

Dans cet article, vous apprendrez :
- Qu’est-ce que le Scraping web avec Camoufox et comment cela réduit la détection des bots basée sur les empreintes digitales.
- Comment configurer Camoufox avec les Proxys résidentiels Bright Data pour une extraction de données fiable.
- Dans quels cas Camoufox est performant, dans quels cas il échoue à grande échelle et quand passer au Navigateur de scraping ou au Web Unlocker de Bright Data pour une utilisation en production.
Qu’est-ce que Camoufox ? Aperçu de ses principales fonctionnalités

Camoufox est un navigateur anti-détection open source basé sur une version modifiée de Firefox. Il est conçu pour l’automatisation des navigateurs et les scénarios de Scraping web où les navigateurs headless standard sont facilement identifiés et bloqués.
Camoufox se concentre sur la réduction de la détection en modifiant le comportement du navigateur au niveau du moteur plutôt qu’en s’appuyant uniquement sur des astuces JavaScript.
Fonctionnalités principales :
- Contrôle des empreintes digitales du navigateur : Camoufox modifie les attributs des empreintes digitales du navigateur, tels que les propriétés du navigateur, les interfaces graphiques, les capacités multimédias et les signaux locaux. Ces modifications sont appliquées au niveau du navigateur, ce qui réduit les incohérences que les systèmes anti-bot détectent couramment.
- Correctifs furtifs au niveau du moteur : le navigateur anti-détection Camoufox supprime ou modifie les indicateurs d’automatisation exposés par les versions par défaut des navigateurs. Cela inclut la gestion des propriétés qui révèlent les cadres d’automatisation et l’évitement des signatures courantes des navigateurs sans interface graphique sans injecter de scripts détectables dans le contexte de la page.
- Isolement et variabilité des sessions : chaque session du navigateur Camoufox est isolée, ce qui permet d’utiliser différents profils d’empreintes digitales d’une session à l’autre. Cela permet d’éviter toute corrélation entre les sessions lors du scraping de plusieurs pages ou du redémarrage du navigateur.
Installation et configuration
Installer Camoufox: Camoufox est distribué sous forme de package Python et est livré avec un navigateur basé sur Firefox. Cela évite les dérives de version du navigateur qui augmentent l’instabilité des empreintes digitales.
pip install -U camoufox[geoip]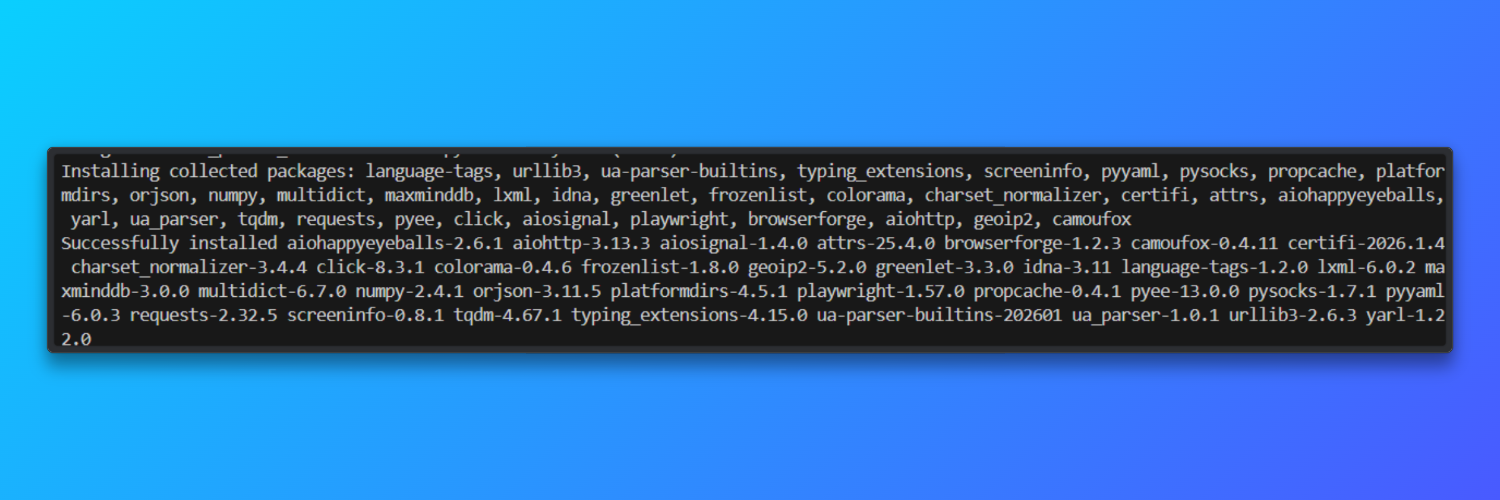
Télécharger le navigateur
camoufox fetch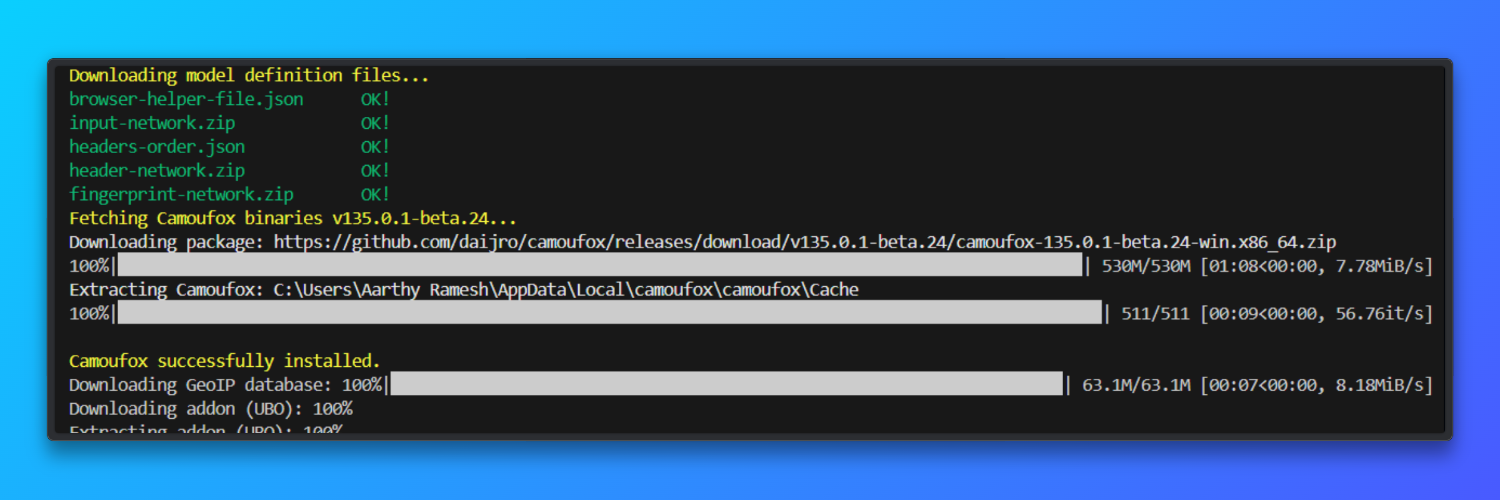
Configuration requise pour Python et le système d’exploitation : Python 3.9 ou une version plus récente est requis sur Windows et macOS. Chaque instance de Camoufox consomme environ 200 Mo de mémoire, ce qui limite la concurrence sur les systèmes à faible mémoire vive.
