

Pourquoi extraire les données détaillées des produits de Zalando ?
Zalando est l’une des plateformes de vente de vêtements en ligne les plus populaires en Europe. Avec plus de 50 millions d’utilisateurs actifs, c’est le premier site de commerce électronique de mode en Europe. Il propose une vaste gamme de produits, notamment des chaussures, des vêtements et des accessoires de marques bien établies et de créateurs émergents.
Les trois principales raisons de récupérer les données détaillées sur les produits de Zalando sont les suivantes :
- Étude de marché : obtenez des informations précieuses sur les tendances actuelles de la mode. Ces informations aident les entreprises à prendre des décisions éclairées, à rester compétitives et à adapter leurs offres pour répondre efficacement aux demandes des clients.
- Surveillance des prix : suivez les fluctuations des prix pour profiter des bonnes affaires et étudier le marché.
- Popularité des marques : concentrez-vous sur les produits populaires sur Zalando pour voir quelles marques sont actuellement les plus appréciées des clients et étudier leur stratégie.
En bref, le scraping de Zalando ouvre un monde de possibilités et est très avantageux tant pour les entreprises que pour les utilisateurs.
Bibliothèques et outils pour le scraping de Zalando
Pour comprendre lequel des nombreux outils de scraping disponibles est le mieux adapté au scraping de Zalando, ouvrez-le dans votre navigateur. Inspectez le DOM et comparez-le avec le code source brut. Vous remarquerez que la structure du DOM est légèrement différente du document HTML produit par le serveur. Cela signifie que le site s’appuie sur JavaScript pour le rendu. Pour scraper un site au contenu dynamique, vous avez besoin d’un outil capable d’exécuter JavaScript, tel que Selenium!
C’est maintenant au tour du langage de programmation. En matière de Scraping web, le plus populaire est Python. Sa syntaxe simple et son riche écosystème de bibliothèques le rendent parfait pour nos objectifs. Utilisons donc Python
Avant de commencer, consultez ces deux guides :
- Scraping web avec Python – Guide étape par étape
- Scraping de sites web dynamiques avec Python
Selenium affiche les sites dans un navigateur web contrôlable auquel vous pouvez demander d’effectuer des opérations spécifiques. En l’utilisant dans Python, vous serez en mesure de créer un Scraper Zalando efficace. Voyons comment !
Scraping des données produit de Zalando avec Selenium
Suivez ce tutoriel étape par étape et apprenez à créer un Scraper Zalando dans Python.
Étape 1 : Configurer un projet Python
Avant de vous lancer dans le Scraping web, assurez-vous de remplir les conditions préalables suivantes :
- Python 3+ installé sur votre machine: téléchargez le programme d’installation, double-cliquez dessus et suivez l’assistant d’installation.
- Un IDE Python de votre choix: PyCharm Community Edition ou Visual Studio Code avec l’extension Python feront l’affaire.
Vous disposez désormais de tout le nécessaire pour configurer un projet Python et écrire du code !
Lancez le terminal et exécutez les commandes ci-dessous pour :
- Créer un dossier zalando-Scraper.
- Y entrer.
- L’initialiser avec un environnement virtuel Python.
mkdir zalando-scraper
cd zalando-scraper
python -m venv envSous Linux ou macOS, exécutez la commande ci-dessous pour activer l’environnement :
./env/bin/activate SousWindows, exécutez :envScriptsactivate.ps1
Ensuite, créez un fichier scraper.py dans le dossier du projet et ajoutez-y la ligne suivante :
print("Hello, World!")Il s’agit du script Python le plus simple que vous puissiez écrire. Pour l’instant, il affiche uniquement « Hello, World ! », mais il contiendra bientôt la logique de scraping Zalando.
Lancez-le pour vérifier qu’il fonctionne avec :
python Scraper.pyIl devrait afficher ce message dans le terminal :
Bonjour, le monde !Maintenant que vous êtes sûr que le script fonctionne comme prévu, ouvrez le dossier du projet dans votre IDE Python.
Super ! Préparez-vous à écrire les premières lignes de votre Scraper.
Étape 2 : Installez les bibliothèques de scraping
Comme mentionné précédemment, Selenium est l’outil choisi pour créer un Scraper Zalando. Dans l’environnement virtuel Python activé, exécutez la commande ci-dessous pour l’ajouter aux dépendances du projet :
pip install seleniumLe processus d’installation peut prendre un certain temps, alors soyez patient.
Notez que ce tutoriel fait référence à Selenium 4.13.x, qui est doté d’une fonctionnalité de détection automatique des pilotes. Si vous disposez d’une version plus ancienne de Selenium sur votre machine, mettez-la à jour avec :
pip install selenium -USupprimez tout le contenu de scraper.py et initialisez un Scraper Selenium avec :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configurez une instance Chrome contrôlable
service = Service()
options = webdriver.ChromeOptions()
# vos options de navigateur...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximiser la fenêtre pour éviter le rendu réactif
driver.maximize_window()
# logique de scraping...
# fermer le navigateur et libérer ses ressources
driver.quit()Le script ci-dessus importe Selenium et l’utilise pour instancier un objet WebDriver. Cela vous permet de contrôler par programmation une instance du navigateur Chrome.
Par défaut, la fenêtre du navigateur s’ouvrira et vous pourrez surveiller les actions effectuées sur la page. Cela est utile lors du développement.
Pour ouvrir Chrome en mode sans interface graphique, configurez les options comme suit :
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')Notez que l’option user-agent supplémentaire est nécessaire, car Zalando bloque les requêtes provenant de navigateurs sans interface graphique qui ne comportent pas cet en-tête. Cette configuration est plus courante en production.
Super ! Il est temps de créer votre Scraper Python pour le Scraping web de Zalando.
Étape 3 : Ouvrez la page cible
Dans ce guide, vous verrez comment extraire les données détaillées d’un produit de la catégorie chaussures sur Zalando UK. Si vous ciblez un autre type de produit, vous devrez apporter des modifications mineures au script que vous êtes sur le point de créer. En effet, chaque produit peut avoir une structure de page spécifique avec des informations différentes.
Au moment où nous écrivons ces lignes, voici à quoi ressemble la page cible :
Plus précisément, voici l’URL de la page cible :
Connectez-vous à la page cible dans Selenium avec :
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get() indique au navigateur de visiter la page spécifiée par l’URL transmise en tant que paramètre.
