
Dans cet article de blog, vous apprendrez :
- Pourquoi Kubeflow Pipelines devrait inclure un composant dédié à la collecte de données web.
- Une application de cette approche à un pipeline spécifique d’analyse des sentiments sur TikTok.
- Comment mettre en œuvre ce pipeline en se connectant aux flux de données des commentaires TikTok via une solution de scraping spécifique.
C’est parti !
Pourquoi Kubeflow Pipelines tire profit des données structurées extraites par Scraping web
Les workflows modernes d’apprentissage automatique et d’IA reposent largement sur des données de haute qualité. Au contraire, les pipelines traditionnels ingèrent souvent des jeux de données statiques ou des fichiers prétraités. Or, ces sources peuvent rapidement devenir obsolètes, laissant les modèles entraînés sur des informations périmées.
C’est là que les données structurées extraites du Web entrent en jeu ! En collectant des données contextuelles en direct sur le Web, les pipelines peuvent rester en phase avec les dernières tendances, le comportement des utilisateurs et les contenus émergents.
Les pipelines Kubeflow, conçus pour des workflows ML modulaires, reproductibles et évolutifs, tirent un immense avantage de l’intégration de composants de collecte de données web. Ces composants fournissent des flux structurés et à jour qui peuvent être automatiquement ingérés, filtrés et traités en aval.
La présence d’un composant de collecte de données web dans votre pipeline contribue certainement à améliorer la précision du modèle. Ainsi, l’ajout d’un composant dédié à la collecte de données web, voire de plusieurs composants pour différentes sources, est stratégiquement judicieux. Il permet à vos pipelines de s’adapter, de se réentraîner et de générer des informations en temps quasi réel, créant ainsi une base solide pour tout projet basé sur l’IA.
Présentation du pipeline Kubeflow pour l’analyse des sentiments sur TikTok
Pour mieux comprendre comment un composant de collecte de données web améliore les pipelines Kubeflow, prenons un exemple concret. Imaginez que vous souhaitiez créer un workflow d’analyse de données qui prend un ensemble de publications TikTok et analyse leur contenu pour en déterminer le sentiment.
Vous pourriez concevoir un pipeline à deux composants :
- Composant de données de commentaires TikTok: récupère les données de commentaires structurées à partir des publications TikTok via le Scraping web.
- Composant d’analyse des données: enrichit ces commentaires avec des informations sur le sentiment (
positif,négatifouneutre).
Le problème est que le scraping de TikTok (ou de nombreuses autres plateformes populaires) est notoirement difficile. Cela est dû aux mesures anti-scraping telles que les CAPTCHA, les défis JavaScript, les blocages d’IP et les limites de débit. La mise à l’échelle de ce processus ne fait qu’ajouter à la complexité, car les restrictions et les interdictions peuvent facilement perturber la collecte de données.
Pour éviter ces problèmes, il est judicieux d’alimenter le composant de collecte de données web avec un service de données web de premier ordre tel que Bright Data. Bright Data permet un scraping web fiable à grande échelle grâce à une infrastructure hautement évolutive soutenue par 150 millions d’adresses IP Proxy dans 195 pays, un taux de réussite de 99,95 % et une disponibilité de 99,99 %.
Plus précisément, nous utiliserons TikTok Scraper, une API de Scraping web conçue pour simplifier la collecte de données structurées à partir des publications TikTok. Il s’agit de l’une des nombreuses API de Scraping web disponibles pour récupérer des données à partir de domaines populaires. De même, vous pouvez utiliser l’API Filter Dataset pour extraire des données filtrées des Jeux de données Bright Data, alimentant ainsi vos pipelines ML/IA avec des données prêtes à l’emploi.
Comment créer un pipeline Kubeflow avec un composant de données de Scraping web dynamique
Dans cette section guidée, vous verrez comment créer le pipeline Kubeflow pour l’analyse des sentiments TikTok présentée précédemment.
Suivez les étapes ci-dessous !
Prérequis
Pour suivre ce tutoriel, vous aurez besoin de :
- Docker installé et fonctionnant sur votre machine.
- Python 3.10+ installé localement.
- Un compte Bright Data avec votre clé API correctement configurée (ne vous inquiétez pas pour la configuration pour l’instant, vous serez guidé à travers cette étape dans une sous-section dédiée).
Une compréhension de base du fonctionnement de Kubeflow Pipelines vous aidera également à comprendre les instructions ci-dessous.
Les systèmes d’exploitation recommandés pour exécuter les exemples ci-dessous sont Linux, macOS ou WSL (Windows Subsystem for Linux).
Étape n° 1 : configuration du projet
Commencez par ouvrir votre terminal et créer un nouveau répertoire pour le projet Kubeflow Pipelines :
mkdir kfp-bright-data-pipelineAccédez au répertoire du projet et créez un environnement virtuel Python à l’intérieur :
cd kfp-bright-data-pipeline
python -m venv .venvEnsuite, ouvrez le dossier du projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un nouveau fichier nommé tiktok_sentiment_analysis_kfp_pipeline.py à la racine du répertoire du projet. Votre structure devrait ressembler à ceci :
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------Dans le terminal de l’IDE, activez l’environnement virtuel. Sous Linux ou macOS, lancez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateUne fois l’environnement virtuel activé, installez la dépendance requise :
pip install kfpLa seule bibliothèque requise est kfp, qui vous permet de créer et de compiler des pipelines d’apprentissage automatique portables et évolutifs.
Enfin, ouvrez tiktok_sentiment_analysis_kfp_pipeline.py et importez les modules nécessaires :
from kfp import dsl, compiler
from kfp.dsl import Input, Output, DatasetEt voilà ! Vous disposez désormais d’un environnement de développement Python dans lequel vous pouvez créer votre pipeline Kubeflow.
Étape n° 2 : démarrer avec Bright Data
Le premier composant de votre pipeline récupérera des données web en direct à l’aide des API de Scraping web de Bright Data. Avant de l’implémenter, vous devez configurer correctement votre compte Bright Data.
