
Dans ce guide, vous apprendrez :
- Qu’est-ce que Puppeteer Real Browser ?
- Comment il fonctionne pour éviter la détection des bots et la résolution de CAPTCHA
- Comment il se compare à Puppeteer vanilla
- Comment l’utiliser contre les systèmes de détection de bots dans le monde réel
- Quelles sont ses principales alternatives
- Ses principales limites
- Une meilleure approche de l’automatisation des navigateurs anti-bots
Plongeons-nous dans le vif du sujet !
Qu’est-ce que Puppeteer Real Browser ?
Puppeteer Real Browser est une bibliothèque JavaScript qui permet au navigateur contrôlé par Puppeteer de se comporter davantage comme un utilisateur réel. Cela réduit la détection des bots sur les services WAF tels que Cloudflare et autres services similaires. Elle prend également en charge la Résolution de CAPTCHA, y compris Cloudflare Turnstile.
La bibliothèque étend Puppeteer avec des configurations personnalisées tout en prenant en charge les Proxies et toutes les autres fonctionnalités de Puppeteer vanilla. Elle est open source, avec plus de 1 000 étoiles sur GitHub, disponible sur npm sous le nom de puppeteer-real-browser et prend en charge Docker pour le déploiement.
Remarque: en février 2026, l’auteur de la bibliothèque, mdervisaygan, a annoncé que le projet ne ferait plus l’objet de mises à jour. Cela ne signifie pas pour autant que Puppeteer Real Browser est nécessairement mort, car les membres de la communauté peuvent poursuivre son développement via un fork.
Comment fonctionne Puppeteer Real Browser ?
Si vous avez déjà travaillé avec des outils d’automatisation de navigateur tels que Puppeteer, Playwright ou Selenium, vous savez que les navigateurs contrôlés par ces outils peuvent être détectés par les systèmes anti-bot. Cela est particulièrement vrai lorsque vous travaillez en mode headless, même en utilisant les meilleurs navigateurs headless.
Les blocages se produisent parce que les bibliothèques d’automatisation configurent les navigateurs de manière à les rendre plus faciles à contrôler. Les solutions anti-bot recherchent ces configurations et ces « fuites » afin de déterminer si les requêtes proviennent d’un véritable utilisateur humain utilisant un navigateur classique ou d’un bot automatisé.
Puppeteer Real Browser résout ce problème à l’aide de Rebrowser, un ensemble de correctifs pour Puppeteer et Playwright conçus pour empêcher la détection de l’automatisation.
Rebrowser modifie directement puppeteer-core, en corrigeant le runtime du navigateur afin de supprimer les traces de bot laissées par Puppeteer. Ces modifications font que le navigateur ressemble davantage à une session utilisateur réelle, ce qui réduit les risques d’être bloqué par les systèmes anti-bot.
Cependant, les WAF tels que Cloudflare peuvent toujours présenter des CAPTCHA en un clic:
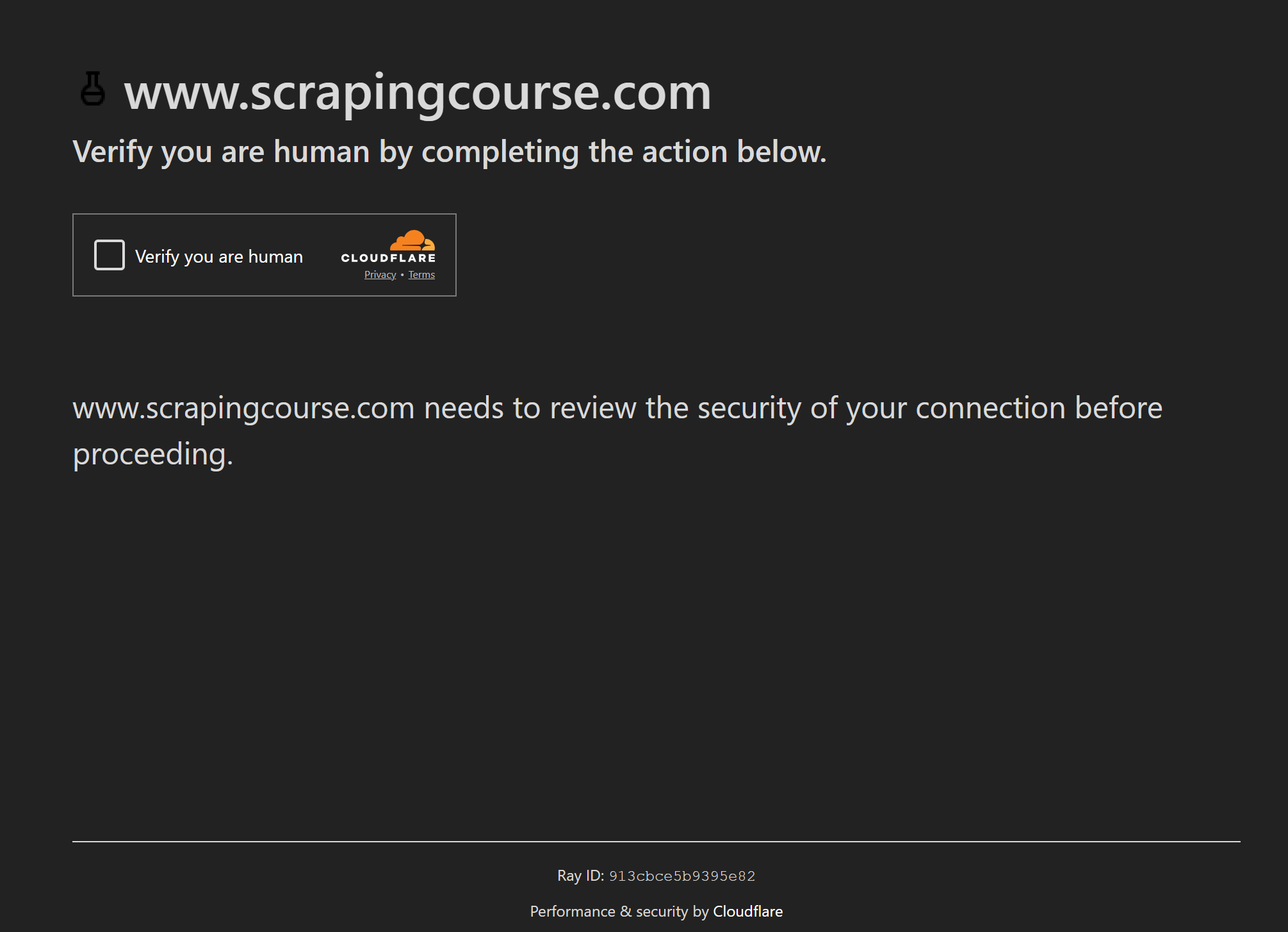
Dans ce cas, Puppeteer Real Browser s’appuie sur ghost-cursor pour interagir avec les CAPTCHA comme le ferait un utilisateur réel. Il s’agit d’une bibliothèque JavaScript qui génère des mouvements de souris semblables à ceux d’un humain dans Puppeteer ou tout autre plan 2D.
