

Dans ce guide, vous apprendrez :
- Qu’est-ce qu’un Scraper ZoomInfo et comment fonctionne-t-il ?
- Les types de données que vous pouvez extraire automatiquement de ZoomInfo
- Comment créer un script de scraping ZoomInfo à l’aide de Python
- Quand et pourquoi une solution plus avancée peut être nécessaire
C’est parti !
Qu’est-ce qu’un Scraper ZoomInfo ?
Un scraper ZoomInfo est un outil permettant d’extraire des données de ZoomInfo, une plateforme de premier plan qui fournit des informations détaillées sur les entreprises et les professionnels. Cette solution automatise le processus de scraping, vous permettant ainsi de collecter un grand nombre de données. Le scraper s’appuie sur des techniques telles que l’automatisation du navigateur pour naviguer sur le site et récupérer du contenu.
Données que vous pouvez récupérer à partir de ZoomInfo
Voici quelques-unes des données les plus importantes que vous pouvez extraire de ZoomInfo :
- Informations sur les entreprises : noms, secteurs d’activité, chiffre d’affaires, siège social et nombre d’employés.
- Informations sur les employés : noms, fonctions, adresses e-mail et numéros de téléphone.
- Informations sur le secteur d’activité : concurrents, tendances du marché et hiérarchies des entreprises.
Récupération de données sur ZoomInfo avec Python : guide étape par étape
Dans cette section, vous apprendrez à créer un Scraper ZoomInfo.
L’objectif est de vous guider dans la création d’un script Python qui collecte automatiquement les données de lapage entreprise NVIDIA ZoomInfo.
Suivez les étapes ci-dessous !
Étape n° 1 : configuration du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre ordinateur. Sinon, téléchargez-le et installez-le en suivant l’assistant.
À présent, utilisez la commande suivante pour créer un dossier pour votre projet :
mkdir zoominfo-scraper
Le répertoire zoominfo-scraper représente le dossier de projet de votre scraper Python ZoomInfo.
Entrez-y et initialisez un environnement virtuel à l’intérieur :
cd zoominfo-Scraper
python -m venv env
Chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition feront l’affaire.
Créez un fichier scraper.py dans le dossier du projet, qui doit contenir la structure de fichiers ci-dessous :

Pour l’instant, scraper.py est un script Python vide. Il contiendra bientôt la logique de scraping souhaitée.
Dans le terminal de l’IDE, activez l’environnement virtuel. Sous Linux ou macOS, exécutez cette commande :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Parfait, vous disposez désormais d’un environnement Python pour le Scraping web !
Étape n° 2 : sélectionnez la bibliothèque de scraping
Avant de vous lancer dans le codage, vous devez comprendre quels outils sont les mieux adaptés pour atteindre votre objectif. Pour ce faire, vous devez d’abord effectuer un test préliminaire afin d’étudier le site cible. Voici comment procéder :
- Ouvrez la page cible en mode navigation privée dans votre navigateur. Cela empêche les cookies et les préférences préenregistrés d’influencer votre analyse.
- Cliquez avec le bouton droit n’importe où sur la page et sélectionnez « Inspecter » pour ouvrir les outils de développement du navigateur.
- Accédez à l’onglet « Réseau ».
- Rechargez la page et examinez l’activité dans l’onglet « Fetch/XHR ».
