

Depuis près de 25 ans, Tripadvisor est un excellent site pour découvrir toutes sortes de destinations de voyage sur le web. Aujourd’hui, nous allons extraire les données des hôtels de Tripadvisor. Tripadvisor utilise diverses techniques pour bloquer les Scrapers web, telles que :
- Défis JavaScript
- Empreinte digitale du navigateur
- Contenu dynamique des pages
Suivez notre guide ci-dessous et, à la fin, vous serez en mesure de scraper Tripadvisor avec facilité.
Prérequis
Tripadvisor utilise diverses techniques de blocage. Pour plus de simplicité, nous les avons répertoriées dans la liste ci-dessous.
- Défi JavaScript: Tripadvisor envoie un défi simple (en JavaScript) à votre navigateur sous la forme d’un CAPTCHA. Si votre navigateur ne parvient pas à le résoudre, il s’agit probablement d’un bot.
- Empreinte digitale du navigateur: ils envoient un cookie à votre navigateur, puis ils vous suivent à l’aide de celui-ci.
- Contenu dynamique: nous obtenons initialement une page vierge. Ensuite, le site effectue une série d’appels API pour récupérer et afficher nos données.
Python Requests et BeautifulSoup ne suffisent tout simplement pas. Nous avons besoin d’un véritable navigateur. Avec Selenium, nous utilisons webdriver pour contrôler notre navigateur à partir d’un script Python. Selenium comprend tout ce dont nous avons besoin. Pour en savoir plus sur le Scraping web avec Selenium, cliquez ici.
Installons Selenium. Vous devez également vous assurer que webdriver est installé. Vous trouverez la dernière version de webdriver ici. Vous devez vous assurer que votre version de Chromedriver correspond à votre version de Chrome.
