

Dans ce tutoriel, nous parlerons des points suivants :
- Pourquoi collecter des données de commerce en ligne sur le web ?
- Bibliothèques et outils de web scraping pour eBay
- Extraction de données produit sur eBay avec Beautiful Soup
Pourquoi collecter des données de commerce en ligne sur le web ?
La collecte de données de commerce en ligne vous permet de récupérer des informations précieuses pour différents scénarios et activités. En particulier :
- Veille tarifaire : en suivant les sites web de commerce en ligne, les entreprises peuvent surveiller en temps réel les prix de différents produits. Cela peut vous aider à identifier les fluctuations des prix, les tendances ponctuelles, et à ajuster votre stratégie de tarification en conséquence. Si vous êtes un consommateur, cela vous aidera à trouver les meilleures offres et économiser de l’argent.
- Analyse de la concurrence : en recueillant des informations sur les offres de produits, les prix, les remises et les promotions de vos concurrents, vous pouvez prendre des décisions basées sur les données concernant vos propres stratégies de tarification, votre assortiment de produits et vos campagnes marketing.
- Études de marché : les données du commerce en ligne fournissent des informations précieuses sur les tendances du marché, les préférences des consommateurs et les modèles d’évolution de la demande. Vous pouvez utiliser ces informations pour alimenter un processus d’analyse des données permettant d’étudier les tendances émergentes et comprendre le comportement des clients.
- Analyse des sentiments : en collectant les avis des clients sur les sites de commerce en ligne, vous pouvez obtenir des informations sur la satisfaction des consommateurs, leurs commentaires sur les produits et les points à améliorer.
Dans le domaine du web scraping de sites de commerce en ligne, eBay est l’un des choix les plus populaires pour au moins trois bonnes raisons :
- Il propose une choix de produits étendu.
- Il est basé sur un système de vente aux enchères qui vous permet de récupérer beaucoup plus de données qu’Amazon et autres plateformes similaires.
- Il propose différents prix pour le même produit (Enchérir + Achat immédiat)
En extrayant des données sur eBay, vous pouvez accéder à une mine d’informations pour soutenir vos activités de veille tarifaire, de comparaison ou d’analyse de prix.
Bibliothèques et outils de web scraping pour eBay
Python est considéré comme l’un des meilleurs langages pour le web scraping grâce à sa facilité d’utilisation, la simplicité de sa syntaxe et son vaste écosystème de bibliothèques. Il s’agit donc du langage de programmation préférentiel pour collecter des données sur eBay. Explorez notre guide détaillé consacré au web scraping sous Python.
Vous devez maintenant choisir les bonnes bibliothèques de web scraping parmi les différentes bibliothèques disponibles. Pour prendre la bonne décision, explorez eBay dans le navigateur. En inspectant les appels AJAX effectués par la page, vous remarquerez que la plupart des données sur le site sont intégrées dans le document HTML renvoyé par le serveur.
Cela signifie qu’il vous suffit d’un simple client HTTP pour répliquer la requête sur le serveur, et d’un analyseur HTML. Pour cette raison, nous recommandons :
- Requests : la bibliothèque client HTTP la plus populaire pour Python. Elle simplifie le processus d’envoi de requêtes HTTP et de traitement de leurs réponses, ce qui facilite la récupération du contenu des pages à partir des serveurs web.
- Beautiful Soup : Une bibliothèque Python complète d’analyse HTML et XML. Elle est principalement utilisée pour le web scraping car elle fournit des méthodes puissantes pour explorer le DOM et extraire des données de ses éléments.
Grâce à Requests et à Beautiful Soup, vous pourrez extraire des données de votre site cible avec Python. Voyons comment.
Extraction de données produit sur eBay avec Beautiful Soup
Suivez ce tutoriel étape par étape et apprenez à créer en Python un script de web scraping pour eBay.
Étape 1 : pour commencer
Pour mettre en œuvre l’extraction des prix, vous devez respecter les prérequis suivantes :
- Python 3.0 ou supérieur installé sur votre ordinateur : Téléchargez le programme d’installation, lancez-le et suivez l’assistant d’installation.