Le problème est que les événements de souris Puppeteer sont souvent détectés comme synthétiques en raison du comportement non naturel du curseur. Puppeteer Real Browser résout ce problème en améliorant la manière dont les valeurs .screenX et .screenY sont gérées, rendant les mouvements de la souris plus naturels. Cela permet de tromper Cloudflare Turnstile, reCAPTCHA et d’autres CAPTCHA en un clic en leur faisant croire que l’interaction provient d’un utilisateur humain réel.
La bibliothèque comprend également :
- Puppeteer Extra: pour activer l’extension via des plugins
- Xvfb: pour gérer les affichages de navigateurs virtuels, idéal pour les environnements sans affichage.
En bref, Puppeteer Real Browser combine différentes améliorations pour créer un outil d’automatisation furtif et haute fidélité qui imite les utilisateurs humains tout en évitant la détection.
Puppeteer Real Browser vs Puppeteer
Vous trouverez ci-dessous un tableau récapitulatif comparant les deux technologies :
| Puppeteer | Puppeteer Real Browser | |
|---|---|---|
| Étoiles GitHub | 1 000 étoiles | 89,7k étoiles |
| Bibliothèque npm | puppeteer |
puppeteer-real-browser |
| Téléchargements npm | ~3,6 millions de téléchargements hebdomadaires | ~10 000 téléchargements hebdomadaires |
Versionpuppeteer-core |
Puppeteer-core standard |
Rebrowser-puppeteer-core corrigé pour supprimer les traces d’automatisation |
| Détection anti-bot | Facilement détecté par une protection avancée contre les bots | Conçu pour échapper aux systèmes de détection de bots (Cloudflare, Akamai, etc.) |
| API | Par défaut | Même API Puppeteer avec des extensions supplémentaires |
| Prise en charge des proxys | Prend en charge les proxies | Prise en charge des proxies |
| Gestion des CAPTCHA | Pas de résolution de CAPTCHA intégrée | Prise en charge de la résolution de CAPTCHA en un clic (par exemple, Cloudflare Turnstile, reCAPTCHA) |
| Prise en charge des plugins | Pas de prise en charge native des plugins | S’intègre à puppeteer-extra pour la prise en charge des plugins |
| Maintenance et mises à jour | Maintenance active par Google | Abandonné par l’auteur (février 2026), mais peut se poursuivre via la communauté |
Comment utiliser Puppeteer Real Browser pour contourner les CAPTCHA
Pour démontrer les capacités de Puppeteer Real Browser, nous allons le tester sur la page Anti-Bot Challenge de Scraping Course:
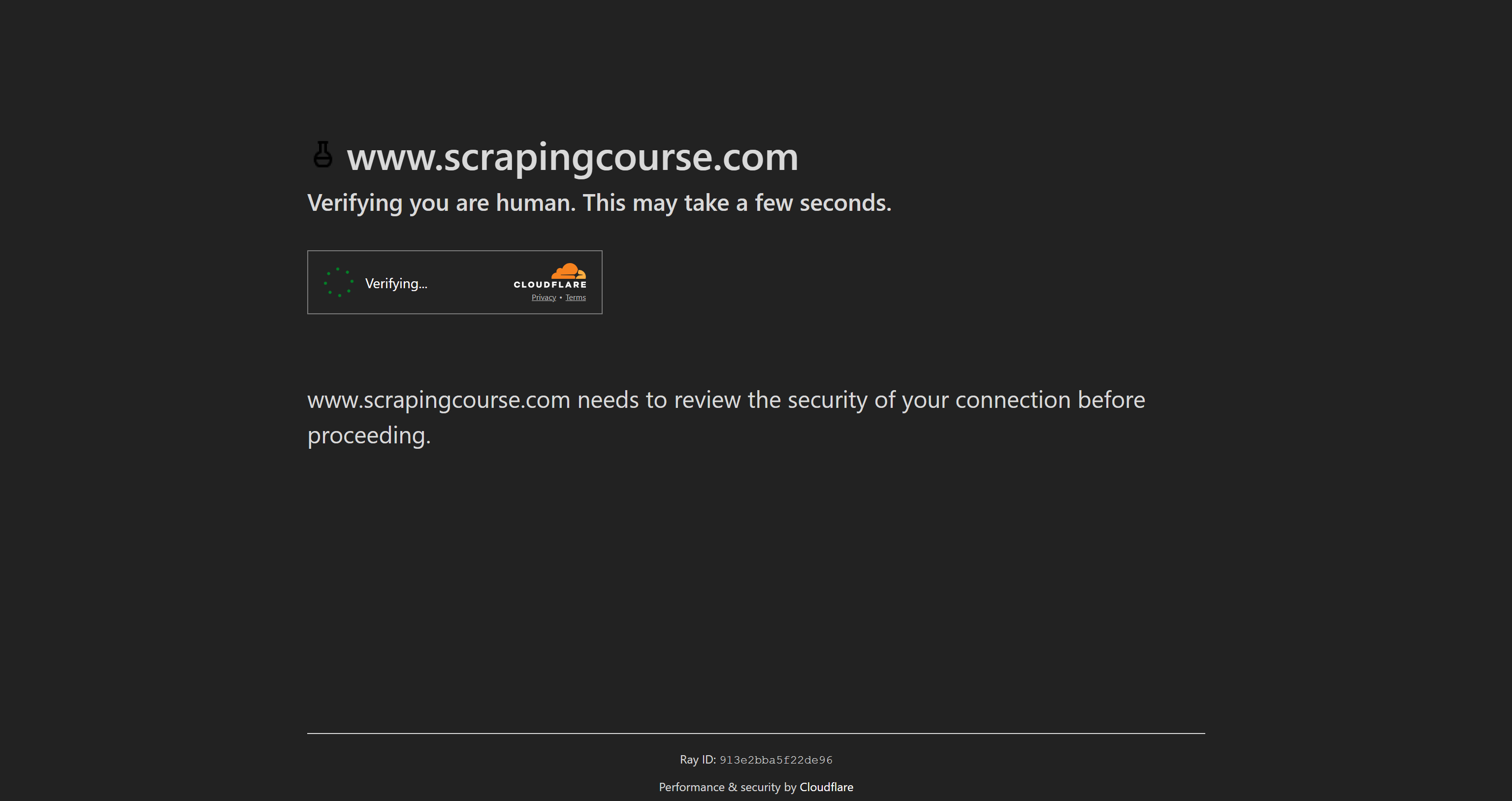
Cette page protégée par Cloudflare comporte un CAPTCHA Turnstile à un clic. Dans cette section étape par étape, nous allons vous montrer comment utiliser Puppeteer Real Browser pour la résolution de CAPTCHA.
Pour une approche alternative, consultez notre guide sur le contournement des CAPTCHA dans Puppeteer. Il est essentiel de savoir qu’un script Puppeteer standard qui tente d’accéder à cette page rencontrera toujours le CAPTCHA Turnstile et sera bloqué.
