
Les outils d’automatisation des navigateurs sont devenus essentiels pour les développeurs qui créent des scanners Web, des robots ou des agents d’intelligence artificielle qui doivent interagir avec les sites Web. Alors que des outils open-source tels que Puppeteer et Playwright sont largement utilisés, Agent Browser de Bright Data apporte une approche différente, conçue pour la furtivité, l’échelle et les flux de travail natifs de l’IA.
Dans ce guide, vous apprendrez :
- En quoi Agent Browser diffère de Puppeteer et Playwright en termes de furtivité et d’empreintes digitales.
- Les fonctionnalités intégrées fournies par Bright Data, telles que la rotation de proxy et la gestion automatisée des sessions.
- Scénarios dans lesquels chaque outil excelle ou échoue.
- Les limites de l’Agent Browser et des cadres traditionnels, et quand choisir l’un ou l’autre.
Pourquoi comparer Agent Browser, Marionnettiste et Dramaturge ?
L’automatisation des navigateurs est devenue une solution incontournable pour les développeurs qui créent des scrapers, des bots et des agents d’intelligence artificielle. Qu’il s’agisse de collecter des données à partir de pages web dynamiques, d’effectuer des connexions automatisées ou d’exécuter des tâches répétitives à grande échelle, les frameworks de navigateur sont désormais un élément essentiel des flux de développement modernes.
Parmi les outils les plus populaires dans ce domaine figurent Puppeteer et Playwright, deux bibliothèques open-source basées sur Node.js qui fournissent une API de haut niveau pour contrôler les navigateurs complets ou sans tête. Puppeteer, maintenu par l’équipe Chrome, est connu pour son intégration étroite avec Chromium et Playwright, développé par Microsoft, s’appuie sur cette base en prenant en charge plusieurs navigateurs (Chromium, Firefox et WebKit) et en permettant des fonctionnalités plus avancées comme les contextes multi-pages et les attentes intégrées. Ces outils ont été largement adoptés en raison de leur flexibilité et de leur contrôle, en particulier pour la création de flux de travail personnalisés.
Cependant, comme les sites web proposent des mécanismes de détection des robots de plus en plus agressifs, de nombreux développeurs passent plus de temps à relever des défis tels que l’empreinte digitale, la résolution de CAPTCHA et la rotation de proxy qu’à écrire de la logique d’entreprise. C’est là qu’intervient notre Agent Browser.
Conçu spécifiquement pour les agents d’IA et les flux de travail d’automatisation, l’Agent Browser fait abstraction d’une grande partie du travail de bas niveau que les utilisateurs de Puppeteer et de Playwright doivent gérer manuellement. Il s’agit d’un environnement de navigation complet conçu pour imiter les utilisateurs réels, avec des fonctions de furtivité, de gestion de proxy, de persistance de session et de gestion CAPTCHA intégrées. Il fait partie de l’infrastructure plus large de Bright Data pour la collecte de données web à grande échelle, et il est conçu pour aider les développeurs à se concentrer sur leurs objectifs d’automatisation plutôt que sur la plomberie nécessaire pour ne pas être détectés.
Principales différences : Furtivité et empreintes digitales
L’un des plus grands défis de l’automatisation des navigateurs est aujourd’hui d’éviter la détection. Les sites web utilisent de plus en plus des systèmes sophistiqués de détection des robots qui surveillent tout, depuis la non-concordance des empreintes digitales du navigateur jusqu’aux mouvements de la souris, etc. C’est là que des outils comme Puppeteer et Playwright commencent à montrer leurs limites.
Puppeteer et Playwright ne sont pas livrés avec des fonctions de furtivité ou d’anti-détection. Les développeurs doivent souvent patcher manuellement des outils tels que puppeteer-extra-plugin-stealth, alterner les proxys ou modifier les en-têtes et les empreintes digitales pour rester sous le radar. Même dans ce cas, les taux de détection peuvent rester élevés, en particulier sur les sites dotés d’une protection avancée contre les robots.
