

Google Travel collecte des données agrégées sur les voyages provenant de l’ensemble du Web pour toutes sortes de catégories liées aux voyages, telles que les vols, les forfaits vacances et les chambres d’hôtel. Il est difficile de rechercher des hôtels, et l’une des plus grandes difficultés consiste à trier les annonces sponsorisées et les chambres aléatoires qui ne correspondent tout simplement pas à votre recherche.
Si vous n’êtes pas intéressé par le scraping, jetez un œil à nos jeux de données de voyage pré-construits. Avec ces jeux de données, nous nous chargeons du scraping à votre place. Si vous êtes prêt à vous lancer dans le scraping, poursuivez votre lecture !
Prérequis
Pour scraper des données de voyage, vous aurez besoin de Python et de Selenium, Requests ou AIOHTTP. Avec Selenium, nous scraperons les informations sur les hôtels directement depuis Google Travel. Avec Requests et AIOHTTP, nous utiliserons l’API Booking.com de Bright Data.
Si vous utilisez Selenium, vous devez vous assurer que Webdriver est installé. Si vous ne connaissez pas Selenium, vous pouvez consulter ce guide pour vous familiariser rapidement avec cet outil.
Installer Selenium
pip install selenium
Installer Requests
pip install requests
Installer AIOHTTP
pip install aiohttp
Une fois que vous avez installé l’outil de votre choix, vous êtes prêt à commencer.
Que faut-il extraire de Google Travel ?
Si vous choisissez de scraper Google Travel manuellement, vous devez mieux comprendre quelles données nous essayons de scraper. Tous nos résultats d’hôtels sont intégrés dans un élément c-wiz personnalisé de Google Travel.
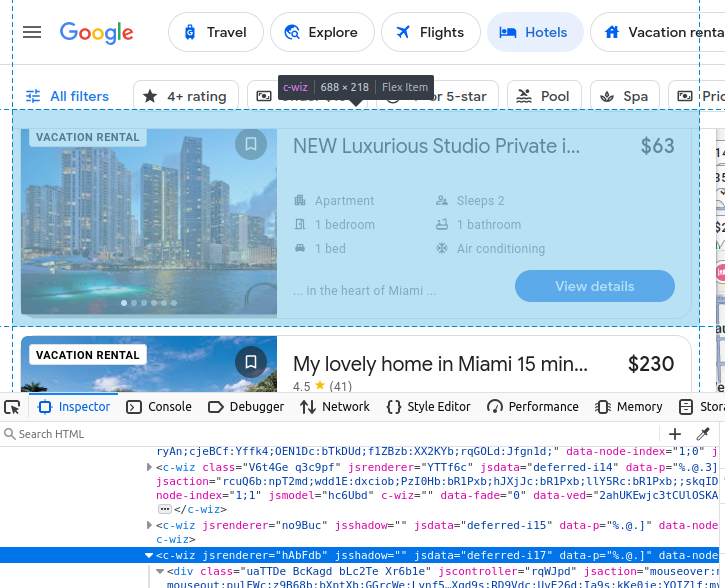
Cependant, la page contient de nombreux éléments c-wiz. Chacune de nos fiches d’hôtel contient un élément a directement dérivé d’un div et de cet élément c-wiz. Nous pouvons écrire un sélecteur CSS pour trouver toutes les balises a dérivées de ces éléments : c-wiz > div > a.
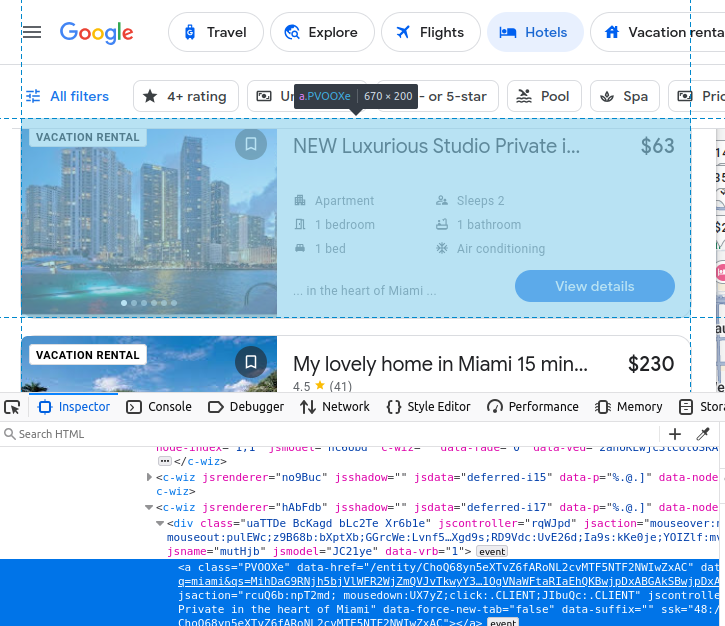
Le nom de l’annonce est intégré dans un h2.