- Un environnement de développement intégré Python de votre choix : Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux choix intéressants possibles.
Ensuite, initialisez un projet Python avec un environnement virtuel, que vous appellerez ebay-scraper, en exécutant les commandes ci-dessous :
mkdir ebay-scraper
cd ebay-scraper
python -m venv envEntrez le dossier du projet et ajoutez un fichier scraper.py contenant le code suivant :
print('Hello, World!')Il s’agit d’un exemple de script qui se contente d’afficher la sortie « Hello, World! » ; mais ce fichier contiendra bientôt votre logique de web scraping sur eBay.
Vérifiez qu’il fonctionne en l’exécutant avec :
python scraper.pySur le terminal, vous devriez voir :
Hello, World!Parfait ! Vous avez maintenant un projet Python.
Étape 2 : installez les bibliothèques de web scraping
Il est temps d’ajouter les bibliothèques nécessaires pour le web scraping dans les dépendances de votre projet. Lancez la commande ci-dessous dans le dossier du projet pour installer les packages Beautiful Soup et Requests :
pip install beautifulsoup4 requestsImportez les bibliothèques dans scraper.py et préparez-vous à les utiliser pour extraire des données sur eBay :
import requests
from bs4 import BeautifulSoup
# scraping logic...Assurez-vous que votre environnement de développement Python ne signale aucune erreur ; vous êtes maintenant prêt à implémenter une logique de web scraping pour votre veille tarifaire.
Étape 3 : téléchargez la page web cible
Si vous êtes un utilisateur eBay, vous avez peut-être remarqué que l’URL de la page produit suit le format ci-dessous :
https://www.ebay.com/itm/<ITM_ID>Comme vous pouvez le voir, il s’agit d’une URL dynamique qui change en fonction de l’ID de l’élément.
Par exemple, voici l’URL d’un produit eBay :
https://www.ebay.com/itm/225605642071?epid=26057553242&hash=item348724e757:g:~ykAAOSw201kD1un&amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJiIci, 225605642071 est l’identifiant unique de l’article. Notez que les paramètres de requête ne sont pas nécessaires pour visiter la page. Vous pouvez les supprimer – eBay continuera à charger correctement la page produit.
Au lieu de coder en dur la page cible dans votre script, vous pouvez faire en sorte que votre script lise l’ID d’élément à partir d’un argument de ligne de commande. De cette façon, vous pourrez extraire des données de n’importe quelle page produit.
Pour ce faire, modifiez scraper.py comme ceci :
import requests
from bs4 import BeautifulSoup
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# scraping logic...
Assume you want to scrape the product 225605642071. You can launch your scraper with:
python scraper.py 225605642071Grâce à sys, vous pouvez accéder aux arguments de ligne de commande. Le premier élément de sys.argv est le nom de votre script, scraper.py. Pour obtenir l’ID de l’élément, vous devez cibler cet élément avec l’index 1.
Si vous oubliez l’ID de l’élément dans l’interface de ligne de commande, l’application échouera et l’erreur ci-dessous sera émise :
Item ID argument missing!Sinon, le paramètre CLI sera lu et utilisé dans une f-string pour générer l’URL cible du produit désiré. Dans ce cas, l’URL contiendra :
https://www.ebay.com/itm/225605642071Maintenant, vous pouvez utiliser Requests pour télécharger cette page web avec la ligne de code suivante :
page = requests.get(url)En arrière-plan, request.get() exécute une requête HTTP GET à l’URL passée par paramètre. La page stocke la réponse produite par le serveur eBay, y compris le contenu HTML de la page cible.
Parfait ! Voyons maintenant comment en extraire les données.
Étape 4 : analysez le document HTML
page.text contient le document HTML renvoyé par le serveur. Passez-le au constructeur BeautifulSoup() pour l’analyser :
soup = BeautifulSoup(page.text, 'html.parser')Le second paramètre spécifie l’analyseur utilisé par Beautiful Soup. Si vous ne le connaissez pas encore, sachez que html.parser est le nom de l’analyseur HTML intégré dans Python.