Comme nous allons utiliser les API de Scraping web, prenez quelques minutes pour consulter la documentation officielle. En bref, ces API fournissent des flux de données structurés provenant de sites web populaires, prêts à être utilisés dans des workflows ML/IA (ou tout autre cas d’utilisation pris en charge).
Si vous n’avez pas encore de compte, créez-en un. Sinon, connectez-vous et ouvrez le tableau de bord utilisateur. À partir de là, accédez à la section « Web Scrapers » :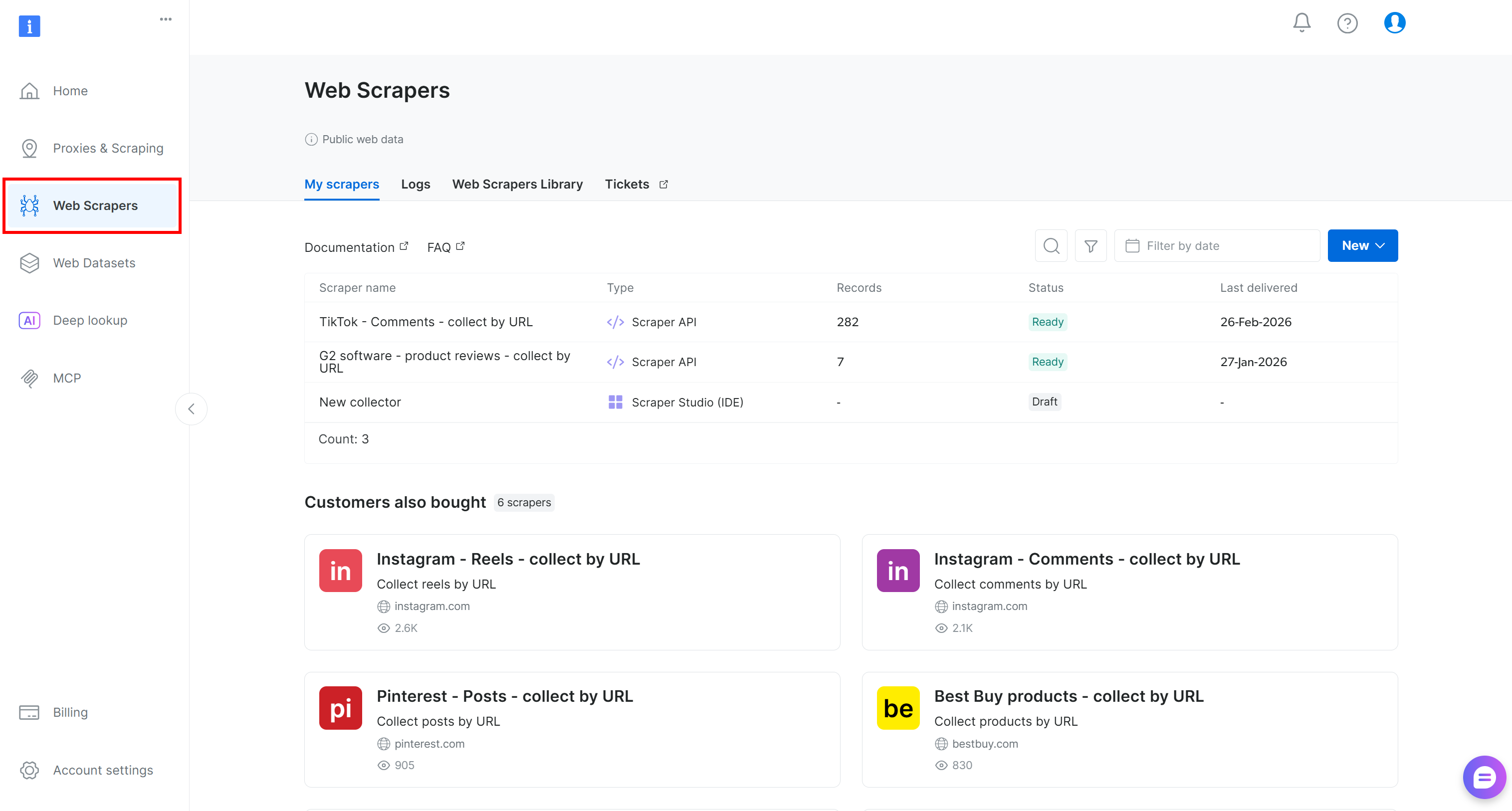
Accédez à l’onglet « Web Scrapers Library ». Vous y trouverez plus de 120 Scrapers prêts à l’emploi pour certaines des plateformes les plus populaires sur Internet.
