

Dans cet article, nous aborderons les thèmes suivants :
- Démystifier PhantomJS
- Les avantages et les inconvénients de l’utilisation de PhantomJS pour l’exploration de données
- Guide étape par étape pour la collecte de données avec PhantomJS
- Automatisation des données : des alternatives plus simples au scraping manuel
Démystifier PhantomJS
PhantomJS est un « navigateur web sans interface ». Cela signifie qu’il ne dispose pas d’interface utilisateur graphique (GUI), mais fonctionne uniquement à partir de scripts (ce qui le rend plus léger, plus rapide et donc plus efficace). Il peut être utilisé pour automatiser différentes tâches à l’aide de JavaScript (JS), telles que le test de code ou la collecte de données.
Pour les débutants, je recommanderais d’abord d’installer PhantomJS sur votre ordinateur à l’aide de « npm » dans votre CLI. Vous pouvez le faire en exécutant la commande suivante :
npm install phantomjs -g
La commande « phantomjs » est désormais disponible.
Avantages et inconvénients de l’utilisation de PhantomJS pour l’exploration de données
PhantomJS présente de nombreux avantages, notamment celui d’être « headless » (sans interface graphique), ce qui, comme je l’ai expliqué ci-dessus, le rend plus rapide car aucun graphique ne doit être chargé pour tester ou récupérer des informations.
PhantomJS peut être utilisé efficacement pour accomplir les tâches suivantes :
Capture d’écran
PhantomJS peut aider à automatiser le processus de capture et d’enregistrement de fichiers PNG, JPEG et même GIF. Cette fonction facilite considérablement l’assurance de l’interface utilisateur/expérience utilisateur frontale. Par exemple, vous pouvez exécuter la ligne de commande : Phantomjs amazon.js, afin de collecter des images des listes de produits concurrents ou de vous assurer que les listes de produits de votre entreprise s’affichent correctement.
Automatisation des pages
Il s’agit d’un avantage majeur de PhantomJS, car il permet aux développeurs de gagner beaucoup de temps. En exécutant des lignes de commande telles que Phantomjs userAgent.js, les développeurs peuvent écrire et vérifier le code JS en relation avec une page web spécifique. Le principal avantage en termes de gain de temps réside dans le fait que ce processus peut être automatisé et réalisé sans avoir à ouvrir un navigateur.
Tests
PhantomJS est avantageux pour tester des sites web, car il rationalise le processus, tout comme d’autres outils de Scraping web populaires tels que Selenium. La navigation sans interface graphique permet de détecter plus rapidement les problèmes, les codes d’erreur étant découverts et transmis au niveau de la ligne de commande.
Les développeurs intègrent également PhantomJS à différents types de systèmes d’intégration continue (CI) afin de tester le code avant sa mise en production. Cela aide les développeurs à corriger les codes défectueux en temps réel, garantissant ainsi un déroulement plus fluide des projets en production.
Surveillance du réseau / Collecte de données
PhantomJS peut également être utilisé pour surveiller le trafic/l’activité réseau. De nombreux développeurs le programment de manière à faciliter la collecte de données cibles, telles que :
- Les performances d’une page web spécifique
- Lorsque des lignes de code sont ajoutées/supprimées
- Les données sur les fluctuations du cours des actions
- Les données relatives aux influenceurs/à l’engagement lors du scraping de sites tels qu’Instagram
Parmi les inconvénients liés à l’utilisation de PhantomJS, on peut citer :
- Il peut être utilisé par des personnes malveillantes pour mener des attaques automatisées (principalement parce qu’il n’utilise pas d’interface utilisateur)
- Il peut parfois s’avérer difficile à utiliser pour les tests de cycle complet/de bout en bout et les tests fonctionnels.
Guide étape par étape pour la collecte de données avec PhantomJS
PhantomJS est très populaire parmi les développeurs NodeJS, nous vous proposons donc un exemple d’utilisation dans un environnement NodeJS. L’exemple montre comment récupérer le contenu HTML à partir de l’URL.
Première étape : configurer package.json et installer les paquets npm
Créez un dossier de projet et un fichier « package.json » à l’intérieur.
{
"name": "phantomjs-example",
"version": "1.0.0",
"title": "PhantomJS Example",
"description": "PhantomJS Example",
"keywords": [
"phantom example"
],
"main": "./index.js",
"scripts": {
"inst": "rm -rf node_modules && rm package-lock.json && npm install",
"dev": "nodemon index.js"
},
"dependencies": {
"phantom": "^6.3.0"
}
}
Exécutez ensuite cette commande dans votre terminal : $ npm install. Cela installera Phantom dans votre dossier de projet local « node_modules ».
