

Python est de loin le langage de Scraping web dominant à travers le monde. Cela n’a pas toujours été le cas. À la fin des années 1990 et au début des années 2000, le Scraping web était presque exclusivement réalisé en Perl et PHP.
Aujourd’hui, nous allons comparer Python à l’un des titans du développement web du passé, PHP. Nous passerons en revue certaines différences entre les deux langages et nous verrons lequel offre la meilleure expérience de Scraping web.
Prérequis
Si vous décidez de suivre ce tutoriel, vous devrez avoir installé Python et PHP. Cliquez sur les liens de téléchargement respectifs et suivez les instructions correspondant à votre système d’exploitation.
- Python
- PHP
Vous pouvez vérifier votre installation de chacun d’eux à l’aide des commandes suivantes.
Python
python --version
Vous devriez obtenir un résultat similaire à celui-ci.
Python 3.10.12
PHP
php --version
Voici le résultat.
PHP 8.3.14 (cli) (compilé le 25 novembre 2024 à 18:07:16) (NTS)
Copyright (c) The PHP Group
Moteur Zend v4.3.14, Copyright (c) Zend Technologies
avec Zend OPcache v8.3.14, Copyright (c), par Zend Technologies
Une compréhension de base des deux langages serait utile, mais ce n’est pas une exigence. En fait, je n’avais jamais écrit de code PHP jusqu’à présent !
Comparaison entre Python et PHP pour le Scraping web
Avant de créer notre projet, nous devons examiner chacun de ces langages plus en détail.
- Syntaxe: Python a une syntaxe plus lisible et largement adoptée, en particulier dans la communauté des données.
- Bibliothèque standard: les deux langages offrent des bibliothèques standard riches.
- Cadres de scraping: Python dispose d’un choix beaucoup plus large de cadres de scraping.
- Performances: PHP tend à offrir des vitesses plus élevées, car il a été conçu pour fonctionner sur le Web.
- Maintenance: Python est généralement plus facile à maintenir grâce à sa syntaxe claire et au soutien important de sa communauté.
| Caractéristique | Python | PHP |
|---|---|---|
| Facilité d’utilisation | Adapté aux débutants et facile à apprendre | Plus difficile pour les développeurs débutants |
| Bibliothèque standard | Riche et complète | Riche et complète |
| Outils de scraping | Nombreux outils de scraping tiers | Écosystème beaucoup plus restreint |
| Prise en charge des données | Conçu pour le traitement des données | Bibliothèques et outils de base disponibles |
| Communauté | Grandes communautés et assistance | Communautés plus petites avec assistance limitée |
| Maintenance | Facile à entretenir, utilisation répandue | Difficile, les programmeurs sont difficiles à trouver |
Que scraper ?
Comme il s’agit uniquement d’une démonstration et que nous voulons un site qui reste cohérent pour l’évaluation comparative, nous allons utiliser quotes.toscrape.com. Ce site nous offre un contenu cohérent et ne bloque pas les Scrapers. Il est parfait pour les cas de test.
Dans l’image ci-dessous, vous pouvez voir l’un des éléments de citation sur la page. Il s’agit d’une balise div avec la classe quote. Nous devons d’abord trouver tous ces éléments.
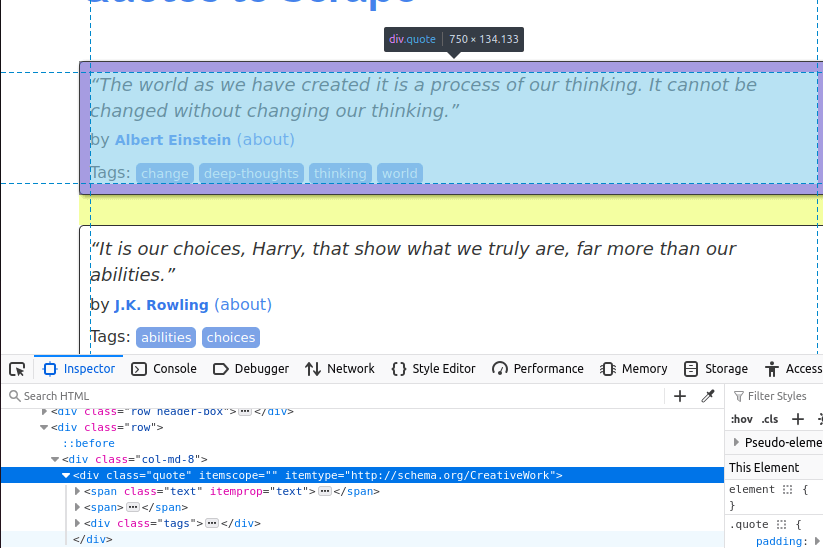
Une fois que nous avons trouvé toutes les cartes de citations sur la page, nous devons extraire les éléments individuels de chacune d’elles.
Le texte est intégré dans un élément span avec la classe text.
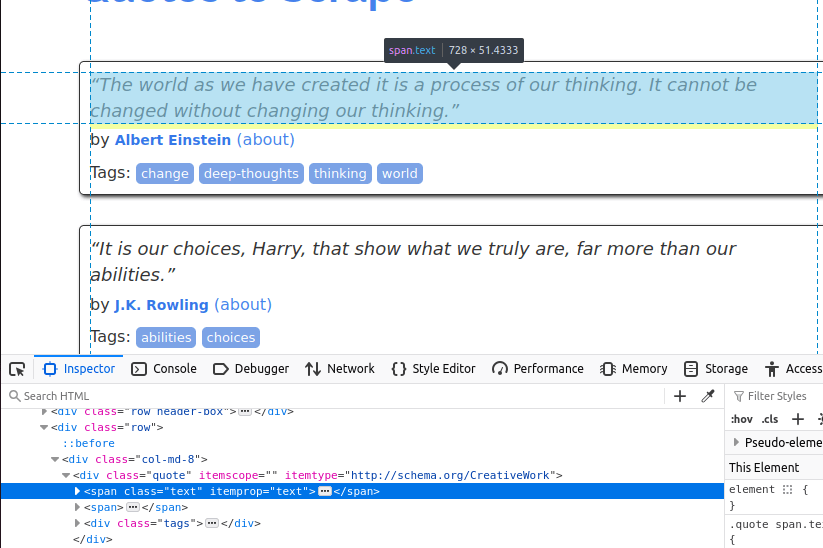
Nous devons maintenant trouver l’auteur. Celui-ci se trouve dans un petit élément avec la classe author.
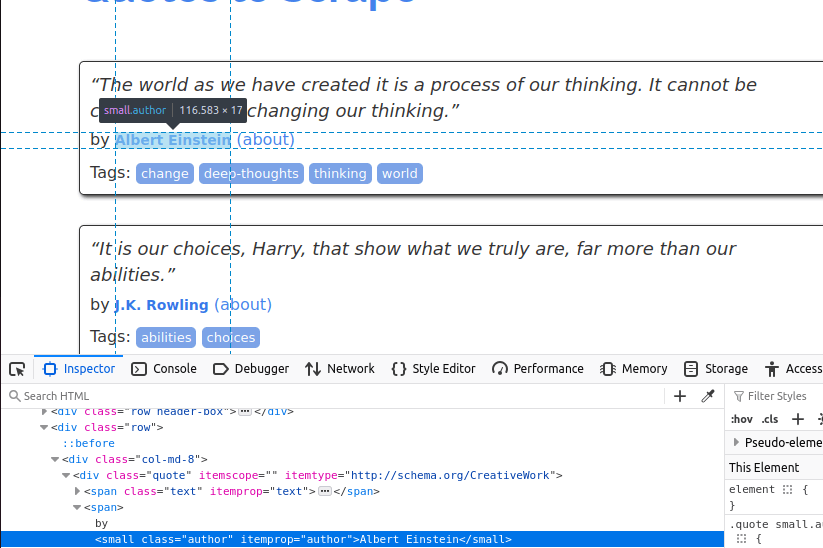
Enfin, nous allons extraire les balises. Elles se trouvent à l’intérieur d'éléments avec la classe tag.