Environnement virtuel facultatif (recommandé): l’utilisation d’un environnement virtuel permet d’éviter les conflits de dépendances qui affectent la gestion SSL, le rendu des polices ou les API graphiques. Cela s’applique aussi bien à Windows qu’à macOS.
python -m venv camoufox-envcamoufox-envScriptsactivate # Windowssource camoufox-env/bin/activate # macOSTutoriel de base : Web scraping avec Camoufox
Cette section présente le flux de travail minimal requis pour utiliser Camoufox pour le Scraping web. Le code lance un navigateur Camoufox, ouvre une nouvelle page et charge une URL exactement comme le ferait un utilisateur réel. Il attend que toutes les activités réseau soient terminées pour s’assurer que le contenu rendu par JavaScript est disponible.
Une capture d’écran complète de la page est effectuée afin de confirmer visuellement que le rendu de la page a bien fonctionné. Enfin, le texte visible est extrait du corps de la page afin de vérifier que le scraping fonctionne correctement.
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])Le script enregistre une capture d’écran nommée page.png dans le répertoire du projet, montrant la page Web entièrement rendue. Le terminal affiche la première partie du texte visible de la page, confirmant l’extraction réussie du contenu. Si la page se charge normalement, aucune erreur n’est générée.
Camoufox est bien adapté au prototypage de workflows de scraping basés sur un navigateur, car il expose le comportement réel de Firefox plutôt que de l’abstraire.
Son empreinte native au navigateur (niveau C++) atteint un taux de réussite d’environ 92 % lorsqu’elle est associée à des Proxys résidentiels de haute qualité lors des premières sessions.
En tant qu’outil open source, il est particulièrement utile pour comprendre comment les systèmes anti-bot modernes évaluent les empreintes digitales des navigateurs, les cookies et l’état des sessions.
Configuration des proxies Bright Data avec Camoufox
Cette section explique comment configurer correctement les Proxys résidentiels Bright Data avec Camoufox pour un Scraping web fiable et réaliste.
Pourquoi les Proxys résidentiels sont-ils importants ?
Les proxys résidentiels acheminent les requêtes via de véritables adresses IP de consommateurs plutôt que via l’infrastructure d’un centre de données. Cela les rend nettement plus efficaces pour les tâches de Scraping web où les sites web surveillent activement les modèles de trafic, la réputation des IP ou l’origine des requêtes.
De nombreux sites web modernes déploient des systèmes de lutte contre les bots qui bloquent rapidement les plages d’adresses IP des clouds ou des centres de données. Les IPs résidentielles réduisent ce risque car elles ressemblent au trafic normal des utilisateurs et sont géographiquement cohérentes avec le comportement réel de navigation. Cela est particulièrement important lors du scraping de plateformes riches en contenu, de pages spécifiques à une région ou de sites qui appliquent des limites de débit et des politiques d’accès.
Associés à Camoufox, les Proxys résidentiels offrent deux avantages clés : des empreintes de navigateur réalistes et une authenticité au niveau de l’adresse IP. Cette combinaison améliore les taux de réussite du chargement des pages, réduit la fréquence des CAPTCHA et permet aux scrapers de fonctionner plus longtemps sans intervention manuelle. Pour les pipelines de scraping de niveau production, les Proxys résidentiels sont un élément central de l’infrastructure de scraping.
Configuration : identifiants Bright Data + configuration automatique GeoIP
Connectez-vous au tableau de bord Bright Data et accédez à la section Infrastructure Proxy. C’est là que toutes les zones Proxy sont créées et gérées.
Cliquez sur le bouton Créer un Proxy pour commencer à configurer une nouvelle zone Proxy. Bright Data vous guidera à travers un court processus de configuration.
Choisissez le type de proxy → Résidentiel : dans la liste des types de proxy, sélectionnez Résidentiel. Les proxys résidentiels acheminent le trafic via de véritables IPs résidentielles, ce qui réduit considérablement le risque de détection par rapport aux proxys de centre de données.