Dans ce tutoriel, recherchez « tiktok.com », car notre objectif est de récupérer les données des commentaires en direct des publications TikTok et d’effectuer une analyse des sentiments sur celles-ci.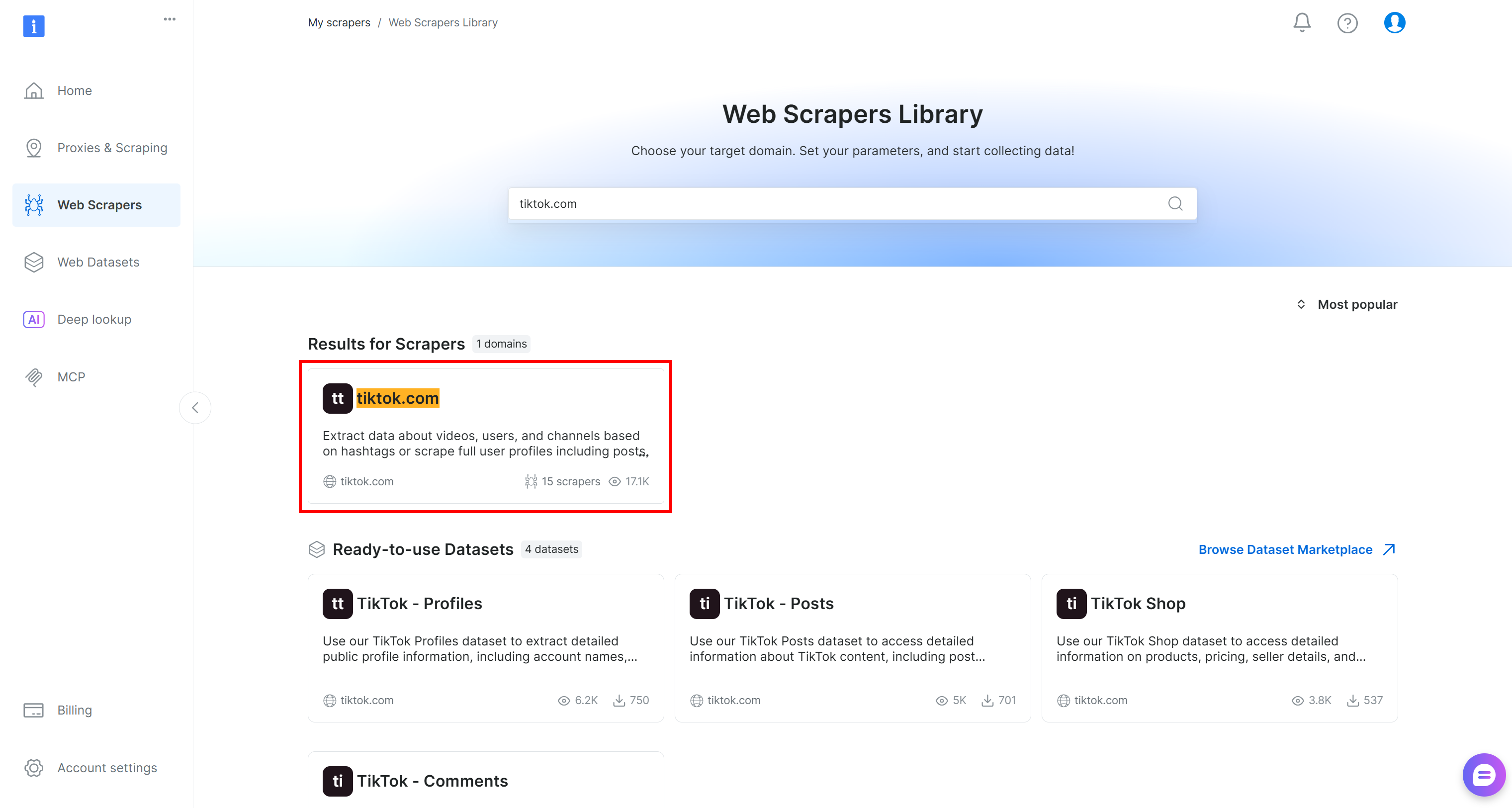
Dans la page du Scraper TikTok, explorez les points de terminaison de scraping disponibles.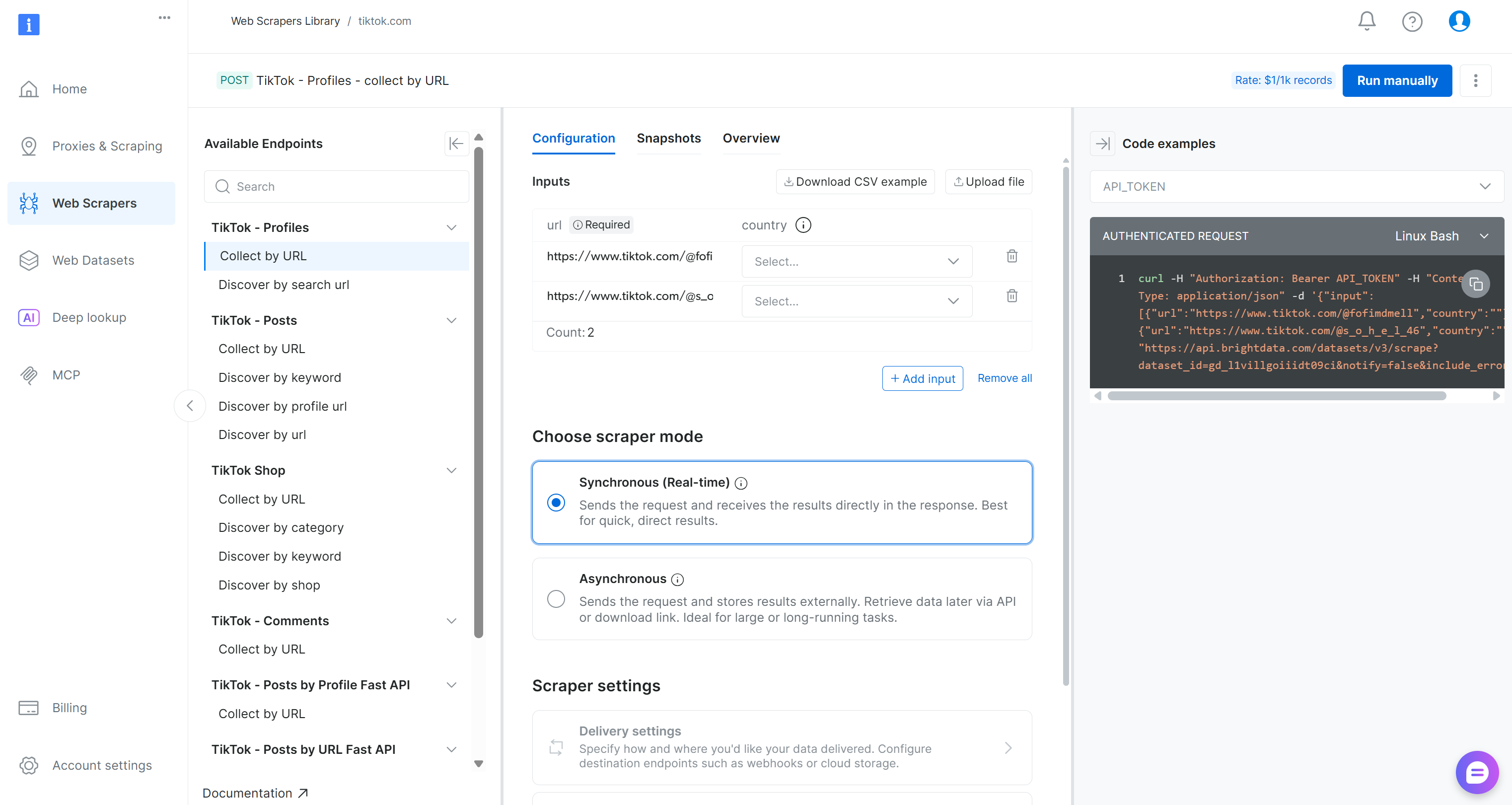
Vous pouvez y configurer les paramètres d’entrée, inspecter les formats de requête/réponse, consulter des exemples d’appels API, et bien plus encore.
