

{
“@context”: “https://schema.org”,
“@type”: “HowTo”,
“name”: “Comment scraper Airbnb en 2026”,
“description”: “Quatre façons de collecter des données de listings Airbnb en 2026, d’un Scraper Python manuel à une API Scraper gérée et un jeu de données prêt à l’emploi.”,
“step”: [
{
“@type”: “HowToStep”,
“position”: 1,
“name”: “Scraping Python manuel”,
“text”: “Envoyez des requêtes avec Python et analysez le HTML. Cela convient à l’apprentissage, mais échoue sous la couche anti-bot d’Airbnb à grande échelle.”
},
{
“@type”: “HowToStep”,
“position”: 2,
“name”: “Web Unlocker pour les pages personnalisées”,
“text”: “Utilisez Bright Data Web Unlocker pour récupérer la page rendue en contournant la détection de bots, puis analysez les champs dont vous avez besoin avec votre propre code.”
},
{
“@type”: “HowToStep”,
“position”: 3,
“name”: “API Scraper Airbnb”,
“text”: “Appelez l’API Scraper Airbnb pour obtenir des enregistrements de listings JSON propres et structurés à n’importe quel volume, sans analyse ni maintenance.”
},
{
“@type”: “HowToStep”,
“position”: 4,
“name”: “Jeu de données Airbnb prêt à l’emploi”,
“text”: “Téléchargez un jeu de données Airbnb prêt à l’emploi pour des données en masse ou historiques, sans code ni scraping requis.”
}
]
}
Airbnb est l’une des sources de données les plus demandées dans le secteur du voyage et de l’immobilier, et l’une des plus difficiles à collecter : les pages se trouvent derrière une couche anti-bot et changent souvent, et en 2026 ces données alimentent de plus en plus des modèles de tarification dynamique et des agents IA qui ont besoin de données fraîches et structurées. Ce guide présente quatre façons de les obtenir, d’une simple requête Python à un jeu de données entièrement géré, avec du code réel et testé ainsi que des résultats en direct pour chacune.
Ce que couvre ce guide
- Les quatre façons d’extraire des données Airbnb en 2026, et quand utiliser chacune
- Un Scraper Python manuel, et exactement où il échoue
- Web Unlocker pour les pages personnalisées, avec le code d’analyse que vous contrôlez
- L’API Scraper Airbnb pour un JSON propre et structuré à n’importe quel volume
- Le jeu de données Airbnb prêt à l’emploi pour les données en masse et historiques
- Alimentation des données Airbnb vers un agent IA via le Web MCP
Prêt à sauter l’étape de construction ? Extrayez des listings en direct avec l’API Scraper Airbnb, téléchargez un jeu de données Airbnb prêt à l’emploi, ou commencez gratuitement avec 5 000 enregistrements par mois et sans carte de crédit.
Quelles données Airbnb valent la peine d’être collectées
Un seul listing Airbnb expose bien plus qu’un prix par nuit. Les champs qui comptent pour la plupart des projets sont :
- Tarification : tarif par nuit, total avant taxes, remises et frais de ménage
