

Dans cet article de blog, vous apprendrez :
- Qu’est-ce qu’un scraper OpenSea ?
- Les types de données que vous pouvez extraire automatiquement d’OpenSea
- Comment créer un script de scraping OpenSea en utilisant Python
- Quand et pourquoi une solution plus avancée peut être nécessaire
Plongeons dans l’aventure !
Qu’est-ce qu’un scraper OpenSea ?
Un scraper OpenSea est un outil conçu pour collecter les données d’OpenSea, la plus grande place de marché de NFT au monde. L’objectif principal de cet outil est d’automatiser la collecte de diverses informations relatives aux NFT. Généralement, il utilise des solutions de navigation automatisées pour récupérer les données OpenSea en temps réel, sans effort manuel.
Données à extraire d’OpenSea
Voici quelques-uns des points de données clés que vous pouvez extraire d’OpenSea :
- Nom de la collection NFT: Le titre ou le nom de la collection NFT.
- Rang de la collection: le rang ou la position de la collection en fonction de ses performances.
- Image du NFT: L’image associée à la collection ou à l’article du NFT.
- Prix plancher: Le prix minimum indiqué pour un article de la collection.
- Volume: Le volume total des transactions de la collection NFT.
- Variation en pourcentage: La variation de prix ou de pourcentage de la performance de la collection sur une période donnée.
- Token ID: identifiant unique pour chaque NFT de la collection.
- Dernier prix de vente: Le prix de vente le plus récent d’un NFT dans la collection.
- Historique des ventes: L’historique des transactions pour chaque article NFT, y compris les prix et les acheteurs précédents.
- Offres: Offres actives faites pour un NFT dans la collection.
- Informations sur le créateur: Détails sur le créateur du NFT, tels que son nom d’utilisateur ou son profil.
- Traits/attributs: Caractéristiques ou propriétés spécifiques des articles NFT (par exemple, rareté, couleur, etc.).
- Description de l’article: Une brève description ou des informations sur l’article NFT.
Comment faire du scrape sur OpenSea : Guide étape par étape
Dans cette section guidée, vous apprendrez à construire un scraper OpenSea. L’objectif est de développer un script Python qui recueille automatiquement des données sur les collections NFT à partir de la section “Top” de la page “Gaming”:
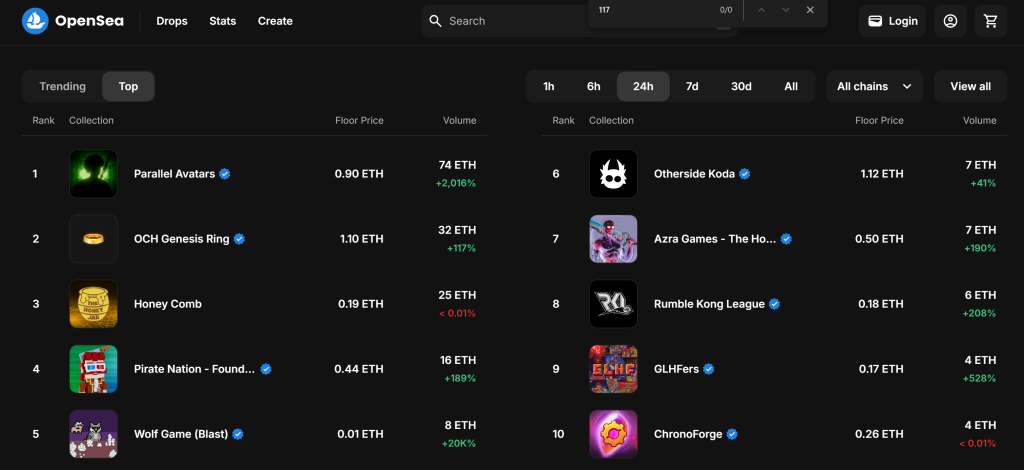
Suivez les étapes ci-dessous et découvrez comment scraper OpenSea !
