

Dans ce tutoriel, vous découvrirez le Scraping web dans Laravel et apprendrez :
- Pourquoi Laravel est une excellente technologie pour le Scraping web
- Quelles sont les meilleures bibliothèques de scraping Laravel
- Comment créer une API de Scraping web Laravel à partir de zéro
C’est parti !
Est-il possible d’effectuer du Scraping web dans Laravel ?
TL;DR : Oui, Laravel est une technologie viable pour le Scraping web.
Laravel est un framework PHP puissant, connu pour sa syntaxe élégante et expressive. Il vous permet notamment de créer des API pour scraper des données sur le Web à la volée. Cela est possible grâce à la prise en charge de nombreuses bibliothèques de scraping, qui simplifient le processus d’extraction de données à partir de pages. Pour plus d’informations, consultez notre article sur le Scraping web en PHP.
Laravel est un excellent choix pour le Scraping web en raison de son évolutivité, de sa facilité d’intégration avec d’autres outils et du soutien important de sa communauté. Sa solide architecture MVC permet de garder votre logique de scraping bien organisée et facile à maintenir. Cela s’avère très utile lors de la création de projets de Scraping web complexes ou à grande échelle.
Meilleures bibliothèques de Scraping web Laravel
Voici les meilleures bibliothèques pour effectuer du Scraping web avec Laravel :
- BrowserKit: faisant partie du framework Symfony, il simule l’API d’un navigateur web pour interagir avec des documents HTML. Il s’appuie sur
DomCrawlerpour naviguer et extraire des documents HTML. Cette bibliothèque est idéale pour extraire des données de pages statiques en PHP. - HttpClient: composant Symfony permettant d’envoyer des requêtes HTTP. Il s’intègre parfaitement à
BrowserKit. - Guzzle: un client HTTP robuste pour envoyer des requêtes web aux serveurs et traiter efficacement les réponses. Il est utile pour récupérer les documents HTML associés aux pages web. Apprenez à configurer un Proxy dans Guzzle.
- Panther: un composant Symfony qui fournit un navigateur sans interface graphique pour le Scraping web. Il vous permet d’interagir avec des sites dynamiques qui nécessitent JavaScript pour le rendu ou l’interaction.
Prérequis
Pour suivre ce tutoriel sur le Scraping web dans Laravel, vous devez remplir les conditions préalables suivantes :
Un IDE pour coder en PHP est également recommandé. Visual Studio Code avec l’extension PHP ou WebStorm sont deux excellentes solutions.
Comment créer une API de Scraping web dans Laravel
Dans cette section étape par étape, vous verrez comment créer une API de Scraping web Laravel. Le site cible sera le site sandbox Quotes scraping, et le point de terminaison du scraping sera :
- Sélectionner les éléments HTML des citations sur la page
- Extraire les données de ces éléments
- Renvoyer les données scrapées au format JSON
Voici à quoi ressemble le site cible :

Suivez les instructions ci-dessous et apprenez à effectuer du Scraping web dans Laravel !
Étape 1 : Configurez un projet Laravel
Ouvrez le terminal. Ensuite, lancez la commande Composer create-command ci-dessous pour initialiser votre application de Scraping web Laravel :
composer create-project laravel/laravel laravel-ScraperLe dossier lavaral-scraper contient désormais un projet Laravel vierge. Chargez-le dans votre IDE PHP préféré.
Voici la structure des fichiers de votre backend actuel :
Parfait ! Vous disposez désormais d’un projet Laravel.
Étape 2 : Initialisez votre API de scraping
Lancez la commande Artisan ci-dessous dans le répertoire du projet pour ajouter un nouveau contrôleur Laravel :
php artisan make:controller HelloWorldControllerCela créera le fichier ScrapingController.php suivant dans le répertoire /app/Http/Controllers:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
class ScrapingController extends Controller
{
//
}Dans le fichier ScrapingController, ajoutez la méthode scrapeQuotes() suivante :
public function scrapeQuotes(): JsonResponse
{
// logique de scraping...
return response()->json('Hello, World!');
}Actuellement, la méthode renvoie un message JSON « Hello, World! » ( Bonjour, le monde ! ) servant de substitut. Bientôt, elle contiendra une logique de scraping dans Laravel.
