

Dans ce guide, vous verrez
- Ce que signifie “scraper” un site web en Markdown et pourquoi c’est utile.
- Les principales approches pour convertir le HTML d’une page web en Markdown pour les sites statiques et dynamiques.
- Comment utiliser Python pour convertir une page web en Markdown.
- Les limites de cette solution et comment les surmonter avec Bright Data.
Plongeons dans le vif du sujet !
Que signifie “extraire un site Web vers Markdown” ?
Scraper un site Web en Markdown signifie convertir son contenu en Markdown.
Plus précisément, il s’agit de prendre le code HTML d’une page web et de le transformer en format de données Markdown.
Par exemple, connectez-vous à un site, ouvrez les DevTools et copiez son HTML :
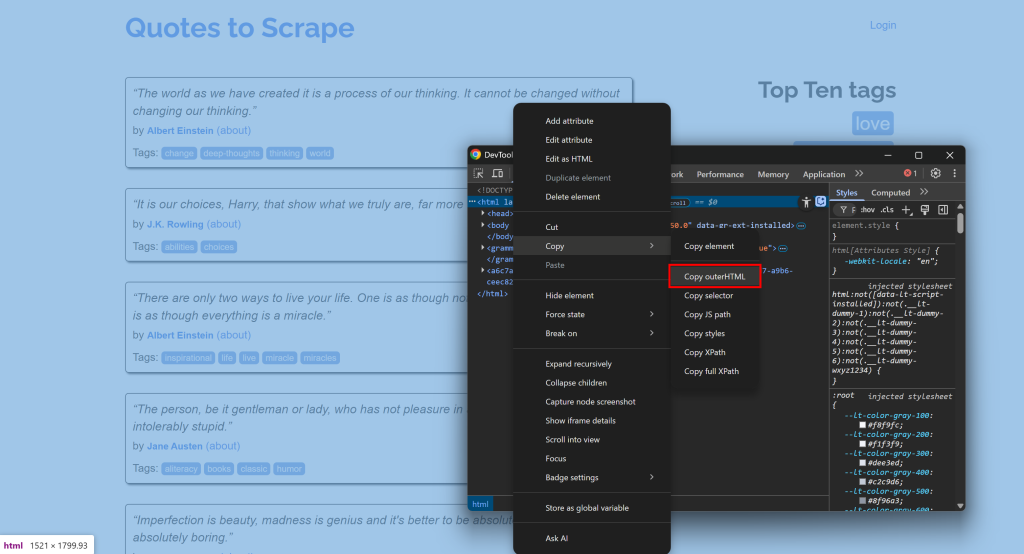
Collez-le ensuite dans un convertisseur HTML-Markdown:
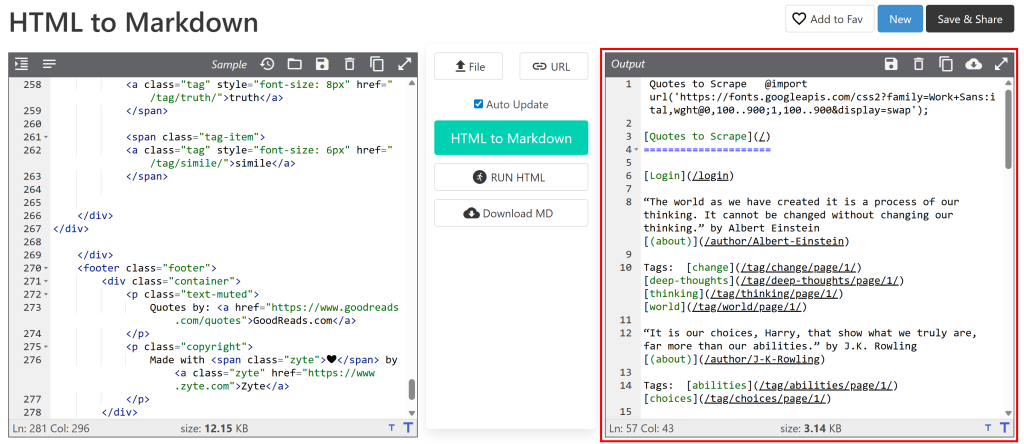
La sortie ressemblera au document Markdown que vous souhaitez obtenir via le Scraping web. L’objectif est maintenant d’automatiser ce processus, ce qui est exactement l’objet de cet article !
[Pourquoi Markdown ?
Pourquoi Markdown plutôt qu’un autre format (comme du texte brut) ? Parce que, comme le montre notre benchmark des formats de données, Markdown est l’un des meilleurs formats pour l’ingestion LLM. Les trois principales raisons sont les suivantes :
- Il préserve la plupart de la structure et des informations de la page (par exemple, les liens, les images, les titres, etc.).