Comme vous allez le voir, Puppeteer Real Browser est une solution efficace pour contourner Cloudflare et les protections anti-bots similaires !
Étape n° 1 : Installer puppeteer-real-browser
Nous partons du principe que vous avez déjà configuré un projet Node.js. Si ce n’est pas le cas, vous pouvez en créer un à l’aide de npm init.
Maintenant, accédez au dossier de votre projet et installez puppeteer-real-browser avec :
npm install puppeteer-real-browserSous Linux, vous devez également installer xvfb en tant que dépendance au niveau du système. Pour les systèmes basés sur Debian, installez-le à l’aide de la commande suivante :
sudo apt-get install xvfbParfait ! Vous êtes maintenant prêt à utiliser Puppeteer Real Browser pour contourner les CAPTCHA.
Étape n° 2 : configuration initiale
Dans votre script JavaScript, importez connect depuis Puppeteer Real Browser :
const { connect } = require("puppeteer-real-browser");La fonction connect() vous permet d’établir une connexion avec le moteur de navigateur modifié dans une fonction asynchrone :
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// logique de scraping...
await browser.close();
})();Tout comme dans Puppeteer vanilla, vous devez appeler browser.close() pour libérer les ressources.
La fonction connect() dans Puppeteer Real Browser accepte les paramètres suivants :
headless: la valeur par défaut estfalse. D’autres valeurs telles que« new »,trueet« shell »peuvent être utilisées, maisfalseest la plus stable.args: des indicateurs Chromium supplémentaires peuvent être passés sous forme de tableau de chaînes. Voir les indicateurs pris en charge.customConfig: Puppeteer Real Browser est initialisé à l’aide dechrome-launcher. Toutes les options que vous passez ici seront ajoutées en tant qu’arguments d’initialisation directs. Vous pouvez utiliser cette option pour définiruserDataDirou un chemin Chrome personnalisé (chromePath).turnstile: sila valeur est true, Puppeteer Real Browser clique automatiquement sur les CAPTCHA Cloudflare Turnstile.connectOption: options envoyées lors de la connexion à Chromium à l’aide depuppeteer.connect().disableXvfb: sous Linux, lorsqueheadless: false, un affichage virtuel (xvfb) est utilisé pour exécuter le navigateur. Définissez-le surtruepour désactiver cette option et voir la fenêtre réelle du navigateur.ignoreAllFlags: sitrue, tous les arguments d’initialisation par défaut sont remplacés, y compris la page « Let’s get started » qui s’affiche lors du premier chargement.plugins: tableau des plugins Puppeteer Extra. Pour en savoir plus, consultez la documentation officielle.
Toutes les autres options prises en charge par la fonction ci-dessus proviennent de la méthode connect() de Puppeteer.
Comme nous voulons contourner Cloudflare, le paramètre clé dans cet exemple est turnstile sur true.
