

Dans ce tutoriel pratique, vous apprendrez à extraire des données de Glassdoor à l’aide de Playwright Python. Vous découvrirez également les techniques anti-scraping utilisées par Glassdoor et comment Bright Data peut vous aider. Vous découvrirez également la solution Bright Data qui accélère considérablement l’extraction de données de Glassdoor.
Évitez le scraping, obtenez les données
Vous souhaitez éviter le processus d’extraction et accéder directement aux données ? Consultez notre ensemble de données Glassdoor.
L’ensemble de données Glassdoor offre un aperçu complet des entreprises avec des avis et des FAQ qui fournissent des informations sur les emplois et les entreprises. Vous pouvez utiliser notre ensemble de données Glassdoor pour trouver les tendances du marché et des informations commerciales sur les entreprises, ainsi que la façon dont les employés actuels et anciens les perçoivent et les évaluent. En fonction de vos besoins, vous avez la possibilité d’acheter l’ensemble de données complet ou un sous-ensemble personnalisé.
Les jeux de données sont disponibles dans des formats tels que JSON, NDJSON, JSON Lines, CSV ou Parquet, et peuvent également être compressés en fichiers .gz.
Est-il légal de scraper Glassdoor ?
Oui, il est légal de scraper des données sur Glassdoor, mais cela doit être fait de manière éthique et conformément aux conditions d’utilisation, au fichier robots.txt et aux politiques de confidentialité de Glassdoor. L’un des plus grands mythes est que le scraping de données publiques telles que les avis sur les entreprises et les offres d’emploi n’est pas légal. Cependant, cela n’est pas vrai. Cela doit être fait dans les limites légales et éthiques.
Comment extraire les données de Glassdoor
Glassdoor utilise JavaScript pour afficher son contenu, ce qui peut rendre l’extraction plus complexe. Pour y parvenir, vous avez besoin d’un outil capable d’exécuter JavaScript et d’interagir avec la page web comme un navigateur. Parmi les choix les plus populaires, on trouve Playwright, Puppeteer et Selenium. Pour ce tutoriel, nous utiliserons Playwright Python.
Commençons à créer le scraper Glassdoor à partir de zéro ! Que vous soyez novice ou déjà familiarisé avec Playwright, ce tutoriel vous aidera à créer un scraper web à l’aide de Playwright Python.
Configuration de l’environnement de travail
Avant de commencer, assurez-vous que les éléments suivants sont installés sur votre ordinateur :
- site officiel
- Visual Studio Code
Ensuite, ouvrez un terminal et créez un nouveau dossier pour votre projet Python, puis accédez-y :
mkdir glassdoor-scraper
cd glassdoor-scraper
Créez et activez un environnement virtuel :
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Installez Playwright:
pip install playwright
Ensuite, installez les binaires du navigateur :
playwright install
Cette installation peut prendre un certain temps, veuillez donc patienter.
Voici à quoi ressemble le processus d’installation complet :
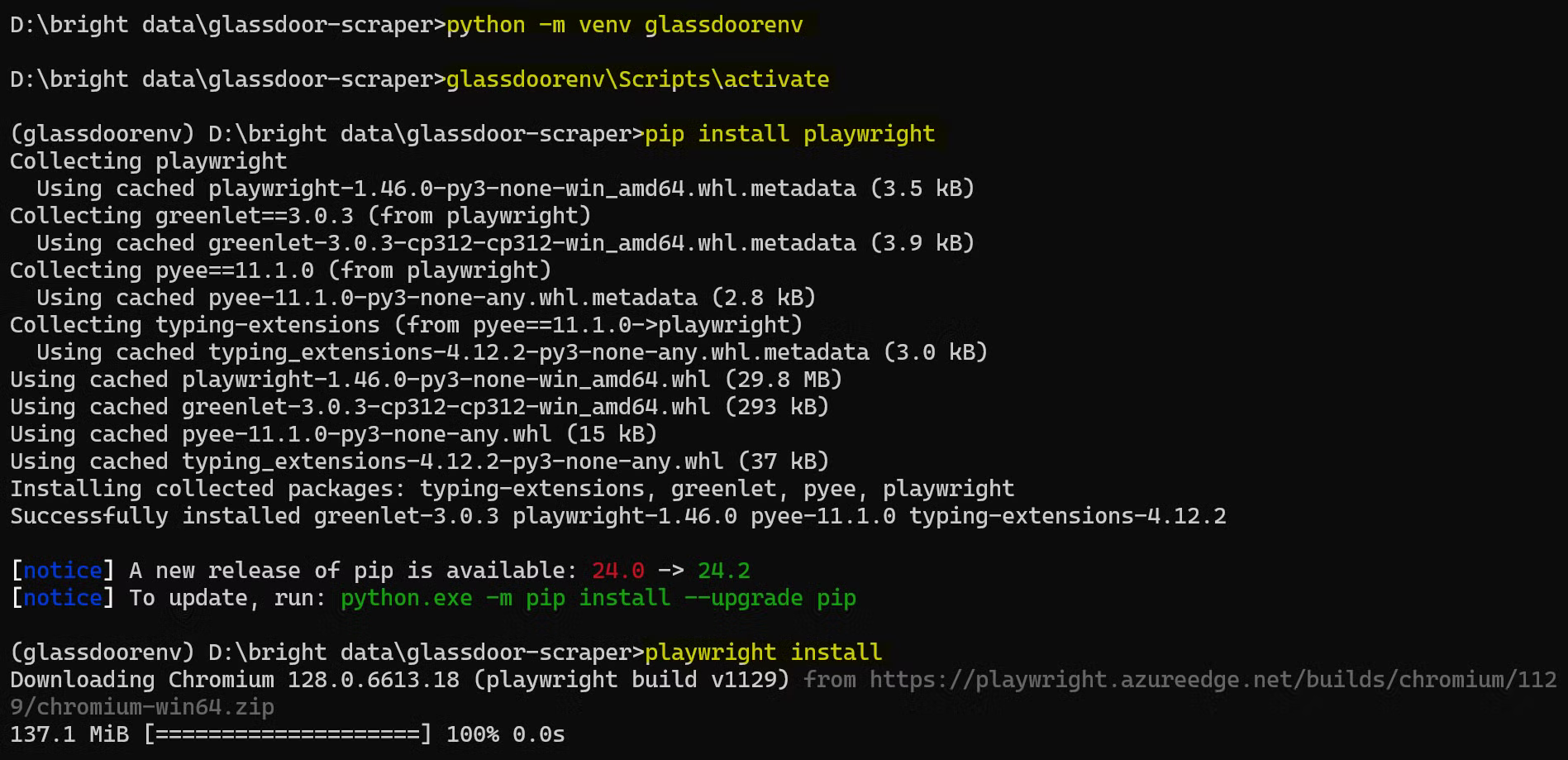
Vous êtes maintenant prêt à commencer à écrire votre code de scraper Glassdoor !