Cela vous donnera un aperçu du comportement de la page web au moment du rendu :
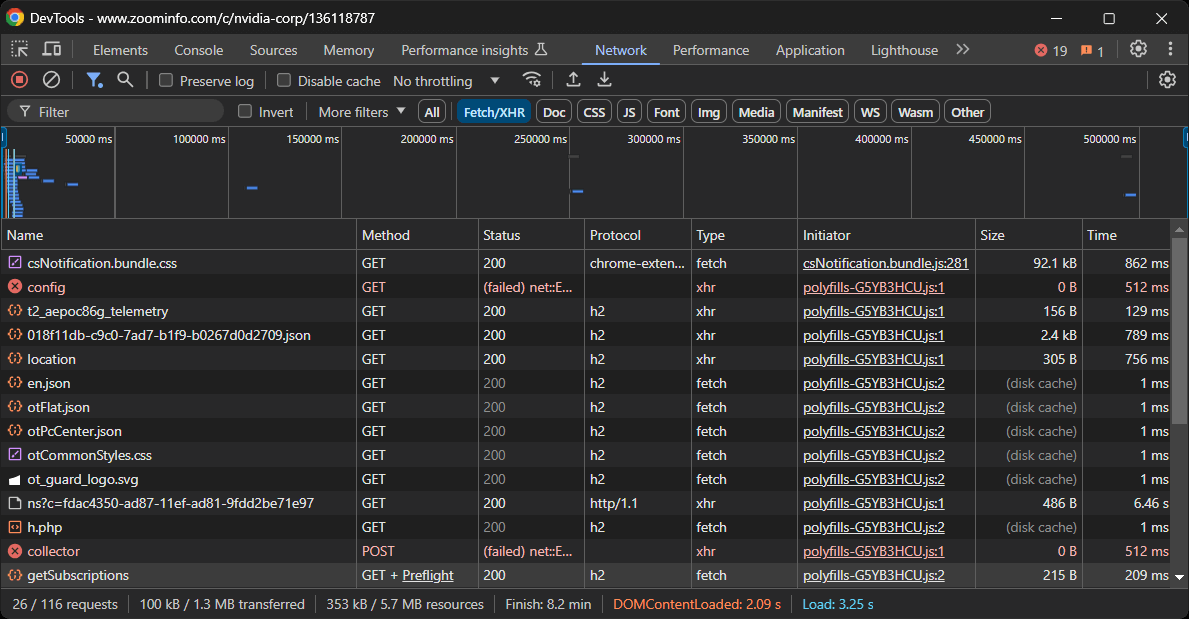
Dans cette section, vous pouvez voir toutes les requêtes AJAX dynamiques effectuées par la page. Inspectez chaque requête et vous remarquerez qu’aucune d’entre elles ne contient de données pertinentes. Cela indique que la plupart des informations de la page sont déjà intégrées dans le document HTML renvoyé par le serveur.
Les résultats vous amèneront naturellement à adopter un client HTTP et un analyseur HTML pour extraire les données de ZoomInfo. Cependant, le site utilise des technologies anti-bot strictes qui peuvent bloquer la plupart des requêtes automatisées ne provenant pas d’un navigateur. Le moyen le plus simple de contourner cela est d’utiliser un outil d’automatisation de navigateur comme Selenium!
Selenium vous permet de contrôler un navigateur web par programmation, en lui demandant d’effectuer des actions spécifiques sur des pages web comme le feraient de vrais utilisateurs. Il est temps de l’installer et de commencer à l’utiliser !
Étape n° 3 : installer et configurer Selenium
En Python, Selenium est disponible via le paquet pip selenium. Dans un environnement virtuel Python activé, installez-le à l’aide de cette commande :
pip install -U selenium
Pour savoir comment utiliser cet outil, suivez notre tutoriel sur le Scraping web avec Selenium.
Importez Selenium dans scraper.py et initialisez un objet WebDriver pour contrôler une instance Chrome :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# créer une instance de pilote Web Chrome
driver = webdriver.Chrome(service=Service())
Le code ci-dessus crée une instance WebDriver pour fonctionner sur Chrome. Notez que ZoomInfo utilise une technologie anti-scraping qui bloque les navigateurs sans interface graphique. Vous ne pouvez donc pas définir le drapeau --headless. Comme solution alternative, envisagez d’explorer Playwright Stealth.
Dans la dernière ligne de votre Scraper, n’oubliez pas de fermer le pilote Web :
driver.quit()
Super ! Vous êtes maintenant prêt à commencer à scraper ZoomInfo.