Deuxième étape : créer un script Phantom JS
Créez un script JS et nommez-le « index.js »
const phantom = require('phantom');
const main = async () => {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
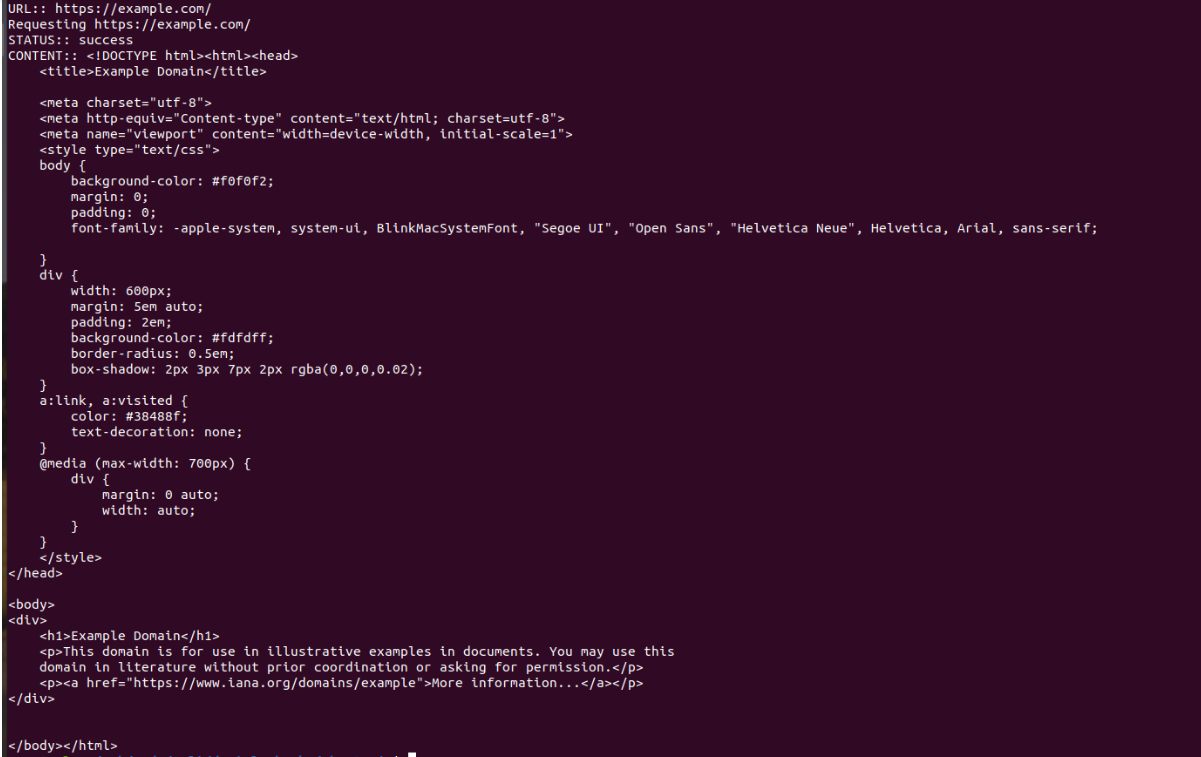
const url = 'https://example.com/';
console.log('URL::', url);
const status = await page.open(url);
console.log('STATUS::', status);
const content = await page.property('content');
console.log('CONTENT::', content);
await instance.exit();
};
main().catch(console.log);Troisième étape : exécuter le script JS
Pour démarrer le script, exécutez dans votre terminal : $ node index.js. Le résultat sera un contenu HTML.
Automatisation des données : des alternatives plus simples au scraping manuel
Lorsqu’il s’agit de scraper des données à grande échelle, certaines entreprises peuvent préférer utiliser des alternatives à PhantomJS.
Il s’agit notamment des solutions suivantes :
- Proxys : le Scrapingweb avec des proxies peut être avantageux dans la mesure où il permet aux utilisateurs de collecter des données à grande échelle, en soumettant un nombre infini de requêtes simultanées. Les proxys peuvent également aider à contourner les blocages des sites cibles, tels que les limitations de débit ou les blocages basés sur la géolocalisation. Dans ce cas, les entreprises peuvent exploiter des adresses IP/appareils mobiles et résidentielles spécifiques à un pays/une ville afin d’acheminer les demandes de données, ce qui leur permet de récupérer des données plus précises sur les utilisateurs (par exemple, les prix des concurrents, les campagnes publicitaires et les résultats de recherche Google).
- Jeux de données prêts à l’emploi : les jeux de données sont essentiellement des « paquets d’informations » qui ont déjà été collectés et sont prêts à être livrés à des algorithmes/équipes pour une utilisation immédiate. Ils comprennent généralement des informations provenant d’un site cible et sont enrichis à partir de sites pertinents sur le web (par exemple, des informations sur les produits d’une catégorie pertinente parmi plusieurs fournisseurs et une variété de marchés e-commerce). Les jeux de données peuvent également être actualisés périodiquement afin de garantir que tous les points de données sont à jour. Le principal avantage ici est qu’aucun temps ni aucune ressource ne sont investis dans la collecte de données, ce qui signifie que davantage de temps peut être consacré à l’analyse des données et à la création de valeur pour les clients.
- API Web Scraper entièrement automatisées : l’API Web Scraper est une solution de collecte de données facile à utiliser, sans code, sans infrastructure et personnalisable. Elle permet aux entreprises de collecter sans effort des données web structurées, sans avoir à se soucier du développement et de la maintenance de logiciels ou de matériel.
Discutez avec l’un des experts en données de Bright Data pour déterminer quels produits répondent le mieux à vos besoins en matière de Scraping web.