N’oubliez pas d’ajouter l’importation suivante :
use IlluminateHttpJsonResponse;Associez la méthode scrapeQuotes() à un point de terminaison dédié en ajoutant les lignes suivantes à routes/api.php:
use AppHttpControllersScrapingController;
Route::get('/v1/scraping/scrape-quotes', [ScrapingController::class, 'scrapeQuotes']);Parfait ! Il est temps de vérifier que l’API de scraping Laravel fonctionne comme prévu. N’oubliez pas que les API Laravel sont disponibles sous le chemin /api. Le point de terminaison API complet est donc /api/v1/scraping/scrape-quotes.
Lancez votre application Laravel à l’aide de la commande suivante :
php artisan serveVotre serveur devrait maintenant être à l’écoute localement sur le port 8000.
Utilisez cURL pour envoyer une requête GET au point de terminaison /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Remarque: sous Windows, remplacez curl par curl.exe. Pour en savoir plus, consultez notre guide cURL pour le Scraping web.
Vous devriez obtenir la réponse suivante :
« Hello, World! »Fantastique ! L’API d’échantillonnage fonctionne à merveille. Il est temps de définir une logique d’échantillonnage avec Laravel.
Étape 3 : Installez les bibliothèques de scraping
Avant d’installer des paquets, vous devez déterminer quelles bibliothèques de Scraping web Laravel correspondent le mieux à vos besoins. Pour ce faire, ouvrez le site cible dans votre navigateur. Cliquez avec le bouton droit de la souris sur la page et sélectionnez « Inspecter » pour ouvrir les outils de développement. Ensuite, allez dans l’onglet « Réseau », rechargez la page et accédez à la section « Fetch/XHR » :
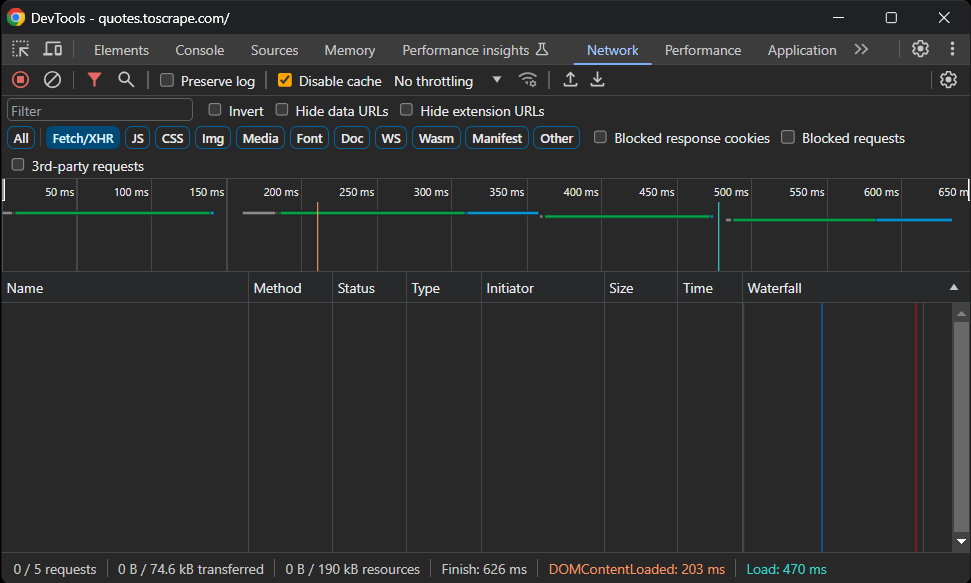
Comme vous pouvez le constater, la page web n’effectue aucune requête AJAX. Cela signifie qu’elle ne charge pas dynamiquement les données côté client. Il s’agit donc d’une page statique dont toutes les données sont intégrées dans les documents HTML.
Comme la page est statique, vous n’avez pas besoin d’une bibliothèque de navigateur sans interface graphique pour la scraper. Vous pourriez toujours utiliser un outil d’automatisation de navigateur, mais cela ne ferait qu’ajouter une charge inutile. L’approche recommandée consiste à utiliser les composants BrowserKit et HttpClient de Symfony.
