

Le scraping web est le processus qui consiste à extraire du contenu et des données de sites web à l’aide de scripts ou d’outils logiciels automatisés. Les informations extraites sont ensuite généralement exportées vers un format plus utile, tel qu’un fichier brut ou CSV, pour faciliter leur utilisation.
Si vous cherchez à simplifier vos workflows de Scraping web,Google Sheetsest là pour vous aider. Il s’agit d’un outil de gestion de données très populaire, idéal pour extraire des données structurées ou tabulaires à partir de sites web et pour analyser ou visualiser vos données. Vous pouvez par exemple l’utiliser pour extraire les détails et les prix des produits à partir de sites de commerce électronique ou pour récupérer les coordonnées à partir d’annuaires professionnels. Il est également utile pour suivre l’engagement sur les réseaux sociaux ou pour effectuer des analyses de l’opinion publique afin de mesurer l’efficacité des campagnes.
Dans ce tutoriel, vous apprendrez à configurer et à utiliser Google Sheets pour le Scraping web.
Configurer vos Google Sheets
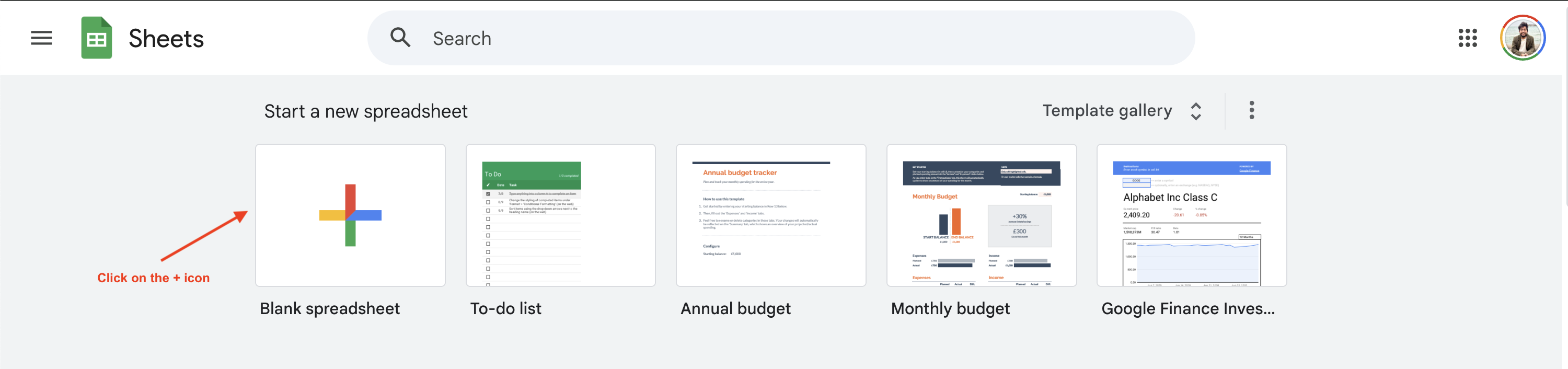
Pour commencer le Scraping web avec Google Sheets, vous devez créer une nouvelle feuille Google Sheet en vous rendant surhttps://sheets.google.comet en cliquant sur le bouton+:
Ce tutoriel montre comment extraire les informations sur les prix des livres à partir dusite webBooks to Scrape, mais vous pouvez utiliser un autre site web en modifiant l’URL et les requêtes suivantes.
Comprendre les formules de Google Sheets
Google Sheets prend en chargedenombreusesformules de cellulequi peuvent être utilisées pour diverses opérations, y compris le Scraping web. Voyons comment certaines de ces formules fonctionnent.
IMPORTXML
La fonctionIMPORTXMLvous permet d’interroger et d’importer des données structurées dans Google Sheets. Elle prend en charge les formats de fichiers XML, HTML, CSV et TSV. La syntaxe de la fonction est la suivante :
=IMPORTXML(url, xpath_query)
La fonction importe les données à partir de l’URL Web spécifiée et utilise le localisateurXPathpour trouver l’élément pertinent sur la page Web. Par exemple, vous pouvez extraire le titreH1du site WebBooks to Scrapeen ajoutant la formule suivante dans une cellule Google Sheets :
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")
Lors de la première utilisation, Google Sheets vous invite à autoriser l’accès avant de récupérer des données à partir de sites Web tiers :
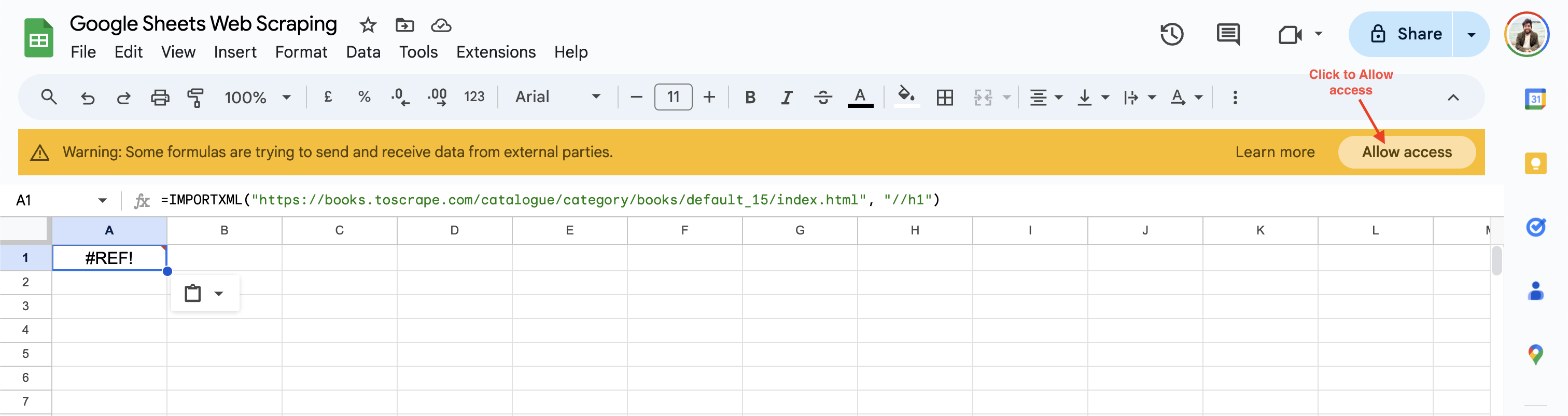
Une fois que vous avez cliqué sur Autoriser l’accès, Google Sheets attribue à la cellule la valeur de l’en-tête H1 de la page Web par défaut.