Comprendre la structure du site web Glassdoor
Avant de commencer à scraper Glassdoor, il est important de comprendre sa structure. Pour ce tutoriel, nous nous concentrerons sur le scraping d’entreprises situées dans un endroit spécifique et proposant des postes particuliers.
Par exemple, si vous souhaitez trouver des entreprises à New York proposant des postes dans le domaine de l’apprentissage automatique et dont la note globale est supérieure à 3,5, vous devrez appliquer les filtres appropriés à votre recherche.
Jetez un œil à la page des entreprises sur Glassdoor:
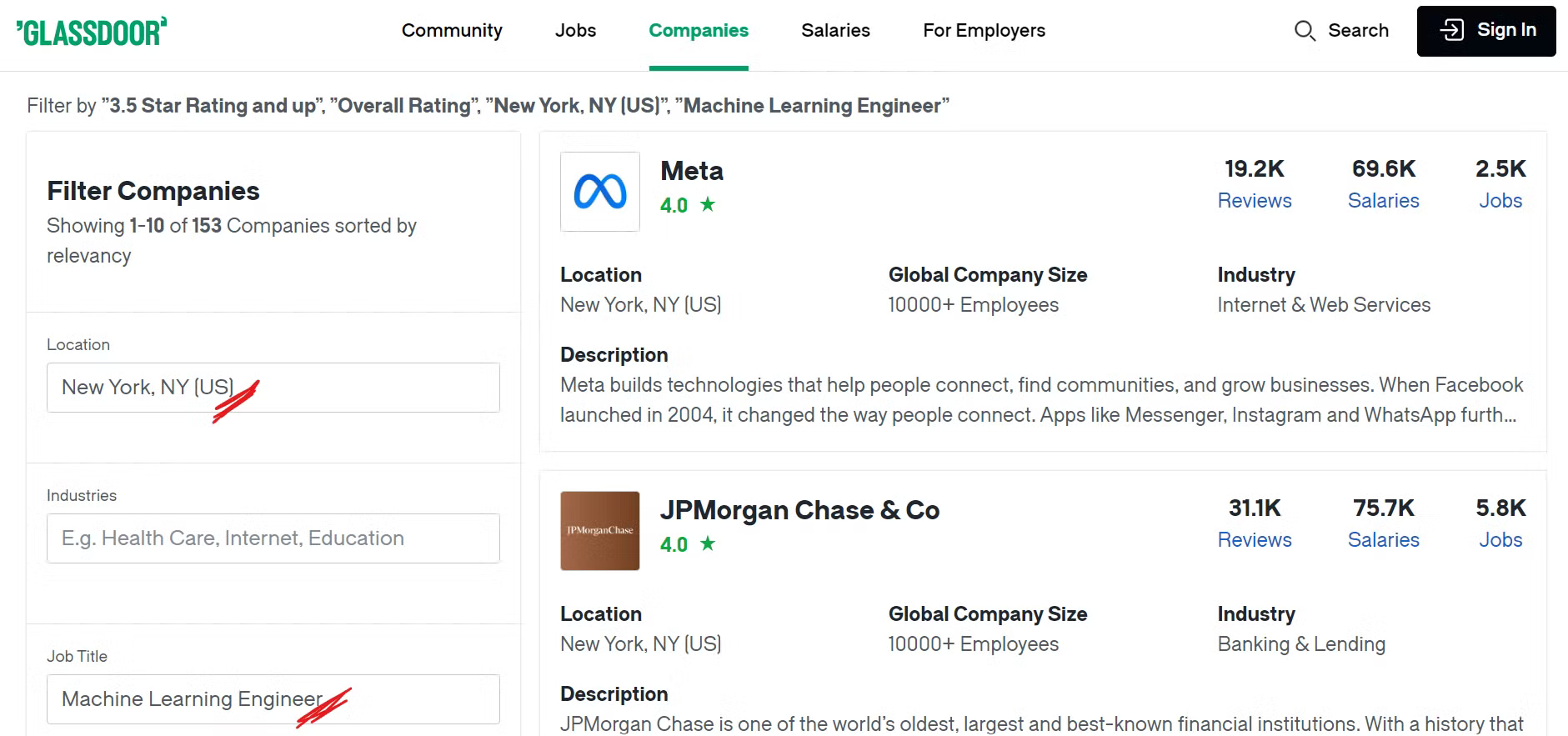
Vous pouvez désormais voir de nombreuses entreprises répertoriées en appliquant les filtres souhaités, et vous vous demandez peut-être quelles données spécifiques nous allons extraire. Voyons cela maintenant !
Identification des points de données clés
Pour collecter efficacement les données de Glassdoor, vous devez identifier le contenu que vous souhaitez extraire.
