

Dans ce tutoriel, vous apprendrez :
- Pourquoi il est judicieux de récupérer des données sur Bilibili via le Scraping web.
- Quels types de données vous pouvez extraire de Bilibili.
- Comment créer un pipeline de scraping et de téléchargement Bilibili pour collecter des données vidéo pour la formation en IA (et d’autres cas d’utilisation).
- Pourquoi un Scraper Bilibili dédié est un meilleur choix pour les applications de niveau entreprise prêtes à être mises en production.
Évitez la complexité :le Scraper Bilibili de Bright Datafournit des données vidéo prêtes à l’emploi à l’échelle de l’entreprise, avec un contournement anti-bot intégré et une disponibilité de 99,99 %.
Plongeons-nous dans le vif du sujet !
Pourquoi scraper Bilibili : cas d’utilisation possibles
Bilibili est une plateforme vidéo basée à Shanghai, souvent décrite comme le « YouTube chinois ». Lancée en 2009, elle est devenue un véritable moteur pour la génération Z, avec plus de 294 millions d’utilisateurs actifs par mois et plus de 3 milliards de vidéos visionnées chaque jour.
Initialement centrée sur l’ACG (anime, bandes dessinées et jeux), elle couvre désormais la technologie, l’éducation, le mode de vie, la musique, l’e-sport et le livestreaming. Bilibili est connue pour ses commentaires « danmu » en temps réel et sa communauté très engagée. Elle combine le contenu généré par les utilisateurs, la culture des influenceurs, les jeux et la publicité dans un même écosystème numérique.
Compte tenu de la croissance rapide de Bilibili, l’accès aux données de la plateforme permet de nombreuses utilisations, telles que :
- Formation à l’IA vidéo: les Jeux de données vidéo à grande échelle de Bilibili peuvent alimenter la vision par ordinateur, la reconnaissance vocale, les LLM multimodaux, les systèmes de recommandation et les modèles de modération de contenu. Cela est possible grâce à des métadonnées riches, des transcriptions, des signaux d’engagement et du contenu audiovisuel brut.
- Tendances et intelligence de contenu: analysez les catégories, les balises, les vues et les mesures d’engagement pour identifier les sujets émergents, les créateurs en pleine croissance et les formats viraux au sein du public de la génération Z et des communautés axées sur l’ACG.
- Analyse des créateurs et des influenceurs: suivez les performances des uploadeurs, la croissance du nombre d’abonnés, les taux d’engagement et la fréquence de publication afin d’évaluer l’impact des KOL (Key Opinion Leader) et d’optimiser les stratégies de marketing d’influence en Chine.
- Analyse du sentiment du public: exploitez les danmu (commentaires rapides) et les commentaires standard pour comprendre les réactions des spectateurs, le ton émotionnel, les références culturelles et les modèles de commentaires en temps réel à grande échelle.
- Analyse comparative de la concurrence: comparez les chaînes de marques, les campagnes sponsorisées et les leaders de catégorie en surveillant les vues, les interactions et les stratégies de contenu dans des niches similaires.
- Étude de pénétration du marché et de localisation: évaluez les préférences en matière de contenu, l’utilisation de la langue et les thèmes tendance afin d’adapter les produits, les campagnes et les messages au public chinois natif du numérique.
Données que vous pouvez récupérer sur Bilibili
Lorsque vous effectuez un scraping sur Bilibili, vous pouvez cibler plusieurs champs de données. Ceux-ci dépendent des types de pages spécifiques à partir desquels vous collectez des données et de vos objectifs généraux. Il existe donc plusieurs catégories de données Bilibili intéressantes qui méritent d’être explorées.
Métadonnées vidéo
Lorsque vous ciblez une vidéo Bilibili spécifique, vous pouvez collecter :
- Informations de base: titre, description, URL de l’image de couverture, identifiant de la vidéo, durée de la vidéo, etc.
- Détails du téléchargement: date et heure de publication et catégorie/partition (par exemple, « Anime », « Tech » ou « Musique »).
- Catégorisation: balises, mots-clés et indication si la vidéo est marquée comme contenu original ou réimpression.
- Statistiques d’engagement: nombre total de vues, de likes, de pièces, de favoris et de partages.
- Commentaires: les commentaires affichés directement sur la vidéo. Cela inclut le texte du commentaire, l’horodatage, la couleur, la taille de la police et le mode d’affichage.
- Sous-titres: transcriptions générées par IA ou fournies par l’utilisateur.
Profils des utilisateurs et des créateurs
Lorsque vous vous concentrez sur la page d’un créateur Bilibili, vous pouvez extraire les informations suivantes :
- Informations d’identité: nom d’utilisateur, identifiant utilisateur, sexe, photo de profil, etc.
- Indicateurs sociaux: nombre d’abonnés, nombre d’abonnements et nombre total de likes reçus sur toutes les vidéos.
- Informations personnelles: biographie de l’utilisateur, date de naissance et niveau du compte.
- Statut du compte: badge de vérification (par exemple, « Musicien officiel ») et niveau d’adhésion (par exemple, VIP/Big Member).
- Liste des œuvres: toutes les vidéos publiées par un créateur spécifique.
Données de recherche et de découverte
Vous pouvez également utiliser le système de recherche de Bilibili pour récupérer :
- Résultats de recherche: listes de vidéos, d’utilisateurs ou de diffusions en direct correspondant à des mots-clés spécifiques.
- Données sur les tendances: mots-clés de recherche populaires et classements quotidiens/hebdomadaires.
- Informations sur les diffusions en direct: identifiant de la salle, titre de la diffusion, statut en direct et nombre de spectateurs simultanés (indice de popularité).
Création d’un Scraper Bilibili et d’un pipeline de téléchargement de vidéos en Python : guide étape par étape
Dans cette section guidée, vous apprendrez à extraire les métadonnées des vidéos Bilibili à partir de la page de la catégorie « Tech »: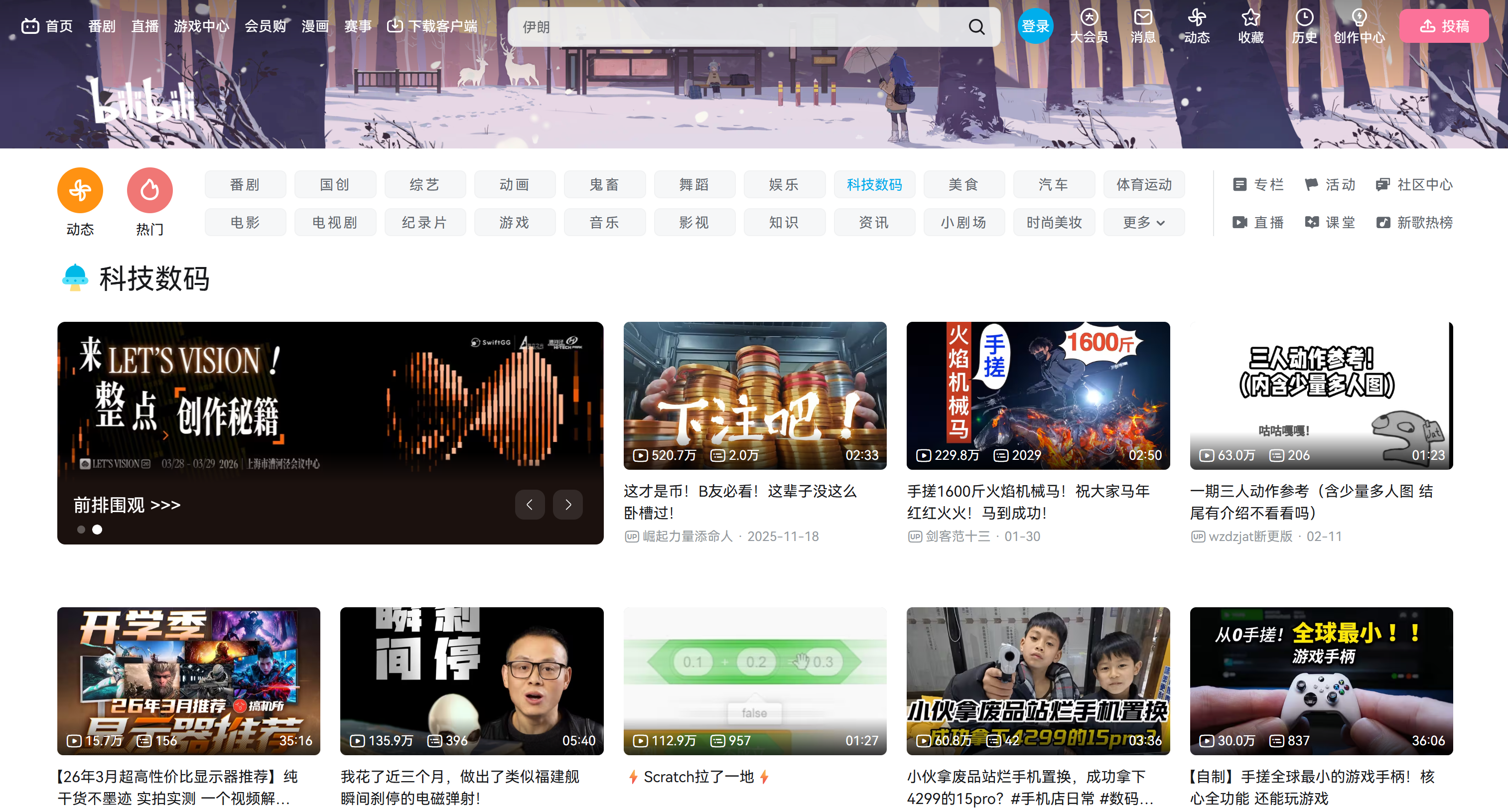
Notez qu’il ne s’agit que d’un exemple. La même logique peut être appliquée à n’importe quelle autre page de catégorie, y compris la page d’accueil principale.