Étape n° 3 : se connecter à la page cible
Utilisez la fonction goto() de l’API Puppeteer pour naviguer vers la page cible :
await page.goto("https://www.scrapingcourse.com/antibot-challenge");Comme turnstile est défini sur true, Puppeteer Real Browser attendra automatiquement le chargement du CAPTCHA Cloudflare Turnstile et tentera de le résoudre.
Étape n° 4 : attendre la Résolution de CAPTCHA
Si vous ouvrez la page cible en mode navigation privée et effectuez manuellement la résolution de CAPTCHA, vous obtiendrez le résultat suivant :

Inspectez le message à l’aide de DevTools, et vous verrez :
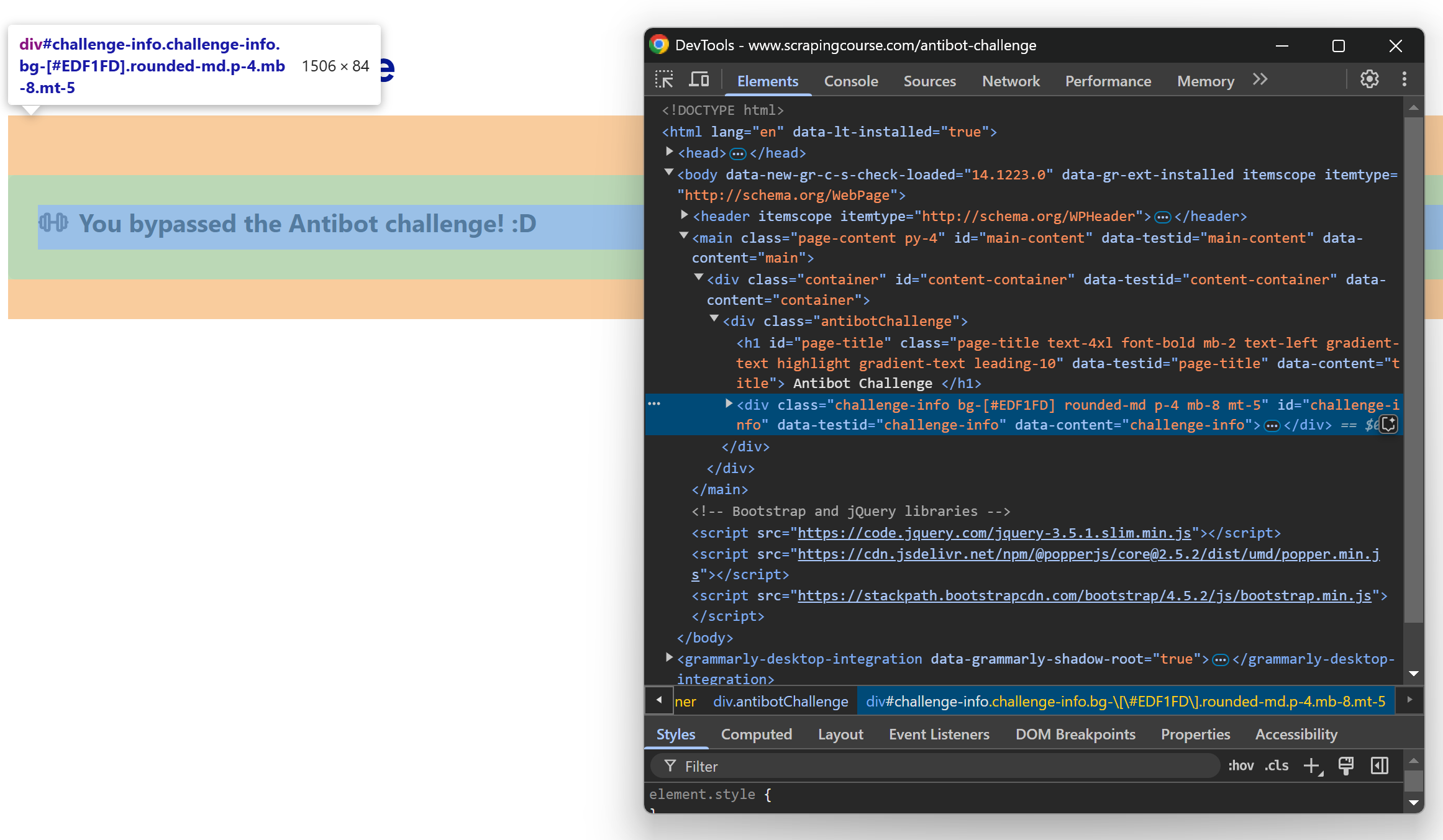
Notez que l’élément du message peut être sélectionné à l’aide du sélecteur CSS #challenge-info.
Maintenant, définissez une fonction personnalisée pour attendre que le DOM de la page change :
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}Cette fonction est nécessaire car puppeteer-real-browser ne fournit pas de rappel intégré pour la résolution du CAPTCHA. Comme nous nous attendons à ce que Puppeteer Real Browser contourne avec succès le CAPTCHA, le DOM de la page sera mis à jour en conséquence, et vous devrez attendre ces changements.
