

Dans ce tutoriel, vous allez apprendre :
- Pourquoi il peut être utile d’extraire les images d’un site
- Comment récupérer les images d’un site web avec Python en utilisant Selenium
C’est parti !
Pourquoi peut-il être utile d’extraire les images d’un site web ?
Le web scraping ne se limite pas à l’extraction de données textuelles. Il peut au contraire cibler n’importe quel type de données, y compris des fichiers multimédias tels que des images. En particulier, l’extraction des images d’un site web est utile dans plusieurs cas d’utilisation. Il s’agit notamment de :
- Récupérer des images pour former des modèles d’apprentissage automatique et d’intelligence artificielle : entraîner un modèle à l’aide d’images téléchargées en ligne pour améliorer sa précision et son efficacité.
- Étudier la façon dont vos concurrents abordent la communication visuelle : comprendre les tendances et les stratégies en donnant à votre équipe marketing l’accès aux images que vos concurrents utilisent pour communiquer des messages clés à leur public.
- Récupérer automatiquement des images visuellement attrayantes auprès de fournisseurs en ligne : utiliser des images de haute qualité pour obtenir un engagement élevé sur votre site et vos plateformes de réseaux sociaux, en attirant et en retenant l’attention du public.
Scraper des images en python : guide étape par étape
Pour extraire les images d’une page web, vous devez effectuer l’opération suivante :
- Vous connecter au site cible
- Sélectionner tous les nœuds HTML d’image d’intérêt sur la page
- Extraire les URL des images pour chacun de ces nœuds
- Télécharger les fichiers images associés à ces URL
Unsplash, l’un des fournisseurs d’images les plus populaires sur internet, est un bon site cible pour cette tâche. Voici à quoi ressemble le tableau de bord pour la recherche d’images gratuites avec le terme « wallpaper » (fond d’écran) :
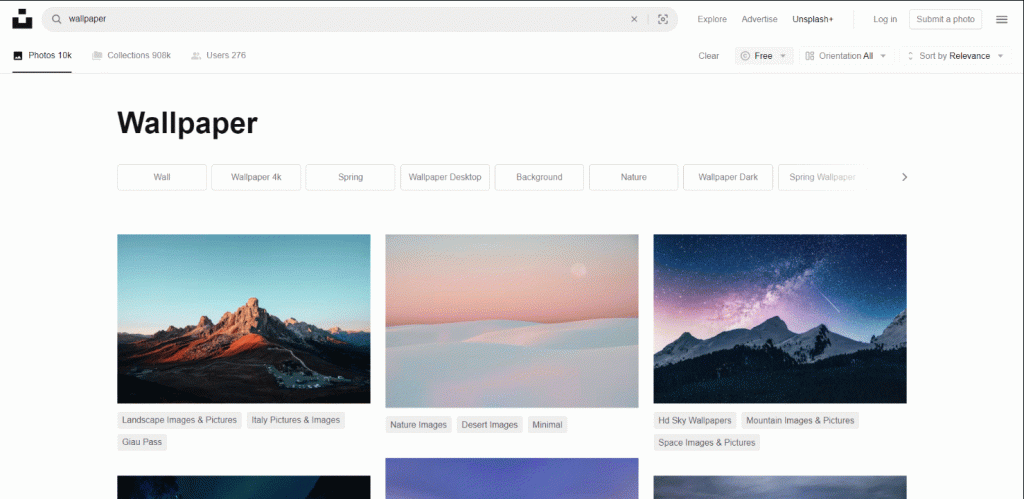
Comme vous pouvez le voir, la page charge de nouvelles images au fur et à mesure que l’utilisateur fait défiler l’écran vers le bas. En d’autres termes, il s’agit d’un site interactif qui nécessite un outil d’automatisation du navigateur pour le scraping.
L’URL de cette page est la suivante :
https://unsplash.com/s/photos/wallpaper?license=freeIl est temps de voir comment récupérer des images de ce site en Python !
Étape N° 1 : Démarrer
Pour suivre ce tutoriel, vérifiez que Python 3 est installé sur votre ordinateur. Sinon, téléchargez le programme d’installation, double-cliquez dessus et suivez les instructions.
Initialisez votre projet Python de scraping d’images en utilisant les commandes ci-dessous :
mkdir image-scraper
cd image-scraper
python -m venv envCela crée le dossier « image-scraper » et ajoute un environnement virtuel Python à l’intérieur.
Ouvrez le dossier du projet dans l’IDE Python de votre choix. PyCharm Community Edition ou Visual Studio Code avec l’extension Python feront l’affaire.
