

Dans cet article, vous apprendrez étape par étape comment extraire des données deGoogle Scholaravec Python. Avant de nous plonger dans les étapes d’extraction, nous allons passer en revue les prérequis et la configuration de notre environnement. C’est parti !
Alternative à l’extraction manuelle de Google Scholar
L’extraction manuelle de Google Scholar peut être difficile et prendre beaucoup de temps. Comme alternative, envisagez d’utiliser les jeux de données de Bright Data:
- Dataset Marketplace: accédez à des données pré-collectées prêtes à l’emploi.
- Ensembles de jeux de données personnalisés: demandez ou créez des jeux de données adaptés à vos besoins spécifiques.
L’utilisation des services de Bright Data vous fait gagner du temps et vous garantit des informations précises et à jour sans les complexités du scraping manuel. Maintenant, continuons !
Prérequis
Avant de commencer ce tutoriel, vous devez installer les éléments suivants :
- La dernière version dePython
- Un éditeur de code de votre choix, tel queVisual Studio Code
De plus, avant de commencer tout projet de scraping, vous devez vous assurer que vos scripts sont conformes au fichierrobots.txtdu site web afin de ne pas scraper des zones restreintes. Le code utilisé dans cet article est destiné uniquement à des fins d’apprentissage et doit être utilisé de manière responsable.
Configurer un environnement virtuel Python
Avant de configurer votre environnement virtuel Python, accédez à l’emplacement souhaité pour votre projet et créez un nouveau dossier nommé google_scholar_scraper:
mkdir google_scholar_scraper
cd google_scholar_scraper
Une fois que vous avez créé le dossier google_scholar_scraper, créez un environnement virtuel pour le projet à l’aide de la commande suivante :
python -m venv google_scholar_env
Pour activer votre environnement virtuel, utilisez la commande suivante sous Linux/Mac :
source google_scholar_env/bin/activate
Cependant, si vous utilisez Windows, utilisez la commande suivante :
.google_scholar_envScriptsactivate
Installez les paquets requis
Une foisvenvactivé, vous devez installerBeautiful Soupetpandas:
pip install beautifulsoup4 pandas
Beautiful Soup permet d’analyser les structures HTML des pages Google Scholar et d’extraire des éléments de données spécifiques, tels que des articles, des titres et des auteurs. pandas organise les données que vous extrayez dans un format structuré et les stocke sous forme de fichier CSV.
En plus de Beautiful Soup et pandas, vous devez également configurerSelenium. Les sites web tels que Google Scholar mettent souvent en place des mesures visant à bloquer les requêtes automatisées afin d’éviter toute surcharge. Selenium vous aide à contourner ces restrictions en automatisant les actions du navigateur et en imitant le comportement des utilisateurs.
Utilisez la commande suivante pour installer Selenium :
pip install selenium
Assurez-vous d’utiliser la dernière version de Selenium (4.6.0 au moment de la rédaction) afin de ne pas avoir à téléchargerChromeDriver.
Créer un script Python pour accéder à Google Scholar
Une fois votre environnement activé et les bibliothèques requises téléchargées, vous pouvez commencer à extraire des données de Google Scholar.
Créez un nouveau fichier Python nommé gscholar_scraper.py dans le répertoire google_scholar_scraper, puis importez les bibliothèques nécessaires :
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
Ensuite, vous allez configurerSelenium WebDriverpour contrôler le navigateur Chrome en mode headless (c’est-à-diresans interface utilisateur graphique), car cela vous permet de scraper des données sans ouvrir de fenêtre de navigateur. Ajoutez la fonction suivante au script pour initialiser Selenium WebDriver :
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
Une fois que vous avez initialisé WebDriver, vous devez ajouter une autre fonction au script qui envoie la requête de recherche à Google Scholar à l’aide du Selenium WebDriver :
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # Attendre jusqu'à 10 secondes que la page se charge
# Renvoie la source de la page (contenu HTML)
return driver.page_source
Dans ce code, driver.get(base_url + params) indique à Selenium WebDriver de naviguer vers l’URL construite. Le code configure également WebDriver pour qu’il attende jusqu’à dix secondes que tous les éléments de la page se chargent avant de procéder à l’analyse.
Analyser le contenu HTML
Une fois que vous disposez du contenu HTML de la page de résultats de recherche, vous avez besoin d’une fonction pour l’analyse et extraire les informations nécessaires.
