

Le scraping web est une méthode programmatique de collecte de données à partir de sites web. Il existe d’innombrables cas d’utilisation du scraping web, notamment les études de marché, la Surveillance des prix, l’analyse de données et la génération de prospects.
Dans ce tutoriel, vous découvrirez un cas d’utilisation pratique axé sur une difficulté courante rencontrée par les parents : la collecte et l’organisation des informations envoyées par l’école. Ici, vous vous concentrerez sur les devoirs et les informations relatives aux repas scolaires.
Voici le schéma d’architecture approximatif du projet final :
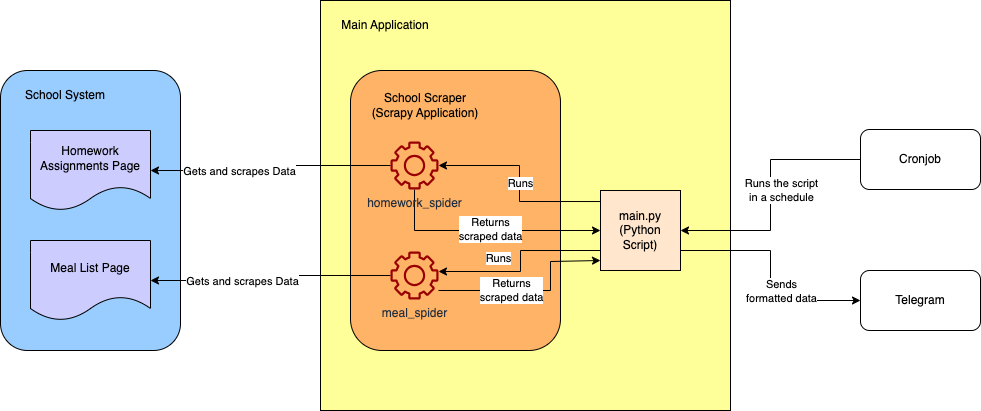
Prérequis
Pour suivre ce tutoriel, vous devez disposer des éléments suivants :
- Python 3.10+
- environnement virtuel activé
- Scrapy CLI 2.11.1
- Visual Studio Code
Pour des raisons de confidentialité, vous utiliserez ce site web fictif consacré au système scolaire : https://systemcraftsman.github.io/scrapy-demo/website/.
Créer le projet
Dans votre terminal, créez le répertoire de base de votre projet (vous pouvez le placer où vous le souhaitez) :
mkdir school-scraper
Accédez au dossier que vous venez de créer et créez un nouveau projet Scrapy en exécutant la commande suivante :
cd Scraper &
scrapy startproject school_scraper
La structure du projet devrait ressembler à ceci :
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
La commande précédente crée deux niveaux de répertoires school_scraper. Dans le répertoire interne, vous trouverez un ensemble de fichiers générés automatiquement : middlewares.py, où vous pouvez définir les middlewares Scrapy ; pipelines.py, où vous pouvez définir des pipelines personnalisés pour modifier vos données ; et settings.py, où vous pouvez définir les paramètres généraux de votre application de scraping.
Plus important encore, il y a un dossier spiders où se trouvent vos spiders. Les spiders sont des classes Python qui peuvent être utilisées pour scraper un site particulier d’une manière particulière. Ils adhèrent au principe de séparation des préoccupations au sein du système de scraping, ce qui permet la création d’un spider dédié pour chaque tâche de scraping.
Comme vous n’avez pas encore généré de spider, ce dossier est vide, mais dans l’étape suivante, vous allez générer votre premier spider.