Vous pouvez vérifier votre numéro de version à l’aide de la commande suivante. Assurez-vous qu’il correspond à votre version de Chromedriver.
google-chrome --version
Vous devriez obtenir un résultat similaire à celui-ci.
Google Chrome 130.0.6723.116
Nous pouvons ensuite installer Selenium à l’aide de la commande suivante.
pip install selenium
Une fois Selenium installé, vous n’avez plus besoin d’installer quoi que ce soit d’autre. Selenium répondra à tous vos besoins en matière de scraping. Tous les autres paquets utilisés dans ce tutoriel sont fournis avec Python.
Que scraper sur Tripadvisor
Voyons comment nous allons extraire les hôtels de Tripadvisor. Lorsque nous effectuons une recherche simple sur Miami sur Tripadvisor, nous obtenons une page similaire à celle que vous voyez dans la capture d’écran ci-dessous. Si vous regardez bien, nous n’obtenons pas seulement des résultats pour les hôtels, mais pour toutes les catégories.
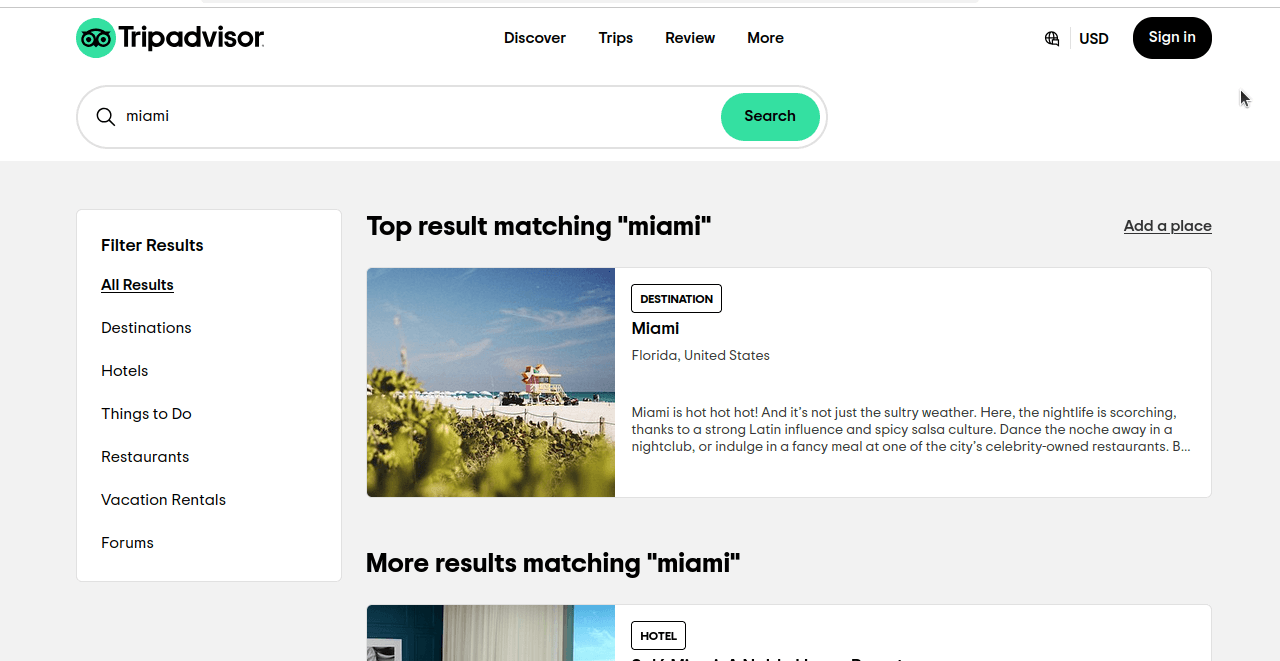
Examinez de plus près l’URL de cette page : https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Maintenant, nous allons cliquer sur « Hôtels » et examiner notre URL : https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Les URL sont toujours très similaires. Ci-dessous, nous allons examiner ces URL, mais nous allons supprimer les parties inutiles.
- Tous les résultats:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - Hôtels:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrc est la requête que nous utilisons pour sélectionner nos résultats. ssrc=a est utilisé pour Tous les résultats. ssrc=h est utilisé pour Hôtels. Si vous cliquez sur ce lien https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h, vous devriez obtenir une page similaire à celle que vous voyez dans la capture d’écran ci-dessous.
