
Dans ce tutoriel, vous apprendrez :
- Ce qu’est MLflow et les capacités de suivi qu’il offre.
- Pourquoi la création d’expériences ML/IA autour de jeux de données extraits via le Scraping web est une approche gagnante.
- Comment effectuer le suivi d’expériences à l’aide d’un jeu de données extraits avec MLflow.
C’est parti !
Qu’est-ce que MLflow ?
MLflow est une plateforme open source permettant de gérer l’ensemble du cycle de vie du machine learning. Elle offre de nombreuses fonctionnalités et une API riche pour suivre, reproduire et déployer efficacement des modèles.
MLflow prend en charge à la fois les workflows traditionnels d’apprentissage automatique et d’apprentissage profond, en proposant des outils pour l’expérimentation, la gestion des versions, l’évaluation et le déploiement. Tout cela de manière reproductible et collaborative.
MLflow est indépendant du langage, fonctionne avec Python, R et Java, et prend en charge les environnements locaux, cloud et gérés. Cela le rend indépendant des fournisseurs et très flexible. De plus, il conserve son caractère open source, avec son référentiel GitHub qui compte plus de 24 000 étoiles.
Les principales fonctionnalités de MLflow sont les suivantes :
- Suivi: enregistrement des expériences, suivi des paramètres, des métriques, des versions de code et des artefacts.
- Modèles: standardisation du packaging des modèles pour le déploiement sur différentes plateformes.
- Registre des modèles: référentiel centralisé pour la gestion des versions, les transitions entre les étapes et les annotations des modèles.
- Projets: packaging de code de science des données réutilisable pour plus de cohérence et de reproductibilité.
- Évaluation de l’IA/LLM: tracez, comparez et évaluez les résultats de l’IA générative ou du LLM.
- Intégration et journalisation automatique: fonctionne avec scikit-learn, TensorFlow, PyTorch, OpenAI et bien d’autres, automatisant la journalisation.
Pour en savoir plus, consultez la documentation officielle.
Pourquoi les jeux de données contenant des données web scrapées sont-ils idéaux pour expérimenter avec MLflow ?
Lors de la création de pipelines ML/IA, la qualité et la variété de vos jeux de données sont généralement déterminantes pour la réussite de vos expériences. Les données web scrapées, de par leur nature, offrent à la fois diversité et échelle. Ce sont les deux ingrédients principaux pour une expérimentation significative.
Contrairement aux jeux de données de petite taille ou synthétiques, les jeux de données dérivés du Web capturent les distributions réelles, les cas limites et la variabilité naturelle. Ces aspects rendent vos modèles plus robustes et vos expériences MLflow plus informatives. C’est pourquoi les données Web sont généralement considérées comme l’une des meilleures sources de données.
Bright Data se distingue comme le meilleur fournisseur de Jeux de données. Sa place de marché propose des Jeux de données structurés prêts pour le ML et l’IA couvrant plus de 150 domaines, du commerce électronique et de la vente au détail aux médias sociaux et aux voyages. Chaque Jeux de données contient des millions d’enregistrements, garantissant à la fois l’étendue et la profondeur.
Ces jeux de données sont régulièrement mis à jour, reflétant la nature dynamique du web, afin que vos workflows ML/IA puissent être formés et évalués à partir des informations les plus récentes. Cette combinaison d’échelle, de fraîcheur et de formatage prêt pour le ML rend les jeux de données Bright Data parfaits pour des expérimentations solides, reproductibles et à fort impact avec MLflow. Explorez les jeux de données disponibles sur la place de marché !
Comment effectuer un suivi des expériences à l’aide de MLflow et d’un jeu de données Bright Data
Dans cette section guidée, vous apprendrez comment effectuer un suivi d’expériences MLflow. Vous construirez notamment un pipeline d’apprentissage automatique à l’aide de l’ensemble de données Bright Data Amazon Best Product Seller.
L’objectif de ce pipeline est de former un modèle qui prédit le prix final d’un produit en fonction de sa note, du nombre d’avis et de la marque. L’hypothèse sous-jacente est que ces caractéristiques contiennent des signaux prédictifs corrélés au prix du produit.
Le pipeline combine le prétraitement avec un modèle Random Forest et évalue ses performances. Tout au long du processus, MLflow suivra les métriques, les artefacts, l’ensemble de données et l’utilisation des ressources système.
Suivez les étapes ci-dessous !
Prérequis
Pour suivre ce tutoriel, vous devez disposer des éléments suivants :
- Python 3.10 ou supérieur installé localement.
- Un compte Bright Data pour accéder aux Jeux de données récupérés.
- Des connaissances de base sur la formation de modèles ML prédictifs à l’aide de scikit-learn.
Étape n° 1 : configuration du projet
Commencez par ouvrir votre terminal et créez un nouveau dossier pour votre projet d’expérience MLflow :
mkdir mlflow-experiment-trackingEnsuite, accédez au répertoire du projet et créez un environnement virtuel Python à l’intérieur :
cd mlflow-experiment-tracking
python -m venv .venvChargez maintenant le dossier du projet dans votre IDE Python préféré. Nous vous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un nouveau fichier nommé experiment.py à la racine de votre répertoire de projet. La structure de votre projet devrait ressembler à ceci :
mlflow-experiment-tracking/
├── .venv/
└── experiment.pyDans le terminal, activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateUne fois l’environnement virtuel activé, installez les dépendances du projet :
pip install mlflow pandas scikit-learn psutil nvidia-ml-pyLes bibliothèques requises sont les suivantes :
mlflow: pour le suivi de bout en bout des expériences, l’observabilité et la journalisation des modèles et des métriques ML.pandas: charge, nettoie et manipule les données tabulaires provenant de JSON/CSV pour l’entraînement des modèles.scikit-learn: construit des pipelines ML, gère le prétraitement, forme les modèles et calcule les métriques d’évaluation.psutil, nvidia-ml-py: requis par MLflow pour surveiller les ressources CPU et GPU et d’autres métriques système pendant les expériences.
Ensuite, dans experiment.py, importez toutes les bibliothèques requises avec :
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputerBravo ! Votre environnement de développement Python est désormais prêt à suivre les expériences ML et IA dans MLflow.
Étape n° 2 : familiarisez-vous avec l’interface utilisateur MLflow
Pour vérifier que MLflow fonctionne, ouvrez un terminal avec votre environnement virtuel activé et lancez l’interface utilisateur MLflow:
mlflow uiLors du premier lancement, MLflow initialisera une base de données SQLite locale pour stocker les données d’expérimentation. Vous remarquerez notamment qu’un fichier mlflow.db est apparu dans le dossier de votre projet. Il s’agit de la base de données locale utilisée par SQLite.
Dans le terminal, vous verrez un journal comme celui-ci :
INFO : Uvicorn s'exécute sur http://127.0.0.1:5000 (appuyez sur CTRL+C pour quitter)Cela signifie que l’interface utilisateur est désormais en cours d’exécution. Ouvrez votre navigateur et rendez-vous sur http://127.0.0.1:5000/. Vous devriez voir :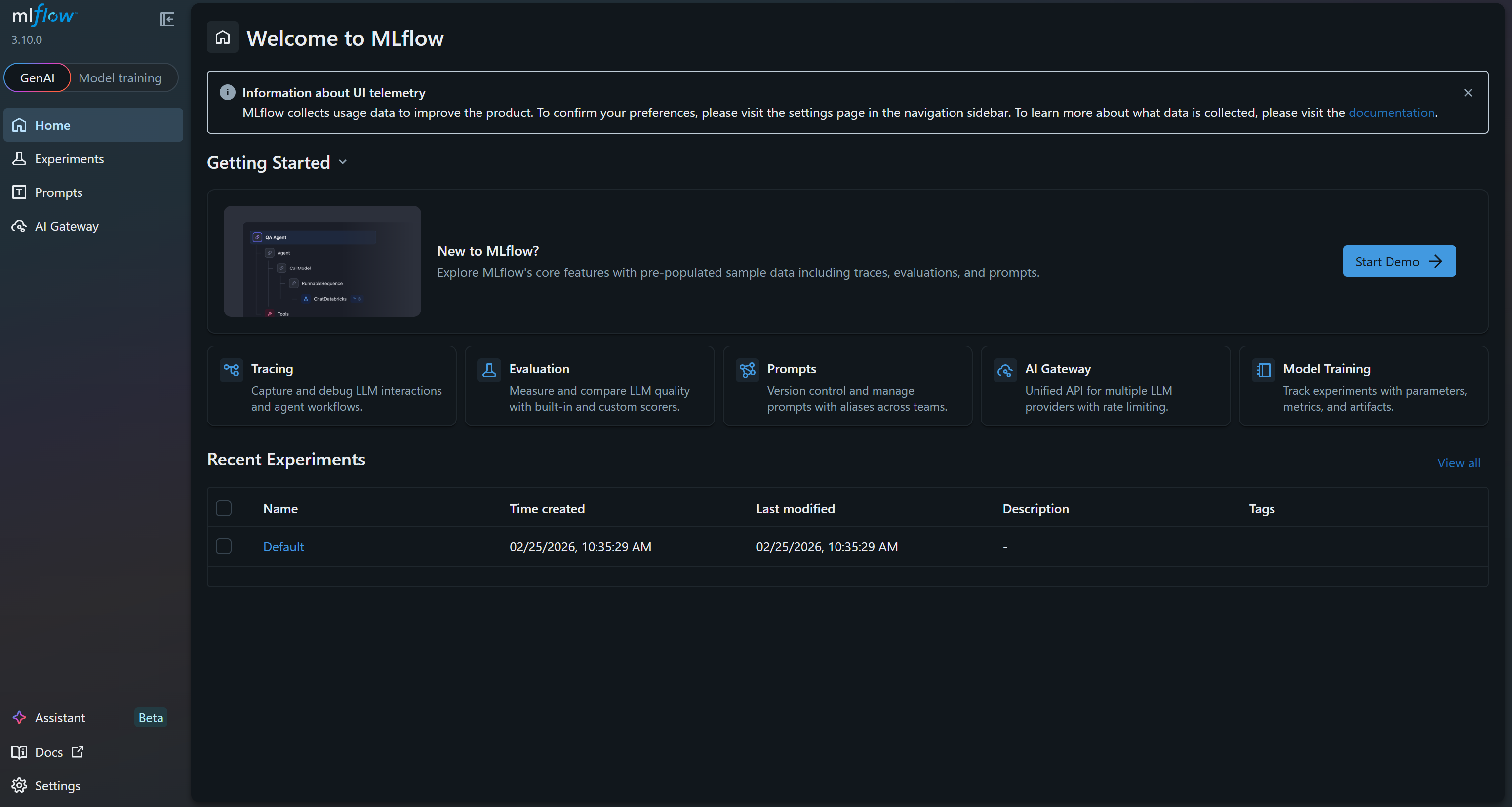
Il s’agit de l’interface utilisateur MLflow, où vous pouvez observer et suivre vos expériences. Prenez quelques minutes pour vous familiariser avec celle-ci en explorant les liens du menu et les fonctionnalités disponibles. Ici, vous pourrez surveiller efficacement les métriques, les journaux et les artefacts pendant vos projets ML. Super !