Voici le script de scraping Zalando jusqu’à présent :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# configure l'instance Chrome
options = webdriver.ChromeOptions()
# vos options de navigateur...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximiser la fenêtre pour éviter le rendu réactif
driver.maximize_window()
# visiter la page cible dans le navigateur contrôlé
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# logique de scraping...
# fermer le navigateur et libérer ses ressources
driver.quit()Exécutez l’application. La fenêtre ci-dessous s’ouvrira pendant moins d’une seconde avant de se fermer :
La mention « Chrome est contrôlé par un logiciel automatisé » garantit que Selenium fonctionne comme prévu.
Étape 4 : familiarisez-vous avec la structure de la page
Pour écrire une logique de scraping efficace, vous devez passer un peu de temps à étudier la structure DOM de la page cible. Cela vous aidera à comprendre comment sélectionner des éléments HTML et en extraire des données.
Ouvrez votre navigateur en mode incognito et rendez-vous sur la page du produit Zalando choisi. Cliquez avec le bouton droit de la souris et sélectionnez l’option « Inspecter » pour ouvrir les DevTools de votre navigateur :
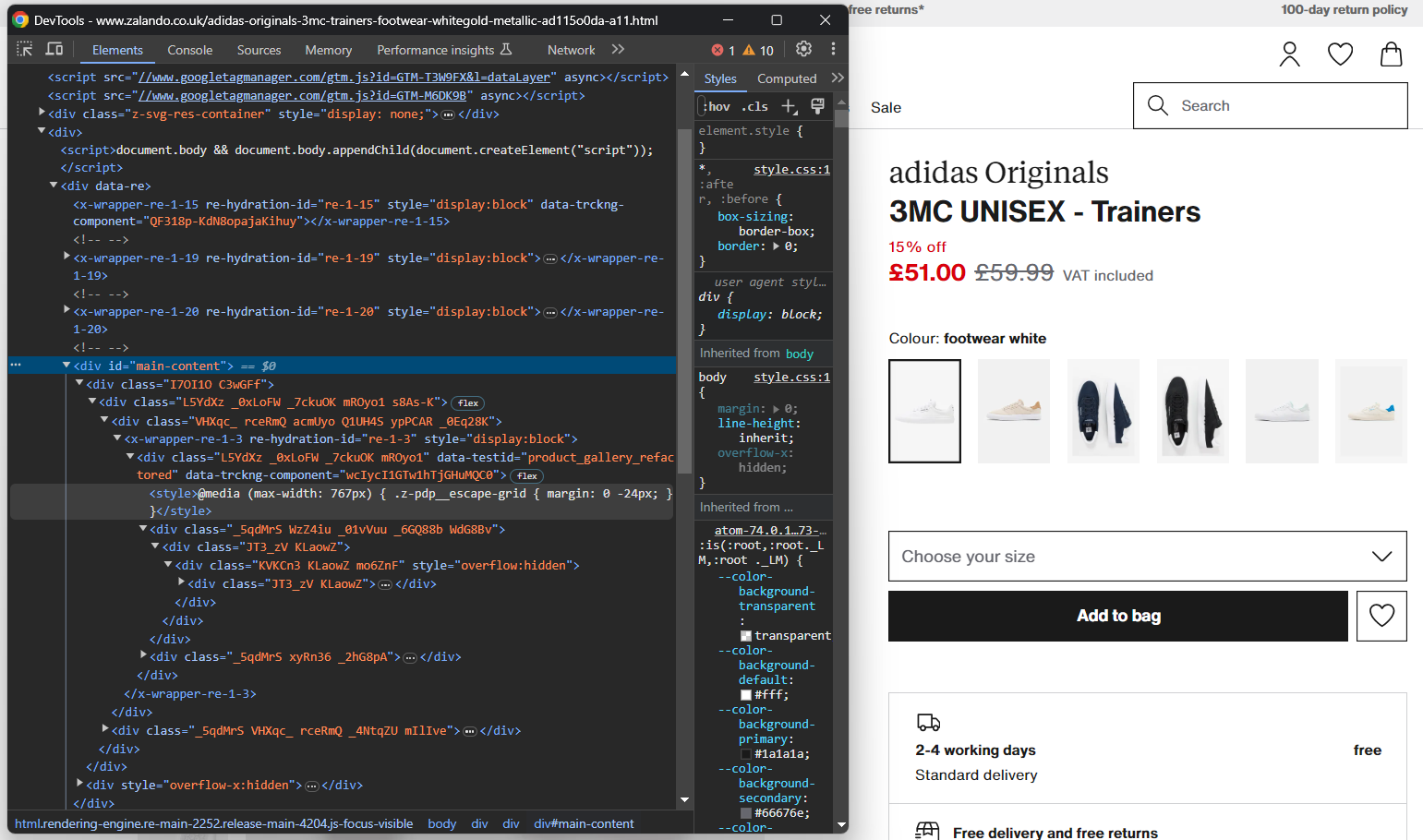
Vous remarquerez certainement que la plupart des classes CSS semblent être générées de manière aléatoire au moment de la compilation. En d’autres termes, vous ne devez pas baser votre stratégie de sélection sur celles-ci, car elles changeront à chaque déploiement. Parallèlement, certains éléments ont des attributs HTML peu courants, tels que data-testid. Cela vous aidera à définir des sélecteurs efficaces.
Interagissez avec la page pour étudier comment le DOM change après avoir cliqué sur des éléments spécifiques, tels que les accordéons. Vous vous rendrez compte que certaines données sont ajoutées dynamiquement au DOM en fonction des actions de l’utilisateur.
Continuez à inspecter la page cible et familiarisez-vous avec sa structure HTML jusqu’à ce que vous vous sentiez prêt à passer à l’étape suivante.
Étape 5 : Commencez à extraire les données sur les produits
Commencez par initialiser une structure de données dans laquelle vous conserverez les données extraites. Un dictionnaire Python sera parfait :
product = {}Commencez à sélectionner des éléments sur la page et extrayez-en les données !