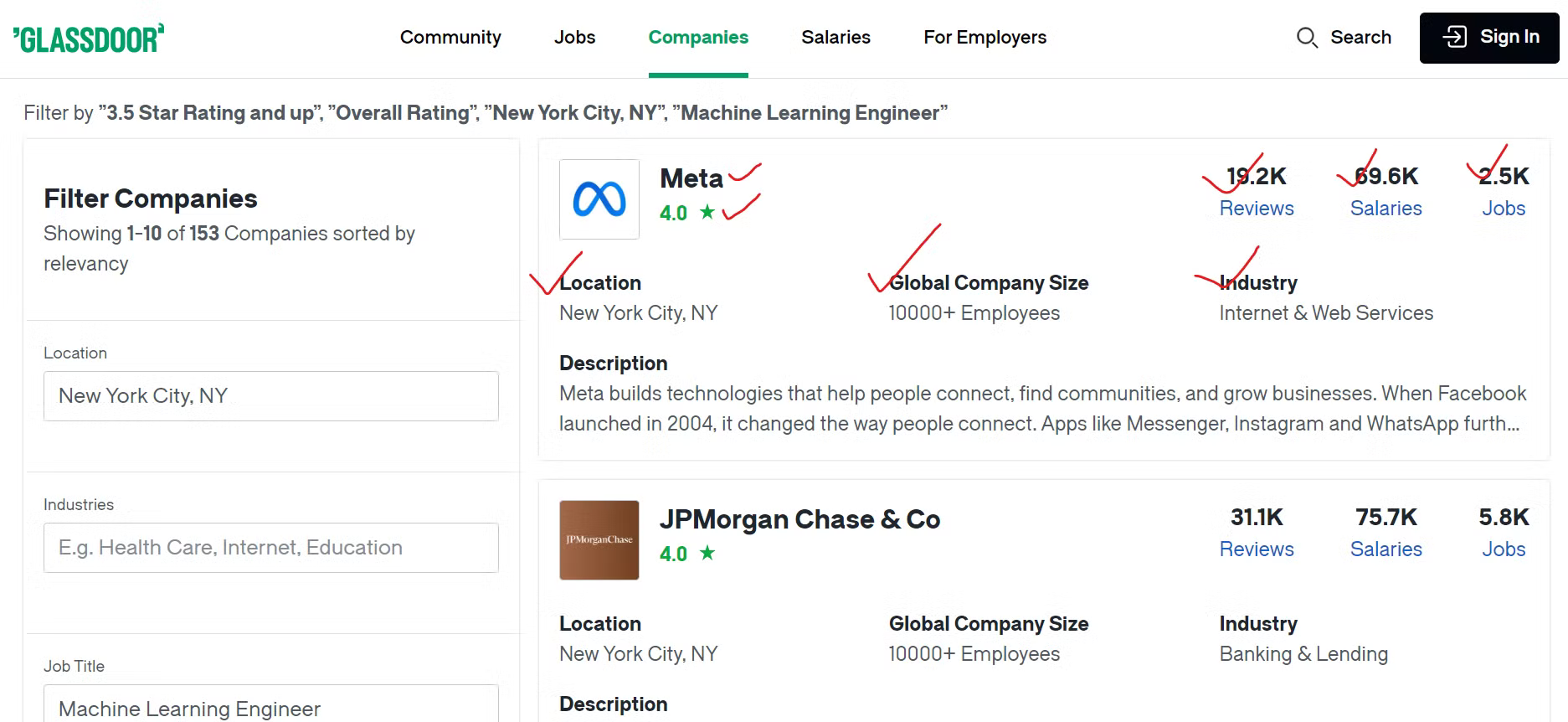
Nous extrairons diverses informations sur chaque entreprise, telles que son nom, un lien vers ses offres d’emploi et le nombre total de postes vacants. De plus, nous extrairons le nombre d’avis d’employés, le nombre de salaires déclarés et le secteur d’activité de l’entreprise. Nous extrairons également la localisation géographique de l’entreprise et le nombre total d’employés dans le monde.
Création d’un scraper Glassdoor
Maintenant que vous avez identifié les données que vous souhaitez extraire, il est temps de créer le scraper à l’aide de Playwright Python.
Commencez par inspecter le site web Glassdoor afin de localiser les éléments correspondant au nom de l’entreprise et aux évaluations, comme indiqué dans l’image ci-dessous :
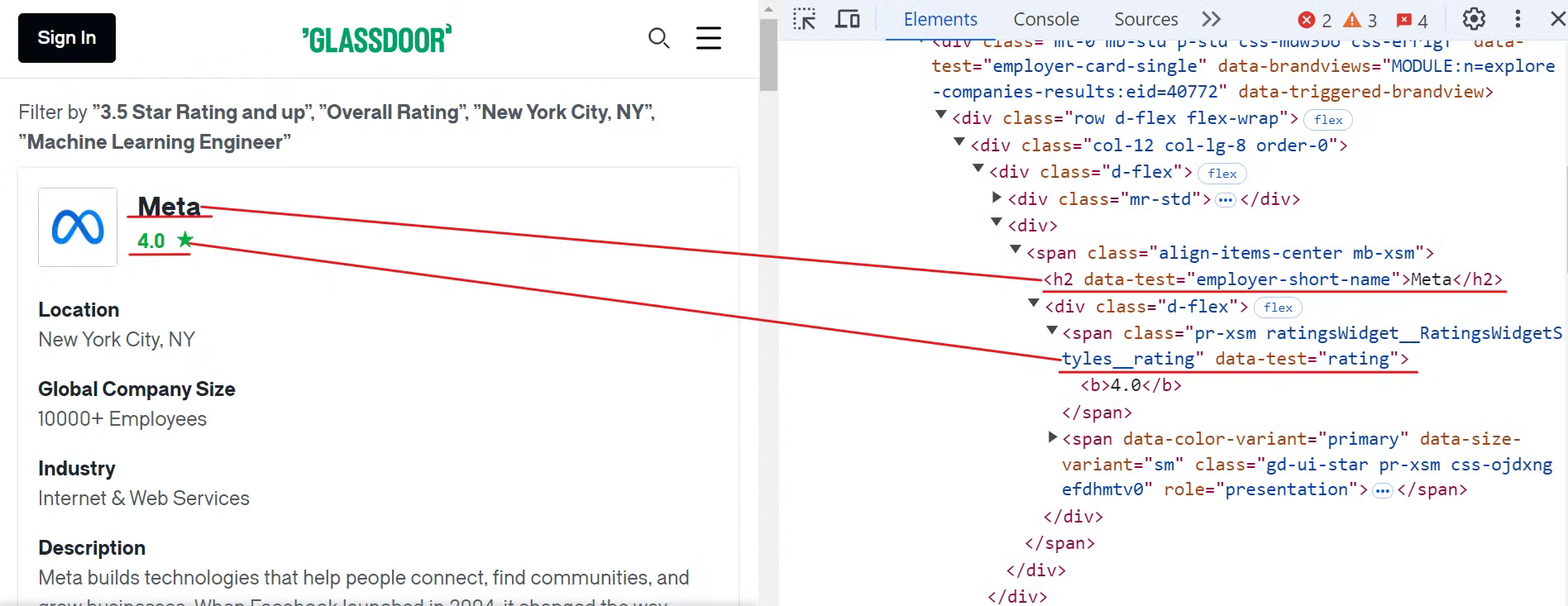
Pour extraire ces données, vous pouvez utiliser les sélecteurs CSS suivants :
[data-test="employer-short-name"]
[data-test="rating"]
De la même manière, vous pouvez extraire d’autres données pertinentes à l’aide de sélecteurs CSS simples, comme indiqué dans l’image ci-dessous :
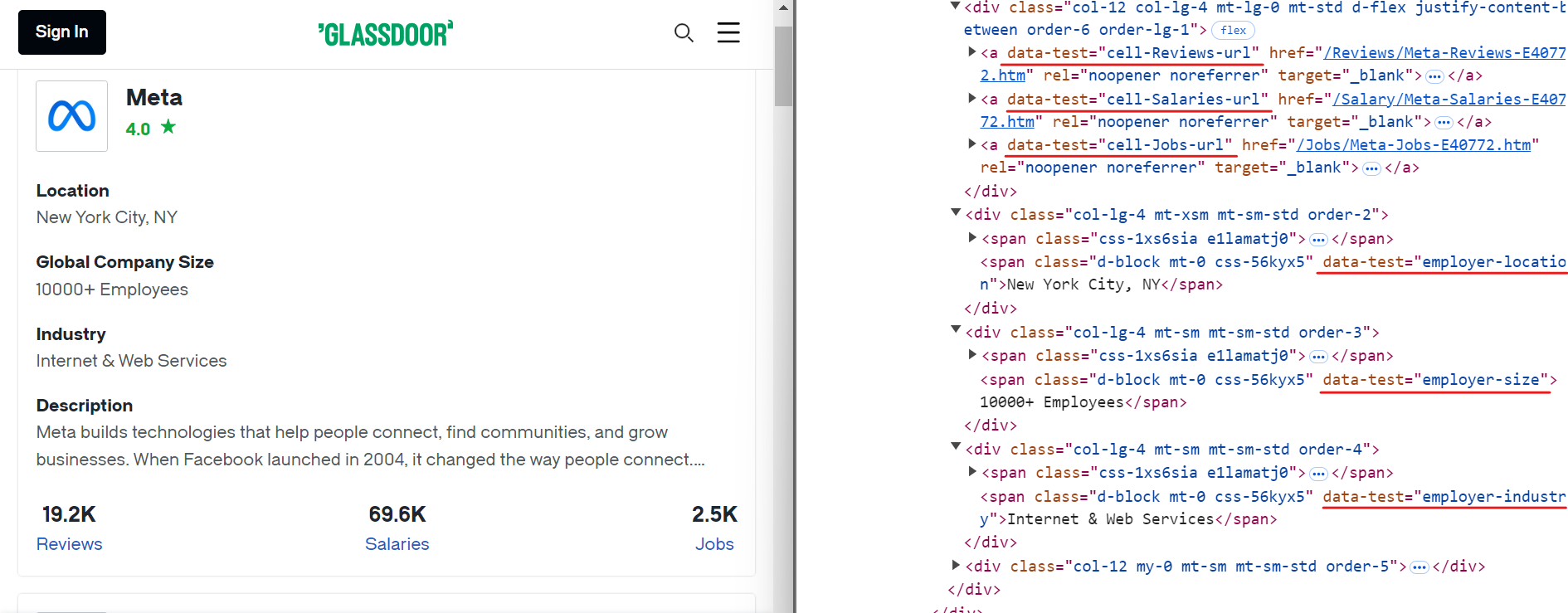
Voici les sélecteurs CSS que vous pouvez utiliser pour extraire des données supplémentaires :
[data-test="employer-location"] /* Localisation géographique de l'entreprise */
[data-test="employer-size"] /* Nombre d'employés dans le monde */
[data-test="employer-industry"] /* Secteur d'activité de l'entreprise */
[data-test="cell-Jobs-url"] /* Lien vers les offres d'emploi de l'entreprise */
[data-test="cell-Jobs"] h3 /* Nombre total d'offres d'emploi */
[data-test="cell-Reviews"] h3 /* Nombre d'avis d'employés */
[data-test="cell-Salaries"] h3 /* Nombre de salaires déclarés */
Ensuite, créez un nouveau fichier nommé glassdoor.py et ajoutez-y le code suivant :
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Lancer une instance du navigateur Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Définir l'URL de base et les paramètres de requête pour la recherche Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construire l'URL complète avec les paramètres de requête et y naviguer
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialiser un compteur pour les enregistrements extraits
record_count = 0
# Localiser toutes les fiches d'entreprise sur la page et les parcourir pour extraire les données
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraire les données pertinentes de chaque fiche d'entreprise