Étape n° 3 : activer les fonctionnalités de journalisation automatique et de traçage système de MLflow
Dans votre fichier experiment.ml, activez la journalisation des métriques système MLflow pour suivre l’utilisation du processeur, du disque, de la mémoire vive et d’autres métriques au niveau du système pendant l’entraînement.
# Activer la journalisation automatique des métriques système (CPU, mémoire, etc.)
mlflow.enable_system_metrics_logging()
# Enregistrer automatiquement les événements pour sklearn
mlflow.sklearn.autolog()
# Configurer la fréquence d'échantillonnage et d'enregistrement des métriques système
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1) Cet extrait active également la journalisation automatique afin que MLflow enregistre automatiquement les événements scikit-learn. Il définit ensuite l’intervalle d’échantillonnage des métriques système à 1 seconde afin de garantir une surveillance détaillée et fréquente.
Fantastique ! Votre application MLflow va désormais suivre les informations utiles relatives à votre expérience d’entraînement du modèle d’apprentissage automatique.
Étape n° 4 : récupérer l’ensemble de données source avec les données extraites de Bright Data
Vous disposez désormais d’une configuration MLflow prête à effectuer des expériences ML/IA. Il ne manque plus que la source de données pour entraîner votre modèle. Comme mentionné précédemment, nous utiliserons l’ensemble de données Amazon Best Sellers de Bright Data pour créer un modèle de prédiction des prix basé sur un pipeline Random Forest.
Vous devez d’abord récupérer l’ensemble de données source. Dans ce cas, il contient plus de 45 champs de données et couvre plus de 171 millions de produits Amazon les plus vendus.
Si vous n’avez pas encore de compte Bright Data, créez-en un. Sinon, connectez-vous. Dans le panneau de configuration de Bright Data, sélectionnez l’option de menu « Web Datasets » (Jeux de données Web). Ensuite, accédez à l’onglet « Dataset Marketplace » (Marché des jeux de données) :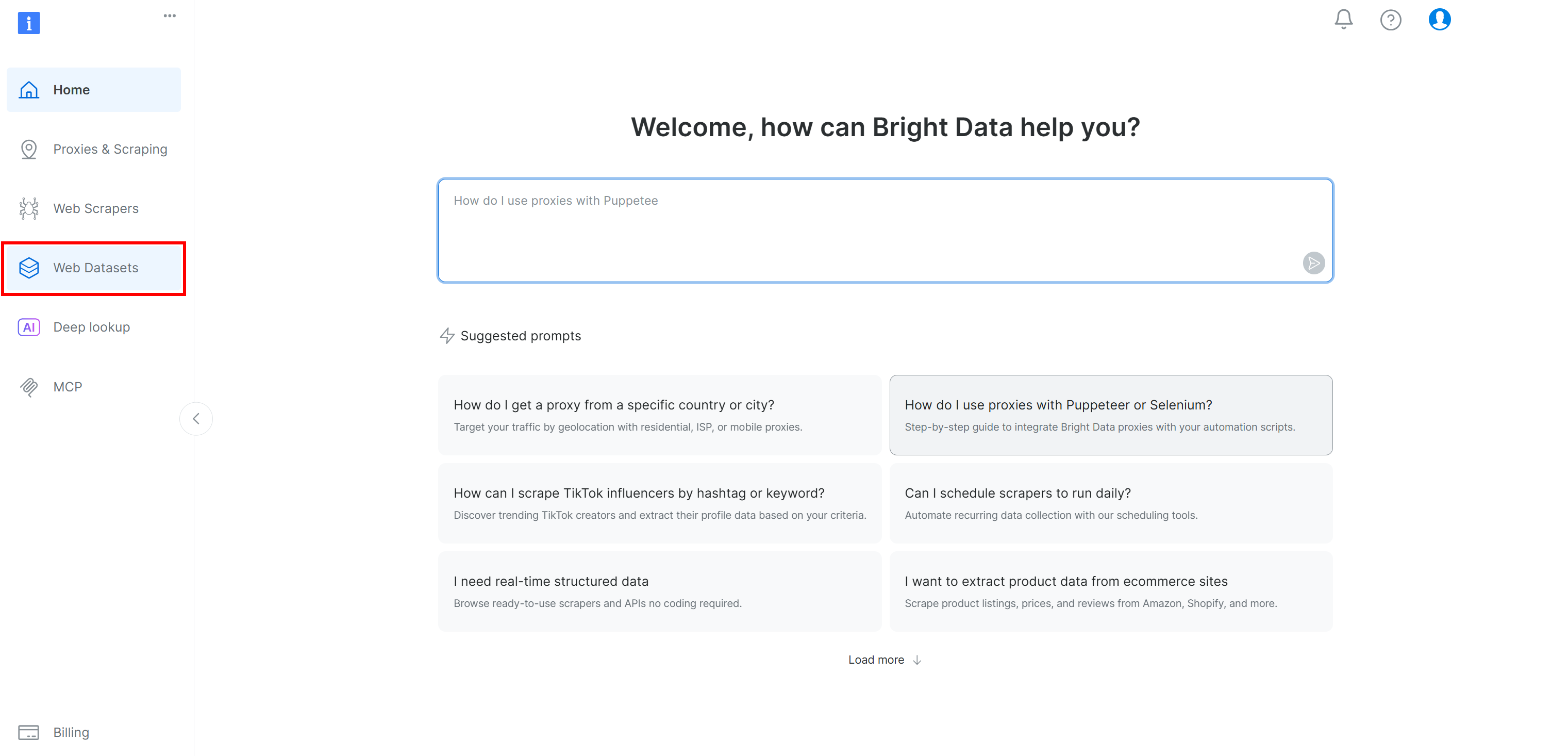
Accédez à l’onglet « Dataset marketplace » :
Vous accéderez à la page «Dataset marketplace »: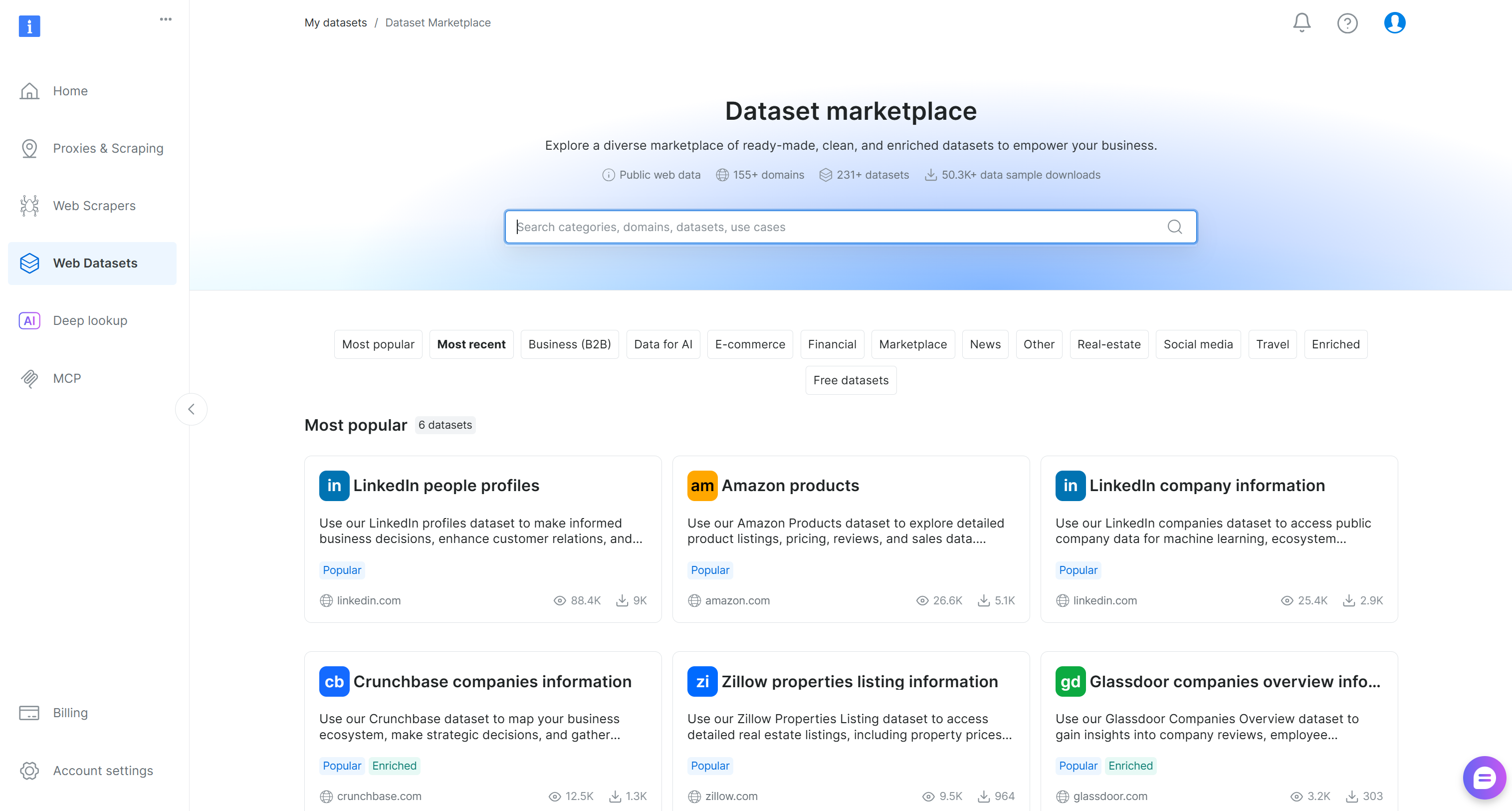
Ici, vous pouvez parcourir plus de 200 Jeux de données extraits de plus de 155 domaines, avec des milliards d’enregistrements disponibles.
Recherchez « Amazon best seller products » (produits les plus vendus sur Amazon) et sélectionnez-le. Vous serez redirigé vers la page de l’ensemble de données: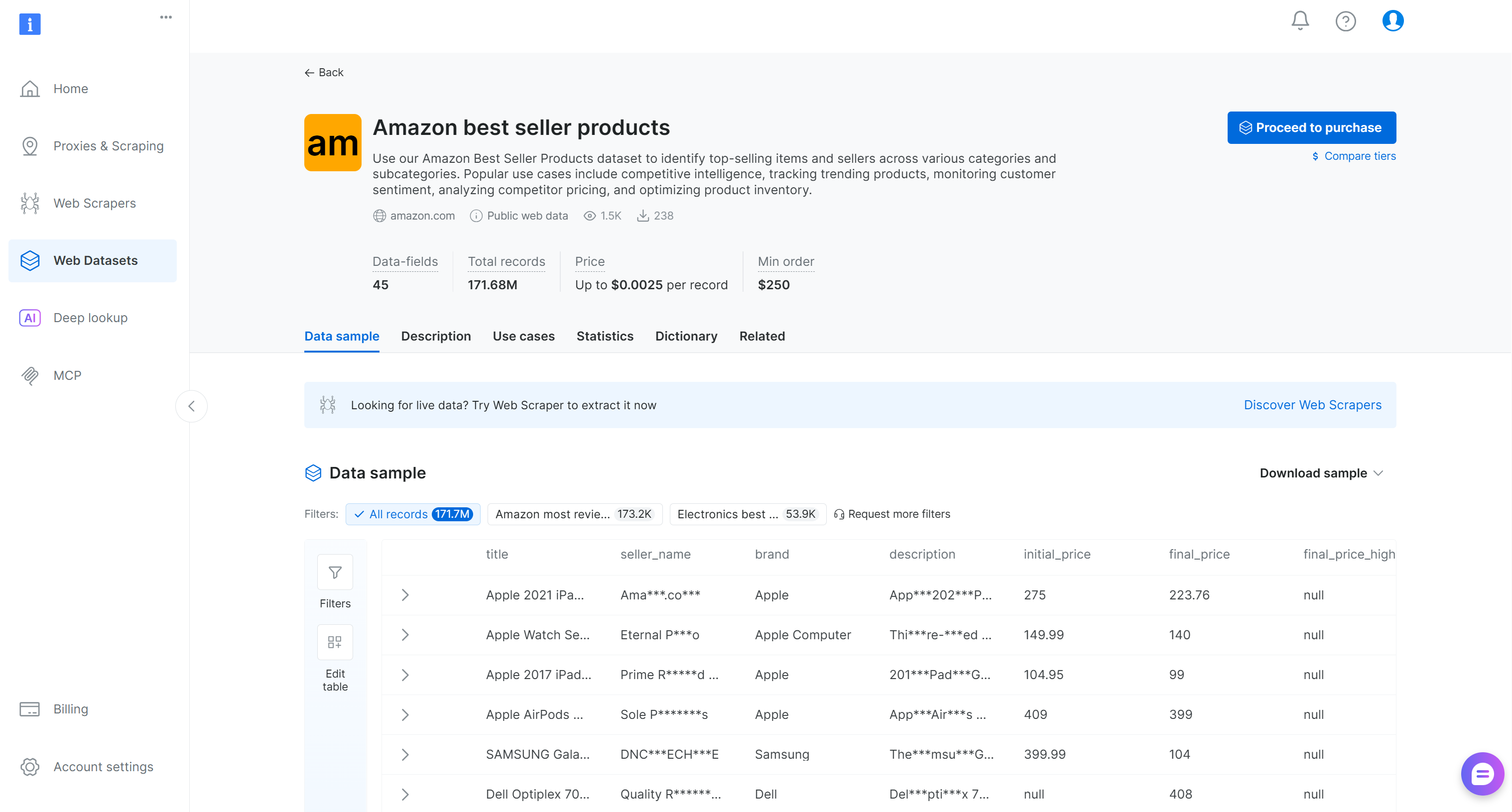
Vous pouvez soit acheter un sous-ensemble filtré d’enregistrements, soit télécharger un échantillon gratuit. Comme il s’agit seulement d’un exemple, nous utiliserons l’échantillon gratuit.