Étape 1 : Configuration du projet
Avant de commencer, vérifiez que Python 3 est installé sur votre machine. Sinon, téléchargez-le et suivez les instructions d’installation.
Utilisez la commande ci-dessous pour créer un dossier pour votre projet :
mkdir opensea-scraper
Le répertoire opensea-scraper représente le dossier du projet de votre Python OpenSea scraper.
Naviguez jusqu’à lui dans le terminal et initialisez un environnement virtuel à l’intérieur :
cd opensea-scraper
python -m venv venv
Chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition feront l’affaire.
Créez un fichier scraper.py dans le dossier du projet, qui devrait maintenant contenir cette structure de fichier :

Pour l’instant, scraper.py est un script Python vierge, mais il contiendra bientôt la logique de scraping souhaitée.
Dans le terminal de l’IDE, activer l’environnement virtuel. Sous Linux ou macOS, lancer cette commande :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Incroyable, vous disposez maintenant d’un environnement Python pour le web scraping !
Étape 2 : Choisir la bibliothèque de scraping
Avant de vous lancer dans le codage, vous devez déterminer les meilleurs outils de scraping pour extraire les données nécessaires. Pour ce faire, vous devez d’abord effectuer un test préliminaire afin d’analyser le comportement du site cible :
- Ouvrez la page cible en mode incognito pour éviter que les cookies et les préférences préenregistrés n’affectent votre analyse.
- Cliquez avec le bouton droit de la souris n’importe où sur la page et sélectionnez “Inspecter” pour ouvrir les outils de développement du navigateur.
- Naviguez jusqu’à l’onglet “Réseau”.
- Recharger la page et interagir avec elle, par exemple en cliquant sur les boutons “1h” et “6h”.
- Surveillez l’activité dans l’onglet “Fetch/XHR”.
Cela vous permettra de savoir si la page web se charge et rend les données de manière dynamique :
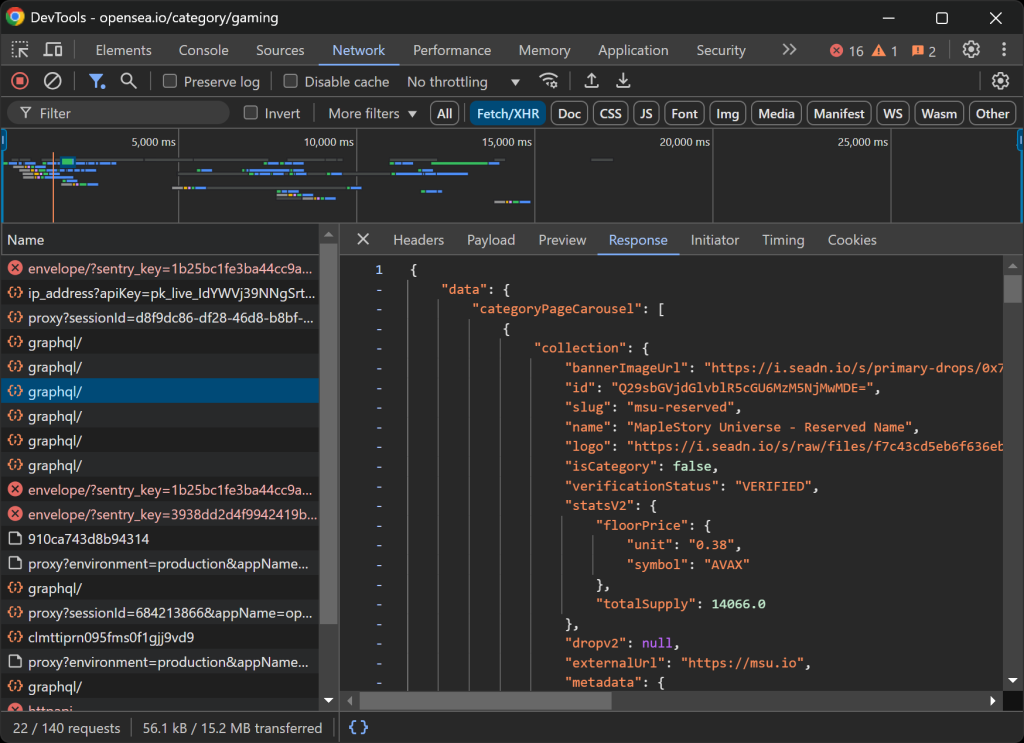
Dans cette section, vous pouvez voir toutes les requêtes AJAX que la page effectue en temps réel. En inspectant ces requêtes, vous remarquerez qu’OpenSea récupère dynamiquement des données du serveur. En outre, une analyse plus poussée révèle que certaines interactions avec des boutons déclenchent un rendu JavaScript pour mettre à jour dynamiquement le contenu de la page.