Pour ce pipeline, localisez le Scraper « Collect by URL » (Collecter par URL) dans le menu déroulant « TikTok – Comments » (TikTok – Commentaires) :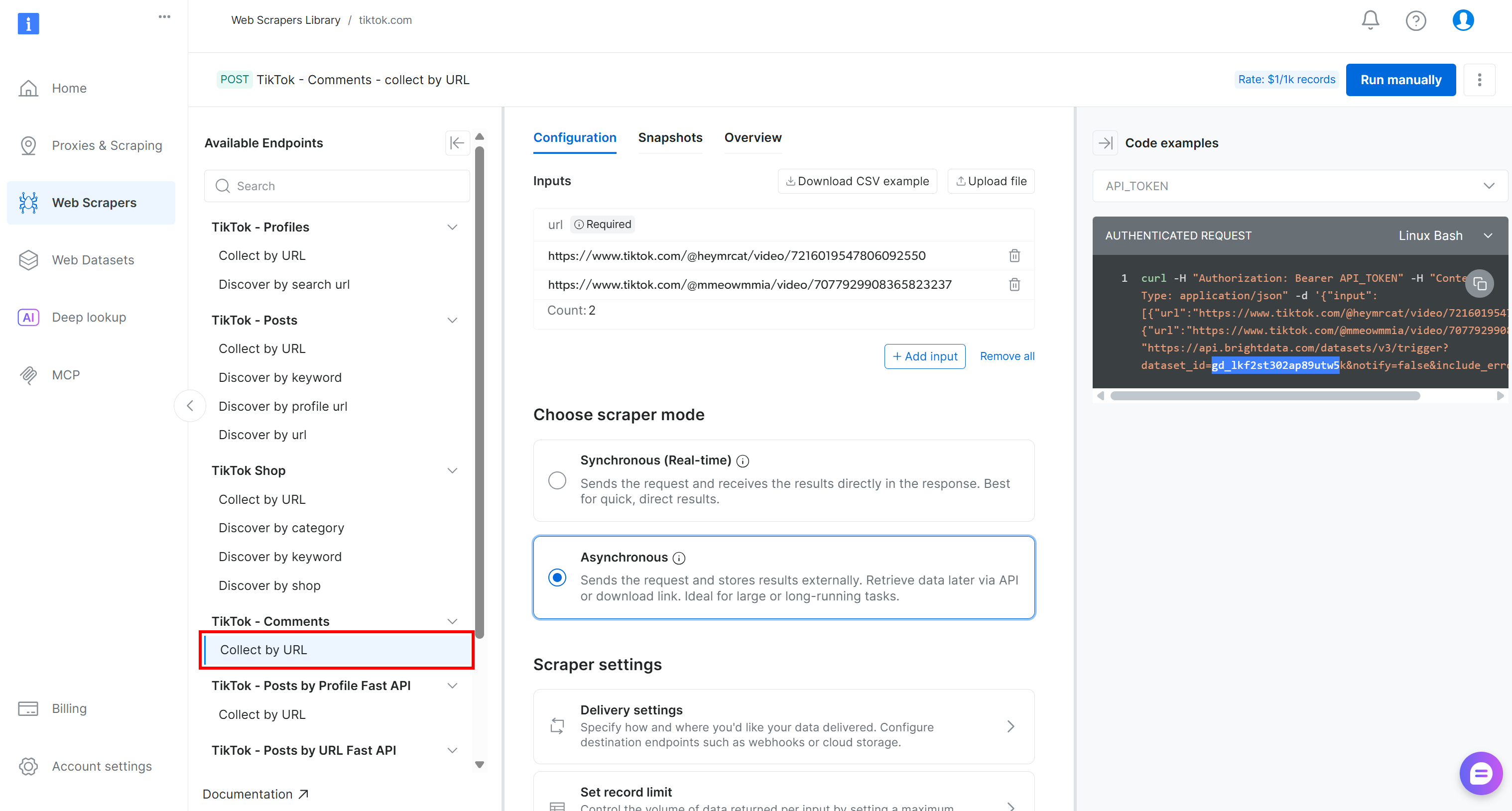
Il s’agit du point de terminaison alimenté par Bright Data que vous utiliserez dans le composant de collecte de données de votre pipeline Kubeflow.
Notez son ID de jeu de données :
gd_lkf2st302ap89utw5kVous en aurez besoin pour déclencher l’API de Scraping web spécifique à la collecte de données de commentaires TikTok.
De plus, comme vous pouvez le voir dans l’extrait à droite, les appels API Bright Data vers les API de Scraping web sont authentifiés à l’aide d’un API_TOKEN. Cette valeur doit être remplacée par votre clé API Bright Data, qui est la méthode recommandée pour authentifier les requêtes API.
Récupérez votre clé API comme expliqué dans la documentation et conservez-la en lieu sûr. Vous l’utiliserez à l’étape suivante !
Étape n° 3 : définir le composant de collecte de données Web
Implémentez le composant du pipeline Kubeflow pour la collecte de données Web en l’intégrant à l’API de Scraping web Bright Data pour le scraping TikTok :
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"])
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Remplacez par votre clé API Bright Data.