Étape n° 4 : se connecter à la page cible
Utilisez la méthode get() d’un objet Selenium WebDriver pour demander au navigateur de visiter la page souhaitée :
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
Votre fichier scraper.py devrait maintenant contenir ces lignes de code :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# créer une instance de Chrome Web Driver
driver = webdriver.Chrome(service=Service())
# se connecter à la page cible
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# logique de scraping...
# fermer le navigateur
driver.quit()
Placez un point d’arrêt de débogage sur la dernière ligne et exécutez le script. Vous devriez être redirigé vers la page de la société NVIDIA.
Le message « Chrome est contrôlé par un logiciel de test automatisé » certifie que Selenium contrôle Chrome comme prévu. Bravo !
Étape n° 5 : extraire les informations générales sur l’entreprise
Vous devez analyser la structure DOM de la page pour comprendre comment extraire les données requises. L’objectif est d’identifier les éléments HTML contenant les données souhaitées. Commencez par inspecter les éléments dans la partie supérieure de la section des informations sur l’entreprise :
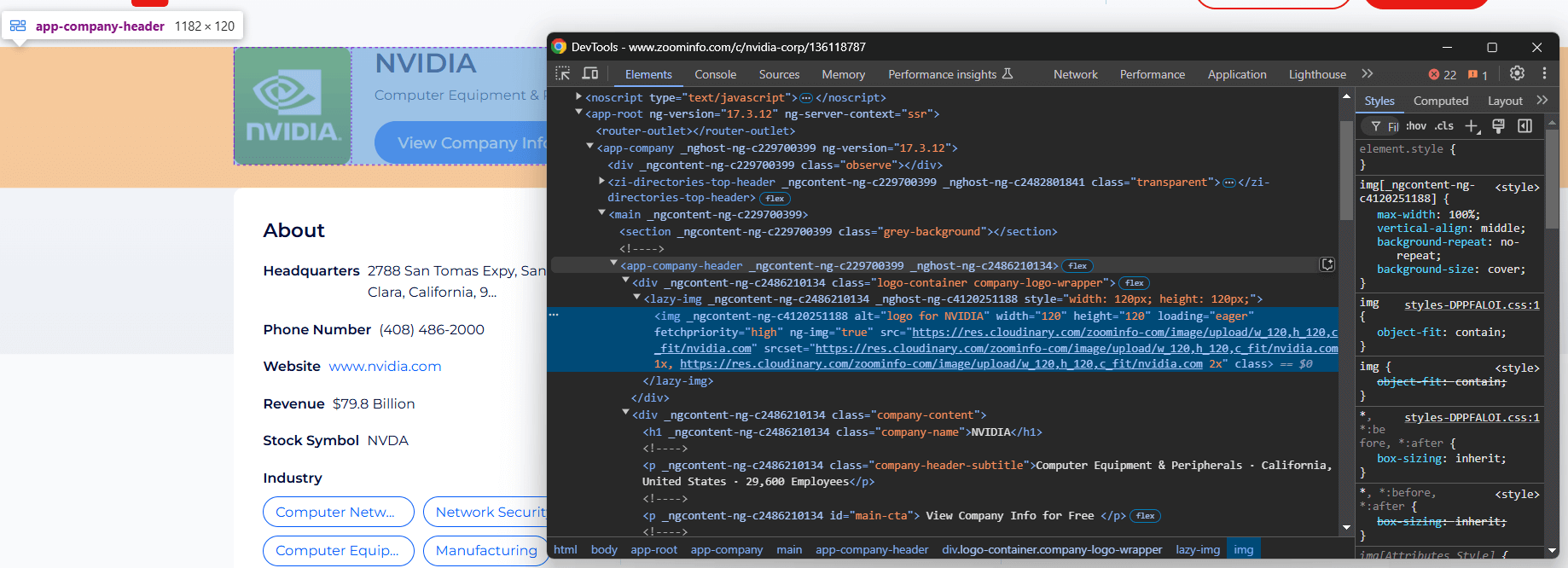
L’élément <app-company-header> contient :
- L’image de l’entreprise dans une balise
<img>à l’intérieur d’une balise<div>avec la classecompany-logo-wrapper. - Le nom de l’entreprise dans un nœud avec la classe
company-name. - Le sous-titre de l’entreprise stocké dans un nœud avec la classe
company-header-subtitle.
