
Dans cet article, vous apprendrez :
- Comment créer un agent IA prêt à l’emploi qui enregistre les conversations dans des bases de données
- Comment mettre en œuvre l’extraction intelligente de données et le suivi d’entités
- Comment créer une gestion des erreurs robuste avec récupération automatique
- Comment améliorer votre agent grâce aux données web en temps réel de Bright Data
C’est parti !
Le défi des conversations IA sans état
Les agents IA actuels fonctionnent généralement comme des systèmes sans état. Ils traitent chaque conversation comme un événement distinct. Ce manque de contexte historique oblige les utilisateurs à répéter les informations. Il en résulte une inefficacité opérationnelle et une frustration des utilisateurs. De plus, les entreprises ne peuvent pas exploiter les données à long terme pour personnaliser ou améliorer leurs services.
L’IA à persistance des données résout ce problème en enregistrant toutes les interactions dans une base de données structurée. En conservant un enregistrement continu, ces systèmes peuvent se souvenir du contexte historique, suivre des entités spécifiques au fil du temps et utiliser les modèles d’interaction passés pour offrir une expérience utilisateur cohérente et personnalisée.
Ce que nous construisons : un système d’agent IA connecté à une base de données
Nous allons créer un agent IA prêt à l’emploi qui traite les messages à l’aide de LangChain et GPT-4. Il enregistre chaque conversation dans PostgreSQL. Il extrait les entités et les informations en temps réel. Il conserve un historique complet des conversations entre les sessions. Il gère les erreurs à l’aide de systèmes de réessai automatique. Il offre une surveillance avec journalisation.
Le système gérera :
- Schéma de base de données avec des relations et des index appropriés
- Agent LangChain avec des outils de base de données personnalisés
- Persistance automatique des conversations et extraction d’entités
- Pipeline de traitement en arrière-plan pour la collecte de données
- Gestion des erreurs avec gestion des transactions
- Interface de requête pour la récupération des données historiques
- Intégration RAG avec Bright Data pour l’intelligence web
Prérequis
Configurez votre environnement de développement avec :
- Python 3.10 ou supérieur. Requis pour les fonctionnalités asynchrones modernes et les indications de type
- PostgreSQL 14+ ou SQLite 3.35+. Base de données pour la persistance des données
- Clé API OpenAI. Pour l’accès à GPT-4. Obtenez-la sur la plateforme OpenAI
- LangChain. Cadre pour la création d’agents IA. Voir la documentation
- Environnement virtuel Python. Permet d’isoler les dépendances. Voir la documentation
venv
Configuration de l’environnement
Créez votre répertoire de projet et installez les dépendances :
mkdir database-agent
cd database-agent
python -m venv venv
# macOS/Linux : source venv/bin/activate
# Windows : venv\Scripts\activate
pip install langchain langchain-openai sqlalchemy psycopg2-binary python-dotenv pydanticCréez un nouveau fichier appelé agent.py et ajoutez les importations suivantes :
import os
import json
import logging
import time
from datetime import datetime, timedelta
from typing import List, Dict, Any, Optional
from queue import Queue
from threading import Thread
# Importations SQLAlchemy
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float, JSON, ForeignKey, text
from sqlalchemy.orm import sessionmaker, relationship, Session, declarative_base
from sqlalchemy.pool import QueuePool
from sqlalchemy.exc import SQLAlchemyError
# Importations LangChain
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema import HumanMessage, AIMessage, SystemMessage
# Importations RAG
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
# Configuration de l'environnement
from dotenv import load_dotenv
load_dotenv()
# Configurer la journalisation
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)Créez un fichier .env avec vos identifiants :
# Configuration de la base de données
DATABASE_URL="postgresql://username:password@localhost:5432/agent_db"
# Ou pour SQLite : DATABASE_URL="sqlite:///./agent_data.db"
# Clés API
OPENAI_API_KEY="your-openai-api-key"
# Facultatif : Bright Data (pour l'étape 7)
BRIGHT_DATA_API_KEY="votre-clé-api-bright-data"
# Paramètres de l'application
AGENT_MODEL="gpt-4-turbo-preview"
CONNECTION_POOL_SIZE=5
MAX_RETRIES=3Vous avez besoin de :
- URL de la base de données: chaîne de connexion pour PostgreSQL ou SQLite
- Clé API OpenAI: pour l’intelligence de l’agent via GPT-4
- Clé API Bright Data: facultative, pour les données Web en temps réel à l’étape 7
Création de votre agent IA connecté à la base de données
Étape 1 : conception du schéma de la base de données
Concevez des tables pour les utilisateurs, les conversations, les messages et les entités extraites. Le schéma utilise des clés étrangères et des relations pour maintenir l’intégrité des données.
Base = declarative_base()
class User(Base):
"""Tableau des profils utilisateur - stocke les informations et les préférences des utilisateurs."""
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
user_id = Column(String(255), unique=True, nullable=False, index=True)
name = Column(String(255))
email = Column(String(255))
preferences = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
last_active = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Relations
conversations = relationship("Conversation", back_populates="user", cascade="all, delete-orphan")
def __repr__(self):
return f"<User(user_id='{self.user_id}', name='{self.name}')>"
class Conversation(Base) :
"""Tableau des sessions de conversation - suit les sessions de conversation individuelles."""
__tablename__ = 'conversations'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), unique=True, nullable=False, index=True)
user_id = Column(Integer, ForeignKey('users.id'), nullable=False)
title = Column(String(500))
summary = Column(Text)
status = Column(String(50), default='active') # active, archived, deleted
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Relations
user = relationship("User", back_populates="conversations")
messages = relationship("Message", back_populates="conversation", cascade="all, delete-orphan")
entities = relationship("Entity", back_populates="conversation", cascade="all, delete-orphan")
def __repr__(self):
return f"<Conversation(id='{self.conversation_id}', user='{self.user_id}')>"
class Message(Base):
"""Tableau des messages individuels - stocke chaque message d'une conversation."""
__tablename__ = 'messages'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
role = Column(String(50), nullable=False) # utilisateur, assistant, système
content = Column(Text, nullable=False)
tokens = Column(Integer)
model = Column(String(100))
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
# Relations
conversation = relationship("Conversation", back_populates="messages")
def __repr__(self):
return f"<Message(role='{self.role}', conversation='{self.conversation_id}')>"
class Entity(Base):
"""Table des entités extraites - stocke les entités nommées extraites des conversations."""
__tablename__ = 'entities'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
entity_type = Column(String(100), nullable=False, index=True) # personne, organisation, lieu, etc.
entity_value = Column(String(500), nullable=False)
context = Column(Text)
confidence = Column(Float, default=0.0)
meta_data = Column(JSON, default={})
extracted_at = Column(DateTime, default=datetime.utcnow)
# Relations
conversation = relationship("Conversation", back_populates="entities")
def __repr__(self):
return f"<Entity(type='{self.entity_type}', value='{self.entity_value}')>"
class AgentLog(Base) :
"""Table des journaux d'opération de l'agent - stocke les journaux opérationnels à des fins de surveillance."""
