

Dans ce guide Goutte web scraping, vous apprendrez :
- Ce qu’est la bibliothèque PHP Goutte
- Comment l’utiliser pour le web scraping dans un tutoriel étape par étape
- Alternatives à Goutte pour le web scraping
- Les limites de cette approche et les solutions possibles
Plongeons dans l’aventure !
Qu’est-ce que la goutte ?
Goutte est une bibliothèque PHP pour le screen scraping et le web crawling, offrant une API intuitive pour naviguer sur les sites web et extraire des données des réponses HTML/XML. Elle comprend un client HTTP intégré et des capacités d’analyse HTML, vous permettant de récupérer des pages web par le biais de requêtes HTTP et de les traiter pour le scraping de données.
Note: Depuis le 1er avril 2023, Goutte n’est plus maintenu et est considéré comme obsolète. Cependant, à l’heure où nous écrivons ces lignes, elle fonctionne toujours de manière fiable.
Comment faire du Web Scraping avec Goutte : Guide étape par étape
Suivez ce tutoriel étape par étape et voyez comment utiliser Goutte pour extraire des données du site “Hockey Teams” :
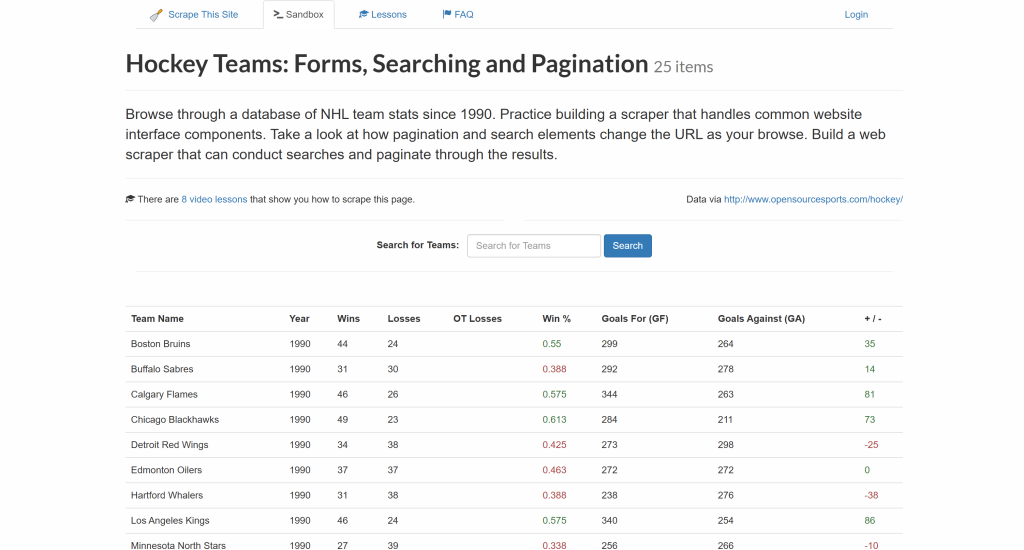
L’objectif est d’extraire les données du tableau ci-dessus et de les exporter dans un fichier CSV.
Il est temps d’apprendre à faire du web scraping avec Goutte !
Étape 1 : Mise en place du projet
Avant de commencer, assurez-vous que votre système répond aux exigences de Goutte – PHP7.1 ou supérieur. Pour vérifier la version actuelle de PHP, exécutez la commande suivante :
php -vLe résultat devrait ressembler à ceci :
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesSi votre version de PHP est inférieure à 7.1, vous devrez mettre à jour PHP avant de continuer.
Ensuite, gardez à l’esprit que Goutte sera installé via Composer, un gestionnaire de dépendances pour PHP. Si Composer n’est pas installé sur votre système, téléchargez-le depuis le site officiel et suivez les instructions d’installation.
Maintenant, créez un nouveau répertoire pour votre projet Goutte et naviguez jusqu’à lui dans le terminal :
mkdir goutte-parser
cd goutte-parserEnsuite, utilisez la commande composer init pour initialiser un projet Composer dans le dossier :
composer initComposer vous demandera d’entrer les détails du projet, comme le nom et la description du paquet. Les réponses par défaut fonctionneront, mais n’hésitez pas à les personnaliser en fonction de vos objectifs.
