article cible :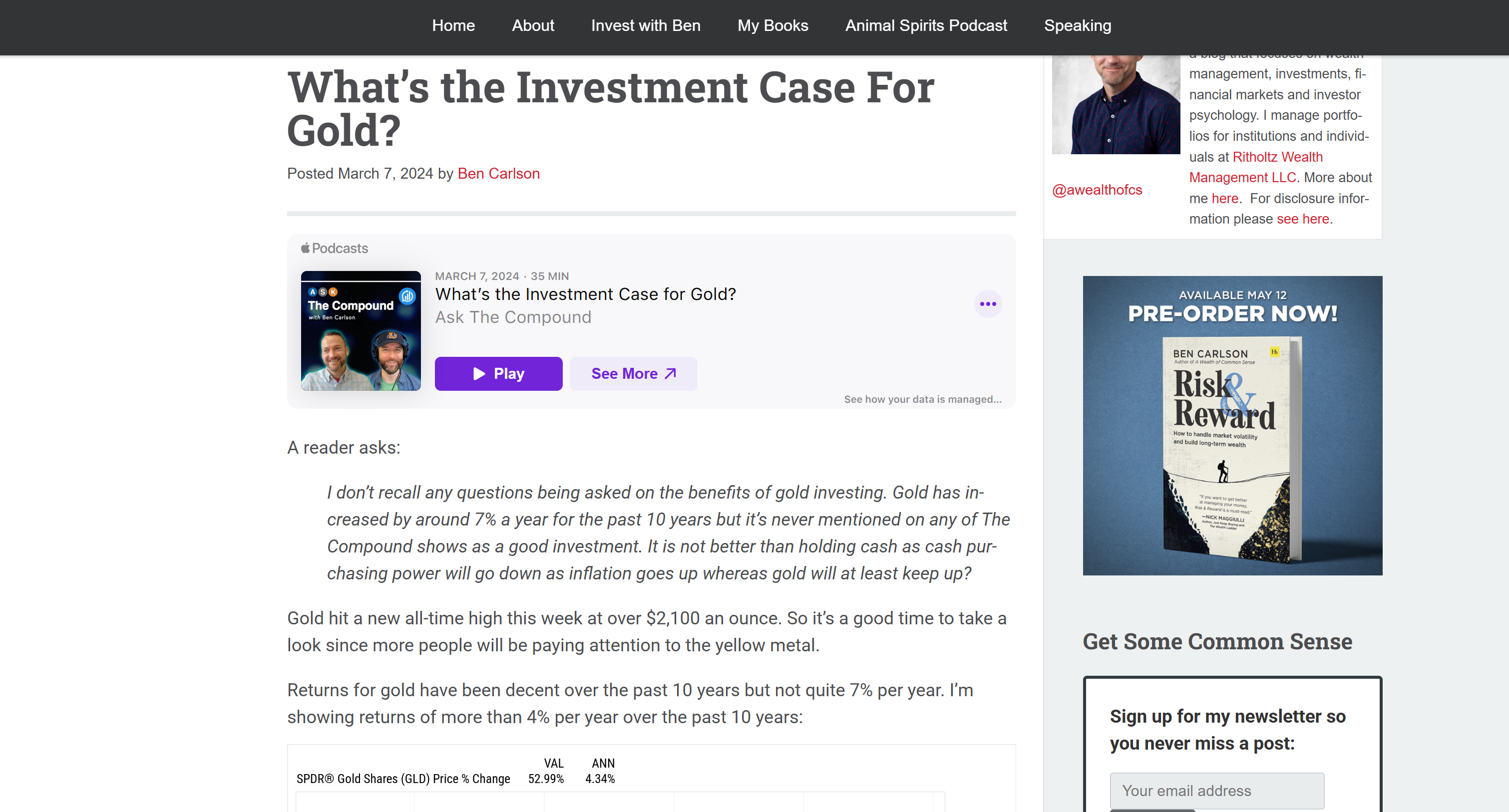
Cela confirme que l’API Bright Data Web Unlocker a réussi à récupérer rapidement le contenu de la page dans un format qui rend le traitement LLM plus efficace et performant.
Et voilà ! Vous venez de créer un agent IA dans AutoGPT qui s’intègre à Bright Data pour la récupération dynamique de données Web.
Prochaines étapes
Il s’agissait d’un exemple simple, mais gardez à l’esprit que l’intégration AutoGPT + Bright Data peut être étendue pour prendre en charge des workflows d’agents bien plus avancés.
Par exemple, avec une approche similaire, vous pouvez connecter votre agent à d’autres produits basés sur l’API Bright Data pour ajouter des capacités de recherche et d’exploration du Web. De même, vous pouvez intégrer des API de scraping qui fournissent des flux de données directs provenant de plusieurs domaines.
Pour rendre votre agent plus puissant, explorez la vaste gamme de fonctionnalités offertes par AutoGPT en consultant la documentation officielle.
Conclusion
Dans cet article, vous avez appris à ajouter les capacités d’exploration Web, d’interaction, de recherche et de scraping de données de Bright Data à AutoGPT. Cela permet aux agents IA de surmonter les principales limites en matière de connaissances et d’interaction propres aux LLM standard.
Vous avez vu comment créer un agent IA simple servant de conseiller en signets. Pour créer des workflows d’agents plus complexes — nécessitant l’accès à des flux Web en direct, à la recherche Web ou à des interactions Web —, intégrez AutoGPT à la suite complète de services Bright Data pour l’IA.
Créez gratuitement un compte Bright Data dès aujourd’hui et commencez à tester nos solutions de données Web optimisées pour l’IA !