__tablename__ = 'agent_logs'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), index=True)
level = Column(String(50), nullable=False) # INFO, WARNING, ERROR
operation = Column(String(255), nullable=False)
message = Column(Text, nullable=False)
error_details = Column(JSON)
execution_time = Column(Float) # en secondes
created_at = Column(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<AgentLog(level='{self.level}', operation='{self.operation}')>"Le schéma définit cinq tables principales. User stocke les profils avec des préférences JSON pour des données flexibles. Conversation suit les sessions avec un suivi du statut. Message contient les échanges individuels avec des indicateurs de rôle pour les messages utilisateur/assistant. Entity capture les informations extraites avec des scores de confiance. AgentLog fournit un suivi des opérations à des fins de surveillance. Les clés étrangères maintiennent l’intégrité référentielle. Les index sur les champs fréquemment interrogés optimisent les performances. Le paramètre cascade="all, delete-orphan" nettoie les enregistrements associés lorsque les enregistrements parents sont supprimés.
Étape 2 : configuration de la couche de connexion à la base de données
Configurez le gestionnaire de connexion à la base de données avec SQLAlchemy. Le gestionnaire gère le pool de connexions, les contrôles d’intégrité et la logique de réessai automatique pour plus de fiabilité.
class DatabaseManager:
"""
Gère les connexions et les opérations de la base de données.
Caractéristiques :
- Mise en pool des connexions pour une utilisation efficace des ressources
- Contrôles de santé pour vérifier la connectivité de la base de données
- Création automatique de tables
"""
def __init__(self, database_url: str, pool_size: int = 5, max_retries: int = 3):
"""
Initialise le gestionnaire de base de données.
Arguments :
database_url : chaîne de connexion à la base de données (par exemple, « sqlite:///./agent_data.db »)
pool_size : nombre de connexions à maintenir dans le pool
max_retries : nombre maximal de tentatives de réessai pour les opérations ayant échoué
"""
self.database_url = database_url
self.max_retries = max_retries
# Créer un moteur avec mise en pool des connexions
self.engine = create_engine(
database_url,
poolclass=QueuePool,
pool_size=pool_size,
max_overflow=10,
pool_pre_ping=True, # Vérifier les connexions avant utilisation
echo=False # Définir sur True pour le débogage SQL
)
# Créer une fabrique de sessions
self.SessionLocal = sessionmaker(
bind=self.engine,
autocommit=False,
autoflush=False
)
logger.info(f"✓ Moteur de base de données créé avec un pool de connexions {pool_size}")
def initialize_database(self):
"""Créer toutes les tables dans la base de données."""
try:
Base.metadata.create_all(bind=self.engine)
logger.info("✓ Tables de base de données créées avec succès")
except Exception as e:
logger.error(f"❌ Échec de la création des tables de base de données : {e}")
raise
def get_session(self) -> Session:
"""Obtenir une nouvelle session de base de données pour effectuer des opérations."""
return self.SessionLocal()
def health_check(self) -> bool:
"""
Vérifier la connectivité de la base de données.
Renvoie :
bool: True si la base de données est en bon état, False dans le cas contraire.
"""
try:
with self.engine.connect() as conn:
conn.execute(text("SELECT 1"))
logger.info("✓ Vérification de l'état de la base de données réussie")
return True
except Exception as e:
logger.error(f"❌ Échec de la vérification de l'état de la base de données : {e}")
return FalseLe DatabaseManager établit des connexions à l’aide du pool de connexions de SQLAlchemy. Le paramètre pool_size=5 maintient cinq connexions persistantes pour plus d’efficacité. L’option pool_pre_ping valide les connexions avant leur utilisation. Cela permet d’éviter les erreurs de connexion obsolètes. Le mécanisme de réessai tente jusqu’à trois fois les opérations ayant échoué avec un délai exponentiel. Il gère les problèmes réseau transitoires.
Étape 3 : Création du noyau de l’agent LangChain
Créez l’agent IA à l’aide de LangChain avec des outils personnalisés qui interagissent avec la base de données. L’agent utilise l’appel de fonction pour enregistrer les informations et récupérer l’historique des conversations.
class DataPersistentAgent:
"""
Agent IA avec capacités de persistance de base de données.
Cet agent :
- Mémorise les conversations entre les sessions
- Enregistre et récupère les informations utilisateur
- Extrait et stocke les entités importantes
- Fournit des réponses personnalisées basées sur l'historique
"""
def __init__(
self,
db_manager: DatabaseManager,
model_name: str = "gpt-4-turbo-preview",
temperature: float = 0.7
):
"""
Initialise l'agent persistant.
Args :
db_manager : instance du gestionnaire de base de données
model_name : modèle LLM à utiliser (par défaut : gpt-4-turbo-preview)
temperature : température du modèle pour la génération de réponses
"""
self.db_manager = db_manager
self.model_name = model_name
# Initialise LLM
self.llm = ChatOpenAI(
model=model_name,
temperature=temperature,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Créer des outils pour l'agent
self.tools = self._create_agent_tools()
# Créer une invite pour l'agent
self.prompt = self._create_agent_prompt()
# Initialiser la mémoire
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# Créer l'agent
self.agent = create_openai_functions_agent(
llm=self.llm,
tools=self.tools,
prompt=self.prompt
)
# Créer un exécuteur d'agent
self.agent_executor = AgentExecutor(
agent=self.agent,
tools=self.tools,
memory=self.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info(f"✓ Agent à données persistantes initialisé avec {model_name}")
def _create_agent_tools(self) -> List[Tool]:
"""Créer des outils personnalisés pour les opérations de base de données."""
def save_user_info(user_data: str) -> str:
"""Enregistrer les informations utilisateur dans la base de données."""
try:
data = json.loads(user_data)
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=data['user_id']).first()
if not user:
user = User(**data)
session.add(user)
else:
for key, value in data.items():
setattr(user, key, value)
session.commit()
session.close()
return f"✓ Informations utilisateur enregistrées avec succès"
except Exception as e:
logger.error(f"Échec de l'enregistrement des informations utilisateur : {e}")
return f"❌ Erreur lors de l'enregistrement des informations utilisateur : {str(e)}"
def retrieve_user_history(user_id: str) -> str:
"""Récupérer l'historique des conversations de l'utilisateur."""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return "Aucun utilisateur trouvé"
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(5).all()
history = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
historique.append({
'conversation_id': conv.conversation_id,
'created_at': conv.created_at.isoformat(),
'message_count': len(messages),
'summary': conv.summary
})
session.close()
return json.dumps(historique, indent=2)
except Exception as e:
logger.error(f"Échec de la récupération de l'historique : {e}")
return f"❌ Erreur lors de la récupération de l'historique : {str(e)}"
def extract_entities(text: str) -> str:
"""Extraire les entités du texte et les enregistrer dans la base de données."""
try:
entities = []
# Extraction simple de mots-clés (remplacer par NER approprié)
keywords = ['important', 'key', 'critical']
for keyword in keywords:
if keyword in text.lower():
entities.append({
'entity_type': 'keyword',
'entity_value': keyword,
'confidence': 0.8
})
return json.dumps(entities, indent=2)
except Exception as e:
logger.error(f"Échec de l'extraction des entités : {e}")
return f"❌ Erreur lors de l'extraction des entités : {str(e)}"
tools = [
Tool(
name="SaveUserInfo",
func=save_user_info,
description="Enregistrer les informations utilisateur dans la base de données. L'entrée doit être une chaîne JSON contenant les détails de l'utilisateur."