Cliquez sur le menu déroulant « Télécharger l’échantillon » et choisissez l’option « Télécharger au format JSON » :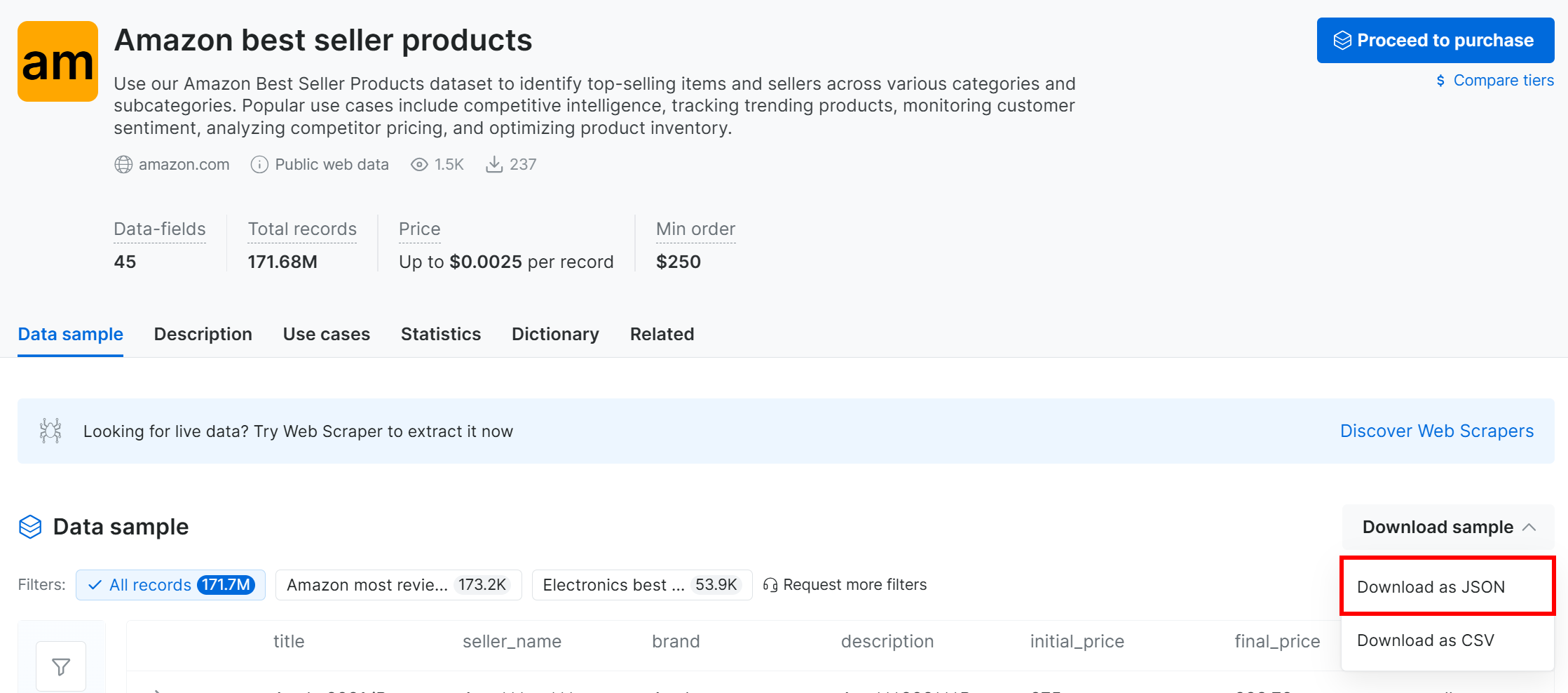
Vous recevrez un échantillon de jeu de données contenant 1 000 enregistrements des produits les plus vendus sur Amazon. Certains champs sont partiellement masqués (par « *** ») pour des raisons de confidentialité, mais le jeu de données complet est disponible après paiement. Néanmoins, l’échantillon est suffisant pour une simple expérimentation MLflow.
Vous pouvez également télécharger un échantillon de jeux de données similaires à partir d’un référentiel GitHub dédié.
Renommez le fichier de données téléchargé en products.json et placez-le dans le dossier de votre projet :
mlflow-experiment-tracking/
├── .venv/
├── experiment.py
├── mlflow.db
└── products.json # <--------Ouvrez le fichier et vous verrez :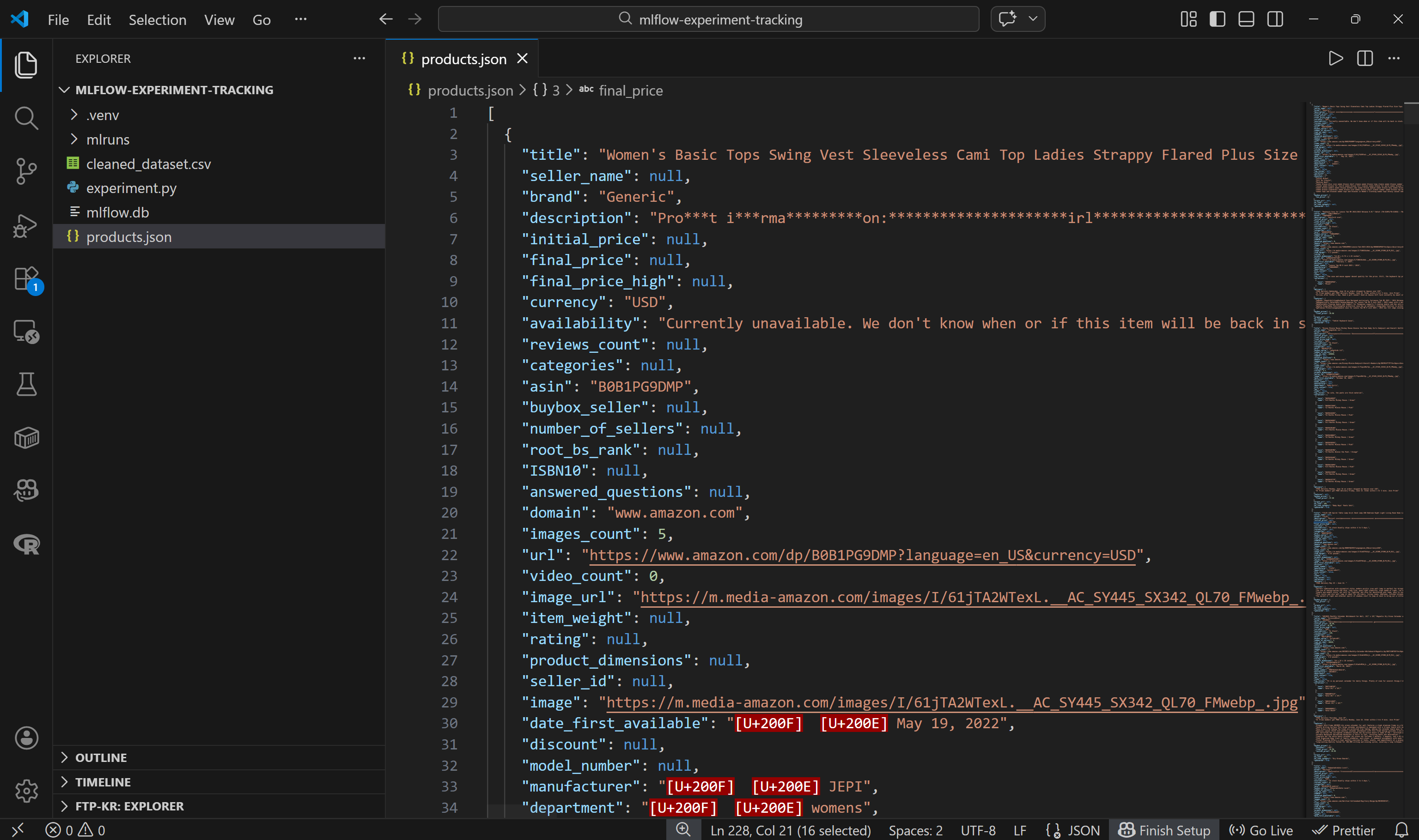
Notez que chaque produit Amazon est représenté par un objet JSON contenant environ 45 champs de données. Cela fournit une base riche pour l’expérimentation.
Parfait ! Vous êtes maintenant prêt à charger cet ensemble de données dans votre code et à commencer à le traiter.
Étape n° 5 : charger et prétraiter l’ensemble de données
Avant de charger l’ensemble de données dans votre code, prenez le temps d’explorer les colonnes disponibles. Accédez à l’onglet « Dictionnaire » pour afficher des informations détaillées sur chaque colonne, notamment sa description et son pourcentage de présence :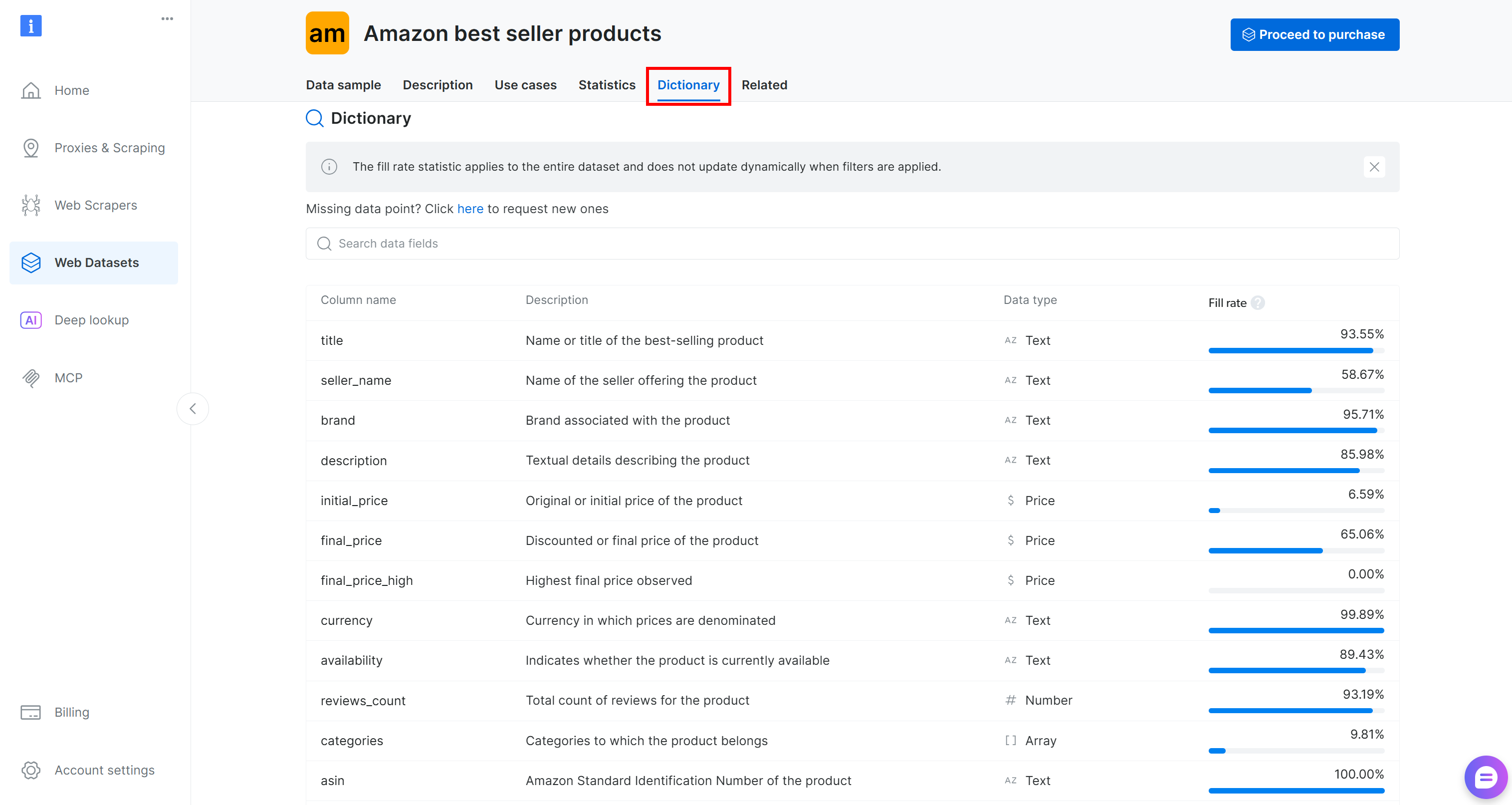
Dans ce cas, les colonnes qui nous intéressent sont les suivantes :
brand(texte): marque associée au produit.final_price(prix): prix réduit ou final du produit.reviews_count(nombre): nombre total d’avis.note(nombre): note moyenne du produit.