- Disponibilité : le calendrier de réservation et les exigences de nuits minimales
- Avis et notes : score global, nombre d’avis et détails par catégorie
- Signaux hôte : statut superhôte, taux de réponse et historique
- Détails du bien : capacité, équipements, coordonnées et images
Chacun de ces éléments correspond à un élément spécifique sur la page de listing en direct. Les encadrés rouges ci-dessous montrent l’origine des champs structurés :
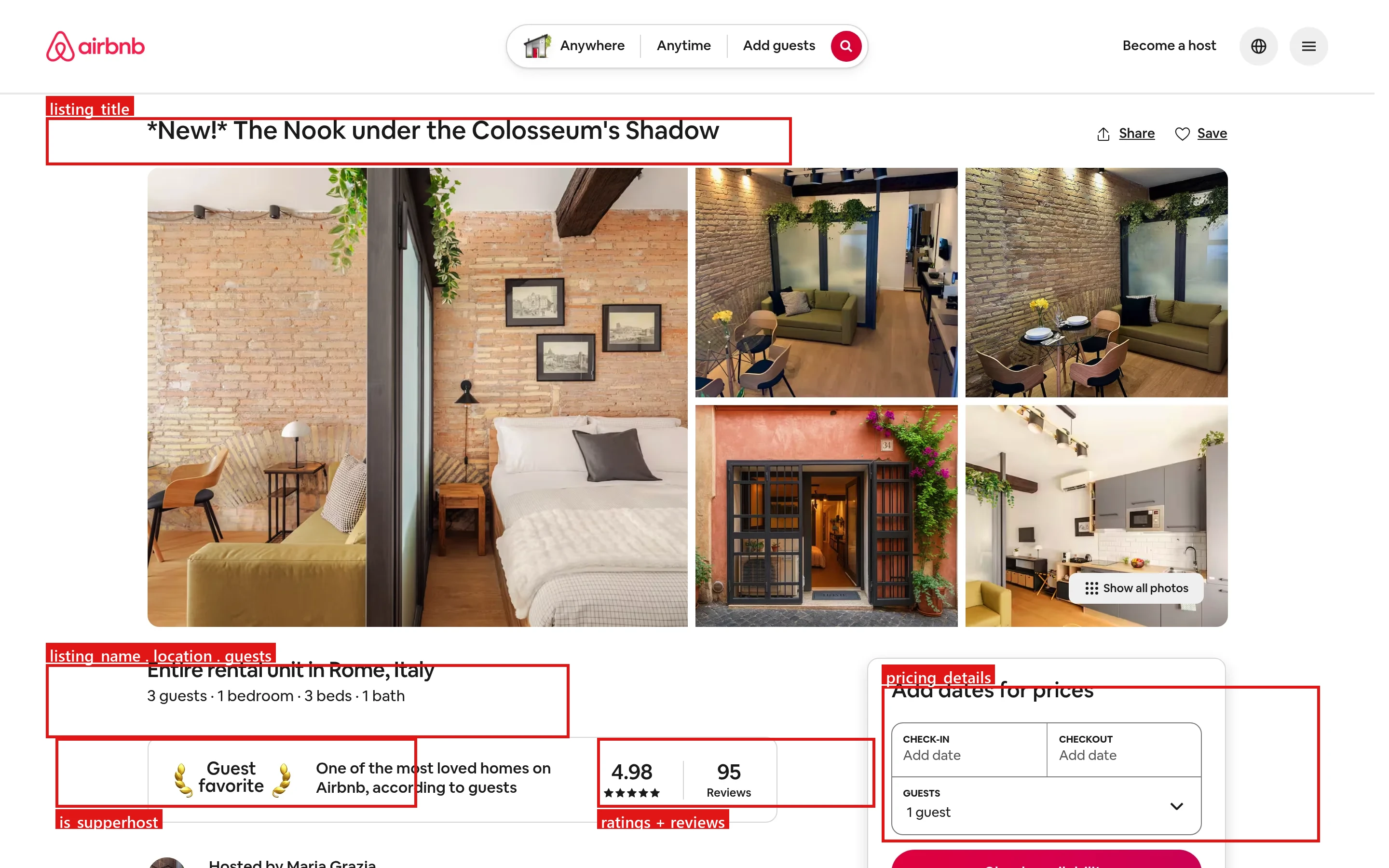
Cas d’usage courants : sélection d’investissements locatifs à court terme, tarification dynamique face à la concurrence locale, analyse des tendances d’occupation et de marché, et fourniture de données de localisation propres aux pipelines IA et analytiques.
Les quatre approches en un coup d’œil
| Approche | Effort | Échelle | Maintenance | Idéal pour |
|---|---|---|---|---|
| Python manuel | Élevé | Faible | Élevée | Apprentissage, extractions ponctuelles minimes |
| Web Unlocker | Moyen | Moyen | Moyenne | Analyse personnalisée, pages sans scraper prédéfini |
| API Scraper Airbnb | Faible | Élevé | Aucune | Données de listings structurées à n’importe quel volume |
| Jeu de données Airbnb | Aucun | En masse | Aucune | Données historiques ou à l’échelle du marché, sans code |
Le résumé honnête : le scraping manuel est la façon la moins chère d’apprendre et la plus coûteuse à exploiter. Les trois autres approches transfèrent les parties difficiles — déblocage, analyse et maintenance — vers une infrastructure gérée.
Approche 1 : Scraping manuel, et où il échoue
Commencez par l’évident : récupérez la page de recherche avec requests et analysez-la. Voici la tentative complète.
import requests
url = "https://www.airbnb.com/s/Rome, Italy/homes"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("DataDome anti-bot active:", "datadome" in resp.text.lower())L’exécution montre à quoi vous êtes réellement confronté :
status: 200
DataDome anti-bot active: TrueLa requête renvoie 200, mais chaque réponse est enveloppée dans la couche de détection de bots de DataDome. Parfois vous obtenez une page de défi sans listings, et d’autres fois une seule requête passe. Cette incohérence est le vrai problème : dès que vous ajoutez de la pagination, d’autres villes ou un volume de requêtes réel, DataDome signale le trafic et vous rencontrez des CAPTCHAs, des limites de débit et des bannissements d’IP. Le rendre fiable nécessite des proxys résidentiels rotatifs, une vraie empreinte de navigateur, une résolution automatisée de CAPTCHA et un analyseur qui survit aux fréquents changements de balisage d’Airbnb. C’est un projet de maintenance, pas un script. Si vous voulez quand même la voie DIY, notre guide de scraping web Python couvre les fondamentaux. Les trois approches suivantes suppriment ce fardeau.