Inspectez l’élément HTML contenant la marque de chaussures :
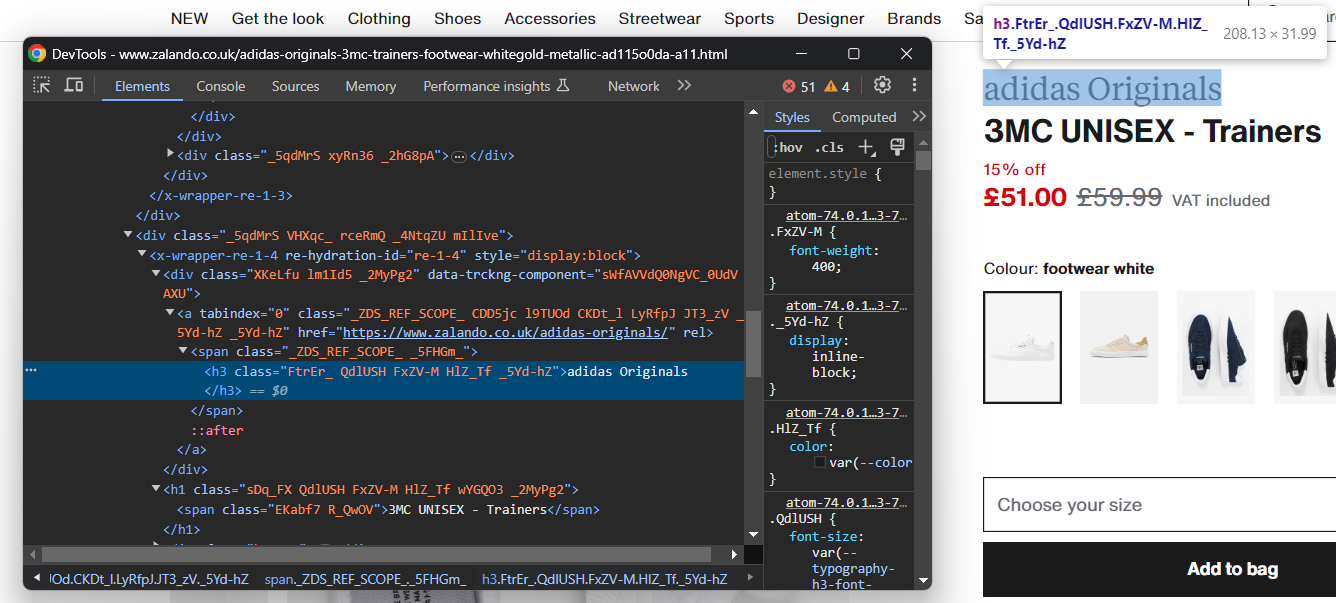
Notez que la marque est un élément <h3> et le nom du produit un élément <h1>. Récupérez ces données à l’aide de :
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element() est une méthode Selenium qui renvoie le premier élément correspondant à la stratégie de sélection transmise en tant que paramètre. En particulier, By.CSS_SELECTOR indique au pilote d’utiliser une stratégie de sélecteur CSS. Selenium prend également en charge :
- By.TAG_NAME : pour rechercher des éléments en fonction de leur balise HTML.
- By.XPATH : pour rechercher des éléments via une expression XPath.
De même, il existe également find_elements(), qui renvoie la liste de tous les nœuds correspondant à la requête de sélection.
N’oubliez pas d’importer By avec :
from selenium.webdriver.common.by import ByÀ partir d’un élément HTML, vous pouvez ensuite accéder à son contenu textuel à l’aide de l’attribut text. Si nécessaire, utilisez la méthode Python replace() pour nettoyer les chaînes de texte.
L’extraction des informations sur les prix est un peu plus délicate. Comme vous pouvez le voir sur l’image ci-dessous, il n’existe pas de moyen facile de sélectionner ces éléments :
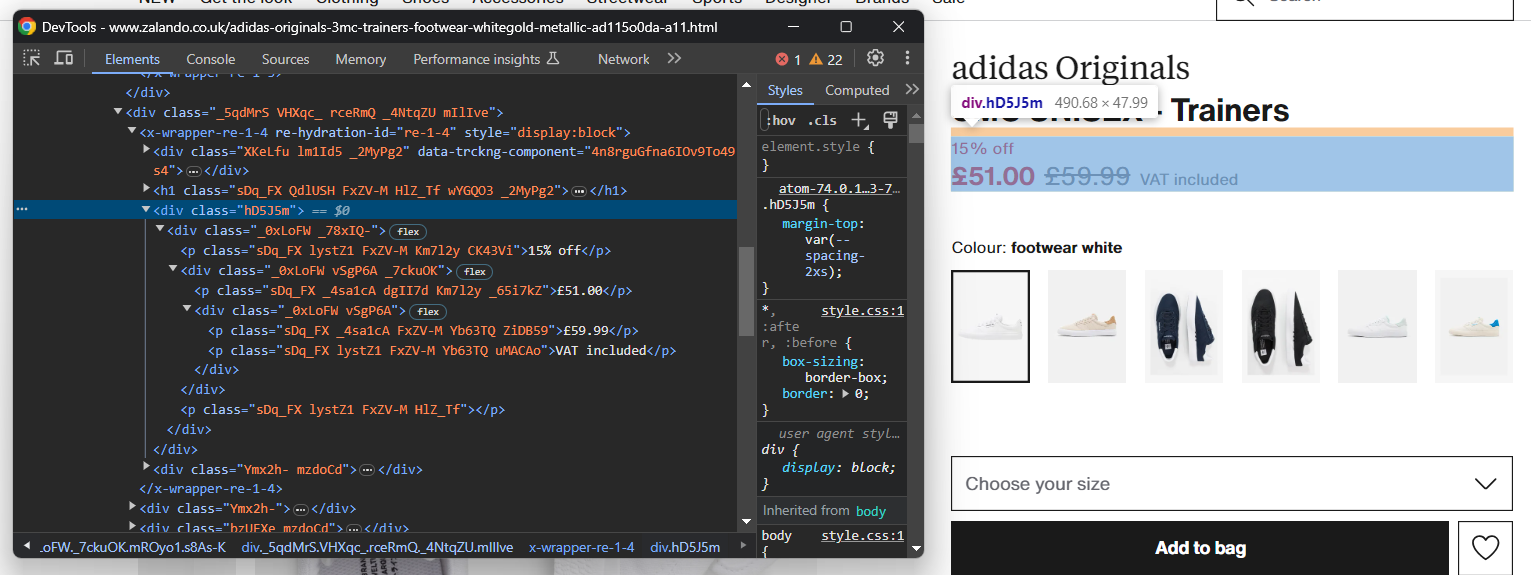
Ce que vous pouvez faire, c’est :
- Accéder au prix <div> en tant que premier élément frère de l’élément <h1> name.