Utilisez Selenium pour localiser ces éléments et collecter les données qu’ils contiennent :
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
Pour que le code fonctionne, n’oubliez pas d’importer By:
from selenium.webdriver.common.by import By
Notez que la méthode find_element() sélectionne un nœud à l’aide de la stratégie de sélection de nœuds spécifiée. Ci-dessus, nous avons utilisé des sélecteurs CSS. Apprenez-en davantage sur la différence entre les sélecteurs XPath et CSS.
Vous pouvez ensuite accéder au contenu du nœud à l’aide de l’attribut text. Pour accéder à un attribut, utilisez la méthode get_attribute().
Imprimez les données récupérées :
print(logo_url)
print(name)
print(subtitle)
Voici ce que vous obtiendrez :
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
Matériel informatique et périphériques · Californie, États-Unis · 29 600 employés
Waouh ! Le scraper ZoomInfo fonctionne à merveille.
Étape n° 6 : extraire les informations « À propos
Concentrez-vous sur la section « À propos » de la page de l’entreprise :
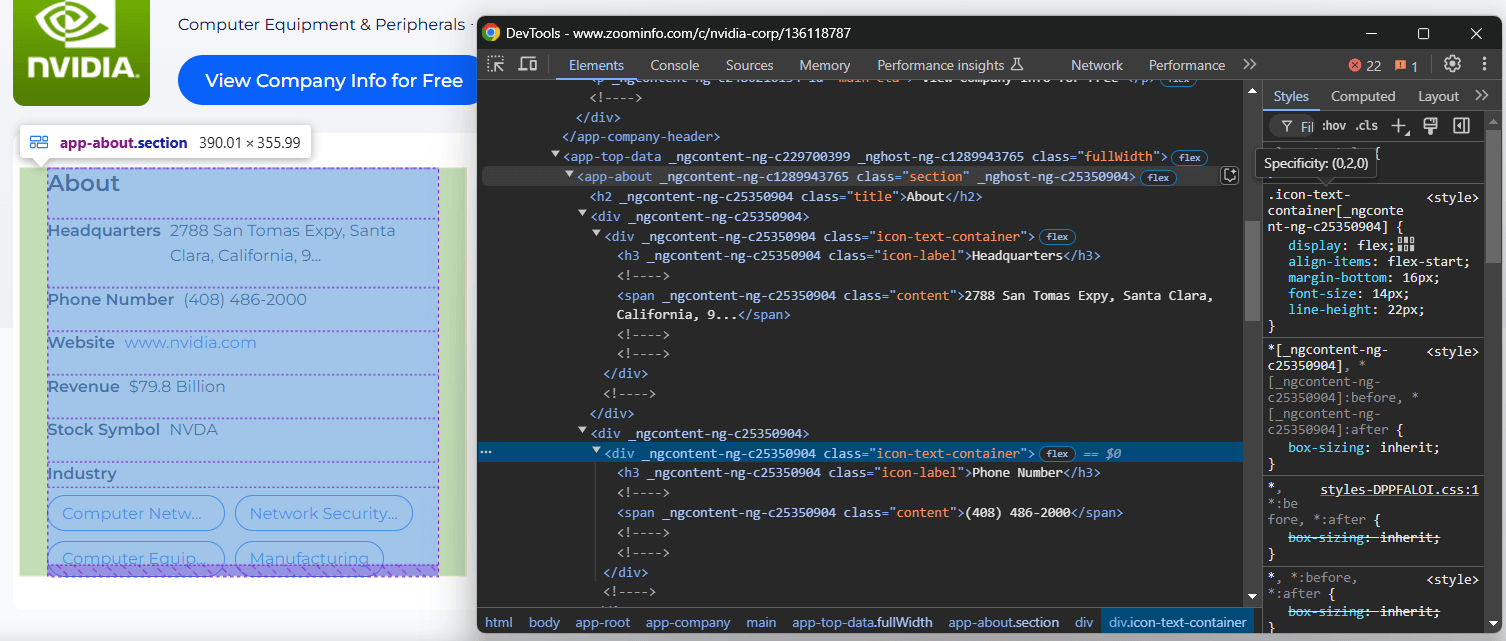
Le nœud <app-about> contient des éléments avec des classes génériques et des attributs apparemment générés de manière aléatoire. Comme ces attributs peuvent changer à chaque compilation, évite de t’y fier pour cibler les éléments à scraper.