Maintenant, ouvrez le dossier du projet dans votre IDE PHP préféré. Visual Studio Code avec l’extension PHP ou IntelliJ WebStorm sont de bons choix.
Créez un fichier index.php vide dans le dossier du projet, qui doit contenir :
php-html-parser/
├── vendor/
├── composer.json
└── index.phpOuvrez le fichier index.php et ajoutez la ligne de code suivante pour importer les bibliothèques de Composer :
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...Ce fichier contiendra bientôt la logique de grattage de la Goutte.
Vous pouvez maintenant exécuter votre script à l’aide de cette commande :
php index.phpC’est parfait ! Vous êtes prêt à commencer à récupérer des données avec Goutte en PHP.
Étape 2 : Installation et configuration de la Goutte
Installez Goutte avec la commande Compose ci-dessous :
composer require fabpot/goutteCela ajoutera la dépendance fabpot/goutte à votre fichier composer.json, qui inclura maintenant :
"require": {
"fabpot/goutte": "^4.0"
}Dans index.php, importez Goutte en ajoutant la ligne de code suivante :
use GoutteClient;Ceci expose le client HTTP Goutte que vous pouvez utiliser pour vous connecter à une page cible, analyser son HTML et en extraire des données. Voyez comment faire dans l’étape suivante !
Étape 3 : Obtenir le code HTML de la page cible
Tout d’abord, créez un nouveau client HTTP Goutte :
$client = new Client();Dans les coulisses, la classe Client de Goutte est simplement une enveloppe autour du composant BrowserKitHttpBrowser de Symfony. Voyez-le en action dans notre guide sur le web scraping avec Laravel.
Ensuite, stockez l’URL de la page web cible dans une variable et utilisez la méthode request() pour récupérer son contenu :
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);Il envoie une requête GET à la page web, récupère son document HTML et l’analyse pour vous. Spécifiquement, l’objet $crawler donne accès à toutes les méthodes du composant DomCrawler de Symfony. $crawler est l’objet que vous utiliserez pour naviguer et extraire des données de la page.
C’est incroyable ! Vous avez maintenant tout ce qu’il vous faut pour le web scraping de la Goutte.
Étape 4 : Préparer la collecte des données qui nous intéressent
Avant d’extraire des données, vous devez vous familiariser avec la structure HTML de la page cible.
Tout d’abord, rappelez-vous que les données qui vous intéressent sont présentées sous forme de lignes à l’intérieur d’un tableau. Comme ce tableau contient plusieurs lignes, un tableau est une structure de données idéale pour stocker les données extraites :
$teams = [];Concentrez-vous à présent sur la structure HTML du tableau. Visitez la page cible dans votre navigateur, cliquez avec le bouton droit de la souris sur le tableau contenant les données qui vous intéressent et sélectionnez l’option “Inspecter” :
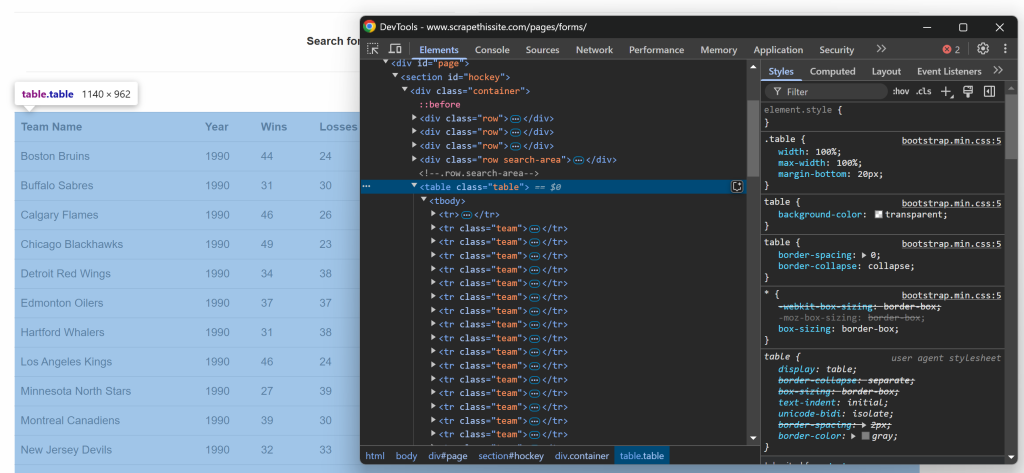
Dans les DevTools, vous verrez que le tableau a une classe table et qu’il est contenu dans un élément
id=``"`hockey``". Cela signifie que vous pouvez cibler le tableau en utilisant le sélecteur CSS suivant :
#hockey .tableAppliquer le sélecteur CSS pour sélectionner le nœud de la table en utilisant la méthode $crawler->filter() :
$table = $crawler->filter("#hockey .table");Ensuite, notez que chaque ligne est représentée par un élément
team. Sélectionnez toutes les lignes et itérez sur elles, en vous préparant à en extraire des données :
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});C’est formidable ! Vous disposez maintenant d’un squelette prêt pour le scraping de données de la Goutte.