Ceci indique que le scraping d’OpenSea nécessite un outil d’automatisation du navigateur comme Selenium!
Selenium vous permet de contrôler un navigateur web de manière programmatique, en imitant les interactions réelles de l’utilisateur afin d’extraire des données de manière efficace. Installons-le et commençons.
Étape 3 : Installer et configurer Selenium
Vous pouvez obtenir Selenium via le paquetage pip selenium. Dans un environnement virtuel activé, exécutez la commande ci-dessous pour installer Selenium :
pip install -U selenium
Pour savoir comment utiliser l’outil d’automatisation du navigateur, lisez notre guide sur le web scraping avec Selenium.
Importez Selenium dans scraper.py et initialisez un objet WebDriver pour contrôler Chrome :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
Le snippet ci-dessus met en place une instance WebDriver pour interagir avec Chrome. Gardez à l’esprit qu’OpenSea emploie des mesures anti-scraping qui détectent les navigateurs headless et les bloquent. Plus précisément, le serveur renvoie une page “Accès refusé”.
Cela signifie que vous ne pouvez pas utiliser l’option --headless pour ce scraper. Comme approche alternative, vous pouvez explorer Playwright Stealth ou SeleniumBase.
Comme OpenSea adapte sa mise en page en fonction de la taille de la fenêtre, agrandissez la fenêtre du navigateur pour vous assurer que la version de bureau est affichée :
driver.maximize_window()
Enfin, veillez toujours à fermer correctement le pilote WebDriver pour libérer des ressources :
driver.quit()
C’est génial ! Vous êtes maintenant entièrement configuré pour commencer à scraper OpenSea.
Étape 4 : Visiter la page cible
Utilisez la méthode get() de Selenium WebDriver pour indiquer au navigateur d’accéder à la page souhaitée :
driver.get("https://opensea.io/category/gaming")
Votre fichier scraper.py devrait maintenant contenir ces lignes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
Placez un point d’arrêt de débogage sur la dernière ligne du script et exécutez-le. Voici ce que vous devriez voir :
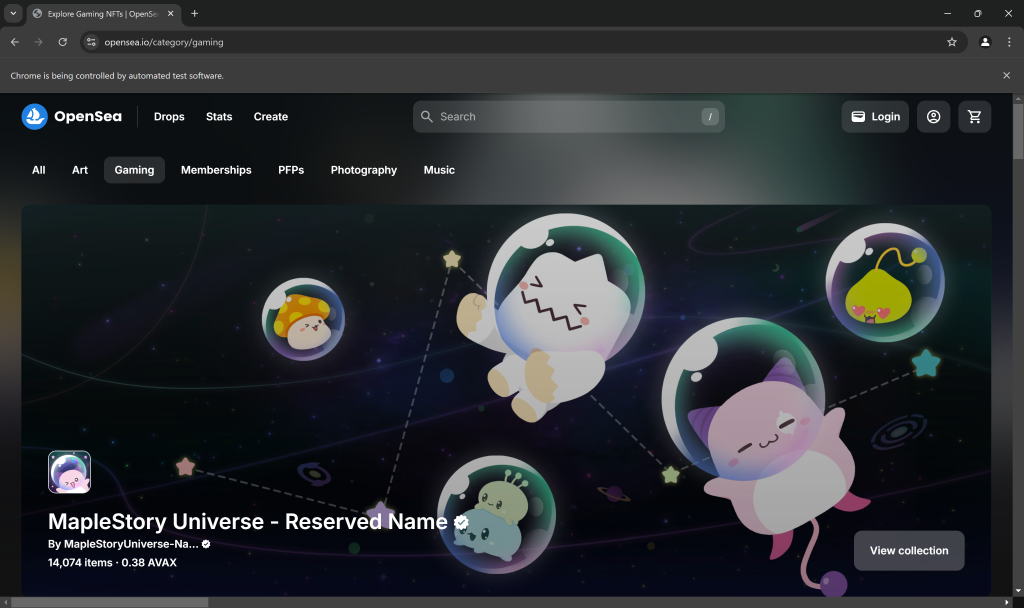
Le message “Chrome est contrôlé par un logiciel de test automatisé” certifie que Selenium contrôle Chrome comme prévu. C’est très bien !