- Obtenir tous les nœuds <p> qu’il contient.
Pour ce faire, utilisez :
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")Gardez à l’esprit que Selenium ne fournit pas de méthode utilitaire pour accéder aux frères d’un nœud. C’est pourquoi vous devez utiliser l’expression Xpath following-sibling::* à la place.
Vous pouvez ensuite obtenir les données relatives au prix du produit avec :
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].textConcentrez-vous maintenant sur la galerie d’images du produit :
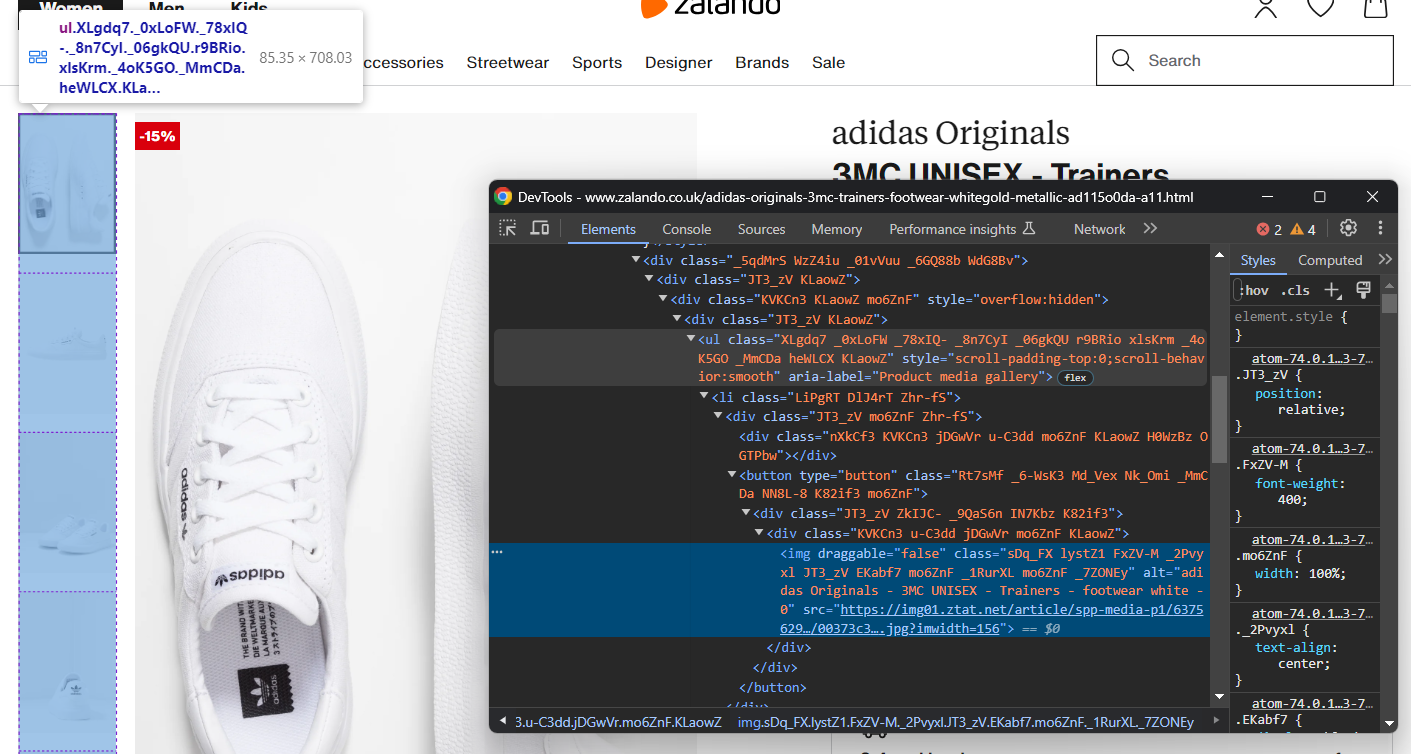
Elle contient plusieurs images, initialisez donc un tableau pour toutes les stocker :
images = []Une fois encore, sélectionner l’élément <img> n’est pas facile, mais vous pouvez y parvenir en ciblant les éléments <li> à l’intérieur de la balise <ul> « Galerie multimédia du produit » :