IMPORTHTML
La fonction IMPORTHTML vous permet d’importer des données à partir d’un tableau ou d’une liste sur une page HTML. La syntaxe de la fonction est la suivante :
=IMPORTHTML(url, requête, index)
Cette fonction importe les données de l'URL vers la feuille en fonction de la requête spécifiée. L’attribut query peut être défini sur une liste ou un tableau en fonction du type de données que vous souhaitez importer. L'index commence à 1 et détermine le tableau ou la liste à importer. Par exemple, vous pouvez récupérer la liste des livres de Books to Scrape à l’aide de cette formule :
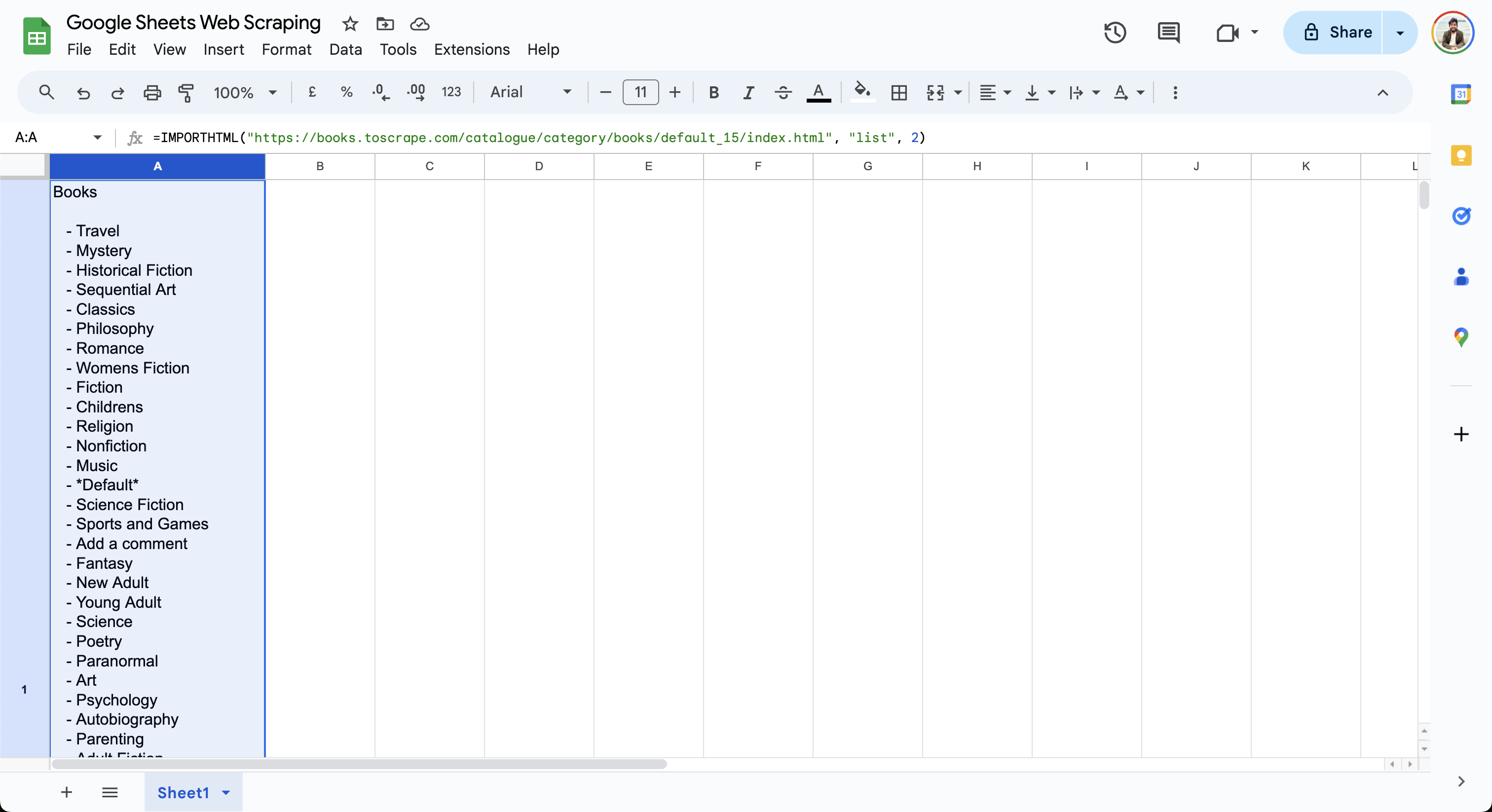
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)
Cette formule affiche la liste des livres dans la cellule actuelle, comme indiqué ici :
Comme vous pouvez le constater, les formulesIMPORTXMLetIMPORTHTMLsont faciles à utiliser et vous permettent de commencer à extraire des données d’une page web à l’aide de requêtes simples. Pour des cas d’utilisation plus complexes, consultez ce guide qui explique comment utiliser VBA et Selenium pour le Scraping web dans Excel.