Agent Browser, quant à lui, a été conçu pour que la furtivité soit une caractéristique de premier ordre. Il exécute des sessions de navigation à tête reposant sur le cloud qui imitent le comportement réel de l’utilisateur, avec des empreintes digitales humaines, des modèles de défilement et d’interaction naturels, et un contrôle intelligent de l’en-tête. Chaque session est lancée avec des caractéristiques de navigateur réalistes qui correspondent à l’emplacement, au type d’appareil et à la version du navigateur émulé.
Voici ce qu’il fait dans sa version initiale :
- Usurpation d’empreintes digitales: Agent Browser crée des empreintes digitales de navigateur qui ressemblent aux environnements réels des utilisateurs (contrairement aux signatures headless par défaut).
- Résolution des CAPTCHA: Il gère automatiquement les défis lorsqu’un CAPTCHA apparaît, réduisant ainsi les interruptions dans les flux automatisés.
- Rotation du proxy: Il assure la rotation des adresses IP et relance automatiquement les demandes si un blocage est détecté.
- Suivi des cookies et des sessions: Il conserve l’état de la session et les cookies de manière persistante, ce qui réduit la détection des demandes répétées.
Ces caractéristiques sont particulièrement importantes lorsque l’on récupère des sites web avec des mises en page dynamiques, des portes de connexion ou un contenu personnalisé. Par exemple, un magasin de commerce électronique affichant des prix ou des disponibilités spécifiques à une région. Sur de telles plateformes, même de petites incohérences dans le comportement du navigateur peuvent déclencher des blocages ou des réponses vides. Avec Agent Browser, les développeurs n’ont pas besoin de configurer manuellement des plugins de furtivité ou des proxys de rotation, tout est géré en arrière-plan.
Cette intégration étroite avec notre infrastructure de proxy signifie également que les développeurs peuvent accéder au contenu à partir de géolocalisations spécifiques, ajuster les en-têtes de référence et maintenir des sessions à long terme, ce qui en fait une option solide pour les flux de travail d’agents à plusieurs étapes.
Traitement des sessions et authentification
La gestion des sessions est essentiellement manuelle avec Puppeteer et Playwright ; les développeurs doivent capturer et réutiliser les cookies ou le stockage local, écrire la logique pour la persistance de la connexion, l’authentification, et gérer les jetons ou la protection CSRF. Cela accroît la complexité, en particulier à grande échelle.
Agent Browser automatise la persistance et la rotation des sessions. Les cookies et le stockage local sont gérés automatiquement dans le nuage, de sorte que l’état de la session est maintenu d’une page à l’autre et d’un onglet à l’autre sans logique personnalisée. Si une session est bloquée, une nouvelle session démarre avec une nouvelle IP et une nouvelle empreinte digitale. Aucun code de réessai ou de traitement CAPTCHA n’est nécessaire.
Cette automatisation réduit les interdictions d’IP, minimise les échecs de session et permet aux développeurs de se concentrer sur les tâches d’automatisation plutôt que sur la gestion des sessions. Elle est également intégrée au réseau de proxy de Bright Data pour un contrôle cohérent des identités.
Facilité d’utilisation et expérience des développeurs
L’un des facteurs clés que les développeurs prennent en compte lorsqu’ils choisissent un outil d’automatisation de navigateur est la rapidité avec laquelle ils peuvent passer de la configuration à la première exécution réussie. Avec Puppeteer et Playwright, la mise en route est simple si vous avez déjà travaillé avec des navigateurs sans tête. L’installation des bibliothèques, le lancement d’une instance de navigateur et la navigation sur une page ne nécessitent que quelques lignes de code. Mais dès que vous avez besoin d’ajouter le support de proxy, la gestion de CAPTCHA, l’empreinte digitale ou la persistance de session, les choses deviennent plus complexes. Vous devrez souvent installer des plugins supplémentaires, configurer des bibliothèques de proxy, gérer manuellement les cookies et résoudre les problèmes de détection.