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Galerie multimédia du produit"] li')for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)De la même manière, vous pouvez collecter les options de couleur des chaussures :
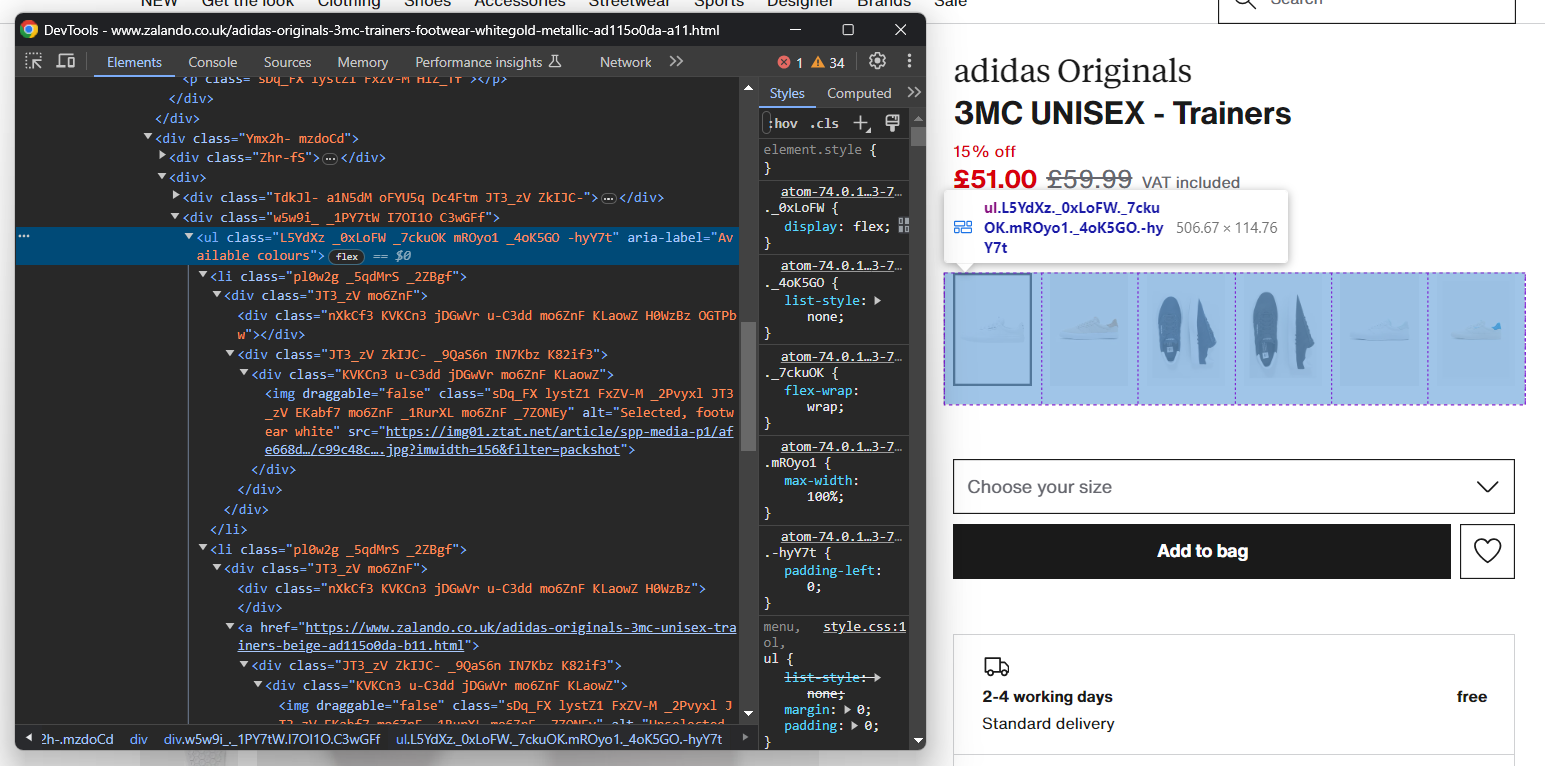
Comme précédemment, chaque élément de couleur est <li>. Plus précisément, chaque section de couleur comporte :
- Un lien facultatif.
- Une image.
- Un nom, stocké dans l’attribut alt de l’élément image.
Extrayez toutes les couleurs avec :
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
# initialise un nouvel objet couleur
color = {
'color': None,
'image': None,
'link': None
}
# vérifier si le lien de couleur est présent et extraire son URL
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
couleur['lien'] = éléments_lien[0].get_attribute('href')
# vérifier si l'image de couleur est présente et récupérer ses données
éléments_image = élément_couleur.find_elements(By.TAG_NAME, 'img')
si len(éléments_image) > 0 :