Vous pouvez donc utiliser delay() pour attendre un certain temps afin de permettre à la page de se mettre entièrement à jour, comme ci-dessous :
await delay(10000);Ensuite, attendez que l’élément de message cible apparaisse sur la page :
await page.waitForSelector("#challenge-info", { timeout: 5000 });Enfin, récupérez et affichez son contenu :
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Message de la page : "${challengeInfo}"`);Si tout fonctionne comme prévu, le script devrait afficher :
Message de la page : « Vous avez contourné le défi Antibot ! 😀 »Étape n° 5 : assembler le tout
Voici votre script Puppeteer Real Browser final :
const { connect } = require("puppeteer-real-browser");
// fonction personnalisée pour implémenter une attente stricte
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// connexion au navigateur contrôlé
const { browser, page } = await connect({
headless: false,
turnstile: true, // activer la gestion CAPTCHA Turnstile
connectOption: {
defaultViewport: null, // agrandir la fenêtre d'affichage à la taille de la fenêtre du navigateur
},
args: ["--start-maximized"], // démarrer le navigateur dans une fenêtre maximisée
});
// naviguer vers la page du défi
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // attendre que la page soit entièrement chargée et inactive
});
// attendre jusqu'à 10 secondes que la résolution de CAPTCHA soit terminée
await delay(10000);
// attendre jusqu'à 5 secondes que l'élément d'information sur le défi apparaisse
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// récupérer et imprimer le texte d'information sur le défi
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Message de la page : "${challengeInfo}"`);
// Fermer le navigateur et libérer ses ressources
await browser.close();
})();Lancez le code ci-dessus, et il ouvrira un navigateur qui se comportera comme suit :