À l’aide des URL des vidéos extraites de cette page, vous créerez ensuite un deuxième script pour les télécharger une par une. Une fois les fichiers vidéo téléchargés, vous pourrez enfin les intégrer directement dans vos pipelines de formation IA/ML.
Suivez les instructions ci-dessous !
Prérequis
Pour suivre ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.10 installé localement.
- FFmpeg installé localement.
- Une bonne connaissance du fonctionnement de l’automatisation des navigateurs.
- Une compréhension de base du fonctionnement de
yt-dlp.
Vérifiez que FFmpeg est installé sur votre machine à l’aide de cette commande :
ffmpeg -versionVous devriez voir quelque chose de similaire à ceci :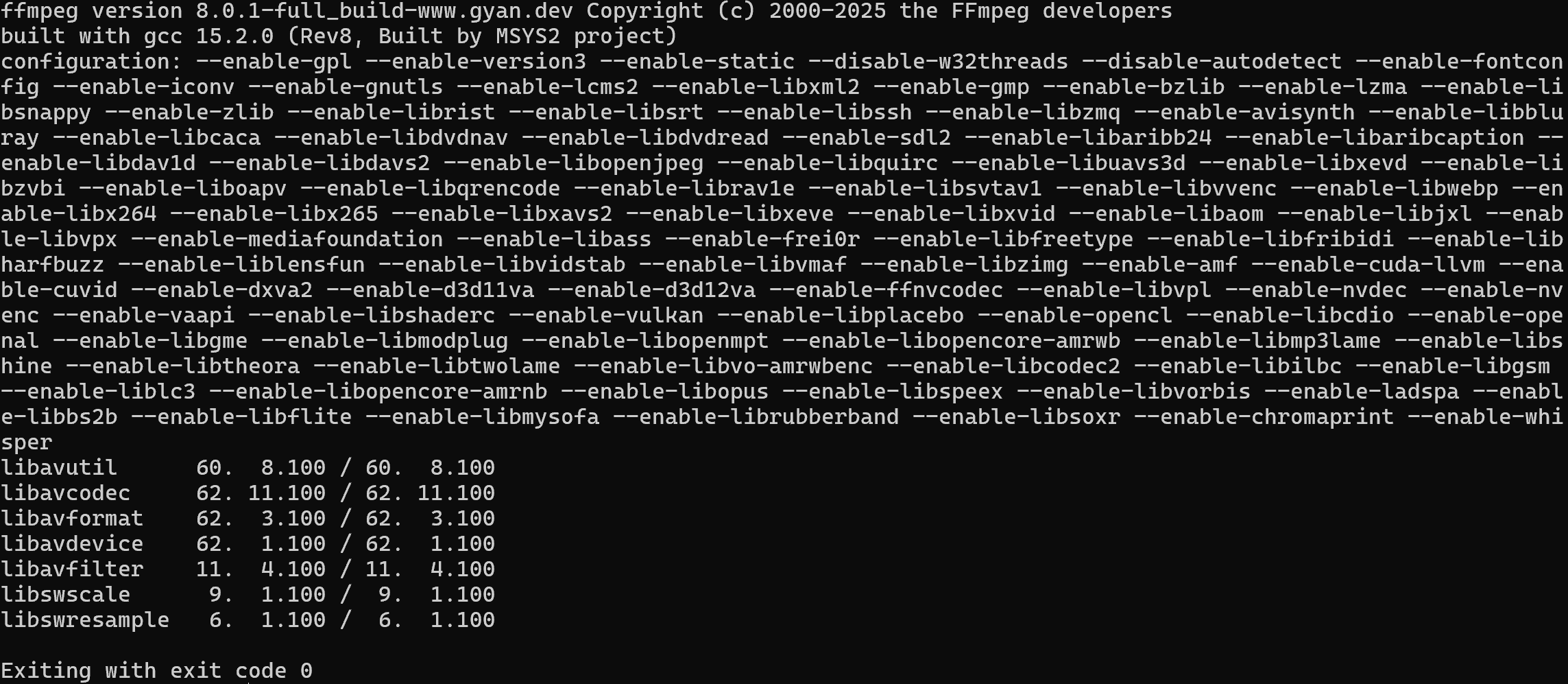
Si vous obtenez une erreur, installez FFmpeg en suivant le guide d’installation officiel pour votre système d’exploitation.
Étape n° 0 : familiarisez-vous avec Bilibili
Avant d’écrire le moindre code, prenez le temps d’explorer le site cible. Vous devez déterminer s’il s’agit d’un site statique ou dynamique, car cela aura une incidence sur votre feuille de route en matière de Scraping web.
Si le site est statique, un simple client HTTP associé à une approche d’analyse HTML peut suffire. S’il est dynamique, vous aurez besoin d’un outil d’automatisation du navigateur. Pour en savoir plus, consultez notre guide sur le contenu statique et dynamique pour le Scraping web.
Rendez-vous sur la page cible dans votre navigateur et commencez à interagir avec elle. Remarquez comment la page utilise un modèle d’interface utilisateur à défilement infini :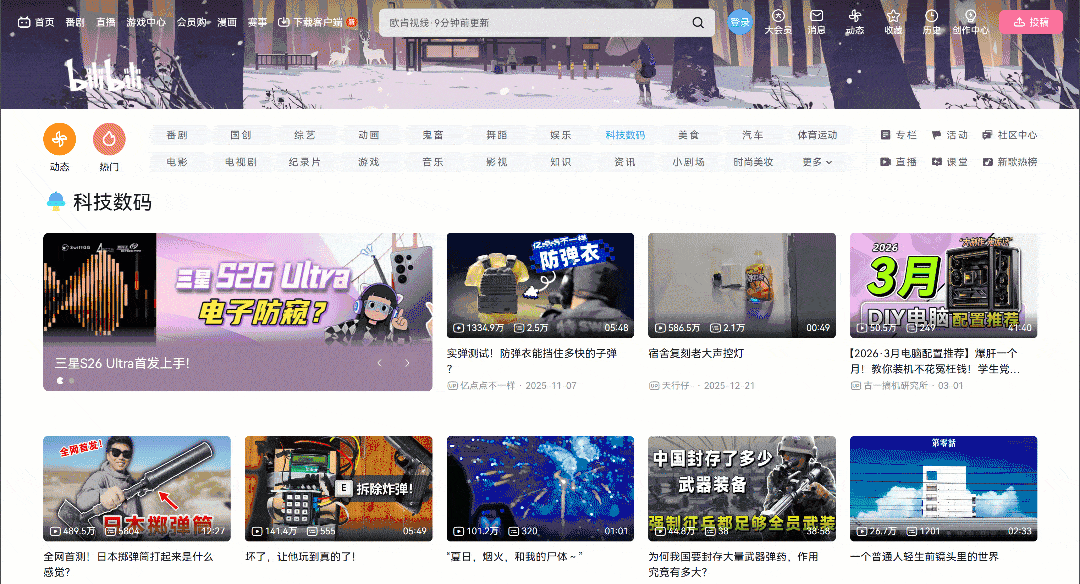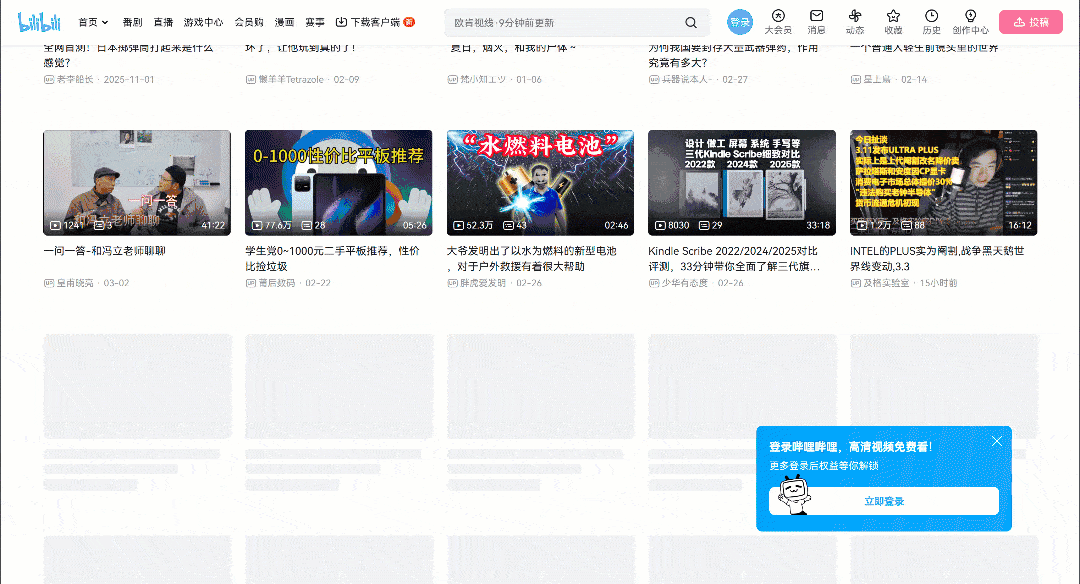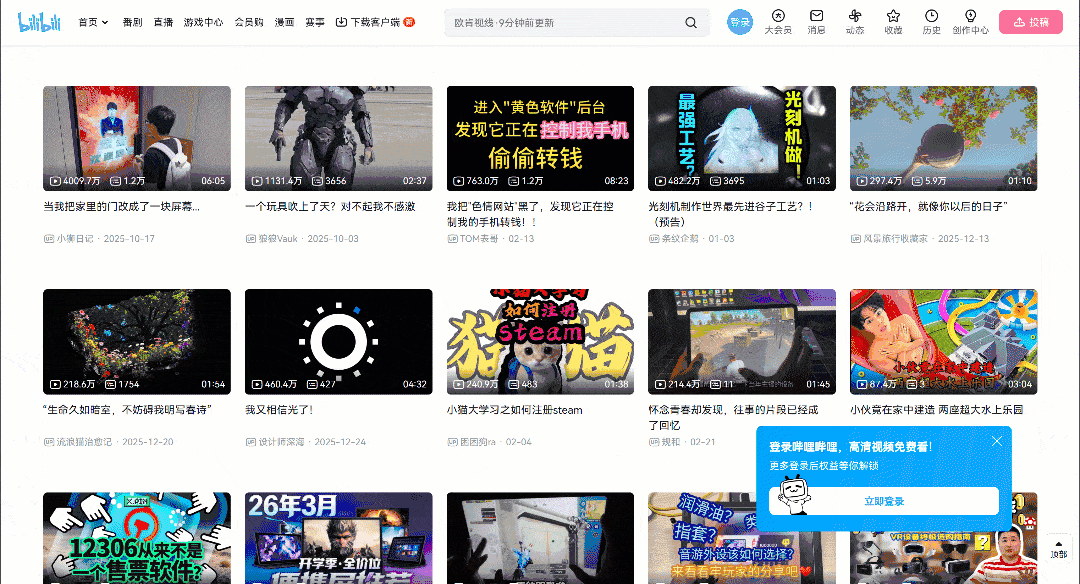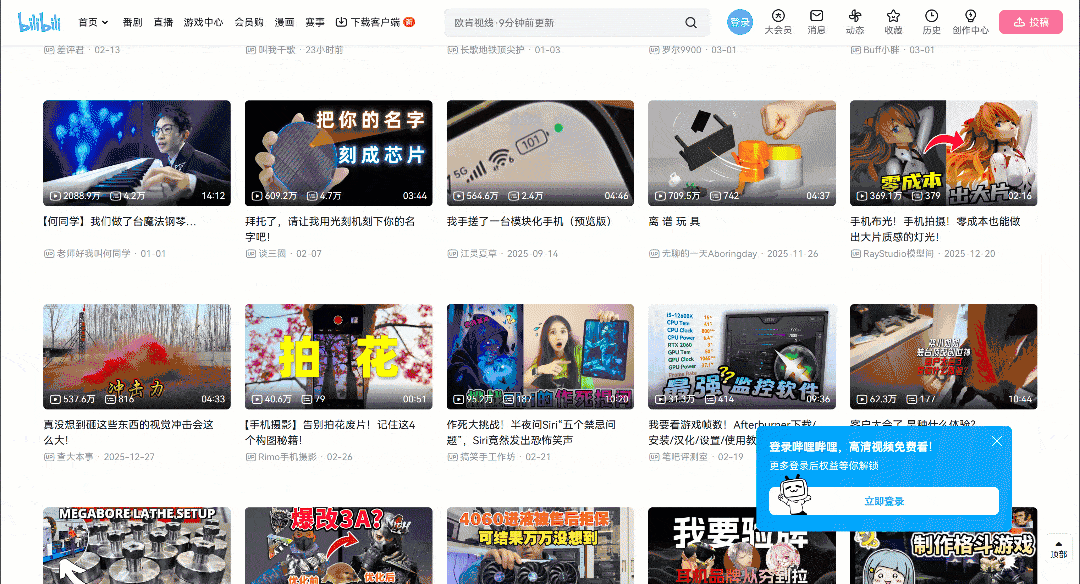
Lorsque vous faites défiler la page vers le bas, de nouvelles cartes vidéo sont chargées automatiquement. Ce comportement indique que le site web est dynamique. Plus précisément, il s’appuie sur JavaScript pour récupérer et afficher de nouvelles données en fonction de l’interaction de l’utilisateur.
De ce fait, une simple requête HTTP ne suffira pas. Vous aurez besoin d’un outil d’automatisation du navigateur pour afficher et extraire correctement le contenu. Dans ce tutoriel, nous utiliserons Playwright, mais des outils tels que Selenium, SeleniumBase ou NODRIVER fonctionneraient également.
Étape n° 1 : configurez votre projet Playwright
Commencez par lancer votre terminal et créer un nouveau répertoire pour votre Scraper Bilibili :
mkdir bilibili-ScraperDéplacez-vous dans le répertoire du projet et créez un environnement virtuel Python à l’intérieur :
cd bilibili-Scraper