Extraction de données à l’aide de la fonction IMPORTXML
Dans la section précédente, vous avez appris l’utilisation de basede la fonction IMPORTXMLpour récupérer les titres des pages en spécifiant l’attribut XPath correspondant. L’attribut XPath est très puissant et vous permet d’accéder à n’importe quel élément d’une page Web, quelle que soit sa hiérarchie. Dans la section suivante, vous utiliserezla fonction IMPORTXMLpour récupérer le titre, le prix et la note de tous les livres figurant surlapage WebBooks to Scrape.
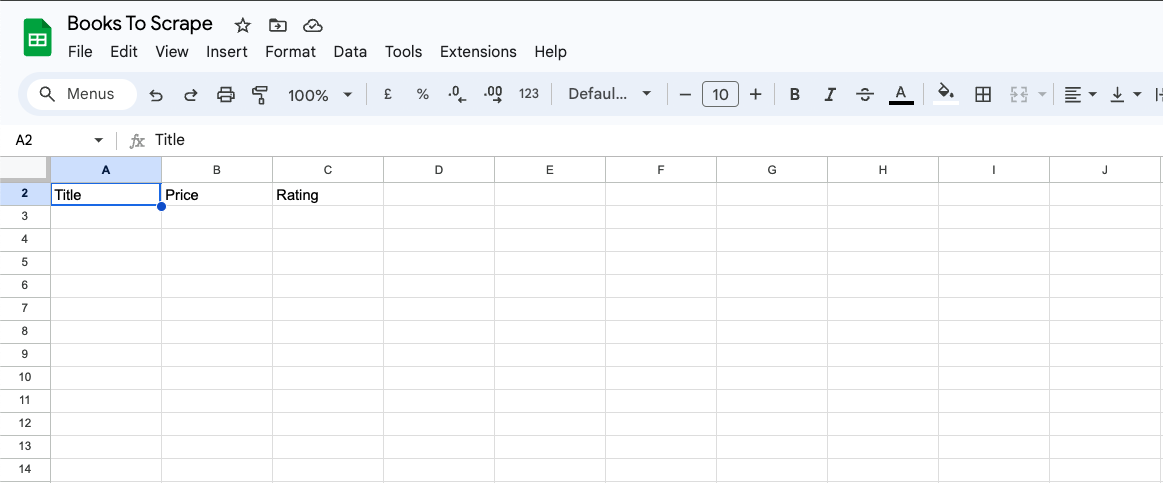
Pour commencer, ajoutez les colonnes Titre, Prix et Note dans Google Sheets :
Pour récupérer le titre du livre à partir de Books to Scrape, vous avez besoin de son emplacement XPath, que vous pouvez trouver à l’aide de l’outil Inspecter du navigateur. Pour trouver le XPath du titre du livre, cliquez avec le bouton droit de la souris sur le titre du premier livre et cliquez sur Inspecter. Cliquez ensuite sur Copier > XPath pour copier son localisateur XPath :