Créer le spider Homework
Pour extraire les données relatives aux devoirs d’un système scolaire, vous devez créer un spider qui se connecte d’abord au système, puis navigue vers la page des devoirs pour extraire les données :
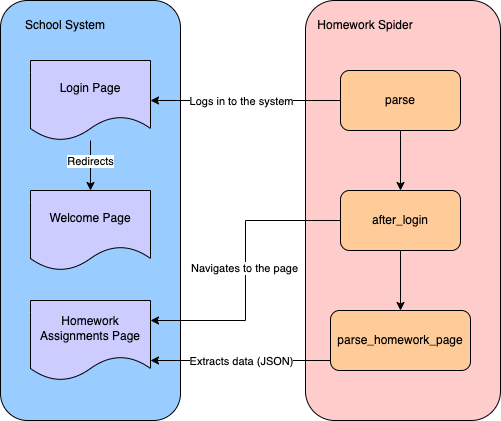
Vous utiliserez l’interface CLI de Scrapy pour créer un spider destiné au Scraping web. Accédez au répertoire school-scraper/school_scraper de votre projet et exécutez la commande suivante pour créer un spider nommé HomeworkSpider dans le dossier spiders:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html
REMARQUE : n’oubliez pas d’exécuter toutes les commandes liées à Python ou Scrapy dans votre environnement virtuel activé.
La commande scrapy genspider génère le spider. Le paramètre suivant est le nom du spider (c’est-à-dire homework_spider), et le dernier paramètre définit l’URL de départ du spider. De cette façon, systemcraftsman.github.io est reconnu comme un domaine autorisé par Scrapy.
Votre résultat devrait ressembler à ceci :
Création du spider « homework_spider » à l'aide du modèle « basic » dans le module :
school_scraper.spiders.homework_spider
Un fichier appelé homework_spider.py doit être créé dans le répertoire school_scraper/spiders et devrait ressembler à ceci :
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Renommez le nom de la classe en HomeworkSpider pour supprimer le mot Spider redondant dans le nom de la classe. La fonction parse est la fonction initiale qui lance le scraping. Dans ce cas, il s’agit de se connecter au système.
REMARQUE : le formulaire de connexion sur
https://systemcraftsman.github.io/scrapy-demo/index.htmlest un formulaire de connexion factice composé de quelques lignes de JavaScript. Comme la page est en HTML, elle n’accepte aucune requête POST. Une requête HTTP GET est donc utilisée à la place pour imiter la connexion.
Mettez à jour la fonction analyse comme suit :
...code omis...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
Ici, vous créez une requête de formulaire pour soumettre le formulaire de connexion dans la page index.html. Le formulaire soumis doit rediriger vers l’URL welcome_page_url définie et doit disposer d’une fonction de rappel pour poursuivre le processus de scraping. Vous ajouterez bientôt la fonction de rappel after_login.
Définissez welcome_page_url en l’ajoutant en haut de la classe où les autres variables sont définies :
...code omis...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...code omis...
Ajoutez ensuite la fonction after_login juste après la fonction parse dans la classe :
...code omis...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...code omis...
La fonction after_login vérifie que le statut de la réponse est 200, ce qui signifie qu’elle est réussie. Elle navigue ensuite vers la page des devoirs et appelle la fonction de rappel parse_homework_page, que vous définirez à l’étape suivante.
Définissez homework_page_url en l’ajoutant en haut de la classe où les autres variables sont définies :
...code omis...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...code omis...
Ajoutez la fonction parse_homework_page après la fonction after_login dans la classe :
...code omis...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...code omis...
La fonction parse_homework_page vérifie si le statut de la réponse est 200 (c’est-à-dire réussi) ; elle analyse ensuite les données des devoirs, qui sont fournies dans un tableau HTML.
La fonction vérifie le code HTTP 200, puis utilise XPath pour extraire chaque ligne de données. Après avoir extrait chaque ligne, la fonction itère sur les données et extrait les éléments spécifiques à l’aide de la fonction privée _get_item, que vous devez ajouter à votre classe Spider.
La fonction _get_item doit ressembler à ceci :
...code omis...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
La fonction _get_item obtient le contenu de chaque cellule à l’aide de XPath ainsi que des numéros de ligne et de colonne. Si une cellule contient plusieurs paragraphes, la fonction les parcourt et ajoute chaque paragraphe.