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construire l'URL pour les offres d'emploi
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extraire des données supplémentaires sur les offres d'emploi, les avis et les salaires
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Imprimer les données extraites
print({
"Entreprise" : company_name,
"Note" : rating,
"URL des emplois" : jobs_url_path,
« Nombre d'emplois » : jobs_count,
« Nombre d'avis » : reviews_count,
« Nombre de salaires » : salaries_count,
« Secteur » : industry,
« Emplacement » : location,
« Taille mondiale de l'entreprise » : global_company_size,
})
record_count += 1
except Exception as e:
print(f"Erreur lors de l'extraction des données de l'entreprise : {e}")
print(f"Nombre total d'enregistrements extraits : {record_count}")
# Fermer le navigateur
await browser.close()
# Point d'entrée du script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Ce code configure un script Playwright pour extraire les données de l’entreprise en appliquant des filtres spécifiques. Par exemple, il applique des filtres tels que l’emplacement (New York, NY), la note (3,5+) et le titre du poste (ingénieur en apprentissage automatique).
Il lance ensuite une instance du navigateur Chromium, navigue vers l’URL Glassdoor qui inclut ces filtres et extrait les données de chaque fiche d’entreprise sur la page. Après avoir collecté les données, il imprime les informations extraites sur la console.
Et voici le résultat :

Bravo !
Il reste toutefois un problème. Actuellement, le code n’extrait que 10 enregistrements, alors qu’il y en a environ 150 disponibles sur la page. Cela montre que le script ne capture que les données de la première page. Pour extraire davantage d’enregistrements, nous devons mettre en place une gestion de la pagination, qui sera abordée dans la section suivante.
Gestion de la pagination
Chaque page de Glassdoor affiche les données d’environ 10 entreprises. Pour extraire tous les enregistrements disponibles, vous devez gérer la pagination en naviguant sur chaque page jusqu’à la fin. Pour gérer la pagination, vous devez localiser le bouton « Suivant », vérifier s’il est activé et cliquer dessus pour passer à la page suivante. Répétez ce processus jusqu’à ce qu’il n’y ait plus de pages disponibles.