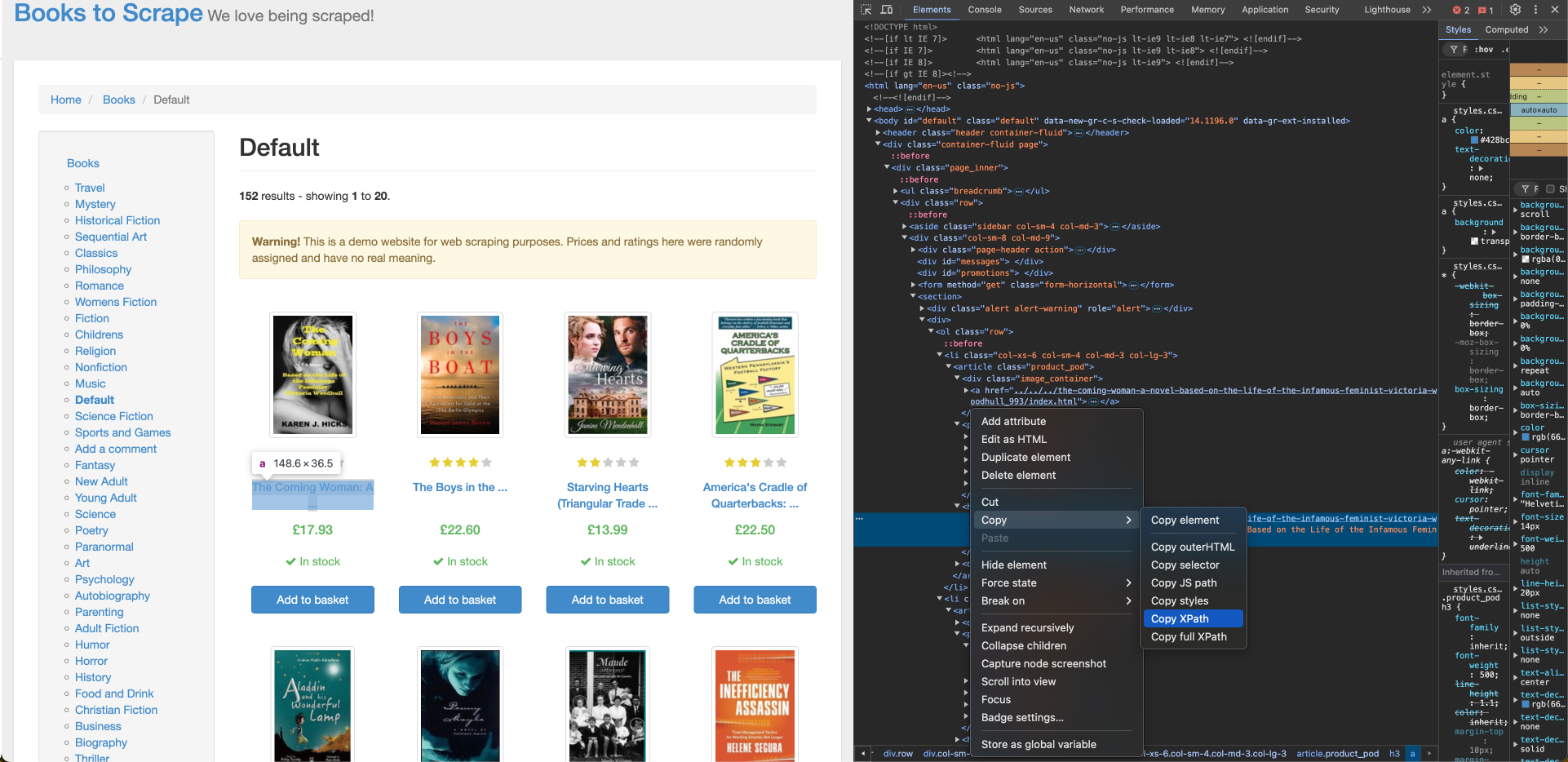
Le XPath du titre du premier livre correspond à une balise d’ancrage (a) et ressemble à ceci :
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a
Vous devez apporter quelques modifications au XPath afin de vous assurer que le titre du livre est correctement importé pour tous les livres de la liste :
- Le XPath contient
li[1]dans le chemin, indiquant que le premier livre est sélectionné. Remplacez-le parlipour récupérer tous les éléments. - Le contenu interne de la balise
acontient un titre de livre tronqué, mais la baliseacontient un attributtitleavec le titre complet du livre. Modifiez leadans le XPath ena/@titlepour utiliser l’attribut title. - Remplacez toutes les guillemets doubles dans le XPath par des guillemets simples pour éviter les problèmes d’échappement dans la formule.