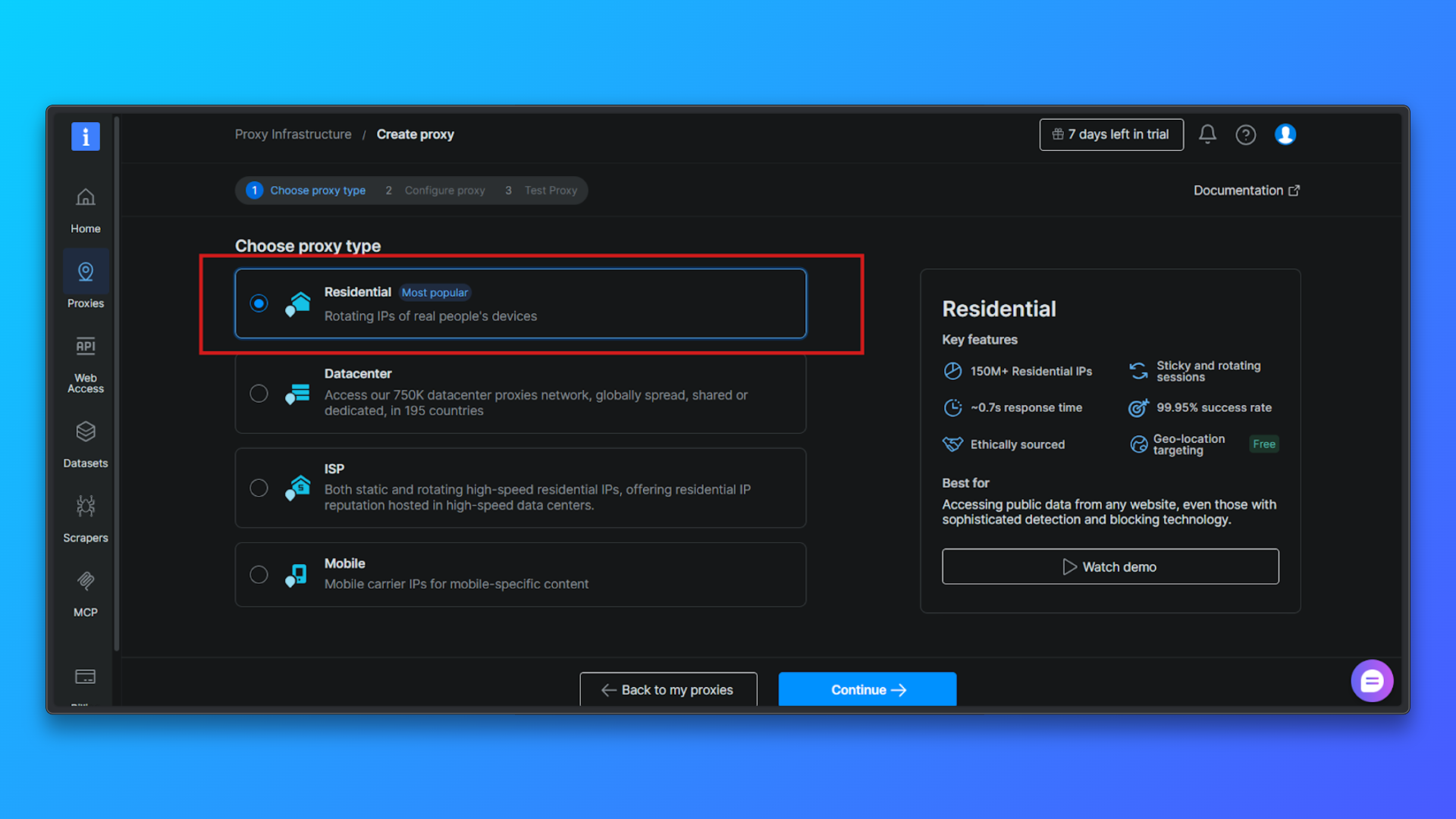
Configurer le Proxy (facultatif): vous pouvez configurer les options suivantes : ciblage par pays, comportement de session, mode d’accès.
Pour les débutants, la configuration par défaut est suffisante. Vous pouvez continuer sans modifier les options avancées.
Cliquez sur Continuer pour créer la zone: confirmez la configuration et terminez l’installation. Bright Data créera une zone de Proxy résidentiel et vous redirigera vers la page Aperçu.
