
Dans cet article, vous apprendrez :
- Qu’est-ce qu’un outil de suivi des prix Amazon et pourquoi est-il utile ?
- Comment en créer un grâce à un tutoriel étape par étape en Python
- Les limites de cette approche et comment les surmonter
C’est parti !
Qu’est-ce qu’un outil de suivi des prix Amazon ?
Un outil de surveillance des prix Amazon est un outil, un service ou un script permettant de surveiller le prix d’un ou plusieurs produits Amazon au fil du temps. Il fournit des mises à jour périodiques sur les changements de prix, vous permettant d’identifier les baisses de prix, les remises ou les fluctuations.
Pourquoi suivre le prix d’un article Amazon ?
Le suivi des prix Amazon vous aide à :
- Économiser de l’argent en achetant des produits à leur prix le plus bas
- Planifier vos achats pendant les soldes ou les promotions
- fixer des prix compétitifs pour vos produits, si vous êtes vendeur
De plus, le suivi des prix Amazon est essentiel pour surveiller les tendances saisonnières et comprendre la dynamique du marché.
Créer un outil de suivi des prix Amazon : guide étape par étape
Dans cette section du tutoriel, vous apprendrez à créer un outil de suivi des prix Amazon à l’aide de Python. Suivez les étapes ci-dessous pour créer un bot de scraping qui :
- Se connecte aux pages Amazon des produits spécifiés
- Récupère les données de prix de ces pages
- Suivra l’évolution des prix au fil du temps
Si vous êtes également intéressé par d’autres données, consultez notre guide sur la manière de scraper les données des produits Amazon.
Il est temps de mettre en œuvre un script de suivi des prix Amazon !
Étape n° 1 : configuration du projet
Avant de commencer, assurez-vous que Python 3+ est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le depuis le site officiel et suivez les instructions d’installation.
Créez ensuite un répertoire pour votre projet de suivi des prix Amazon à l’aide de cette commande :
mkdir amazon-price-tracker
Accédez à ce répertoire et configurez un environnement virtuel à l’intérieur :
cd amazon-price-tracker
python -m venv venv
Ouvrez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux bons choix.
Créez un fichier scraper.py dans le dossier du projet, qui devrait maintenant contenir cette structure de fichiers :
scraper.py contiendra la logique de suivi des prix Amazon.
Dans le terminal de votre IDE, activez l’environnement virtuel. Sous Linux ou macOS, utilisez :
./venv/bin/activate
De manière équivalente, sous Windows, exécutez :
venv/Scripts/activate
Parfait ! Vous êtes maintenant prêt à commencer.
Étape n° 2 : configurer les bibliothèques de scraping
Comme indiqué dans notre guide sur le scraping des sites de commerce électronique, le scraping d’Amazon nécessite un outil d’automatisation du navigateur. Ce n’est pas parce que le site est particulièrement dynamique, mais parce qu’Amazon utilise des mesures anti-bot pour détecter et bloquer les requêtes automatisées.
En termes simples, vous avez besoin d’un outil d’automatisation du navigateur tel que Selenium pour récupérer des données sur Amazon. Pour commencer, installez Selenium comme suit :
pip install selenium
Si vous n’êtes pas familier avec cette bibliothèque, consultez notre tutoriel sur le Scraping web avec Selenium.
Importez la bibliothèque Selenium dans votre script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
Ensuite, créez un objet ChromeDriver pour contrôler une instance du navigateur Chrome :
# Initialisez le WebDriver pour contrôler Chrome.
driver = webdriver.Chrome(service=Service())
# Logique de scraping...
# Libérez les ressources du pilote.
driver.quit()
driver sera utilisé pour interagir avec la page produit Amazon afin de suivre les prix.
N’oubliez pas qu’Amazon adopte des mesures anti-scraping qui peuvent bloquer les navigateurs sans interface graphique. Pour éviter tout problème, conservez votre navigateur contrôlé par Selenium en mode avec interface graphique.