Étape 5 : Interagir avec la page web
Par défaut, la page “Gaming” affiche les collections NFT “Trending” :
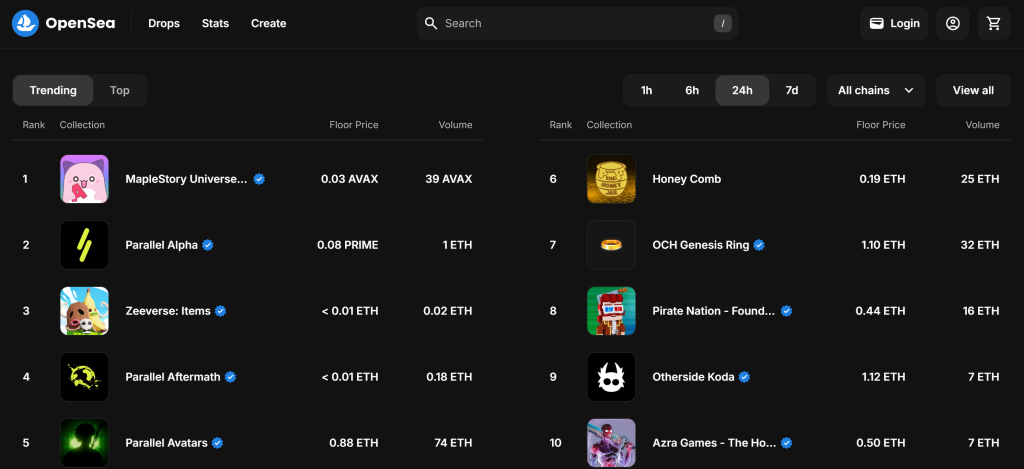
Rappelez-vous que vous êtes intéressé par la collection NFT “Top”. En d’autres termes, vous voulez demander à votre scraper OpenSea de cliquer sur le bouton “Top” comme ci-dessous :
Dans un premier temps, inspectez le bouton “Haut” en cliquant dessus avec le bouton droit de la souris et en sélectionnant l’option “Inspecter” :
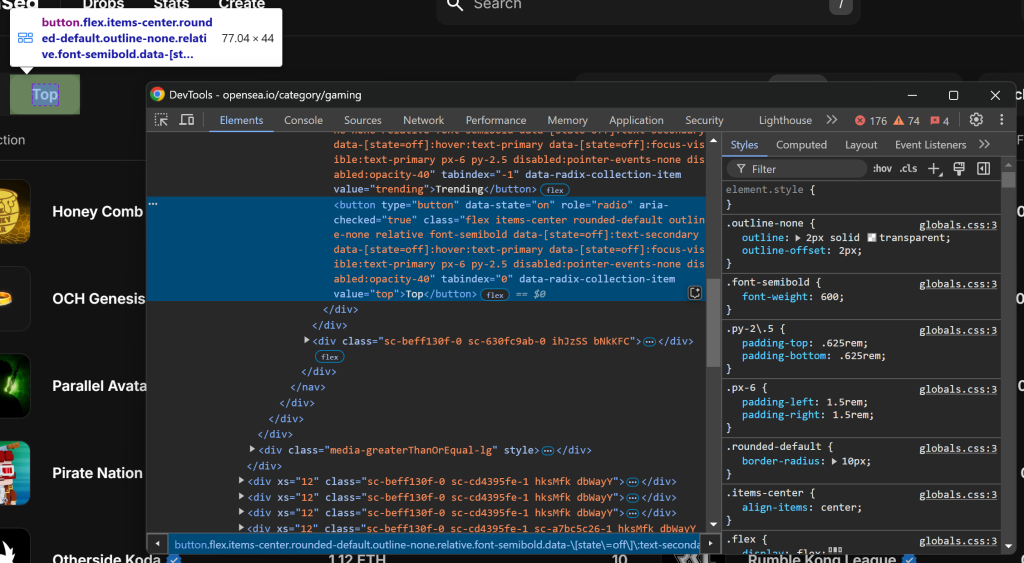
Notez que vous pouvez le sélectionner en utilisant le sélecteur CSS [value="top"]. Utilisez find_element() de Selenium pour appliquer ce sélecteur CSS à la page. Ensuite, une fois l’élément sélectionné, cliquez dessus avec click():
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
Pour que le code ci-dessus fonctionne, n’oubliez pas d’ajouter l’importation By :
from selenium.webdriver.common.by import By
Génial ! Ces lignes de code simuleront l’interaction souhaitée.
Étape n° 6 : Se préparer à gratter les collections du NFT