Étape 5 : Mise en œuvre de la logique d’extraction des données
Comme précédemment, inspectez cette fois les lignes du tableau :
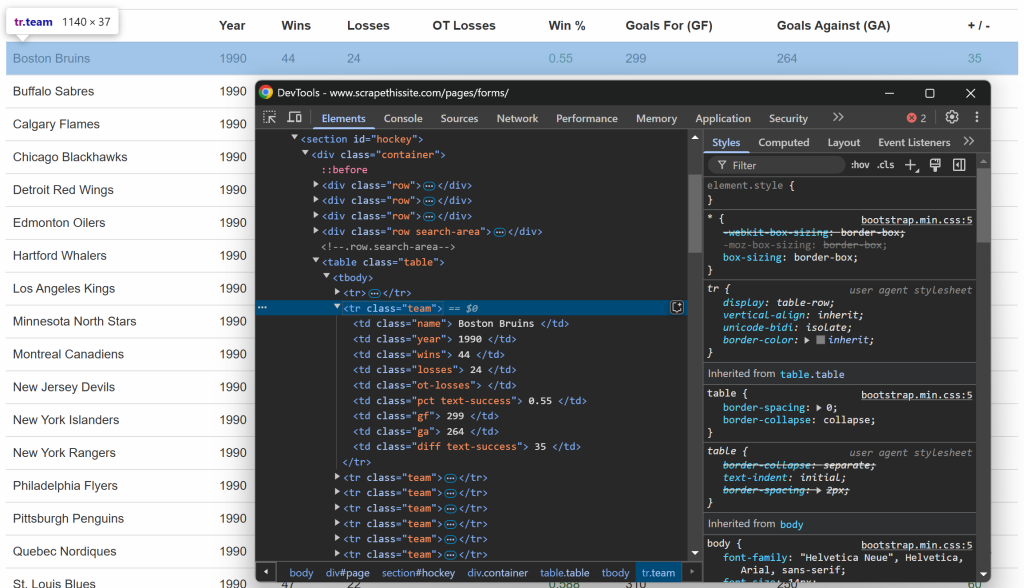
Vous pouvez constater que chaque ligne contient les informations suivantes dans des colonnes dédiées :
- Nom de l’équipe → à l’intérieur de l’élément
.name - Année de la saison → à l’intérieur de l’élément
.year - Nombre de victoires → à l’intérieur de l’élément
.wins - Nombre de pertes → à l’intérieur de l’élément
.losses - Pertes en heures supplémentaires → à l’intérieur de l’élément
.ot-losses - Pourcentage de gain → à l’intérieur de l’élément
.pct - Buts marqués (Goals For – GF) → à l’intérieur de l’élément
.gf - Buts encaissés (Goals Against – GA) → à l’intérieur de l’élément
.ga - Différence de buts → à l’intérieur de l’élément
.diff
Pour récupérer une seule information, vous devez suivre ces deux étapes :
- Sélectionner l’élément HTML à l’aide de
filter() - Extraire son contenu textuel à l’aide de la méthode
text()et supprimer les espaces supplémentaires à l’aide detrim()
Par exemple, vous pouvez récupérer le nom de l’équipe avec :
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());De même, étendez cette logique à toutes les autres colonnes :
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());Une fois que vous avez extrait les données qui vous intéressent de la ligne, stockez-les dans le tableau $teams:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];Après avoir parcouru toutes les lignes, le tableau $teams contiendra :
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)Génial ! Le grattage des données de la Goutte a été effectué avec succès.