),
Tool(
name="RetrieveUserHistory",
func=retrieve_user_history,
description="Récupère l'historique des conversations d'un utilisateur dans la base de données. L'entrée doit être l'identifiant utilisateur."
),
Tool(
name="ExtractEntities",
func=extract_entities,
description="Extraire les entités importantes du texte et les enregistrer dans la base de données. L'entrée doit être le texte à analyser."
)
]
return tools
def _create_agent_prompt(self) -> ChatPromptTemplate:
"""Créer un modèle d'invite d'agent."""
system_message = """Vous êtes un assistant IA utile, capable de mémoriser et d'apprendre à partir des conversations.
Vous avez accès aux outils suivants :
- SaveUserInfo : enregistrer les informations utilisateur à retenir pour les conversations futures.
- RetrieveUserHistory : rechercher les conversations passées avec un utilisateur.
- ExtractEntities : extraire et enregistrer les informations importantes des conversations.
Utilisez ces outils pour fournir des réponses personnalisées et adaptées au contexte. Vérifiez toujours si vous avez eu des conversations précédentes avec un utilisateur avant de répondre.
Soyez proactif dans l'enregistrement des informations importantes pour les conversations futures."""
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
return prompt
def chat(self, user_id: str, message: str, conversation_id: Optional[str] = None) -> Dict[str, Any]:
"""
Traite un message de chat et le conserve dans la base de données.
Cette méthode gère :
1. La création ou la récupération de conversations
2. L'enregistrement des messages des utilisateurs dans la base de données
3. La génération des réponses des agents
4. L'enregistrement des réponses des agents dans la base de données
5. La journalisation des opérations à des fins de surveillance
Arguments :
user_id : identifiant unique de l'utilisateur
message : texte du message de l'utilisateur
conversation_id : identifiant facultatif de la conversation pour poursuivre une conversation existante
Retourne :
dict : contient conversation_id, response et execution_time
"""
start_time = datetime.utcnow()
try:
# Obtenir ou créer une conversation
session = self.db_manager.get_session()
if conversation_id:
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
else:
# Créer une nouvelle conversation
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
user = User(user_id=user_id, name=user_id)
session.add(user)
session.commit()
conversation = Conversation(
conversation_id=f"conv_{user_id}_{datetime.utcnow().timestamp()}",
user_id=user.id,
title=message[:100]
)
session.add(conversation)
session.commit()
# Enregistrer le message de l'utilisateur
user_message = Message(
conversation_id=conversation.id,
role="user",
content=message,
model=self.model_name
)
session.add(user_message)
session.commit()
# Obtenir la réponse de l'agent
response = self.agent_executor.invoke({
"input": f"[ID utilisateur : {user_id}] {message}"
})
# Enregistrer le message de l'assistant
assistant_message = Message(
conversation_id=conversation.id,
role="assistant",
content=response['output'],
model=self.model_name
)
session.add(assistant_message)
session.commit()
# Enregistrer l'opération
execution_time = (datetime.utcnow() - start_time).total_seconds()
log_entry = AgentLog(
conversation_id=conversation.conversation_id,
level="INFO",
operation="chat",
message="Chat traité avec succès",
execution_time=execution_time
)
session.add(log_entry)
session.commit()
# Extraire conversation_id avant de fermer la session
conversation_id_result = conversation.conversation_id
session.close()
logger.info(f"✓ Chat traité pour l'utilisateur {user_id} en {execution_time:.2f}s")
return {
'conversation_id': conversation_id_result,
'response': response['output'],
'execution_time': execution_time
}
except Exception as e:
logger.error(f"❌ Erreur lors du traitement du chat : {e}")
# Enregistrer l'erreur
session = self.db_manager.get_session()
error_log = AgentLog(
conversation_id=conversation_id or "unknown",
level="ERROR",
operation="chat",
message=str(e),
error_details={'exception_type': type(e).__name__}
)
session.add(error_log)
session.commit()
session.close()
raiseLe DataPersistentAgent encapsule l’agent d’appel de fonction de LangChain avec des outils de base de données. L’outil SaveUserInfo conserve les données utilisateur en créant ou en mettant à jour des enregistrements utilisateur. L’outil RetrieveHistory interroge les conversations passées pour fournir un contexte. L’invite système demande à l’agent d’être proactif en matière de sauvegarde des informations et de vérification de l’historique. Le ConversationBufferMemory conserve le contexte à court terme au sein des sessions. Le stockage en base de données assure la persistance à long terme entre les sessions.
Étape 3.5 : Création du module de collecte de données
Construisez des outils pour extraire et structurer les données des conversations. Le collecteur génère des résumés, extrait les préférences et identifie les entités à l’aide du LLM.
class DataCollector:
"""
Collecte et structure les données issues des conversations des agents.
Ce module :
- Génère des résumés de conversation
- Extrait les préférences des utilisateurs à partir de l'historique des conversations
- Identifie et enregistre les entités nommées
"""
def __init__(self, db_manager: DatabaseManager, llm: ChatOpenAI):
"""
Initialise le collecteur de données.
Arguments :
db_manager : instance du gestionnaire de base de données
llm : modèle linguistique pour l'analyse de texte
"""
self.db_manager = db_manager
self.llm = llm
logger.info("✓ Collecteur de données initialisé")
def extract_conversation_summary(self, conversation_id: str) -> str:
"""
Générer et enregistrer le résumé de la conversation à l'aide du LLM.
Arguments :
conversation_id : ID de la conversation à résumer
Renvoie :
str : texte du résumé généré
"""
try:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return "Conversation introuvable"
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
# Créer le texte de la conversation
conv_text = "n".join([
f"{msg.role}: {msg.content}" for msg in messages
])
# Générer un résumé à l'aide de LLM
summary_prompt = f"""Résumez la conversation suivante en 2 ou 3 phrases, en reprenant les principaux sujets et résultats :
{conv_text}
Résumé :"""
summary_response = self.llm.invoke([HumanMessage(content=summary_prompt)])
summary = summary_response.content
# Mettre à jour la conversation avec le résumé
conversation.summary = summary
session.commit()
session.close()
logger.info(f"✓ Résumé généré pour la conversation {conversation_id}")
return summary
except Exception as e:
logger.error(f"Échec de la génération du résumé : {e}")
return ""
def extract_user_preferences(self, user_id: str) -> Dict[str, Any]:
"""
Extraire et enregistrer les préférences utilisateur à partir de l'historique des conversations.
Arguments :
user_id : ID de l'utilisateur à analyser
Renvoie :
dict : préférences extraites
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Obtenir les conversations récentes
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(10).all()
all_messages = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
all_messages.extend([msg.content for msg in messages if msg.role == "user"])
if not all_messages:
return {}
# Analyser les préférences à l'aide de LLM
analysis_prompt = f"""Analysez les messages suivants d'un utilisateur et extrayez ses préférences, ses centres d'intérêt et son style de communication.