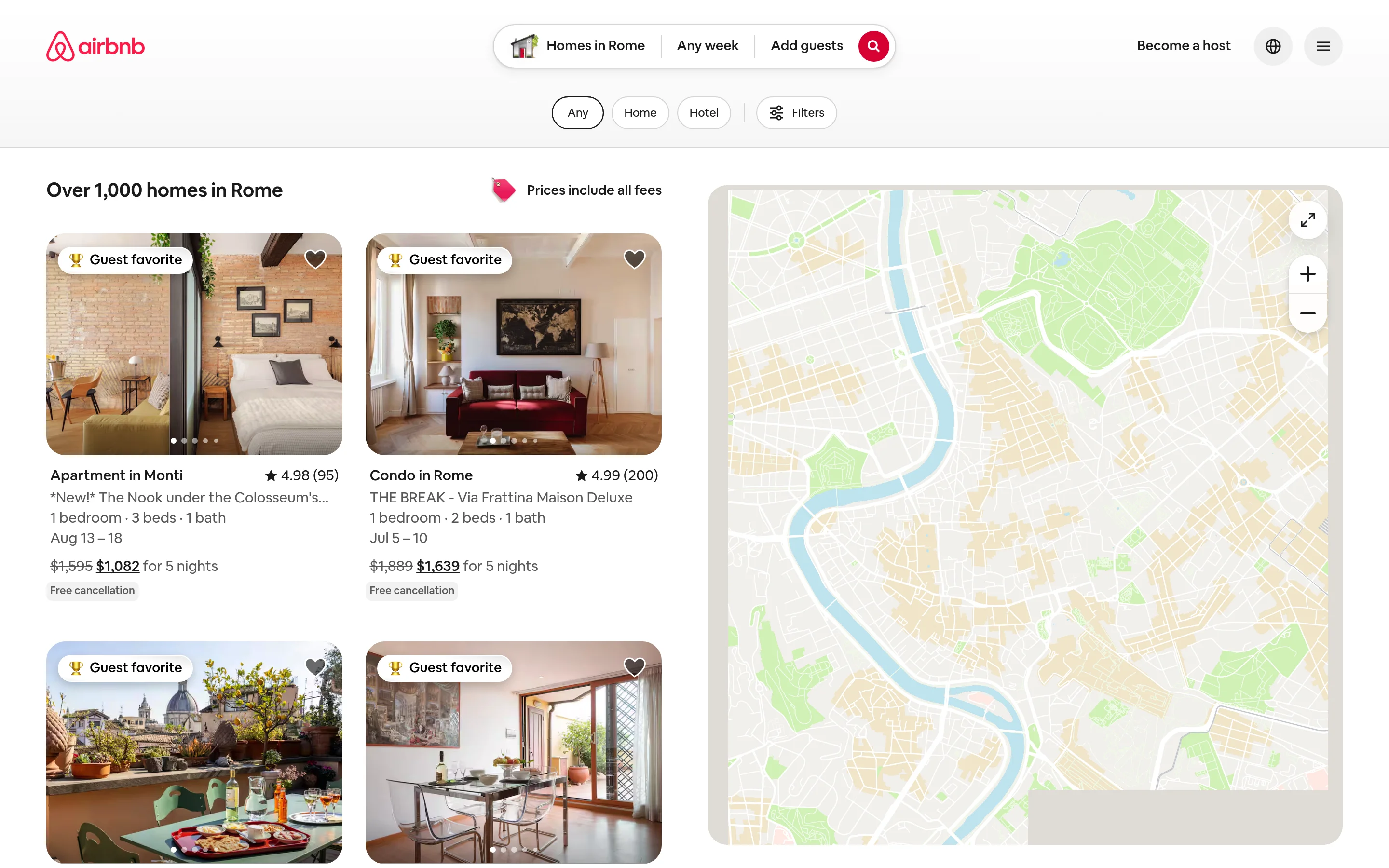
Approche 2 : Web Unlocker pour les pages personnalisées
Quand vous avez besoin de la page brute (par exemple, un type de page sans scraper prédéfini), le Web Unlocker gère le déblocage et vous restitue le HTML entièrement rendu. Vous analysez toujours les données vous-même, ce qui est le bon compromis quand vous voulez un contrôle total sur l’extraction.
Airbnb intègre ses données de listing en JSON dans la page, donc une fois que vous avez le HTML, vous pouvez extraire les champs directement sans sélecteurs CSS fragiles.
import os
import re
import requests
API = "https://api.brightdata.com/request"
payload = {
"zone": os.environ["BRIGHTDATA_UNLOCKER_ZONE"],
"url": "https://www.airbnb.com/s/Rome, Italy/homes",
"format": "raw",
"country": "us", # geo-target for consistent currency and language
}
headers = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
html = requests.post(API, json=payload, headers=headers, timeout=120).text
names = re.findall(r'"localizedStringWithTranslationPreference":"([^"]+)"', html)
prices = re.findall(r'"accessibilityLabel":"([^"]*?$[d,]+[^"]*?)"', html)
print(len(set(names)), "listings parsed")
for name, price in list(zip(names[::2], prices))[:4]:
print("-", name, "|", price)Cela renvoie de vrais listings analysés :
30 listings parsed
- *New!* The Nook under the Colosseum's Shadow | $1,082 for 5 nights, originally $1,595
- THE BREAK - Via Frattina Maison Deluxe | $1,639 for 5 nights, originally $1,889
- The Unique Home Pantheon | $1,064 for 5 nights, originally $1,481
- 360 penthouse overlooking central Rome | $3,010 for 5 nightsWeb Unlocker vous fait passer le mur, et vous gardez un contrôle total sur l’analyse. Le coût est que vous êtes toujours propriétaire de la logique d’extraction et devez la mettre à jour quand Airbnb modifie la structure de ses pages. Si tout ce que vous voulez, c’est des données de listing propres, l’API Scraper supprime complètement cette étape.
Approche 3 : L’API Scraper Airbnb
L’API Scraper Airbnb est un scraper prédéfini. Vous envoyez des URLs de listings ou de recherches et recevez du JSON structuré. Pas de proxies, pas d’analyse, pas de maintenance du balisage. Elle fait partie du Web Scraper API de Bright Data, qui couvre plus de 700 sites.