Super ! Il est temps d’automatiser votre logique de scraping Amazon.
Étape n° 3 : se connecter à la page cible
Supposons que vous souhaitiez suivre le prix de la PS5 sur Amazon :
Voici l’URL de la page produit :
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
La partie après amazon.com n’est qu’un slug pour faciliter la lecture, mais la partie importante est le code après /dp/. Ce code est appelé Amazon ASIN, un identifiant unique pour les produits Amazon.
En d’autres termes, vous pouvez accéder à la même page produit en utilisant directement l’ASIN dans le format suivant :
https://www.amazon.com/product/dp/<AMAZON_ASIN>
Dans cet exemple, l’ASIN de la PS5 est B0CL5KNB9M. Enregistrez cet ASIN dans une variable et utilisez-le pour générer l’URL du produit Amazon :
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
Ensuite, utilisez la méthode get() de Selenium pour demander au navigateur d’accéder à la page cible :
driver.get(amazon_url)
Définissez un point d’arrêt avant l’instruction driver.quit(), puis exécutez le script. La page du produit Amazon devrait maintenant s’afficher dans le navigateur :
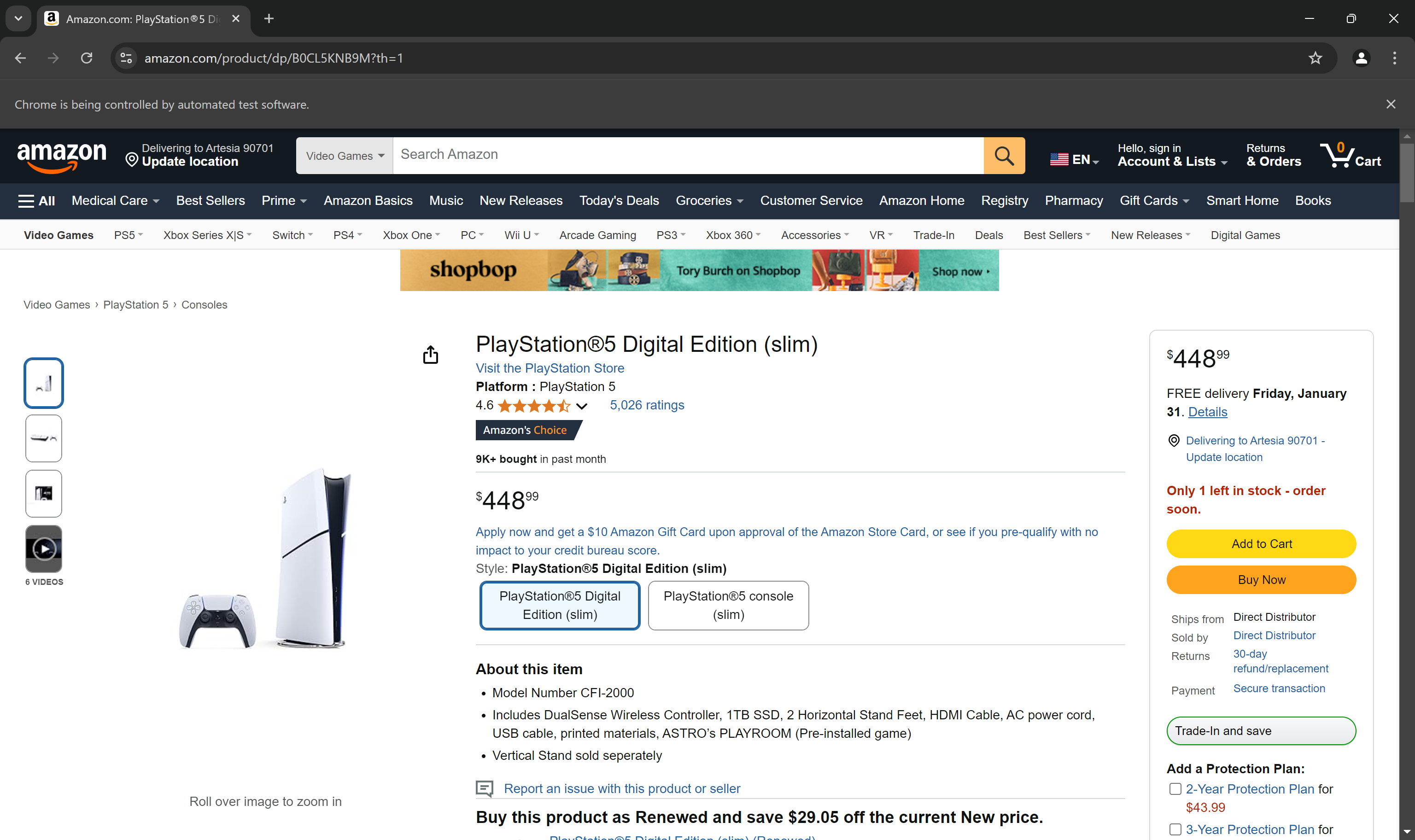
Le message « Chrome est contrôlé par un logiciel automatisé » prouve que Selenium fonctionne comme prévu sur le navigateur.
N’oubliez pas qu’Amazon utilise des mesures anti-bot, qui peuvent entraîner des défis CAPTCHA ou des requêtes bloquées. Ne vous inquiétez pas, nous aborderons les stratégies pour gérer ces problèmes plus loin dans cet article.
Pour en savoir plus sur l’Amazon ASIN Scraper de Bright Data, cliquez ici.
Étape n° 4 : récupérer les informations sur les prix
Ouvrez la page du produit cible en mode incognito dans votre navigateur. Ensuite, cliquez avec le bouton droit de la souris sur le prix affiché sur la page et sélectionnez l’option « Inspecter » :
Dans la section DevTools, examinez le code HTML de l’élément de prix. Notez que le prix se trouve à l’intérieur d’un élément .a-price.
Sélectionnez l’élément avec un sélecteur CSS et extrayez les données qui s’y trouvent :
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
La fonction replace() est utilisée pour supprimer les caractères de nouvelle ligne du prix.