- Il est concis, ce qui permet de limiter l’utilisation de jetons et d’accélérer le traitement par l’IA.
- Les LLM ont tendance à comprendre le Markdown beaucoup mieux que le HTML.
C’est pourquoi les meilleurs outils de scraping de l’IA travaillent par défaut avec Markdown.
Approches HTML à Markdown
Vous savez maintenant que le scraping d’un site en Markdown consiste simplement à convertir le HTML de ses pages en Markdown. À un niveau élevé, le processus se présente comme suit :
- Se connecter au site.
- Récupérer le code HTML sous forme de chaîne de caractères.
- Utiliser une bibliothèque HTML-Markdown pour générer la sortie Markdown.
Le problème est que toutes les pages web ne sont pas livrées de la même manière. Les deux premières étapes peuvent varier considérablement selon que la page cible est statique ou dynamique. Voyons comment gérer les deux scénarios en élargissant les étapes nécessaires !
Étape 1 : Se connecter à un site
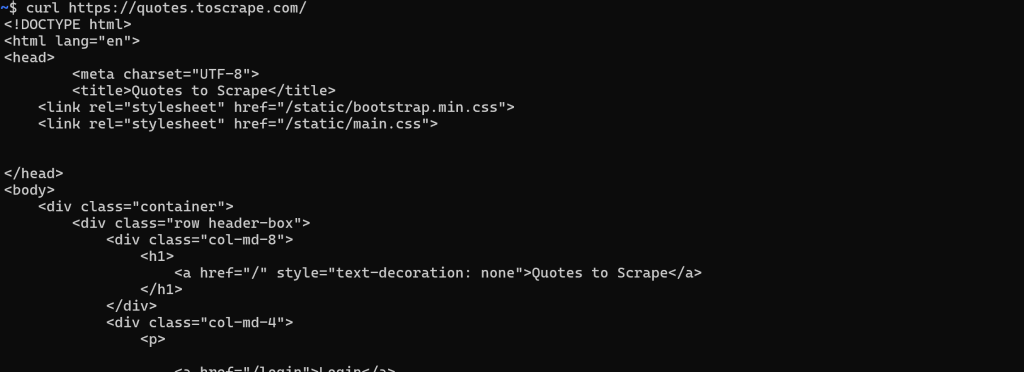
Sur une page web statique, le document HTML renvoyé par le serveur est exactement ce que vous voyez dans le navigateur. En d’autres termes, tout est fixe et intégré dans le document HTML produit par le serveur.
Dans ce cas, la récupération du HTML est simple. Il suffit d’effectuer une requête GET HTTP à l’URL de la page avec n’importe quel client HTTP:
En revanche, sur un site web dynamique, la majeure partie (ou une partie) du contenu est récupérée via AJAX et rendue dans le navigateur via JavaScript. Cela signifie que le document HTML initial renvoyé par le serveur web ne contient que le strict minimum. Ce n’est qu’après l’exécution de JavaScript du côté client que la page est remplie avec le contenu complet :

Dans de tels cas, vous ne pouvez pas vous contenter de récupérer le HTML avec un simple client HTTP. Vous avez besoin d’un outil capable de rendre la page, tel qu’un outil d’automatisation du navigateur. Des solutions telles que Playwright, Puppeteer ou Selenium vous permettent de contrôler de manière programmatique un navigateur pour charger la page cible et obtenir son HTML entièrement rendu.