La fonction parse_homework_page nécessite également la définition d’une variable date_str, que vous devez définir comme 12.03.2024, car il s’agit de la date que vous avez dans votre site web statique.
REMARQUE : dans un scénario réel, vous devez définir la date de manière dynamique, car les données du site web sont dynamiques.
Définissez date_str en l’ajoutant en haut de la classe où les autres variables sont définies :
...code omis...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...code omis...
Le fichier final homework_spider.py se présente comme suit :
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response) :
if response.status == 200 :
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
Dans votre répertoire school-scraper/school_scraper, exécutez la commande suivante pour vérifier que les données relatives aux devoirs ont bien été extraites :
scrapy crawl homework_spider
Vous devriez voir le résultat récupéré parmi les autres journaux :
...résultat omis...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Extrait de <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html>
{'MATHS': "Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.n", 'ENGLISH': 'Lisez l'histoire « Manny and His Monster Manners » aux pages 100 à 107 de votre journal de lecture et réalisez les activités des pages 108 et 109 en fonction de l'histoire.nnReading Log kitabınızın 100-107 sayfalarındaki « Manny and His Monster Manners » dans votre carnet de lecture et effectuez les activités des pages 108 et 109 en fonction de l'histoire.n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO : Fermeture du spider (terminé)
...sortie omise...
Félicitations ! Vous avez implémenté votre premier spider. Passons au suivant !
Créer le spider de la liste des repas
Pour créer un spider qui explore la page de la liste des repas, exécutez la commande suivante dans votre répertoire school-scraper/school_scraper:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html
La classe spider générée devrait ressembler à ceci :
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Le processus de création du spider meal est très similaire à celui du spider homework. La seule différence réside dans la page HTML à scraper.
Pour gagner du temps, remplacez tout le contenu de meal_spider.py par ce qui suit :
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
meal_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
date_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
key = ""
try:
for row in rows[1:]:
if self._get_item(row, week_no) in data.keys():
key = self._get_item(row, week_no)
else:
data[key] = self._get_item(row, week_no, "n")
finally:
return data
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str
Notez que les fonctions parse et after_login sont presque identiques. La seule différence réside dans le nom de la fonction de rappel parse_meal_page, qui analyse le code HTML de la page des repas à l’aide d’une logique XPath différente. La fonction bénéficie également de l’aide d’une fonction privée appelée _get_item, qui fonctionne de manière similaire à celle créée pour les devoirs.
La manière dont le tableau est utilisé dans les pages devoirs et liste des repas diffère, de sorte que l’analyse et le traitement des données diffèrent également.
Pour vérifier le meal_spider, exécutez la commande suivante dans votre répertoire school-scraper/school_scraper:
scrapy crawl meal_spider
Votre résultat devrait ressembler à ceci :
...résultat omis...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG : extrait de <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRANnKIRMIZILAHANA SALATAnROKALI GÖBEK SALATAn', 'FRUIT TIME': 'FINDIK& KURU ÜZÜMn'}
2024-03-20 02:44:42 [scrapy.core.engine] INFO: Fermeture du spider (terminé)
...sortie omise...
REMARQUE : les données provenant d’un site Web original, aucune n’a été traduite afin de conserver leur format d’origine.
Mise en forme des données
Les scrapers que vous avez créés pour les devoirs et la page des listes de repas sont prêts à extraire les données au format JSON. Cependant, vous souhaiterez peut-être formater les données en déclenchant les spiders par programmation.
Dans les applications Python, le fichier main.py sert généralement de point d’entrée où vous initialisez votre application en invoquant ses composants clés. Cependant, dans ce projet Scrapy, vous n’avez pas créé de point d’entrée car la CLI Scrapy fournit un framework pré-construit pour implémenter les spiders, et vous pouvez exécuter les spiders via la même CLI.
Pour formater les données dans ce scénario, vous allez créer un programme Python de ligne de commande basique qui prend des arguments et effectue le scraping en conséquence.