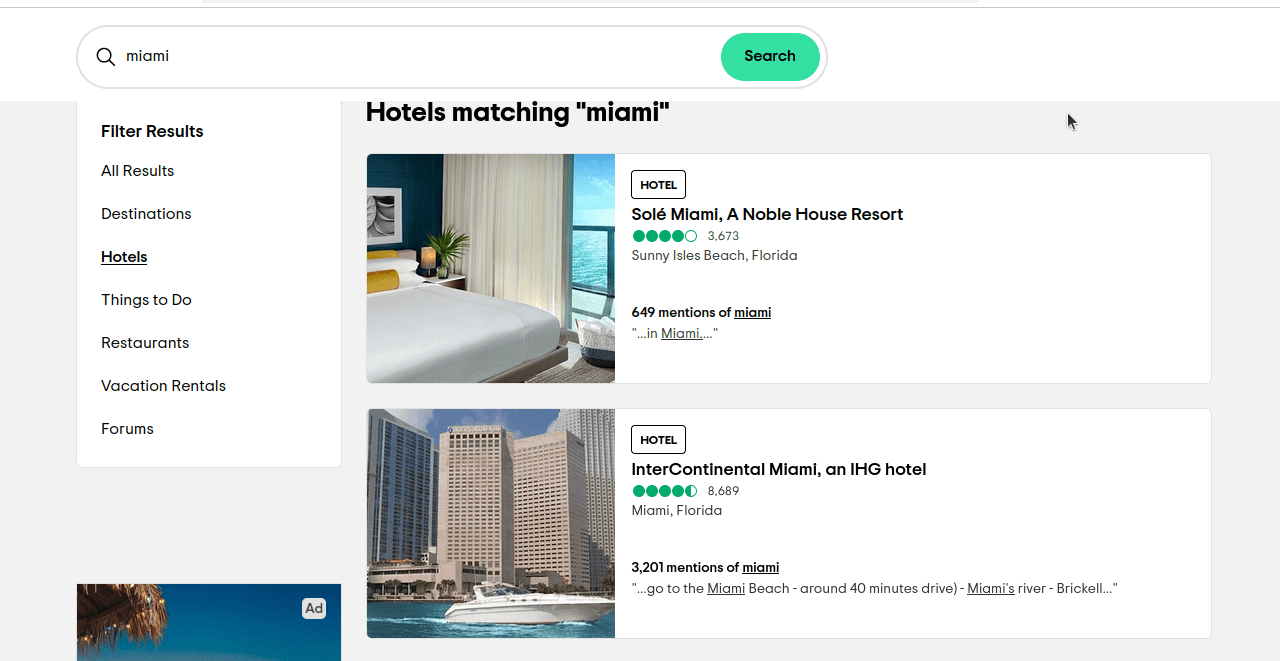
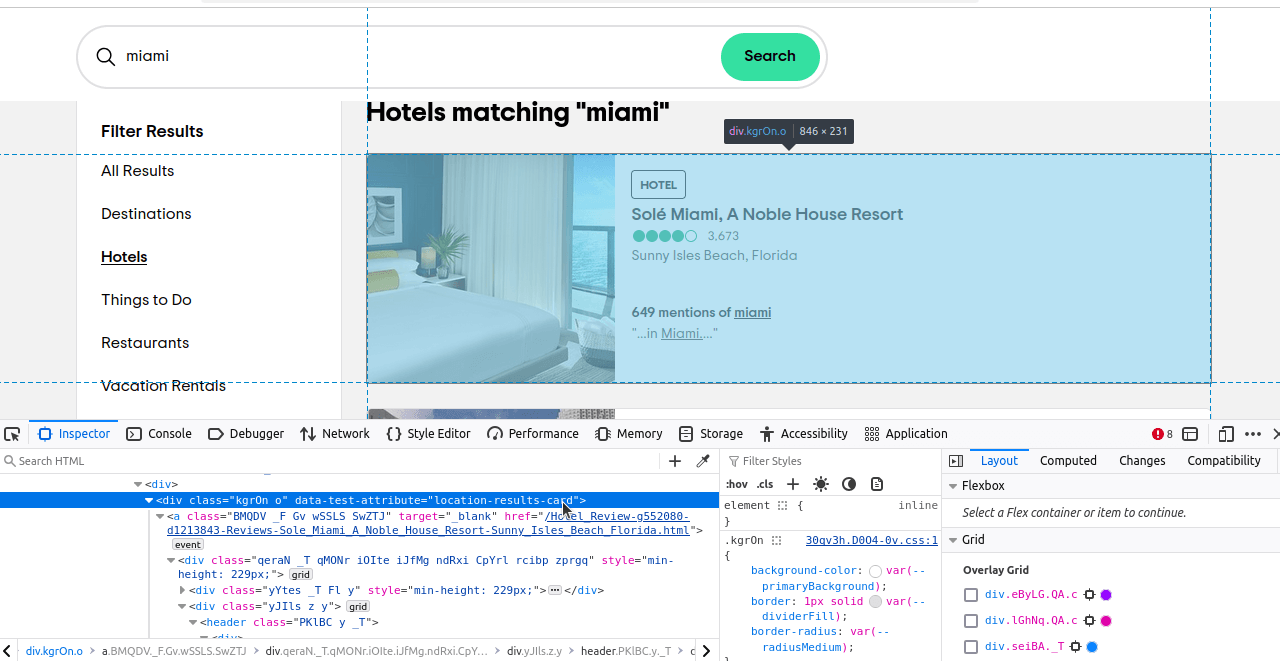
Il ne nous reste plus qu’à déterminer les éléments que nous voulons localiser. Si vous inspectez ces éléments, vous remarquerez que chaque résultat possède un attribut data-test « location-results-card ». C’est très important. Nous pouvons l’utiliser pour écrire notre sélecteur CSS : div[data-test-attribute='location-results-card']. Lorsque nous scrappons la page réelle, nous recherchons tous les éléments de la page qui correspondent à ce sélecteur.
Récupérer les données de Tripadvisor avec Vanilla Selenium
Nous allons maintenant essayer de scraper Tripadvisor à l’aide du bon vieux Selenium. Nous allons écrire un script assez simple dans l’ensemble. Nous n’avons besoin que de deux fonctions. L’une pour effectuer notre scraping, et l’autre pour écrire nos données dans un fichier CSV. Une fois que nous les aurons, nous rassemblerons le tout dans un script entièrement fonctionnel.
Jetez un œil à write_to_csv(). Il prend deux arguments, data et page_number. data peut être soit un dictionnaire, soit un tableau d’objets dictionnaire que nous voulons écrire. page_number est utilisé pour écrire notre nom de fichier. Nous utilisons Path(filename).exists() pour vérifier si notre fichier existe. mode est le mode que nous utilisons pour ouvrir le fichier. Si le fichier existe, nous définissons notre mode sur « a », ou append. Si le fichier n’existe pas, nous laissons notre mode par défaut, « w », write. Ces deux modes garantissent que nous avons toujours un fichier et que le fichier existant ne sera pas écrasé.