La variable soup stocke maintenant une structure arborescente qui expose certaines méthodes utiles pour sélectionner des éléments du DOM. Les méthodes les plus employées sont :
- find() : renvoie le premier élément HTML correspondant à la condition de sélecteur passée par paramètre.
- find_all() : renvoie une liste d’éléments HTML correspondant à la stratégie du sélecteur d’entrée.
- select_one() : renvoie les éléments HTML correspondant au sélecteur CSS d’entrée.
- select() : renvoie une liste des éléments HTML correspondant au sélecteur CSS passé par paramètre.
Utilisez ces méthodes pour sélectionner des éléments HTML par balise, ID, classes CSS, etc. Vous pouvez ensuite extraire des données de leurs attributs et du contenu texte. Voyons comment.
Étape 5 : inspectez la page produit
Si vous voulez structurer une stratégie efficace d’extraction de données, vous devez d’abord vous familiariser avec la structure des pages web cibles. Ouvrez votre navigateur et accédez à quelques produits eBay.
Vous remarquerez tout d’abord que, selon la catégorie de produit, la page contient des informations différentes. Dans les produits électroménagers, vous aurez accès aux spécifications techniques.

Lorsque vous accédez à des articles vestimentaires, vous pouvez voir les tailles et les couleurs disponibles.

Ces incohérences dans la structure des pages web compliquent quelque peu notre travail de web scraping. Cependant, certains champs d’information figurent sur toutes les pages, notamment les prix des produits et les frais d’envoi.
Familiarisez-vous également avec les outils DevTools de votre navigateur. Cliquez avec le bouton droit de la souris sur un élément HTML contenant des données qui vous intéressent et sélectionnez Inspecter. La fenêtre ci-dessous s’ouvre :
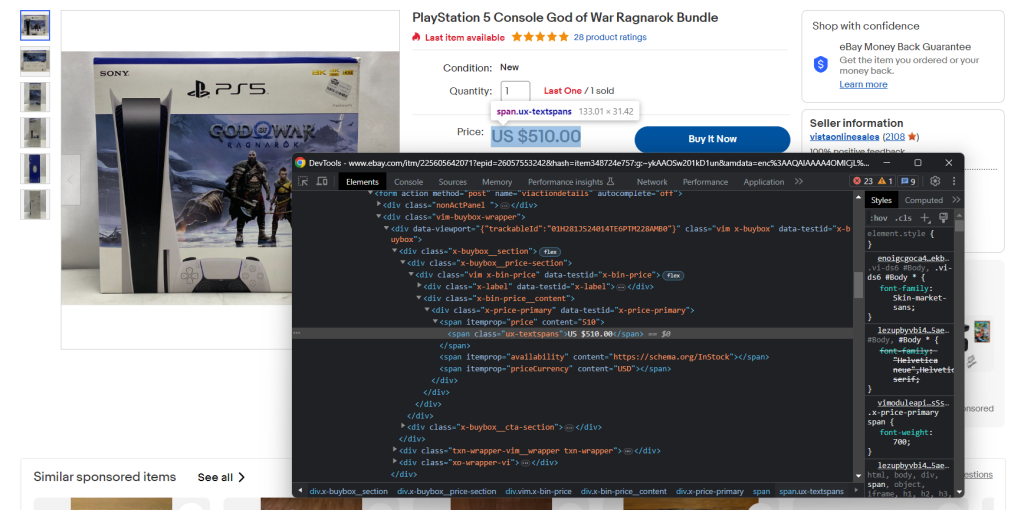
Ici, vous pouvez explorer la structure DOM de la page et comprendre comment définir des stratégies de sélecteur efficaces.
Prenez le temps nécessaire pour examiner quelques pages produit avec DevTools.