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)Parfait ! Vous venez d’implémenter une logique de scraping, mais il reste encore des données à récupérer.
Étape 6 : extraire les données relatives aux détails du produit
Les détails du produit sont stockés dans des cartes placées sous l’élément de sélection des couleurs :
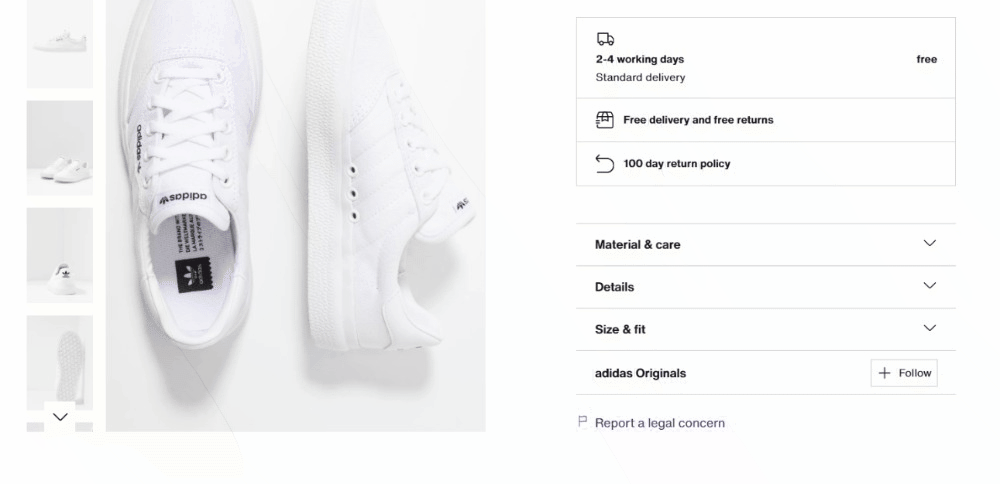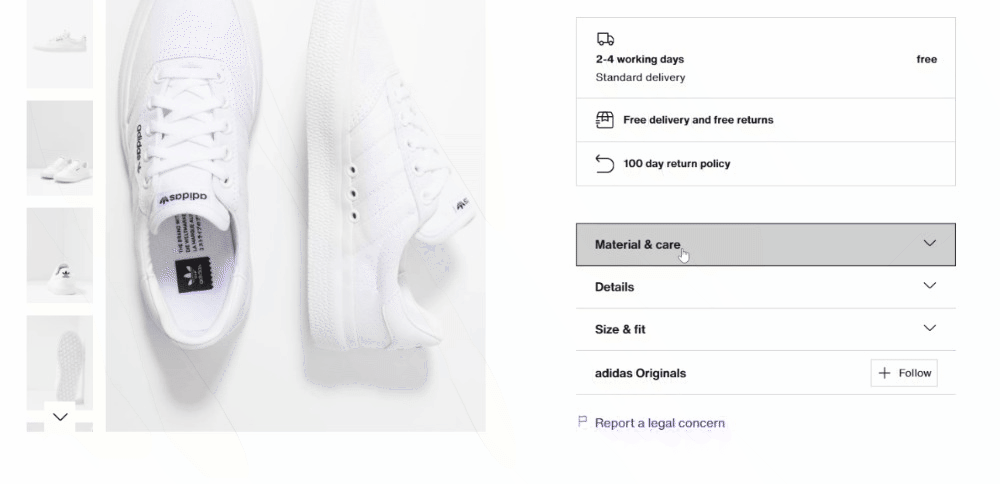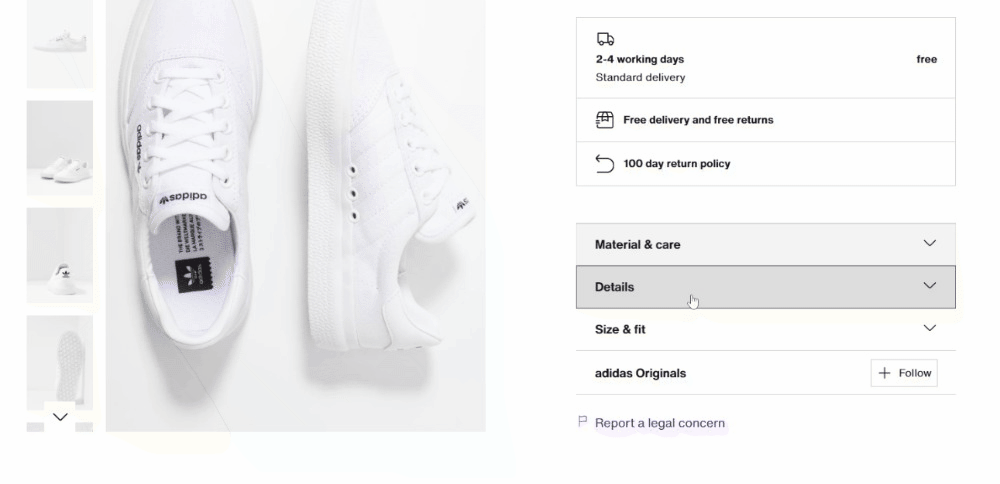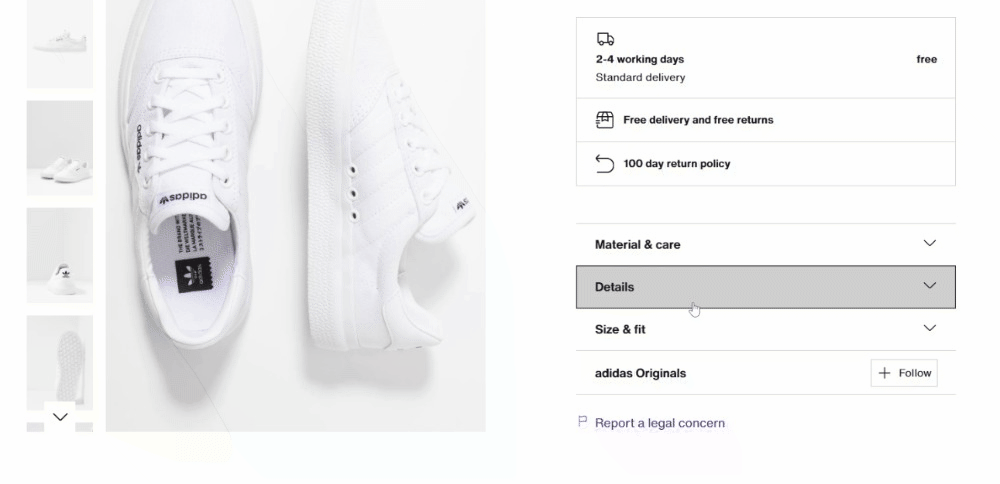
Commencez par vous concentrer sur les informations de livraison :
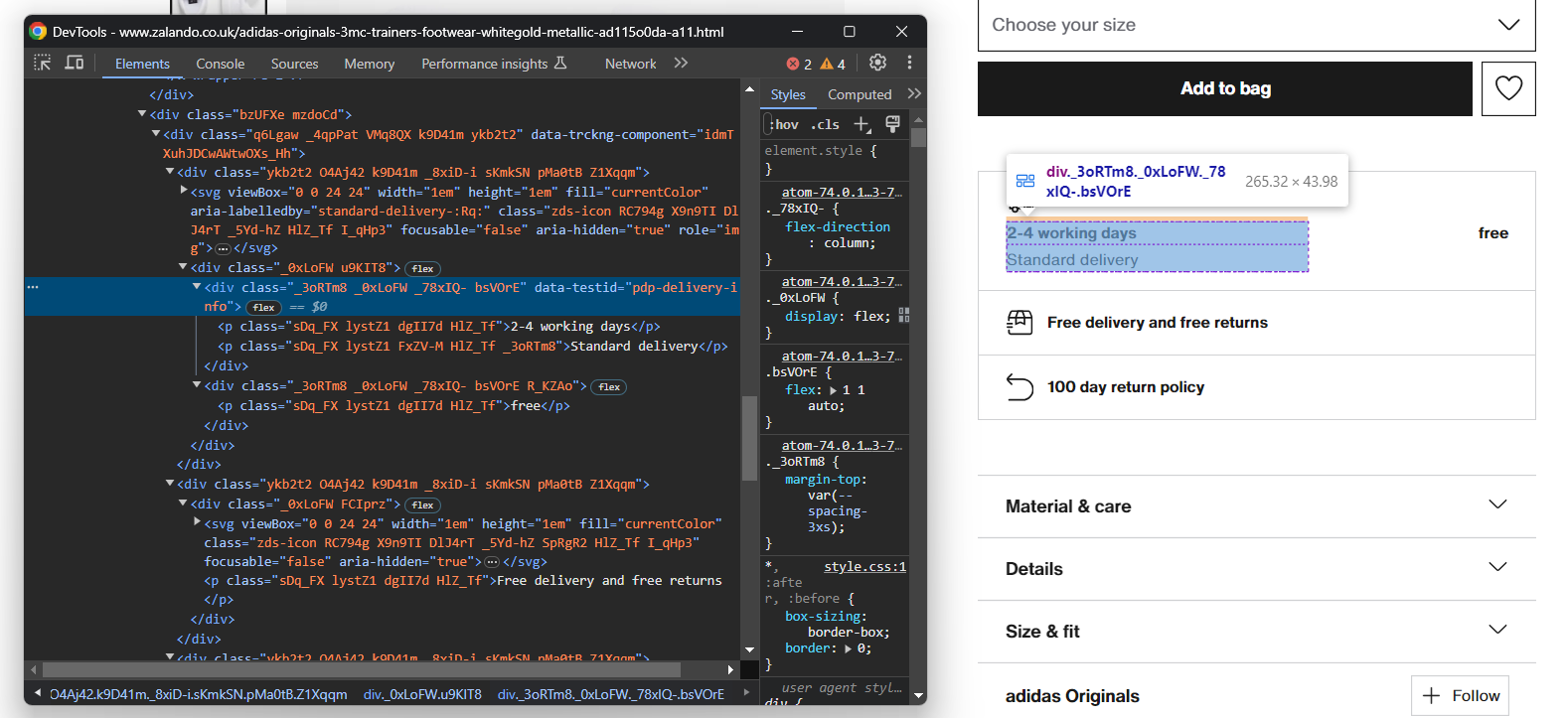
Elles se composent de trois champs de données, donc initialisez un dictionnaire de livraison comme ci-dessous :
livraison = {
'heure': Aucune,
'type': Aucun,
'coût': Aucun,
}Une fois encore, il n’existe pas de sélecteur facile pour sélectionner ces trois éléments. Voici ce que vous pouvez faire :
- Sélectionner le nœud dont l’attribut data-testid est « pdp-delivery-info ».