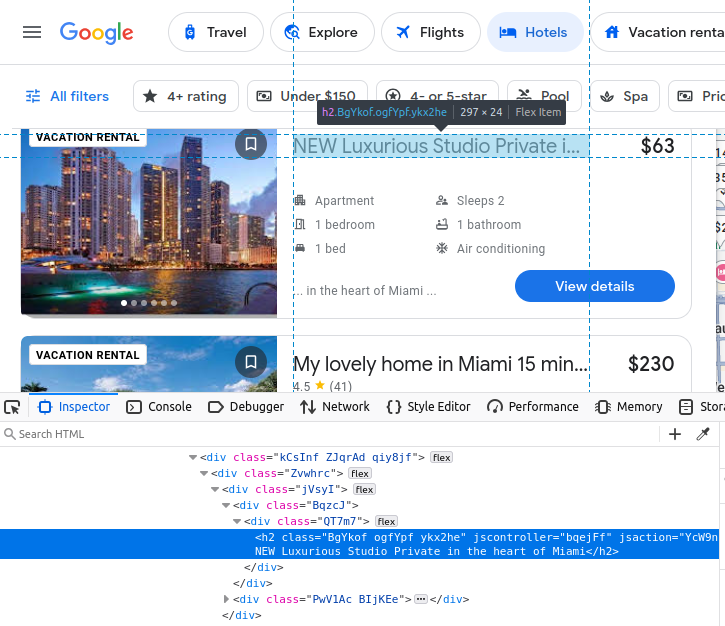
Notre prix est intégré dans un span.
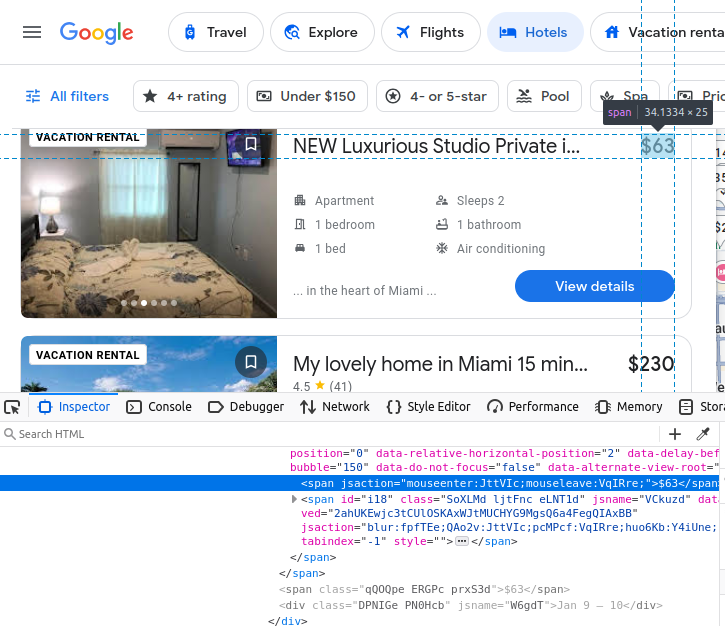
Nos équipements sont intégrés dans des éléments li (liste).