# L'ID de l'API de Scraping web Bright Data « TikTok – Commentaires → Collecter par URL ».
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Les en-têtes HTTP communs à toutes les requêtes adressées à Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Déclencher l'API de Scraping web Bright Data sur les publications TikTok saisies
trigger = requests.post(
f"https://api.brightdata.com/Jeux de données/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Récupérer l'ID de l'instantané des données
snapshot_id = trigger.json()["snapshot_id"]
# Interroger le point de terminaison de l'instantané pour vérifier si l'instantané
# contenant les données d'intérêt a été produit
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Accéder aux données de réponse JSON
response_data = progress.json()
# Si la réponse ne comprend pas de statut, cela signifie qu'elle contient les données extraites
if isinstance(response_data, dict) and "status" in response_data:
# Extraire le statut actuel de l'instantané
status = progress.json()["status"]
# Attendre 5 secondes avant la prochaine vérification
time.sleep(5)
else:
scraped_data = response_data
break
# Stocker l'ensemble de données récupérées
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)Remarque: veillez à remplacer le paramètre fictif <YOUR_BRIGHT_DATA_API_KEY> par la clé API Bright Data que vous avez récupérée précédemment. Dans un pipeline prêt pour la production, évitez de coder en dur les secrets dans vos composants. Gérez-les plutôt de manière sécurisée, comme expliqué dans la documentation.
Dans Kubeflow Pipelines, un composant est une unité autonome (définie via l’annotation dsl.component ) qui effectue une tâche spécifique. Dans ce cas, le composant récupère les données web de Bright Data. Chaque composant est packagé dans un conteneur Docker.
Pour ce composant, l’image de base est un environnement Python 3.10. Ensuite, la bibliothèquerequests est incluse car elle est utilisée pour effectuer des requêtes HTTP vers les points de terminaison de l’API Bright Data. Au moment du déploiement, lorsque le composant est construit, l’image Python 3.10 sera extraite et les requêtes seront installées automatiquement.
Bright Data prend en charge la livraison de données synchrone et asynchrone via ses API de Scraping web. La méthode synchrone est idéale pour une récupération rapide des données, tandis que la méthode asynchrone est mieux adaptée aux Jeux de données plus volumineux. Pour un pipeline prêt à la production, il est généralement recommandé de s’appuyer sur l’approche asynchrone.
Dans la méthode asynchrone, lorsque vous demandez des données, celles-ci peuvent ne pas être disponibles immédiatement. À la place, Bright Data génère un instantané des données demandées, ce qui peut prendre quelques secondes ou plus. Cela nécessite un mécanisme de sondage, dans lequel vous vérifiez à plusieurs reprises si l’instantané est disponible avant de le récupérer.
Dans ce contexte, voici comment fonctionne le code du composant de données web, étape par étape :
- Envoi de la demande de données: le composant envoie un appel API à Bright Data pour commencer à générer l’instantané des données que vous avez demandées.
- Interroger le point de terminaison de l’instantané: le composant appelle de manière répétée le point de terminaison de l’instantané pour vérifier son statut. Si la réponse contient un champ
de statut« en cours d’exécution », l’instantané est encore en cours de préparation. Si le champde statutest absent, cela signifie que l’instantané est prêt et contient les données extraites. - Récupérer les données: une fois l’instantané prêt, le composant extrait les données de la réponse API et les met à la disposition des composants en aval dans le pipeline.
Incroyable ! Le composant du pipeline Kubeflow pour la collecte de données web est terminé.
Étape n° 4 : créer le composant d’analyse des sentiments
Les données récupérées sur TikTok seront récupérées sous forme de tableau JSON avec la structure suivante :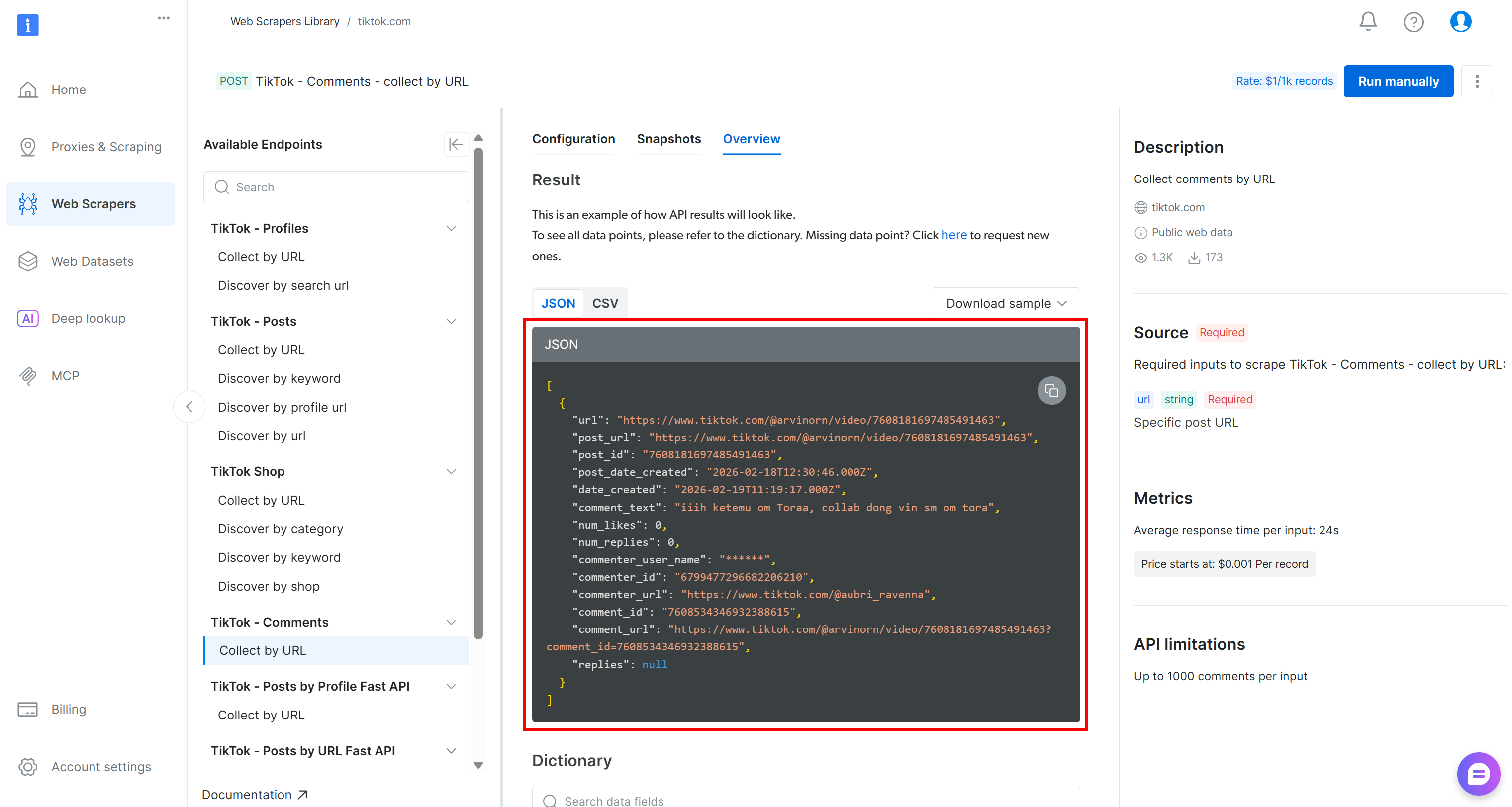
Pour effectuer une analyse des sentiments sur ces données, vous pouvez transmettre le champ comment_text à un outil d’analyse des sentiments tel que VADER Sentiment Analysis. VADER est un outil basé sur un lexique et des règles, spécialement conçu pour capturer les sentiments exprimés sur les réseaux sociaux. Bien sûr, vous pouvez également utiliser d’autres méthodes d’analyse des sentiments, notamment des modèles basés sur l’IA.