N’oubliez pas d’importer By:
from selenium.webdriver.common.by import By
Super ! Vous avez réussi à implémenter la fonctionnalité clé de votre outil Amazon Price Tracker : le scraping des prix.
Étape n° 5 : stocker les prix
La fonctionnalité phare d’un outil de suivi des prix Amazon est sa capacité à suivre l’historique des prix, afin que vous puissiez évaluer les changements et les fluctuations au fil du temps. Pour ce faire, vous devez stocker les données de prix quelque part, par exemple dans une base de données ou un fichier.
Pour simplifier, nous utiliserons un fichier JSON comme base de données. Le fichier stockera l’ASIN du produit et une liste des prix historiques.
Tout d’abord, assurez-vous que le fichier JSON existe avec la structure suivante :
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
Voici comment initialiser un tel fichier en Python s’il n’existe pas :
# Nom du fichier JSON db et données initiales
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Écrire le fichier JSON db s'il n'existe pas
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Logique Selenium...
Pour fonctionner, l’extrait ci-dessus nécessite les deux importations suivantes :
import os
import json
Avant la logique de scraping, chargez le fichier JSON pour accéder à ses données actuelles :
# Ouvrir le fichier JSON en lecture et écriture
with open(file_name, "r+") as file:
# Charger les données de prix actuelles
price_data = json.load(file)
# Logique de scraping...
Après avoir scrapé le prix, ajoutez le nouveau prix avec un horodatage à la liste des prix:
price = price_element.text.replace("n", "")
# Horodatage actuel
timestamp = datetime.now().isoformat()
# Ajouter un nouveau point d'information sur le prix
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
Ajoutez l’importation suivante :
from datetime import datetime
Enfin, mettez à jour le fichier JSON :
# Déplacez le pointeur de fichier au début
file.seek(0)
# Remplacez les données récupérées
json.dump(price_data, file, indent=4)
# Tronquez le fichier afin que, si le nouveau contenu est plus court que l'original, les données supplémentaires soient effacées.
file.truncate()
Fantastique ! La logique de suivi des prix a été mise en œuvre.