python -m venv .venvEnsuite, chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python et PyCharm Community Edition sont deux bonnes options.
Créez un nouveau fichier nommé scraper.py à la racine du répertoire du projet, qui devrait ressembler à ceci :
bilibili-Scraper/
├── .venv/
└── scraper.py # <-----------Dans le terminal intégré de votre IDE, activez l’environnement virtuel. Sous Linux/macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, exécutez :
.venv/Scripts/activateUne fois l’environnement virtuel activé, installez playwright avec :
pip install playwrightTerminez l’installation en téléchargeant les binaires requis pour le navigateur:
python -m playwright installAjoutez maintenant la configuration Playwright de base suivante à scraper.py:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# Lancez une instance Chromium contrôlée en mode headful.
browser = await p.chromium.launch(headless=False) # Définissez sur True en production.
context = await browser.new_context()
page = await context.new_page()
# Logique de scraping...
# Fermer le navigateur et libérer ses ressources
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Cet extrait initialise une instance du navigateur Chromium et permet à Playwright de la contrôler.
Pendant le développement, il est utile de conserver headless=False afin de pouvoir suivre visuellement ce que fait le navigateur. En production, envisagez de définir headless=True pour réduire l’utilisation des ressources et accélérer l’exécution en activant le mode headless.
Bravo ! Vous disposez désormais d’un environnement Python prêt pour le Scraping web de Bilibili via l’automatisation du navigateur.
Étape n° 2 : se connecter au site cible
Utilisez Playwright pour naviguer vers la page web cible, qui est la page de la catégorie « Tech » de Bilibili :
# La page cible « Technologie » de Bilibili
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Accédez à la page cible
await page.goto(target_bilibili_page)La fonction goto() demande au navigateur contrôlé de visiter l’URL spécifiée et d’attendre que la page se charge.
Et voilà ! Vous êtes désormais connecté à la page de destination Bilibili.
L’étape suivante consiste à automatiser le défilement afin que les nouvelles cartes vidéo se chargent dynamiquement. Une fois le contenu supplémentaire affiché, vous serez prêt à extraire les données de ces éléments HTML.
Étape n° 3 : charger de nouvelles cartes vidéo
Comme mentionné précédemment, la page d’accueil et les pages de catégories de Bilibili reposent sur un modèle d’interface utilisateur à défilement infini. Au départ, seules quelques cartes vidéo sont visibles. Au fur et à mesure que vous faites défiler la page, davantage de contenu est chargé dynamiquement via JavaScript.