Créez le fichier « scraper.py » dans le dossier du projet et initialisez-le comme suit :
print('Hello, World!')Pour l’instant, ce fichier est un simple script qui affiche « Hello, World! », mais il contiendra bientôt la logique de scraping d’images.
Vérifiez que le script fonctionne en appuyant sur le bouton « run » (exécuter) de votre IDE ou en exécutant la commande ci-dessous :
python scraper.pyLe message suivant devrait apparaître dans votre terminal :
Hello, World!Parfait ! Votre projet Python est maintenant créé. Implémentez la logique nécessaire pour récupérer les images d’un site web en suivant les étapes suivantes.
Étape n° 2 : Installer Selenium
Selenium est une excellente bibliothèque pour le scraping d’images, car elle peut gérer des sites avec du contenu statique et dynamique. En tant qu’outil d’automatisation du navigateur, elle peut assurer le rendu des pages même si elles nécessitent l’exécution de JavaScript. Pour en savoir plus, consultez notre guide sur le web scraping avec Selenium.
Comparé à un analyseur HTML tel que BeautifoulSoup, Selenium peut cibler plus de sites et couvrir plus de cas d’utilisation. Par exemple, il fonctionne également avec des fournisseurs d’images qui s’appuient sur les interactions de l’utilisateur pour charger les nouvelles images. C’est exactement le cas avec Unsplash, le site cible de ce guide.
Avant d’installer Selenium, vous devez activer l’environnement virtuel Python. Sous Windows, vous pouvez le faire à l’aide de cette commande :
envScriptsactivateSous macOS et Linux, exécutez plutôt :
source env/bin/activateDans le terminal env, installez le package Selenium WebDriver avec la commande pip suivante :
pip install seleniumSoyez patient, car l’installation peut durer un certain temps.
Excellent ! Nous allons pouvoir commencer à scraper des images en Python.
Étape n° 3 : Connexion au site cible
Importez Selenium et les classes nécessaires pour contrôler une instance de Chrome en ajoutant le script suivant à scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import OptionsVous pouvez maintenant initialiser une instance Chrome WebDriver sans tête avec ce code :
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment while developing
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)Décommentez la ligne « --headless », si vous voulez que Selenium lance une fenêtre Chrome avec l’interface graphique. Cela vous permettra de suivre ce que le script fait sur la page en temps réel, ce qui est utile pour le débogage. En production, conservez l’option « --headless » activée pour économiser des ressources.
N’oubliez pas de fermer la fenêtre du navigateur en ajoutant cette ligne à la fin de votre script :
# close the browser and free up its resources
driver.quit() Certaines pages affichent les images différemment selon la taille de l’écran de l’utilisateur. Pour éviter les problèmes liés au contenu réactif, agrandissez la fenêtre de Chrome avec :
driver.maximize_window()Vous pouvez maintenant demander à Chrome de se connecter à la page cible via Selenium en utilisant la méthode get() :
url = "https://unsplash.com/s/photos/wallpaper?license=free"
driver.get(url)Réunissez tout cela, et vous obtiendrez :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up its resources
driver.quit()Lancez le script de scraping d’images en mode « avec tête ». Il affichera la page suivante pendant une fraction de section avant de fermer Chrome :
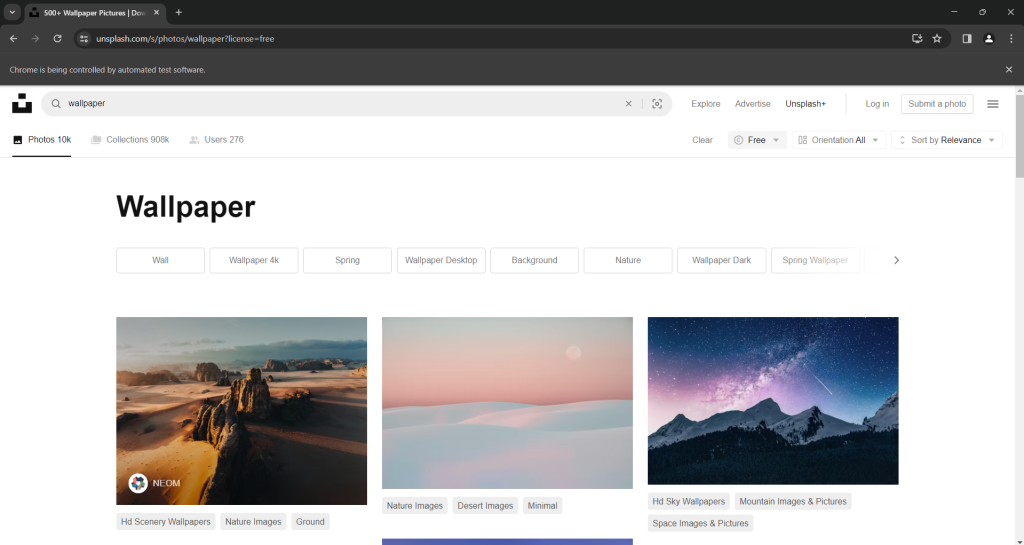
Le message « Chrome est contrôlé par un logiciel de test automatisé » signifie que Selenium fonctionne sur la fenêtre Chrome comme souhaité.