Étape n° 6 : planifier la logique de suivi des prix
Actuellement, vous devez exécuter manuellement le script chaque fois que vous souhaitez extraire et suivre les prix Amazon. Cela peut fonctionner pour une utilisation occasionnelle. Cependant, l’automatisation du script pour qu’il s’exécute à intervalles réguliers le rend beaucoup plus efficace.
Pour ce faire, utilisez la bibliothèque Python schedule. Celle-ci fournit une API intuitive pour planifier des tâches dans Python.
Installez la bibliothèque en exécutant la commande suivante dans votre environnement virtuel activé :
pip install schedule
Ensuite, encapsulez toute votre logique de suivi des prix Amazon dans une fonction qui accepte l’ASIN comme paramètre :
def track_price(amazon_asin):
# Logique complète de suivi des prix Amazon...
Vous disposez désormais d’une tâche Python que vous pouvez planifier pour qu’elle s’exécute toutes les 12 heures :
# Exécuter immédiatement
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Ensuite, planifiez le travail pour qu'il s'exécute toutes les 12 heures
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
La boucle while garantit que le script reste actif pour traiter les tâches planifiées.
N’oubliez pas les deux importations suivantes :
import schedule
import time
Parfait ! Vous venez d’automatiser l’ensemble du processus, transformant votre script en un outil de suivi des prix Amazon entièrement automatique.
Étape n° 7 : assembler le tout
Voici à quoi devrait ressembler votre outil de suivi des prix Amazon en Python :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Initialise le WebDriver pour contrôler Chrome
driver = webdriver.Chrome(service=Service())
# Génération de l'URL du produit Amazon
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# Nom du fichier JSON db et données initiales
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Écrire le fichier JSON db s'il n'existe pas
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Ouvrir le fichier JSON pour lecture et écriture
with open(file_name, "r+") as file:
# Charger les données de prix actuelles
price_data = json.load(file)
# Accéder à la page cible
driver.get(amazon_url)
# Extraire le prix
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# Horodatage actuel
timestamp = datetime.now().isoformat()
# Ajouter un nouveau point d'information sur le prix
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# Déplacer le pointeur de fichier au début
file.seek(0)
# Remplacer les données extraites
json.dump(price_data, file, indent=4)
# Tronquer le fichier afin que, si le nouveau contenu est plus court que l'original, les données supplémentaires soient effacées.
file.truncate()
# Libérer les ressources du pilote
driver.quit()
# Exécuter immédiatement
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Ensuite, planifier l'exécution de la tâche toutes les 12 heures
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Lancez-le comme suit :
python3 Scraper.py
Ou, sous Windows :
python Scraper.py
Laissez le script s’exécuter pendant plusieurs heures. Le script générera un fichier price_history.json similaire à celui-ci :
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
Remarquez que chaque entrée du tableau des prix est enregistrée exactement 12 heures après la précédente.
Mission accomplie !
Étape n° 8 : prochaines étapes
Vous venez de créer un outil fonctionnel de suivi des prix Amazon, mais il est possible de l’améliorer pour passer au niveau supérieur. Voici quelques améliorations possibles :
- Ajouter une journalisation: comme pour tout processus non surveillé, il est essentiel de comprendre ce qui se passe. Pour ce faire, ajoutez une journalisation afin de suivre les actions du script.
- Utiliser une base de données: remplacez le fichier JSON par une base de données pour stocker les données. Cela facilite le partage et l’accès à l’historique des prix à partir de plusieurs appareils ou applications.