Maintenant, chargez le fichier JSON :
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)Puis convertissez-le en un DataFrame pandas:
df = pd.DataFrame(data)Si vous examinez la colonne final_price, vous remarquerez qu’elle contient parfois uniquement des valeurs numériques (par exemple, 1500), tandis que d’autres fois, elle comprend des chaînes formatées (par exemple, 1 500 $).
Pour un traitement cohérent, convertissez tous les prix au format numérique et supprimez les lignes où final_price est nul:
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
df = df.dropna(subset=["final_price"])Enfin, enregistrez les jeux de données dans MLflow :
# Définir les colonnes de caractéristiques et la colonne cible
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Définir explicitement la source de l'ensemble de données
dataset_source = CodeDatasetSource(tags="v1")
# Enregistrer l'ensemble de données dans MLflow avec certaines métadonnées
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET
)Ce code définit les caractéristiques d’entrée (rating, reviews_count, brand) et la variable cible (final_price) pour votre pipeline ML. Il crée ensuite un objet CodeDatasetSource et enregistre le DataFrame sélectionné dans MLflow avec des métadonnées afin de garantir le suivi et la reproductibilité de l’expérience.
Incroyable ! Vous êtes désormais prêt à utiliser ces données dans votre pipeline de formation de modèle.
Étape n° 6 : définir le pipeline du modèle prédictif
Préparez vos données pour l’entraînement du modèle ML à l’aide de la logique suivante :
# Séparer les caractéristiques et la cible
X = df[FEATURES]
y = df[TARGET]
# Pipeline de prétraitement :
# - Imputation médiane pour les colonnes numériques
# - Remplissage constant + encodage one-hot pour les colonnes catégorielles
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Pipeline ML complet : prétraitement + modèle RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Diviser l'ensemble de données en ensembles d'entraînement et de test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Cet extrait prépare les données et construit un pipeline ML complet en :
- Séparant les caractéristiques d’entrée (
note,nombre d'avis,marque) de la cible (prix final). - Traitant les valeurs manquantes avec une imputation médiane pour les caractéristiques numériques et un remplissage constant pour les caractéristiques catégorielles, puis en codant le champ de texte
de la marqueen format numérique. Ces précautions garantissent que le modèle reçoit des entrées numériques propres. - Combinant le prétraitement avec un modèle Random Forest et en divisant les données en ensembles d’entraînement et de test pour l’évaluation.
Super ! Il est temps de lancer votre expérience MLflow sur l’ensemble de données scrapé par Bright Data.
Étape n° 7 : exécutez l’expérience MLflow
Vous disposez désormais de tous les éléments nécessaires pour exécuter votre expérience MLflow. Exécutez-la avec :
# Démarrer l'exécution MLflow et activer le suivi des métriques système
avec mlflow.start_run(log_system_metrics=True) as run:
# Enregistrer l'ensemble de données comme entrée pour l'exécution
mlflow.log_input(mlflow_dataset, context="training")
# Entraîner le pipeline du modèle
pipeline.fit(X_train, y_train)
# Générer les prédictions sur l'ensemble de test
predictions = pipeline.predict(X_test)
# Enregistrer les métriques d'évaluation (RMSE et R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Enregistrer le jeu de données CSV de sortie dans un fichier local, puis en tant qu'artefact dans MLflow
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Enregistrer le modèle entraîné avec signature et exemple d'entrée
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Exécution terminée. Vérifiez l'onglet « System Metrics » (Mesures système) dans l'interface utilisateur MLflow pour l'ID d'exécution : {run.info.run_id}")Voici ce que fait l’extrait ci-dessus :
- Démarrer une exécution MLflow avec le suivi des métriques système activé.
- Enregistre
mlflow_datasetcomme entrée de l’expérience à des fins de traçabilité et de reproductibilité. - Entraîne le pipeline du modèle en ajustant le pipeline ML complet (prétraitement + Random Forest) sur les données d’entraînement.
- Génère des prédictions en utilisant le modèle formé pour prédire les valeurs cibles sur l’ensemble de test.
- Enregistre RMSE et R² dans MLflow pour évaluer les performances du modèle.
- Enregistrez l’ensemble de données nettoyé en tant qu’artefact afin de pouvoir l’explorer dans MLflow à titre de référence.
- Enregistre le pipeline formé dans MLflow, y compris sa signature d’entrée et un exemple d’entrée pour la reproductibilité.
Super ! Il ne vous reste plus qu’à explorer le code final et à lancer votre expérience MLflow.
Étape n° 8 : rassemblez tous les éléments et exécutez l’expérience
Votre fichier experiment.py doit contenir :
# pip install mlflow pandas scikit-learn psutil nvidia-ml-py
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# Activer la journalisation automatique des métriques système (CPU, mémoire, etc.)
mlflow.enable_system_metrics_logging()
# Journaliser automatiquement les événements pour sklearn
mlflow.sklearn.autolog()
# Configurer la fréquence d'échantillonnage et de journalisation des métriques système (1 seconde)
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1)
# Charger les données de produits extraites du fichier de données Bright Data en entrée
# (télécharger depuis : /cp/datasets/browse/gd_l1vijixj9g2vp7563)
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Convertir JSON en DataFrame pandas
df = pd.DataFrame(data)
# Nettoyer la colonne cible « final_price » :
# - Supprimer les signes dollar et les virgules
# - Convertir en numérique
# - Les valeurs non valides deviennent NaN
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
# Supprimer les lignes où la valeur cible est manquante
df = df.dropna(subset=["final_price"])
# Définir les colonnes de caractéristiques et la colonne cible
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Définir explicitement la source du jeu de données
dataset_source = CodeDatasetSource(tags="v1")
# Enregistrer l'ensemble de données dans MLflow avec certaines métadonnées
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET)
# Séparer les caractéristiques et la cible
X = df[FEATURES]
y = df[TARGET]
# Pipeline de prétraitement :
# - Imputation médiane pour les colonnes numériques
# - Remplissage constant + encodage one-hot pour les colonnes catégorielles
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Pipeline ML complet : prétraitement + modèle RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Diviser l'ensemble de données en ensembles d'entraînement et de test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Définir l'expérience MLflow
mlflow.set_experiment("brightdata_product_price_prediction")
# Démarrer l'exécution MLflow et activer le suivi des métriques système
with mlflow.start_run(log_system_metrics=True) as run:
# Enregistrer l'ensemble de données comme entrée pour l'exécution
mlflow.log_input(mlflow_dataset, context="training")
# Entraîner le pipeline du modèle
pipeline.fit(X_train, y_train)
# Générer les prédictions sur l'ensemble de test
predictions = pipeline.predict(X_test)
# Enregistrer les métriques d'évaluation (RMSE et R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Enregistrer le jeu de données CSV de sortie dans un fichier local, puis en tant qu'artefact dans MLflow
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Enregistrer le modèle entraîné avec signature et exemple d'entrée
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Exécution terminée. Vérifiez l'onglet « System Metrics » (Mesures système) dans l'interface utilisateur MLflow pour l'ID d'exécution : {run.info.run_id}")Une fois votre environnement Python activé, exécutez votre expérience MLflow à l’aide de :
python experiment.pyL’exécution devrait prendre quelques secondes, alors soyez patient.