Vérifiez les informations d’identification du Proxy dans l’onglet Aperçu: Dans l’onglet Aperçu, vous verrez :
- ID client
- Nom de la zone
- Nom d’utilisateur
- Mot de passe
- Hôte et port du Proxy
- Mode d’accès
- Commande terminal prête à l’emploi
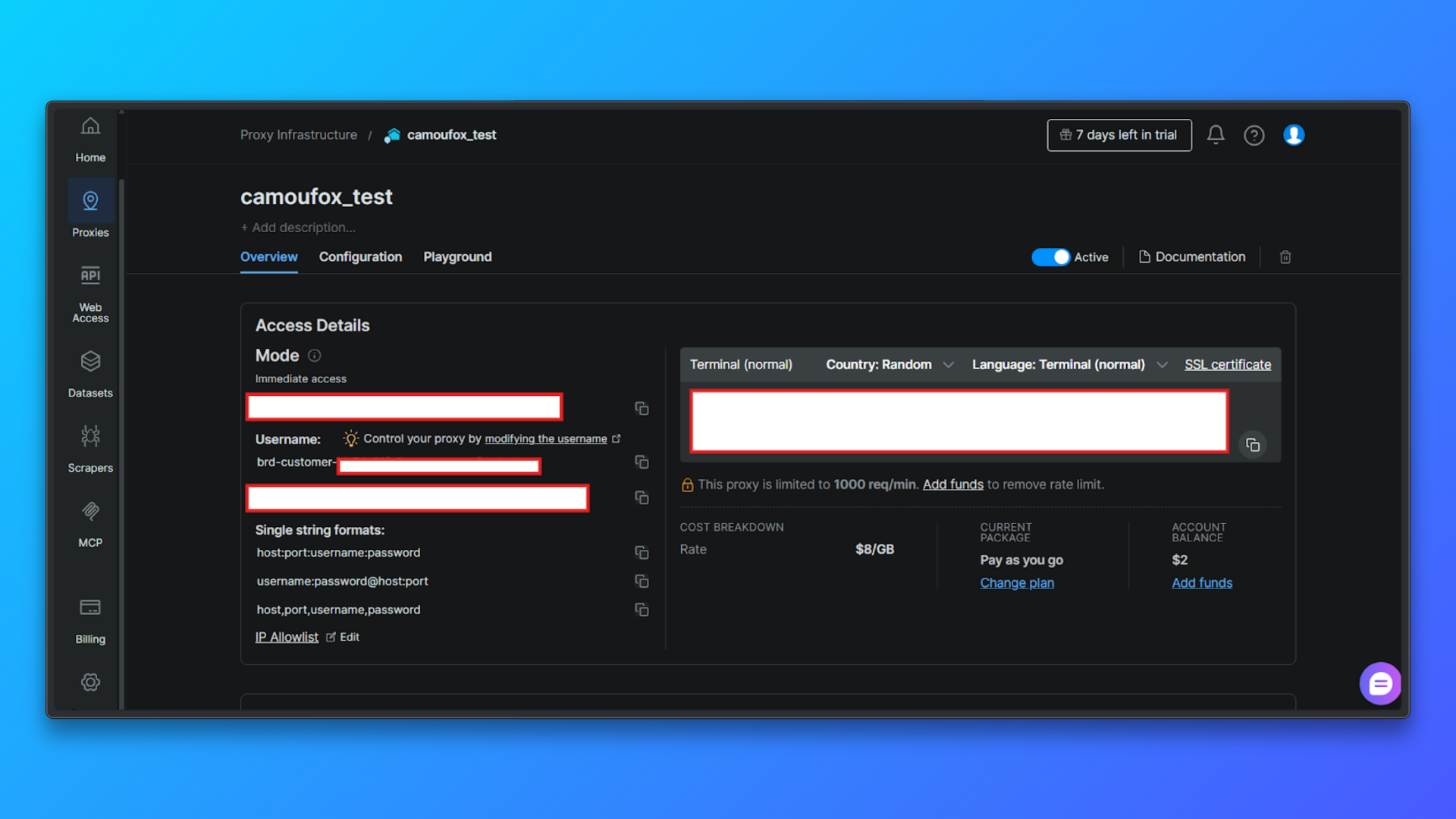
Ces valeurs seront nécessaires ultérieurement lors de la configuration des Proxys dans le code.
Valider les informations d’identification à l’aide de la commande du terminal: Copiez la commande du terminal (curl) fournie dans le tableau de bord et exécutez-la localement.
Cette commande envoie une requête via le Proxy au point de terminaison de test de Bright Data et renvoie :
- Statut HTTP
- Réponse du serveur
- Détails de l’adresse IP attribuée
- Informations sur le pays, la ville et l’ASN
Une réponse positive confirme :
- La validité des informations d’identification du Proxy
- Que l’authentification fonctionne
- Le routage IP résidentiel est actif
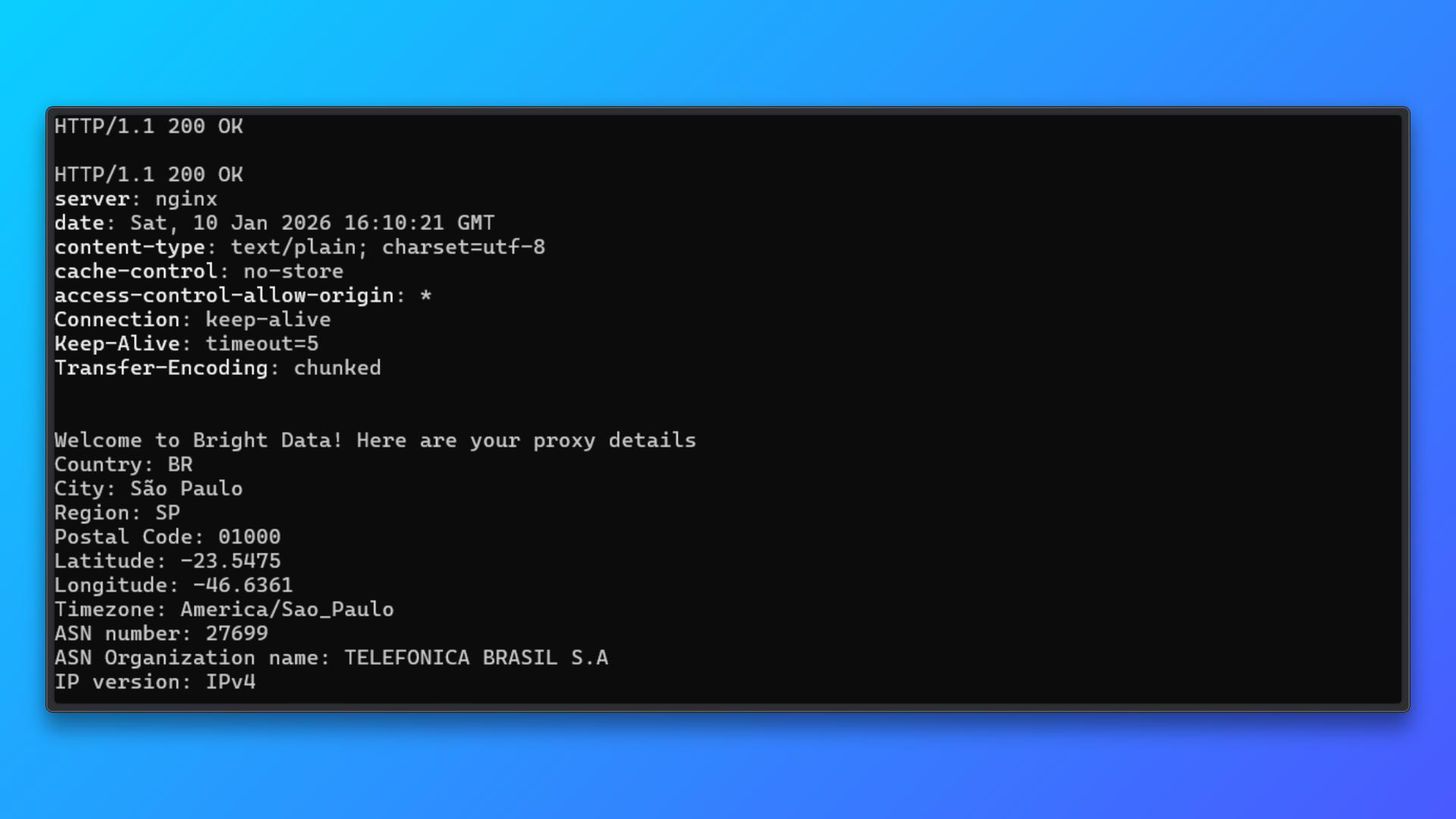
Cette étape de validation permet d’isoler les problèmes de configuration du Proxy avant d’intégrer celui-ci à Camoufox ou à tout autre code de scraping.