Pour extraire les informations de cette section, commencez par sélectionner le nœud <app-about>:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
Concentrez-vous maintenant sur tous les éléments .icon-text-container à l’intérieur de <app-about>. Inspectez ensuite leurs étiquettes (.icon-label) pour identifier les éléments spécifiques qui vous intéressent. Si l’étiquette correspond, extrayez les données de l’élément .content. Encapsulez cette logique dans une fonction :
def scrape_about_node(text_container_elements, text_label):
# itérez à travers eux pour extraire les données des
# nœuds spécifiques qui vous intéressent
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# sélectionnez l'élément de contenu et extrayez-en les données
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
Vous pouvez ensuite extraire les informations « À propos » avec :
siège social = scrape_about_node(text_container_elements, « Siège social »)
numéro_de_téléphone = scrape_about_node(text_container_elements, « Numéro de téléphone »)
chiffre d'affaires = scrape_about_node(text_container_elements, « Chiffre d'affaires »)
symbole_boursière = scrape_about_node(text_container_elements, « Symbole boursier »)
Ensuite, ciblez les balises relatives au secteur d’activité et à l’entreprise.
Sélectionnez le secteur d’activité de l’entreprise avec h3 .incon-label et les balises avec zi-directories-chips a. Récupérez les données à partir de celles-ci avec :
industry_element = about_element.find_element(By.CSS_SELECTOR, « h3.icon-label »)
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, « zi-directories-chips a »)
tags = [tag_element.text for tag_element in tag_elements]
Incroyable ! La logique d’extraction des données ZoomInfo est terminée.
Étape n° 7 : collecter les données extraites
Vous disposez actuellement des données extraites réparties dans plusieurs variables. Remplissez un nouvel objet entreprise avec ces données :
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
« phone_number » : phone_number,
« revenue » : revenue,
« stock_symbol » : stock_symbol,
« industry » : industry,
« tags » : tags
}
Imprimez les données récupérées pour vous assurer qu’elles contiennent les informations souhaitées
print(items)
Cela produira le résultat suivant :
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Matériel informatique et périphériques · Californie, États-Unis · 29 600 employés », « headquarters » : « 2788 San Tomas Expy, Santa Clara, Californie, 95051, États-Unis », « phone_number » : «(408) 486-2000', 'revenu': '79,8 milliards de dollars', 'symbole boursier': 'NVDA', 'secteur': 'Siège social', 'tags': ['Équipement de réseau informatique', 'Matériel et logiciels de sécurité réseau', 'Matériel informatique et périphériques', 'Fabrication']}
Fantastique ! Il ne reste plus qu’à exporter ces informations vers un fichier lisible par l’homme, tel que JSON.
Étape n° 8 : Exporter vers JSON
Exportez les informations sur l'entreprise vers un fichier company.json à l’aide de la commande suivante :
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
Tout d’abord, open() crée un fichier de sortie company.json. Ensuite, json.dump() transforme company en sa représentation JSON et l’écrit dans le fichier de sortie.