Formidable ! Analysons le code HTML de la page pour apprendre à en extraire des images.
Étape n° 4 : Inspecter le site cible
Avant de plonger dans la logique Python d’extraction d’images, vous devez inspecter le code source HTML de votre page cible. Ce n’est qu’ainsi que vous pourrez comprendre comment définir une logique de sélection de nœuds efficace et comment extraire les données souhaitées.
Consultez donc le site cible dans votre navigateur, faites un clic droit sur une image et sélectionnez l’option « Inspecter » pour ouvrir les DevTools :
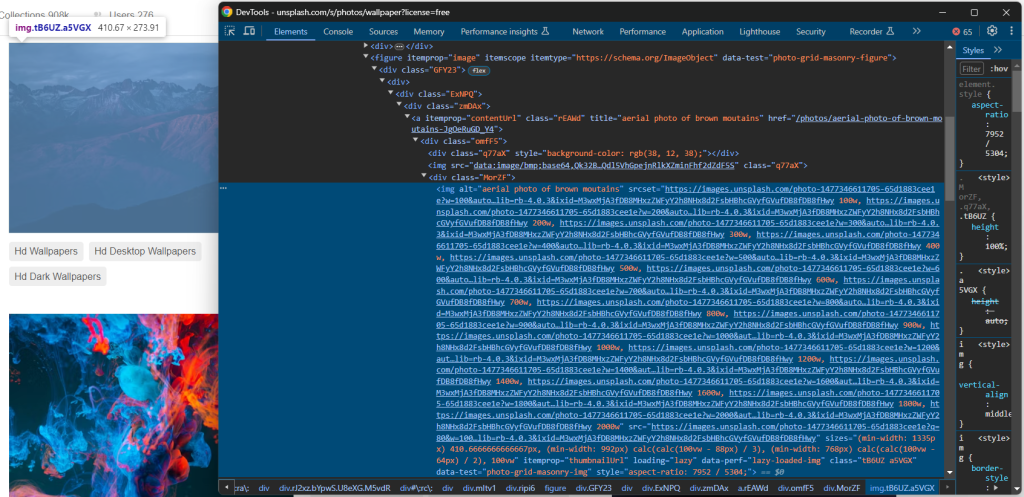
Ici, vous pouvez remarquer quelques faits intéressants.
Premièrement, l’image est contenue dans un élément HTML <img>. Cela signifie que le sélecteur CSS permettant de sélectionner les nœuds de l’image est :
[data-test="photo-grid-masonry-img"]Deuxièmement, les éléments Image possèdent à la fois l’attribut « src » traditionnel et l’attribut « srcset ». Si vous ne connaissez pas ce dernier attribut, sachez que « srcset » spécifie plusieurs images sources avec des conseils pour aider le navigateur à choisir la bonne en fonction des points de rupture réactifs.
En détail, la valeur d’un attribut « srcset » a le format suivant :
<image_source_1_url> <image_source_1_size>, <image_source_1_url> <image_source_2_size>, ...Où :
<image_source_1_url>,<image_source_2_url>, etc. sont les URL des images de différentes tailles.<image_source_1_size>,<image_source_2_size>, etc. sont les tailles de chaque source d’image. Les valeurs autorisées sont des largeurs de pixels (par exemple,200w) ou des rapports de pixels (par exemple,1,5x).
Ce scénario dans lequel une image possède les deux attributs est assez courant sur les sites réactifs modernes. Cibler directement l’URL de l’image dans « src » n’est pas la meilleure approche, car « srcset » peut contenir l’URL d’une image de meilleure qualité.
Dans le code HTML ci-dessus, vous pouvez également constater que toutes les URL d’images sont absolues. Il n’est donc pas nécessaire de leur concaténer l’URL de base du site.
Dans l’étape suivante, vous apprendrez comment extraire les bonnes images en Python à l’aide de Selenium.