Étape 2 : Récupérer le code HTML sous forme de chaîne de caractères
Pour les pages web statiques, cette étape est simple. La réponse du serveur web à votre requête GET contient déjà le document HTML complet sous forme de chaîne. La plupart des clients HTTP, comme Requests de Python, fournissent une méthode ou un champ pour y accéder directement :
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Accéder au contenu HTML de la page sous forme de chaîne de caractères
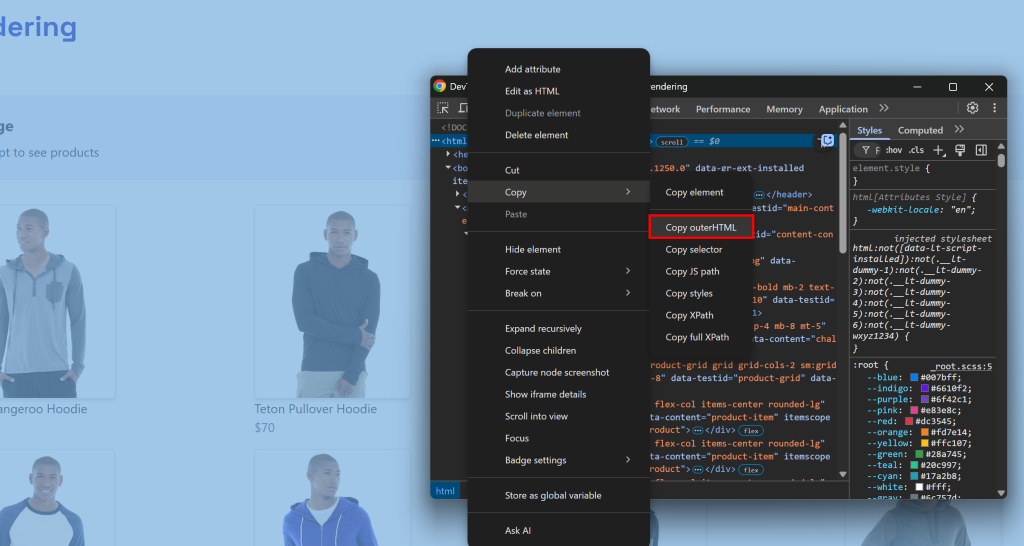
html = response.textPour les sites web dynamiques, les choses sont beaucoup plus délicates. Cette fois, vous n’êtes pas intéressé par le document HTML brut renvoyé par le serveur. Au lieu de cela, vous devez attendre que le navigateur rende la page, que le DOM se stabilise, puis accéder au HTML final.
Cela correspond à ce que vous feriez normalement manuellement en ouvrant DevTools et en copiant le HTML à partir du nœud <html>:
La difficulté consiste à savoir quand le rendu de la page est terminé. Les stratégies les plus courantes sont les suivantes :
- Attendre l’événement
DOMContentLoaded: Se déclenche lorsque le HTML initial est analysé et que les<script>différés sont chargés et exécutés. L’attente de cet événement est le comportement par défaut de Playwright. - Attendre l’événement
load: Se déclenche lorsque la page entière a été chargée, y compris les feuilles de style, les scripts, les iframes et les images (à l’exception de celles chargées paresseusement). - Attendre l’événement
networkidle: Considère que le rendu est terminé lorsqu’il n’y a pas de demande de réseau pendant une durée donnée (par exemple,500 msdans Playwright). Cette méthode n’est pas fiable pour les sites dont le contenu est mis à jour en temps réel, car elle ne se déclenchera jamais. - Attendre des éléments spécifiques: Utilisez les API d’attente personnalisées fournies par les frameworks d’automatisation des navigateurs pour attendre que certains éléments apparaissent dans le DOM.
Une fois la page entièrement rendue, vous pouvez extraire le code HTML à l’aide de la méthode ou du champ spécifique fourni par l’outil d’automatisation du navigateur. Par exemple, dans Playwright:
html = attend page.content()Étape 3 : Utiliser une bibliothèque HTML-to-Markdown pour générer la sortie Markdown
Une fois que vous avez récupéré le code HTML sous forme de chaîne, il vous suffit de l’envoyer à l’une des nombreuses bibliothèques HTML-Markdown disponibles. Les plus populaires sont les suivantes :
| Bibliothèque | Langage de programmation | Étoiles GitHub |
|---|---|---|
markdownify |
Python | 1.8k+ |
turndown |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-to-markdown |
Go | 3k+ |
html-à-markdown |
PHP | 1.8k+ |
Scraping d’un site web en Markdown : Exemples pratiques en Python
Dans cette section, vous verrez des exemples complets de scripts Python pour convertir un site web en Markdown. Les scripts ci-dessous mettent en œuvre les étapes expliquées précédemment. Notez que vous pouvez facilement convertir la logique en JavaScript ou en tout autre langage de programmation.
L’entrée sera l’URL d’une page web, et la sortie sera le contenu Markdown correspondant !
Sites statiques
Dans cet exemple, nous utiliserons les deux bibliothèques suivantes :
requests: Pour effectuer la requête GET et obtenir le code HTML de la page sous forme de chaîne de caractères.markdownify: Pour convertir le HTML de la page en Markdown.
