

Lorsque vous effectuez du Scraping web, l’analyse HTML est essentielle, quels que soient les outils que vous utilisez.Le Scraping web avec Java ne fait pas exception à cette règle. En Python, nous utilisons des outils tels queRequestsetBeautifulSoup. Avec Java, nous pouvons envoyer nos requêtes HTTP et analyser notre HTML à l’aide dejsoup. Nous utiliseronsBooks to Scrapepour ce tutoriel.
Pour commencer
Dans ce tutoriel, nous allons utiliser Maven pour la gestion des dépendances. Si vous ne l’avez pas déjà, vous pouvez installer Mavenici.
Une fois Maven installé, vous devez créer un nouveau projet Java. La commande ci-dessous crée un nouveau projet, jsoup-scraper.
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Ensuite, vous devrez ajouter les dépendances pertinentes. Remplacez le code danspom.xmlpar le code ci-dessous. Cela ressemble à la gestion des dépendances dansRustavec Cargo.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<ARTIFACTID>jsoup-scraper</ARTIFACTID>
<PACKAGING>jar</PACKAGING>
<VERSION>1.0-SNAPSHOT</VERSION>
<NAME>jsoup-scraper</NAME>
<URL>http://maven.apache.org</URL>
<DEPENDENCIES>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
</project>
Collez le code suivant dans App.java. Il n’y a pas grand-chose, mais c’est le Scraper de base à partir duquel nous allons travailler.
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//se connecter à un site web et récupérer son code HTML
Document doc = Jsoup.connect(url).get();
//imprimer le titre
System.out.println("Titre de la page : " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Nombre total de pages récupérées : "+(pageCount-1));
}
}
Jsoup.connect("https://books.toscrape.com").get(): cette ligne récupère la page et renvoie un objetDocumentque nous pouvons manipuler.doc.title()renvoie le titre dans le document HTML, dans ce cas :Tous les produits | Livres à extraire - Sandbox.
Utilisation des méthodes DOM avec Jsoup
jsoup contient diverses méthodes permettant de rechercher des éléments dans le DOM (Document Object Model). Nous pouvons utiliser l’une des méthodes suivantes pour rechercher facilement des éléments de page.
getElementById(): recherche un élément à l’aide de sonidentifiant.getElementsByClass(): recherche tous les éléments à l’aide de leur classe CSS.getElementsByTag(): recherche tous les éléments à l’aide de leur balise HTML.getElementsByAttribute(): recherche tous les éléments contenant un certain attribut.
getElementById
Sur notre site cible, la barre latérale contient une balise div avec un identifiant promotions_left. Vous pouvez le voir dans l’image ci-dessous.
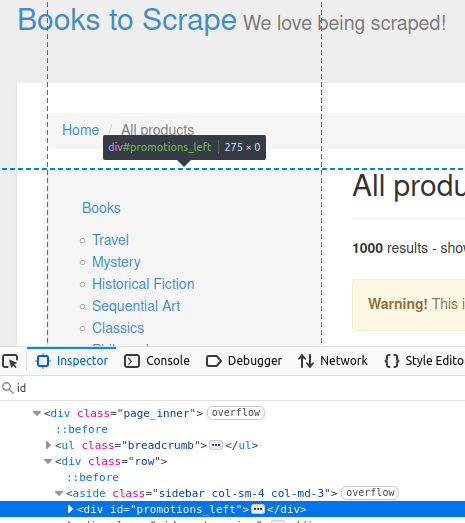
//obtenir par Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
Ce code affiche l’élément HTML que vous voyez dans la page d’inspection.
Sidebar: <div id="promotions_left">
</div>
getElementsByTag
getElementsByTag() nous permet de trouver tous les éléments de la page avec une certaine balise. Regardons les livres sur cette page.
Chaque livre est contenu dans une balise article unique.