La page cible affiche les 10 premières collections NFT pour la catégorie sélectionnée. Puisqu’il s’agit d’une liste, initialiser un tableau vide pour stocker les informations récupérées :
nft_collections = []
Inspectez ensuite l’élément HTML d’une entrée de collection NFT :
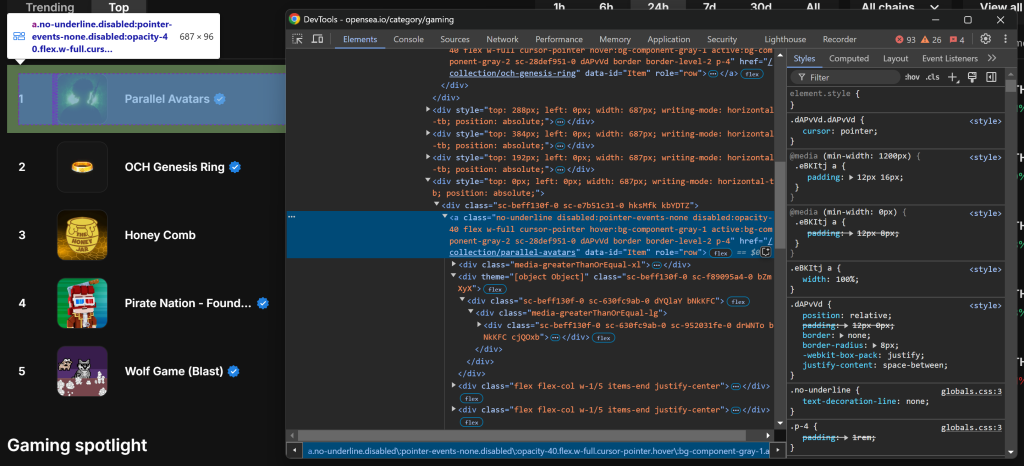
Notez que vous pouvez sélectionner toutes les entrées de la collection NFT à l’aide du sélecteur CSS a[data-id="Item"]. Étant donné que certains noms de classe dans les éléments semblent être générés de manière aléatoire, évitez de les cibler directement. Concentrez-vous plutôt sur les attributs data-*, car ils sont généralement utilisés pour les tests et restent cohérents dans le temps.
Récupérer tous les éléments d’entrée de la collection NFT en utilisant find_elements() :
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
Ensuite, il faut parcourir les éléments et se préparer à extraire des données de chacun d’entre eux :
for item_element in item_elements:
# Scraping logic...
Génial ! Vous êtes prêt à commencer à récupérer les données des éléments NFT d’OpenSea.