Étape 6 : Mise en œuvre de la logique d’exploration
Il ne faut pas oublier que le site cible présente les données sur plusieurs pages et n’en montre qu’une partie à la fois. Sous le tableau, il y a un élément de pagination qui fournit des liens vers toutes les pages :

Ainsi, vous pouvez gérer la pagination dans votre script de scraping en suivant ces étapes simples :
- Sélectionner les éléments du lien de pagination
- Extraire les URL des pages paginées
- Visitez chaque page et appliquez la logique de scraping élaborée précédemment
Commencez par inspecter les éléments du lien de pagination :
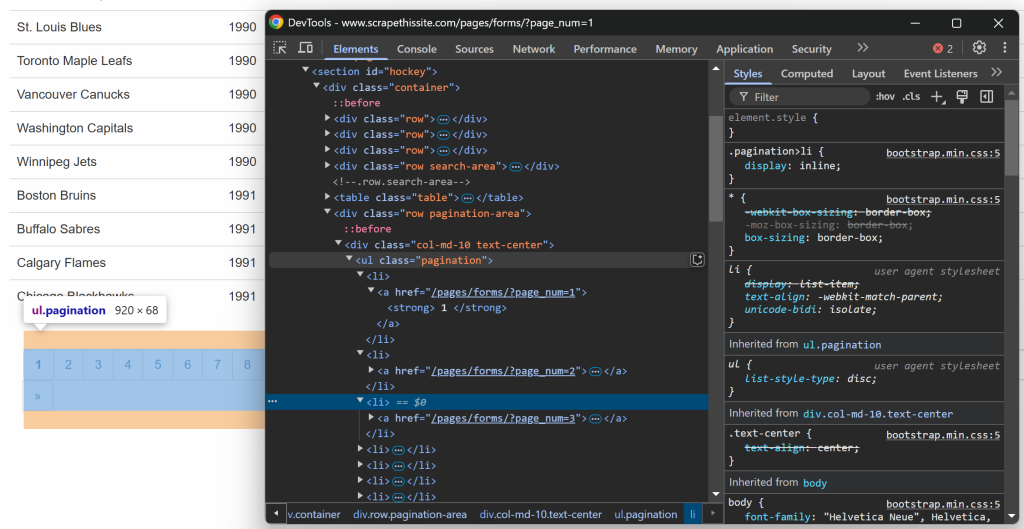
Notez que vous pouvez sélectionner tous les liens de pagination à l’aide du sélecteur CSS suivant :
.pagination li aPour mettre en œuvre l’étape 2 et collecter toutes les URL de pagination, utilisez la logique suivante :
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});Cette commande initialise une liste d’URL qui stockeront les liens de pagination, en commençant par l’URL de la première page. Elle sélectionne ensuite tous les éléments de pagination et les parcourt, en ajoutant de nouvelles URL au tableau $urls uniquement si elles ne sont pas déjà présentes. Comme les URL de la page sont relatives, elles doivent être converties en URL absolues avant d’être ajoutées à la liste.
Étant donné que la gestion de la pagination ne doit être exécutée qu’une seule fois et qu’elle n’est pas directement liée à l’extraction de données, il est préférable de l’intégrer dans une fonction :
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}Vous pouvez appeler la fonction getPaginationUrls() comme suit :
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");Après exécution, $urls contiendra toutes les URL paginées :
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)C’est parfait ! Vous venez d’implémenter le web crawling dans Goutte.
Étape 7 : Récupérer les données de toutes les pages
Maintenant que toutes les URL des pages sont stockées dans un tableau, vous pouvez les récupérer une par une :
- Itération sur la liste
- Récupération et analyse du contenu HTML pour chaque URL
- Extraction des données nécessaires
- Stockage des informations récupérées dans le tableau
$teams.
Mettre en œuvre la logique ci-dessus de la manière suivante :
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}Notez l’instruction echo qui enregistre la page sur laquelle le scraper opère. Cette information est utile pour comprendre ce que fait le script pendant son exécution.
C’est beau ! Il ne reste plus qu’à exporter les données extraites dans un format lisible par l’homme, tel que le format CSV.