L’exemple ci-dessous collecte ce listing précis, celui que vous pouvez voir en direct sur Airbnb.
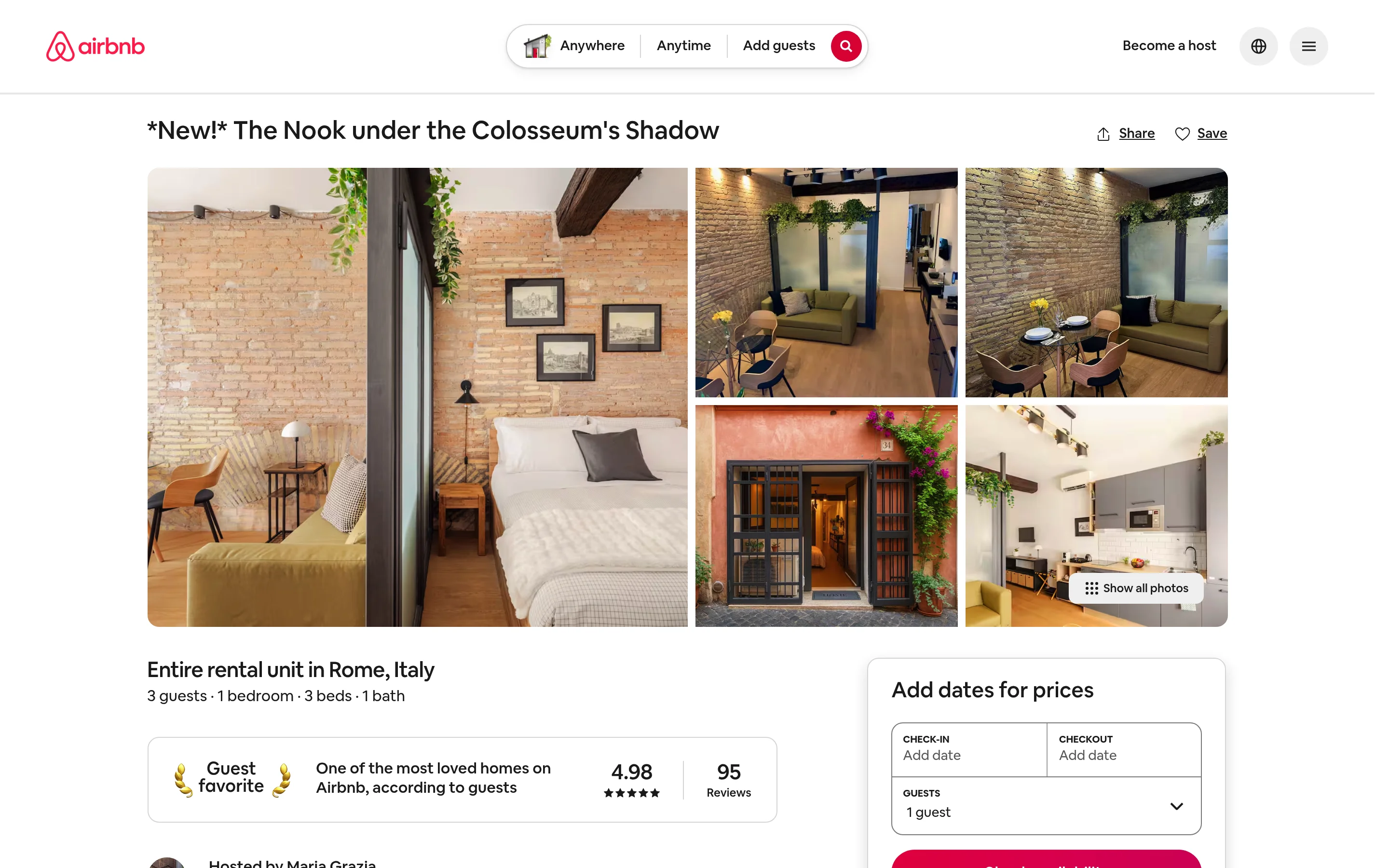
Pour jusqu’à 20 URLs, utilisez le point de terminaison synchrone et obtenez les résultats en un seul appel.
import os
import requests
DATASET_ID = "gd_ld7ll037kqy322v05" # Airbnb Properties Information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.airbnb.com/rooms/1409274854260723534"}]},
timeout=180,
)
listing = resp.json()[0]
for field in ("listing_title", "ratings", "property_number_of_reviews",
"is_supperhost", "guests", "location", "lat", "long"):
print(f"{field}: {listing[field]}")
print("amenities:", len(listing["amenities"]), "| images:", len(listing["images"]),
"| available_dates:", len(listing["available_dates"]))La réponse est un enregistrement propre unique avec 51 champs. Résultat réel pour ce listing :
listing_title: *New!* The Nook under the Colosseum's Shadow
ratings: 4.98
property_number_of_reviews: 95
is_supperhost: True
guests: 3
location: Rome, Lazio, Italy
lat: 41.8949
long: 12.4895
amenities: 12 | images: 66 | available_dates: 185Aucune logique d’analyse, aucune gestion de proxy, et le schéma reste stable même quand Airbnb modifie son HTML. C’est la différence entre scraper une page et consommer un produit de données maintenu.