Installez les deux avec :
pip install requests markdownifyLa page cible sera la page statique “Quotes to Scrape“. Vous pouvez atteindre l’objectif avec le snippet suivant :
import requests
from markdownify import markdownify as md
# L'URL de la page à récupérer
url = "http://quotes.toscrape.com/"
# Récupérer le contenu HTML à l'aide de requêtes
response = requests.get(url)
# Obtenir le HTML sous forme de chaîne de caractères
html_content = response.text
# Convertir le contenu HTML en Markdown
markdown_content = md(html_content)
# Imprimer la sortie Markdown
print(markdown_content)En option, vous pouvez exporter le contenu vers un fichier .md avec :
avec open("page.md", "w", encoding="utf-8") as f :
f.write(markdown_content)Le résultat du script sera :
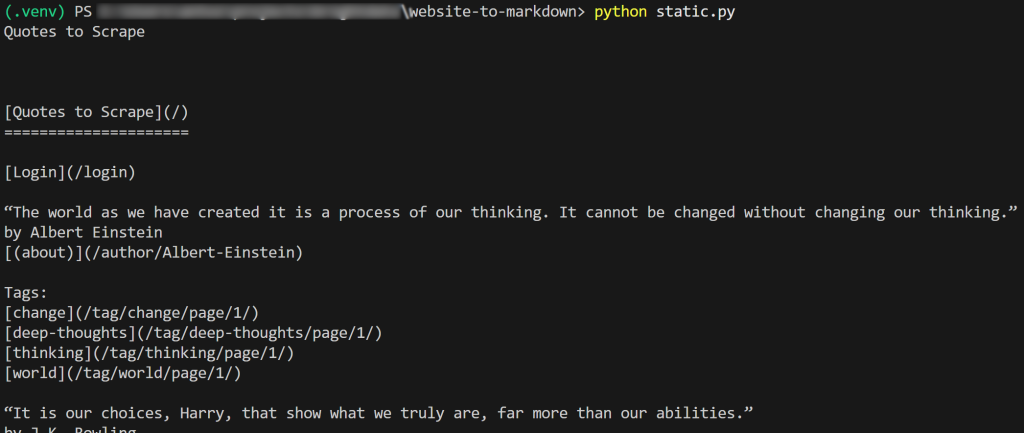
Si vous copiez le résultat Markdown et le collez dans un moteur de rendu Markdown, vous verrez :
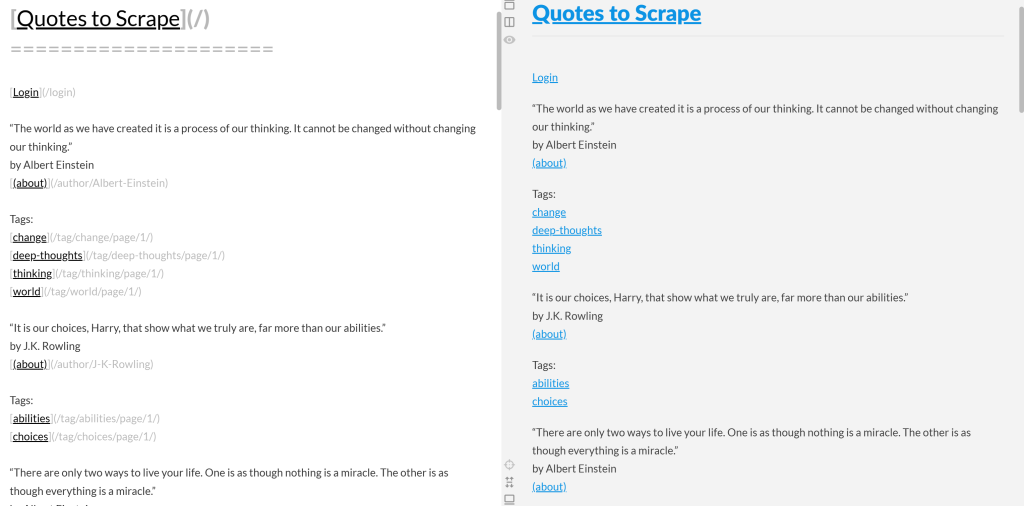
Remarquez que cela ressemble à une version simplifiée du contenu original de la page “Citations à gratter” :
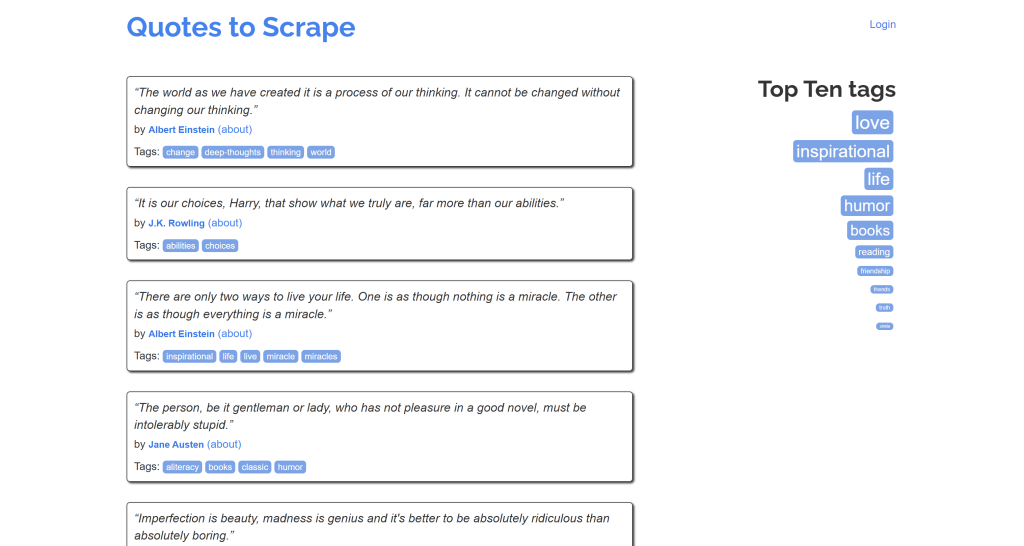
Mission accomplie !
