

La mise en place d’une solution fiable d’extraction de données web commence par une infrastructure adéquate. Dans ce guide, vous allez créer une application d’une seule page qui accepte n’importe quelle URL de page web publique et une invite en langage naturel. Elle récupère, analyse et renvoie ensuite des données JSON propres et structurées, automatisant ainsi entièrement le processus d’extraction.
La pile combine l’infrastructure de scraping anti-bot de Bright Data, le backend sécurisé de Supabase et les outils de développement rapide de Lovable dans un flux de travail transparent.
Ce que vous allez construire
Voici le pipeline de données complet que vous allez construire – de l’entrée utilisateur à la sortie JSON structurée et au stockage :
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
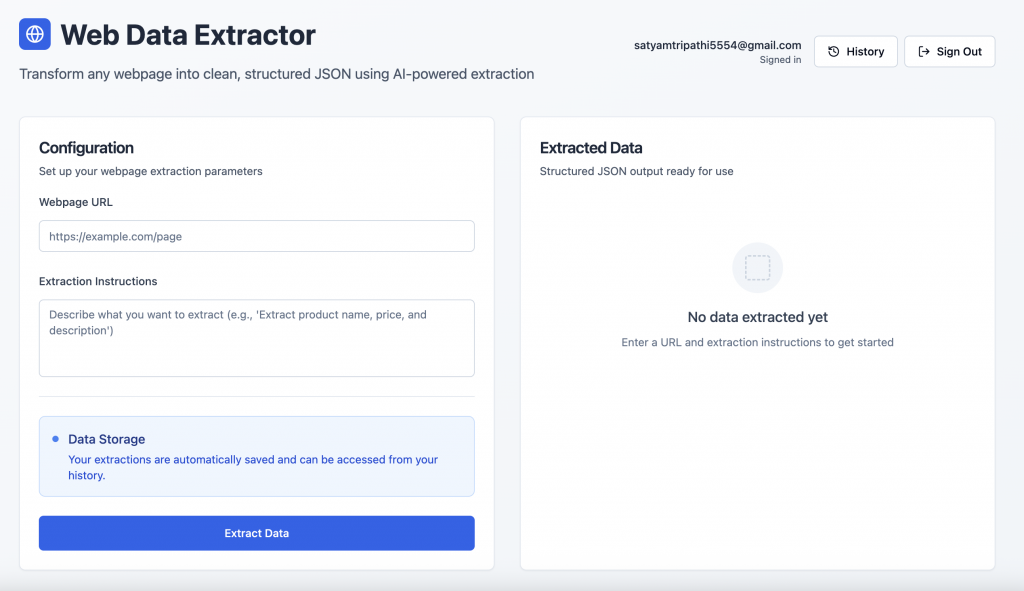
User ExportVoici un aperçu de l’application finie :
Authentification des utilisateurs : Les utilisateurs peuvent s’inscrire ou se connecter en toute sécurité à l’aide de l’écran d’authentification fourni par Supabase.

Interface d’extraction de données : Après s’être connecté, l’utilisateur peut saisir l’URL d’une page web et une invite en langage naturel pour extraire des données structurées.
Aperçu de la pile technologique
Voici la répartition de notre pile et l’avantage stratégique que chaque composant apporte.
- Bright Data : Le scraping Web se heurte souvent à des blocages, des CAPTCHA et une détection avancée des robots. Bright Data est conçu pour relever ces défis. Il offre
- Rotation automatique du proxy
- Résolution des CAPTCHA et protection contre les robots
- Une infrastructure mondiale pour un accès cohérent
- Rendu JavaScript pour les contenus dynamiques
- Gestion automatisée des limites de débit
Pour ce guide, nous utiliserons le Web Unlocker de Bright Data, un outil spécialement conçu pour récupérer de manière fiable le code HTML complet des pages les plus protégées.