Pour obtenir les bons sélecteurs CSS et les bons éléments pour les articles, vous devez inspecter manuellement la page Google Scholar. Utilisez les outils de développement de votre navigateur et recherchez les classes ou les identifiants uniques pour les éléments auteur, titre et extrait (par exemple gs_rt pour le titre, comme le montre l’image suivante) :
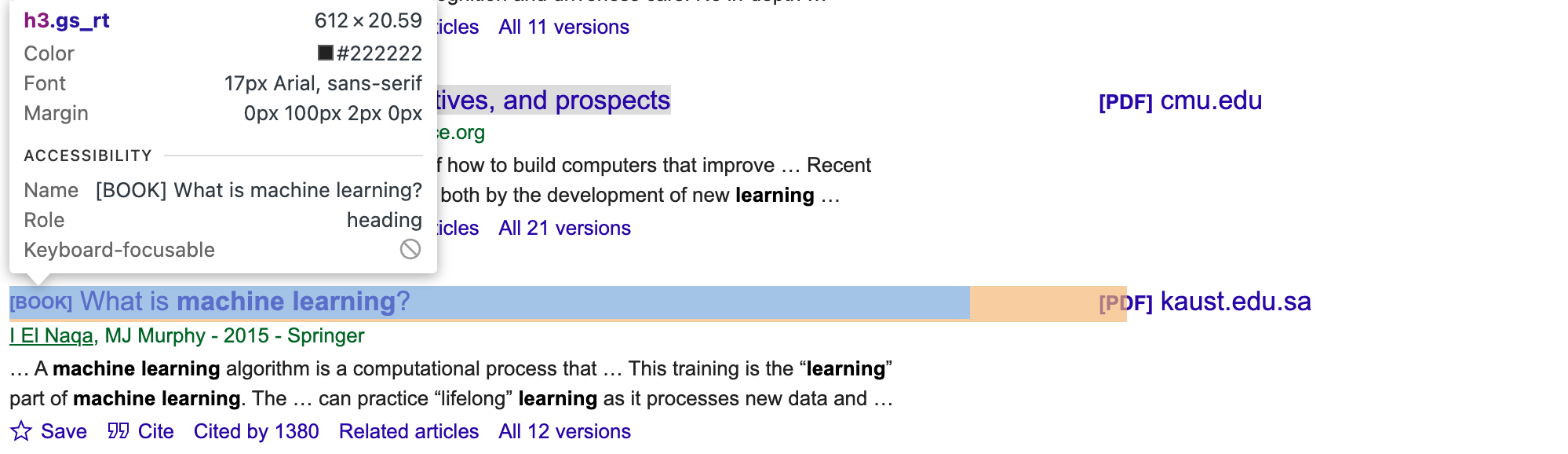
Ensuite, mettez à jour le script :
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
Cette fonction utilise BeautifulSoup pour naviguer dans la structure HTML, localiser les éléments contenant des informations sur les articles, extraire les titres, les auteurs et les extraits de chaque article, puis les combiner dans une liste de dictionnaires.
Vous remarquerez que le script mis à jour contient .select(.gs_ri), qui est le sélecteur CSS correspondant à chaque élément de résultat de recherche sur la page Google Scholar. Ensuite, le code extrait le titre, les auteurs et l’extrait (brève description) de chaque résultat à l’aide de sélecteurs plus spécifiques (.gs_rt, .gs_a et .gs_rs).
Exécutez le script
Pour tester le script de scraping, ajoutez le code _main_ suivant afin d’effectuer une recherche sur « machine learning » :
if __name__ == "__main__":
search_query = "machine learning"
# Initialiser le Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
La fonction fetch_search_results extrait le contenu HTML de la page de résultats de recherche. Ensuite, parse_results extrait les données du contenu HTML.
Le script complet se présente comme suit :
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Utiliser Selenium WebDriver pour récupérer la page
driver.get(base_url + params)
# Attendre que la page se charge
driver.implicitly_wait(10) # Attendre jusqu'à 10 secondes que la page se charge
# Renvoyer la source de la page (contenu HTML)
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Initialiser le Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Exécutez python gscholar_scraper.py pour exécuter le script. Votre résultat devrait ressembler à ceci :
% python3 scrape_gscholar.py
titre auteurs extrait
0 [PDF][PDF] Algorithmes d'apprentissage automatique - une revue B Mahesh - International Journal of Science an... … Voici un aperçu rapide de certains des plus couramment utilisés...
1 [LIVRE][B] Apprentissage automatique E Alpaydin - 2021 - books.google.com Le MIT présente une introduction concise à l'apprentissage automatique...