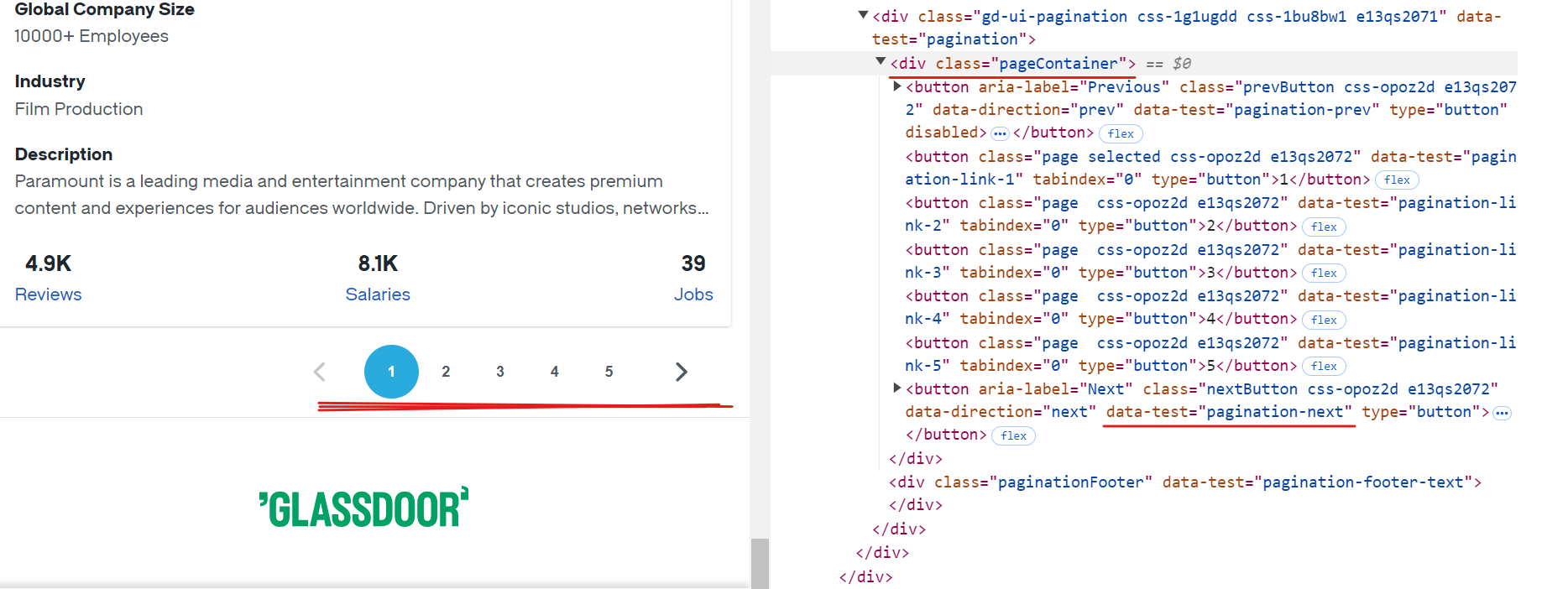
Le sélecteur CSS pour le bouton « Suivant » est [data-test="pagination-next"], qui se trouve dans une balise <div> avec la classe pageContainer, comme le montre l’image ci-dessus.
Voici un extrait de code montrant comment gérer la pagination :
while True:
# S'assurer que le conteneur de pagination est visible avant de continuer
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifier le bouton « Suivant » sur la page
next_button = page.locator('[data-test="pagination-next"]')
# Déterminez si le bouton « suivant » est désactivé, indiquant qu'il n'y a plus de pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Arrêtez s'il n'y a plus de pages à parcourir
# Naviguer vers la page suivante
await next_button.click()
await asyncio.sleep(3) # Laisser le temps à la page de se charger complètement
Voici le code modifié :
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Lancer une instance du navigateur Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Définir l'URL de base et les paramètres de requête pour la recherche Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construire l'URL complète avec les paramètres de requête et y accéder
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialiser un compteur pour les enregistrements extraits
record_count = 0
while True:
# Localiser toutes les fiches d'entreprise sur la page et les parcourir pour extraire les données
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraire les données pertinentes de chaque fiche d'entreprise
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construire l'URL pour les offres d'emploi
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extraire des données supplémentaires sur les offres d'emploi, les avis et les salaires
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Imprimer les données extraites
print({
"Entreprise" : company_name,
"Note" : rating,
"URL des emplois" : jobs_url_path,
« Nombre d'emplois » : jobs_count,
« Nombre d'avis » : reviews_count,
« Nombre de salaires » : salaries_count,
« Secteur » : industry,
« Emplacement » : location,
« Taille mondiale de l'entreprise » : global_company_size,
})
record_count += 1
except Exception as e:
print(f"Erreur lors de l'extraction des données de l'entreprise : {e}")
try:
# S'assurer que le conteneur de pagination est visible avant de continuer
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifier le bouton « Suivant » sur la page
next_button = page.locator('[data-test="pagination-next"]')
# Déterminez si le bouton « suivant » est désactivé, n'affichant aucune autre page
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Arrêtez s'il n'y a plus de pages à parcourir
# Naviguer vers la page suivante
await next_button.click()
await asyncio.sleep(3) # Laisser le temps à la page de se charger complètement
except Exception as e:
print(f"Erreur lors de la navigation vers la page suivante : {e}")
break # Quitter la boucle en cas d'erreur de navigation
print(f"Nombre total d'enregistrements extraits : {record_count}")
# Fermer le navigateur
await browser.close()
# Point d'entrée du script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Le résultat est :

Super ! Vous pouvez désormais extraire les données de toutes les pages disponibles, et pas seulement de la première.