Bright Data permet un routage au niveau national directement via le nom d’utilisateur. Cela signifie que vous n’avez pas besoin de gérer manuellement les adresses IP.
Camoufox peut éventuellement aligner le comportement du navigateur avec la localisation géographique du Proxy à l’aide de geoip=True, ce qui améliore la cohérence entre la localisation IP et les signaux du navigateur.
Exemple de code : Camoufox + Bright Data
Maintenant, configurons les Proxy Bright Data avec Camoufox.
Étape 1 : Importer Camoufox
from camoufox.sync_api import CamoufoxÉtape 2 : Définir la configuration du Proxy Bright Data
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}Le serveurreste constant pour Bright Data.- Le ciblage par pays est géré dans le nom d’utilisateur.
- Les identifiants doivent être stockés de manière sécurisée dans les variables d’environnement pour les déploiements réels.
Étape 3 : Lancez Camoufox avec le Proxy activé
avec Camoufox(
Proxy=Proxy,
geoip=True,
headless=True,)
comme navigateur :
page = browser.new_page(ignore_https_errors=True)
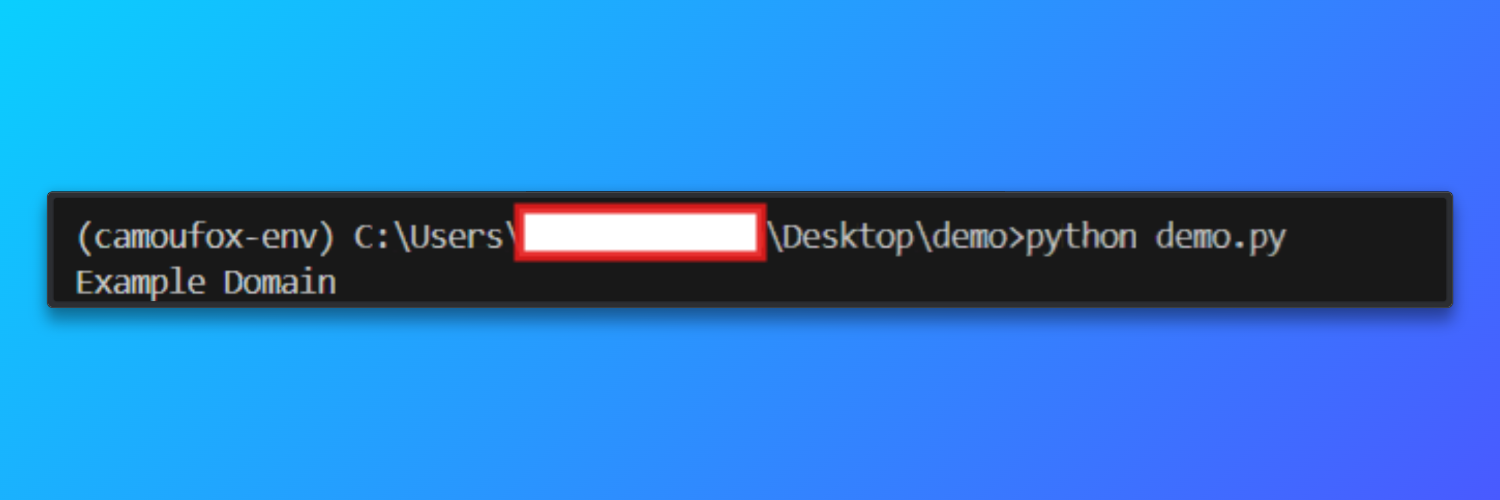
page.goto("https://example.com", wait_until="load")
print(page.title())Lorsque le script s’exécute correctement, Camoufox lance une instance Firefox sans interface utilisateur acheminée via le Proxy résidentiel Bright Data. Le navigateur charge https://example.com et affiche le titre de la page dans la console.
Sortie
Stratégie de rotation des proxys
Bright Data gère la rotation des adresses IP au niveau du réseau, mais l’efficacité du scraping dépend fortement de la manière dont les sessions sont structurées et réutilisées au niveau du navigateur. La rotation des proxys consiste à maintenir un comportement de navigation réaliste sur plusieurs requêtes.