Mission accomplie ! Vous venez de mettre en œuvre un pipeline de suivi d’expérience MLflow avec un ensemble de données extraites de Bright Data.
Étape n° 9 : explorer les résultats de suivi MLflow
Rendez-vous sur l’interface utilisateur MLflow à l'adresse http://127.0.0.1:5000/. Vous devriez voir une entrée d'expérience brightdata_product_price_prediction (qui est le nom donné à l’expérience MLflow dans le code). Cliquez dessus :
Passez à la section « Training runs » (Exécutions de formation) pour plus de détails :
Vous devriez voir la dernière exécution que vous venez d’effectuer :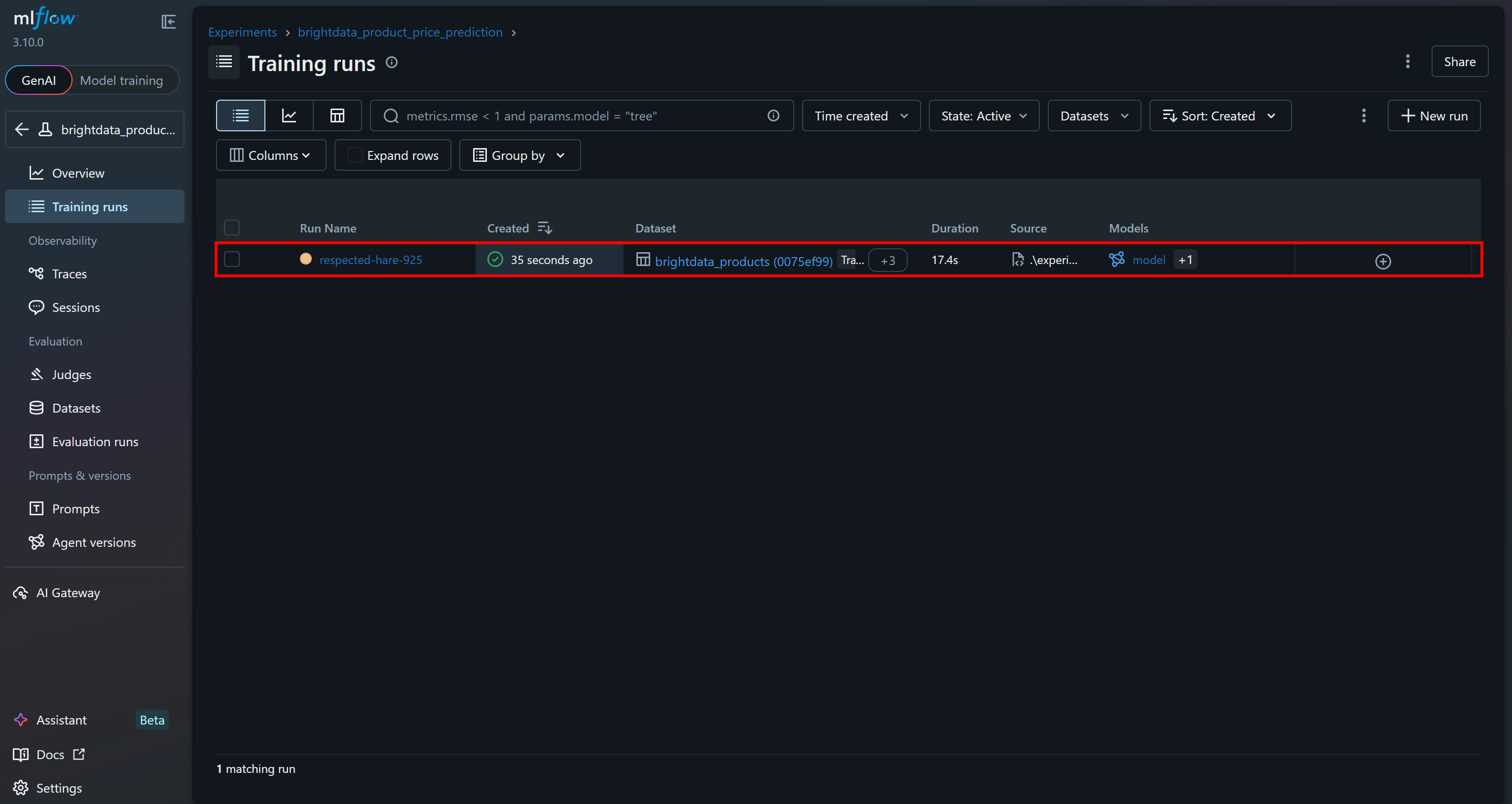
Cliquez dessus pour accéder immédiatement à plus de 15 métriques :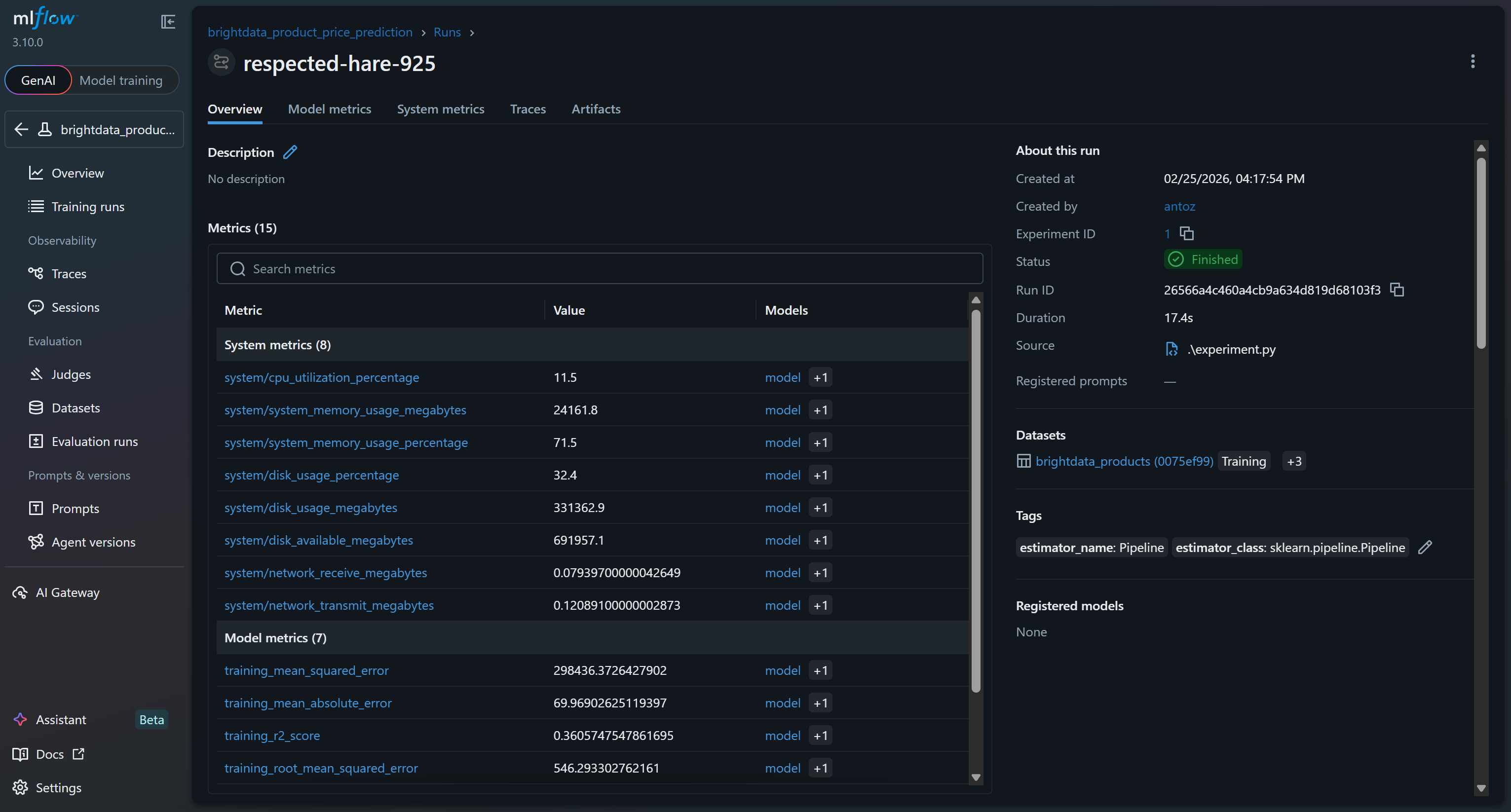
Il s’agit notamment des métriques système et modèle collectées automatiquement par les fonctionnalités de traçage de MLflow, ainsi que des métriques modèle enregistrées pendant votre exécution (par exemple, val_rmse, r2_score).