Enregistrer les données au format CSV
Maintenant que vous avez extrait les données, enregistrons-les dans un fichier CSV pour les traiter ultérieurement. Pour ce faire, vous pouvez utiliser le module Python csv. Vous trouverez ci-dessous le code mis à jour qui enregistre les données extraites dans un fichier CSV :
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Lancer une instance du navigateur Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Définir l'URL de base et les paramètres de requête pour la recherche Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construire l'URL complète avec les paramètres de requête et y accéder
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Ouvrir le fichier CSV pour y écrire les données extraites
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Entreprise", "URL des offres d'emploi", "Nombre d'offres d'emploi", "Nombre d'avis", "Nombre de salaires",
"Secteur d'activité", "Localisation", "Taille de l'entreprise à l'échelle mondiale", "Note"
])
# Initialiser un compteur pour les enregistrements extraits
record_count = 0
while True:
# Localiser toutes les fiches d'entreprise sur la page et les parcourir pour extraire les données
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraire les données pertinentes de chaque fiche d'entreprise
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construire l'URL pour les offres d'emploi
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extraire des données supplémentaires sur les offres d'emploi, les avis et les salaires
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Écrire les données extraites dans le fichier CSV
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Erreur lors de l'extraction des données de l'entreprise : {e}")
try:
# S'assurer que le conteneur de pagination est visible avant de continuer
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifier le bouton « suivant » sur la page
next_button = page.locator('[data-test="pagination-next"]')
# Déterminez si le bouton « suivant » est désactivé, indiquant qu'il n'y a plus de pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Arrêtez s'il n'y a plus de pages à parcourir
# Naviguer vers la page suivante
await next_button.click()
await asyncio.sleep(3) # Laisser le temps à la page de se charger complètement
except Exception as e:
print(f"Erreur lors de la navigation vers la page suivante : {e}")
break # Quitter la boucle en cas d'erreur de navigation
print(f"Nombre total d'enregistrements extraits : {record_count}")
# Fermer le navigateur
await browser.close()
# Point d'entrée du script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Ce code enregistre désormais les données extraites dans un fichier CSV nommé glassdoor_data.csv.
Le résultat est le suivant :
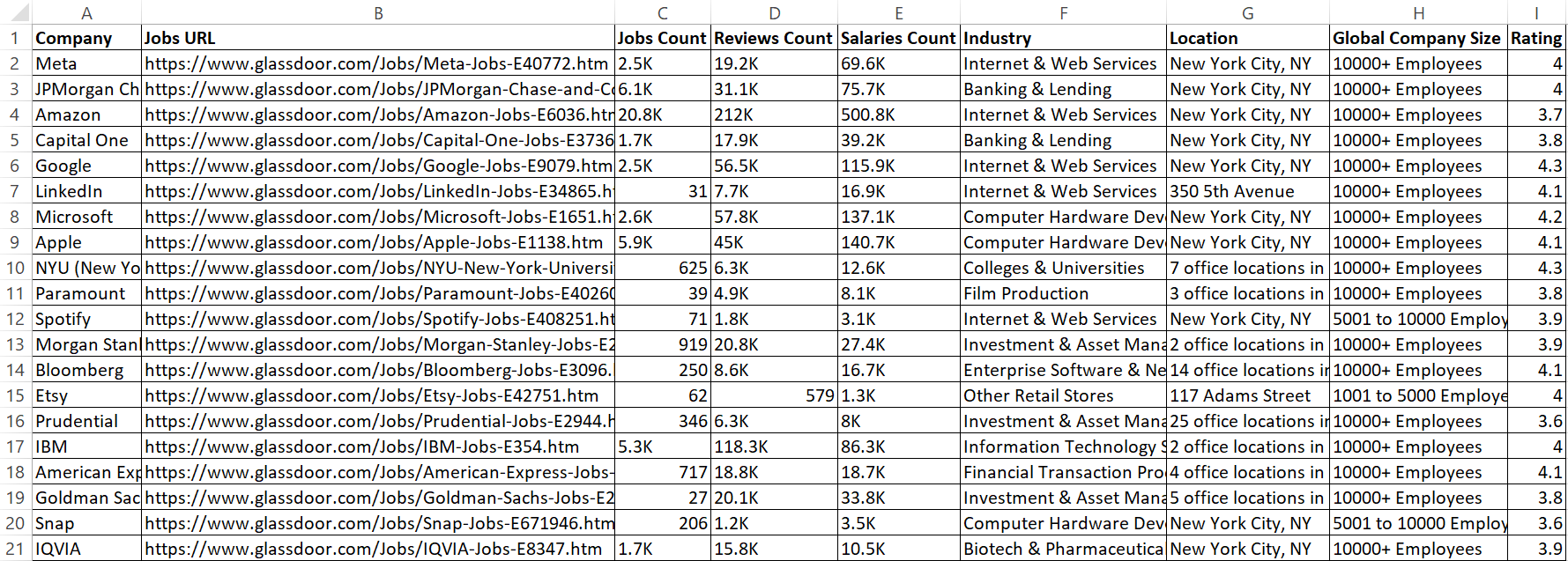
Génial ! Les données sont désormais plus claires et plus faciles à lire.
Techniques anti-scraping utilisées par Glassdoor
Glassdoor surveille le nombre de requêtes provenant d’une adresse IP au cours d’une période donnée. Si les requêtes dépassent une limite définie, Glassdoor peut bloquer temporairement ou définitivement l’adresse IP. De plus, si une activité inhabituelle est détectée, Glassdoor peut présenter un défi CAPTCHA, comme je l’ai expérimenté.
La méthode décrite ci-dessus convient pour scraper quelques centaines d’entreprises. Cependant, si vous devez en scraper des milliers, le risque que les mécanismes anti-bot de Glassdoor détectent votre script de scraping automatisé est plus élevé, comme je l’ai constaté lorsque j’ai scrapé de plus grands volumes de données.
Le scraping de données à partir de Glassdoor peut s’avérer difficile en raison de ses mécanismes anti-scraping. Contourner ces mécanismes anti-bot peut être frustrant et nécessiter beaucoup de ressources. Cependant, il existe des stratégies pour aider votre scraper à imiter le comportement humain et réduire le risque d’être bloqué. Parmi les techniques courantes, on peut citer le Proxy rotatif, la configuration d’en-têtes de requête réels, la randomisation des taux de requête, etc. Si ces techniques peuvent améliorer vos chances de réussite, elles ne garantissent pas un succès à 100 %.
Ainsi, la meilleure approche pour extraire des données de Glassdoor, malgré ses mesures anti-bot, consiste à utiliser une API Glassdoor Scraper 🚀.
Une meilleure alternative : l’API Glassdoor Scraper
Bright Data propose un ensemble de données Glassdoor pré-collecté et structuré pour l’analyse, comme indiqué précédemment dans le blog. Si vous ne souhaitez pas acheter un ensemble de données et que vous recherchez une solution plus efficace, envisagez d’utiliser l’API Glassdoor Scraper de Bright Data.