Ajoutez les composants symfony/browser-kit et symfony/http-client aux dépendances de votre projet avec :
composer require symfony/browser-kit symfony/http-clientBravo ! Vous disposez désormais de tout ce dont vous avez besoin pour effectuer le scraping de données dans Laravel.
Étape 4 : Télécharger la page cible
Importez BrowserKit et HttpClient dans ScrapingController:
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;Dans scrapeQuotes(), initialisez un nouvel objet HttpBrowser:
$browser = new HttpBrowser(HttpClient::create());Cela vous permet d’effectuer des requêtes HTTP en simulant le comportement d’un navigateur. Dans le même temps, n’oubliez pas que cela n’exécute pas les requêtes dans un navigateur réel. HttpBrowser fournit simplement des fonctionnalités similaires à celles d’un navigateur, telles que la gestion des cookies et des sessions.
Utilisez la méthode request() pour effectuer une requête HTTP GET vers l’URL de la page cible :
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');Le résultat sera un objet Crawler, qui effectue automatiquement l’analyse du document HTML renvoyé par le serveur. Cette classe fournit également des capacités de sélection de nœuds et d’extraction de données.
Vous pouvez vérifier que la logique ci-dessus fonctionne en extrayant le HTML de la page à partir du crawler :
$html = $crawler->outerHtml();Pour le test, faites en sorte que votre API renvoie ces données.
Votre fonction scrapeQuotes() ressemblera désormais à ceci :
public function scrapeQuotes(): JsonResponse
{
// initialiser un client HTTP de type navigateur
$browser = new HttpBrowser(HttpClient::create());
// télécharger et analyser le code HTML de la page cible
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// récupérer le code HTML externe de la page et le renvoyer
$html = $crawler->outerHtml();
return response()->json($html);
}Incroyable ! Votre API renverra désormais :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citations à extraire</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<!-- omis pour plus de concision ... -->Étape 5 : Inspecter le contenu de la page
Pour définir la logique d’extraction des données, il est essentiel d’examiner la structure HTML de la page cible.
Ouvrez donc Quotes To Scrape dans votre navigateur. Cliquez ensuite avec le bouton droit sur un élément HTML de citation et sélectionnez l’option « Inspecter ». Dans les outils de développement de votre navigateur, développez le code HTML et commencez à l’étudier :
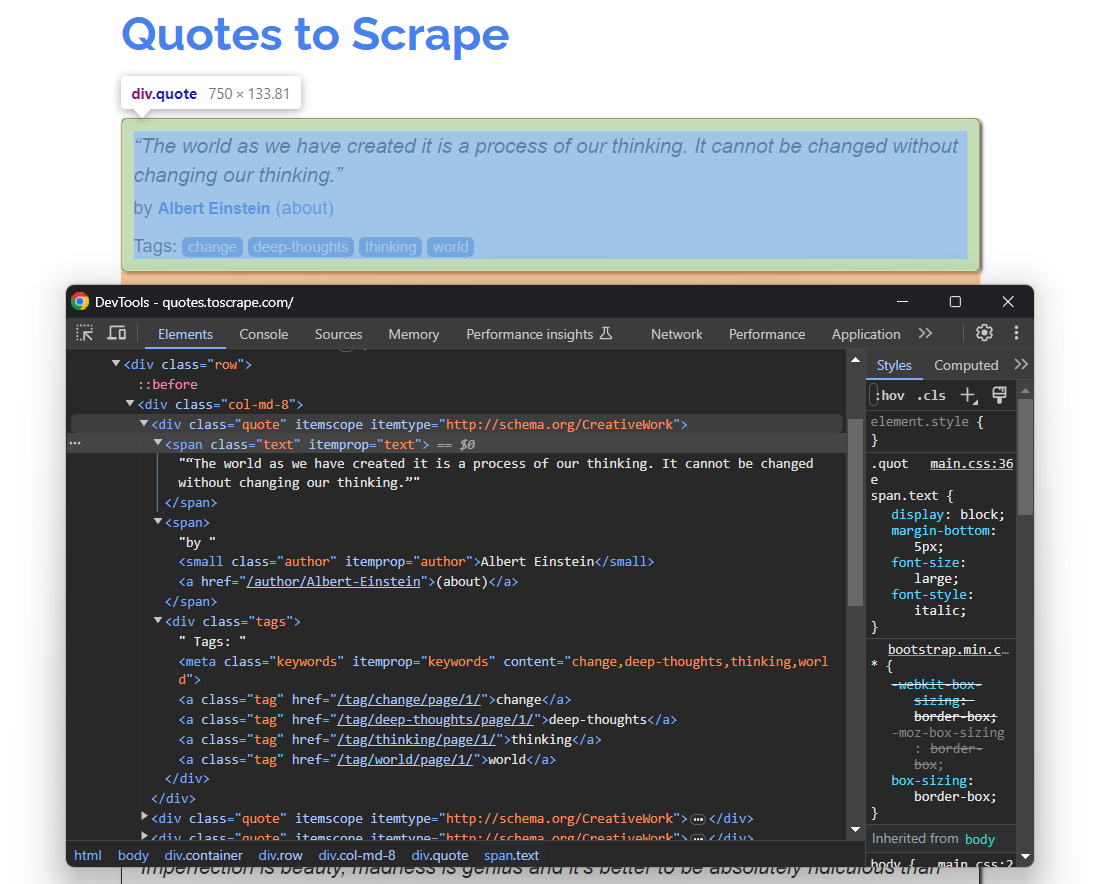
Ici, remarquez que chaque carte de citation est un nœud HTML .quote qui contient :
- Un élément
.textavec le texte de la citation - Un nœud
.authoravec le nom de l’auteur - De nombreux éléments
.tag, chacun affichant une seule balise