Plus précisément, la page se charge initialement avec un nombre fixe d’éléments de cartes vidéo à l’intérieur d’un élément HTML .head-cards: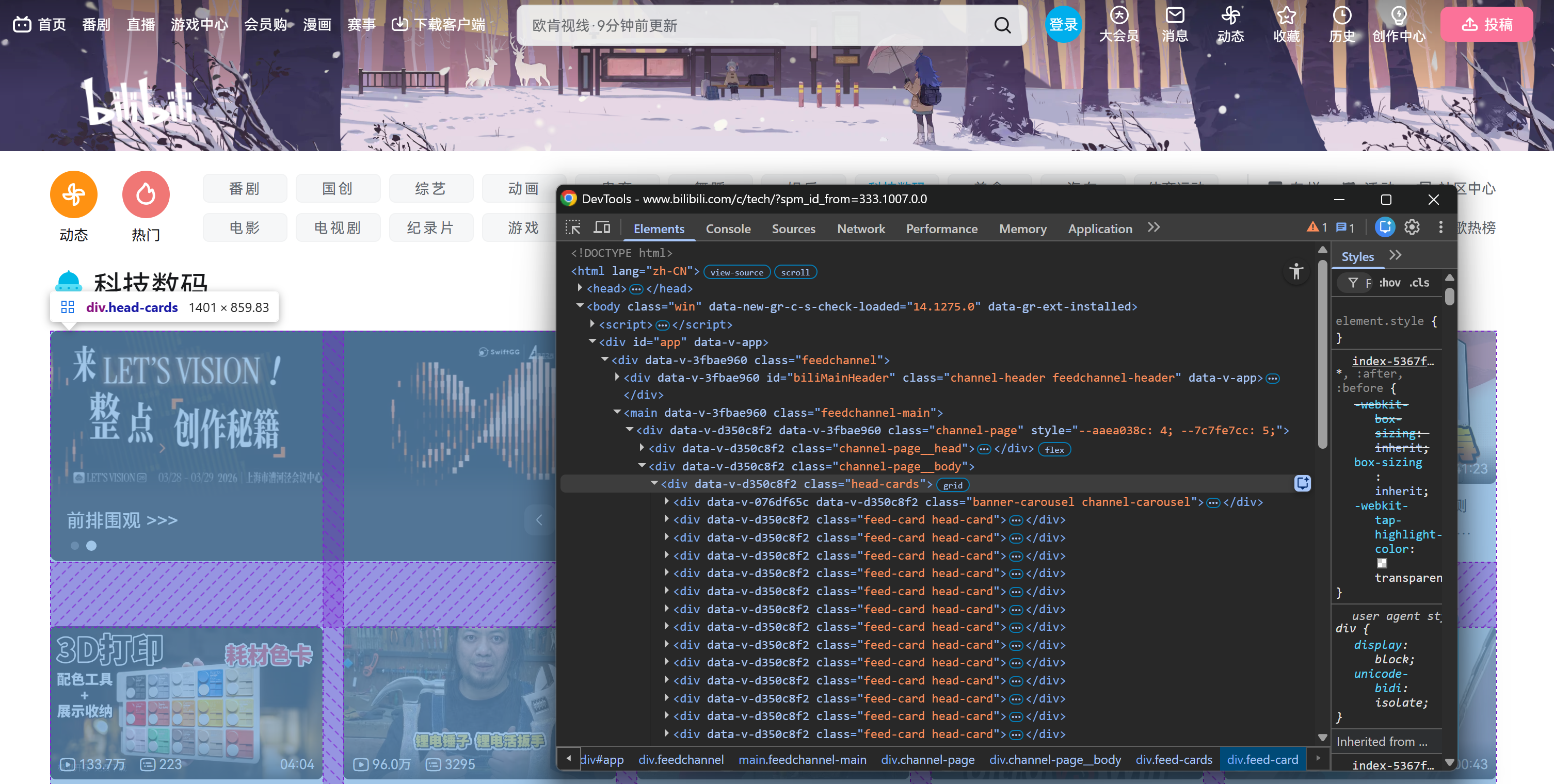
Après avoir fait défiler la page vers le bas, un conteneur .feed-cards est ajouté à la page. Cette section est remplie dynamiquement avec de nouvelles cartes vidéo à mesure que vous continuez à faire défiler la page :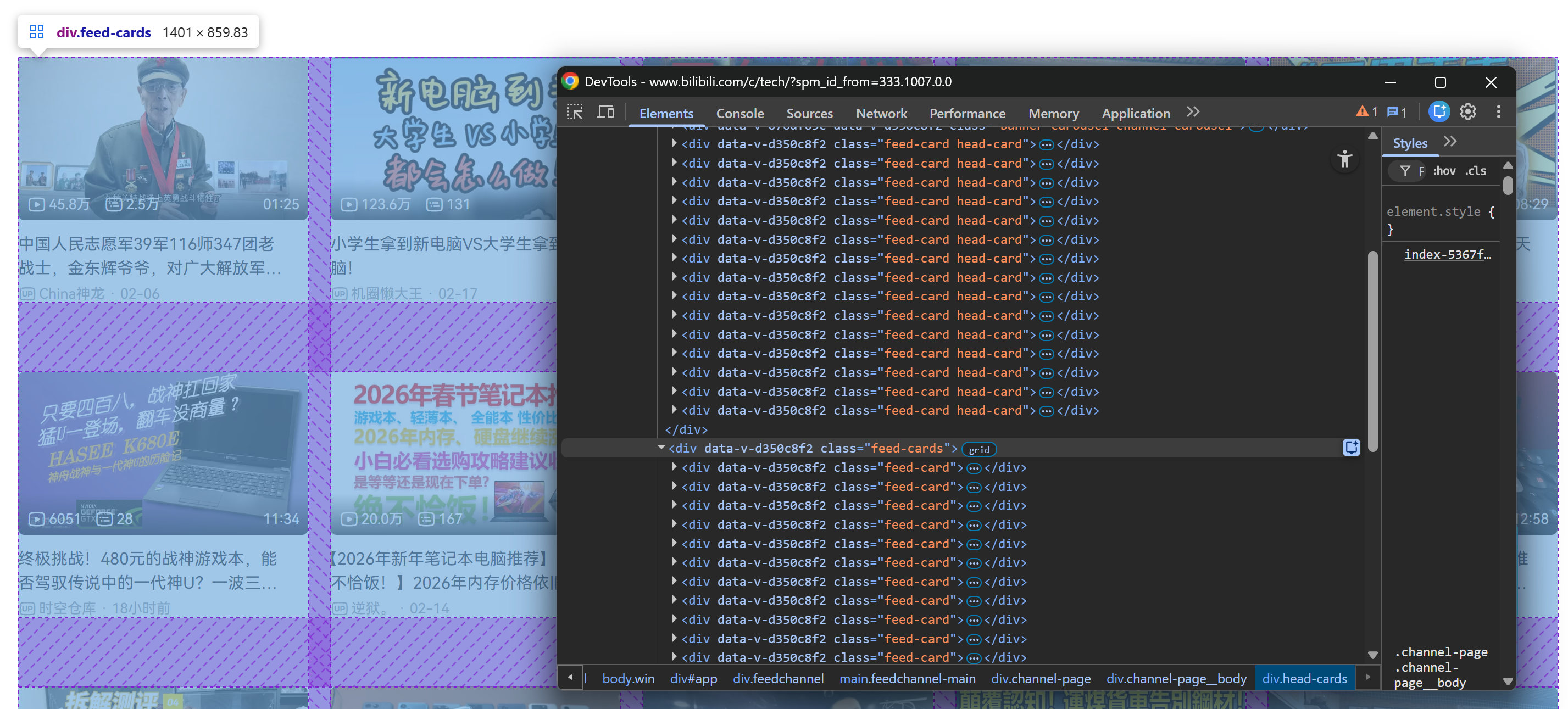
Ce qui importe ici, c’est que toutes les cartes vidéo (qu’elles soient présentes de manière statique lors du chargement initial de la page ou chargées dynamiquement pendant le défilement) peuvent être sélectionnées via ce sélecteur CSS :
.feed-cardDans ce tutoriel sur le scraping de Bilibili, supposons que vous souhaitiez récupérer au moins 50 vidéos. Pour y parvenir, vous devez simuler plusieurs interactions de défilement. Playwright ne fournit pas d’API spécifique pour le défilement, vous devrez donc exécuter un simple script JavaScript directement dans le contexte de la page :
for _ in range(3):
# Autoriser le chargement différé
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Autoriser le chargement différé
await asyncio.sleep(2) Cette boucle exécute window.scrollTo() trois fois, faisant défiler la page de haut en bas à chaque itération. Les appels asyncio.sleep() sont importants car :
- Elles rendent le comportement de défilement plus naturel.
- Ils réduisent le risque de déclencher des mécanismes anti-bot.
- Ils laissent le temps au contenu chargé de manière différée de s’afficher complètement avant le défilement suivant.
Comme les cartes vidéo sont chargées dynamiquement, vous ne pouvez pas supposer qu’elles sont présentes immédiatement après le défilement. Vous devez plutôt attendre explicitement que la 50e carte soit attachée au DOM. Dans Playwright, procédez comme suit :
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")Ce code crée un localisateur Playwright pour le 50e élément .feed-card (nth(49) car l’indexation commence à 0). Ensuite, il attend que cet élément soit attaché au DOM avec wait_for().