2 Apprentissage automatique : tendances, perspectives et pr... MI Jordan, TM Mitchell - Science, 2015 - scien... … L'apprentissage automatique aborde la question de h...
3 [LIVRE][B] Qu'est-ce que l'apprentissage automatique ? I El Naqa, MJ Murphy - 2015 - Springer … Un algorithme d'apprentissage automatique est un calcul...
4 [LIVRE][B] Apprentissage automatique
Faire de la requête de recherche un paramètre
Actuellement, la requête de recherche est codée en dur. Pour rendre le script plus flexible, vous devez le passer en tant que paramètre afin de pouvoir facilement changer le terme de recherche sans modifier le script.
Commencez par importer sys pour accéder aux arguments de ligne de commande passés au script :
import sys
Ensuite, mettez à jour le script du bloc __main__ pour utiliser la requête comme paramètre :
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Initialiser le Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Exécutez la commande suivante avec une requête de recherche spécifiée :
python gscholar_scraper.py <requête_de_recherche>
À ce stade, vous pouvez exécuter toutes sortes de requêtes de recherche via le terminal (par exemple « intelligence artificielle », « modélisation basée sur les agents » ou « apprentissage affectif »).
Activer la pagination
En général, Google Scholar n’affiche que quelques résultats de recherche par page (une dizaine), ce qui peut s’avérer insuffisant. Pour obtenir davantage de résultats, vous devez explorer plusieurs pages de recherche, ce qui implique de modifier le script afin de demander et d’analyser des pages supplémentaires.
Vous pouvez modifier la fonction fetch_search_results pour inclure un paramètre de départ qui contrôle le nombre de pages à récupérer. Le système de pagination de Google Scholar incrémente ce paramètre de dix pour chaque page suivante.
Si vous parcourez la première page d’un lien Google Scholar classique tel que https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5, le paramètre start dans l’URL détermine l’ensemble de résultats affiché. Par exemple, start=0 récupère la première page, start=10 récupère la deuxième page, start=20 récupère la troisième page, et ainsi de suite.
Mettons à jour le script pour gérer cela :
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Utiliser Selenium WebDriver pour récupérer la page
driver.get(base_url + params)
# Attendre que la page se charge
driver.implicitly_wait(10) # Attendre jusqu'à 10 secondes que la page se charge
# Renvoyer la source de la page (contenu HTML)
return driver.page_source
Ensuite, vous devez créer une fonction pour gérer le scraping de plusieurs pages :
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
for i in range(num_pages):
start = i * 10 # chaque page contient 10 résultats
html_content = fetch_search_results(driver, query, start=start)
articles = parse_results(html_content)
all_articles.extend(articles)
return all_articles
Cette fonction parcourt le nombre de pages spécifié (num_pages), analyse le contenu HTML de chaque page et rassemble tous les articles dans une seule liste.
N’oubliez pas de mettre à jour le script principal pour utiliser la nouvelle fonction :
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Usage: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Initialise le Selenium WebDriver
driver = init_selenium_driver()
try:
all_articles = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(all_articles)
df.to_csv('results.csv', index=False)
finally:
driver.quit()
Ce script comprend également une ligne (df.to_csv('results.csv', index=False)) permettant de stocker toutes les données agrégées et non pas simplement de les afficher dans le terminal.
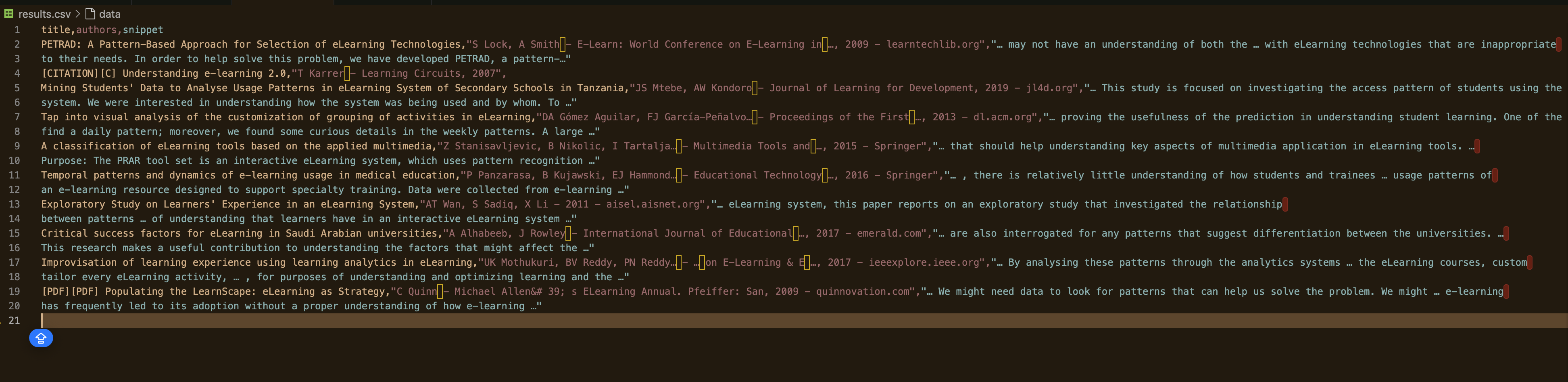
Maintenant, exécutez le script et spécifiez le nombre de pages à extraire :
python gscholar_scraper.py « understanding elearning patterns » 2
Votre résultat devrait ressembler à ceci :
Comment éviter le blocage d’IP
La plupart des sites web disposent de mesures anti-bot qui détectent les modèles de requêtes automatisées afin d’empêcher le scraping. Si un site web détecte une activité inhabituelle, votre IP peut être bloquée.