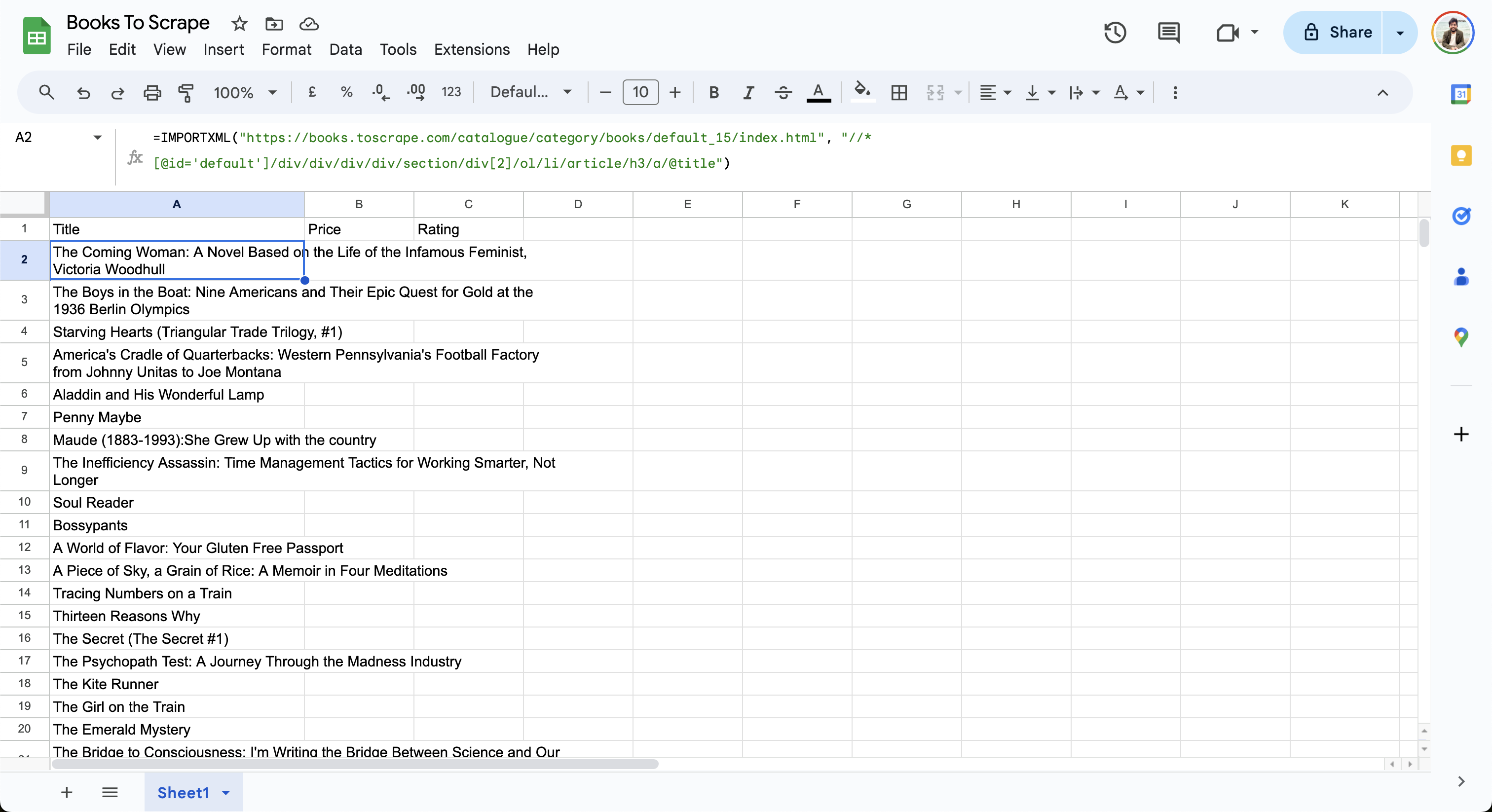
Une fois que vous avez ajusté le XPath, ajoutez la formule suivante avec le XPath mis à jour dans la cellule A2 de votre feuille Google Sheet :
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")
La feuille importe les données de la page Web et met à jour les lignes comme suit :
Ensuite, construisez le XPath pour le prix et ajoutez-le à la cellule B2 dans la feuille Google Sheet :
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")
Enfin, recherchez le chemin XPath pour la note et ajoutez-le à la cellule C2 dans la feuille Google Sheet :
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")
Les données finales dans la feuille se présentent comme suit :
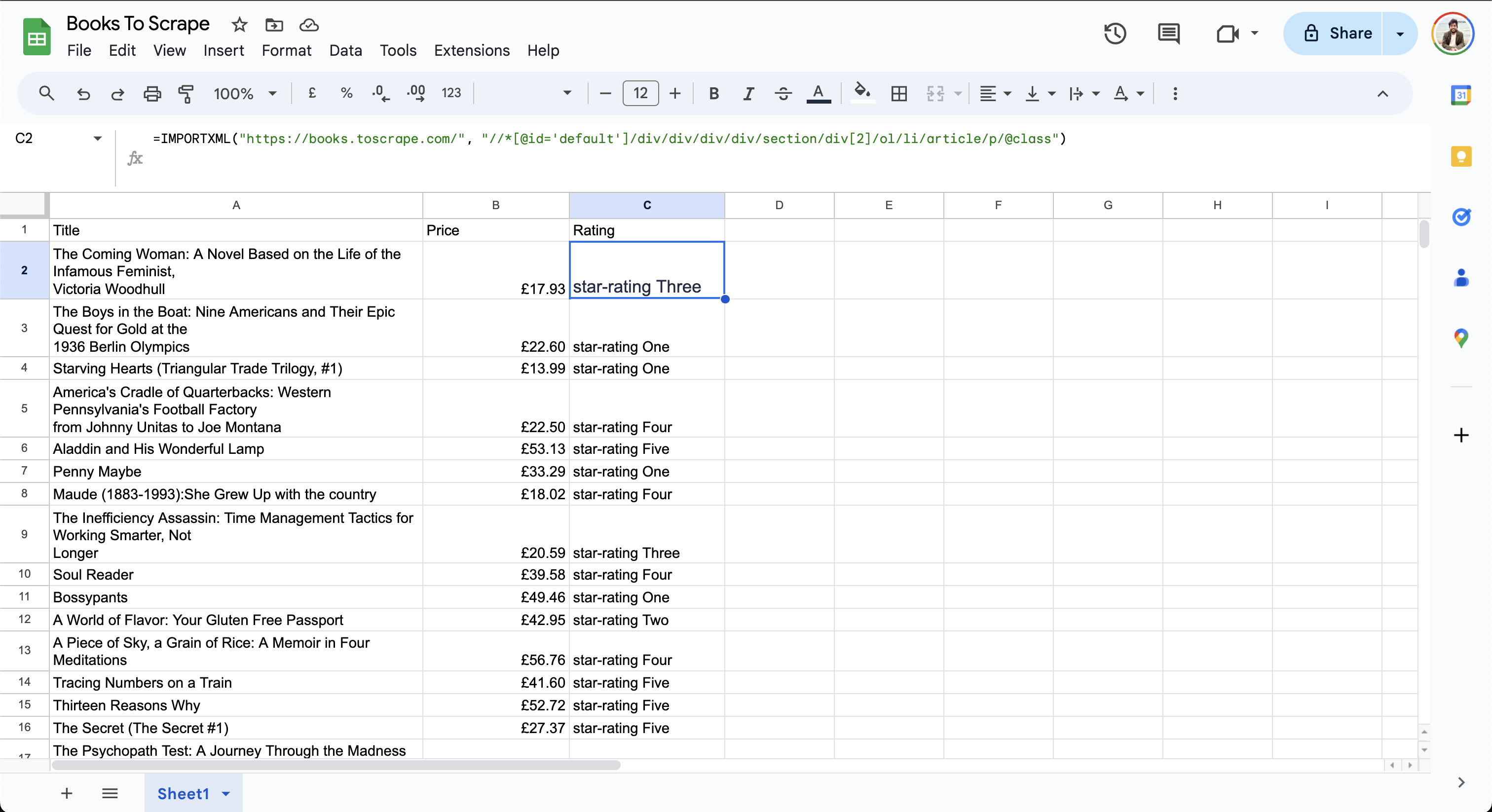
Notez que la colonne« Note »afficheune note de trois étoilesouune note de quatre étoiles. Étant donné queXPath 2.0n’est pas encore pris en charge par Google Sheets, vous ne pouvez pas manipuler les données pour simplifier le résultat.
Gestion des pages Web complexes
Bien que Google Sheets soit bien adapté aux tâches de scraping simples, le scraping peut devenir difficile si le site web cible contient du contenu dynamique et une pagination ou s’il nécessite des interactions par clic. Par exemple, si votre page web charge du contenu de manière asynchrone à l’aide de JavaScript, les formulesIMPORTXMLetIMPORTHTMLde Google Sheets ne peuvent pas en extraire les données, car elles ne prennent en charge que les pages web statiques. De même, si le contenu repose sur des interactions de l’utilisateur telles que des clics, des saisies ou des défilements, ces formules ne pourront pas extraire les données. Si vous souhaitez extraire du contenu dynamique, vous pouvez écrire un script qui utilise un navigateur sans interface graphique tel que Selenium.