- Passez à son parent.
- Récupérez tous les éléments <p> descendants.
Implémentez cette logique et extrayez les données de livraison avec :
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].textComme Selenium ne permet pas d’accéder au parent d’un nœud, vous devez utiliser l’expression Xpath parent::*.
Ensuite, concentrez-vous sur les accordéons détaillant les produits :
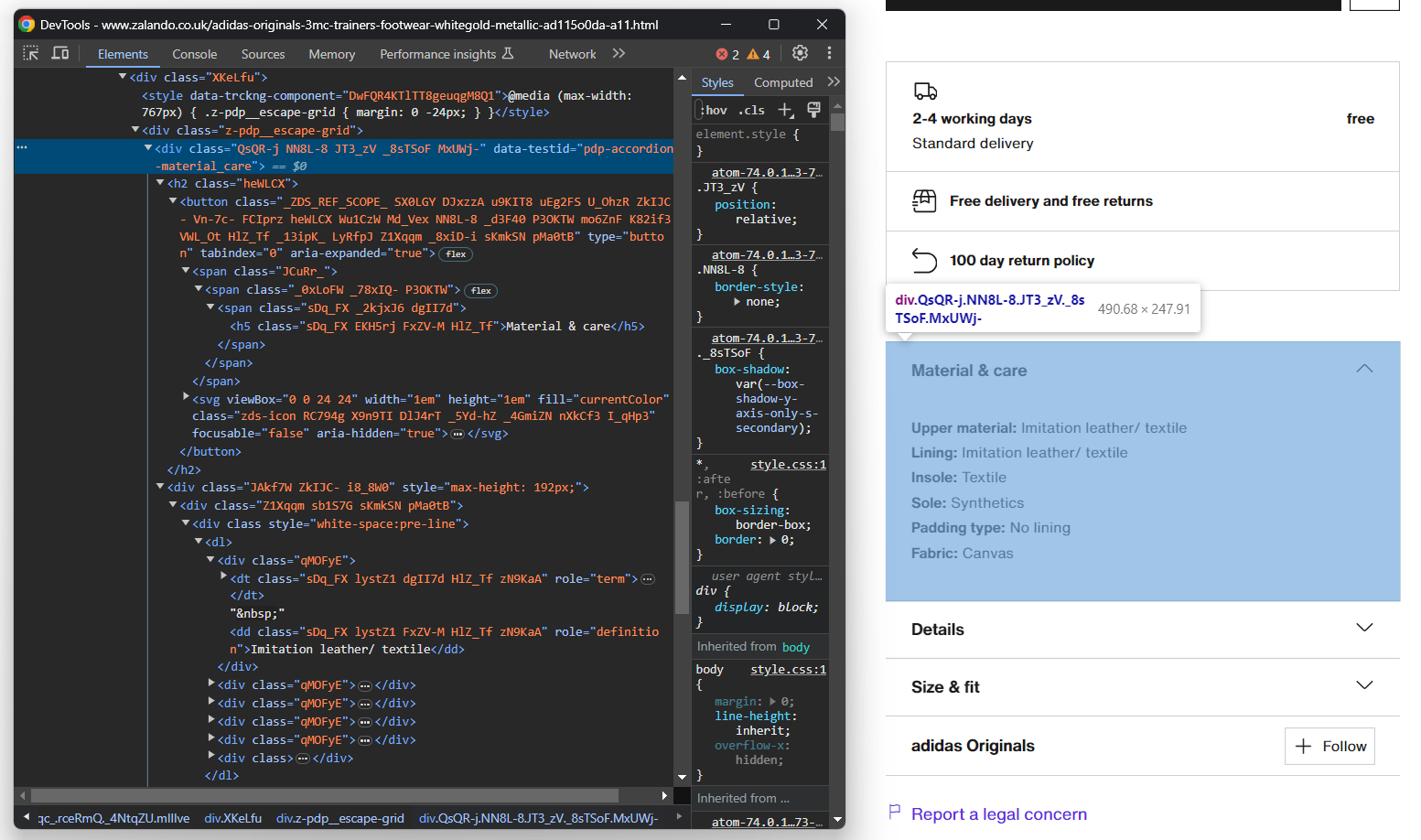
Cette fois-ci, vous pouvez obtenir tous les éléments accordéon en ciblant les nœuds dont l’attribut data-testid commence par « pdp-accordion- ». Pour ce faire, utilisez le sélecteur CSS suivant :
[data-testid^="pdp-accordion-"]Cette section contient plusieurs champs, vous devez donc créer un dictionnaire pour en garder la trace :
info = {}Appliquez ensuite le sélecteur CSS susmentionné pour sélectionner les accordéons détaillant les informations sur les produits :
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]L’élément « Taille et coupe » ne contient pas de données pertinentes, vous pouvez donc l’ignorer. [:2] réduira la liste aux deux premiers éléments comme souhaité.