Cette API puissante est conçue pour extraire les données Glassdoor de manière transparente, en gérant le contenu dynamique et en contournant facilement les mesures anti-bot. Grâce à cet outil, vous pouvez gagner du temps, garantir l’exactitude des données et vous concentrer sur l’extraction d’informations exploitables à partir des données.
Pour commencer à utiliser l’API Glassdoor Scraper, suivez les étapes suivantes :
Tout d’abord, créez un compte. Rendez-vous sur le site web de Bright Data, cliquez sur « Essai gratuit » et suivez les instructions d’inscription. Une fois connecté, vous serez redirigé vers votre tableau de bord, où vous recevrez des crédits gratuits.
Rendez-vous ensuite dans la section « Web Scraper API » et sélectionnez « Glassdoor » dans la catégorie « B2B data ». Vous trouverez différentes options de collecte de données, telles que la collecte d’entreprises par URL ou la collecte d’offres d’emploi par URL.
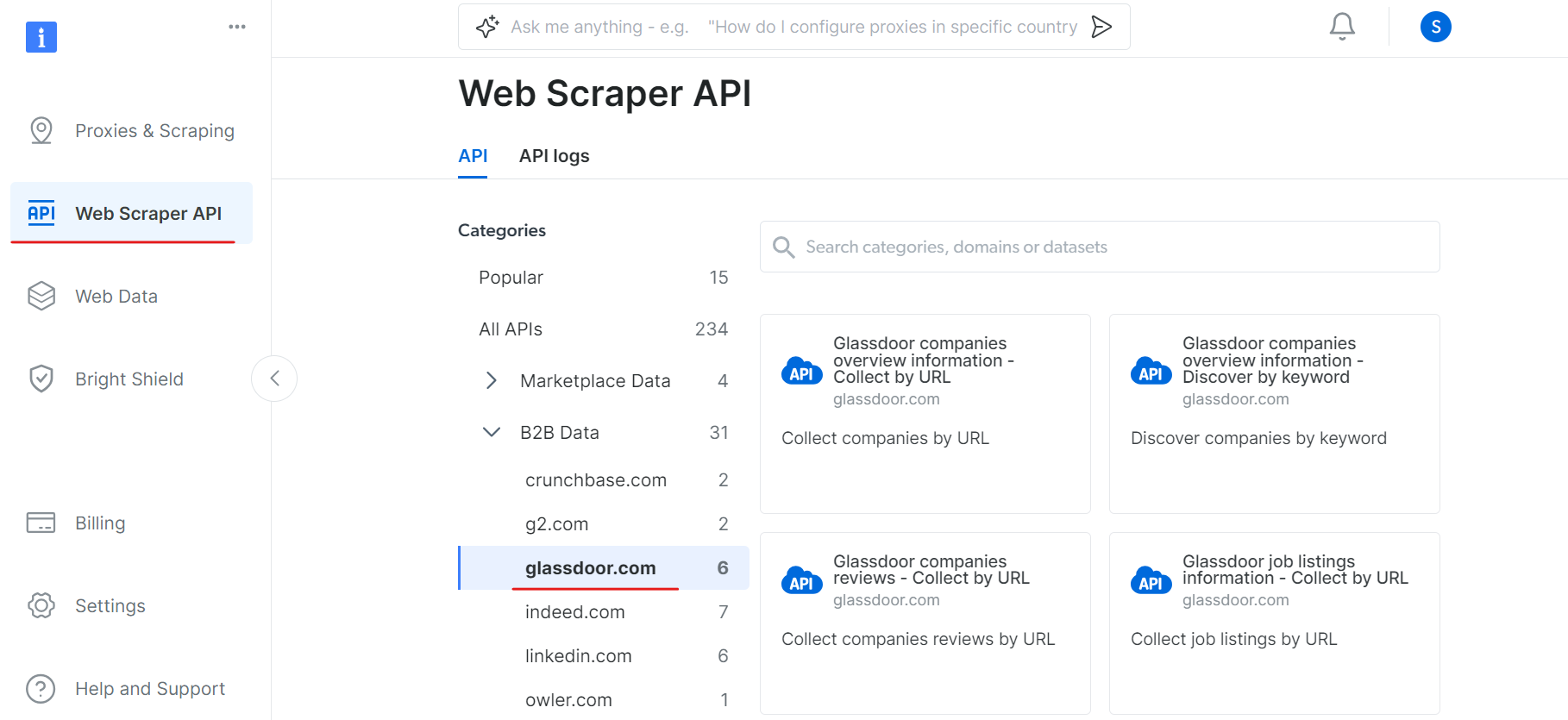
Sous « Informations générales sur les entreprises Glassdoor », obtenez votre jeton API et copiez votre identifiant de jeu de données (par exemple, gd_l7j0bx501ockwldaqf).