Google Sheets ne peut pas non plus gérer automatiquement les tâches d’extraction paginées. Bien que vous puissiez ajouter manuellement la formule IMPORTXML après la dernière ligne avec une URL mise à jour, cette méthode n’est pas évolutive, car elle nécessite de répéter le processus pour chaque page.
Si vous recherchez des cas d’utilisation plus avancés, tels que la gestion de contenu dynamique ou de grands volumes de données, envisagez d’utiliser les produits Bright Data pour une extraction de données efficace. Bright Data fournit une API de Scraping web unifiée pour toutes les tâches d’extraction de données et gère en arrière-plan les complexités des Proxys, des CAPTCHA et des agents utilisateurs. Son API gère les requêtes en masse, l’analyse et la validation, ce qui vous permet de déployer et de mettre à l’échelle plus rapidement. De plus, elle fournit une vaste collection de Jeux de données préconstruitsprovenant de sites web populaires, tels queLinkedInetZillow, qui peuvent être intégrés à vos flux de travail existants, ce qui réduit les tracas liés à la maintenance des scripts de scraping.
Automatisation de l’actualisation des données dans Google Sheets
Pour certaines tâches de scraping, telles que le suivi des prix ou de l’engagement sur les réseaux sociaux, vous devez actualiser automatiquement les données scrapées à intervalles réguliers afin de vous assurer d’avoir accès à des données précises pour l’analyse et la prise de décision.