Étape 7 : Récupérer les éléments de la collection NFT
Inspecter une entrée de collection NFT :
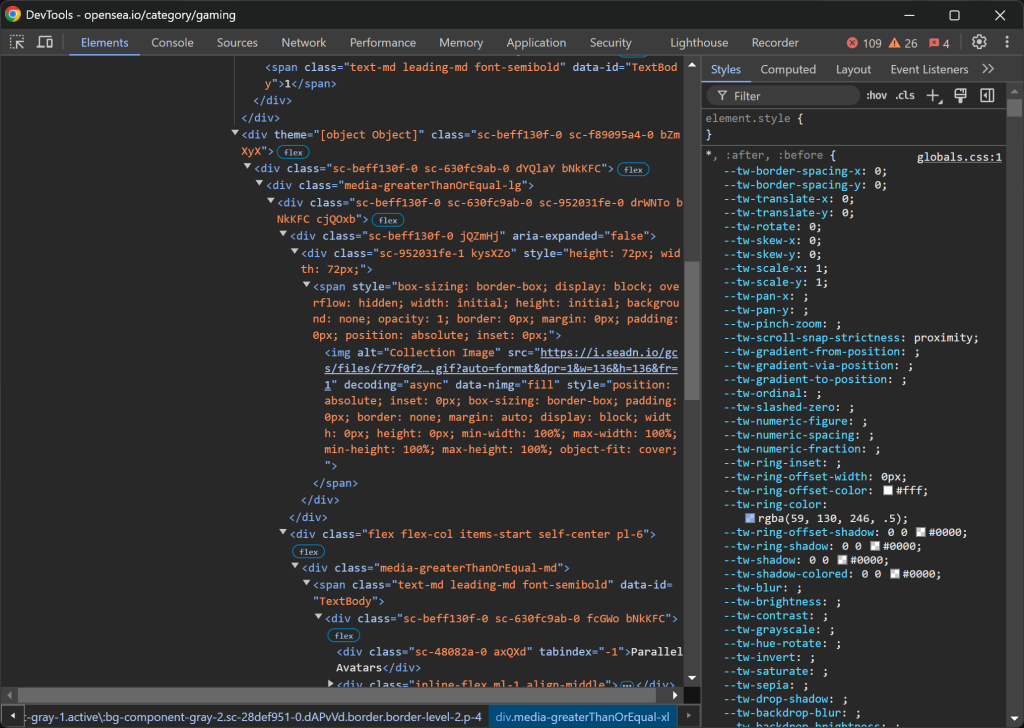
La structure HTML est assez complexe, mais vous pouvez en extraire les détails suivants :
- L’image de la collection de
img[alt="Collection Image"] - Le rang de la collection est de
[data-id= "TextBody"] - Le nom de la collection de
[tabindex="-1"]
Malheureusement, ces éléments n’ont pas d’attributs uniques ou stables, et vous devrez donc vous appuyer sur des sélecteurs potentiellement instables. Commencez par mettre en œuvre la logique d’extraction pour ces trois premiers attributs :
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
La propriété .text récupère le contenu textuel de l’élément sélectionné. Étant donné que le rang sera utilisé ultérieurement pour trier les données extraites, il est converti en nombre entier. Entre-temps, .get_attribute("src") récupère la valeur de l’attribut src, en extrayant l’URL de l’image.
Ensuite, il faut se concentrer sur les colonnes .w-1/5:
Voici comment les données sont structurées :
- La première colonne
.w-1/5contient le prix plancher. - La deuxième colonne
.w-1/5contient le volume et le pourcentage de variation, chacun dans des éléments séparés.
Extrayez ces valeurs en suivant la logique suivante :
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
Notez que vous ne pouvez pas utiliser .w-1/5 directement mais que vous devez échapper / avec N.