Messages :
{chr(10).join(all_messages[:20])}
Renvoyez un objet JSON avec la structure suivante :
{{
"interests": ["interest1", "interest2"],
« communication_style » : « description »,
« preferred_topics » : [« topic1 », « topic2 »],
« language_preference » : « language »
}}"""
response = self.llm.invoke([HumanMessage(content=analysis_prompt)])
try:
# Extraire JSON de la réponse
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
preferences = json.loads(content)
# Mettre à jour les préférences de l'utilisateur
user.preferences = preferences
session.commit()
logger.info(f"✓ Préférences extraites pour l'utilisateur {user_id}")
return preferences
except json.JSONDecodeError:
logger.warning("Échec de l'analyse du JSON des préférences")
return {}
finally:
session.close()
except Exception as e:
logger.error(f"Échec de l'extraction des préférences : {e}")
return {}
def extract_entities_with_llm(self, conversation_id: str) -> List[Dict[str, Any]]:
"""
Extraire les entités nommées à l'aide de LLM.
Arguments :
conversation_id : ID de la conversation à analyser
Renvoie :
list : liste des entités extraites
"""
try :
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation :
return []
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
conv_text = "n".join([msg.content for msg in messages])
# Extraire les entités à l'aide de LLM
entity_prompt = f"""Extraire les entités nommées de la conversation suivante. Identifier :
- Personnes (PERSONNE)
- Organisations (ORG)
- Lieux (LOC)
- Dates (DATE)
- Produits (PRODUIT)
- Technologies (TECH)
Conversation :
{conv_text}
Renvoyer un tableau JSON d'entités au format :
[
{{"type": "PERSON", "value": "John Doe", "context": "mentioned as team lead"}},
{{"type": "ORG", "value": "Acme Corp", "context": "customer company"}}
]"""
response = self.llm.invoke([HumanMessage(content=entity_prompt)])
try:
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
entities_data = json.loads(content)
# Enregistrer les entités dans la base de données
saved_entities = []
for entity_data in entities_data:
entity = Entity(
conversation_id=conversation.id,
entity_type=entity_data['type'],
entity_value=entity_data['value'],
context=entity_data.get('context', ''),
confidence=0.9 # L'extraction LLM a un niveau de confiance élevé
)
session.add(entity)
saved_entities.append(entity_data)
session.commit()
session.close()
logger.info(f"✓ Extraction de {len(saved_entities)} entités à partir de la conversation {conversation_id}")
return saved_entities
except json.JSONDecodeError:
logger.warning("Échec de l'analyse JSON des entités")
return []
except Exception as e:
logger.error(f"Échec de l'extraction des entités : {e}")
return []Le DataCollector utilise le LLM pour analyser les conversations. La méthode extract_conversation_summary crée des résumés concis des conversations. La méthode extract_user_preferences analyse les modèles de messages afin d’identifier les centres d’intérêt et les styles de communication des utilisateurs. La méthode extract_entities_with_llm utilise des invites structurées pour extraire des entités nommées telles que des personnes, des organisations et des technologies. Toutes les données extraites sont enregistrées dans la base de données pour référence ultérieure.
Étape 4 : Création du pipeline de traitement intelligent des données
Implémentez un traitement en arrière-plan pour gérer la collecte de données sans bloquer l’agent. Le pipeline utilise des threads de travail et des files d’attente pour traiter les résumés et les entités.
class DataProcessingPipeline:
"""
Pipeline de traitement des données asynchrone.
Ce pipeline :
- Traite les conversations en arrière-plan
- Génère des résumés
- Extrait des entités sans bloquer le flux principal
- Met à jour périodiquement les préférences des utilisateurs
"""
def __init__(self, db_manager: DatabaseManager, collector: DataCollector, batch_size: int = 10) :
"""
Initialise le pipeline de traitement.
Arguments :
db_manager : instance du gestionnaire de base de données
collector : collecteur de données pour les opérations de traitement
batch_size : nombre d'éléments à traiter dans chaque lot
"""
self.db_manager = db_manager
self.collector = collector
self.batch_size = batch_size
# Files d'attente de traitement
self.summary_queue = Queue()
self.entity_queue = Queue()
self.preference_queue = Queue()
# Threads de travail
self.workers = []
self.running = False
logger.info("✓ Pipeline de traitement des données initialisé")
def start(self):
"""Démarrer les travailleurs de traitement en arrière-plan."""
self.running = True
# Créer des threads de travail
summary_worker = Thread(target=self._process_summaries, daemon=True)
entity_worker = Thread(target=self._process_entities, daemon=True)
preference_worker = Thread(target=self._process_preferences, daemon=True)
summary_worker.start()
entity_worker.start()
preference_worker.start()
self.workers = [summary_worker, entity_worker, preference_worker]
logger.info("✓ 3 processus d'arrière-plan lancés")
def stop(self):
"""Arrêter les processus d'arrière-plan."""
self.running = False
for worker in self.workers:
worker.join(timeout=5)
logger.info("✓ Processus d'arrière-plan arrêtés")
def queue_conversation_for_processing(self, conversation_id: str, user_id: str):
"""
Ajouter la conversation aux files d'attente de traitement.
Arguments :
conversation_id : ID de la conversation à traiter
user_id : ID de l'utilisateur pour l'extraction des préférences
"""
self.summary_queue.put(conversation_id)
self.entity_queue.put(conversation_id)
self.preference_queue.put(user_id)
logger.info(f"✓ Conversation {conversation_id} mise en file d'attente pour traitement")
def _process_summaries(self):
"""Processeur pour le traitement des résumés de conversation."""
while self.running:
try:
if not self.summary_queue.empty():
conversation_id = self.summary_queue.get()
self.collector.extract_conversation_summary(conversation_id)
self.summary_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Erreur dans le travailleur de résumé : {e}")
def _process_entities(self):
"""Travailleur chargé du traitement de l'extraction d'entités."""
while self.running:
try:
if not self.entity_queue.empty():
conversation_id = self.entity_queue.get()
self.collector.extract_entities_with_llm(conversation_id)
self.entity_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Erreur dans le travailleur d'entité : {e}")
def _process_preferences(self):
"""Worker pour le traitement des préférences utilisateur."""
while self.running:
try:
if not self.preference_queue.empty():
user_id = self.preference_queue.get()
self.collector.extract_user_preferences(user_id)
self.preference_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Erreur dans le travailleur de préférences : {e}")
def get_queue_status(self) -> Dict[str, int]:
"""
Obtenir les tailles actuelles des files d'attente.
Renvoie :
dict : tailles des files d'attente pour chaque type de traitement
"""
return {
'summary_queue': self.summary_queue.qsize(),
'entity_queue': self.entity_queue.qsize(),
'preference_queue': self.preference_queue.qsize()
}Le ProcessingPipeline dissocie la collecte de données du traitement des messages. Lorsqu’une conversation est terminée, elle est ajoutée aux files d’attente plutôt que d’être traitée immédiatement. Des threads de travail distincts extraient ces files d’attente et traitent les éléments en arrière-plan. Cela empêche la collecte de données de bloquer les réponses des agents. Le paramètre daemon=True garantit que les workers se terminent lorsque le programme principal se ferme. La surveillance de l’état des files d’attente permet de suivre les retards de traitement.