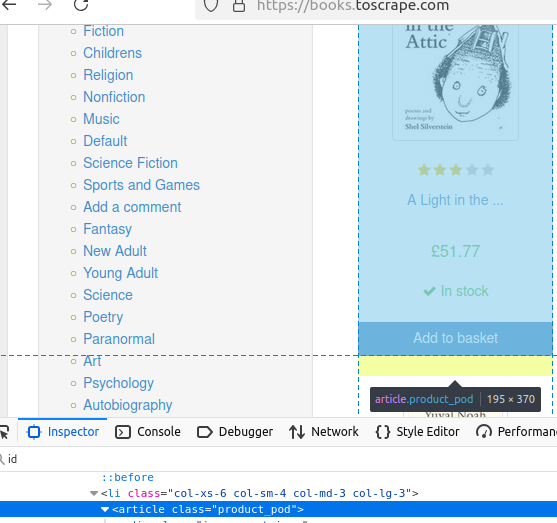
Le code ci-dessous n’affichera rien, mais renverra un tableau de livres. Ces livres serviront de base pour le reste de nos données.
//obtenir par balise
Elements books = doc.getElementsByTag("article");
getElementsByClass
Examinons le prix d’un livre. Comme vous pouvez le voir en surbrillance, sa classe est price_color.
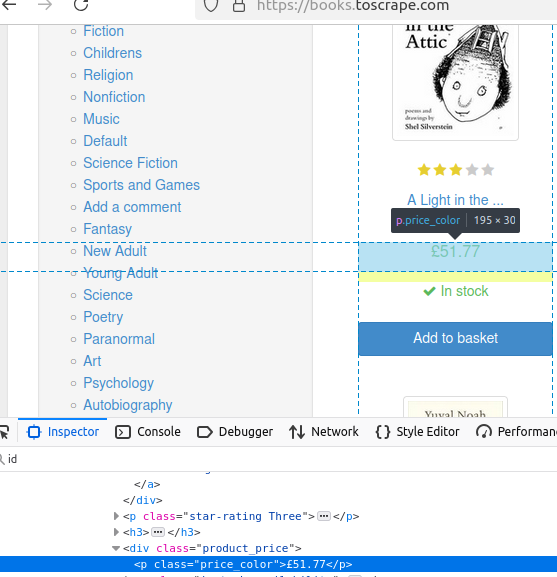
Dans cet extrait, nous trouvons tous les éléments de la classe price_color. Nous affichons ensuite le texte du premier élément à l’aide de .first().text().
System.out.println("Prix : " + book.getElementsByClass("price_color").first().text());
getElementsByAttribute
Comme vous le savez peut-être déjà, tous les éléments a nécessitent un attribut href. Dans le code ci-dessous, nous utilisons getElementsByAttribute("href") pour trouver tous les éléments avec un href. Nous utilisons .first().attr("href") pour renvoyer son href.
//obtenir par attribut
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Lien : https://books.toscrape.com/" + hrefs.first().attr("href"));
Techniques avancées
Sélecteurs CSS
Lorsque nous voulons utiliser plusieurs critères pour trouver des éléments, nous pouvons passer des sélecteurs CSSdans la méthodeselect(). Cette méthode renvoie un tableau de tous les objets correspondant au sélecteur. Ci-dessous, nous utilisonsli[class='next']pour trouver tous les élémentsliavec la classenext.
Éléments nextPage = doc.select("li[class='next']");
Gestion de la pagination
Pour gérer notre pagination, nous utilisons nextPage.first() pour appeler getElementsByAttribute("href").attr("href") sur le premier élément renvoyé par le tableau et extraire son href. Il est intéressant de noter qu’après la page 2, le mot catalogue est supprimé des liens. S’il n’est pas présent dans le href, nous le rajoutons. Nous combinons ensuite ce lien avec notre URL de base et l’utilisons pour obtenir le lien vers la page suivante.
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
Tout assembler
Voici notre code final. Si vous souhaitez extraire plusieurs pages, remplacez simplement le 1 dans while (pageCount <= 1) par la valeur souhaitée. Si vous souhaitez extraire 4 pages, utilisez while (pageCount <= 4).