Étape 8 : Exporter les données scrapées au format CSV
Pour l’instant, les données recueillies sont stockées dans le tableau $teams. Pour les rendre accessibles à d’autres équipes et faciliter leur analyse, exportez-les dans un fichier CSV.
PHP fournit un support intégré pour l’exportation CSV à travers la fonction fputcsv(). Utilisez-la pour écrire les données scannées dans un fichier nommé teams.csv comme ci-dessous :
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Mission accomplie ! Le grattoir de la Goutte est entièrement fonctionnel.
Étape n° 9 : Assembler le tout
Votre script de scraping web de la Goutte devrait maintenant contenir :
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Lancez-le avec cette commande :
php index.phpLe scraper enregistre la sortie suivante :
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...A la fin de l’exécution, un fichier teams.csv contenant ces données apparaîtra dans le dossier du projet :
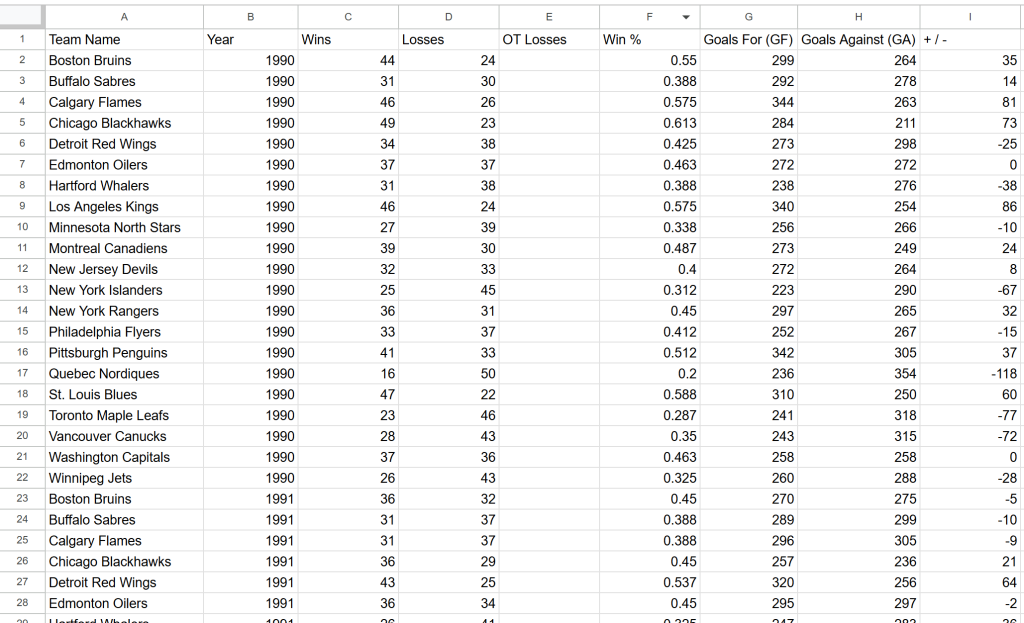
Et voilà ! Les données exactes du site cible sont désormais disponibles dans un format structuré.
Alternatives à la bibliothèque PHP Goutte pour le Web Scraping
Comme indiqué au début de cet article, Goutte est obsolète et n’est plus maintenu. Cela signifie que vous devez envisager des solutions alternatives.