Maintenant, si vous exécutez le script en mode headful (headless=False), vous verrez le navigateur faire défiler trois fois de manière autonome :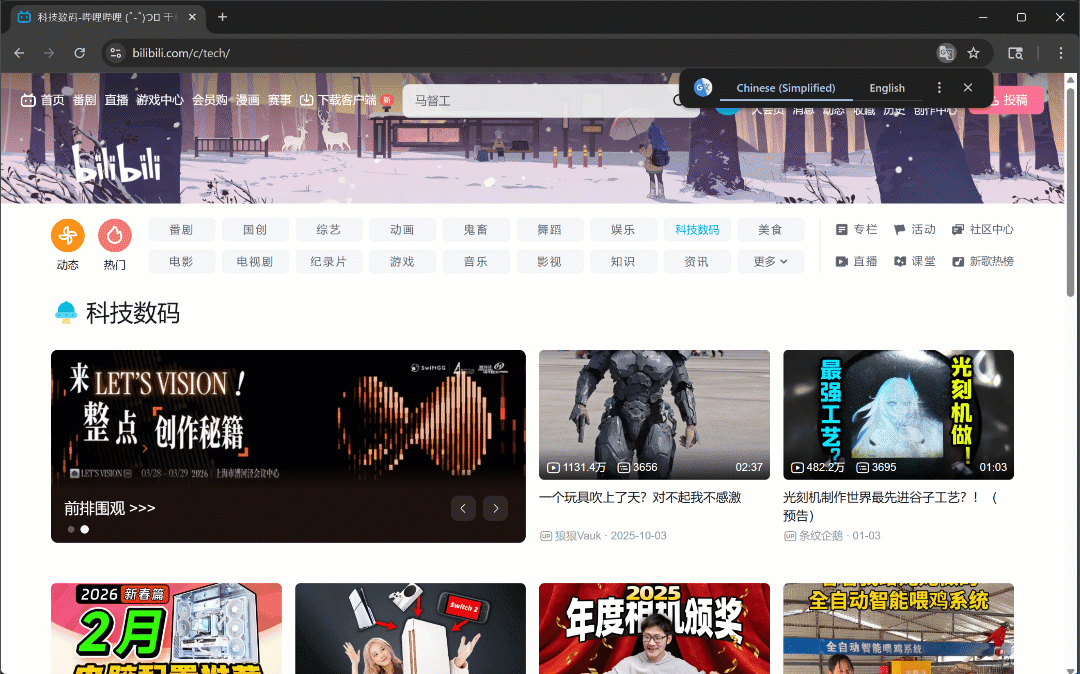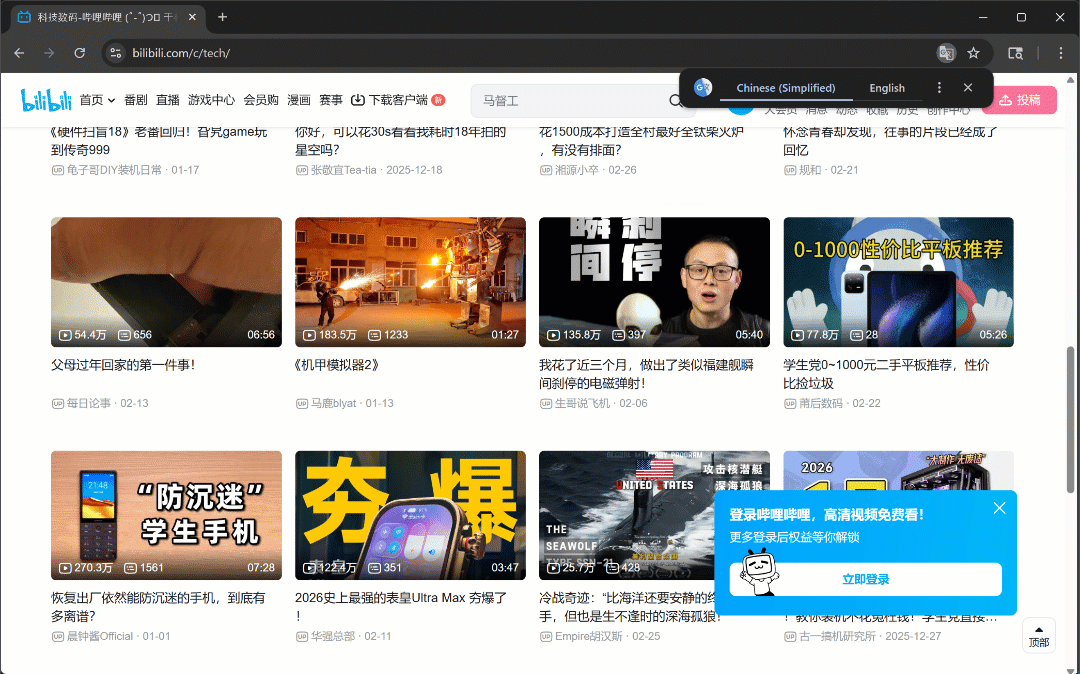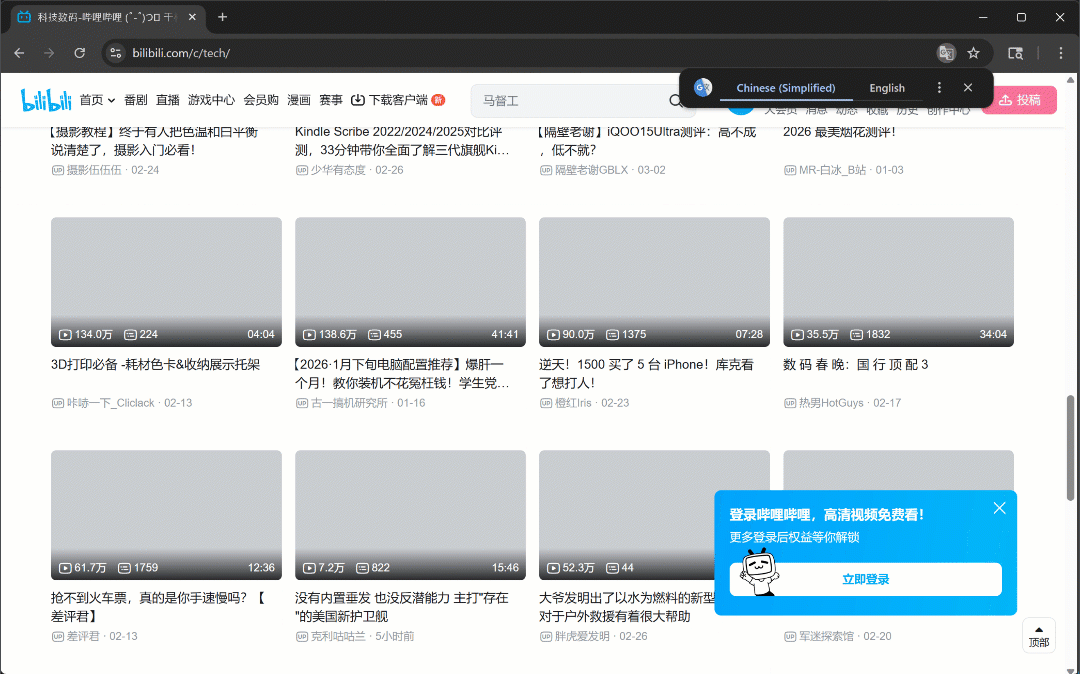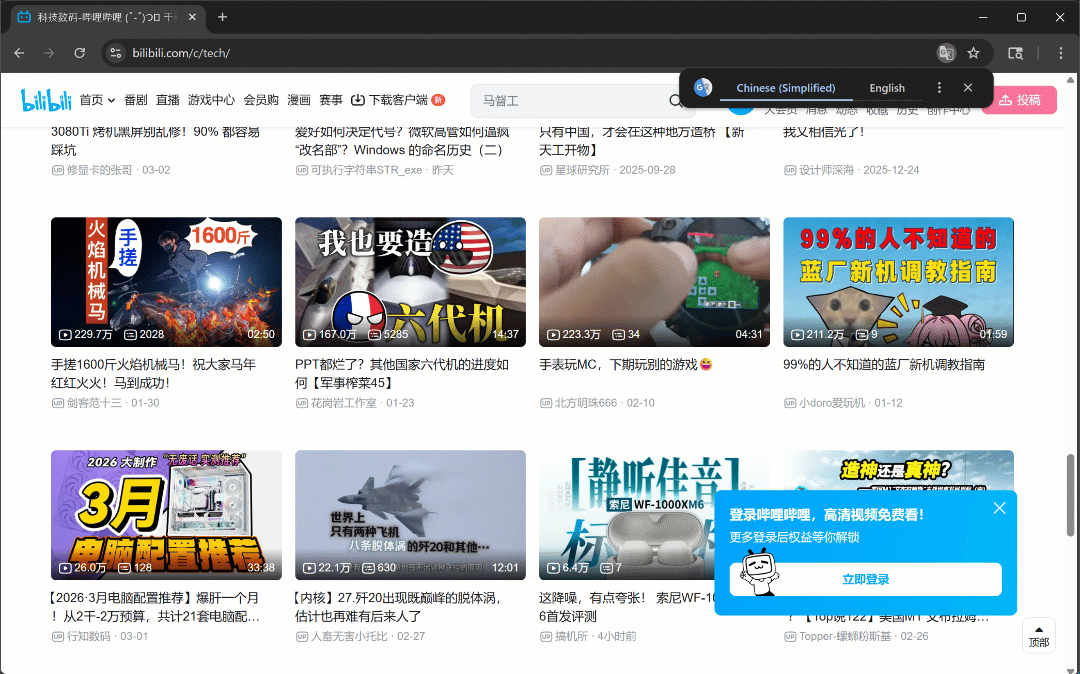
Comme prévu, de nouvelles cartes vidéo se chargent après chaque défilement.
Après cette étape, vous pouvez être sûr qu’au moins 50 cartes vidéo sont présentes sur la page. Fantastique !
Étape n° 4 : familiarisez-vous avec la structure des cartes vidéo
Pour extraire les bonnes données, vous devez d’abord comprendre comment chaque carte vidéo est structurée dans le DOM.