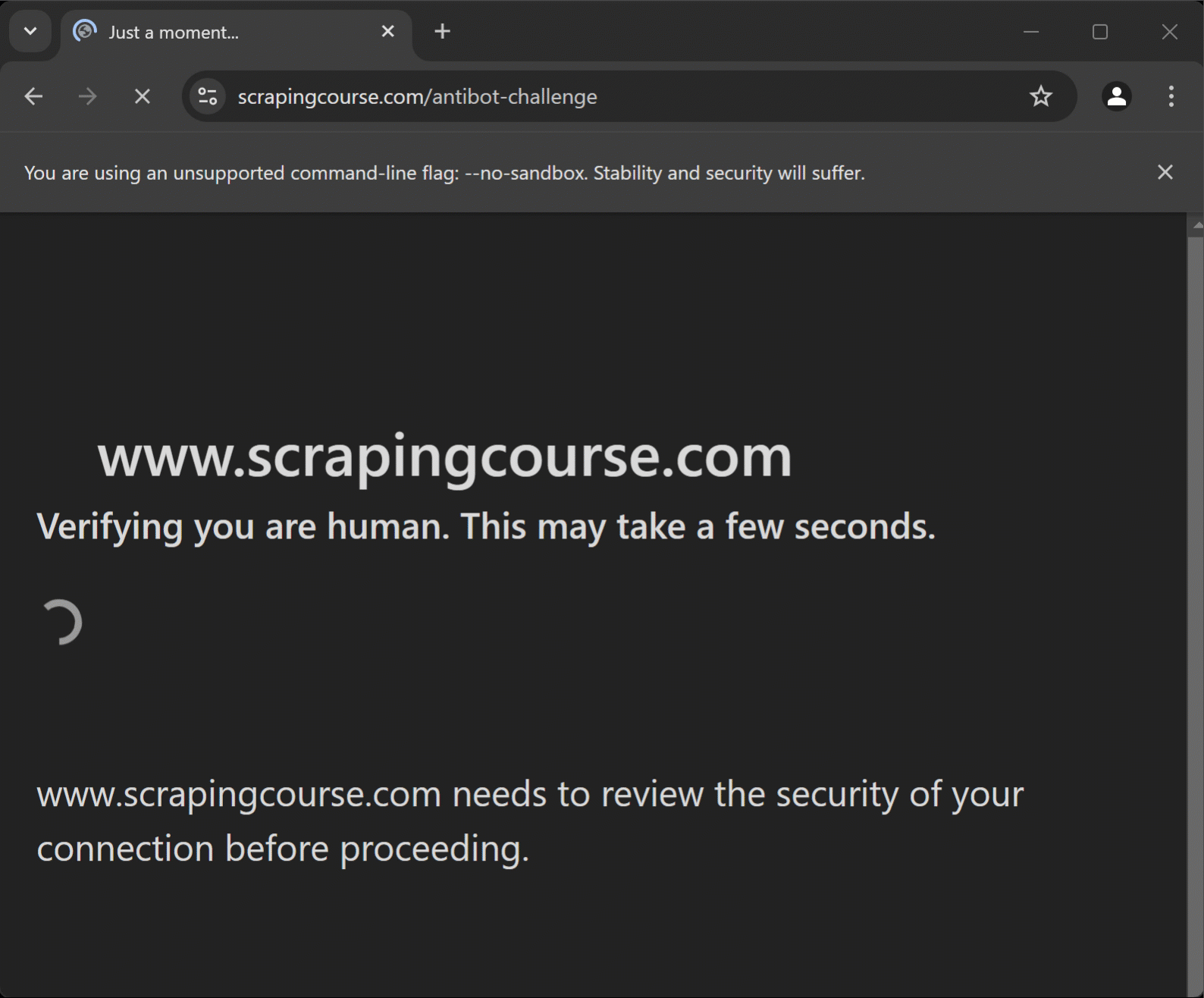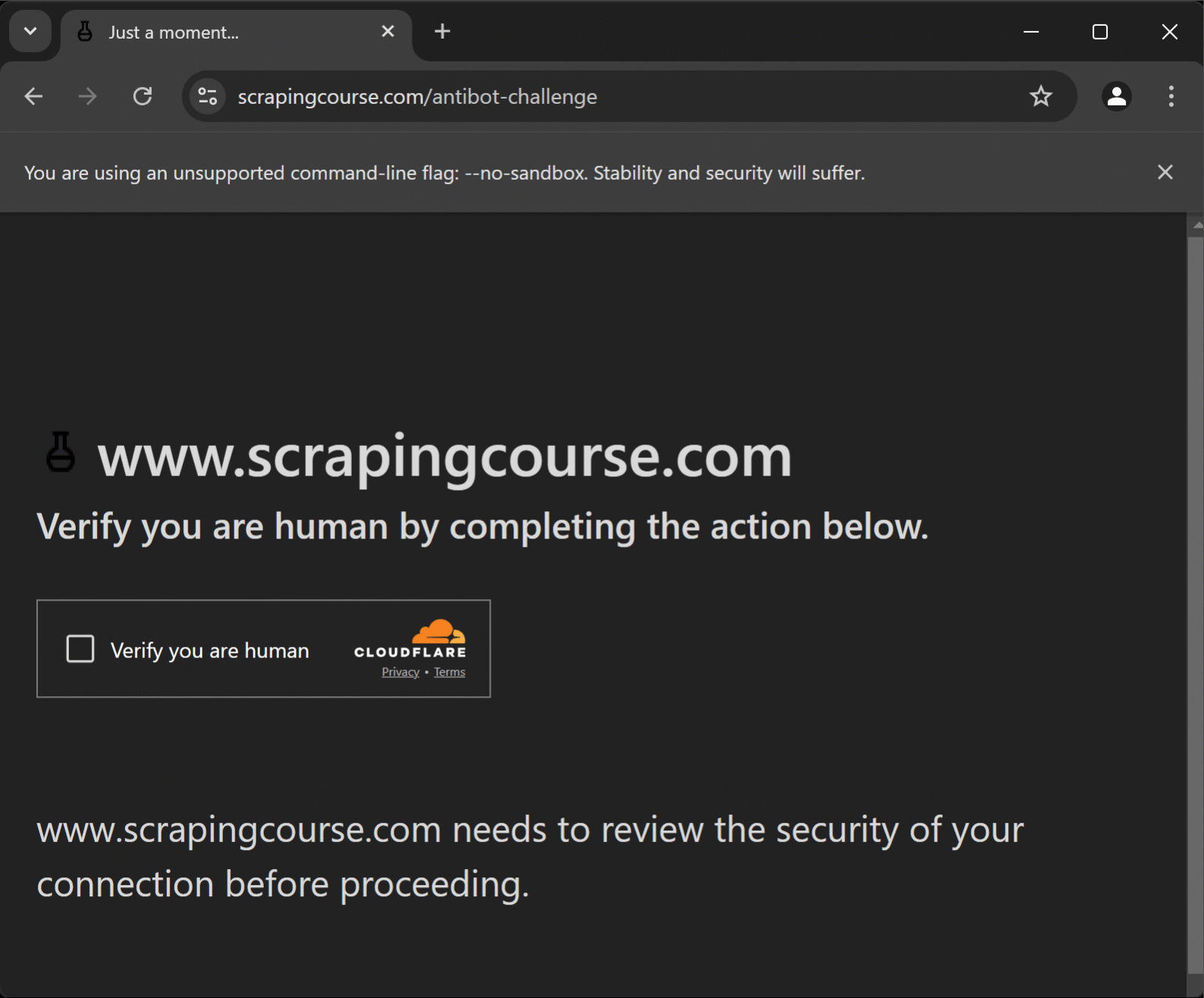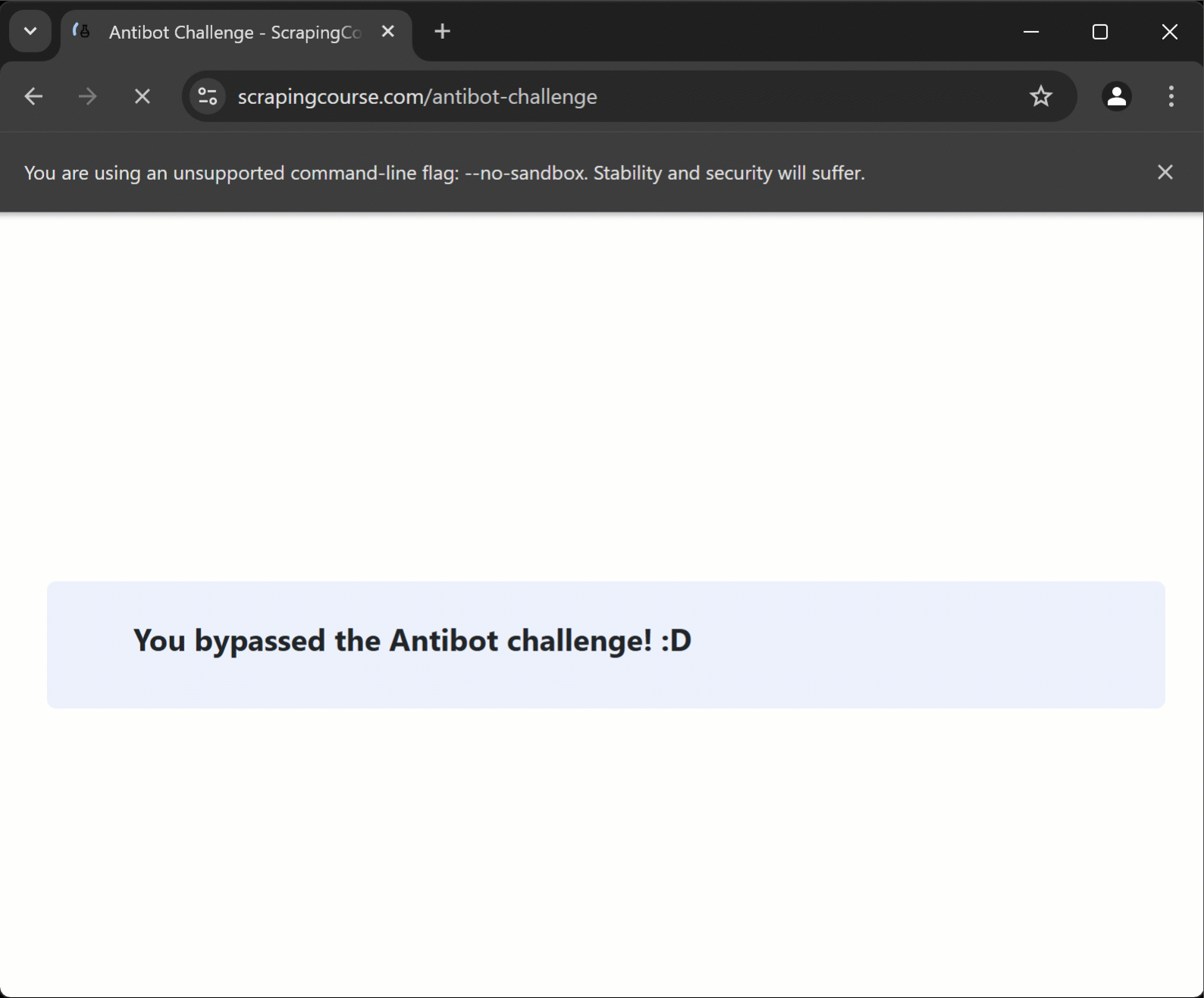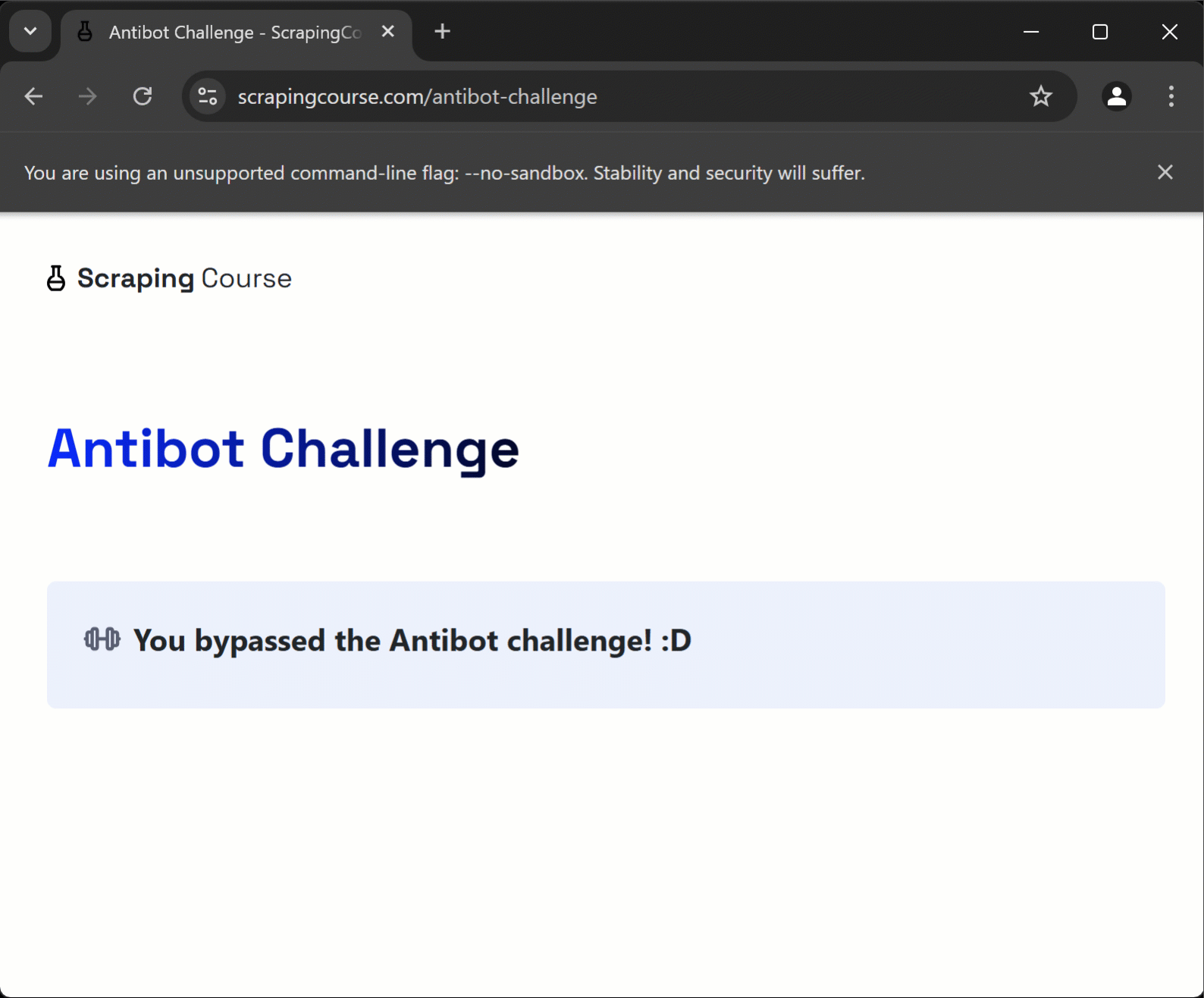
Le script visite une page protégée par Cloudflare, effectue automatiquement la résolution de CAPTCHA, puis atteint la page de destination, d’où il extrait les données.
Comme prévu, le script produira ce résultat dans le terminal :
Message de la page : « Vous avez contourné le défi Antibot ! 😀 »Fantastique ! La résolution du CAPTCHA Cloudflare a été effectuée automatiquement.
Alternatives à puppeteer-real-browser
Comme puppeteer-real-browser n’est plus maintenu, il vaut la peine d’explorer des alternatives qui offrent des fonctionnalités similaires, telles que :
- Puppeteer Stealth: un plugin pour Puppeteer Extra qui applique diverses techniques d’évasion pour rendre l’automatisation moins détectable. Il modifie les empreintes digitales du navigateur, désactive les fuites WebRTC et imite le comportement humain pour contourner les mesures anti-bot.