Pour les travaux plus importants, passez au point de terminaison asynchrone. Vous déclenchez une collecte, interrogez l’état jusqu’à la fin, puis téléchargez. Cela passe à l’échelle de milliers d’URLs en un seul travail.
import os
import time
import requests
DATASET_ID = "gd_ld7ll037kqy322v05"
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
HEADERS = {"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"}
# 1. Trigger
urls = [
"https://www.airbnb.com/rooms/1409274854260723534",
"https://www.airbnb.com/rooms/667303913003951222",
# ... hundreds more
]
trigger = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"},
headers=HEADERS,
json={"input": [{"url": u} for u in urls]},
)
snapshot_id = trigger.json()["snapshot_id"]
# 2. Poll until ready
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}",
headers=HEADERS,
).json()["status"]
if status == "ready":
break
if status == "failed":
raise RuntimeError("collection failed")
time.sleep(10)
# 3. Download
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}",
params={"format": "json"},
headers=HEADERS,
).json()
print(len(data), "listings collected")Vous ne payez que pour les enregistrements livrés, le Web Scraper API commence à partir de 0,70 $ pour 1 000 enregistrements, et chaque nouveau compte reçoit 5 000 enregistrements gratuits par mois pour tester, sans carte de crédit requise. Il existe également une version sans code dans le panneau de contrôle si vous préférez ne rien écrire.
Approche 4 : Le jeu de données Airbnb prêt à l’emploi
Si vous avez besoin d’un historique ou d’une couverture à l’échelle du marché plutôt que d’une liste spécifique d’URLs, ignorez complètement la collecte et achetez le jeu de données Airbnb. C’est le même schéma structuré, pré-collecté et actualisé.
Le jeu de données de la marketplace contient plus de 6,5 millions d’enregistrements sur 51 champs, à partir de 0,0025 $ par enregistrement avec une commande minimale de 250 $, en téléchargement unique ou en abonnement avec actualisation. Vous filtrez par localisation, date ou autres attributs et téléchargez en JSON, CSV ou Parquet. C’est l’option acheter-plutôt-que-construire : zéro ingénierie, accès instantané, et parfait pour le backtesting de modèles de tarification ou l’analyse d’une ville entière en une fois. Bright Data publie les mêmes données prêtes à l’emploi pour d’autres marketplaces, dont les meilleurs fournisseurs de données Amazon et les meilleurs fournisseurs de données e-commerce.
Bonus : alimenter un agent IA directement avec des données Airbnb (MCP)
Le plus grand changement de 2026 est que le consommateur de ces données est souvent un agent IA, pas un tableau de bord. Les agents ont besoin de données web en direct à la demande, et le Model Context Protocol (MCP) est la façon dont ils appellent des outils externes. Le serveur Web MCP de Bright Data donne à n’importe quel LLM — que ce soit Claude, GPT ou Gemini — une recherche en direct (API SERP) et du scraping via la même infrastructure de déblocage, de sorte que l’agent ne rencontre jamais le mur DataDome de l’Approche 1.
Pointez votre client MCP vers le serveur hébergé avec une seule ligne, sans installation requise :
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKENOu exécutez-le localement avec npx :
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": { "API_TOKEN": "your-token-here" }
}
}
}Encore plus rapide, le CLI Bright Data connecte le MCP à votre agent en une seule commande :
brightdata add mcp, agent claude-code,cursor,codexLe mode Rapid gratuit expose search_engine, scrape_as_markdown et discover à un crédit par requête, puisant dans les mêmes 5 000 crédits mensuels gratuits. Un agent peut alors répondre à une invite comme « trouver des listings Airbnb disponibles à Rome à moins de 200 $ la nuit et résumer les cinq moins chers » en cherchant et en scrapant en direct, sans aucun code de scraping dans votre application. Le mode Pro ajoute 60+ outils structurés, dont des extracteurs de données web prédéfinis et l’automatisation du Navigateur de scraping, pour les agents en production. Pour une présentation complète, consultez le tutoriel de scraping Web MCP.