VADER est inclus dans NLTK, l’un des kits d’outils Python les plus populaires pour le traitement du langage naturel. Voici un exemple de workflow type :
- Lisez le tableau JSON d’entrée (les commentaires TikTok récupérés) à partir du composant précédent.
- Utiliser
pandaspour simplifier le filtrage et la sélection des données. - Transmettre les données textuelles à l’analyseur de sentiments VADER via
nltk. - Enregistrer les résultats analysés pour qu’ils puissent être utilisés par les composants en aval.
En résumé, le composant d’analyse des sentiments peut être implémenté comme suit :
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"])
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Télécharger le lexique des sentiments VADER (utilisé par NLTK pour l'évaluation des sentiments)
nltk.download("vader_lexicon")
# Charger l'ensemble de données d'entrée contenant les commentaires TikTok
df = pd.read_json(input_dataset.path)
# Initialiser l'analyseur de sentiments
sia = SentimentIntensityAnalyzer()
# Appliquer l'analyse des sentiments à chaque commentaire et les classer comme positifs, négatifs ou neutres
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" si sia.polarity_scores(str(t))["compound"] >= 0.05 sinon
« negative » si sia.polarity_scores(str(t))["compound"] <= -0.05 else « neutral »
))
# Enregistrer les résultats dans l'ensemble de données de sortie pour les composants en aval
df.to_json(sentiment_output.path, orient="records")Super ! Les deux principaux composants du pipeline (à savoir la collecte de données web et l’analyse des sentiments) sont désormais entièrement implémentés.
Étape n° 5 : finaliser le pipeline Kubeflow
Maintenant que les deux composants sont prêts, vous pouvez les assembler en un seul pipeline Kubeflow à l’aide d’une fonction annotée avec dsl.pipeline:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Liste des URL des publications TikTok à partir desquelles extraire les commentaires
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Collecte des commentaires TikTok à l'aide du composant de Scraping web Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Analyse des sentiments sur les commentaires collectés
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)Ce pipeline exécute d’abord le composant de collecte de commentaires TikTok sur deux vidéos cibles provenant du même profil (@nike). Plus précisément, les deux vidéos TikTok sources ont été sélectionnées parce qu’elles présentent de nouvelles chaussures. Il est essentiel pour l’entreprise d’effectuer une analyse des sentiments sur ces vidéos afin de comprendre ce que le public pense du lancement.
L’ensemble de données produit via l’API Bright Data Scraping web est ensuite transmis au composant d’analyse des sentiments en aval. L’étape d’analyse des sentiments traite les commentaires récupérés et génère un nouvel ensemble de données contenant des étiquettes de sentiments (positifs, négatifs ou neutres). Ce résultat peut être utilisé par d’autres composants en aval, tels que le reporting ou la visualisation.
Excellent ! Le pipeline Kubeflow est désormais entièrement défini.
Étape n° 6 : compiler le pipeline
La dernière étape consiste à compiler le pipeline dans un fichier de pipeline Kubeflow YAML:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Lorsque vous exécutez le script tiktok_sentiment_analysis_kfp_pipeline.py, ce code génère un fichier nommé tiktok_sentiment_analysis_kfp_pipeline.yaml. Ce fichier YAML contient la spécification complète du pipeline requise pour le déploiement Kubeflow. Mission accomplie !
Étape n° 7 : code final
Vous trouverez ci-dessous le pipeline Kubeflow complet que vous devriez avoir dans votre fichier tiktok_sentiment_analysis_kfp_pipeline.py:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"])
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Remplacez par votre clé API Bright Data.
# L'ID de l'API de Scraping web Bright Data « TikTok – Commentaires → Collecter par URL ».
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Les en-têtes HTTP communs à toutes les requêtes adressées à Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Déclencher l'API de Scraping web Bright Data sur les publications TikTok saisies
trigger = requests.post(
f"https://api.brightdata.com/Jeux de données/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Récupérer l'ID de l'instantané des données
snapshot_id = trigger.json()["snapshot_id"]
# Interroger le point de terminaison de l'instantané pour vérifier si l'instantané
# contenant les données d'intérêt a été produit
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Accéder aux données de réponse JSON
response_data = progress.json()
# Si la réponse ne comprend pas de statut, cela signifie qu'elle contient les données extraites
if isinstance(response_data, dict) and "status" in response_data:
# Extraire le statut actuel de l'instantané
status = progress.json()["status"]
# Attendre 5 secondes avant la prochaine vérification
time.sleep(5)
else:
scraped_data = response_data
break
# Stocker l'ensemble de données récupérées
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"])
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Télécharger le lexique des sentiments VADER (utilisé par NLTK pour l'évaluation des sentiments)
nltk.download("vader_lexicon")
# Charger l'ensemble de données d'entrée contenant les commentaires TikTok
df = pd.read_json(input_dataset.path)
# Initialiser l'analyseur de sentiments
sia = SentimentIntensityAnalyzer()
# Appliquer l'analyse des sentiments à chaque commentaire et les classer comme positifs, négatifs ou neutres
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" si sia.polarity_scores(str(t))["compound"] >= 0.05 sinon
« negative » si sia.polarity_scores(str(t))["compound"] <= -0.05 else « neutral »
))
# Enregistrer les résultats dans l'ensemble de données de sortie pour les composants en aval.
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Liste des URL des publications TikTok à partir desquelles extraire les commentaires.