- Supabase:Supabase fournit une base de backend sécurisée pour les applications modernes :
- Gestion intégrée de l’authentification et de la session
- Une base de données PostgreSQL avec support en temps réel
- Fonctions Edge pour une logique sans serveur
- Stockage sécurisé des clés et contrôle d’accès
- Lovable: Lovable rationalise le développement grâce à des outils alimentés par l’IA et à l’intégration native de Supabase. Il offre :
- Génération de code pilotée par l’IA
- Echafaudage front-end/back-end transparent
- React + Tailwind UI out of the box
- Prototypage rapide pour des applications prêtes à la production
- Google Gemini AI:Gemini transforme du HTML brut en JSON structuré à l’aide d’invites en langage naturel. Il prend en charge :
- Compréhension et analyse précise du contenu
- Support d’entrée large pour un contexte pleine page
- Extraction de données évolutive et rentable
Conditions préalables et configuration
Avant de commencer le développement, assurez-vous d’avoir accès aux éléments suivants :
- Compte Bright Data
- S’inscrire sur brightdata.com
- Créer une zone Web Unlocker
- Obtenez votre clé API à partir des paramètres du compte
- Compte Google AI Studio
- Visitez Google AI Studio
- Créer une nouvelle clé API
- Projet Supabase
- Inscrivez-vous sur supabase.com
- Créer une nouvelle organisation, puis un nouveau projet
- Dans le tableau de bord de votre projet, allez dans Edge Functions → Secrets → Add New Secret. Ajoutez des secrets tels que
BRIGHT_DATA_API_KEYetGEMINI_API_KEYavec leurs valeurs respectives.
- Compte adorable
- S’inscrire sur lovable.dev
- Allez dans votre profil → Paramètres → Intégrations
- Sous Supabase, cliquez sur Connecter Supabase
- Autoriser l’accès à l’API et le lier à l’organisation Supabase que vous venez de créer
Construire l’application étape par étape avec les invites de Lovable
Vous trouverez ci-dessous un flux structuré, basé sur des invites, pour développer votre application d’extraction de données web, du front-end au back-end, à la base de données et à l’analyse intelligente.
Étape 1 – Configuration du frontend
Commencez par concevoir une interface utilisateur propre et intuitive.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingEtape #2 – connecter Supabase et ajouter l’authentification
Pour lier votre projet Supabase :
- Cliquez sur l’icône Supabase dans le coin supérieur droit de Lovable
- Sélectionnez Connect Supabase
- Choisissez l’organisation et le projet que vous avez créés précédemment
Lovable intégrera automatiquement votre projet Supabase. Une fois lié, utilisez l’invite ci-dessous pour activer l’authentification :
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable générera le schéma SQL et les déclencheurs requis – revoyez-les et approuvez-les pour finaliser votre flux d’authentification.
Étape 3 – définir le schéma de la base de données Supabase
Configurez les tables nécessaires pour enregistrer et stocker l’activité d’extraction :
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataÉtape 4 – Créer la fonction Supabase Edge
Cette fonction gère la logique de base du scraping, de la conversion et de l’extraction :
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Convertir du HTML brut en Markdown avant de l’envoyer à Gemini AI présente plusieurs avantages clés. Elle élimine le bruit HTML inutile, améliore les performances de l’IA en fournissant des données plus propres et plus structurées, et réduit l’utilisation de jetons, ce qui permet un traitement plus rapide et plus rentable.
Considération importante : Lovable est très doué pour créer des applications à partir du langage naturel, mais il ne sait pas toujours comment intégrer correctement des outils externes tels que Bright Data ou Gemini. Pour garantir une mise en œuvre précise, incluez un exemple de code de travail dans vos invites. Par exemple, la méthode fetchContentViaBrightData The dans l’invite ci-dessus démontre un cas d’utilisation simple du Web Unlocker de Bright Data.
Bright Data propose plusieurs API, notamment Web Unlocker, SERP API et Scraper API, chacune avec son point de terminaison, sa méthode d’authentification et ses paramètres. Lorsque vous configurez un produit ou une zone dans le tableau de bord de Bright Data, l’onglet Vue d’ensemble fournit des extraits de code spécifiques au langage (Node.js, Python, cURL) adaptés à votre configuration. Utilisez ces extraits tels quels ou adaptez-les à votre logique Edge Function.
Étape 5 – connecter le frontend à Edge Function
Une fois que votre fonction Edge est prête, intégrez-la dans votre application React :
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesÉtape n° 6 – ajouter l’historique de l’extraction
Fournir aux utilisateurs un moyen de revoir les demandes antérieures :
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutÉtape 7 – Polissage de l’interface utilisateur et améliorations finales
Affinez l’expérience grâce à des touches d’interface utilisateur utiles :
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageConclusion
Cette intégration réunit le meilleur de l’automatisation web moderne : des flux d’utilisateurs sécurisés avec Supabase, un scraping fiable via Bright Data, et une analyse flexible, alimentée par l’IA avec Gemini – le tout alimenté par le constructeur intuitif de Lovable, basé sur le chat, pour un flux de travail à code zéro et à haute productivité.
Prêt à créer votre propre système ? Commencez sur brightdata.com et découvrez les solutions de collecte de données de Bright Data pour un accès évolutif à n’importe quel site, sans aucun problème d’infrastructure.