- Playwright Stealth: un plugin Playwright Extra qui intègre les mêmes techniques de furtivité que Puppeteer Stealth. Il corrige les API du navigateur pour empêcher les fuites d’empreintes digitales.
- SeleniumBase: un framework d’automatisation complet basé sur Selenium avec des fonctionnalités anti-bot intégrées. Il comprend des techniques d’évasion des bots, l’usurpation d’agent utilisateur, la gestion des CAPTCHA et d’autres outils pour aider les scripts Selenium à contourner la protection anti-bot.
- undetected-chromedriver: une version modifiée de ChromeDriver qui aide les scripts Selenium à contourner la détection des bots. Il supprime les indicateurs d’automatisation, obscurcit les propriétés WebDriver et garantit que le navigateur se comporte davantage comme une session opérée par un humain.
Limitations de Puppeteer Real Browser
Puppeteer Real Browser est un puissant outil d’automatisation de navigateur anti-bot, mais il présente quelques inconvénients. L’auteur est transparent sur ces contraintes et fournit des informations claires sur ses limites.
Les principales limitations sont les suivantes :
- Plus de maintenance: en février 2026, l’auteur original a annoncé que la bibliothèque ne ferait plus l’objet de mises à jour. Les améliorations futures dépendront des contributions de la communauté plutôt que d’un développement actif.
- Pas indétectable à 100 %: bien qu’il réduise la détection des bots, les systèmes anti-bots avancés peuvent toujours signaler le trafic automatisé.
- Nécessite une configuration supplémentaire: les utilisateurs peuvent avoir besoin d’ajuster les Proxy, les en-têtes et d’autres paramètres pour une furtivité et une fonctionnalité optimales.
- Impossible d’accéder aux fonctions dans l’objet fenêtre: cela se produit parce que le runtime du navigateur est fermé par Rebrowser. Une solution consiste à injecter du JavaScript dans la page à l’aide de puppeteer-intercept-and-modify-requests ou à utiliser des plugins Chrome.
- Dépendant de bibliothèques externes: la bibliothèque s’appuie sur des projets tiers tels que Rebrowser, Puppeteer Extra et ghost-cursor, qui pourraient être modifiés ou abandonnés.
- Problèmes avec reCAPTCHA: reCAPTCHA v3 nécessite qu’une session Google active soit transmise. Même avec un navigateur indétectable, les tentatives d’automatisation sans session valide sont susceptibles d’être signalées.
Automatisation transparente du navigateur anti-bot
Les inconvénients mentionnés ci-dessus pourraient vous dissuader d’envisager Puppeteer Real Browser. Vous pourriez essayer l’une de ses alternatives, mais vous risquez de rencontrer des difficultés similaires.
Ce qui importe, c’est que la plupart des bibliothèques d’automatisation de navigateur anti-bot se concentrent sur le patchage des navigateurs, et non sur la bibliothèque d’automatisation de navigateur elle-même. Bien que des modifications mineures du cœur de ces bibliothèques puissent être nécessaires, la plupart des efforts sont consacrés au patchage des moteurs de navigateur afin d’éviter les fuites de détection.
Imaginez maintenant pouvoir utiliser des bibliothèques d’automatisation de navigateur classiques telles que Playwright, Puppeteer et Selenium, en vous appuyant sur leurs mises à jour et leurs API stables, pour contrôler un navigateur cloud évolutif spécialement conçu pour le Scraping web. C’est exactement l’expérience offerte par le Navigateur de scraping de Bright Data!
Le Navigateur de scraping est doté d’une fonctionnalité intégrée de déblocage de sites web qui gère automatiquement le blocage pour vous. Il s’intègre de manière transparente à un réseau Proxy de 400M+ monthly adresses IP, fonctionne efficacement dans le cloud et comprend un solveur CAPTCHA intégré.
Les navigateurs de scraping optimisés sont la véritable solution pour parvenir à une automatisation anti-bot des navigateurs !
Conclusion
Dans cet article, vous avez compris comment gérer la détection des bots dans Puppeteer à l’aide de Puppeteer Real Browser. Cette bibliothèque fournit une version corrigée de puppeteer-core pour le Scraping web sans être bloqué.
Le problème est que puppeteer-real-browser n’est plus maintenu. Ainsi, même s’il fonctionne aujourd’hui, il pourrait ne plus fonctionner demain, car les solutions anti-bot ne cessent d’évoluer.
Le problème ne réside pas dans l’API de Puppeteer pour contrôler le navigateur, mais dans les navigateurs eux-mêmes. La solution est un navigateur cloud, toujours à jour et évolutif, avec une fonctionnalité anti-bot intégrée, tel que le Navigateur de scraping!
Le Navigateur de scraping de Bright Data est un navigateur cloud hautement évolutif qui fonctionne avec Puppeteer, Selenium, Playwright et d’autres. Il gère pour vous l’empreinte digitale du navigateur, la résolution CAPTCHA et les nouvelles tentatives automatisées.
De plus, il fait automatiquement tourner l’adresse IP de sortie à chaque requête, grâce à un réseau proxy mondial qui comprend :
- Proxy de centre de données – Plus de 770 000 adresses IP de centres de données.
- Proxys résidentiels – Plus de 150 millions d’IPs résidentielles dans plus de 195 pays.
- Proxy ISP – Plus de 700 000 adresses IP FAI.
- Proxy mobile – Plus de 7 millions d’adresses IP mobiles.
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer notre Navigateur de scraping ou tester nos Proxy.