Sites dynamiques
Ici, nous allons utiliser ces deux bibliothèques :
playwright: Pour rendre la page cible dans une instance de navigateur contrôlée.markdownify: Pour convertir le DOM de la page en Markdown.
Installez les deux dépendances ci-dessus avec :
pip install playwright markdownifyEnsuite, complétez l’installation de Playwright avec :
python -m playwright installLa destination sera la page dynamique “JavaScript Rendering” sur le site ScrapingCourse.com :
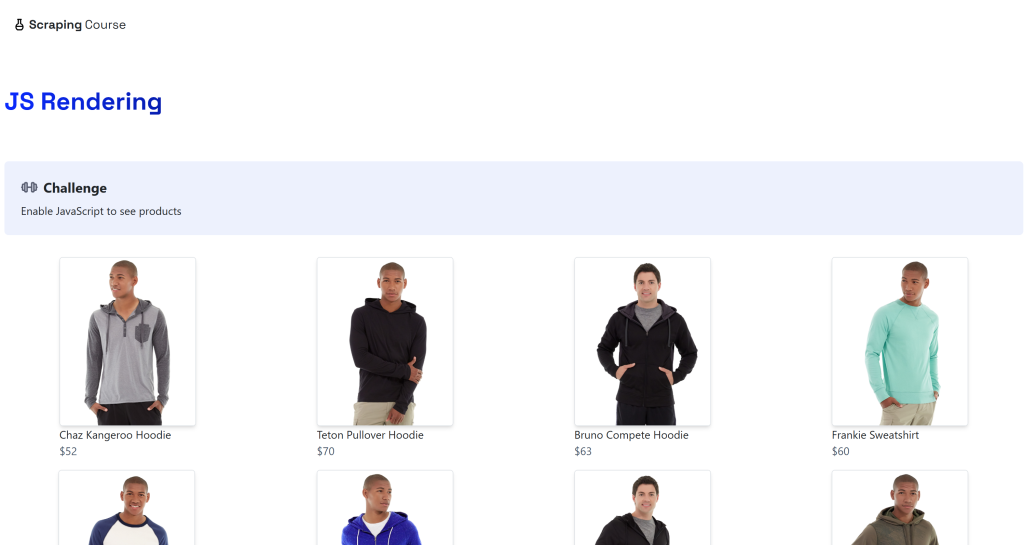
Cette page récupère les données du côté client via AJAX et les rend à l’aide de JavaScript :
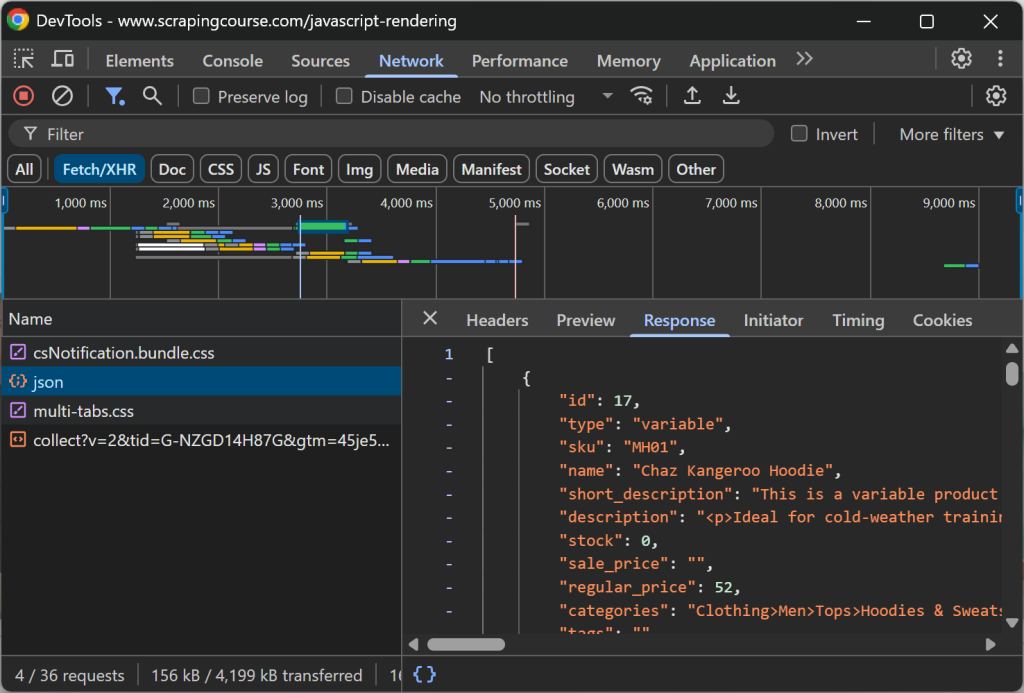
Scraper un site web dynamique en Markdown comme ci-dessous :
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
avec sync_playwright() as p :
# Lancer un navigateur sans tête
browser = p.chromium.launch()
page = browser.new_page()
# URL de la page dynamique
url = "https://scrapingcourse.com/javascript-rendering"
# Naviguer vers la page
page.goto(url)
# Attendre jusqu'à 5 secondes que le premier élément du lien produit soit rempli
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Obtenir le rendu HTML complet