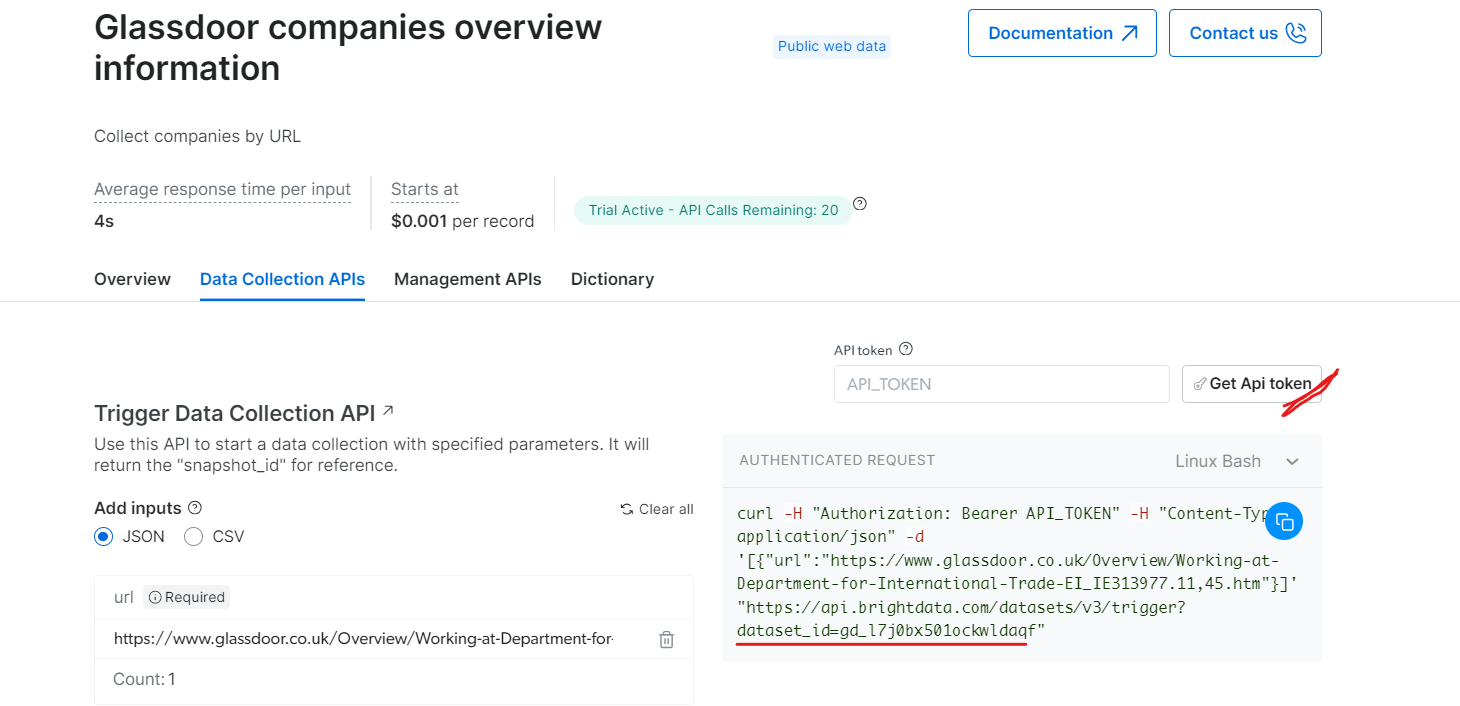
Voici maintenant un extrait de code simple qui montre comment extraire les données d’une entreprise en fournissant l’URL, le jeton API et l’ID de l’ensemble de données.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Déclenche un ensemble de données à l'aide de l'API BrightData.
Args :
api_token (str) : le jeton API pour l'authentification.
dataset_id (str) : l'ID de l'ensemble de données à déclencher.
company_url (str) : l'URL de la page de l'entreprise à analyser.
Retourne :
dict : la réponse JSON de l'API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/Jeux de données/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
Une fois le code exécuté, vous recevrez un identifiant d’instantané comme indiqué ci-dessous :

Utilisez l’ID de l’instantané pour récupérer les données réelles de l’entreprise. Exécutez la commande suivante dans votre terminal. Pour Windows, utilisez :
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Jeux de données/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Pour Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Jeux de données/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Après avoir exécuté la commande, vous obtiendrez les données souhaitées.
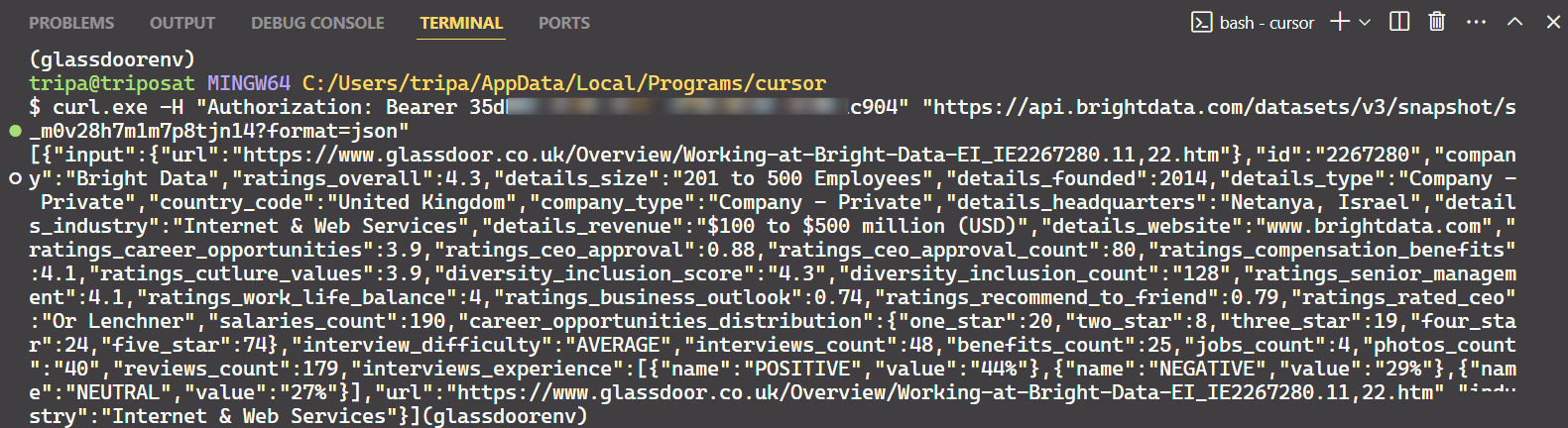
C’est tout ce qu’il faut faire !
De la même manière, vous pouvez extraire différents types de données de Glassdoor en modifiant le code. Je vous ai expliqué une méthode, mais il en existe cinq autres. Je vous recommande donc d’explorer ces options pour récupérer les données que vous souhaitez. Chaque méthode est adaptée à des besoins spécifiques et vous aide à obtenir exactement les données dont vous avez besoin.
Conclusion
Dans ce tutoriel, vous avez appris à extraire des données de Glassdoor à l’aide de Playwright Python. Vous avez également découvert les techniques anti-scraping utilisées par Glassdoor et comment les contourner. Pour résoudre ces problèmes, l’API Bright Data Glassdoor Scraper a été introduite. Elle vous aide à contourner les mesures anti-scraping de Glassdoor et à extraire les données dont vous avez besoin en toute simplicité.
Vous pouvez également essayer Navigateur de scraping, un navigateur de nouvelle génération qui peut être intégré à n’importe quel autre outil d’automatisation de navigateur. Navigateur de scraping peut facilement contourner les technologies anti-bot tout en évitant l’empreinte digitale du navigateur. Il s’appuie sur des fonctionnalités telles que la rotation des agents utilisateurs, la rotation des adresses IP et la Résolution de CAPTCHA.
Inscrivez-vous dès maintenant et testez gratuitement les produits Bright Data.