Avant de le connecter à un agent, vous pouvez essayer exactement les mêmes outils depuis votre terminal avec le CLI Bright Data, qui puise dans les mêmes crédits gratuits. Un rapide search et scrape contre Airbnb :
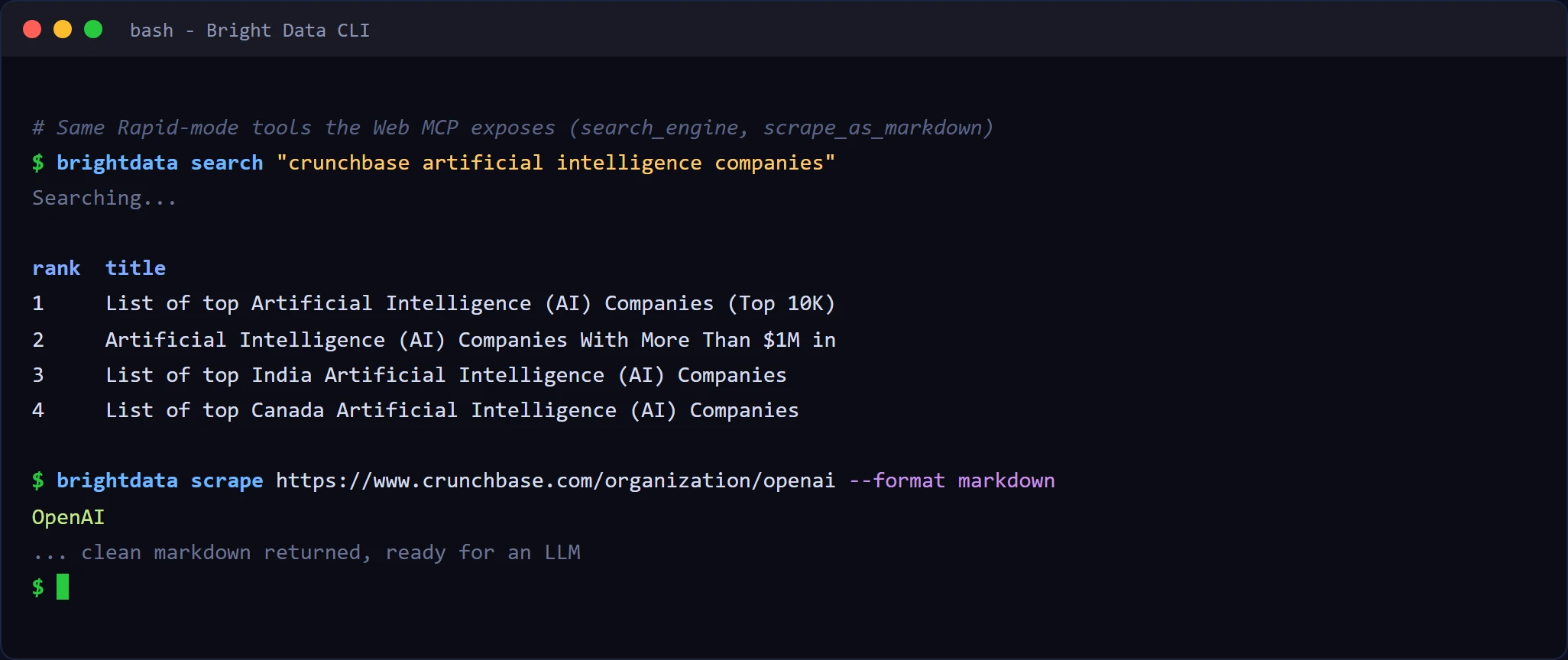
Les commandes search et scrape du CLI correspondent exactement aux outils search_engine et scrape_as_markdown du MCP, donc ce qui s’affiche dans votre terminal est exactement ce que l’agent reçoit une fois connecté.
Voir fonctionner à l’intérieur de l’agent
Une fois connecté, vous demandez en langage naturel et l’agent décide quels outils MCP appeler. Des invites qui fonctionnent directement :
- « Trouver des appartements à louer sur Airbnb à Rome et en recommander quelques-uns avec des notes. »