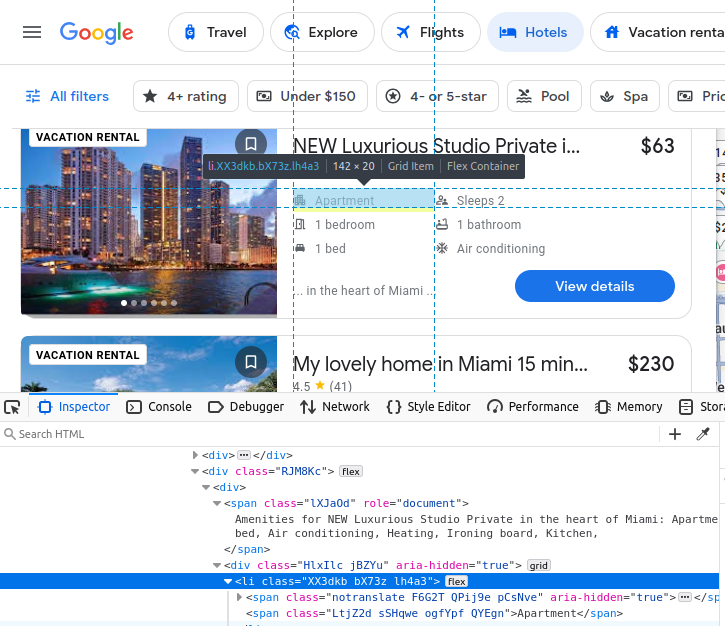
Après avoir trouvé notre fiche d’hôtel, nous pouvons en extraire toutes les données susmentionnées.
Extraire les données avec Selenium
L’extraction de ces données avec Selenium est relativement simple une fois que vous savez ce que vous recherchez. Cependant, Google Travel charge nos résultats de manière dynamique, ce qui rend le processus un peu délicat, car il repose sur des délais préconfigurés, des clics de souris et des fenêtres personnalisées. Sans la fenêtre personnalisée, vos résultats ne se chargeront pas correctement.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PAGE {page}------------------")
print("ÉLÉMENTS TROUVÉS : ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
si rating_holder :
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("bouton suivant trouvé !")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- Tout d’abord, nous créons une instance de
ChromeOptions. Nous l’utilisons pour ajouter nos arguments--headlesset--window-size=1920,1080.- Sans notre taille de fenêtre personnalisée, les résultats ne se chargent pas correctement, ce qui nous oblige à récupérer les mêmes résultats encore et encore.
- Lorsque nous lançons le navigateur, nous utilisons l’argument clé,
options=OPTIONS. Cela lance Chrome avec nos options personnalisées. ActionChains(driver)nous donne une instanceActionChains. Nous l’utilisons plus tard dans notre script pour déplacer le curseur vers le boutonSuivant, puis cliquer dessus.- Nous utilisons une boucle
whilepour contenir notre durée d’exécution. Une fois le scraping terminé, nous sortons de cette boucle. hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")nous donne tous les liens vers les hôtels sur la page. Nous trouvons leurs éléments parents à l’aide de leur xpath :hotel_card = hotel_link.find_element(By.XPATH, "..").- Ensuite, nous parcourons et extrayons toutes les données individuelles que nous avons examinées précédemment :
- url :
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - Lorsque nous recherchons le prix, la carte contient parfois des éléments supplémentaires tels que
DEALetGREAT PRICE. Pour nous assurer d’obtenir toujours le bon prix, nous extrayons les élémentsspandans un tableau. Si le tableau contient ces mots, nous prenons le deuxième élément (price_holder[1].text) au lieu du premier (price_holder[0].text). - Nous utilisons également la méthode
find_elements()lorsque nous recherchons la note. Si aucune note n’est présente, nous lui attribuons une valeur par défautn/a. hotel_card.find_elements(By.CSS_SELECTOR, « li »)nous donne nos détenteurs d’équipements. Nous les extrayons chacun à l’aide de leur attributtext.
- url :
- Nous continuons cette boucle jusqu’à ce que nous ayons récupéré toutes les pages souhaitées. Une fois que nous avons obtenu nos données, nous définissons
donesurTrueet sortons de la boucle. - Nous fermons le navigateur de scraping et utilisons
json.dump()pour enregistrer toutes nos données récupérées dans un fichier JSON.
Lors du scraping des hôtels sur Google Travel, nous n’avons rencontré aucun problème de blocage, mais tout est possible. Si vous rencontrez des problèmes, nous proposons à la fois des Proxys résidentiels et un Navigateur de scraping intégré pour vous aider à surmonter tout obstacle.