rendered_html = page.content()
# Convertit le HTML en Markdown
markdown_content = md(rendered_html)
# Imprimer le texte Markdown résultant
print(markdown_content)
# Fermer le navigateur et libérer ses ressources
browser.close()Dans l’extrait ci-dessus, nous avons opté pour l’option 4 (“Attendre des éléments spécifiques”) parce qu’elle est la plus fiable. En détail, regardez cette ligne de code :
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)Cette ligne attend jusqu’à 5000 millisecondes (5 secondes) que l’élément .product-link (une balise <a> ) ait un attribut href non vide. Cela suffit pour indiquer que le premier élément produit de la page a été rendu, ce qui signifie que les données ont été récupérées et que le DOM est désormais stable.
Le résultat sera le suivant :
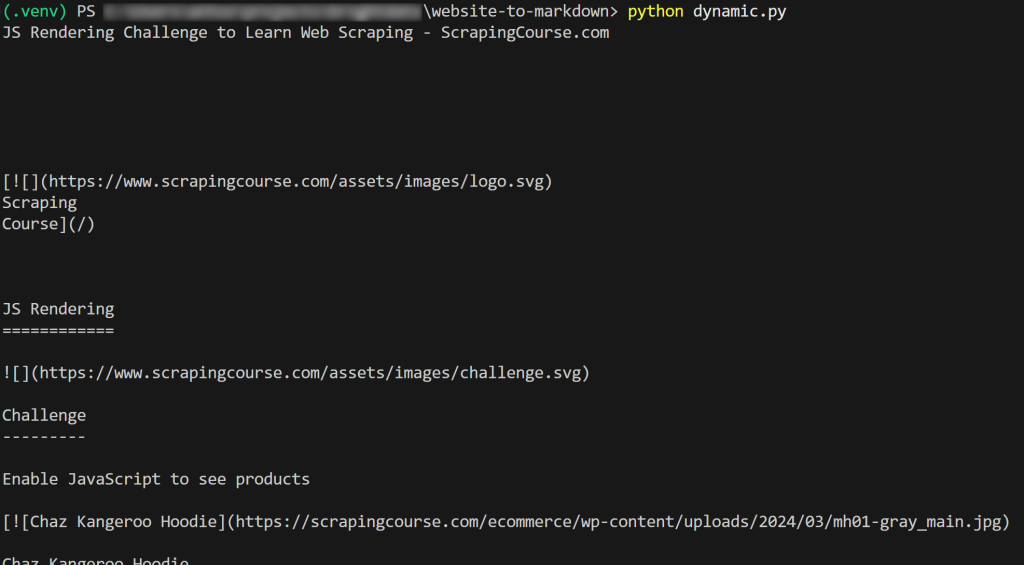
Et voilà ! Vous venez d’apprendre comment récupérer un site web en Markdown.
Limites de ces approches et solution
Tous les exemples de ce billet de blog ont un aspect fondamental en commun : ils se réfèrent à des pages qui ont été conçues pour être faciles à gratter !