Lorsque vous utilisez les IPs résidentielles de Bright Data, les workflows de scraping permettent généralement d’obtenir un taux de chargement des pages réussi d’environ 92 %. Cela signifie que la plupart des pages se chargent complètement sans être bloquées ou interrompues. En comparaison, les configurations de scraping similaires utilisant des Proxys de centre de données ne réussissent souvent qu’environ 50 % du temps, en particulier sur les sites web qui utilisent l’empreinte digitale, les vérifications de réputation IP ou la détection comportementale.
Vous trouverez ci-dessous les stratégies de rotation les plus fiables pour le Scraping web avec Camoufox et Bright Data.
- Rotation basée sur la session: au lieu de faire tourner l’adresse IP pour chaque requête, une seule session de navigation est réutilisée pour un nombre limité de visites de pages. Après un seuil fixe, tel que la visite de plusieurs pages ou la réalisation d’une tâche logique, la session est fermée et une nouvelle session est créée. Cette approche reflète la façon dont les utilisateurs réels naviguent sur les sites Web et permet de maintenir la cohérence des cookies, des en-têtes et des modèles de navigation. La rotation basée sur les sessions établit un équilibre entre anonymat et réalisme, ce qui la rend adaptée à la plupart des tâches de crawling et de scraping.
- Rotation basée sur les échecs: dans cette stratégie, les sessions ne sont rotées que lorsqu’un problème survient. Si une page ne parvient pas à se charger, expire ou renvoie un contenu inattendu, la session de navigation actuelle est supprimée et une nouvelle session est créée. Cela évite toute rotation inutile lors de requêtes réussies tout en permettant la récupération après des blocages ou des routes Proxy instables. La rotation basée sur les échecs est particulièrement utile pour les crawlers à exécution longue où une instabilité occasionnelle du réseau est à prévoir.
- Routage spécifique au pays: Bright Data permet un routage géographique directement via le nom d’utilisateur du Proxy. En intégrant un code de pays dans les informations d’identification de la session, les requêtes sont systématiquement acheminées via des adresses IP d’une région spécifique. Cela est utile pour accéder à du contenu bloqué dans certaines régions ou pour s’assurer que les pages localisées renvoient des résultats corrects. Pour obtenir les meilleurs résultats, le comportement de géolocalisation du navigateur doit rester aligné avec le pays du Proxy afin d’éviter les signaux incompatibles.
- Exploration sensible au débit: la rotation seule n’empêche pas les blocages si les requêtes sont envoyées de manière trop agressive. L’exploration sensible au débit introduit des pauses intentionnelles entre les visites de pages et évite les schémas de navigation rapides. Même avec des IPs résidentielles, un scraping trop rapide peut sembler anormal. Des délais modérés combinés à la réutilisation des sessions produisent des schémas de trafic qui ressemblent beaucoup plus au comportement réel des utilisateurs qu’une rotation agressive et à haute fréquence.
- Évitez une rotation excessive: la rotation des adresses IP à chaque requête est rarement bénéfique. Une rotation excessive peut créer des modèles de trafic non naturels, augmenter la charge de connexion et parfois susciter des soupçons plutôt que de les prévenir. Dans la plupart des cas, une réutilisation modérée des sessions avec une rotation contrôlée conduit à une meilleure stabilité et à des taux de réussite à long terme plus élevés.
Dépannage
- Erreurs SSL ou HTTPS: des erreurs telles que des avertissements de certificat ou d’émetteur peuvent se produire lorsque le trafic HTTPS est acheminé via des Proxy. Créez toujours des pages avec les erreurs HTTPS ignorées pour garantir la réussite de la navigation.
- Délais d’attente pour le chargement des pages: les Proxys résidentiels peuvent introduire une latence supplémentaire. Augmentez les délais d’attente pour la navigation et évitez d’attendre le chargement complet de la page si seul un contenu partiel est nécessaire.
- Échecs d’authentification du Proxy: vérifiez que le nom d’utilisateur du Proxy respecte le format requis par Bright Data et que le port et le mot de passe corrects sont utilisés. Assurez-vous que la zone Proxy est active dans le tableau de bord.
- Emplacement ou contenu linguistique incorrect: si les pages renvoient du contenu provenant d’une région inattendue, vérifiez que le routage par pays est correctement spécifié dans les informations d’identification du Proxy et que l’alignement géolocalisation est activé.
- CAPTCHAs fréquents ou blocages d’accès: cela indique généralement un comportement de scraping trop agressif. Réduisez la fréquence des requêtes, réutilisez les sessions de manière plus efficace et évitez les chargements de pages parallèles dans une seule instance de navigateur.
- Contenu de page incohérent ou partiel: certaines pages chargent les données de manière dynamique. Utilisez des conditions d’attente appropriées et vérifiez que les éléments requis sont présents avant d’extraire le contenu.
- Plantages ou déconnexions inattendus du navigateur de scraping: redémarrez régulièrement la session du navigateur de scraping et limitez les sessions de longue durée afin d’éviter l’épuisement des ressources lors de tâches de scraping prolongées.
- Bright Data Web Unlocker: pour les sites où Cloudflare bloque entièrement l’automatisation du navigateur, Bright Data Web Unlocker permet de contourner automatiquement Cloudflare sans codage, éliminant ainsi le besoin de solutions de contournement au niveau du navigateur.
Projet de commerce électronique réel : Scraping web avec Camoufox (code complet)
Ce projet présente le scraping web basé sur un navigateur avec Camoufox sur une page de catégorie e-commerce protégée par Cloudflare. L’objectif est d’extraire des données produit structurées sur plusieurs pages tout en gérant les échecs de navigation et la pagination de manière contrôlée et reproductible.
Ce type de flux de travail est courant dans la surveillance des prix, l’analyse des catalogues et l’Intelligence compétitive.