Pour définir l’intervalle de calcul dans Google Sheets, il vous suffit de cliquer sur Fichier > Paramètres et d’accéder à l’onglet Calcul:
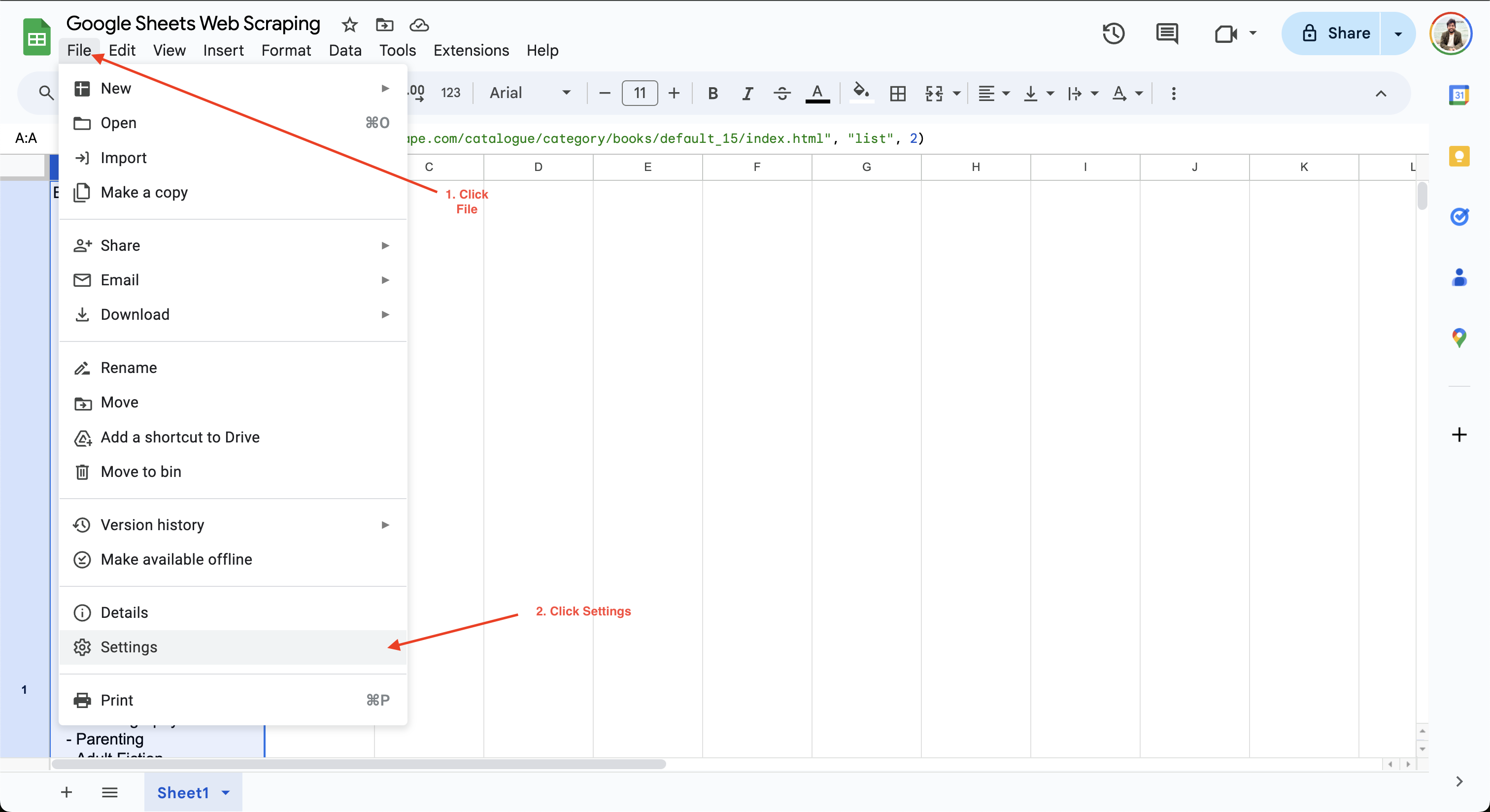
Vous pouvez ensuite mettre à jour l’intervalle de calcul à une minute ou une heure. Par exemple, ici, le paramètre Recalculer est mis à jour sur À chaque modification et toutes les minutes afin de garantir que les données sont automatiquement actualisées toutes les minutes :
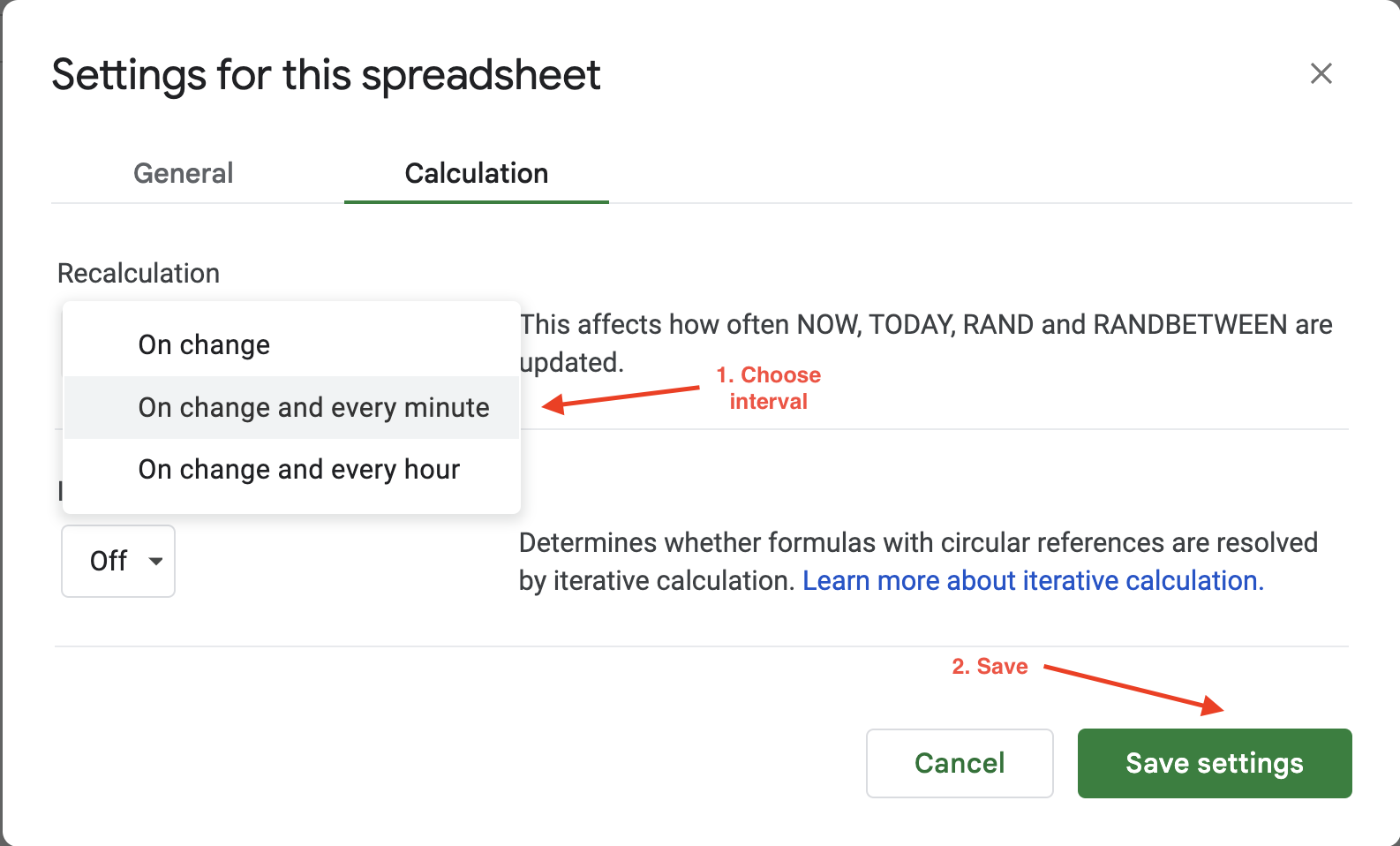
Les options de rafraîchissement automatique de Google Sheets offrent une flexibilité limitée pour configurer la fréquence ou les déclencheurs de rafraîchissement, car vous ne pouvez choisir qu’entre deux valeurs : toutes les heures ou toutes les minutes. Si vous recherchez plus de flexibilité, Bright Data propose des ensembles de données propres, validés et à jour dans plusieurs formats de fichiers, tels que JSON, CSV et Parquet. Il est donc idéal pour les tâches de scraping à grande échelle qui nécessiteraient autrement la maintenance d’une vaste infrastructure.
Mise en œuvre des meilleures pratiques et dépannage
Si vous souhaitez améliorer l’efficacité de votre scraping, veillez à être sélectif quant aux données que vous extrayez. Essayer de scraper des données inutiles peut ralentir votre processus et augmenter la charge sur le site web cible.
Si vous souhaitez extraire de grands volumes de données, ajoutez des délais artificiels entre les requêtes et envisagez d’exécuter les tâches pendant les heures creuses afin de vous assurer que le site web n’est pas surchargé par un trafic inattendu. Un trafic important peut entraîner des interdictions d’IP ou des limitations de débit, vous empêchant de poursuivre votre tâche d’extraction. Apprenez-en davantage sur l’extraction de sites web sans être bloqué.