Créez un fichier appelé main.py dans le répertoire racine de votre projet Scraper avec le contenu suivant :
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework" :
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal" :
process.crawl(MealSpider)
process.start()
print(_prepare_message("MEAL LIST", results[0]))
if __name__ == "__main__" :
main()
Le fichier main.py contient une fonction principale et constitue le point d’entrée de votre application. Lorsque vous exécutez main.py, la méthode principale est invoquée. La méthode principale prend un argument de type tableau appelé args, que vous pouvez utiliser pour envoyer des arguments au programme.
Le fichier main.py commence par vérifier la valeur de args et configure les paramètres du crawler Scrapy en définissant un pipeline appelé ResultsPipeline. Comme vous pouvez le voir, le pipeline ResultsPipeline est défini dans ce fichier, mais vous définissez les pipelines sous le package pipelines.
ResultsPipeline récupère simplement les résultats et les ajoute à un tableau appelé results. Cela signifie que le tableau results peut être utilisé comme entrée pour la fonction privée _prepare_message, qui sert à préparer le message formaté. Cela se fait par spider dans la fonction principale, et la distinction devient possible grâce au deuxième argument du tableau args, qui représente le type de spider. Si le type de spider est homework, le processus du crawler appelle HomeworkSpider et le lance. Si le type de spider est meal, le processus du crawler appelle MealSpider et le lance.
Lorsqu’un spider démarre, le ResultsPipeline injecté ajoute les données dans le tableau results, et la fonction principale peut les utiliser pour chaque spider en appelant _prepare_message, ce qui aide à formater la sortie des données.
Dans le répertoire principal de votre projet, exécutez le fichier main.py nouvellement implémenté à l’aide de la commande suivante pour récupérer les devoirs :
python main.py homework
Votre sortie devrait ressembler à ceci :
...sortie omise...
====DEVOIRS====
----------------
===MATHÉMATIQUES===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===ANGLAIS===
Lisez l'histoire « Manny and His Monster Manners » aux pages 100 à 107 de votre journal de lecture et réalisez les activités des pages 108 et 109 en rapport avec l'histoire.
Lisez l'histoire « Manny and His Monster Manners » aux pages 100 à 107 de votre carnet de lecture et réalisez les activités des pages 108 et 109 en fonction de l'histoire.
----------------
...résultat omis...
Pour obtenir la liste des repas du jour, exécutez la commande python main.py meal. Votre résultat ressemble à ceci :
...sortie omise...
====LISTE DES REPAS====
----------------
===PETIT-DÉJEUNER===
PANCAKE
KREM PEYNİR
SÜZME PEYNİR
KAKAOLU FINDIK KREMASI
SÜT
----------------
===DÉJEUNER===
TARHANA ÇORBA
EKŞİLİ KÖFTE
ERİŞTE
----------------
===SALADE/DESSERT===
AYRAN
KIRMIZILAHANA SALATA
ROKALI GÖBEK SALATA
----------------
===FRUITS===
FINDIK& KURU ÜZÜM
----------------
...résultat omis...
Conseils pour surmonter les obstacles courants liés au Scraping web
Félicitations ! Si vous êtes arrivé jusqu’ici, vous avez officiellement créé un Scraper Scrapy.
Bien qu’il soit facile de créer un Scraper web avec Scrapy, vous pouvez rencontrer certains obstacles lors de la mise en œuvre, tels que les CAPTCHA, les interdictions d’IP, la gestion des sessions ou des cookies, et les sites web dynamiques. Voyons quelques conseils pour gérer ces différents scénarios :
Sites web dynamiques
Les sites web dynamiques fournissent un contenu variable aux visiteurs en fonction de facteurs tels que la configuration du système, l’emplacement, l’âge et le sexe. Par exemple, deux personnes visitant le même site web dynamique peuvent voir un contenu différent, adapté à chacune d’elles.