Agent Browser est conçu pour réduire cette complexité. L’intégration peut se faire par le biais de l’API ou du MCP, sans qu’il soit nécessaire de procéder à une configuration par site. Il n’est pas nécessaire de maintenir votre propre infrastructure de navigateur ; il n’est pas nécessaire de patcher des plugins furtifs ou de faire tourner les IP manuellement, tout est géré automatiquement en arrière-plan.
Les développeurs peuvent choisir entre une expérience avec ou sans tête, avec un contrôle programmatique sur la session du début à la fin. Pour ceux qui préfèrent les flux de travail basés sur le code, Agent Browser est compatible avec Playwright, Puppeteer et Selenium. Les exemples de code ci-dessous vous aideront à l’intégrer dans votre stack existant avec un minimum de friction.
JavaScript :
const pw = require('playwright');
const SBR_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
// Scraping browswer here...
const browser = await pw.chromium.connectOverCDP(SBR_CDP);
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html);
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
// Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const { Builder, Browser } = require('selenium-webdriver');
const SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>';
async function main() {
console.log('Connecting to Scraping Browser...');
const driver = await new Builder()
.forBrowser(Browser.CHROME)
// Scraping browswer here...
.usingServer(SBR_WEBDRIVER)
.build();
try {
console.log('Connected! Navigating to <https://example.com>...');
await driver.get('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await driver.getPageSource();
console.log(html);
} finally {
driver.quit();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
Python :
import asyncio
from playwright.async_api import async_playwright
SBR_WS_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
# Scraping browswer here...
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to <https://example.com>...')
await page.goto('<https://example.com>')
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if __name__ == '__main__':
asyncio.run(main())
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
# Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>'
def main():
print('Connecting to Scraping Browser...')
# Scraping browswer here...
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to <https://example.com>...')
driver.get('<https://example.com>')
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
L’objectif est simple : éliminer la configuration standard, afin que les développeurs puissent se concentrer sur ce que leur automatisation doit faire, et non sur la manière de la faire fonctionner de manière fiable.
Sous le capot : des fonctions intégrées avec des données brillantes
Ce qui différencie le navigateur d’agents, c’est ce qui est déjà inclus au lancement de la session.
- Larotation du proxy est gérée automatiquement. Chaque session est soutenue par notre vaste réseau de proxy, qui comprend plus de 150 millions d’adresses IP résidentielles dans 195 pays.
- L’empreinte digitale du navigateur est conçue de manière à ressembler à celle d’un être humain, en évitant les signes révélateurs sans tête et en émulant des environnements réels (jusqu’à l’appareil, le système d’exploitation et la version du navigateur).
- Larésolution du CAPTCHA est intégrée, aucun service externe n’est requis, aucune session échouée n’est suspendue en raison de problèmes visuels.
- Lapersistance de la session est cohérente. Les onglets, les cookies et le stockage local sont préservés, ce qui est essentiel pour des tâches telles que le scraping authentifié ou les flux de travail par étapes.
- Lecontrôle des références et des en-têtes vous permet de simuler des visites provenant de sources connues ou fiables, ce qui est utile dans les situations où les en-têtes HTTP affectent la diffusion des pages.
Tout cela est intégré dans un environnement standardisé, basé sur le cloud, ce qui permet d’obtenir des performances constantes, quels que soient le lieu et le moment où la session est exécutée. Il est évolutif, accessible par API et étroitement intégré au pipeline de données plus large, de sorte que le résultat est immédiatement prêt pour l’IA, qu’il soit structuré ou brut, en temps réel ou par lots.