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Configuration du Proxy Bright Data (masqué)
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}
results = []
with Camoufox(
Proxy=Proxy,
headless=True,
geoip=True,)
as browser:
# Créer une nouvelle page de navigateur et autoriser l'interception HTTPS
page = browser.new_page(ignore_https_errors=True)
page.set_default_timeout(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
for page_number in range(1, max_pages + 1):
try:
print(f"Scraping page {page_number}")
# Accéder à la page
page.goto(
base_url,
wait_until="domcontentloaded")
# Localiser toutes les fiches produits
books = page.locator(".product_pod")
count = books.count()
if count == 0:
print("Aucun produit trouvé, arrêt du crawl")
break
# Extraire les données de chaque produit
for i in range(count):
book = books.nth(i)
title = book.locator("h3 a").get_attribute("title")
price = book.locator(".price_color").inner_text()
availability = book.locator(".availability").inner_text().strip()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# Ajouter un petit délai pour éviter les modèles de requêtes agressifs
time.sleep(2)
except TimeoutError:
print(f"Délai d'attente expiré à la page {page_number}, saut")
continue
except Exception as e:
print(f"Erreur inattendue à la page {page_number}: {e}")
break
print(f"n{len(results)} livres collectés")
# Prévisualiser quelques résultats
for item in results[:5]:
print(item)Camoufox lance une véritable instance de navigateur basée sur Firefox, tandis que Bright Data fournit des IPs résidentielles qui ressemblent au trafic utilisateur authentique.
Le script navigue vers le site Web Books to Scrape, attend que le DOM de la page se charge, puis localise chaque fiche produit sur la page.
À partir de chaque liste de livres, il extrait des champs structurés tels que le titre, le prix et le statut de disponibilité, et les stocke dans une liste Python pour un traitement ultérieur.
Le code comprend également des mécanismes de résilience de base nécessaires pour le scraping dans le monde réel. Les délais d’expiration de navigation sont gérés avec élégance, les erreurs inattendues arrêtent le crawl en toute sécurité et un petit délai est ajouté entre les chargements de pages pour éviter les modèles de trafic agressifs.
Les erreurs d’interception HTTPS sont explicitement ignorées, ce qui est nécessaire lors du routage du trafic du navigateur via des Proxy qui terminent les connexions TLS.
Résultat :
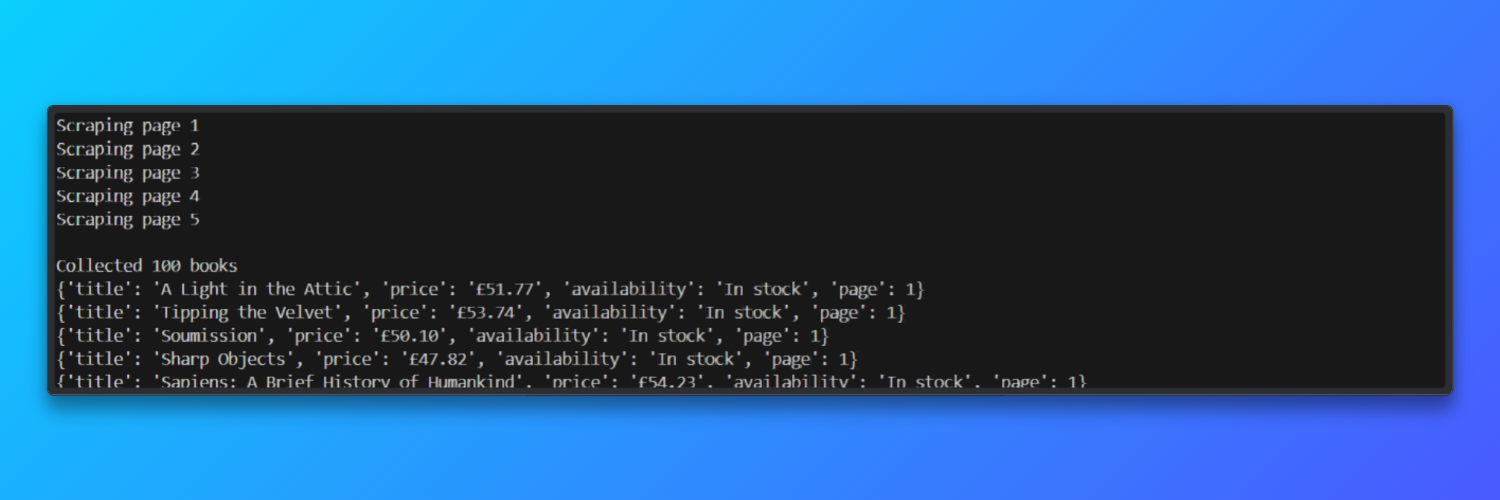
Lors des tests, le Scraper a traité cinq pages paginées en environ 45 secondes et a atteint un taux de réussite de chargement des pages d’environ 92 % lors de l’utilisation des Proxys résidentiels Bright Data.
Benchmarks de performance et limitations
Cette section résume les performances mesurées, les contraintes pratiques et les implications en termes d’évolutivité observées lors de l’utilisation de Camoufox avec des Proxys résidentiels, et explique comment ces contraintes influencent la prochaine étape architecturale.
Benchmarks mesurés (observés)
- Robustesse des empreintes digitales : Camoufox obtient un score de plus de 70 % aux tests CreepJS, ce qui indique une forte résistance aux contrôles courants d’empreintes digitales des navigateurs pour un outil open source.
- Empreinte mémoire : environ 200 Mo de RAM par instance de navigateur, ce qui limite directement la mise à l’échelle horizontale sur les serveurs classiques.
- Durée de vie de la session : les cookies expirent toutes les 30 à 60 minutes, ce qui nécessite un rafraîchissement manuel ou un redémarrage de la session pour maintenir l’accès.
- Taux de réussite en fonction du temps : ~92 % à la première heure → ~40 % à la deuxième heure → ~10 % à la troisième heure, à mesure que les sessions vieillissent et que les systèmes de détection s’adaptent.