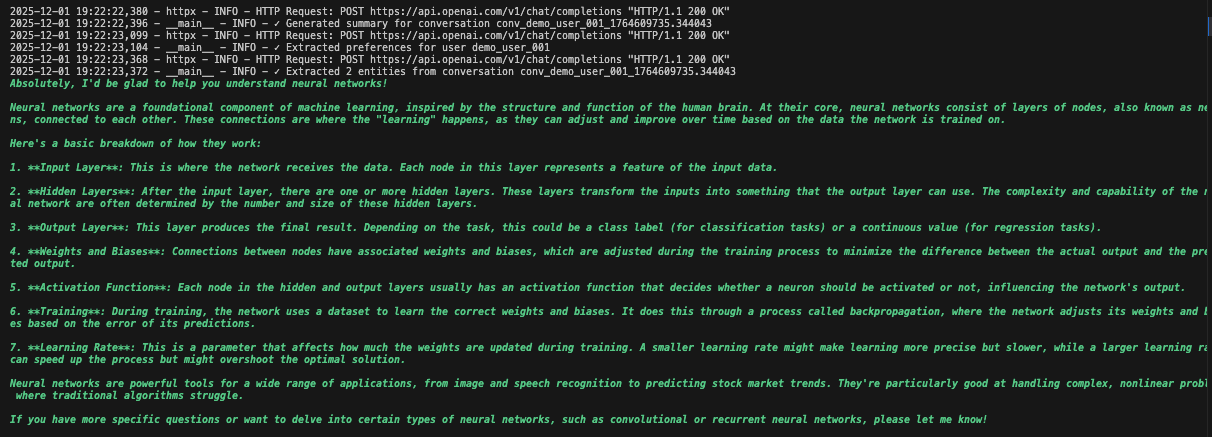
Étape 5 : Ajout d’une surveillance et d’une journalisation en temps réel
Créez un système de surveillance pour suivre les performances des agents, détecter les erreurs et générer des rapports. Le moniteur analyse les journaux pour fournir des informations opérationnelles.
class AgentMonitor:
"""
Surveillance en temps réel et collecte de métriques.
Ce module :
- Suit les métriques de performance
- Surveille la santé du système
- Génère des rapports analytiques
"""
def __init__(self, db_manager: DatabaseManager):
"""
Initialise le moniteur d'agent.
Args :
db_manager : instance du gestionnaire de base de données
"""
self.db_manager = db_manager
logger.info("✓ Moniteur d'agent initialisé")
def get_performance_metrics(self, hours: int = 24) -> Dict[str, Any]:
"""
Obtient les mesures de performance pour la période spécifiée.
Arguments :
hours : nombre d'heures à examiner
Renvoie :
dict : mesures de performance, y compris le nombre d'opérations et les taux d'erreur
"""
try :
session = self.db_manager.get_session()
cutoff_time = datetime.utcnow() - timedelta(hours=hours)
# Requête des journaux
logs = session.query(AgentLog).filter(
AgentLog.created_at >= cutoff_time
).all()
# Calculer les mesures
total_operations = len(logs)
error_count = len([log for log in logs if log.level == "ERROR"])
avg_execution_time = sum([log.execution_time or 0 for log in logs]) / max(total_operations, 1)
# Obtenir le nombre de conversations
conversations = session.query(Conversation).filter(
Conversation.created_at >= cutoff_time
).count()
messages = session.query(Message).join(Conversation).filter(
Message.created_at >= cutoff_time
).count()
session.close()
metrics = {
'time_period_hours' : hours,
'total_operations' : total_operations,
'error_count' : error_count,
'error_rate' : error_count / max(total_operations, 1),
'avg_execution_time': avg_execution_time,
'conversations_created': conversations,
'messages_processed': messages
}
logger.info(f"✓ Indicateurs de performance générés pour les dernières {hours} heures")
return metrics
except Exception as e:
logger.error(f"Échec de l'obtention des mesures de performance : {e}")
return {}
def health_check(self) -> Dict[str, Any]:
"""
Effectuer un contrôle de santé.
Renvoie :
dict : état de santé, y compris la connectivité de la base de données et les taux d'erreur
"""
try:
# Vérifier la connectivité de la base de données
db_healthy = self.db_manager.health_check()
# Vérifier le taux d'erreur récent
metrics = self.get_performance_metrics(hours=1)
recent_errors = metrics.get('error_count', 0)
# Déterminer l'état général
is_healthy = db_healthy and recent_errors < 10
health_status = {
'status': 'healthy' if is_healthy else 'degraded',
'database_connected': db_healthy,
'recent_errors': recent_errors,
'timestamp': datetime.utcnow().isoformat()
}
logger.info(f"✓ Vérification de l'état : {health_status['status']}")
return health_status
except Exception as e:
logger.error(f"Health check failed: {e}")
return {
'status': 'unhealthy',
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
}AgentMonitor offre une visibilité sur les opérations du système. Il suit des métriques telles que le nombre total d’opérations, les taux d’erreur et les temps d’exécution moyens en interrogeant la table AgentLog. La méthode get_metrics calcule des statistiques sur des fenêtres temporelles configurables. La méthode get_error_report récupère des informations détaillées sur les erreurs à des fins de débogage. Cette surveillance permet une détection proactive des problèmes. Les taux d’erreur élevés déclenchent une enquête avant que les utilisateurs ne soient affectés.
Étape 6 : Création de l’interface de requête
Créez des fonctionnalités de requête pour récupérer et analyser les données stockées. L’interface fournit des méthodes pour rechercher des conversations, suivre des entités et générer des analyses.
class DataQueryInterface:
"""
Interface pour interroger les données stockées par l'agent.
Ce module fournit des méthodes pour :
- Interroger les analyses utilisateur
- Récupérer l'historique des conversations
- Rechercher des informations spécifiques
"""
def __init__(self, db_manager: DatabaseManager):
"""
Initialiser l'interface de requête.
Args :
db_manager : instance du gestionnaire de base de données
"""
self.db_manager = db_manager
logger.info("✓ Interface de requête initialisée")
def get_user_analytics(self, user_id: str) -> Dict[str, Any]:
"""
Obtenir les analyses pour un utilisateur spécifique.
Arguments :
user_id : ID de l'utilisateur à analyser
Renvoie :
dict : analyses utilisateur, y compris le nombre de conversations et les préférences
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Obtenir le nombre de conversations
conversation_count = session.query(Conversation).filter_by(user_id=user.id).count()
# Obtenir le nombre de messages
message_count = session.query(Message).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obtenir le nombre d'entités
entity_count = session.query(Entity).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obtenir la plage horaire
first_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at).first()
last_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at.desc()).first()
session.close()
analytics = {
'user_id': user_id,
'name': user.name,
'conversation_count': conversation_count,
'message_count': message_count,
'entity_count': entity_count,
'preferences': user.preferences,
'first_interaction': first_conversation.created_at.isoformat() if first_conversation else None,
'last_interaction': last_conversation.created_at.isoformat() if last_conversation else None,
'avg_messages_per_conversation': message_count / max(conversation_count, 1)
}
logger.info(f"✓ Analyses générées pour l'utilisateur {user_id}")
return analytics
except Exception as e:
logger.error(f"Échec de l'obtention des analyses utilisateur : {e}")
return {}L’interface QueryInterface fournit des méthodes pour accéder aux données stockées. La méthode get_user_conversations récupère l’historique complet des conversations avec inclusion facultative des messages. La méthode search_conversations effectue une recherche en texte intégral dans le contenu des messages à l’aide de l’opérateur ILIKE de SQL. La méthode get_entity_mentions trouve toutes les conversations dans lesquelles des entités spécifiques ont été mentionnées. La méthode get_user_analytics génère des statistiques sur l’activité des utilisateurs. Ces requêtes permettent de créer des tableaux de bord, de générer des rapports et de créer des expériences personnalisées.