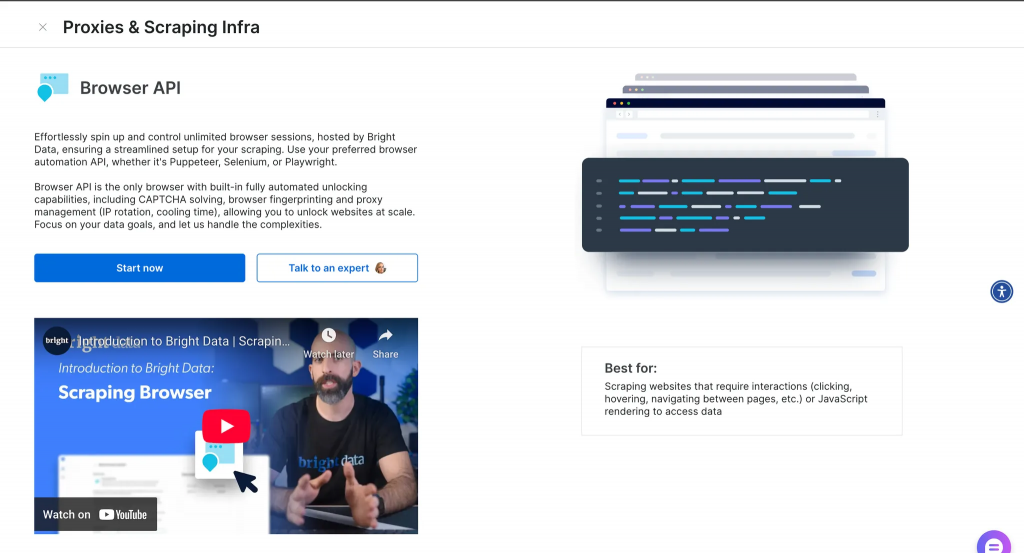
Vous trouverez ci-dessous un aperçu de ce que vous obtiendrez dans votre tableau de bord après avoir créé un compte.

Après avoir cliqué sur “En savoir plus”, vous obtenez des informations supplémentaires, comme indiqué ci-dessous.
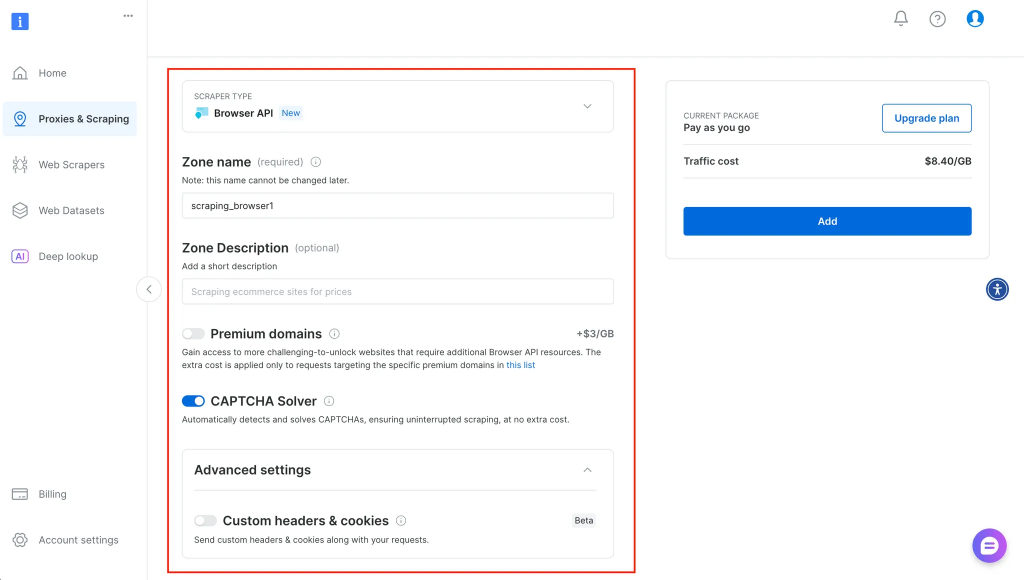
Après avoir cliqué sur démarrer, vous êtes redirigé vers un endroit où vous pouvez entrer plus d’informations sur votre service et le configurer en conséquence, comme indiqué ci-dessous :
Choisir le bon outil : Quand chaque outil a du sens
Chaque outil a sa place et le fait de savoir quand utiliser l’un plutôt que l’autre peut faire gagner du temps et éviter des frustrations.