Avec les sélecteurs CSS ci-dessus, vous avez tout ce dont vous avez besoin pour effectuer du Scraping web dans Laravel. Utilisez ces sélecteurs pour cibler les éléments DOM qui vous intéressent et en extraire les données dans les étapes suivantes !
Étape 6 : Préparez-vous à effectuer le Scraping web
Comme la page cible contient plusieurs citations, créez une structure de données dans laquelle stocker les données extraites. Un tableau sera idéal :
quotes = []Ensuite, utilisez la méthode filter() de la classe Crawler pour sélectionner tous les éléments de citation :
$quote_html_elements = $crawler->filter('.quote');Cela renvoie tous les nœuds DOM de la page qui correspondent au sélecteur CSS .quote spécifié.
Ensuite, parcourez-les et préparez-vous à appliquer la logique d’extraction de données à chacun d’entre eux :
foreach ($quote_html_elements as $quote_html_element) {
// créer un nouveau crawler de citations
$quote_crawler = new Crawler($quote_html_element);
// logique de scraping...
}Notez que les objets DOMNode renvoyés par filter() ne fournissent pas de méthodes pour la sélection des nœuds. Vous devez donc créer une instance Crawler locale limitée à votre élément HTML quote spécifique.
Pour que le code ci-dessus fonctionne, ajoutez l’importation suivante :
use SymfonyComponentDomCrawlerCrawler;Vous n’avez pas besoin d’installer manuellement le package DomCrawler. En effet, il s’agit d’une dépendance directe du composant BrowserKit.
Super ! Vous avez fait un pas de plus vers votre objectif de Scraping web Laravel.
Étape 7 : implémenter le scraping des données
À l’intérieur de la boucle foreach:
- Extrayez les données qui vous intéressent des éléments
.text,.authoret.tag - Remplissez un nouvel objet
$quoteavec ces données - Ajoutez le nouvel objet
$quoteà$quotes
Commencez par sélectionner l’élément .text à l’intérieur de l’élément HTML quote. Utilisez ensuite la méthode text() pour en extraire le texte interne :
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();Notez que chaque citation est encadrée par les caractères spéciaux u201c et u201d. Vous pouvez les supprimer à l’aide de la fonction PHP str_replace() comme suit :
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);De même, récupérez les informations sur l’auteur avec :
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();L’extraction des balises peut s’avérer un peu plus difficile. Étant donné qu’une seule citation peut comporter plusieurs balises, vous devez définir un tableau et extraire chaque balise individuellement :
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}Notez que les éléments DOMNode renvoyés par filter() n’exposent pas la méthode text(). De manière équivalente, ils fournissent l’attribut textContent.