Étape 7 : Création d’un RAG avec les données web en temps réel de Bright Data
Améliorez votre agent connecté à la base de données grâce aux capacités RAG de l’intelligence web en temps réel de Bright Data. Cette intégration combine votre historique de conversations avec des données web récentes pour obtenir de meilleures réponses.
class BrightDataRAGEnhancer:
"""
Améliorez l'agent à persistance de données grâce à l'intelligence web de Bright Data.
Ce module :
- Récupère les données web en temps réel de Bright Data
- Ingère les données web dans le magasin vectoriel pour RAG
- Améliore l'agent grâce à des connaissances enrichies par le web
"""
def __init__(self, api_key: str, db_manager: DatabaseManager):
"""
Initialise l'optimiseur RAG avec Bright Data.
Arguments :
api_key : clé API Bright Data
db_manager : instance du gestionnaire de base de données
"""
self.api_key = api_key
self.db_manager = db_manager
self.base_url = "https://api.brightdata.com"
# Initialise le magasin de vecteurs pour RAG
self.embeddings = OpenAIEmbeddings()
self.vector_store = Chroma(
embedding_function=self.embeddings,
persist_directory="./chroma_db"
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
logger.info("✓ Bright Data RAG enhancer initialisé")
def fetch_dataset_data(
self,
dataset_id: str,
filters: Optional[Dict[str, Any]] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""
Récupère les données depuis Bright Data Dataset Marketplace.
Arguments :
dataset_id : ID du jeu de données à récupérer
filters : filtres facultatifs pour les données
limit : nombre maximal d'enregistrements à récupérer
Retourne :
list : enregistrements du jeu de données récupérés
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/datasets/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
try:
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
data = response.json()
logger.info(f"✓ Retrieved {len(data)} records from Bright Data dataset {dataset_id}")
return data
except Exception as e:
logger.error(f"Échec de la récupération de l'ensemble de données Bright Data : {e}")
return []
def ingest_web_data_to_rag(
self,
dataset_records: List[Dict[str, Any]],
text_fields: List[str],
metadata_fields: Optional[List[str]] = None
) -> int:
"""
Ingérer les données web dans le magasin vectoriel RAG.
Arguments :
dataset_records : enregistrements provenant de Bright Data
text_fields : champs à utiliser comme contenu textuel
metadata_fields : champs à inclure dans les métadonnées
Retourne :
int : nombre de morceaux de documents ingérés
"""
try :
documents = []
for record in dataset_records :
# Combiner les champs de texte
text_content = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if not text_content.strip():
continue
# Créer les métadonnées
metadata = {
"source": "bright_data",
"record_id": record.get("id", "unknown"),
"timestamp": datetime.utcnow().isoformat()
}
if metadata_fields:
for field in metadata_fields:
if field in record:
metadata[field] = record[field]
# Diviser le texte en morceaux
chunks = self.text_splitter.split_text(text_content)
for chunk in chunks:
documents.append({
"content": chunk,
"metadata": metadata
})
# Ajouter au magasin vectoriel
if documents:
texts = [doc["content"] for doc in documents]
metadatas = [doc["metadata"] for doc in documents]
self.vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
logger.info(f"✓ Ingestion de {len(documents)} morceaux de documents dans RAG")
return len(documents)
except Exception as e :
logger.error(f"Échec de l'ingestion des données Web dans RAG : {e}")
return 0
def create_rag_enhanced_agent(
self,
base_agent: DataPersistentAgent
) -> DataPersistentAgent:
"""
Améliorez l'agent existant avec les capacités RAG.
Arguments :
base_agent : agent de base à améliorer
Renvoie :
DataPersistentAgent : agent amélioré avec l'outil RAG
"""
def rag_search(query: str) -> str:
"""Recherche à la fois dans l'historique des conversations et dans les données Web."""
try:
# Récupérer à partir de l'historique des conversations
session = self.db_manager.get_session()
messages = session.query(Message).filter(
Message.content.ilike(f'%{query}%')
).order_by(Message.created_at.desc()).limit(5).all()
results = []
for msg in messages:
results.append({
'content': msg.content,
'source': 'conversation_history',
'relevance': 0.8
})
session.close()
# Récupération à partir du magasin vectoriel (données Web)
try:
vector_results = self.vector_store.similarity_search_with_score(query, k=5)
for doc, score in vector_results:
results.append({
'content': doc.page_content,
'source': 'web_data',
'relevance': 1 - score
})
except Exception as e:
logger.error(f"Échec de la récupération à partir du magasin vectoriel : {e}")
if not results:
return "Aucune information pertinente trouvée."
# Formater le contexte
context_text = "nn".join([
f"[{item['source']}] {item['content'][:200]}..."
for item in results[:5]
])
return f"Contexte récupéré :n{context_text}"
except Exception as e:
logger.error(f"Échec de la recherche RAG : {e}")
return f"Erreur lors de la recherche : {str(e)}"
# Ajouter l'outil RAG à l'agent
rag_tool = Tool(
name="SearchKnowledgeBase",
func=rag_search,
description="Rechercher des informations pertinentes à la fois dans l'historique des conversations et dans les données Web en temps réel. L'entrée doit être une requête de recherche."
)
base_agent.tools.append(rag_tool)
# Recréer l'agent avec de nouveaux outils
base_agent.agent = create_openai_functions_agent(
llm=base_agent.llm,
tools=base_agent.tools,
prompt=base_agent.prompt
)
base_agent.agent_executor = AgentExecutor(
agent=base_agent.agent,
tools=base_agent.tools,
memory=base_agent.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info("✓ Agent amélioré avec capacités RAG")
return base_agentBrightDataEnhancer intègre des données web en temps réel à votre agent. La méthode fetch_dataset récupère des données structurées depuis la place de marché Bright Data. La méthode ingest_to_rag traite et découpe ces données. Elle les stocke dans une base de données vectorielle Chroma pour la recherche sémantique. La méthode retrieve_context effectue une recherche hybride. Elle combine l’historique de la base de données avec la recherche de similarité vectorielle. La méthode create_rag_tool regroupe cette fonctionnalité dans un outil LangChain utilisé par l’agent. La méthode enhance_agent ajoute cette fonctionnalité RAG à votre agent existant. Elle permet à l’agent de répondre à des questions en utilisant à la fois l’historique des conversations internes et les données externes récentes.