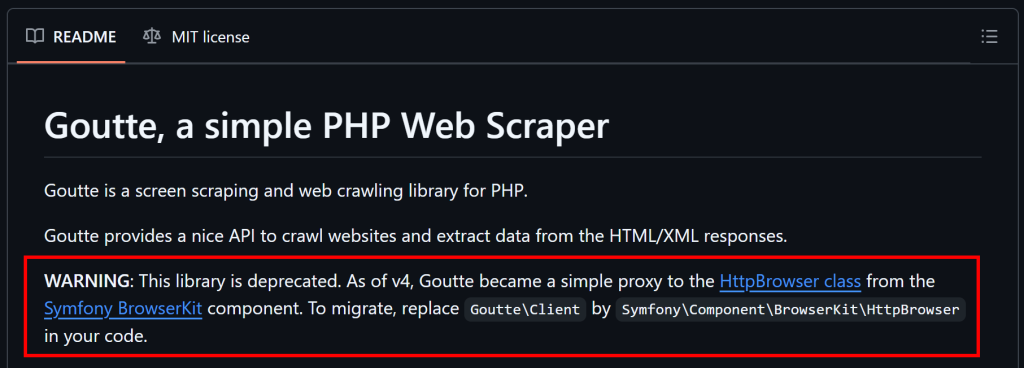
Comme expliqué sur GitHub, puisque Goutte v4 est essentiellement devenu un proxy pour la classe HttpBrowser de Symfony, vous devriez migrer vers elle. Pour ce faire, il vous suffit d’installer ces bibliothèques :
composer require symfony/browser-kit symfony/http-clientEnsuite, remplacez :
use GoutteClient;avec
use SymfonyComponentBrowserKitHttpBrowser;Enfin, supprimez Goutte en tant que dépendance dans votre projet. L’API sous-jacente reste la même, vous ne devriez donc pas avoir besoin de changer grand-chose dans votre script.
Au lieu de Goutte, vous pouvez également combiner un client HTTP avec un analyseur HTML. Quelques alternatives recommandées :
- Guzzle ou cURL pour effectuer des requêtes HTTP.
DomHTMLDocument, Simple HTML DOM Parser, ouDomCrawlerpour analyser le HTML en PHP.
Toutes ces alternatives vous offrent une plus grande flexibilité et garantissent que votre script de web scraping reste maintenable à long terme.
Limites de cette approche du Web Scraping
Goutte est un outil puissant, mais son utilisation pour le web scraping comporte plusieurs limites :
- La bibliothèque est obsolète
- Son API n’est plus maintenue
- Il est soumis à des limiteurs de taux et à des blocs anti-scraping.
- Il ne peut pas gérer les pages dynamiques qui s’appuient sur JavaScript
- La prise en charge du proxy intégré est limitée, ce qui est essentiel pour éviter les interdictions d’accès à l’Internet.
Certaines de ces limitations peuvent être atténuées par l’utilisation de bibliothèques alternatives ou d’approches différentes, comme indiqué dans notre guide sur le web scraping avec PHP. Néanmoins, vous serez toujours confronté à des mesures anti-scraping qui ne peuvent être contournées qu’à l’aide d’une API Web Unlocker.
L’API Web Unlocker est un point d’extrémité spécialisé dans le scraping, conçu pour contourner les protections anti-bots et récupérer le code HTML brut de n’importe quelle page web. Pour l’utiliser, il suffit de faire un appel à l’API et d’analyser le contenu renvoyé. Cette approche s’intègre parfaitement à Goutte (ou aux composants mis à jour de Symfony), comme démontré dans cet article.
Conclusion
Dans ce guide, vous avez exploré ce qu’est Goutte et ce qu’elle offre pour le web scraping à travers un tutoriel étape par étape. Comme cette bibliothèque est désormais obsolète, vous avez également eu l’occasion d’explorer certaines de ses alternatives.
Quelle que soit la bibliothèque de scraping PHP que vous choisissez, le plus grand défi est que la plupart des sites web protègent leurs données à l’aide de technologies anti-bot et anti-scraping. Ces mécanismes peuvent détecter et bloquer les requêtes automatisées, ce qui rend les méthodes de scraping traditionnelles inefficaces.
Heureusement, Bright Data propose une série de solutions pour éviter tout problème :
- Web Unlocker: Une API qui contourne les protections anti-scraping et fournit du HTML propre à partir de n’importe quelle page web avec un minimum d’effort.
- Navigateur de scraping: Un navigateur contrôlable basé sur le cloud avec un rendu JavaScript. Il gère automatiquement les CAPTCHA, l’empreinte du navigateur, les tentatives, etc. pour vous. Il s’intègre parfaitement à Panther ou Selenium PHP.
- API de récupération de données sur le web: Points d’extrémité pour l’accès programmatique à des données web structurées provenant de dizaines de domaines populaires.
Vous ne voulez pas vous occuper du “web scraping”, mais vous êtes toujours intéressé par les “données web en ligne” ? Découvrez nos ensembles de données prêts à l’emploi !
Inscrivez-vous à Bright Data dès maintenant et commencez votre essai gratuit pour tester nos solutions de scraping.