Commencez par cliquer avec le bouton droit de la souris sur l’une des cartes vidéo dans la section .head-cards et inspectez-la dans les outils de développement du navigateur :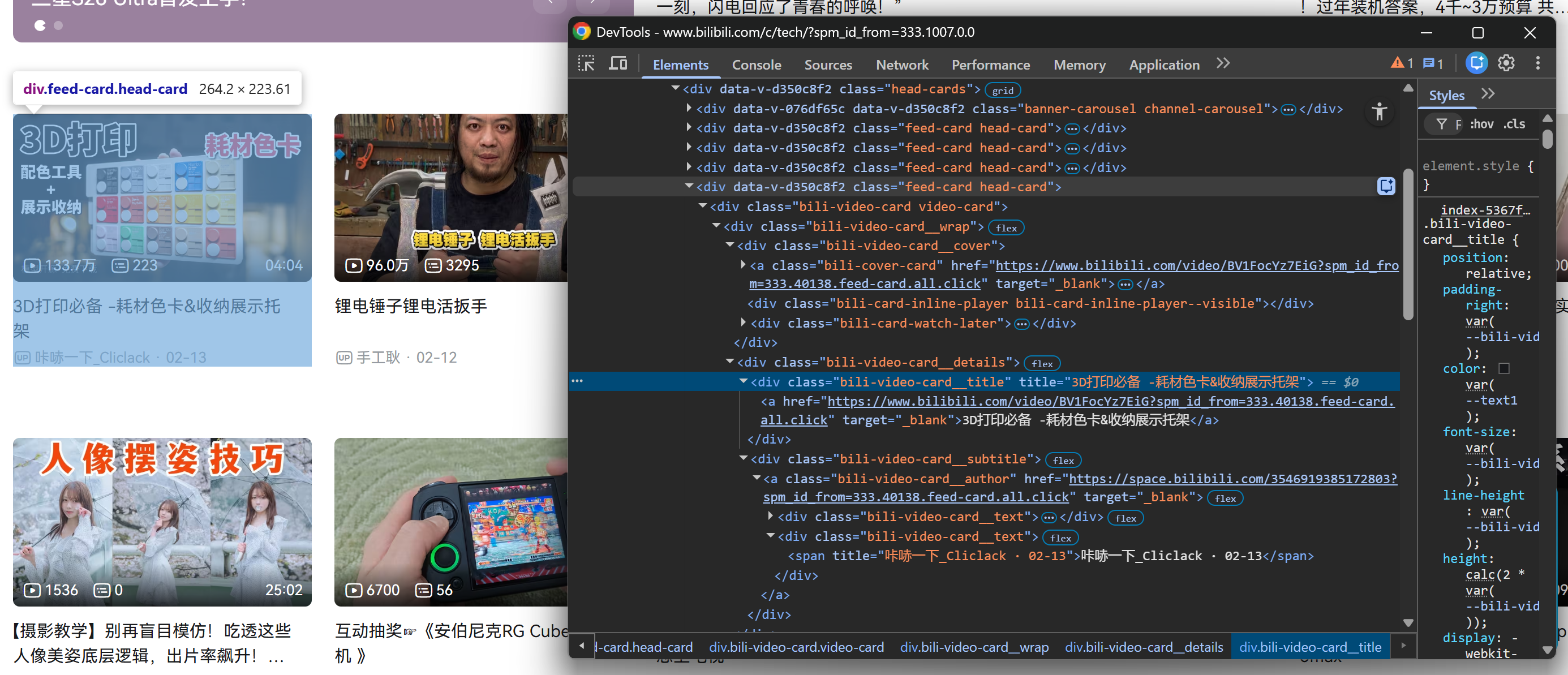
Répétez ensuite le même processus pour une carte vidéo dans la section .feed-cards chargée :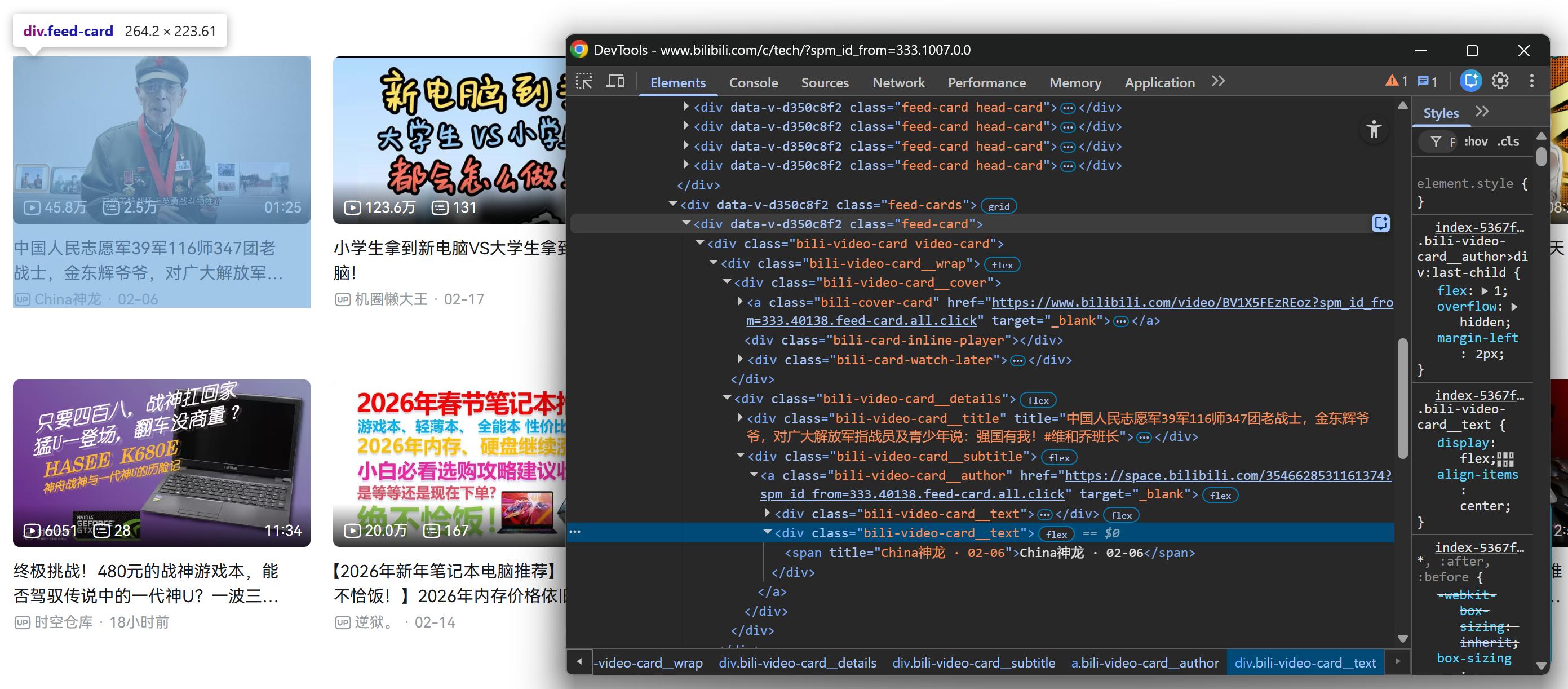
Heureusement, tous les éléments .feed-card partagent la même structure interne. Cela signifie que vous n’avez pas besoin de faire la distinction entre les cartes vidéo chargées lors du rendu initial de la page et celles chargées dynamiquement après le défilement. Vous pouvez toutes les cibler à l’aide des mêmes sélecteurs !
Remarquez comment, à partir de chaque carte vidéo, vous pouvez collecter :
- Le titre de la vidéo à partir de l’élément
.bili-video-card__title a. - L’URL de la vidéo à partir de l’attribut
hrefdu même nœud<a>title. - Le sous-titre brut (qui contient le nom de l’auteur + la date de publication) à partir de
.bili-video-card__subtitle span[title]. - L’URL du profil de l’auteur à partir de l’élément
.bili-video-card__author.
Parfait ! Maintenant que vous comprenez la structure DOM, l’étape suivante consiste à traduire ces connaissances en une logique de scraping programmatique des données Bilibili.
Étape n° 5 : extraire les données vidéo
N’oubliez pas que la page cible contient plusieurs cartes vidéo. Vous devez donc d’abord créer une structure de données pour stocker les résultats récupérés. Une liste est parfaite pour cela :
videos = []Ensuite, parcourez toutes les cartes vidéo et appliquez la logique d’extraction décrite précédemment :
for i in range(feed_card_count):
# Obtenir la carte vidéo actuelle à partir de laquelle extraire les données
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Stocker les données récupérées
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)L’extrait ci-dessus parcourt chaque fiche vidéo et :
- Extrait le titre, l’URL de la vidéo, les sous-titres bruts et l’URL du profil de l’auteur.
- Analyse la chaîne de sous-titres (qui suit le format
« <NOM_DE_L'AUTEUR> · <DATE> ») pour extraire séparément le nom de l’auteur et la date de la vidéo. - Construit un dictionnaire
vidéostructuré et l’ajoute à la listedes vidéos.
À la fin de la boucle « for », la liste des vidéos contiendra plus de 50 objets vidéo Bilibili structurés. Génial !
Étape n° 6 : exporter les données récupérées
Pour faciliter le traitement des données récupérées, exportez-les dans un fichier videos.json:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)Si vous exécutez scraper.py maintenant, cela devrait générer un fichier videos.json contenant des données vidéo Bilibili structurées, comme ceci :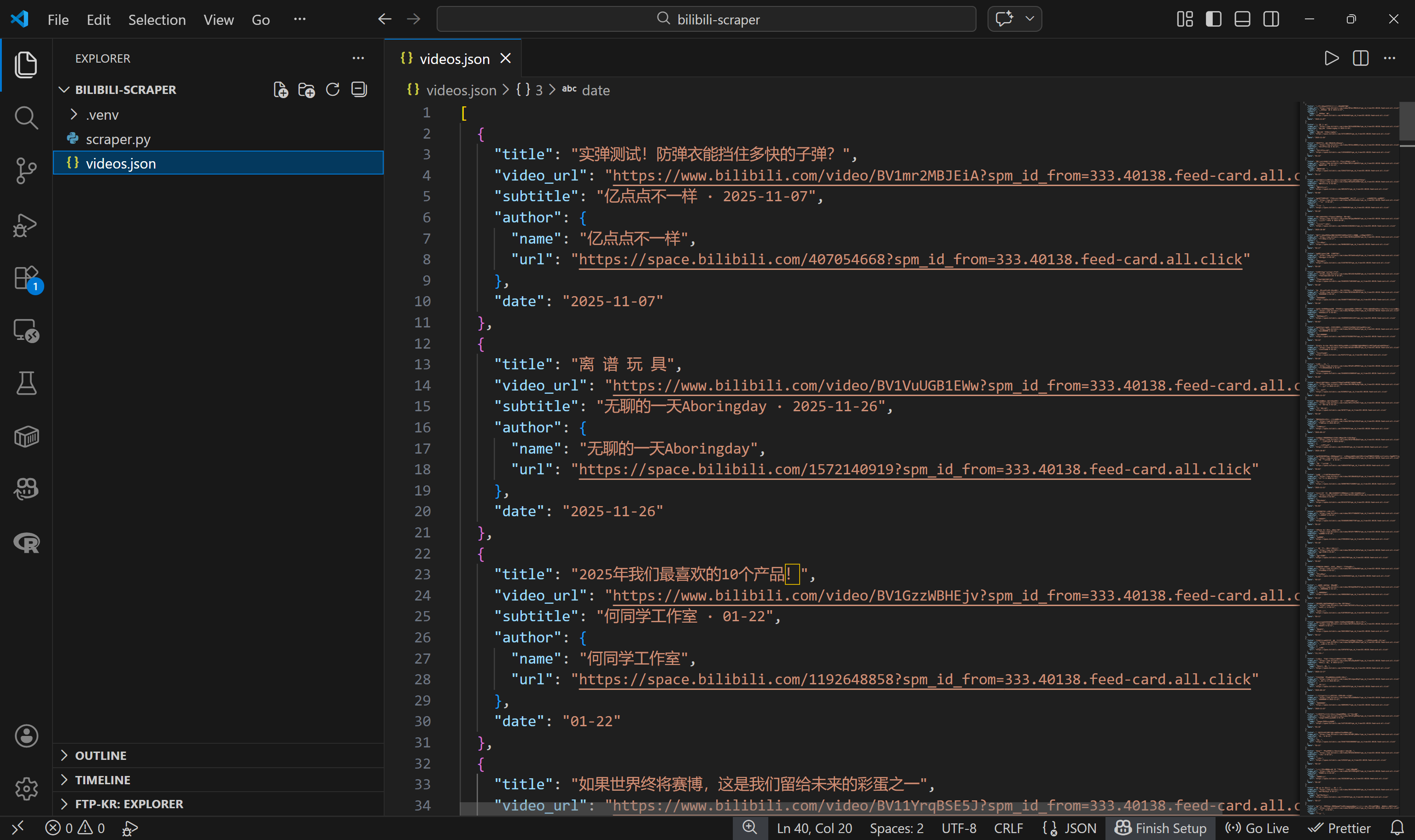
Mission accomplie ! Vous avez commencé avec une page contenant de nombreuses fiches vidéo et vous disposez désormais de leurs métadonnées stockées dans un fichier JSON structuré.