Étape n° 5 : Récupérer toutes les URL d’images
Utilisez la méthode findElements() pour sélectionner tous les nœuds d’images HTML souhaités sur la page :
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]") Pour fonctionner, cette instruction nécessite l’importation suivante :
from selenium.webdriver.common.by import ByEnsuite, initialiser une liste qui contiendra les URL extraites des éléments de l’image :
image_urls = []Interroger les nœuds dans « image_html_nodes », collecter l’URL dans « src » ou l’URL de l’image la plus grande dans « srcset » (si présent), et l’ajouter à « image_urls » :
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continueNotez qu’Unsplash est un site assez dynamique et qu’au moment où vous exécutez cette boucle, certaines images peuvent ne plus se trouver sur la page. Pour vous prémunir contre cette erreur, saisissez l’exception « StaleElementReferenceException ».
Encore une fois, n’oubliez pas d’ajouter cette importation :
from selenium.common.exceptions import StaleElementReferenceExceptionVous pouvez maintenant imprimer les URL des images scrappées avec :
print(image_urls)Le fichier scraper.py actuel doit contenir :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# log in the terminal the scraped data
print(image_urls)
# close the browser and free up its resources
driver.quit()Exécutez le script pour récupérer les images, et vous obtiendrez un résultat similaire à celui-ci :
[
'https://images.unsplash.com/photo-1707343843598-39755549ac9a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDF8MHxzZWFyY2h8MXx8d2FsbHBhcGVyfGVufDB8fDB8fHwy',
# omitted for brevity...
'https://images.unsplash.com/photo-1507090960745-b32f65d3113a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8MjB8fHdhbGxwYXBlcnxlbnwwfHwwfHx8Mg%3D%3D'
]Nous y voilà ! Le tableau ci-dessus contient les URL des images à récupérer. Il ne reste plus qu’à voir comment télécharger des images en Python.
Étape n° 6 : Télécharger les images
La façon la plus simple de télécharger une image en Python est d’utiliser la méthode « urlretrieve() » du paquet « url.request » de la bibliothèque « standard ». Cette fonction copie un objet réseau spécifié par une URL dans un fichier local.
Importez « url.request » en ajoutant la ligne suivante au début de votre fichier scraper.py :
import urllib.requestDans le dossier du projet, créez un répertoire « images » :
mkdir imagesC’est là que le script enregistrera les fichiers images.
Maintenant, il faut parcourir la liste contenant les URL des images scrappées. Pour chaque image, générez un nom de fichier incrémental et téléchargez l’image avec « urlretrieve () » :
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1Voici tout ce dont vous avez besoin pour télécharger des images en Python. Les instructions « print()» ne sont pas obligatoires, mais elles sont utiles pour comprendre ce que fait le script.
Parfait ! Vous venez d’apprendre comment récupérer les images d’un site web en Python. Il est temps de voir le code complet du script Python de scraping d’images.
Étape n° 7 : Assembler le tout
Voici le code du script final scraper.py :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
import urllib.request
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# to keep track of the images saved to disk
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1
# close the browser and free up its resources
driver.quit()Génial ! Vous pouvez créé un script automatisé pour télécharger des images depuis un site en Python avec moins de 100 lignes de code.
Exécutez-le avec la commande suivante :
python scraper.pyLe script Python de récupération d’images enregistrera la chaîne suivante :
downloading image no. 1 ...
images downloaded successfully to "./images/1.jpg"
# omitted for brevity...
downloading image no. 20 ...
images downloaded successfully to "./images/20.jpg"Explorez le dossier « /images ». Vous y trouverez toutes les images téléchargées automatiquement par le script :
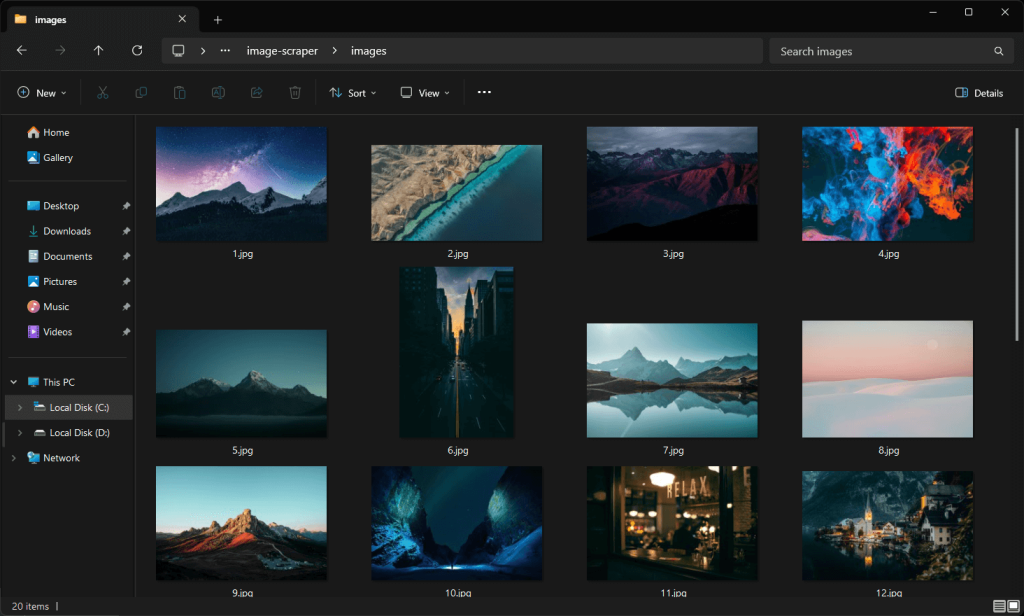
Notez que ces images sont différentes de celles de la capture d’écran de la page Unsplash vue précédemment, car le site reçoit en permanence du contenu.