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//connect to a website and get its HTML
Document doc = Jsoup.connect(url).get();
//print the title
System.out.println("Page Title: " + doc.title());
//get by Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Barre latérale : " + sidebar);
//obtenir par balise
Elements books = doc.getElementsByTag("article");
for (Element book : books) {
System.out.println("------Livre------");
System.out.println("Titre : " + book.getElementsByTag("img").first().attr("alt"));
System.out.println("Prix : " + book.getElementsByClass("price_color").first().text());
System.out.println("Disponibilité : " + book.getElementsByClass("instock availability").first().text());
//obtenir par attribut
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Lien : https://books.toscrape.com/" + hrefs.first().attr("href"));
}
//trouver le bouton suivant à l'aide de son sélecteur CSS
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total pages scraped: "+(pageCount-1));
}
}
Avant d’exécuter le code, n’oubliez pas de le compiler.
mvn package
Exécutez-le ensuite à l’aide de la commande suivante.
mvn exec:java -Dexec.mainClass="com.example.App"
Voici le résultat de la première page.
---------------------PAGE 1--------------------------
Titre de la page : Tous les produits | Livres à scraper - Sandbox
Barre latérale : <div id="promotions_left">
</div>
------Livre------
Titre : A Light in the Attic
Prix : 51,77 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------Livre------
Titre : Tipping the Velvet
Prix : 53,74 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------Livre------
Titre : Soumission
Prix : 50,10 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/soumission_998/index.html
------Livre------
Titre : Sharp Objects
Prix : 47,82 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------Livre------
Titre : Sapiens : Une brève histoire de l'humanité
Prix : 54,23 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------Livre------
Titre : The Requiem Red
Prix : 22,65 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------Livre------
Titre : The Dirty Little Secrets of Getting Your Dream Job
Prix : 33,34 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------Livre------
Titre : The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
Prix : 17,93 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------Livre------
Titre : The Boys in the Boat : Neuf Américains et leur quête épique de l'or aux Jeux olympiques de Berlin en 1936
Prix : 22,60 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------Livre------
Titre : The Black Maria
Prix : 52,15 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------Livre------
Titre : Starving Hearts (Triangular Trade Trilogy, n° 1)
Prix : 13,99 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------Livre------
Titre : Shakespeare's Sonnets
Prix : 20,66 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------Livre------
Titre : Set Me Free (Libère-moi)
Prix : 17,46 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/set-me-free_988/index.html
------Livre------
Titre : Scott Pilgrim's Precious Little Life (La précieuse petite vie de Scott Pilgrim) (Scott Pilgrim #1)
Prix : 52,29 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------Livre------
Titre : Rip it Up and Start Again
Prix : 35,02 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------Livre------
Titre : Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Prix : 57,25 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------Livre------
Titre : Olio
Prix : 23,88 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/olio_984/index.html
------Livre------
Titre : Mesaerion : The Best Science Fiction Stories 1800-1849
Prix : 37,59 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------Livre------
Titre : Libertarianism for Beginners (Le libertarianisme pour les débutants)
Prix : 51,33 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------Livre------
Titre : Ce n'est que l'Himalaya
Prix : 45,17 £
Disponibilité : En stock
Lien : https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
Nombre total de pages récupérées : 1
Conclusion
Maintenant que vous avez appris à extraire des données HTML à l’aide de jsoup, vous pouvez commencer à créer des Scrapers web plus avancés. Que vous scrapiez des listes de produits, des articles d’actualité ou des données de recherche, la gestion du contenu dynamique et la prévention des blocages constituent des défis majeurs.
Pour optimiser efficacement vos efforts de scraping, pensez à utiliser les outils de Bright Data :
- Proxys résidentiels – Évitez les interdictions d’IP et accédez à des contenus géo-restreints.
- Navigateur de scraping – Affichez sans effort les sites riches en JavaScript.
- Jeux de données prêts à l’emploi: évitez complètement le scraping et obtenez instantanément des données structurées.
En combinant jsoup avec l’infrastructure appropriée, vous pouvez extraire des données à grande échelle tout en minimisant les risques de détection. Prêt à passer au niveau supérieur en matière de Scraping web ? Inscrivez-vous dès maintenant et commencez votre essai gratuit.