Voici à quoi ressemblera l’ensemble de la logique de scraping des données Laravel :
// créer un nouveau crawler de citations
$quote_crawler = new Crawler($quote_html_element);
// exécuter la logique d'extraction de données
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// supprimer les caractères spéciaux des informations textuelles brutes
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}Et voilà ! Vous êtes presque arrivé au but.
Étape 8 : renvoyer les données extraites
Créez un objet $quote avec les données récupérées et ajoutez-le à $quotes:
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
$quotes[] = $quote;Ensuite, mettez à jour les données de réponse de l’API avec la liste $quotes:
return response()->json(['quotes' => $quotes]);À la fin de la boucle de scraping, $quotes contiendra :
array(10) {
[0]=>
array(3) {
["text"]=>
string(113) « Le monde tel que nous l'avons créé est le résultat de notre pensée. Il ne peut être changé sans changer notre façon de penser. »
["author"]=>
string(15) « Albert Einstein »
["tags"]=>
array(4) {
[0]=>
string(6) "change"
[1]=>
string(13) "deep-thoughts"
[2]=>
string(8) "thinking"
[3]=>
string(5) "world"
}
}
// omis pour plus de concision...
[9]=>
tableau(3) {
["texte"]=>
chaîne(48) "Une journée sans soleil, c'est comme, vous savez, la nuit."
["author"]=>
string(12) "Steve Martin"
["tags"]=>
array(3) {
[0]=>
string(5) "humour"
[1]=>
string(7) "évident"
[2]=>
string(6) "comparaison"
}
}
}Super ! Ces données seront ensuite sérialisées en JSON et renvoyées par l’API de scraping Laravel.
Étape 9 : Assemblez le tout
Voici le code final du fichier ScrapingController dans Laravel :
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateHttpJsonResponse;
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class ScrapingController extends Controller
{
public function scrapeQuotes(): JsonResponse
{
// initialise un client HTTP similaire à un navigateur
$browser = new HttpBrowser(HttpClient::create());
// télécharge et analyse le code HTML de la page cible
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// où stocker les données extraites
$quotes = [];
// sélectionner tous les éléments HTML de citation sur la page
$quote_html_elements = $crawler->filter('.quote');
// itérer sur chaque élément HTML de citation et appliquer
// la logique d'extraction
foreach ($quote_html_elements as $quote_html_element) {
// créer un nouveau crawler de citation
$quote_crawler = new Crawler($quote_html_element);
// exécuter la logique d'extraction des données
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// supprimer les caractères spéciaux des informations textuelles brutes
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}
// créer un nouvel objet citation
// avec les données récupérées
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
// ajouter l'objet citation au tableau citations
$quotes[] = $quote;
}
var_dump($quotes);
return response()->json(['quotes' => $quotes]);
}
}Il est temps de le tester !
Démarrez votre serveur Laravel :
php artisan serveEnsuite, effectuez une requête GET vers le point de terminaison /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Vous obtiendrez le résultat suivant :
{
"quotes": [
{
"text": "Le monde tel que nous l'avons créé est le fruit de notre pensée. Il ne peut être changé sans changer notre façon de penser.",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
// omis pour plus de concision...
{
"text": "Une journée sans soleil, c'est comme, vous savez, la nuit.",
"author": "Steve Martin",
"tags": [
"humour",
"évidence",
"comparaison"
]
}
]
}Et voilà ! En moins de 100 lignes de code, vous venez de réaliser du Scraping web dans Laravel.
Prochaines étapes
L’API que vous avez créée ici n’est qu’un exemple basique de ce que vous pouvez réaliser avec Laravel en matière de Scraping web. Pour faire passer votre projet au niveau supérieur, envisagez les améliorations suivantes :
- Implémentez le crawling web: le site cible contient plusieurs citations réparties sur plusieurs pages. Il s’agit d’un scénario courant qui nécessite le crawling web pour une récupération complète des données. Lisez notre article sur la définition d’un crawler web.