Par exemple, lors de la création de ce script, il est arrivé à un moment donné que la réponse renvoyée ne contenait que des données vides :
DataFrame vide
Colonnes : []
Index : []
Lorsque cela se produit, votre adresse IP a peut-être déjà été bloquée. Dans ce cas, vous devez trouver un moyen de contourner le problème pour éviter que votre adresse IP ne soit signalée. Voici quelques techniques pour éviter le blocage des adresses IP.
Utilisez des Proxy
Les services de Proxy vous aident à répartir les requêtes sur plusieurs adresses IP, ce qui réduit le risque de blocage. Par exemple, lorsque vous transférez une requête via un Proxy, le serveur Proxy achemine les requêtes directement vers le site web. De cette façon, le site web ne voit votre requête qu’à partir de l’adresse IP du Proxy et non de la vôtre. Si vous souhaitez savoir comment mettre en œuvre un Proxy dans votre projet, consultez cet article.
Faites tourner les adresses IP
Une autre technique permettant d’éviter les blocages d’IP consiste à configurer votre script pour qu’il alterne les adresses IP après un certain nombre de requêtes. Vous pouvez le faire manuellement ouutiliser un service proxy qui alterne automatiquement les IP pour vous. Il est ainsi plus difficile pour le site web de détecter et de bloquer votre IP, car les requêtes semblent provenir d’utilisateurs différents.
Intégrer des réseaux privés virtuels
Un réseau privé virtuel (VPN) masque votre adresse IP en acheminant votre trafic Internet via un serveur situé ailleurs. Vous pouvez configurer un VPN avec des serveurs dans différents pays afin de simuler un trafic provenant de diverses régions. Cela permet également de masquer votre adresse IP réelle et rend plus difficile pour les sites web de suivre et de bloquer vos activités en fonction de votre IP.
Conclusion
Dans cet article, nous avons exploré comment extraire des données de Google Scholar à l’aide de Python. Nous avons mis en place un environnement virtuel, installé des paquets essentiels tels que Beautiful Soup, pandas et Selenium, et écrit des scripts pour récupérer et analyser les résultats de recherche. Nous avons également mis en place une pagination pour extraire plusieurs pages et discuté des techniques permettant d’éviter le blocage des adresses IP, telles que l’utilisation de Proxy, la rotation des adresses IP et l’intégration de VPN.
Bien que l’extraction manuelle puisse être efficace, elle s’accompagne souvent de défis tels que les interdictions d’IP et la nécessité d’une maintenance continue des scripts. Pour simplifier et améliorer vos efforts de collecte de données, pensez à tirer parti des solutions de Bright Data. Notre réseau de Proxy résidentiels offre un haut niveau d’anonymat et de fiabilité, garantissant le bon déroulement de vos tâches de scraping sans interruption. De plus, nos API de Scraping web gèrent automatiquement la rotation des adresses IP et la Résolution de CAPTCHA, vous permettant ainsi de gagner du temps et d’économiser vos efforts. Pour des données prêtes à l’emploi, explorez notre vaste gamme de jeux de données adaptés à divers besoins.
Passez à la vitesse supérieure en matière de collecte de données :inscrivez-vous dès aujourd’huipour un essai gratuit avec Bright Data et découvrez des solutions de scraping efficaces et fiables pour vos projets.