Si votre objectif est simplement de scraper Bilibili, le tutoriel pourrait s’arrêter ici (assurez-vous simplement de vérifier la dernière étape pour obtenir le script complet). Si vous souhaitez aller plus loin et télécharger les vidéos elles-mêmes, continuez à lire…
Étape n° 7 : Préparez-vous à télécharger les vidéos Bilibili
La façon la plus simple de télécharger des vidéos Bilibili à partir des URL que vous avez récupérées précédemment est d’utiliser yt-dlp.
yt-dlp est un téléchargeur audio/vidéo riche en fonctionnalités qui prend en charge des centaines de sites web, dont Bilibili. Il peut être utilisé à la fois à partir de la ligne de commande et via une API Python programmatique. Ici, nous allons l’exploiter de manière programmatique via son API Python.
Une fois votre environnement virtuel activé, installez yt-dlp:
pip install yt-dlpAjoutez ensuite un nouveau fichier appelé video-downloader.py à la racine de votre projet :
bilibili-Scraper/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------Ce fichier contiendra la logique de téléchargement de vidéos Bilibili alimentée par yt-dlp.
Le script video-downloader.py doit :
- Lire le fichier
videos.json. - Extraire l’URL
vidéo (video_url)pour chaque vidéo. - Utiliser la classe
YoutubeDLdeyt_dlppour télécharger les fichiers vidéo.
Voici l’implémentation :
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Charger les données vidéo à partir du fichier JSON d'entrée
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"{len(videos)} vidéos chargées depuis {INPUT_FILE}n")
# S'assurer que le dossier de sortie existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Téléchargement : {video.get('title')}")
try:
ydl.download([video_url])
print(f"Vidéo #{index} téléchargéen")
except Exception as e:
print(f"Échec du téléchargement de la vidéo #{index} : {e}n")Waouh ! Moins de 35 lignes de code ont suffi pour atteindre l’objectif.
Étape n° 8 : télécharger les fichiers vidéo
Assurez-vous que ffmpeg est installé localement, puis exécutez le script video-downloader.py. Dans le terminal, vous devriez voir quelque chose comme ceci :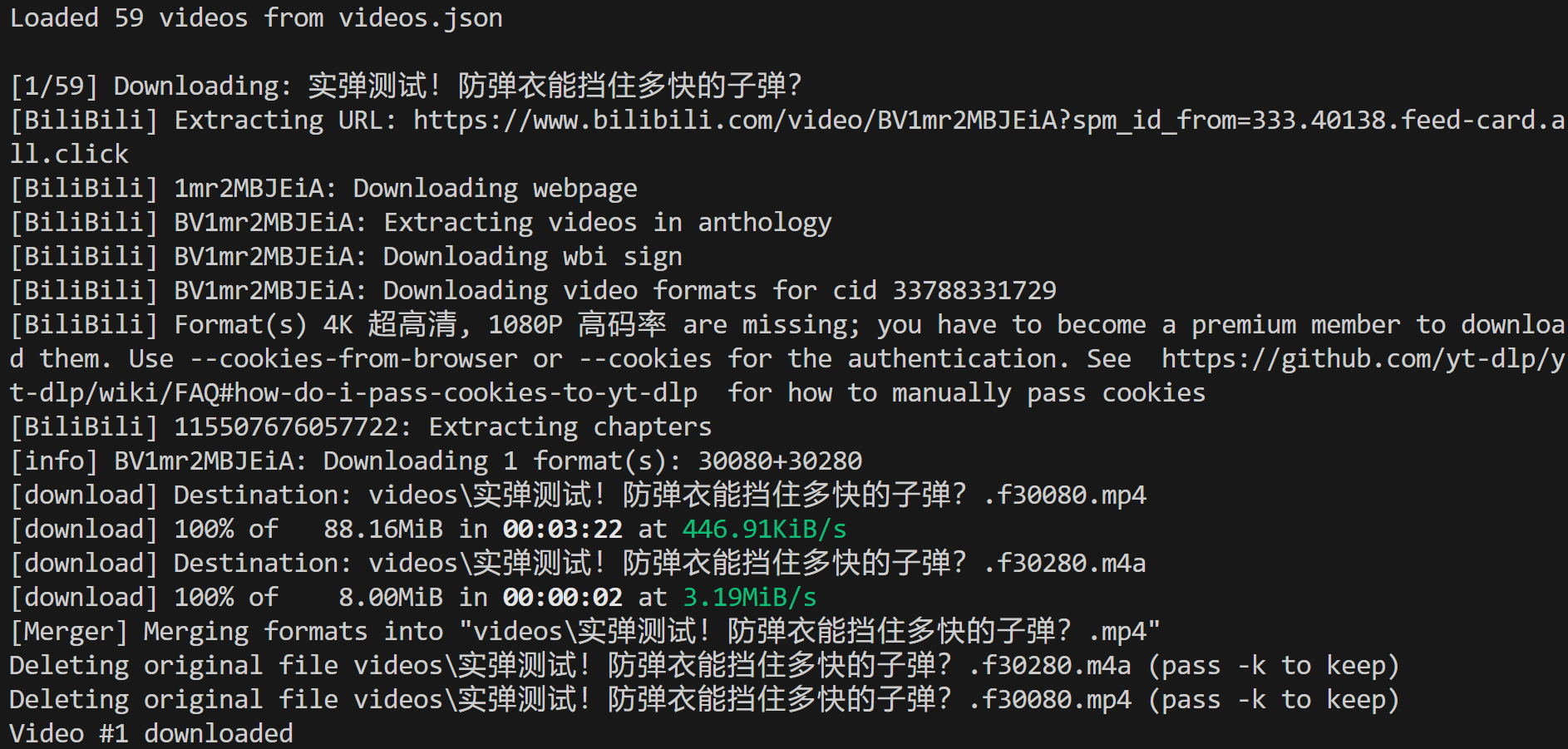
Cela indique que 59 vidéos ont été chargées à partir du fichier d’entrée videos.json et que la première a été téléchargée avec succès vers le chemin d’accès local :
./videos/实弹测试!防弹衣能挡住多快的子弹?.mp4Dans Visual Studio Code, vous verrez le fichier vidéo MP4 apparaître dans ce chemin d’accès précis :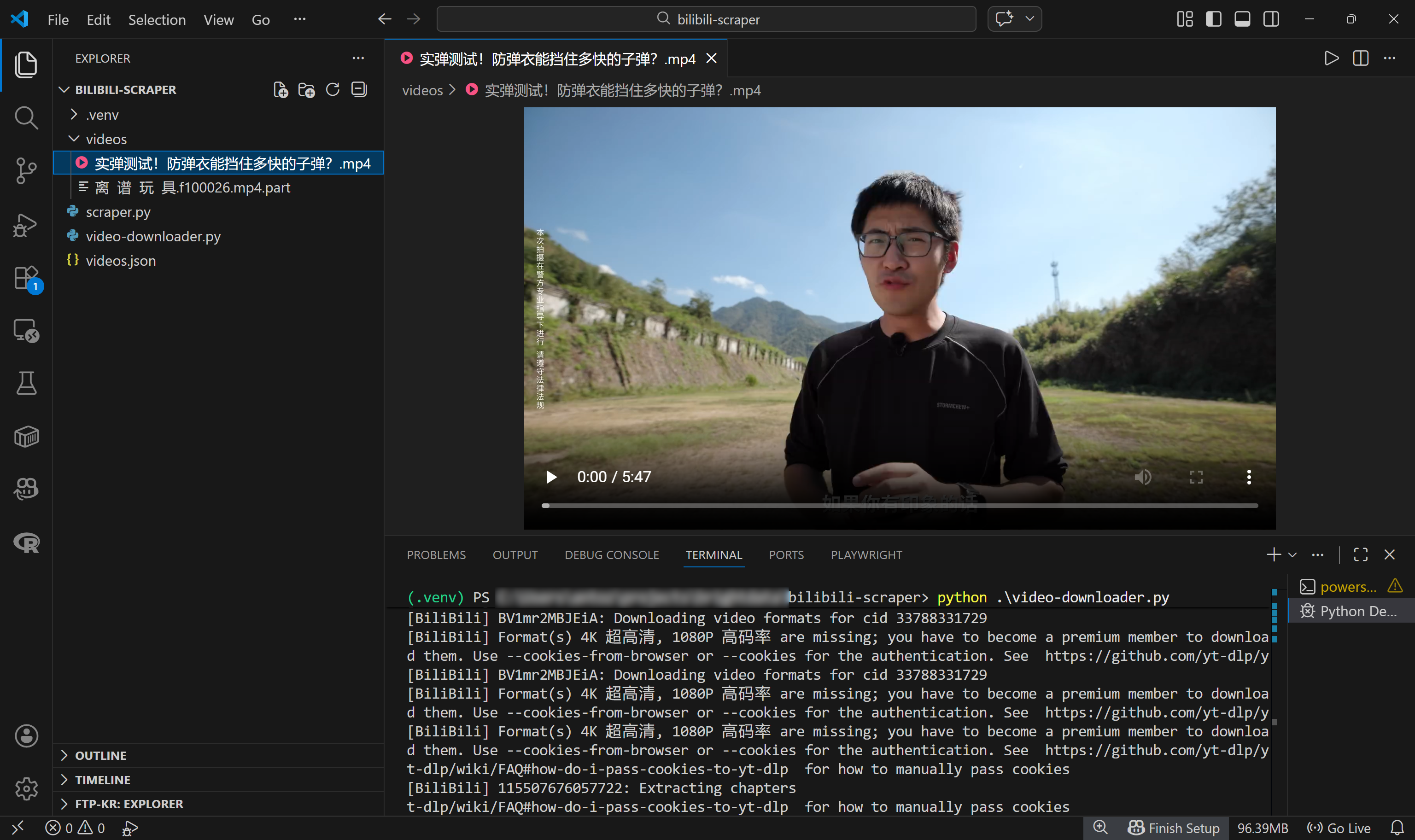
Incroyable ! Vous disposez désormais d’un système Bilibili entièrement automatisé qui non seulement découvre de nouvelles vidéos, mais les télécharge également. Grâce à ces fichiers, vous pouvez même former des modèles d’IA via un pipeline ML multimodal.