- Planifiez votre tâche de scraping: ajoutez un planificateur pour appeler votre API à intervalles réguliers, stockez les données dans une base de données et assurez-vous de toujours disposer de données à jour.
- Intégrez un Proxy: effectuer plusieurs requêtes à partir de la même adresse IP peut entraîner un blocage par des mesures anti-scraping. Pour éviter cela, envisagez d’intégrer des Proxys résidentiels dans votre Scraper PHP.
Veillez à ce que vos opérations de Scraping web Laravel restent éthiques et respectueuses
Le Scraping web est un moyen efficace de collecter des données précieuses à des fins diverses. Cependant, l’objectif est de récupérer des données de manière responsable, sans nuire au site cible. Il est donc important d’aborder le Scraping web avec les précautions qui s’imposent.
Suivez ces conseils pour garantir un Scraping web Kotlin responsable :
- Vérifiez et respectez les conditions d’utilisation du site: avant de scraper un site, consultez ses conditions d’utilisation. Celles-ci comprennent souvent des informations sur les droits d’auteur, les droits de propriété intellectuelle et les directives d’utilisation de leurs données.
- Respectez le fichier robots.txt: le fichier robots.txt d’un site définit les règles d’accès à ses pages par les robots d’indexation automatisés. Pour respecter les pratiques éthiques, adhérez à ces directives. Pour en savoir plus, consultez notre guide robots.txt pour le Scraping web.
- Ciblez uniquement les informations accessibles au public: concentrez-vous sur les données accessibles au public. Évitez de scraper des pages protégées par des identifiants de connexion ou d’autres formes d’autorisation. Cibler des données privées ou sensibles sans autorisation appropriée est contraire à l’éthique et peut entraîner des conséquences juridiques.
- Limitez la fréquence de vos requêtes: effectuer trop de requêtes en peu de temps peut surcharger le serveur, ce qui affecte les performances du site pour tous les utilisateurs. Cela peut également déclencher des mesures de limitation du débit et vous faire bloquer. Évitez de saturer le serveur cible en ajoutant des délais aléatoires entre vos requêtes.
- Utilisez des outils de scraping fiables et à jour: privilégiez les fournisseurs réputés et optez pour des outils bien entretenus et régulièrement mis à jour. Vous aurez ainsi la garantie qu’ils sont conformes aux dernières pratiques éthiques en matière de scraping Laravel. Si vous avez des doutes, consultez notre article sur la manière de choisir le meilleur service de Scraping web.
Conclusion
Dans ce guide, vous avez découvert pourquoi Laravel est un bon framework pour créer des API de Scraping web. Vous avez également eu l’occasion d’explorer certaines de ses meilleures bibliothèques de Scraping web. Ensuite, vous avez appris à créer une API de Scraping web Laravel qui extrait les données d’une page cible à la volée. Comme vous l’avez vu, le Scraping web avec Laravel est simple et ne nécessite que quelques lignes de code.
Le problème est que la plupart des sites protègent leurs données à l’aide de solutions anti-bot et anti-scraping. Ces technologies peuvent détecter et bloquer vos requêtes automatisées. Heureusement, Bright Data propose un ensemble de solutions pour faciliter le scraping :
- Navigateur de scraping: un navigateur contrôlable basé sur le cloud qui offre des capacités de rendu JavaScript tout en gérant les CAPTCHA, les empreintes digitales du navigateur, les réessais automatisés, etc. Il s’intègre aux bibliothèques de navigateurs d’automatisation les plus populaires, telles que Playwright et Puppeteer.
- Web Unlocker: une API de déverrouillage qui peut renvoyer de manière transparente le code HTML propre de n’importe quelle page, contournant ainsi toutes les mesures anti-scraping.
- Scraping web: pointsde terminaison pour l’accès programmatique à des données web structurées provenant de dizaines de domaines populaires.
Vous ne voulez pas vous occuper du Scraping web, mais vous êtes toujours intéressé par les données en ligne ? Découvrez les Jeux de données prêts à l’emploi de Bright Data !
Inscrivez-vous dès maintenant et commencez votre essai gratuit.