Fonctions individuelles
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Écriture des données dans le fichier CSV...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Écriture réussie de {page} dans CSV...")
- Au début de la fonction, nous vérifions si nos
donnéessont uneliste. Si ce n’est pas le cas, nous les convertissons en liste. f"tripadvisor-{page_number}.csv"construit notre nom de fichier.- Notre
modepar défaut est« w », mais si le fichier existe, nous changeons notre mode en« a ». csv.DictWriter(file, fieldnames=data[0].keys())initialise notre rédacteur de fichiers.- Si nous sommes en mode écriture, nous utilisons les clés de notre premier objet pour nos en-têtes. Si nous ajoutons des données au fichier, nous n’avons pas besoin de le faire.
- Une fois le fichier configuré, nous utilisons
writer.writerows(data)pour écrire nos données dans un fichier CSV.
Maintenant, examinons notre fonction de scraping. Cette fonction ne prend qu’un seul argument, notre page _number...assez explicite. Nous commençons par configurer certaines options ChromeOptions personnalisées. Nous ajoutons des arguments pour rendre notre navigateur headless et utiliser un faux agent utilisateur. Cela devrait permettre de masquer suffisamment notre navigateur pour que Tripadvisor nous laisse passer. Nous utilisons ensuite webdriver pour lancer notre navigateur et naviguer vers la page des résultats de recherche. Nous utilisons sleep(5) afin d’attendre 5 secondes que le contenu se charge, ce qui nous permet également de ressembler davantage à un utilisateur normal. Nous utilisons le sélecteur CSS que nous avons mentionné précédemment dans la section « Que scraper ? ». Si nous n’avons pas de hotel_cards, nous prenons une capture d’écran et quittons la fonction prématurément. Si nous avons des hotel_cards, nous extrayons leurs données et les ajoutons à notre tableau scraped_data. Une fois le scraping des données terminé, nous les écrivons toutes dans un fichier CSV.
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Connexion au Navigateur de scraping...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connecté ! Récupération de la page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
« location » : data_array[3],
« location_mentions » : data_array[4].split(« »)[0],
« review_summary » : data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Carte {index} récupérée avec succès")
print(f"Page {page_number} récupérée")
write_to_csv(scraped_data, page_number)
Récupérer les données Tripadvisor
Une fois tous les éléments assemblés, nous obtenons un script comme celui-ci. N’hésitez pas à copier-coller le code ci-dessous dans votre propre fichier Python.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Écriture dans CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Écriture des données dans le fichier CSV...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Écriture réussie de {page} dans CSV...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Connexion au Navigateur de scraping...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connecté ! Récupération de la page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