Nous y voilà ! La logique de scraping d’OpenSea pour obtenir les collections NFT est terminée.
Étape n° 8 : Collecte des données récupérées
Les données extraites sont actuellement réparties sur plusieurs variables. Remplissez un nouvel objet nft_collection avec ces données :
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
Ensuite, n’oubliez pas de l’ajouter au tableau nft_collections:
nft_collections.append(nft_collection)
En dehors de la boucle for, triez les données extraites par ordre croissant :
nft_collections.sort(key=lambda x: x["rank"])
Fantastique ! Il ne reste plus qu’à exporter ces informations vers un fichier lisible par l’homme comme le CSV.
Étape 9 : Exporter les données scrapées au format CSV
Python dispose d’un support intégré pour l’exportation de données vers des formats tels que CSV. Vous pouvez y parvenir avec ces lignes de code :
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
Ce snippets exporte les données extraites de la liste nft_collections vers un fichier CSV nommé nft_collections.csv. Il utilise le module csv de Python pour créer un objet “writer” qui écrit les données dans un format structuré. Chaque entrée est stockée sous la forme d’une ligne dont les en-têtes de colonne correspondent aux clés du dictionnaire de la liste nft_collections.
Importer csv de la bibliothèque standard de Python avec :
imprort csv
Étape n° 10 : Assembler le tout
C’est le code final de votre scraper OpenSea :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
Et voilà ! En moins de 100 lignes de code, vous pouvez construire un simple script de scraping OpenSea en Python.
Lancez-la avec la commande suivante dans le terminal :
python scraper.py
Après un certain temps, ce fichier nft_collections.csv apparaîtra dans le dossier du projet :
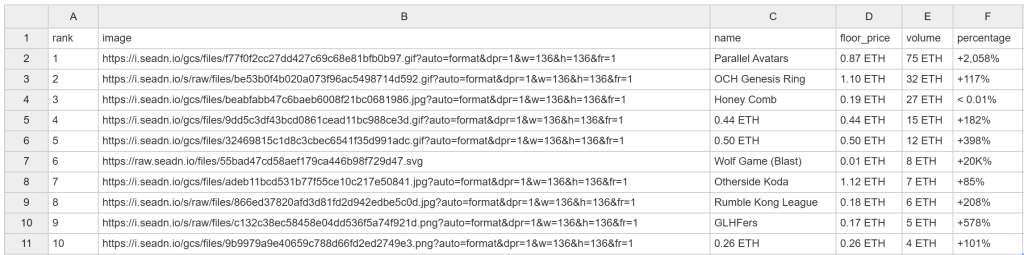
Félicitations ! Vous venez de gratter OpenSea comme prévu.
Débloquer facilement les données OpenSea
OpenSea offre bien plus qu’un simple classement des collections NFT. Il fournit également des pages détaillées pour chaque collection NFT et les articles individuels qu’elle contient. Comme les prix des NFT fluctuent fréquemment, votre script de scraping doit être exécuté automatiquement et fréquemment pour capturer des données fraîches. Cependant, la plupart des pages d’OpenSea sont protégées par des mesures anti-scraping strictes, ce qui rend la récupération des données difficile.