Ces éléments HTML sont dynamiques et leur contenu n’est ajouté au DOM que lorsqu’ils sont ouverts. Vous devez donc simuler l’interaction du clic avec la méthode click() :
for info_element in info_elements:
info_element.click()
// logique de scraping...
Ensuite, remplissez l'objet info par programmation avec :
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').textLa logique ci-dessus extrait dynamiquement les informations contenues dans les accordéons et les organise par nom.
Pour mieux comprendre le fonctionnement de ce code, essayez d’imprimer info. Vous verrez :
{'Matériau et entretien' : {'Matériau supérieur' : 'Simili cuir/textile', 'Doublure' : 'Simili cuir/textile', 'Semelle intérieure' : 'Textile', 'Semelle' : 'Synthétique', 'Type de rembourrage' : 'Sans doublure', 'Tissu' : 'Toile'}, « Détails » : {« Bout de la chaussure » : « Rond », « Type de talon » : « Plat », « Fermeture » : « Lacets », « Fermeture de la chaussure » : « Lacets », « Motif » : « Uni », « Numéro d'article » : « AD115O0DA-A11 »}}Fantastique ! Les détails du produit Zalando ont été récupérés !
Étape 7 : Remplir l’objet produit
Il ne reste plus qu’à remplir le dictionnaire produit avec les données récupérées :
# assigner les données récupérées au dictionnaire
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = infoVous pouvez également ajouter une instruction de journalisation pour vérifier que le Scraper Zalando fonctionne comme prévu :
print(job)
Exécutez le script :
python Scraper.pyCela produira un résultat similaire à :
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }Et voilà ! Vous venez d’apprendre à extraire les données produit de Zalando.
Étape 8 : Exporter les données extraites au format JSON
Pour l’instant, les données extraites sont stockées dans un dictionnaire Python. Exportez-les au format JSON pour faciliter leur partage et leur lecture :
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)L’extrait ci-dessus crée un fichier de sortie product.json avec open() et le remplit avec des données JSON via json.dump(). Consultez notre guide pour en savoir plus sur la façon d’analyser et de sérialiser des données en JSON dans Python.
N’oubliez pas d’ajouter l’importation json :
import jsonCe package provient de la bibliothèque standard Python, vous n’avez donc même pas besoin de l’installer manuellement.
Incroyable ! Vous êtes parti de données produit brutes contenues dans une page web et vous disposez désormais de données JSON semi-structurées. Vous êtes prêt à découvrir le Scraper Zalando complet.
Étape 8 : Assemblez le tout
Voici le code complet du fichier scraper.py :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# configurez l'instance Chrome
options = webdriver.ChromeOptions()
# vos options de navigateur...
driver = webdriver.Chrome(
service=service,
options=options)
# maximiser la fenêtre pour éviter le rendu réactif
driver.maximize_window()
# visiter la page cible dans le navigateur contrôlé
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# instancier l'objet qui contiendra les données extraites
product = {}
# logique d'extraction
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].text
images = []
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')
for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Couleurs disponibles"] li')
for color_element in color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
livraison['coût'] = livraison_éléments[2].texte
info = {}
info_éléments = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
for info_element in info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# fermer le navigateur et libérer ses ressources
driver.quit()
# assigner les données récupérées au dictionnaire
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(product)
# exporter les données récupérées vers un fichier JSON
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)En un peu plus de 100 lignes de code, vous venez de créer un Scraper web Zalando complet pour récupérer les données détaillées des produits.
Exécutez-le avec :
python Scraper.pyPatientez quelques secondes jusqu’à ce que le script soit terminé.
À la fin du processus de scraping, un fichier product.json apparaîtra dans le dossier racine de votre projet. Ouvrez-le et vous verrez :
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
« images » : [
« https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156 »,
// omis pour plus de concision...
« https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156 »
],
« colors » : [
{
« color » : « footwear white »,
« image » : « https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// omis pour plus de concision...
{
"color": "white",
"image": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
« lien » : « https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html »
}
],
« livraison » : {
« délai » : « 2 à 4 jours ouvrés »,
« type » : « Livraison standard »,
« coût » : « gratuit »
},
« info » : {
« Matériau et entretien » : {
« Matériau extérieur » : « Simili cuir/textile »,
« Doublure » : « Simili cuir/textile »,
« Semelle intérieure » : « Textile »,
« Semelle » : « Synthétique »,
« Type de rembourrage » : « Sans doublure »,
« Tissu » : « Toile »
},
« Détails » : {
« Bout de la chaussure » : « Rond »,
« Type de talon » : « Plat »,
« Fermeture » : « Lacets »,
« Attache » : « Lacets »,
« Motif » : « Uni »,
« Numéro d'article » : « AD115O0DA-A11 »
}
}
}Félicitations ! Vous venez d’apprendre à scraper Zalando en Python !
Conclusion
Dans ce tutoriel, vous avez compris pourquoi Zalando est un excellent site de commerce électronique à scraper et comment en extraire des données. Vous avez vu ici comment créer un Scraper Zalando qui récupère automatiquement les données d’une page produit.
Comme vous pouvez le constater, le scraping de Zalando n’est pas une tâche facile, et ce pour au moins trois raisons :
- Le site met en œuvre certaines mesures anti-scraping qui pourraient bloquer votre script.
- Les pages web contiennent des classes CSS aléatoires.
- Chaque page produit a une structure spécifique et peut contenir des informations différentes.
Pour éviter le premier problème et ne plus vous soucier d’être bloqué, essayez notre nouvelle solution ! Le Navigateur de scraping est un navigateur contrôlable qui gère automatiquement les CAPTCHA, les empreintes digitales, les nouvelles tentatives automatisées, et bien plus encore. Cependant, vous devrez toujours écrire du code et continuer à le maintenir. Résolvez les deux autres problèmes grâce à une solution prête à l’emploi, découvrez notre scraper Zalando!
Remarque : ce guide a été minutieusement testé par notre équipe au moment de sa rédaction, mais comme les sites web mettent fréquemment à jour leur code et leur structure, certaines étapes peuvent ne plus fonctionner comme prévu.