Exécution de votre système d’agent complet avec persistance des données
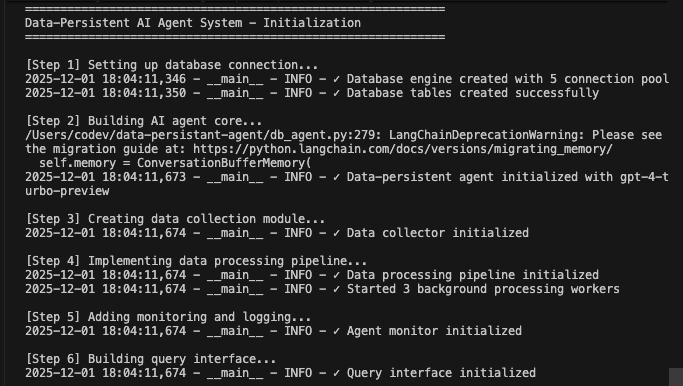
Rassemblez tous les composants pour créer un système fonctionnel.
def main():
"""Flux d'exécution principal démontrant le fonctionnement conjoint de tous les composants."""
print("=" * 60)
print("Système d'agent IA à persistance de données - Initialisation")
print("=" * 60)
# Étape 1 : Initialisation de la base de données
print("n[Étape 1] Configuration de la connexion à la base de données...")
db_manager = DatabaseManager(
database_url=os.getenv("DATABASE_URL"),
pool_size=5,
max_retries=3
)
db_manager.initialize_database()
# Étape 2 : initialiser l'agent principal
print("n[Étape 2] Création du noyau de l'agent IA...")
agent = DataPersistentAgent(
db_manager=db_manager,
model_name=os.getenv("AGENT_MODEL", "gpt-4-turbo-preview")
)
# Étape 3 : Initialisation du collecteur de données
print("n[Étape 3] Création du module de collecte de données...")
collector = DataCollector(db_manager, agent.llm)
# Étape 4 : Initialisation du pipeline de traitement
print("n[Étape 4] Mise en œuvre du pipeline de traitement des données...")
pipeline = DataProcessingPipeline(db_manager, collector)
pipeline.start()
# Étape 5 : Initialisation de la surveillance
print("n[Étape 5] Ajout de la surveillance et de la journalisation...")
monitor = AgentMonitor(db_manager)
# Étape 6 : Initialisation de l'interface de requête
print("n[Étape 6] Création de l'interface de requête...")
query_interface = DataQueryInterface(db_manager)
# Étape 7 : Amélioration RAG Bright Data facultative
print("n[Étape 7] Amélioration RAG (facultative)...")
bright_data_key = os.getenv("BRIGHT_DATA_API_KEY")
if bright_data_key and bright_data_key != "your-bright-data-api-key":
print("Récupération des données web en temps réel depuis Bright Data...")
enhancer = BrightDataRAGEnhancer(bright_data_key, db_manager)
# Exemple : récupération et intégration des données web
web_data = enhancer.fetch_dataset_data(
dataset_id="example_dataset_id",
limit=100
)
if web_data:
enhancer.ingest_web_data_to_rag(
dataset_records=web_data,
text_fields=["title", "content", "description"],
metadata_fields=["url", "published_date"]
)
# Améliorer l'agent avec RAG
agent = enhancer.create_rag_enhanced_agent(agent)
print("✓ Agent amélioré avec les capacités RAG de Bright Data")
else:
print("⚠️ Clé API Bright Data introuvable - intégration des données web ignorée")
print("n" + "=" * 60)
print("Conversations de démonstration")
print("=" * 60)
# Interactions utilisateur de démonstration
test_user = "demo_user_001"
# Première conversation
print("n📝 Conversation 1 :")
response1 = agent.chat(
user_id=test_user,
message="Bonjour ! Je souhaite en savoir plus sur l'apprentissage automatique. »
)
print(f"Agent : {response1['response']}n")
# File d'attente pour traitement
pipeline.queue_conversation_for_processing(
response1['conversation_id'],
test_user
)
# Deuxième conversation
print("📝 Conversation 2 :")
response2 = agent.chat(
user_id=test_user,
message="Aidez-moi à comprendre les réseaux neuronaux ?",
conversation_id=response1['conversation_id']
)
print(f"Agent : {response2['response']}n")
# Attendre le traitement en arrière-plan
print("⏳ Traitement des données en arrière-plan...")
time.sleep(5)
print("n" + "=" * 60)
print("Analyses et surveillance")
print("=" * 60)
# Obtenir les mesures de performance
metrics = monitor.get_performance_metrics(hours=1)
print(f"n📊 Indicateurs de performance :")
print(f" - Total des opérations : {metrics.get('total_operations', 0)}")
print(f" - Taux d'erreur : {metrics.get('error_rate', 0):.2%}")
print(f" - Temps d'exécution moyen : {metrics.get('avg_execution_time', 0):.2f}s")
print(f" - Conversations créées : {metrics.get('conversations_created', 0)}")
print(f" - Messages traités : {metrics.get('messages_processed', 0)}")
# Obtenir les analyses utilisateur
analytics = query_interface.get_user_analytics(test_user)
print(f"n👤 Analyses utilisateur :")
print(f" - Nombre de conversations : {analytics.get('conversation_count', 0)}")
print(f" - Nombre de messages : {analytics.get('message_count', 0)}")
print(f" - Nombre d'entités : {analytics.get('entity_count', 0)}")
print(f" - Moyenne de messages/conversation : {analytics.get('avg_messages_per_conversation', 0):.1f}")
# Vérification de l'état
health = monitor.health_check()
print(f"n🏥 État du système : {health['status']}")
# État de la file d'attente
queue_status = pipeline.get_queue_status()
print(f"n📋 Files d'attente en cours de traitement :")
print(f" - File d'attente récapitulative : {queue_status['summary_queue']}")
print(f" - File d'attente des entités : {queue_status['entity_queue']}")
print(f" - File d'attente des préférences : {queue_status['preference_queue']}")
# Arrêt du pipeline
pipeline.stop()
print("n" + "=" * 60)
print("Système d'agent à persistance des données - Terminé")
print("=" * 60)
print("n✓ Toutes les données ont été conservées dans la base de données")
print("✓ Traitement en arrière-plan terminé")
print("✓ Système prêt pour une utilisation en production")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("nn⚠️ Arrêt progressif...")