Malheureusement, la plupart des pages web du monde réel ne sont pas aussi ouvertes aux bots de Scraping web. Bien au contraire, de nombreux sites mettent en œuvre des protections anti-scraping telles que les CAPTCHA, les interdictions d’IP, les empreintes de navigateur, et bien plus encore.
En d’autres termes, vous ne pouvez pas vous attendre à ce qu’une simple requête HTTP ou une instruction Playwright goto() fonctionne comme prévu. Lorsque vous ciblez la plupart des sites web du monde réel, vous pouvez rencontrer des erreurs 403 Forbidden:

ou des pages d’erreur ou de vérification humaine :
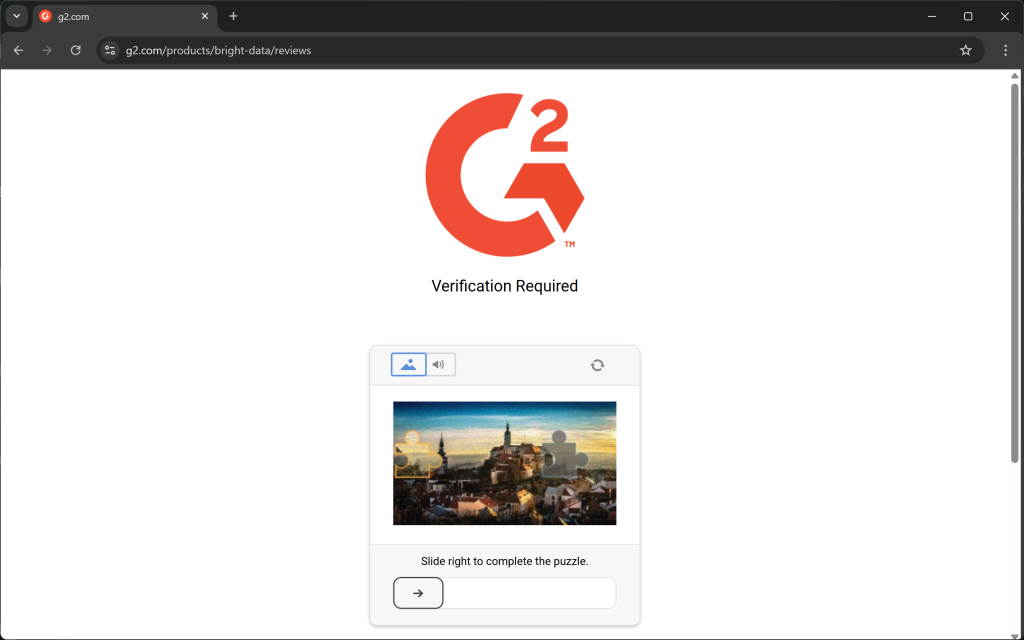
Un autre aspect clé à prendre en compte est que la plupart des bibliothèques HTML-Markdown effectuent une conversion de données brutes. Cela peut conduire à des résultats indésirables. Par exemple, si une page contient des éléments <style> ou <script> intégrés directement dans le HTML, leur contenu (c’est-à-dire le code CSS et JavaScript, respectivement) sera inclus dans la sortie Markdown :

Cela n’est généralement pas souhaitable, en particulier si vous prévoyez d’envoyer le Markdown à un LLM pour le traitement des données. Après tout, ces éléments de texte ne font qu’ajouter du bruit.
La solution ? S’appuyer sur une API Web Unlocker dédiée qui peut accéder à n’importe quel site, quelles que soient ses protections, et produire du Markdown prêt pour le LLM. Cela garantit que le contenu extrait est propre, structuré et prêt pour les tâches d’IA en aval.
Scraping web avec Web Unlocker
Web Unlocker de Bright Data est une API de scraping web basée sur le cloud qui peut renvoyer le HTML de n’importe quelle page web. Et ce, quelles que soient les protections anti-scraping ou anti-bot en place, et que la page soit statique ou dynamique.
L’API est soutenue par un réseau de Proxy de plus de 150 millions d’IP, ce qui vous permet de vous concentrer sur la collecte de données pendant que Bright Data s’occupe de l’infrastructure complète de déblocage, du rendu JavaScript, de la Résolution de CAPTCHA, de la mise à l’échelle et des mises à jour de maintenance.
L’utilisation est simple. Envoyez une requête HTTP POST à Web Unlocker avec les bons arguments, et vous obtiendrez en retour la page web entièrement débloquée. Vous pouvez également configurer l’API pour qu’elle renvoie le contenu au format Markdown optimisé par LLM.