Outre les interdictions d’IP, la présentation d’undéfi CAPTCHAaux utilisateurs est une autre technique anti-bot couramment utilisée par les sites web pour restreindre l’accès au contenu jusqu’à ce que l’utilisateur vérifie qu’il est bien humain. Envisagez d’utiliser lesProxys résidentiels Bright Datapour les tâches de scraping avancées qui bénéficieraient de la rotation des IP et des solveurs CAPTCHA automatiques.
Avant de scraper des données, vous devez également consulter les conditions d’utilisation du site web afin de vous assurer de leur conformité. Vos scripts doivent suivre les instructionsdu fichier robot.txtpour interagir avec le site web. Consultezce guidepour en savoir plus sur l’utilisation des règlesrobot.txtpour le Scraping web.
Conclusion
Google Sheets est bien adapté au scraping de données provenant de sites web statiques qui ne comportent pas de contenu dynamique, d’éléments cachés ou de pagination. Dans cet article, vous avez appris à automatiser facilement les tâches d’extraction de données à l’aide des formules IMPORTXML et IMPORTHTML sans avoir besoin d’expérience préalable en matière de script.
Pour les tâches de scraping complexes qui impliquent du contenu dynamique ou de grands volumes de données,Bright Datafournit des API faciles à utiliser, flexibles, évolutives et performantes pour le scraping web dans différents formats, notamment JSON, CSV ou NDJSON. En coulisses, il gère les complexités du scraping en s’occupant de la rotation des adresses IP et des agents utilisateurs, des CAPTCHA et du contenu dynamique. Si vous êtes prêt à passer au niveau supérieur en matière de Scraping web, pensez à essayer la meilleure API Web Scraper.
Inscrivez-vous dès aujourd’hui pour un essai gratuit et commencez à optimiser vos flux de données !