Étape n° 9 : code final
Le fichier scraper.py contiendra le code suivant :
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# Lancer une instance Chromium contrôlée en mode headful
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# La page Bilibili « Tech » cible
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Accéder à la page cible
await page.goto(target_bilibili_page)
# Faire défiler la page entière 3 fois
for _ in range(3):
# Autoriser le chargement différé
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Autoriser le chargement différé
await asyncio.sleep(2)
# Attendre que le 50e élément de carte vidéo soit attaché au DOM
cinquantième_carte = page.locator(".feed-card").nth(49)
attendre cinquantième_carte.wait_for(state="visible")
# Sélectionner toutes les cartes de flux via le localisateur
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count} cartes de flux chargées.")
# Où stocker les données récupérées
videos = []
# Appliquer la logique de récupération des données Bilili à chaque carte vidéo
for i in range(feed_card_count):
# Obtenir la carte vidéo actuelle à partir de laquelle extraire les données
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Stocker les données récupérées
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# Fermer le navigateur et libérer ses ressources
await browser.close()
# Exporter les données récupérées vers un fichier JSON
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
print(f"{len(videos)} vidéos Bilibili récupérées exportées vers videos.json")
if __name__ == "__main__":
asyncio.run(main())Lancez-le avec :
python Scraper.pyCela générera un fichier videos.json contenant les données vidéo Bilibili récupérées. Vous pouvez ensuite télécharger ces vidéos à l’aide du script video-downloader.py:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Charger les données vidéo à partir du fichier JSON d'entrée
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Loaded {len(videos)} videos from {INPUT_FILE}n")
# S'assurer que le dossier de sortie existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Téléchargement : {video.get('title')}")
try:
ydl.download([video_url])
print(f"Vidéo #{index} téléchargéen")
except Exception as e:
print(f"Échec du téléchargement de la vidéo #{index} : {e}n")Exécutez-le avec :
python video-downloader.pyLe résultat sera un dossier ./videos contenant les fichiers MP4 pour chaque vidéo Bilibili découverte.
Et voilà ! Vous venez d’apprendre à créer un Scraper Bilibili et à l’utiliser pour alimenter un téléchargeur avec les données vidéo récupérées. Ce processus vous aide à récupérer les fichiers vidéo réels pour l’entraînement de l’IA ou tout autre cas d’utilisation.
Étapes suivantes
Maintenant que vous disposez à la fois de métadonnées structurées et des fichiers vidéo réels, vous pouvez transmettre ces données à un pipeline de formation IA. Par exemple, vous pouvez extraire des images pour des tâches de vision par ordinateur, générer des transcriptions pour le réglage fin du modèle NLP, analyser des signaux audio ou créer des systèmes de recommandation basés sur le contenu vidéo et les métadonnées. La combinaison des titres, des auteurs, des dates et des fichiers vidéo bruts vous offre un ensemble de données multimodales riche, prêt à être expérimenté.
De plus, pour accélérer la phase de téléchargement, envisagez de paralléliser le processus afin que plusieurs vidéos soient téléchargées simultanément. Cette approche permet d’utiliser pleinement votre bande passante disponible, ce qui se traduit par des temps de téléchargement plus rapides.
Une solution prête à l’emploi pour le scraping de Bilibili : obtenez des données vidéo pour l’IA
Si vous exécutez le script de téléchargement sur un grand nombre de vidéos, vous finirez par rencontrer des erreurs telles que :
Impossible de télécharger la page web : erreur HTTP 412 : condition préalable non remplie (causée par <HTTPError 412: Precondition Failed>)Cela se produit parce que Bilibili dispose de protections anti-bot. Lorsque la plateforme détecte un trafic suspect (tel qu’un nombre trop important de requêtes automatisées provenant de la même adresse IP), elle commence à renvoyer une réponse 412 Precondition Failed.
La page d’erreur se présente comme suit :
Ce n’est là qu’un des défis auxquels vous devez faire face lorsque vous scrapez Bilibili. Parmi les autres problèmes courants, citons les changements structurels des pages cibles, la détection basée sur les empreintes digitales, etc. Si une configuration personnalisée Playwright + yt-dlp fonctionne bien pour les projets à petite échelle, sa maintenance à long terme peut s’avérer complexe et fragile.
Pour scraper Bilibili de manière fiable à grande échelle, vous avez besoin d’une infrastructure plus robuste qui gère la rotation des adresses IP, les empreintes digitales des navigateurs, la Résolution de CAPTCHA et les réessais automatiques. C’est précisément ce qu’offre le Bilibili Scraper de Bright Data.
Cette API de scraping web, également disponible sous forme de Scraper sans code, récupère les titres des vidéos, les dates de mise en ligne, le nombre de vues, les likes, les commentaires, les favoris, la durée, le nom des uploadeurs, les descriptions, les URL, etc. Tout cela en contournant automatiquement les mécanismes anti-bot pour vous.
Ce qui rend Bilibili Scraper unique, c’est qu’il fonctionne sur une infrastructure Proxy avec plus de 150 millions d’adresses IP dans 195 pays, atteignant un temps de disponibilité de 99,99 %, un taux de réussite de 99,95 % et prenant en charge une concurrence illimitée. Cela permet des scénarios de scraping à grande échelle, au niveau de l’entreprise, ce qui est fondamental étant donné que la formation multimodale en IA nécessite des volumes massifs de données vidéo.
Après avoir récupéré les URL des vidéos, intégrez l’API Web Unlocker de Bright Data dans les workflows automatisés yt-dlp pour éviter les erreurs 412 et télécharger des vidéos sans blocage. Grâce à Bright Data, vous pouvez oublier les limites de débit, les blocages ou les échecs yt-dlp pour obtenir plus de vidéos pour former vos modèles d’IA/ML.
Conclusion
Dans cet article, vous avez découvert le type de données que vous pouvez extraire de Bilibili et les principaux cas d’utilisation qu’il prend en charge. L’un des scénarios les plus intéressants est la formation de l’IA sur des données vidéo. Avec des centaines de millions de vidéos disponibles sur la plateforme, Bilibili représente une source massive de contenu multimédia accessible au public.
Le processus commence par un Scraper Bilibili que vous avez appris à construire étape par étape. Celui-ci collecte des métadonnées vidéo structurées, y compris les URL des vidéos. Vous pouvez ensuite transmettre ces URL à un workflow alimenté par yt-dlp pour télécharger les fichiers vidéo réels, comme le montre ce guide.
Bright Data prend en charge le scraping de Bilibili grâce à un Scraper dédié et à des options d’intégration directe yt-dlp pour des téléchargements fiables et ininterrompus. Pour plus d’informations, consultez nos solutions d’accès à des données vidéo à grande échelle pour la formation LLM.
Inscrivez-vous dès aujourd’hui à Bright Data et découvrez nos solutions de collecte de données vidéo !