Suivez le guide de configuration initiale, puis utilisez Web Unlocker pour scraper un site web au format Markdown avec seulement quelques lignes de code :
# pip install requests
import requests
# Remplacez les valeurs suivantes par celles de votre compte Bright Data
BRIGHT_DATA_API_KEY= "<VOTRE_CLÉ_API_DE_BRIGHT_DATA>"
WEB_UNLOCKER_ZONE = "<VOTRE_NOM_DE_ZONE_DE_DÉBLOCAGE_WEB>"
# Remplacer par votre URL cible
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Préparer les en-têtes nécessaires
headers = {
"Authorization" : f "Bearer {BRIGHT_DATA_API_KEY}", # Pour l'authentification
"Content-Type" : "application/json"
}
# Préparer la charge utile POST de Web Unlocker
payload = {
"url" : url_to_scrape,
"zone" : WEB_UNLOCKER_ZONE,
"format" : "raw",
"data_format" : "markdown" # Pour obtenir la réponse en tant que contenu Markdown
}
# Faites une demande POST à l'API Web Unlocker de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=en-têtes
)
# Obtenir la réponse Markdown et l'imprimer
markdown_content = response.text
print(markdown_content)Exécutez le script et vous obtiendrez :
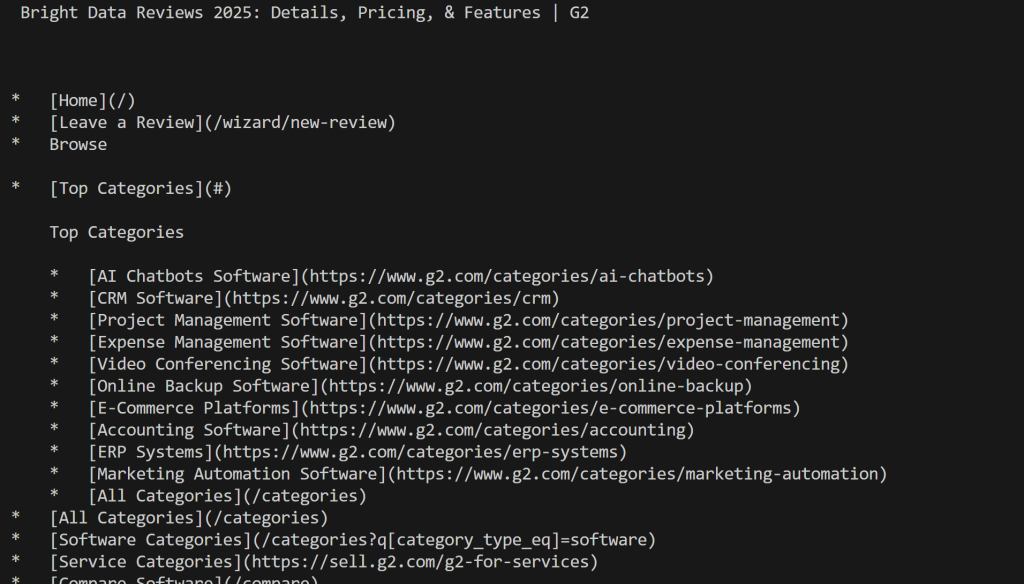
Notez que, cette fois, vous n’avez pas été bloqué par G2. Au lieu de cela, vous avez obtenu le contenu réel de Mardkwon, comme vous le souhaitiez.
C’est parfait ! Convertir un site web en Markdown n’a jamais été aussi facile.
Remarque: cette solution est disponible via plus de 75 intégrations avec des outils d’agents IA tels que CrawlAI, Agno, LlamaIndex et LangChain. En outre, elle peut être utilisée directement via l’outil scrape_as_markdown sur le serveur Bright Data Web MCP.
Conclusion
Dans cet article de blog, vous avez découvert pourquoi et comment convertir une page Web en Markdown. Comme nous l’avons vu, la conversion de HTML en Markdown n’est pas toujours simple en raison de difficultés telles que les protections anti-scraping et les résultats Markdown sous-optimaux.
Bright Data vous couvre avec Web Unlocker, une API de scraping web basée sur le cloud capable de convertir n’importe quelle page web en Markdown optimisé par LLM. Vous pouvez appeler cette API manuellement ou l’intégrer directement dans des solutions de création d’agents IA ou via l’intégration Web MCP.
N’oubliez pas que Web Unlocker n’est qu’un des nombreux outils de données web et de scraping disponibles dans l ‘infrastructure IA de Bright Data.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à explorer nos solutions de données web prêtes pour l’IA !