Étape 6 : extrayez les données de prix
Tout d’abord, vous avez besoin d’une structure de données dans laquelle stocker les données à extraire. Initialisez un dictionnaire Python avec :
item = {}Comme vous l’avez remarqué à l’étape précédente, les données de prix se trouvent dans cette section :

Inspectez l’élément HTML de prix :
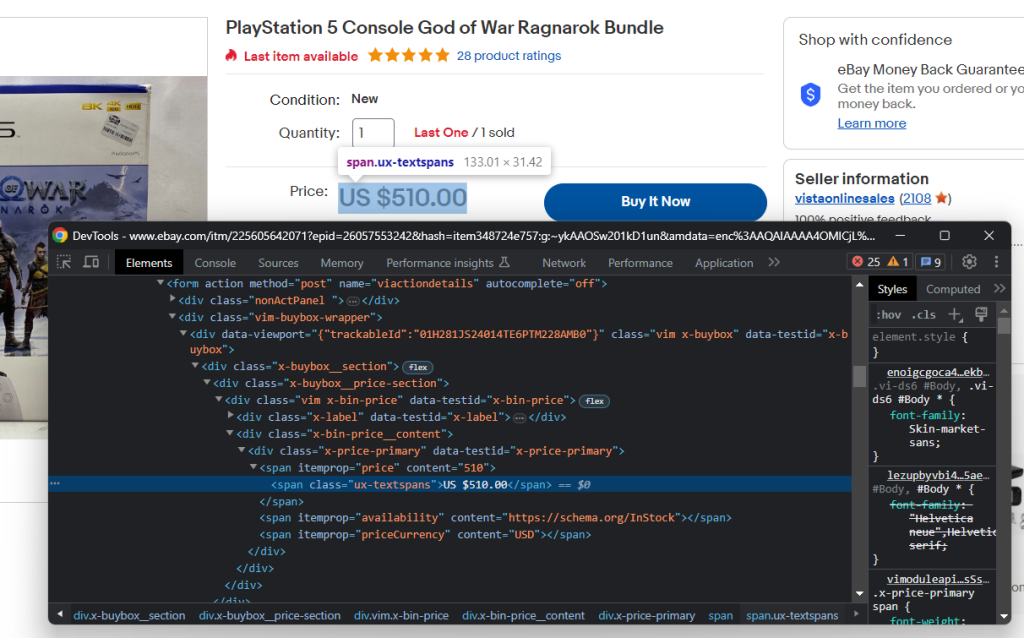
Vous pouvez obtenir le prix du produit avec le sélecteur CSS ci-dessous :
.x-price-primary span[itemprop="price"]
And the currency with:
.x-price-primary span[itemprop="priceCurrency"]
Apply those selectors in Beautiful Soup and retrieve the desired data with:
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']Ce code permet de sélectionner les éléments HTML de prix et de devise, puis de collecter la chaîne contenue dans leur attribut de contenu.
N’oubliez pas que le prix ci-dessus n’est qu’une partie du montant total que vous devrez payer pour obtenir l’article désiré. Cela inclut également les frais d’envoi.
Inspectez l’élément de frais d’envoi :
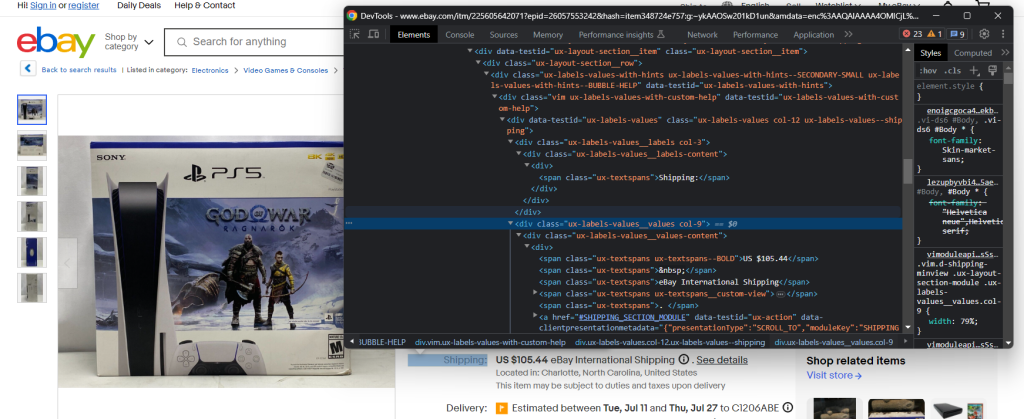
Cette fois-ci, l’extraction des données souhaitées est un peu plus difficile car il n’y a pas de sélecteur CSS évident pour obtenir l’élément. Vous pouvez cependant faire une itération sur chaque .ux-labels-values__labels div. Lorsque l’élément courant contient la chaîne « Shipping: », vous pouvez accéder à son élément frère adjacent dans le DOM et extraire le prix dans .ux-textspans–BOLD :
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
breakL’élément de frais d’envoi contient les données souhaitées au format suivant :
US $105.44Pour extraire le prix, vous pouvez utiliser un regex avec la méthode re.findall(). N’oubliez pas d’ajouter la ligne suivante à la section d’importation de votre script :
import re
Add the collected data to the item dictionary:
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
Print it with:
print(item)
And you will get:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}Cela suffit pour mettre en œuvre un processus de suivi des prix en Python. Néanmoins, il y a beaucoup d’autres informations utiles sur la page produit eBay. Il peut donc être intéressant d’apprendre à les extraire !