- « Extraire les détails clés pour airbnb.com/rooms/ID : note, statut superhôte, capacité. »
- « Comparer les prix par nuit des Airbnbs deux chambres à Rome par rapport à Florence. »
- « Résumer le sentiment des avis pour ce listing en trois points. »
Voici la première invite s’exécutant dans Claude Code. L’agent appelle search_engine et scrape_as_markdown de lui-même, puis répond avec des données en direct sans aucun code de scraping dans le projet.
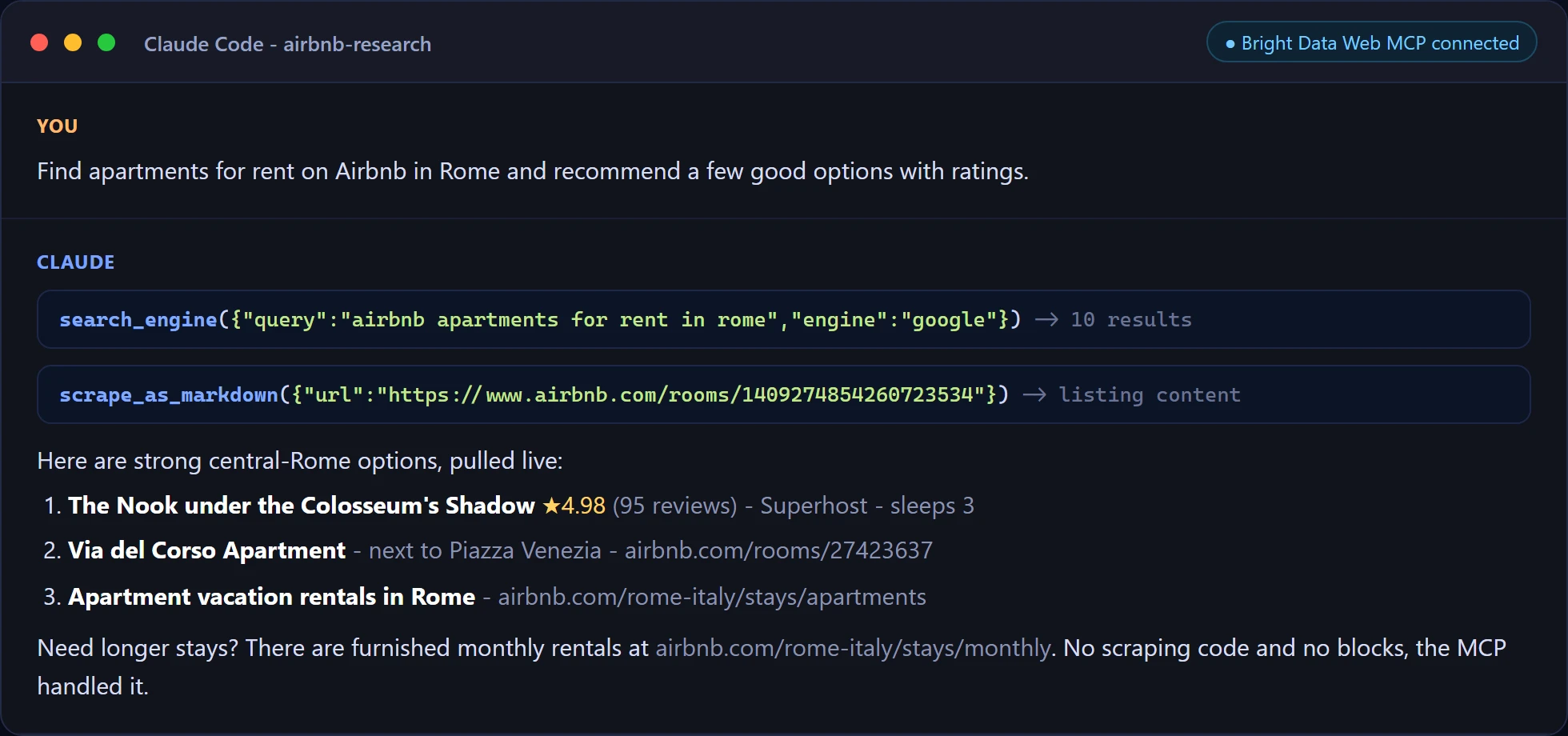
Et une extraction ciblée dans Cursor, extrayant les champs d’un listing directement depuis la page en direct.
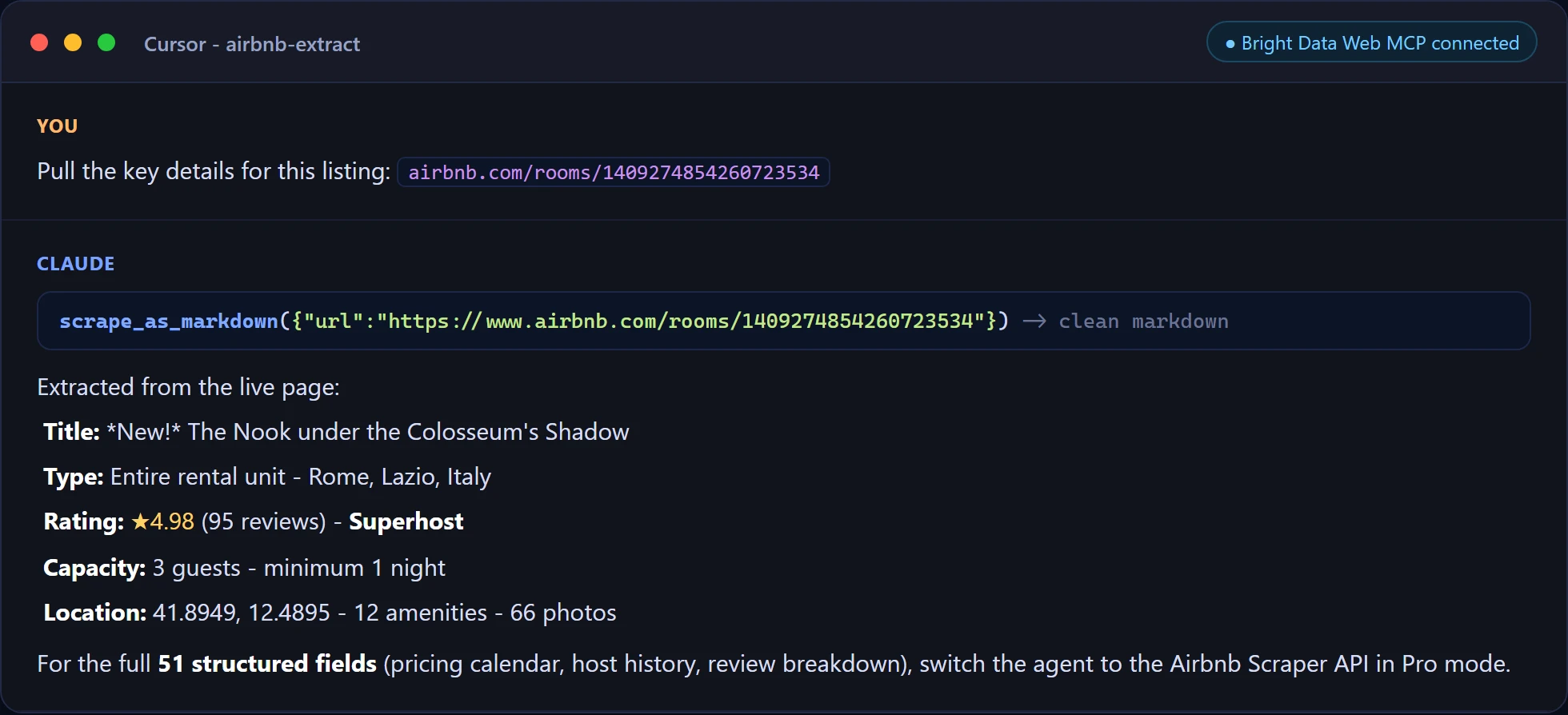
Pour les agents en production qui ont besoin de chaque champ, activez le mode Pro et l’agent dispose de 60+ outils de données web structurés à appeler aux côtés de l’API Scraper Airbnb de l’Approche 3.