« location » : data_array[3],
« location_mentions » : data_array[4].split(« »)[0],
« review_summary » : data_array[5]
}
scraped_data.append(hotel_dict)
print(f« Carte {index} récupérée avec succès »)
print(f"Page {page_number} récupérée")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
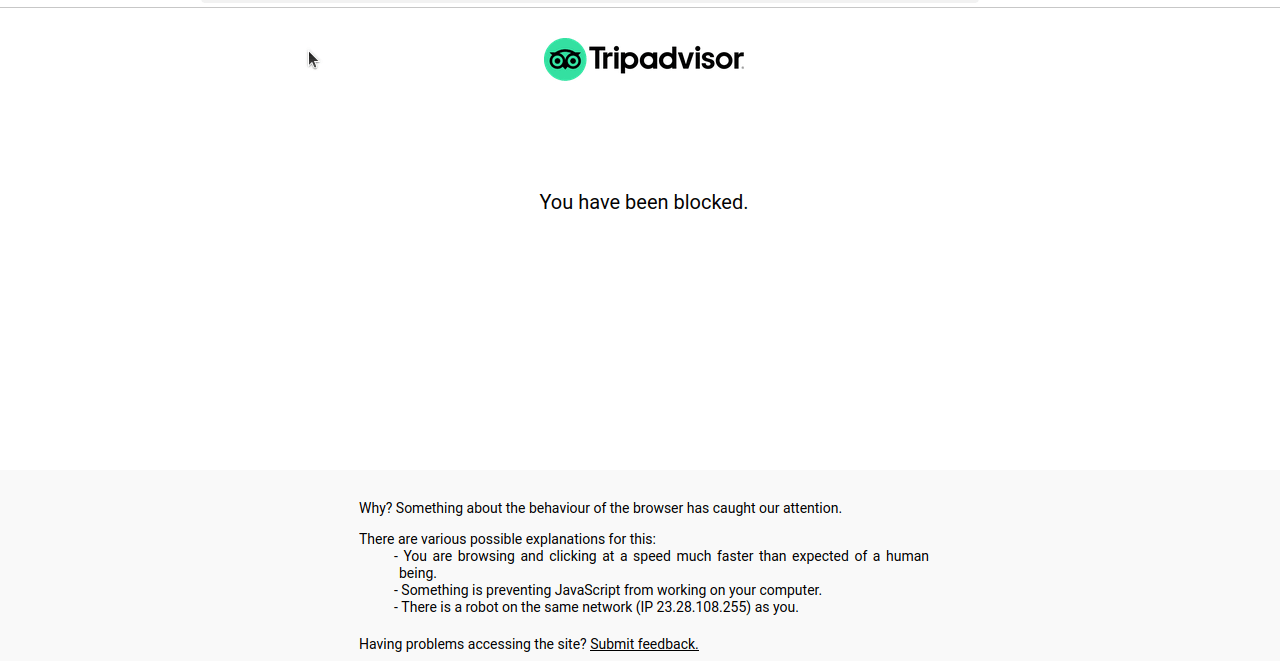
Lorsque nous exécutons ce code, nous obtenons le plus souvent un écran bloqué ou un CAPTCHA comme celui que vous voyez dans la capture d’écran suivante.

Techniques avancées
Vous trouverez ci-dessous certaines des techniques avancées utilisées dans notre script. Nous aborderons principalement la manière dont la pagination est gérée et certaines techniques permettant d’éviter le blocage.
Gestion de la pagination
Jetez un œil à l’URL que nous utilisons : https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}. Notre pagination est gérée avec le paramètre offset. Nous obtenons 30 résultats par page. page_number*30 multiplie notre numéro de page par le nombre de résultats par page (30). La page 0 affichera les résultats 1 à 30. La page 2 affichera les résultats 31 à 60, et ainsi de suite.
Examinons également notre fonction principale. PAGES contient le nombre de pages que nous souhaitons extraire. Si vous souhaitez extraire les cinq premières pages de données, remplacez simplement PAGES = 1 par PAGES = 5.
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Atténuer le blocage
Avec Vanilla Selenium, nous utilisons plusieurs techniques pour éviter d’être bloqués. Nous utilisons à la fois un faux agent utilisateur et la fonction sleep(5). Cette fonction sleep permet à la page de se charger et espace également nos requêtes lorsque nous récupérons plusieurs pages.
Voici notre agent utilisateur. Il indique à Tripadvisor que notre navigateur est compatible avec Chrome 130.0.0.0 et Safari 537.36. Lorsque Tripadvisor lit cette information, son serveur nous renvoie une page compatible avec ces navigateurs.
Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/130.0.0.0 Safari/537.36
Cependant, il est toujours possible d’être repéré et que votre Scraper soit bloqué. Pour contourner systématiquement leur blocage, nous avons besoin d’un outil un peu plus puissant que Vanilla Selenium.
Envisagez d’utiliser Bright Data
Bright Data propose toutes sortes de solutions pour contourner les blocages rencontrés avec Vanilla Selenium. Le Navigateur de scraping nous permet d’exécuter une instance distante de Selenium en utilisant uniquement les meilleurs Proxy de Bright Data. Tout d’abord, nous allons passer en revue le processus d’inscription. Ensuite, nous modifierons notre script précédent pour qu’il fonctionne avec le Navigateur de scraping.
Création d’un compte
Tout d’abord, rendez-vous sur notre page du Navigateur de scraping. Cliquez sur « Essai gratuit ». Vous pouvez créer un compte à l’aide de Google, Github ou de votre adresse e-mail.
Une fois votre compte créé, vous serez redirigé vers le tableau de bord. Cliquez sur « Ajouter ».