Comme nous l’avons observé précédemment, l’utilisation de navigateurs sans tête n’est pas une option, ce qui signifie que vous gaspillerez des ressources pour maintenir l’instance du navigateur ouverte. En outre, lorsque vous essayez d’interagir avec d’autres éléments de la page, vous risquez de rencontrer des problèmes :
Par exemple, le chargement des données peut être bloqué et les requêtes AJAX dans le navigateur peuvent être bloquées, ce qui entraîne une erreur 403 Forbidden:
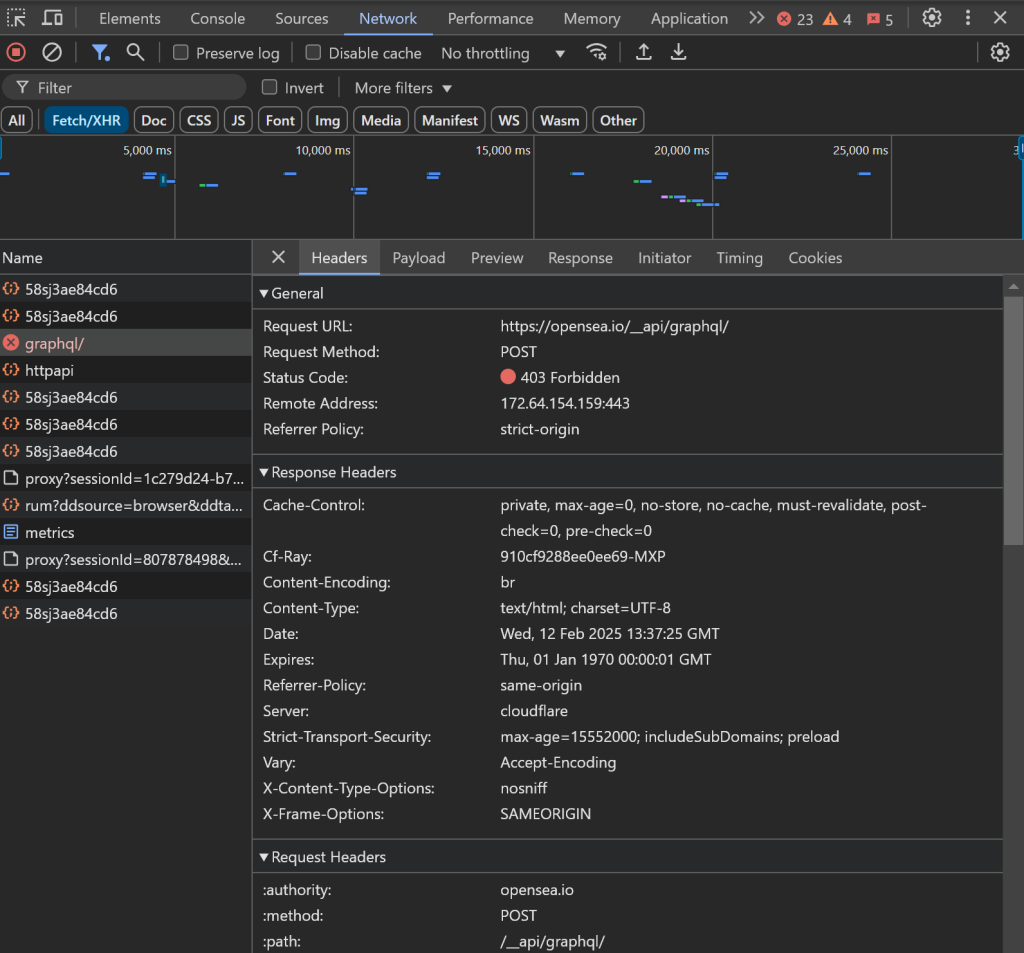
Ceci est dû aux mesures anti-bot avancées mises en place par OpenSea pour bloquer les bots de scraping.
Ces problèmes font du scraping d’OpenSea sans les bons outils une expérience frustrante. La solution ? Utilisez le scraper OpenSea dédié de Bright Data, qui vous permet de récupérer les données du site via de simples appels API ou no-code sans risque d’être bloqué !
Conclusion
Dans ce tutoriel étape par étape, vous avez appris ce qu’est un scraper OpenSea et les types de données qu’il peut collecter. Vous avez également construit un script Python pour récupérer les données NFT d’OpenSea, le tout avec moins de 100 lignes de code.
Le défi réside dans les mesures anti-bot strictes d’OpenSea, qui bloquent les interactions automatisées avec le navigateur. Contournez ces problèmes avec notre OpenSea Scraper, un outil que vous pouvez facilement intégrer avec une API ou un no-code pour récupérer les données NFT publiques, y compris le nom, la description, le token ID, le prix actuel, le dernier prix de vente, l’historique, les offres, et bien plus encore.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à utiliser nos API de scraper !