except Exception as e:
logger.error(f"Erreur système : {e}")
import traceback
traceback.print_exc()Exécutez votre système d’agent connecté à la base de données :
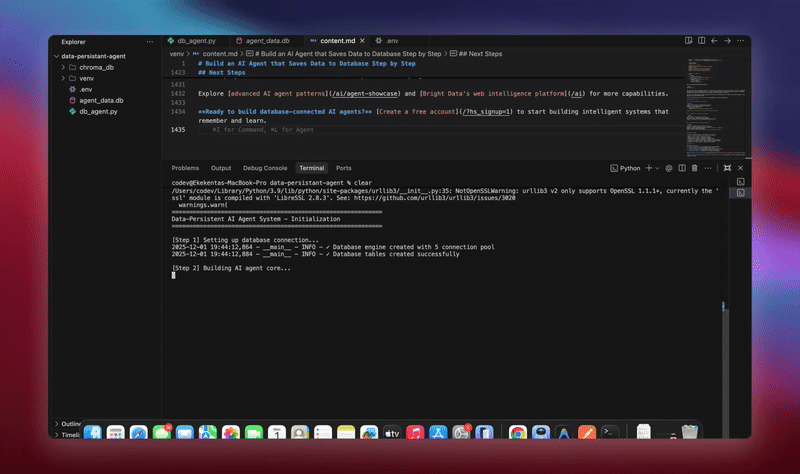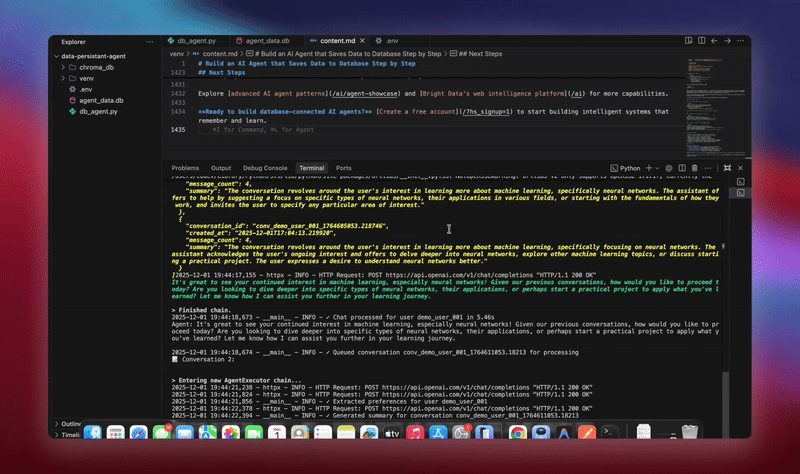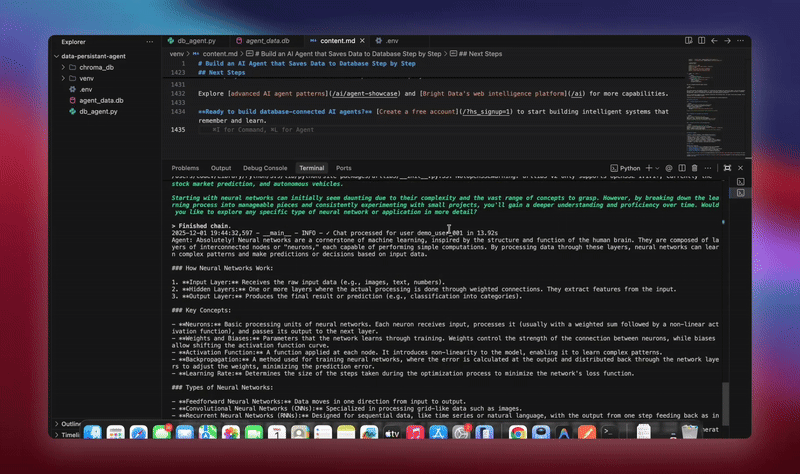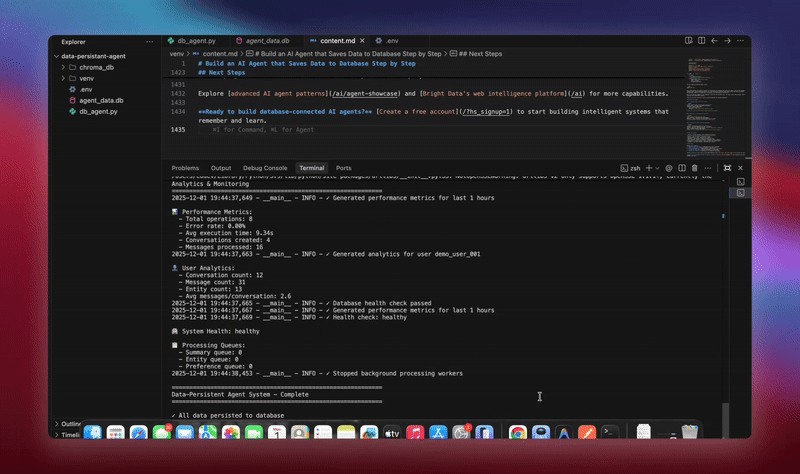
python agent.pyLe système exécute le workflow complet. Il initialise la base de données et crée toutes les tables. Il configure l’agent LangChain avec les outils de base de données. Il démarre les processus d’arrière-plan pour le traitement. Il traite les conversations de démonstration et les enregistre dans la base de données. Il extrait les entités et génère des résumés en arrière-plan. Il affiche des analyses et des métriques en temps réel.
Vous verrez des journaux détaillés à mesure que chaque composant initialise et traite les données. L’agent stocke chaque message. Il extrait des informations. Il conserve le contexte complet de la conversation.
Cas d’utilisation pratiques
1. Assistance client avec historique complet
# L'agent récupère les interactions passées.
support_agent = DataPersistentAgent(db_manager)
response = support_agent.chat(
user_id="customer_123",
message="I'm still having that connection issue")
# L'agent consulte les conversations précédentes concernant les problèmes de connexion.2. Assistant IA personnel avec apprentissage
# L'agent apprend les préférences au fil du temps
query_interface = QueryInterface(db_manager)
analytics = query_interface.get_user_analytics("user_456")
# Affiche les modèles d'interaction, les préférences, les sujets courants3. Assistant de recherche avec base de connaissances
# Combine l'historique des conversations avec les données web
enhancer = BrightDataEnhancer(api_key, db_manager)
enhancer.ingest_to_rag(research_data, ["title", "abstract", "content"])
agent = enhancer.enhance_agent(agent)
# L'agent se réfère à la fois aux discussions passées et aux dernières recherchesRésumé des avantages
| Fonction | Sans base de données | Avec base de données Persistance |
|---|---|---|
| Mémoire | Perdue au redémarrage | Stockage permanent |
| Personnalisation | Aucune | Basée sur l’historique complet |
| Analyses | Impossible | Données d’interaction complètes |
| Récupération des erreurs | Intervention manuelle | Nouvelle tentative automatique et journalisation |
| Évolutivité | Instance unique | Multi-instance avec état partagé |
| Informations | Perdu après la session | Extrait et suivi |
Conclusion
Vous disposez désormais d’un système d’agent IA prêt à l’emploi qui conserve les conversations dans des bases de données. Le système stocke chaque interaction, extrait les entités et les informations, conserve l’historique complet des conversations et assure une surveillance avec récupération automatique des erreurs.
Améliorez-le en ajoutant l’authentification des utilisateurs pour un accès sécurisé, en créant des tableaux de bord pour visualiser les analyses, en mettant en œuvre des intégrations pour la recherche sémantique, en créant des points de terminaison API pour l’intégration ou en le déployant avec Docker pour plus d’évolutivité. La conception modulaire permet une personnalisation facile en fonction de vos besoins spécifiques.
Découvrez les modèles avancés d’agents IA et la plateforme de veille web de Bright Data pour bénéficier de fonctionnalités supplémentaires.
Créez un compte gratuit pour commencer à construire des systèmes intelligents qui mémorisent et apprennent.