Étape 7 : récupérez les détails d’un élément
Si vous examinez l’onglet « À propos de cet élément », vous remarquerez qu’il contient beaucoup de données intéressantes :
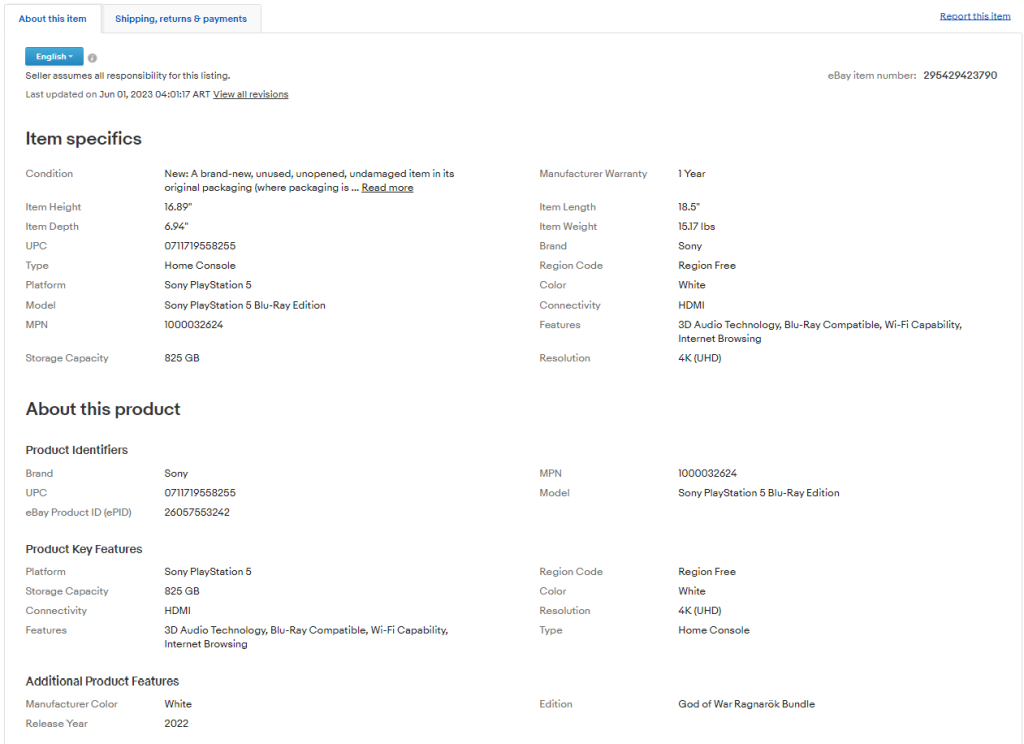
Les sections et les champs qui s’y trouvent varient d’un produit à l’autre. Vous devez donc trouver un moyen de les extraire tous de manière astucieuse.