Vous devriez voir un menu déroulant similaire à l’image ci-dessous. Cliquez sur le Navigateur de scraping.
Vous serez alors redirigé vers la page où vous pouvez configurer le Navigateur de scraping. Nous allons simplement utiliser les paramètres par défaut. Par défaut, le Navigateur de scraping est équipé d’un solveur CAPTCHA intégré.
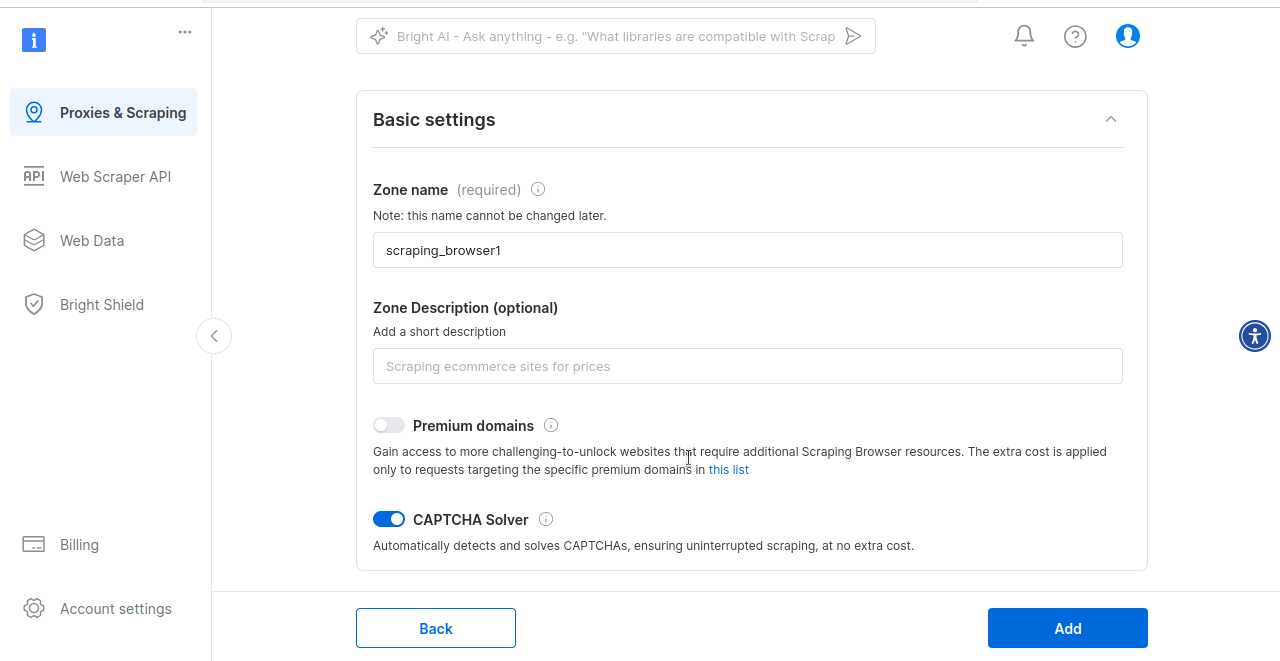
Enfin, vous serez invité à créer votre zone de Navigateur de scraping. Si vous êtes prêt à essayer le Navigateur de scraping, cliquez sur Oui.