Bien que Scrapy puisse extraire du contenu web dynamique, il n’est pas conçu pour cela. Pour extraire du contenu dynamique, vous devez programmer Scrapy pour qu’il s’exécute régulièrement, en enregistrant et en comparant les résultats afin de suivre les changements sur les pages web au fil du temps.
Dans certains cas, le contenu dynamique des pages web peut être traité comme du contenu statique, en particulier lorsque ces pages ne sont mises à jour qu’occasionnellement.
CAPTCHAs
En général, les CAPTCHA sont des images dynamiques comportant des caractères alphanumériques. Les visiteurs de la page doivent saisir les valeurs correspondantes à l’image CAPTCHA pour passer le processus de validation.
Les CAPTCHA sont utilisés sur les pages web pour s’assurer que le visiteur de la page est un humain (par opposition à un spider ou un bot) et, souvent, pour empêcher le Scraping web.
Le système scolaire fictif avec lequel vous avez travaillé ici n’utilise pas de système CAPTCHA, mais si vous en rencontrez un, vous pouvez créer un middleware Scrapy qui télécharge le CAPTCHA et le convertit en texte à l’aide d’une bibliothèque OCR.
Manipulation des sessions et des cookies
Lorsque vous ouvrez une page web, vous entrez dans une session au sein du système de cette page. Cette session conserve vos informations de connexion et d’autres données pertinentes afin de vous reconnaître dans l’ensemble du système.
De la même manière, vous pouvez suivre les informations relatives à un visiteur d’une page web à l’aide d’un cookie. Cependant, contrairement aux données de session, les cookies sont stockés sur l’ordinateur du visiteur plutôt que sur le serveur du site web, et les utilisateurs peuvent les supprimer s’ils le souhaitent. Par conséquent, vous ne pouvez pas utiliser les cookies pour conserver une session, mais vous pouvez les utiliser pour diverses tâches de soutien où la perte de données n’est pas critique.
Il peut arriver que vous ayez besoin de manipuler la session d’un utilisateur ou de mettre à jour ses cookies. Scrapy peut gérer ces deux situations, soit grâce à ses fonctionnalités intégrées, soit grâce à des bibliothèques tierces compatibles.
Interdiction d’adresse IP
L’interdiction d’adresse IP, également appelée blocage d’adresse IP, est une technique de sécurité par laquelle un site web bloque certaines adresses IP entrantes. Cette technique est généralement utilisée pour empêcher les robots ou les araignées d’accéder à des informations sensibles, garantissant ainsi que seuls les utilisateurs humains peuvent accéder aux données et les traiter. Parallèlement aux CAPTCHA, les entreprises utilisent l’interdiction d’adresse IP pour dissuader les activités de Scraping web.
Dans ce scénario, le système scolaire n’utilise pas de mécanisme de blocage d’IP. Cependant, s’il en avait mis un en place, vous devriez adopter des stratégies telles que l’utilisation d’une IP dynamique ou le masquage de votre adresse IP derrière un Proxy pour continuer à scraper leur site web.
Conclusion
Dans cet article, vous avez appris à créer des robots d’indexation pour vous connecter et effectuer l’analyse de tableaux à l’aide de XPath dans Scrapy. De plus, vous avez appris à déclencher les robots d’indexation par programmation pour un meilleur contrôle des données.
Vous pouvez accéder au code complet de ce tutoriel dans ce référentiel GitHub.
Pour ceux qui cherchent à étendre les capacités de Scrapy et à surmonter les obstacles au scraping, Bright Data propose des solutions adaptées aux données web publiques. L’intégration de Bright Data à Scrapy améliore les capacités de scraping, les services de Proxy permettent d’éviter les interdictions d’IP et Web Unlocker simplifie la gestion des CAPTCHA et du contenu dynamique, rendant la collecte de données avec Scrapy plus efficace.
Inscrivez-vous dès maintenant et discutez avec l’un de nos experts en données de nos solutions de scraping.