Plus précisément, les sections les plus importantes sont « Caractéristiques de l’article » et « À propos de ce produit ». Ces deux sections figurent sur la plupart des produits. Inspectez l’une des deux sections ; vous remarquerez que vous pouvez les sélectionner avec :
.section-title
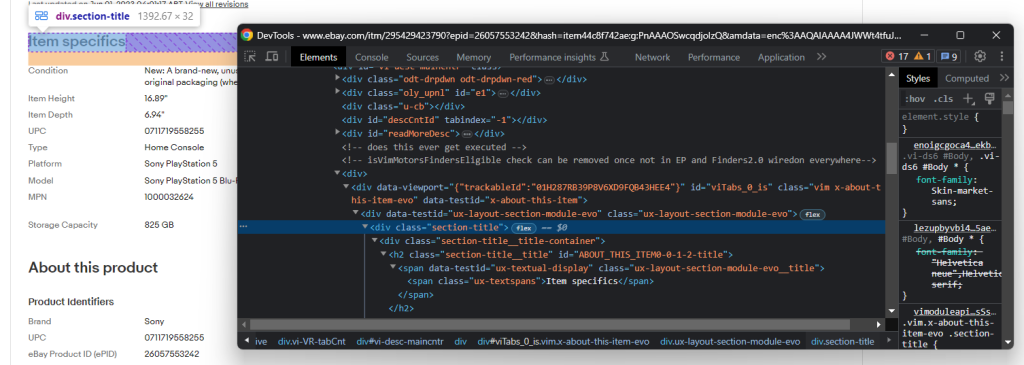
Dans une section donnée, vous pouvez explorez la structure DOM :
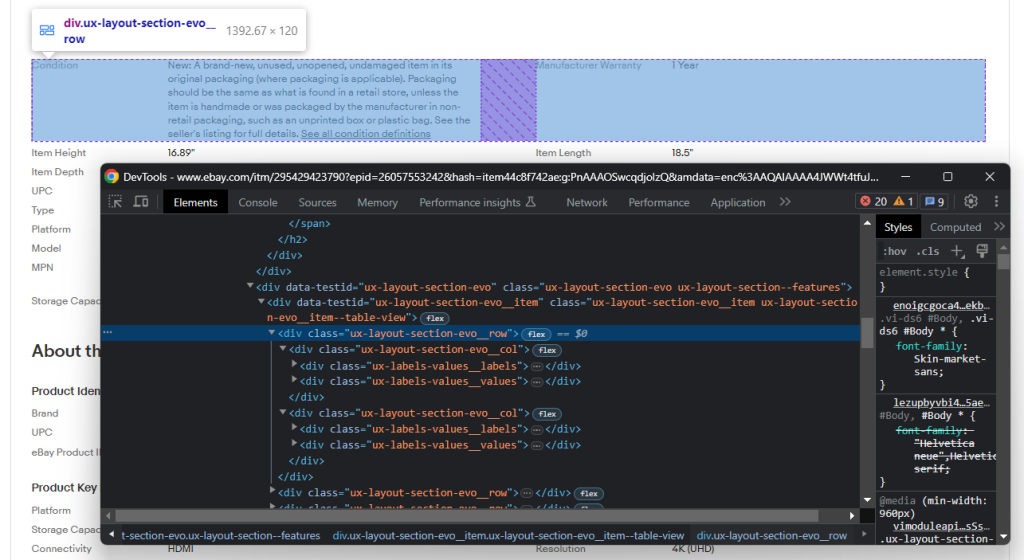
Remarquez que cette structure se compose de plusieurs lignes, qui contiennent chacune des éléments .ux-layout-section-evo__col. Ces derniers contiennent deux éléments :
- .ux-labels-values__labels : nom de l’attribut.
- .ux-labels-values__values : valeur de l’attribut.
Vous êtes maintenant prêt à écrire une procédure pour extraire toutes les informations figurant dans la section des détails :
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.textCe code parcourt chaque élément du champ des détails HTML et ajoute la paire clé-valeur associée à chaque attribut de produit au dictionnaire des éléments.
À la fin de la boucle for, l’élément contient :
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab ", 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89"', 'Item Length': '18.5"', 'Item Depth': '6.94"', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}Parfait ! Vous avez réussi à récupérer vos données.