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Collecte des commentaires TikTok à l'aide du composant de Scraping web Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Analyse des sentiments sur les commentaires collectés
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Lancez le script ci-dessus avec :
python3 tiktok_sentiment_analysis_kfp_pipeline.pyAprès avoir exécuté la commande, un fichier nommé tiktok_sentiment_analysis_kfp_pipeline.yaml devrait être généré, comme indiqué ci-dessous :
Vous pouvez maintenant le déployer sur Kubeflow pour le tester ou l’exécuter localement à l’aide de Docker. Dans ce guide, nous nous concentrerons sur la deuxième approche.
Étape n° 8 : tester le pipeline Kubeflow localement
Pour exécuter le pipeline Kubeflow localement, vous pouvez utiliser la classe DockerRunner. Cela nécessite que Docker soit installé et fonctionne sur votre machine.
DockerRunner exécute chaque tâche du pipeline dans un conteneur Docker distinct. En d’autres termes, il simule le fonctionnement du pipeline dans un environnement Kubeflow réel.
Une fois votre environnement virtuel activé, commencez par installer la bibliothèque Docker requise :
pip install docker Ensuite, ajoutez un fichier run_pipeline_local.py à votre dossier de projet :
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yamlRemplissez-le comme suit :
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# initialise le runner Docker local
local.init(runner=local.DockerRunner())
# Exécutez le pipeline en tant qu'appel de fonction Python
pipeline_task = tiktok_sentiment_pipeline()Ce script importe la fonction tiktok_sentiment_pipeline() depuis tiktok_sentiment_analysis_kfp_pipeline.py et l’exécute via le runner Docker local, en exécutant chaque composant dans son propre conteneur.
Pour tester le pipeline, assurez-vous que Docker est en cours d’exécution. Ensuite, exécutez :
python3 run_pipeline_local.pyLes journaux d’exécution devraient afficher un message de réussite, similaire à l’exemple ci-dessous :
La sortie du pipeline sera enregistrée dans le dossier ./local_outputs. Il est temps d’explorer les résultats !
Étape n° 9 : exploration des résultats du pipeline
Après avoir exécuté le pipeline, ouvrez le dossier ./local_outputs. À l’intérieur, vous trouverez un sous-dossier pour l’exécution en cours contenant tous les artefacts produits.
Commencez par explorer l’ensemble de données de sortie produit par le composant collect-tiktok-comments: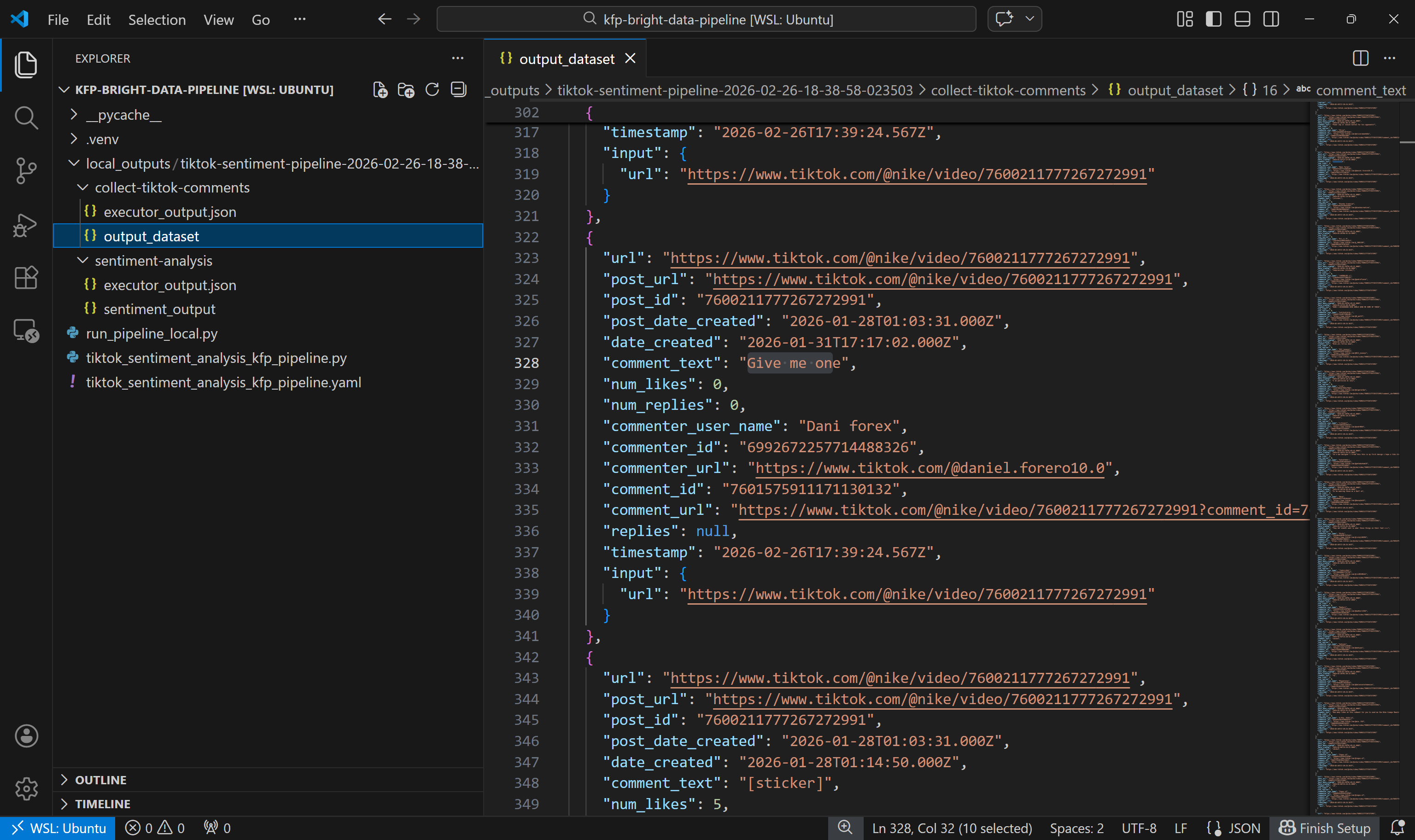
Cet ensemble de données comprend les commentaires renvoyés par TikTok Scraper via Bright Data pour les deux publications spécifiées, comme prévu.