- Implémenter la gestion des erreurs: ajoutez une gestion des erreurs robuste pour gérer les mesures anti-bot, les délais d’attente du réseau et les pannes imprévues. Assurez-vous que le script réessaie ou passe gracieusement lorsque des erreurs se produisent.
- Lisez les options à partir de l’interface CLI: permettez au script d’accepter les entrées à partir de la ligne de commande, telles que l’ASIN et les options de planification. Cela le rendra plus flexible.
- Système de notification: intégrez des alertes par e-mail ou via des applications de messagerie pour vous informer des changements de prix importants.
Limites de cette approche et comment les surmonter
Le script de suivi des prix Amazon créé dans le chapitre précédent n’est qu’un exemple basique. Vous ne pouvez pas compter sur un script aussi simple pour une utilisation à long terme, à moins de mettre en œuvre les étapes suivantes. Bien que ces étapes améliorent le script, elles le rendent également plus complexe et plus difficile à gérer.
Cependant, quelle que soit la sophistication de votre script, Amazon peut toujours le bloquer à l’aide de CAPTCHA :
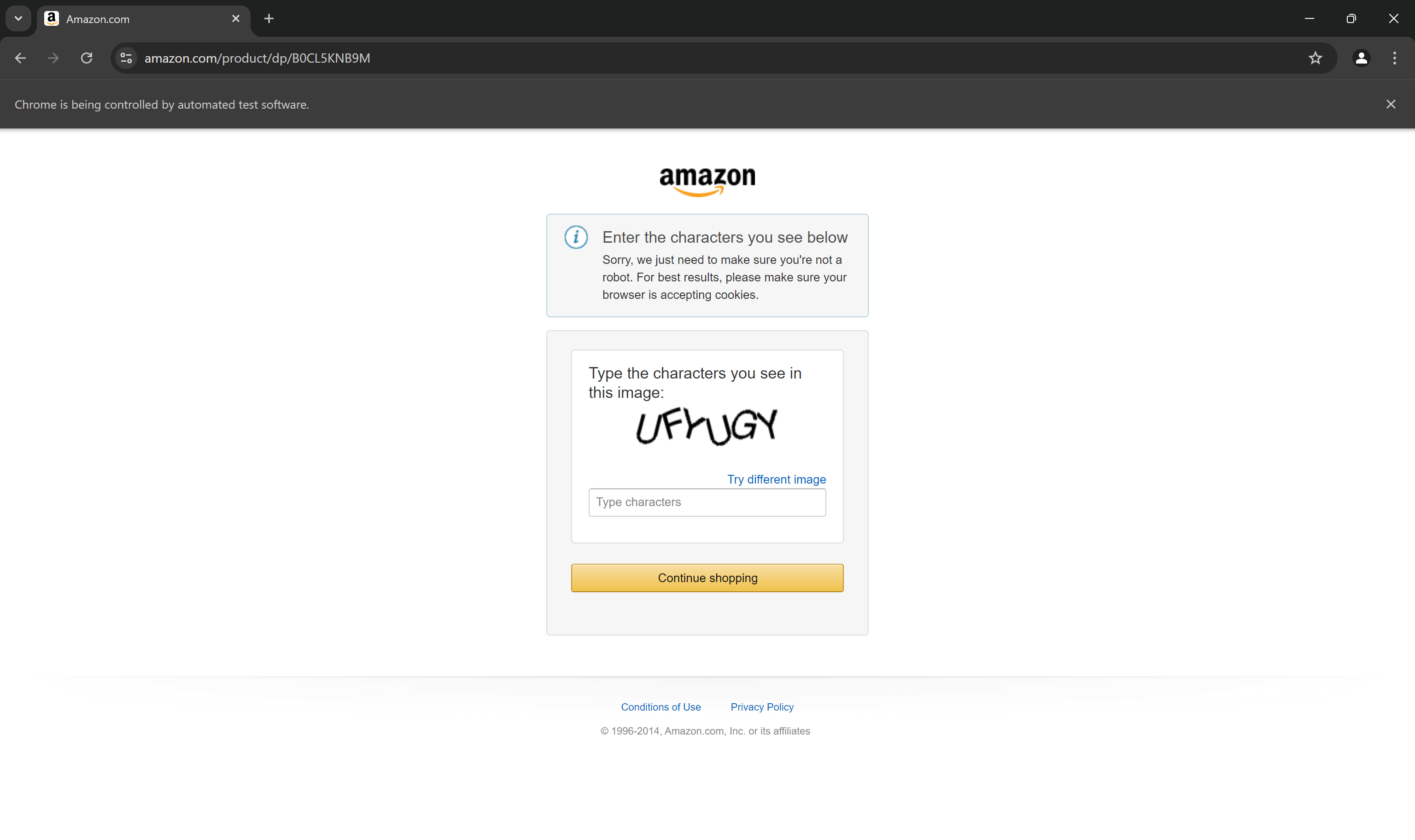
En réalité, il y a de fortes chances que votre script de scraping Amazon basé sur Selenium soit déjà bloqué par des CAPTCHA. Dans un premier temps, pensez à suivre notre guide sur la manière de contourner les CAPTCHA dans Python.
Vous pouvez néanmoins rencontrer des erreurs 429 Too Many Requests en raison d’une limitation stricte du débit. Dans ce cas, une bonne stratégie consiste à intégrer un Proxy dans Selenium pour faire tourner votre IP de sortie.
Ces défis soulignent à quel point le scraping de sites comme Amazon peut devenir frustrant sans les bons outils. De plus, l’impossibilité d’utiliser des outils d’automatisation du navigateur rend votre script lent et gourmand en ressources.