Maintenant que nous savons quelles données nous voulons, nous sommes prêts à commencer.
Pour commencer
Il est maintenant temps de tout configurer. Nous aurons besoin de quelques dépendances avec Python et PHP.
Python
Pour Python, nous devons installer Requests et BeautifulSoup.
Nous pouvons les installer tous les deux avec pip.
pip install requests
pip install beautifulsoup4
PHP
Apparemment, toutes ces dépendances sont censées être préinstallées avec PHP. Cependant, lorsque j’ai voulu les utiliser, elles ne l’étaient pas.
sudo apt install php-curl
sudo apt install php-xml
Une fois nos dépendances installées, nous sommes prêts à commencer à coder.
Récupération des données
J’ai commencé par écrire le Scraper suivant en Python. Le code ci-dessous effectue une série de requêtes sur quotes.toscrape.com. Il extrait le texte, le nom et l’auteur de chaque citation. Une fois toutes les citations récupérées, nous les écrivons dans un fichier JSON. N’hésitez pas à le copier/coller dans votre propre fichier Python.
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("Récupération terminée. Citations enregistrées dans quotes.json.")
- Tout d’abord, nous définissons les variables pour
page_numberetoutput_json. while page_number <= 5indique au Scraper de continuer son travail jusqu’à ce que nous ayons scrapé 5 pages.response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")envoie une requête à la page sur laquelle nous nous trouvons.- Nous trouvons tous nos éléments
divcibles avecdivs = soup.select("div[class='quote']"). - Nous parcourons les
divset extrayons leurs données :quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: nous trouvons tous les élémentstag_holder, puis nous extrayons leur texte individuellement.
- Une fois que nous avons terminé, nous enregistrons le tableau
output_jsondans un fichier etaffichonsun message dans le terminal à l’aide de la fonctionprint().
Voici des captures d’écran de certaines de nos exécutions. Nous avons effectué davantage d’exécutions, mais par souci de concision, nous utiliserons ici un échantillon de 3 exécutions.
L’exécution 1 a pris 11,642 secondes.