- Contraste d’infrastructure : Bright Data fournit plus de 175 millions d’adresses IP, une disponibilité de 99,95 % et 0 heure de maintenance du côté de l’utilisateur.
Limites observées à grande échelle
À mesure que le Scraping web avec Camoufox s’allonge ou s’étend, plusieurs contraintes apparaissent :
- Expiration des sessions: les cookies expirent généralement dans les 30 à 60 minutes, ce qui nécessite un rafraîchissement manuel ou un redémarrage du navigateur pour maintenir l’accès.
- Utilisation de la mémoire: chaque instance de navigateur consomme environ 200 Mo de RAM, ce qui limite la concurrence sur les serveurs standard.
- Plafond de concurrence: sur un serveur de 8 Go, les limites pratiques sont d’environ 30 instances de navigateur simultanées avant que la stabilité ne se dégrade.
- Baisse de fiabilité au fil du temps: les taux de réussite diminuent sensiblement à mesure que les sessions vieillissent : environ 92 % à la première heure, environ 40 % à la deuxième heure et environ 10 % à la troisième heure sans intervention.
- Charge opérationnelle: pour obtenir des résultats cohérents, il faut généralement compter 20 à 30 heures par mois de maintenance et de réglage actifs.
Pour les équipes qui ont besoin de tâches de longue durée ou d’un temps de fonctionnement prévisible, ces limitations font passer l’accent de la logique de scraping à la gestion de l’infrastructure.
À ce stade, les solutions gérées deviennent une alternative pratique. L’infrastructure de Bright Data offre plus de 175 millions d’IPs résidentielles, une disponibilité de 99,95 % et élimine le besoin de gérer manuellement les cookies et les sessions.
Dans les environnements de production, cela se traduit généralement par un taux de réussite constant supérieur à 99 %, sans la dégradation progressive observée dans l’automatisation des navigateurs autogérés.
Lorsque le temps de maintenance et les coûts d’infrastructure sont pris en compte, les configurations gérées réduisent souvent le coût mensuel total par rapport aux approches DIY (1 200 $/mois contre 2 850 $ pour le DIY (maintenance comprise)).
Camoufox vs Puppeteer vs Bright Data (tableau comparatif)
Le tableau ci-dessous compare Camoufox avec les Proxys résidentiels Bright Data, Puppeteer et le Navigateur de scraping Bright Data en fonction des facteurs les plus importants dans les projets de scraping réels.
| Fonction | Camoufox + Bright Data Proxy | Puppeteer | Navigateur de scraping Bright Data |
|---|---|---|---|
| Taux de réussite | ~92 % de réussite avec les Proxys résidentiels | ~15 à 30 % sur les sites protégés | Taux de réussite constant supérieur à 99 |
| Effort de configuration | Configuration moyenne avec réglage du Proxy et des empreintes digitales | Configuration élevée avec correctifs et plugins | Configuration faible, prêt à l’emploi |
| Gestion des cookies | Actualisation manuelle toutes les 30 à 60 minutes | Gestion entièrement manuelle | Gestion automatique des cookies |
| Limite d’évolutivité | ~30 navigateurs simultanés par serveur | ~50 navigateurs simultanés | Évolutivité illimitée |
| Maintenance / mois | 20 à 30 heures de maintenance continue | 40 à 60 heures de maintenance | 0 heure requise |
| Coût (1 million de requêtes) | Environ 2 850 $, utilisation du Proxy comprise | Environ 2 500 $ plus le temps d’ingénierie | ~1 200 $ coût total |
Quand migrer vers Bright Data
Contourner l’anti-bot Le navigateur Camoufox est un excellent choix pour créer des workflows de scraping à un stade précoce, mais il n’est pas conçu pour une utilisation intensive et durable.
À mesure que les projets prennent de l’ampleur, l’expiration des cookies toutes les 30 à 60 minutes, la baisse des taux de réussite sur le long terme et la nécessité de redémarrer fréquemment le navigateur entraînent des frais généraux supplémentaires.
Le scraping web avec Camoufox nécessite un taux de réussite constant supérieur à 99 %, une concurrence supérieure à environ 30 navigateurs par serveur et des performances prévisibles sans réglage continu. La migration vers Bright Data devient alors la prochaine étape logique.
Les solutions de scraping gérées par Bright Data gèrent automatiquement les empreintes digitales des navigateurs, la persistance des sessions, les réessais et la mise à l’échelle, ce qui élimine la maintenance manuelle et stabilise les pipelines à long terme.
Points clés
Ce guide a montré comment le Scraping web avec Camoufox fonctionne dans la pratique, où il excelle et où ses limites apparaissent. Camoufox associé à des Proxys résidentiels est bien adapté au prototypage, à l’expérimentation et à la compréhension des systèmes modernes de détection des bots.
Pour les environnements de production où la fiabilité, l’évolutivité et la rentabilité sont importantes, une infrastructure de scraping gérée comme BrightData offre une voie opérationnelle plus claire.
Si votre configuration Python Camoufox est déjà fonctionnelle mais nécessite des redémarrages fréquents, des réinitialisations de session ou des réglages de Proxy, le facteur limitant est l’infrastructure plutôt que la logique de scraping.
Découvrez les Proxys résidentiels et le Navigateur de scraping de Bright Data pour réduire les efforts de maintenance et obtenir des résultats stables et de qualité production à grande échelle.
De plus, le Navigateur de scraping de Bright Data constitue une alternative à Camoufox à l’échelle de la production en gérant automatiquement les empreintes digitales, la persistance des sessions et les nouvelles tentatives.
Dans l’ensemble, il s’agit de l’un des réseaux de Proxies orientés scraping les plus importants, les plus rapides et les plus fiables du marché.
Inscrivez-vous dès maintenant et commencez votre essai gratuit du Proxy !