Alors, faut-il abandonner ? Pas du tout ! La véritable solution consiste à s’appuyer sur un service tel que Bright Insights, qui fournit des informations exploitables sur le commerce électronique, basées sur l’IA, pour vous aider à :
- Éviter les pertes de revenus: identifiez et traitez les pertes de revenus liées au retrait de la liste, aux ruptures de stock ou aux problèmes de visibilité.
- Suivre les ventes et les parts de marché: découvrez les opportunités inexploitées, suivez les ventes de vos concurrents et repérez les tendances à un stade précoce.
- Optimiser vos prix: surveillez les prix de vos concurrents en temps réel pour rester compétitif.
- Maximiser les médias de vente au détail: utilisez l’analyse pour optimiser la publicité, maximiser le retour sur investissement et garantir des résultats en croissance.
- Optimiser votre gamme de produits: améliorez votre gamme de produits en suivant vos concurrents et en maximisant vos revenus.
- Optimisation cross-canal: tirez parti des informations cross-canal pour gérer les ventes de produits et remporter des succès sur toutes les plateformes.
Bright Insights vous fournit toutes les données e-commerce dont vous avez besoin, y compris des fonctionnalités de suivi des prix Amazon.
Conclusion
Dans cet article, vous avez découvert ce qu’est un outil de suivi des prix Amazon et les avantages qu’il offre. Vous avez également vu comment en créer un à l’aide de Python et Selenium pour le Scraping web.
Le défi réside dans le fait qu’Amazon utilise des mesures anti-bot strictes, telles que les CAPTCHA, les empreintes digitales des navigateurs et les interdictions d’IP, pour bloquer les scripts automatisés. Mais grâce à notre outil de suivi des prix Amazon, vous pouvez oublier ces difficultés et obtenir les prix Amazon.
Si le Scraping web vous intéresse et que vous souhaitez obtenir différents types de données Amazon, pensez également à notre API Amazon Scraper!
Créez dès aujourd’hui un compte Bright Data gratuit et découvrez nos services.