Pour explorer les métriques du modèle, accédez à l’onglet correspondant :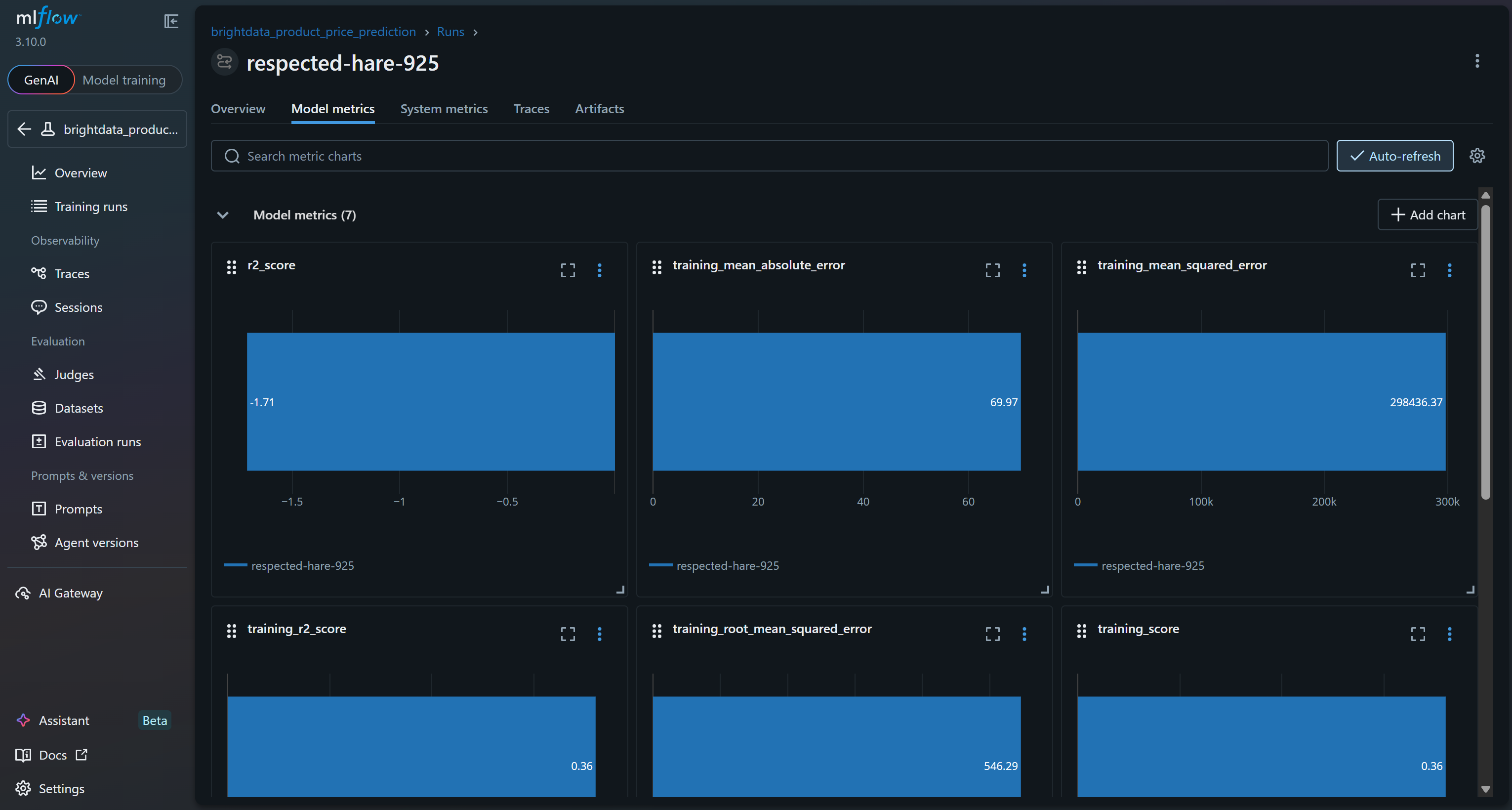
Ou consultez les graphiques des métriques système dans l’onglet « Métriques système » :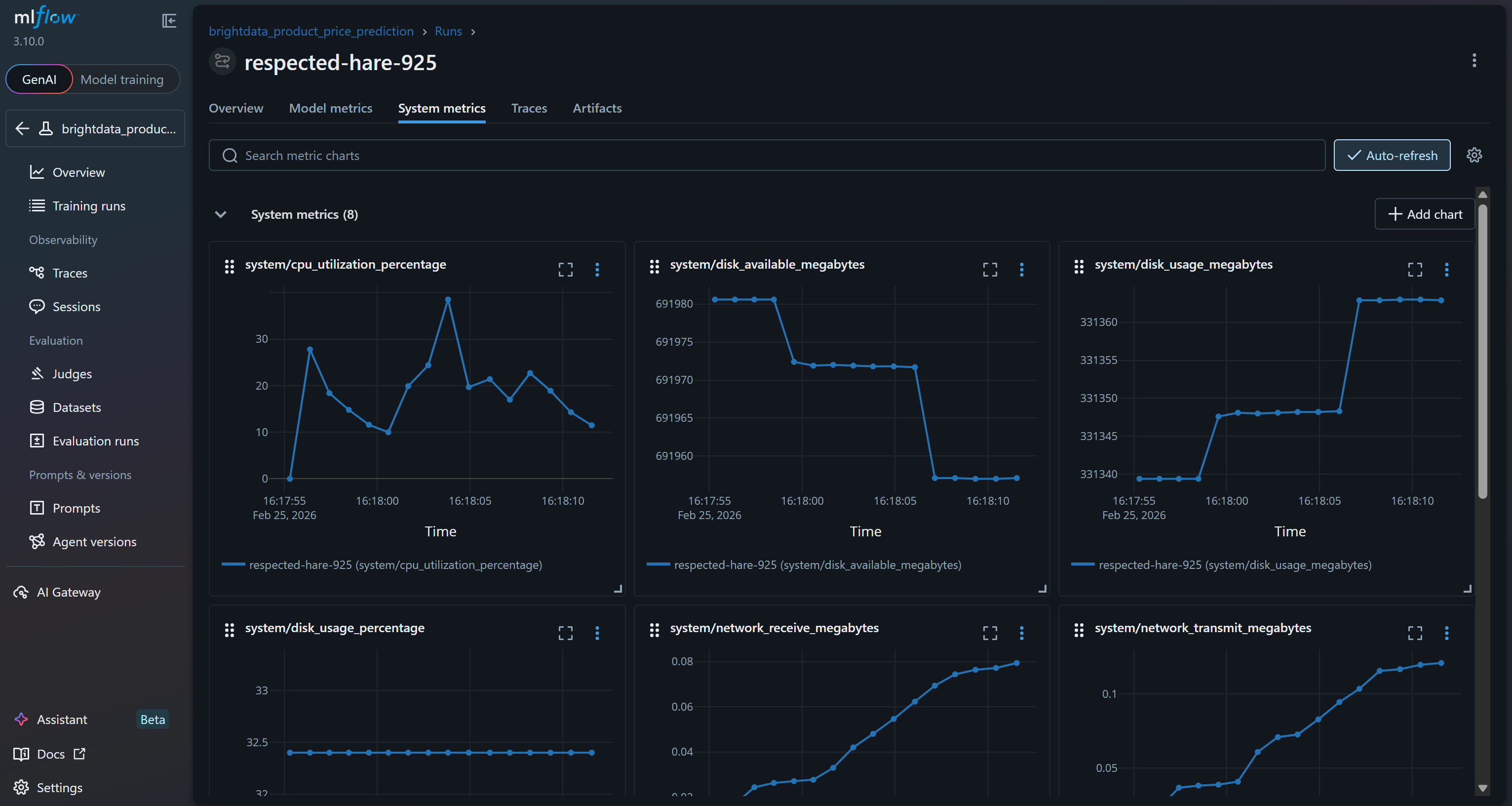
De plus, la section « Artefacts » affiche les fichiers de sortie (tels que le fichier cleaned_dataset.csv, tel qu’enregistré dans votre code) :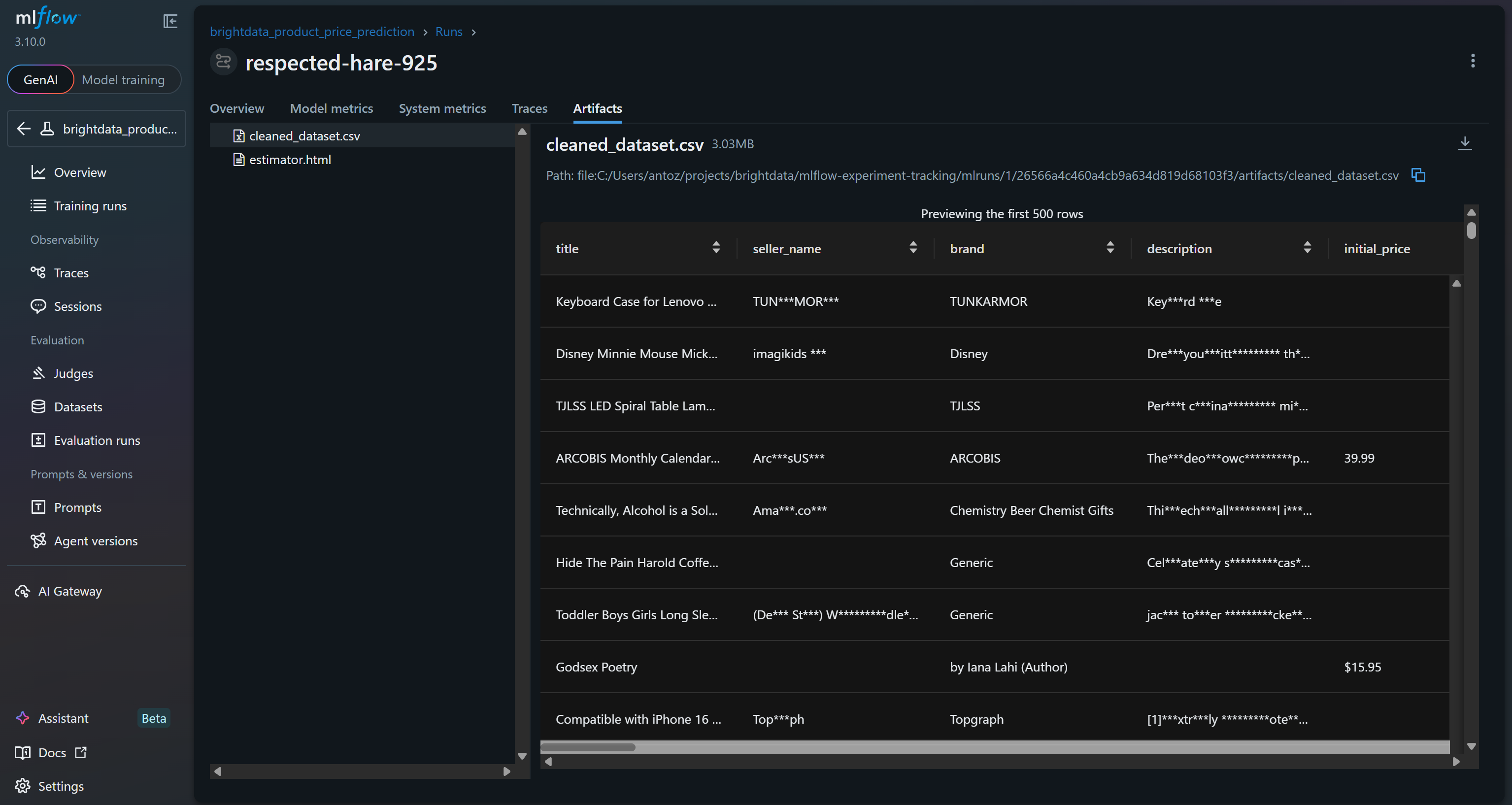
Ce ne sont là que quelques-unes des métriques et des résultats que vous pouvez suivre grâce à une expérience MLflow construite autour d’un ensemble de données scrapées par Bright Data !
Étape n° 10 : commenter les résultats
Pour vérifier que le processus d’entraînement du modèle a fonctionné, concentrez-vous sur les métriques du modèle :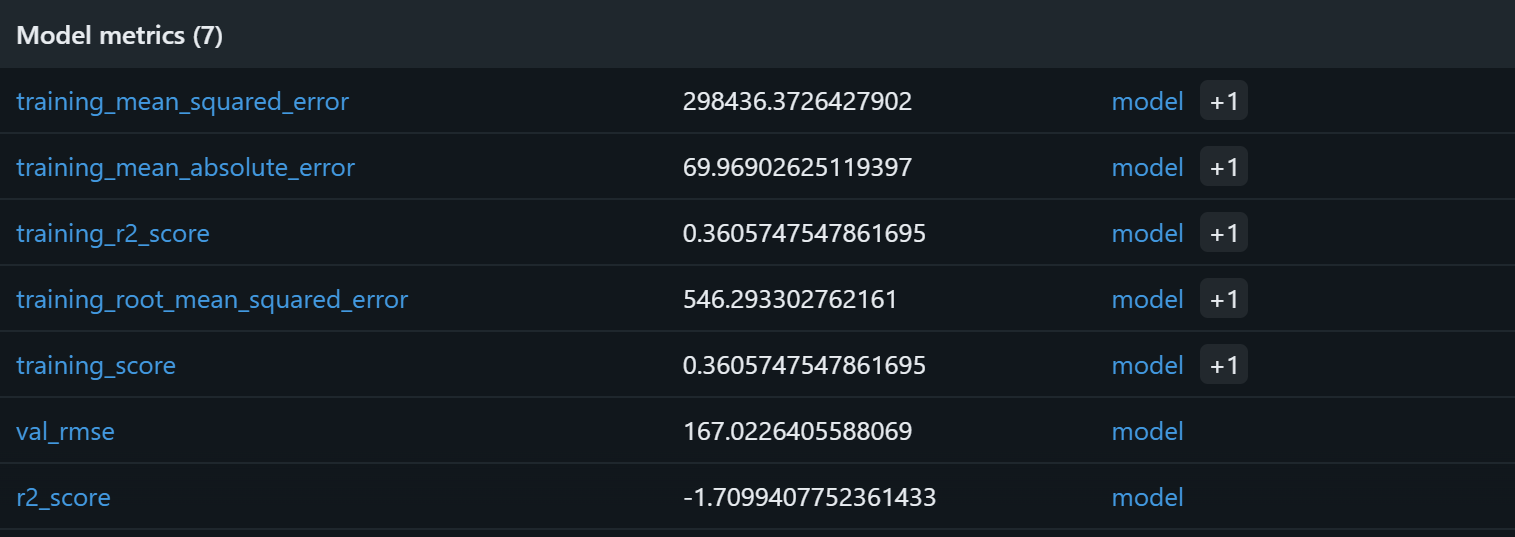
D’après ces métriques du modèle, le pipeline actuel est susceptible de produire des prédictions sans signification sur l’ensemble de validation. Le R² d’entraînement de 0,36 indique que le modèle explique environ 36 % de la variance dans les données d’entraînement, ce qui est modeste. Le RMSE d’entraînement (546) et le MAE (~70) suggèrent que les erreurs sont assez élevées par rapport aux prix habituels des produits, peut-être en raison de données bruitées ou de faibles corrélations entre les caractéristiques et la cible.
Plus préoccupante encore est la performance de validation : le R² est négatif (-1,71) et le RMSE de validation (167) reste significatif. Un R² négatif implique que le modèle est moins performant que la simple prédiction du prix moyen pour tous les échantillons. Cela indique que la relation supposée entre la note, le nombre d'avis, la marque et le prix final n’est peut-être pas suffisamment forte ou linéaire pour être capturée efficacement par une forêt aléatoire !