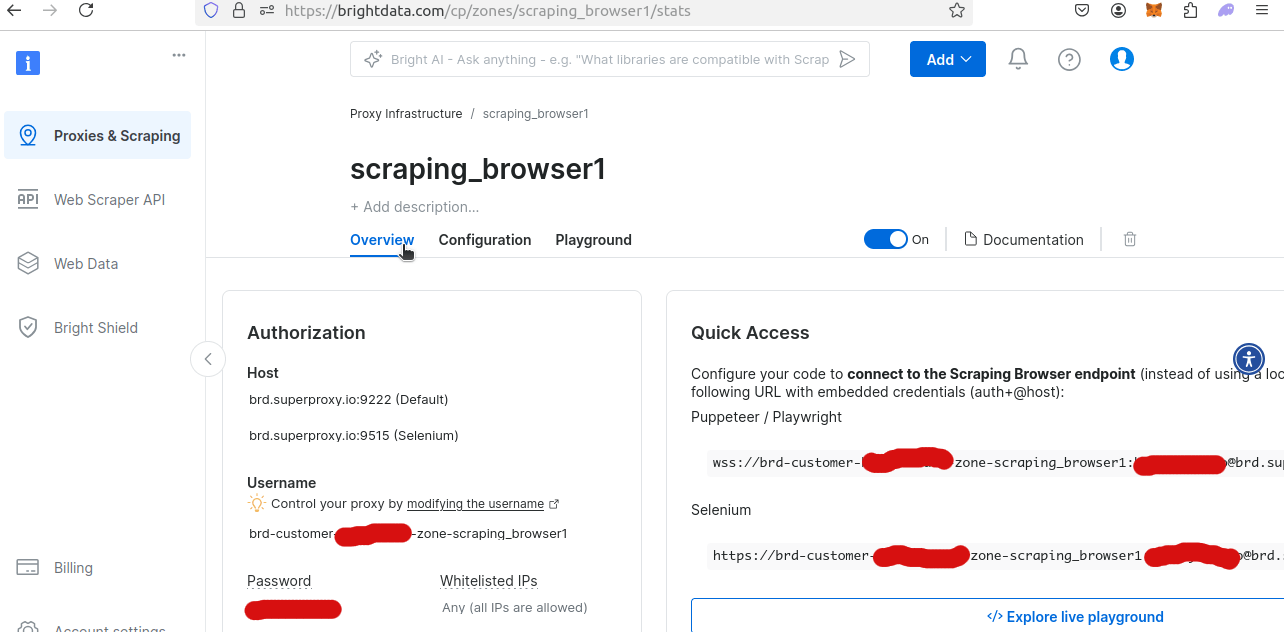
Si vous consultez la vue d’ensemble de votre nouvelle zone de Navigateur de scraping, vous pourrez obtenir votre nom d’utilisateur et votre mot de passe uniques. Vous en aurez besoin pour accéder à Scraping Browser à partir de votre script Python.
Extraire nos données à l’aide du Navigateur de scraping Bright Data
Notre exemple de code ci-dessous a été modifié pour utiliser Remote Webdriver avec le Navigateur de scraping. Veillez à remplacer YOUR_USERNAME, YOUR_ZONE_NAME et YOUR_PASSWORD par votre nom d’utilisateur, votre zone et votre mot de passe réels !
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-VOTRE_NOM_D'UTILISATEUR-zone-VOTRE_NOM_DE_ZONE:VOTRE_MOT_DE_PASSE"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Écriture dans CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Écriture des données dans le fichier CSV...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Écriture réussie de {page} dans CSV...")
def scrape_page(page_number: int):
print("Connexion au Navigateur de scraping...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connecté ! Récupération de la page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("Aucune fiche d'hôtel trouvée ! Prise d'une capture d'écran et sortie.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
« location » : data_array[3],
« location_mentions » : data_array[4].split(« »)[0],
« review_summary » : data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Carte {index} récupérée avec succès")
print(f"Page {page_number} récupérée")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Cet exemple est assez similaire à notre exemple avec Vanilla Selenium, mais il existe quelques petites différences à noter ici. Elles concernent principalement le fait que nous utilisons un pilote Web distant au lieu d’un pilote Web standard.
- Nous configurons une instance de webdriver distant avec notre connexion Proxy :
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515". - Notre gestion des erreurs est légèrement modifiée :
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png"). Nous utilisons désormaisdriver.get_screenshot_as_file()au lieu dedriver.save_screenshot().
À part quelques modifications mineures pour notre connexion Proxy à distance, notre code pour le Navigateur de scraping avec Selenium est pratiquement identique à celui de Vanilla Selenium. La plus grande différence : le Navigateur de scraping obtient facilement nos résultats.
Lorsque vous exécutez ce code, vous pouvez recevoir l’erreur ci-dessous. Cela peut se produire lorsque vous utilisez une connexion à distance. Si c’est le cas, réessayez le script. Il faut parfois plusieurs essais pour établir une connexion stable.
urllib3.exceptions.ProtocolError: ('Connexion interrompue.', RemoteDisconnected('La connexion distante a été fermée sans réponse'))
Si votre script s’est exécuté avec succès, vous devriez obtenir le résultat ci-dessous.
Connexion au Navigateur de scraping...
-------------------------------
Connecté ! Récupération de la page...