Le scraping de ces résultats avec Selenium est à la fois fastidieux et délicat, mais tout à fait réalisable.
Extrayez les données avec l’API Travel de Bright Data
Parfois, vous ne voulez pas dépendre d’un Scraper ou passer toute la journée à gérer des sélecteurs et des localisateurs. Pas de problème ! Nous proposons plusieurs types de données de voyage. Vous pouvez même extraire des données sur les hôtels à l’aide de notre API Booking.com. Il vous suffit d’effectuer quelques requêtes HTTP. Nous nous occupons du reste pour que vous puissiez vaquer à vos occupations.
Requêtes
Le code ci-dessous vous permet de configurer l’API Booking.com. Il vous suffit d’entrer votre clé API, votre lieu de voyage, votre date d’arrivée et votre date de départ. Tout d’abord, il envoie une requête à l’API pour générer les données. Ensuite, il vérifie les données toutes les 10 secondes jusqu’à ce que notre rapport soit prêt. Une fois que nous avons reçu nos données, nous les enregistrons dans un fichier JSON.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
#booking.com dataset
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Demande réussie. Réponse :")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Erreur : {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#créer l'URL de l'instantané
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Interrogation de l'instantané pour l'ID : {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("L'instantané est prêt. Téléchargement en cours...")
snapshot_data = response.json()
#écrire l'instantané dans un nouveau fichier json
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantané enregistré dans {output_file}")
break
elif response.status_code == 202:
print("L'instantané n'est pas encore prêt. Nouvelle tentative dans 10 secondes...")
else:
print(f"Erreur : {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "votre-clé-api-bright-data"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()prend votreAPI_KEY,LOCATIONetDATES. Il effectue ensuite une requête pour les données et renvoie lesnapshot_id.- Le
snapshot_idest très important. Nous en avons besoin pour récupérer l’instantané. - Une fois le
snapshot_idgénéré,poll_and_retrieve_snapshot()vérifie toutes les 10 secondes si les données sont prêtes. - Une fois les données prêtes, nous utilisons
json.dump()pour les enregistrer dans un fichier JSON.
Lorsque vous exécutez le code, vous devriez voir quelque chose de similaire à ceci dans votre terminal.
Demande réussie. Réponse :
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Interrogation du snapshot pour l'ID : s_m5moyblm1wikx4ntot...
Le snapshot n'est pas encore prêt. Réessai dans 10 secondes...
L'instantané n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané est prêt. Téléchargement...
Instantané enregistré dans snapshot-data.json
Vous obtiendrez alors un fichier JSON rempli d’objets comme celui-ci.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
« url » : « https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children= »,
« location » : « Miami »,
« check_in » : « 2026-02-01T00:00:00.000Z »,
« check_out » : « 2026-02-02T00:00:00.000Z »,
« adults » : 2,
« children » : null,
« rooms » : 1,
« id » : « 55989 »,
« title » : « Ramada Plaza by Wyndham Marco Polo Beach Resort »,
« address » : « 19201 Collins Avenue »,
« city » : « Sunny Isles Beach (Floride) »,
« review_score » : 6,2,
« review_count » : « 1788 »,
« image » : « https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
« final_price » : 217,
« original_price » : 217,
« currency » : « USD »,
« tax_description » : null,
« nb_livingrooms » : 0,
« nb_kitchens » : 0,
« nb_bedrooms » : 0,
« nb_all_beds » : 2,
« full_location » : {
« description » : « Il s'agit de la distance à vol d'oiseau sur la carte. La distance réelle peut varier. »,
« main_distance » : « 11,4 miles du centre-ville »,
« display_location » : « Miami Beach »,
« beach_distance » : « En bord de mer »,
« nearby_beach_names » : []
},
« no_prepayment » : false,
« free_cancellation » : true,
« property_sustainability » : {
« is_sustainable » : false,
« level_id » : « L0 »,
« facilities » : [
« 436 »,
« 490 »,
« 492 »,
« 496 »,
« 506 »
]
},
« timestamp » : « 2026-01-07T16:43:24.954Z »
},
AIOHTTP
Avec AIOHTTP, nous pouvons accélérer considérablement ce processus. Nous pouvons en effet déclencher, interroger et télécharger plusieurs Jeux de données simultanément. Le code ci-dessous s’appuie sur nos concepts tirés de l’exemple Requests ci-dessus, mais utilise à la place la puissante fonction aiohttp.ClientSession() pour effectuer plusieurs requêtes de manière asynchrone.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
« url » : « https://www.booking.com »,
« location » : location,
« check_in » : dates[« check_in »],
« check_out » : dates[« check_out »],
« adults » : 2,
« rooms » : 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"Demande réussie pour l'emplacement : {location}. Réponse :")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"Erreur pour l'emplacement : {location}. Statut : {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file) :
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Interrogation de l'instantané pour l'ID : {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"Instantané pour {output_file} prêt. Téléchargement en cours...")