Et voilà ! Votre mission est terminée.
Étape n° 8 : Étapes suivantes
Bien que nous ayons atteint notre objectif, nous pouvons encore améliorer notre script Python. Voici le plus important :
- Exportez les URL des images au format CSV ou les stocker dans une base de données : de cette manière, vous pourrez les télécharger ou les utiliser à l’avenir.
- Évitez de télécharger des images qui se trouvent déjà dans le dossier «
/images» : cette amélioration permet d’économiser les ressources du réseau en ignorant les images qui ont déjà été téléchargées. - Récupérez également les informations sur les métadonnées : la récupération des balises et des informations sur l’auteur peut être utile pour obtenir des informations complètes sur les images téléchargées. Découvrez comment dans notre guide sur le web scraping en Python.
- Récupérez plus d’images : simulez l’interaction du défilement infini, chargez plus d’images et téléchargez-les toutes.
Conclusion
Dans ce guide, vous avez appris pourquoi il est utile de récupérer des images sur un site web et comment le faire en Python. En particulier, vous avez vu un tutoriel étape par étape sur la façon de construire un script Python pour scraper les images permettant de télécharger automatiquement les images d’un site web. Comme démontré ici, ce n’est pas complexe et quelques lignes de code suffisent.
Cependant, n’oubliez pas que la majorité des sites web utilisent des solutions anti-bots. Selenium est un outil formidable, mais il ne peut rien contre ces technologies aussi avancées. Celles-ci peuvent détecter votre script automatisé et l’empêcher d’accéder aux images du site.
Pour éviter cela, vous avez besoin d’un outil qui peut assurer le rendu JavaScript et qui est également capable de gérer les empreintes digitales, les CAPTCHA et l’anti-scraping à votre place. C’est exactement ce que propose le navigateur Scraping Browser de Bright Data !
Discutez de nos solutions de scraping avec l’un de nos experts en données.
FAQ
Est-il légal de scraper les images d’un site web ?
L’extraction d’images d’un site web n’est pas illégale en soi. Toutefois, il est essentiel de ne télécharger que des images publiques, de respecter le fichier robots.txt pour le scraping et de se conformer aux conditions générales du site. Beaucoup de gens pensent que le web scraping est illégal, mais c’est un mythe. Pour en savoir plus, consultez notre article sur les mythes concernant le web scraping.
Quelles sont les meilleures bibliothèques pour télécharger des images avec Python ?
Pour les sites à contenu statique, un client HTTP tel que requests et un analyseur HTML tel que beautifulsoup4 suffisent. Pour les sites à contenu dynamique ou les pages hautement interactives, vous aurez besoin d’un outil d’automatisation de navigateur comme Selenium ou Playwright. Consultez la liste des meilleurs outils de navigation sans tête pour le web scraping.
Comment résoudre l’erreur « HTTP 403 : Forbidden » dans urllib.request ?
Vous recevez l’erreur HTTP 403 parce que le site cible reconnaît votre requête envoyée avec urllib.request comme provenant d’un script automatisé. Un moyen efficace d’éviter ce problème est de définir l’en-tête « User-Agent » avec une valeur réelle. Lorsque vous utilisez la méthode « urlretrieve() », voici comment vous pouvez y parvenir :
opener = urllib.request.build_opener()
user_agent_string = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
opener.addheaders = [("User-Agent", user_agent_header)]
urllib.request.install_opener(opener)
# urllib.request.urlretrieve(...)