L’exécution 2 a pris 11,413 secondes.

L’exécution 3 a pris 10,258 secondes.

Notre temps d’exécution moyen avec Python est de 11,104 secondes.
PHP
Après avoir écrit le code Python, j’ai demandé à ChatGPT de le réécrire pour moi en PHP. Au départ, le code ne fonctionnait pas, mais après quelques modifications mineures, il était utilisable.
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "Erreur lors de la récupération de la page $pageNumbern";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Récupération terminée. Citations enregistrées dans quotes.json.n";
- Comme dans le code Python, nous commençons par les variables
pageNumberetoutputJson. - Nous utilisons une boucle
whilepour maintenir la durée d’exécution du scraping proprement dit :while ($pageNumber <= 5). $ch = curl_init($url);configure notre requête HTTP. Nous utilisonscurl_setopt()pour suivre les redirections.$response = curl_exec($ch);exécute la requête HTTP.$dom = new DOMDocument();configure un nouvel objetDOMque nous pouvons utiliser. Cela s’apparente à l’utilisation deBeautifulSoup()précédemment.- Nous obtenons nos
divsen utilisant leur Xpath au lieu de leur sélecteur CSS :$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";renvoie le texte de chaque citation.$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";nous donne l’auteur.- Nous obtenons nos
balisesen recherchant à nouveau tous les éléments de balise et en les parcourant à l’aide d’une boucle afin d’extraire leur texte. - Enfin, lorsque tout est terminé, nous enregistrons notre sortie dans un fichier json et affichons un message à l’écran.
Voici les résultats de notre exécution avec PHP.
L’exécution 1 a pris 11,351 secondes.

L’exécution 2 a pris 9,846 secondes.

L’exécution 3 a pris 9,795 secondes.

Notre moyenne PHP était de 10,33 secondes.
Après d’autres tests, PHP a continué à donner des résultats plus rapides… Parfois jusqu’à 7 secondes !
Envisagez d’utiliser Bright Data
Si les sections ci-dessus vous ont interpellé, écrivez des Scrapers web ! Lorsque vous extrayez des données pour gagner votre vie, ce sont des codes comme ceux que vous voyez ci-dessus que vous écrivez tout le temps !
Nous proposons une gamme de produits qui peuvent rendre vos scrapers plus robustes.Le Navigateur de scrapingvous offre un navigateur distant avec intégration Proxy et rendu JavaScript intégrés. Si vous souhaitez simplement des proxys et la Résolution de CAPTCHA sans navigateur, utilisezWeb Unlocker.
Les Scrapers ne conviennent pas à tout le monde.
Si vous souhaitez simplement obtenir vos données et passer à autre chose, jetez un œil à nos Jeux de données.Nous nous chargeons du scraping à votre place.Découvrez nosJeux de données prêts à l’emploi. Nos Jeux de données les plus populaires sont LinkedIn, Amazon, Crunchbase, Zillow et Glassdoor. Vous pouvez consulter gratuitement des exemples de données et télécharger des rapports au format CSV ou JSON.
Conclusion
Avec une vitesse moyenne de 11,104 secondes en Python et de 10,33 secondes en PHP, notre scraper PHP était systématiquement plus rapide que le scraper Python. Cela pourrait s’expliquer en partie par la latence du serveur, mais lors de tests supplémentaires, PHP a continué à battre Python à presque chaque exécution.
Si PHP est clairement battu en termes de vitesse, ce n’est pas tout à fait vrai en ce qui concerne la syntaxe. De nos jours, peu de développeurs sont à l’aise avec la syntaxe utilisée dans des langages tels que PHP ou Perl. Ce sont les langages de script d’antan. De plus, votre équipe n’est peut-être pas à l’aise avec PHP. Il faut un type particulier de codeur pour écrire ce genre de code en permanence et maintenir les applications héritées en état de fonctionnement.
Passez à la vitesse supérieure avec Bright Data. Inscrivez-vous dès maintenant et commencez votre essai gratuit !