Les améliorations potentielles comprennent l’élargissement de l’ensemble de caractéristiques, l’ingénierie des caractéristiques (par exemple, la transformation logarithmique du nombre d’avis, le codage de la popularité de la marque), l’essai de modèles alternatifs tels que le gradient boosting ou XGBoost, et l’augmentation de la taille du jeu de données au-delà du sous-ensemble de 1 000 échantillons. Avec un jeu de données Bright Data plus important, vous disposeriez de plus de données et d’une plus grande variété, ce qui vous permettrait de mener des expériences plus approfondies et plus pertinentes.
En bref, le pipeline actuel fonctionne techniquement, mais ne parvient pas à saisir correctement les tendances sous-jacentes des prix. Grâce au suivi des expériences MLflow, vous avez pu identifier que les hypothèses sous-jacentes à ce pipeline d’apprentissage automatique sont probablement erronées.
Prochaines étapes
Si vous souhaitez utiliser MLflow pour tracer les pipelines d’IA avec les Jeux de données Bright Data à des fins de réglage fin ou de RAG, n’oubliez pas que le traçage MLflow est entièrement compatible avec OpenTelemetry. Plus précisément, MLflow fournit une solution d’observabilité LLM qui capture les entrées, les sorties et les métadonnées pour chaque étape intermédiaire d’une requête.
Lors de l’intégration avec OpenAI, vous pouvez l’activer facilement avec :
import mlflow
mlflow.openai.autolog() Pour plus de détails, consultez la documentation officielle de MLflow.
Conclusion
Dans ce tutoriel, vous avez découvert ce que MLflow apporte à la création et au suivi des pipelines d’apprentissage automatique et d’IA. Vous avez également compris pourquoi les Jeux de données scrapés constituent d’excellentes sources pour l’entraînement ou le réglage fin des modèles.
Comme démontré, Bright Data propose une riche place de marché de jeux de données couvrant des centaines de domaines et des milliards d’enregistrements de données web. Ces jeux de données sont continuellement mis à jour via le Scraping web afin de prendre en charge les workflows d’apprentissage automatique et d’IA. Plus précisément, ils sont parfaitement compatibles avec le suivi MLflow, comme indiqué ici.
Créez un compte Bright Data gratuit et commencez dès aujourd’hui à explorer nos solutions de données web !