snapshot_data = await response.json()
# Enregistrer les données de l'instantané dans un fichier
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantané enregistré dans {output_file}")
break
elif response.status == 202:
print(f"L'instantané pour {output_file} n'est pas encore prêt. Réessayer dans 10 secondes...")
else:
print(f"Erreur lors de l'interrogation de l'instantané pour {output_file}. Statut : {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# Traiter tous les emplacements en parallèle
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
- Les fonctions
get_bookings()etpoll_and_retrieve_snapshot()utilisent désormais notre objetaiohttp.ClientSessionpour créer des requêtes asynchrones vers le serveur. process_location()est utilisé pour traiter toutes les données d’un emplacement.main()nous permet d’appelerprocess_location()simultanément sur tous les emplacements.
Avec AIOHTTP, vous pouvez déclencher, interroger et télécharger plusieurs Jeux de données en même temps. Ainsi, vous n’avez pas besoin d’attendre inutilement la fin d’un rapport avant de générer le suivant.
Jetez un œil au résultat. Comme vous pouvez le voir, nous déclenchons les deux rapports. Ensuite, nous téléchargeons un rapport tout en attendant l’autre. À grande échelle, cela vous fera gagner un temps considérable.
Demande réussie pour l'emplacement : Miami. Réponse :
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Demande réussie pour l'emplacement : Key West. Réponse :
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Interrogation de l'instantané pour l'ID : s_m5mtmtv62hwhlpyazw...
Interrogation de l'instantané pour l'ID : s_m5mtmtv72gkkgxvdid...
L'instantané pour snapshot-miami.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané pour snapshot-miami.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
L'instantané pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Le snapshot pour snapshot-miami.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Le snapshot pour snapshot-miami.json est prêt. Téléchargement en cours...
Le snapshot pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Snapshot enregistré dans snapshot-miami.json.
Le snapshot pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Le snapshot pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Le snapshot pour snapshot-key_west.json n'est pas encore prêt. Nouvelle tentative dans 10 secondes...
Le snapshot pour snapshot-key_west.json est prêt. Téléchargement en cours...
Snapshot enregistré dans snapshot-key_west.json
Solutions alternatives de Bright Data
Au-delà de nos puissantes API Web Scraper, Bright Data fournit des jeux de données prêts à l’emploi adaptés à divers besoins. Parmi nos jeux de données de voyage les plus recherchés, on trouve :
- Jeux de données sur les hôtels
- Jeux de données Expedia
- Jeux de données sur le tourisme
- Jeux de données Booking.com
- Jeux de données TripAdvisor
Avec Bright Data, vous pouvez choisir entre des jeux de données personnalisés entièrement gérés ou autogérés, ce qui vous permet d’extraire des données de n’importe quel site web public et de les personnaliser selon vos spécifications exactes.
Conclusion
En parcourant le web, vous pouvez trouver une mine d’informations sur les hôtels grâce à Google Travel. Que vous préfériez le modèle DIY avec Selenium ou que vous souhaitiez simplement obtenir des résultats rapides et pratiques avec l’API Booking.com, vous pouvez récolter ces données pour obtenir des informations vraiment précieuses. Que vous souhaitiez analyser l’historique des prix ou simplement réserver une chambre de manière efficace, vous venez d’ajouter une nouvelle compétence utile à votre arsenal technologique !
Inscrivez-vous dès maintenant pour essayer gratuitement les produits Bright Data.