Carte 0 récupérée avec succès
Carte 1 récupérée avec succès
Carte 2 récupérée avec succès
Carte 3 récupérée avec succès
Carte 4 récupérée avec succès
Carte 5 récupérée avec succès
Carte 6 récupérée avec succès
Carte 7 récupérée avec succès
Carte 8 récupérée avec succès
Carte 9 récupérée avec succès
Carte 10 récupérée avec succès
Carte 11 récupérée avec succès
Carte 12 récupérée avec succès
Carte 13 récupérée avec succès
Carte 14 récupérée avec succès
Carte 15 récupérée avec succès
Carte 16 récupérée avec succès
Carte 17 récupérée avec succès
Carte 18 récupérée avec succès
Carte 19 récupérée avec succès
Carte 20 récupérée avec succès
Carte 21 récupérée avec succès
Carte 22 récupérée avec succès
Carte 23 récupérée avec succès
Carte 24 récupérée avec succès
Carte 25 récupérée avec succès
Carte 26 récupérée avec succès
Carte 27 récupérée avec succès
Carte 28 récupérée avec succès
Carte 29 récupérée avec succès
Page 0 récupérée
Écriture dans le fichier CSV...
Écriture des données dans le fichier CSV...
0 écrit avec succès dans le fichier CSV...
Voici une capture d’écran de nos données CSV à l’aide d ‘ONLYOFFICE.
L’image ne s’affiche pas Raisons possibles
- Le fichier image est peut-être corrompu
- Le serveur hébergeant l’image est indisponible
- Le chemin d’accès à l’image est incorrect
- Le format de l’image n’est pas pris en charge
Autre approche : Jeux de données
Si vous ne souhaitez pas coder un Scraper ou si vous avez besoin de données à plus grande échelle, pensez à utiliser les jeux de données structurés de Tripadvisor. Nos jeux de données fournissent des informations bien organisées et de haute qualité, adaptées à vos besoins, vous permettant d’analyser les tendances en matière de voyage, de surveiller les prix de vos concurrents et d’optimiser l’expérience client sans effort.
Grâce à un ensemble de données Tripadvisor, vous pouvez accéder à des points de données clés tels que les noms d’hôtels, les avis, les notes, les équipements, les prix, etc. Toutes ces données sont fournies dans des formats flexibles (par exemple, JSON, CSV, Parquet) et mises à jour selon un calendrier adapté à votre flux de travail. Mieux encore, ces jeux de données sont 100 % conformes et évolutifs, ce qui vous permet de gagner du temps et d’économiser des ressources tout en garantissant leur exactitude.
Principaux avantages :
- Accédez à tous les points de données importants de Tripadvisor sans rencontrer de blocages.
- Adaptez les jeux de données à vos besoins spécifiques grâce à des filtres et à un formatage personnalisé.
- Automatisez la livraison des données vers des plateformes telles que Snowflake, S3 ou Azure.
Concentrez-vous sur l’analyse des données, pas sur leur collecte : laissez-nous nous occuper de la partie difficile. Découvrez dès aujourd’hui nos Jeux de données Tripadvisor !
Conclusion
Des défis JavaScript au contenu entièrement dynamique, Tripadvisor peut être très difficile à scraper. Maintenant que vous avez terminé notre guide, cela devrait être un peu plus facile. À ce stade, vous devriez comprendre que vous pouvez utiliser Selenium pour contrôler un navigateur à la fois localement et à distance. Avec les navigateurs headless (comme Selenium), vous avez également la possibilité de faire une capture d’écran de vos données. Cela facilite grandement le débogage de notre Scraper. Vous savez comment extraire les données des hôtels et vous savez comment écrire un fichier CSV à l’aide du bon vieux Python, sans avoir à installer quoi que ce soit d’autre !
Si vous souhaitez effectuer un scraping à grande échelle, Bright Data propose une multitude de produits pour vous aider. Le Navigateur de scraping vous offre tous les meilleurs outils pour toutes les tâches liées au scraping. Vous pouvez contrôler un vrai navigateur avec une connexion Proxy stable et le navigateur sans interface graphique de votre choix. Vous n’aurez plus jamais à vous soucier des CAPTCHA !
Vous pouvez également choisir la meilleure façon d’obtenir des données : achetez un ensemble de données Tripadvisor prêt à l’emploi. Inscrivez-vous dès maintenant pour commencer votre essai gratuit !