Étape 8 : Exportez les données extraites au format JSON
Pour l’instant, les données collectées sont stockées dans un dictionnaire Python. Pour les rendre plus facile à partager et à lire, vous pouvez les exporter en JSON :
import json
# scraping logic...
with open('product_info.json', 'w') as file:
json.dump(item, file)Tout d’abord, vous devez initialiser un fichier product_info.json avec open(). Ensuite, vous pouvez écrire la représentation JSON du dictionnaire des éléments dans le fichier de sortie avec json.dump(). Consultez notre article pour découvrir comment analyser et sérialiser des données en Python pour les convertir en JSON.
Le paquet json vient de la bibliothèque standard de Python ; vous n’avez donc même pas besoin d’installer une dépendance supplémentaire pour atteindre votre objectif.
Bien ! Vous êtes passé de données brutes contenues dans une page web à des données JSON semi-structurées. Il est temps de jeter un coup d’œil à l’ensemble de notre web scraper eBay.
Étape 9 : au final
Voici l’ensemble du script scraper.py :
import requests
from bs4 import BeautifulSoup
import sys
import re
import json
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# download the target page
page = requests.get(url)
# parse the HTML document returned by the server
soup = BeautifulSoup(page.text, 'html.parser')
# initialize the object that will contain
# the scraped data
item = {}
# price scraping logic
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']
shipping_price = None
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is not a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
break
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
# product detail scraping logic
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.text
# export the scraped data to a JSON file
with open('product_info.json', 'w') as file:
json.dump(item, file, indent=4)En moins de 70 lignes de code, vous pouvez construire un web scraper pour assurer la surveillance des données relatives aux produits eBay.
Par exemple, lancez-le sur l’élément identifié par l’ID 225605642071 avec :
python scraper.py 225605642071À la fin du processus de web scraping, le fichier product_info.json ci-dessous apparaîtra dans le dossier racine de votre projet :
{
"price": "499.99",
"shipping_price": "72.58",
"currency": "USD",
"Condition": "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details",
"Manufacturer Warranty": "1 Year",
"Item Height": "16.89"",
"Item Length": "18.5"",
"Item Depth": "6.94"",
"Item Weight": "15.17 lbs",
"UPC": "0711719558255",
"Brand": "Sony",
"Type": "Home Console",
"Region Code": "Region Free",
"Platform": "Sony PlayStation 5",
"Color": "White",
"Model": "Sony PlayStation 5 Blu-Ray Edition",
"Connectivity": "HDMI",
"MPN": "1000032624",
"Features": "3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing",
"Storage Capacity": "825 GB",
"Resolution": "4K (UHD)",
"eBay Product ID (ePID)": "26057553242",
"Manufacturer Color": "White",
"Edition": "God of War Ragnarok Bundle",
"Release Year": "2022"
}Félicitations ! Vous venez d’apprendre à extraire des données eBay en Python !
Conclusion
Dans ce guide, vous avez compris pourquoi eBay est l’une des meilleures cibles pour effectuer une veille tarifaire et vous avez découvert comment en extraire des prix grâce au web scraping. Plus précisément, vous avez vu, grâce à notre tutoriel détaillé, comment construire un web scraper en Python pour collecter des données d’éléments. Comme vous l’avez vu, ce n’est pas difficile et cela ne nécessite que quelques lignes de code.
Cela étant, vous avez constaté à quel point la structure des pages d’eBay peut varier. Le web scraper construit ici peut donc fonctionner pour un produit mais pas pour un autre. En outre, l’interface utilisateur d’eBay change souvent, ce qui vous impose de modifier régulièrement le script. Heureusement, vous pouvez éviter cela avec notre web scraper eBay !
Si vous voulez étendre votre processus de web scraping et extraire des prix d’autres plateformes de commerce en ligne, gardez à l’esprit qu’un certain nombre d’entre elles recourent fortement à JavaScript. Lorsque vous avez affaire à de tels sites, une approche traditionnelle basée sur un analyseur HTML ne fonctionnera pas. Au lieu de cela, vous avez besoin d’un outil permettant d’assurer le rendu JavaScript et de gérer automatiquement les empreintes de navigateur, les CAPTCHA et l’itération de nouvelles tentatives. C’est exactement à cela que sert notre nouveau Scraping Browser !
Vous ne voulez pas du tout vous occuper de web scraping, mais vous êtes intéressés par les données eBay ? Acheter un jeu de données eBay.