Utilisez le navigateur de l’agent si :
- Vous devez pouvoir gérer des mécanismes anti-bots avancés sans avoir à créer des couches furtives personnalisées.
- Vos flux de travail impliquent des tâches en plusieurs étapes qui nécessitent la persistance de la session (par exemple, connexions, soumissions de formulaires).
- Vous souhaitez lancer et mettre à l’échelle des centaines ou des milliers de sessions de navigation à travers différentes géolocalisations.
- Vous préférez vous concentrer sur le travail de l’agent et non sur la gestion de son infrastructure.
S’en tenir à Marionnettiste ou Dramaturge si :
- Votre tâche est de petite envergure, rapide et locale, comme un script qui extrait quelques titres ou automatise des tests dans l’IC.
- Vous souhaitez contrôler totalement l’environnement du navigateur et n’avez pas besoin d’un déblocage intégré.
- Vous travaillez dans un environnement hors ligne ou sécurisé où l’utilisation d’un navigateur à distance n’est pas possible.
Dans certains cas, une approche hybride est préférable. Par exemple, vous pouvez exécuter les scripts Playwright localement, mais utiliser les proxys de Bright Data pour gérer la rotation des IP et le ciblage géographique. Vous pouvez également utiliser le Web MCP pour les cibles à haut risque et des frameworks open-source pour le scraping à faible friction.
Limites et considérations
Aucun outil n’est parfait et chacun d’entre eux présente des inconvénients.
Le navigateur Agent étant basé sur le cloud, il n’est pas conçu pour une utilisation hors ligne ou pour des environnements où la localisation des données est essentielle. Pour les équipes travaillant dans des secteurs réglementés ou avec des réseaux restreints, il peut être préférable d’exécuter les navigateurs localement.
Puppeteer et Playwright, bien que flexibles, nécessitent une maintenance constante au fur et à mesure de l’évolution des sites web. Les nouvelles techniques de détection des robots ou les modifications de la mise en page brisent souvent les scripts existants, en particulier lorsque les plugins de furtivité ne sont plus à jour. Et à mesure que l’échelle augmente, la maintenance de l’infrastructure du navigateur, la rotation des adresses IP et la prévention des blocages peuvent devenir des préoccupations permanentes.
Il faut également tenir compte du fait que l’Agent Browser est conçu pour les sites web publics et les tâches d’automatisation conformes à l’éthique du scraping. Il n’est pas conçu pour contourner les murs de connexion sans autorisation ou pour récupérer du contenu derrière des murs payants.
Conclusion et prochaines étapes
Le choix entre Agent Browser, Puppeteer et Playwright dépend des exigences de votre flux de travail. Si vous avez besoin de discrétion, d’échelle et de simplicité, Agent Browser offre l’automatisation sans les inconvénients. Si vous souhaitez construire quelque chose de rapide et de local avec un contrôle total, Puppeteer et Playwright sont des options solides. Dans les deux cas, comprendre leurs différences, en particulier en ce qui concerne la gestion des sessions, l’empreinte digitale et l’infrastructure, peut vous aider à éviter les pertes de temps et les ruptures de flux.
Vous pouvez explorer Agent Browser ou le connecter à votre pile d’automatisation existante en utilisant Playwright, Puppeteer, ou même MCP. Pour en savoir plus, consultez notre guide sur le web scraping avec ChatGPT ou sur la création d’agents avec MCP.