Ensuite, examinez l’ensemble de données de sortie de l’analyse des sentiments :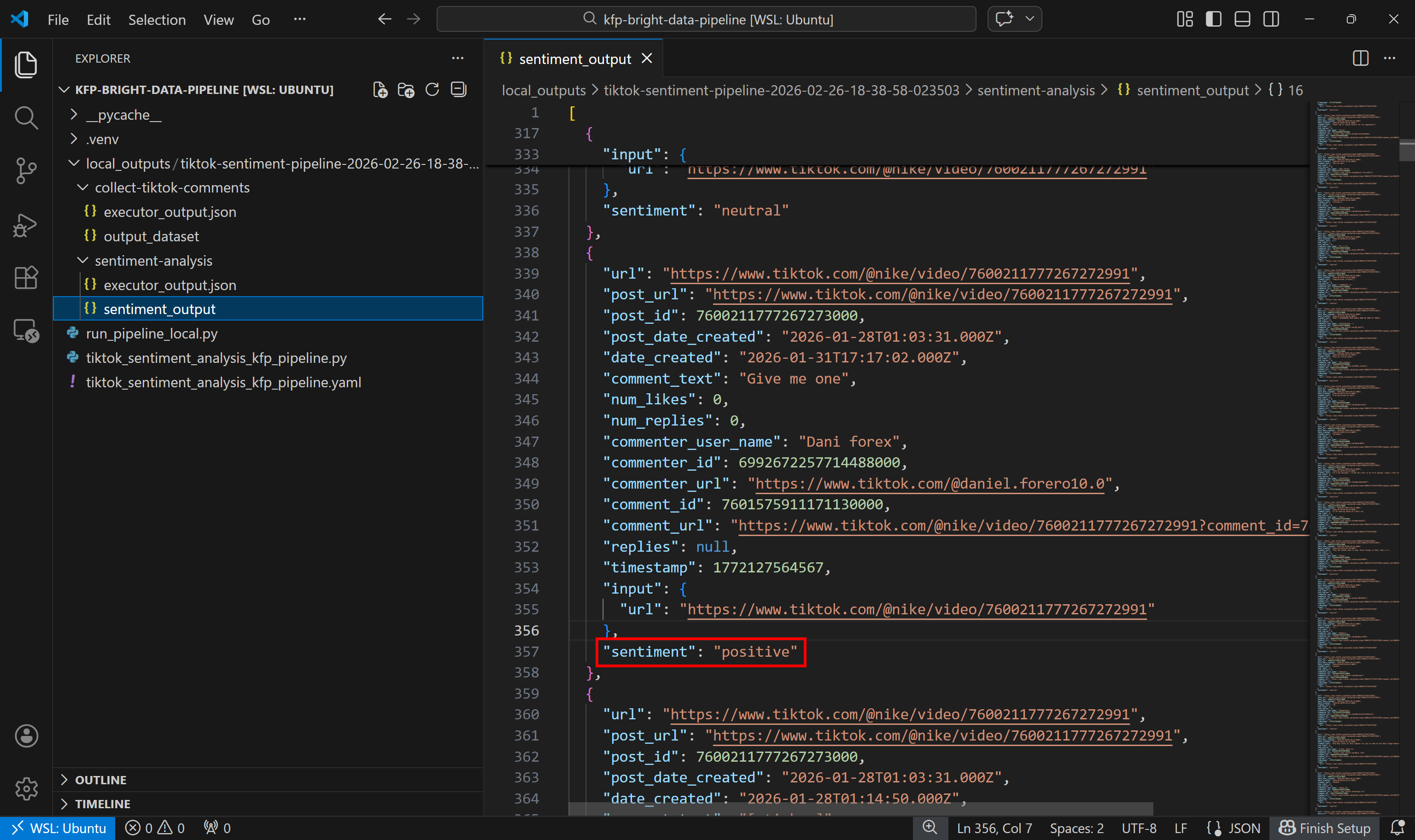
Remarquez comment chaque commentaire a été étiqueté comme positif, négatif ou neutre par le composant d’analyse des sentiments.
Et voilà ! Vous venez de voir comment créer un pipeline Kubeflow qui récupère des données web récentes à l’aide de Bright Data, puis les analyse.
Conclusion
Dans ce tutoriel, vous avez compris pourquoi les pipelines Kubeflow tirent parti des données récentes récupérées via le Scraping web. Vous avez notamment vu l’importance d’avoir un composant dédié dans votre pipeline pour collecter des données récentes, contextuelles et structurées sur le web.
Bright Data prend en charge cette fonctionnalité grâce à une large gamme d’API de Scraping web, qui agissent comme des flux de données structurés pour vos pipelines. Comme démontré, grâce aux API de Scraping web de Bright Data, la création d’un composant de collecte de données web dans un pipeline Kubeflow est assez simple !
Créez un compte Bright Data gratuit et commencez dès aujourd’hui à explorer nos solutions de données web !