N’oubliez pas d’importer json depuis la bibliothèque standard Python :
import json
Étape n° 9 : assembler le tout
Voici le fichier scraper.py final :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# itérer à travers eux pour extraire les données des
# nœuds spécifiques qui nous intéressent
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# sélectionner l'élément de contenu et en extraire les données
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
# créer une instance de pilote Web Chrome
driver = webdriver.Chrome(service=Service())
# se connecter à la page cible
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# extraire les informations sur l'entreprise
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# extraire les données de la section « À propos »
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
text_container_elements = about_element.find_elements(By.CSS_SELECTOR, ".icon-text-container")
siège social = scrape_about_node(text_container_elements, « Siège social »)
numéro de téléphone = scrape_about_node(text_container_elements, « Numéro de téléphone »)
chiffre d'affaires = scrape_about_node(text_container_elements, « Chiffre d'affaires »)
symbole boursier = scrape_about_node(text_container_elements, « Symbole boursier »)
# extraire le secteur d'activité et les balises de l'entreprise
industry_element = about_element.find_element(By.CSS_SELECTOR, « h3.icon-label »)
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, « zi-directories-chips a »)
tags = [tag_element.text for tag_element in tag_elements]
# collecter les données récupérées
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# exporter les données récupérées au format JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# fermer le navigateur
driver.quit()
En un peu plus de 70 lignes de code, vous venez de créer un script de scraping de données ZoomInfo en Python !
Lancez le Scraper à l’aide de la commande suivante :
python3 script.py
Ou, sous Windows :
python script.py
Un fichier company.json apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez :
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Computer Equipment & Peripherals · Californie, États-Unis · 29 600 employés »,
« headquarters » : « 2788 San Tomas Expy, Santa Clara, Californie, 95051, États-Unis »,
« phone_number » : « (408) 486-2000 »,
« revenue » : « 79,8 milliards de dollars »,
« stock_symbol » : « NVDA »,
« industry » : « Siège social »,
« tags » : [
« Équipement de réseau informatique »,
« Matériel et logiciels de sécurité réseau »,
« Équipement informatique et périphériques »,
« Fabrication »
]
}Félicitations, mission accomplie !
Débloquer facilement les données ZoomInfo
ZoomInfo offre bien plus que de simples présentations d’entreprises : il fournit une multitude d’informations utiles. Le problème est que l’extraction de ces données peut s’avérer assez difficile, car la plupart des pages du domaine ZoomInfo sont protégées par des mesures anti-bot.
Si vous essayez d’accéder à ces pages à l’aide de Selenium ou d’autres outils d’automatisation de navigateur, vous risquez de vous heurter à une page CAPTCHA qui bloquera vos tentatives.
Dans un premier temps, pensez à suivre notre guide sur la manière de contourner les CAPTCHA dans Python. Cependant, vous pourriez encore rencontrer des erreurs 429 Too Many Requests en raison de la limitation stricte du débit du site. Dans ce cas, vous pouvez intégrer un Proxy dans Selenium pour faire tourner votre IP de sortie.
Ces problèmes résument bien à quel point le scraping de ZoomInfo sans les bons outils peut rapidement devenir un processus frustrant. De plus, le fait que vous ne puissiez pas utiliser de navigateurs headless rend votre script de scraping lent et gourmand en ressources.
La solution ? Utiliser l’API ZoomInfo Scraper dédiée de Bright Data pour récupérer les données du site cible via de simples appels API et sans être bloqué !
Conclusion
Dans ce tutoriel étape par étape, vous avez appris ce qu’est un Scraper ZoomInfo et les types de données qu’il peut récupérer. Vous avez également créé un script Python pour scraper ZoomInfo afin d’obtenir des données générales sur les entreprises, ce qui a nécessité moins de 100 lignes de code.
Le défi réside dans le fait que ZoomInfo utilise des mesures anti-bot strictes, notamment des CAPTCHA, l’empreinte digitale du navigateur et des interdictions d’IP, pour bloquer les scripts automatisés. Oubliez tous ces défis grâce à notre API ZoomInfo Scraper.
Si le Scraping web ne vous convient pas, mais que vous êtes toujours intéressé par les données sur les entreprises ou les employés, explorez nos Jeux de données ZoomInfo!
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données.