Transformer les données en insights
Une fois que vous avez les listings, l’analyse est rapide. En utilisant les prix analysés dans l’Approche 2, un court extrait résume le marché local.
import statistics
prices = [1082, 1639, 1064, 3010, 904, 1115, 2008, 1398] # USD, 5-night totals
print("listings:", len(prices))
print("median:", statistics.median(prices))
print("range:", min(prices), "to", max(prices))Tracer l’échantillon complet montre la distribution dans le centre de Rome en un coup d’œil.
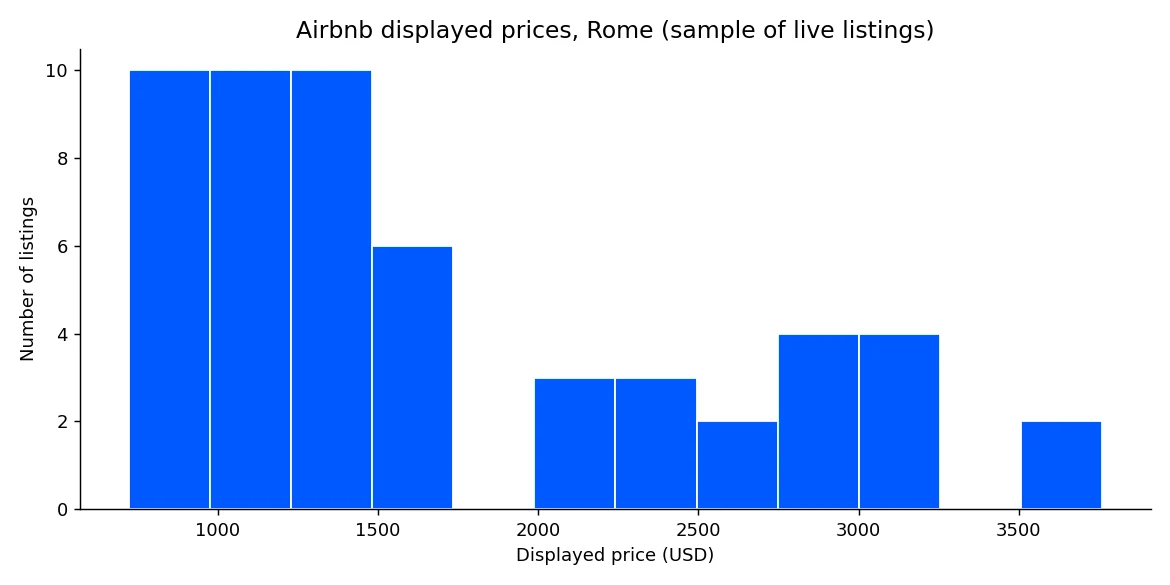
Cette distribution est le fondement de la tarification compétitive, de la détection des valeurs aberrantes et de la modélisation de l’occupation.
Comment choisir
- Juste en exploration ou apprentissage ? Le scraping manuel vous apprend comment la page est construite. Ne l’utilisez pas en production.
- Besoin d’une page sans scraper prédéfini et souhait de contrôler l’analyse ? Utilisez Web Unlocker.
- Besoin de données de listings propres et structurées à n’importe quel volume ? Utilisez l’API Scraper Airbnb. C’est la valeur par défaut pour la plupart des projets.
- Besoin de données historiques ou à l’échelle du marché sans code ? Utilisez le jeu de données Airbnb.
Pour des comparaisons directes d’outils dédiés, consultez nos comparatifs des meilleurs scrapers Airbnb et des meilleurs fournisseurs de données Airbnb.
Le schéma qui s’applique à tous : laisser l’infrastructure gérée s’occuper du déblocage et de la structuration pour que votre équipe consacre son temps à l’analyse, et non à surveiller des scrapers. Le réseau de Bright Data est conçu exactement pour cela, avec une conformité RGPD et CCPA, une certification ISO 27001 et une infrastructure à sourcing éthique derrière chaque requête.
Conclusion
Scraper Airbnb en 2026 concerne moins l’analyse astucieuse et davantage le choix du bon niveau d’abstraction. Le code manuel convient à l’apprentissage mais échoue sous la couche anti-bot d’Airbnb. Web Unlocker vous donne la page quand vous avez besoin d’un contrôle personnalisé. L’API Scraper Airbnb vous donne des enregistrements structurés sans aucune maintenance. Le jeu de données vous donne l’ensemble du marché sans aucun code. Commencez avec les 5 000 requêtes sur l’API Scraper, pointez-la vers les listings qui vous intéressent, et construisez à partir de là.
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “Puis-je scraper Airbnb avec de simples requêtes Python ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Pas de manière fiable. Airbnb protège ses pages avec la détection de bots DataDome. Une requête par défaut renvoie souvent une page de défi, et même quand une passe, cela échoue à grande échelle avec des CAPTCHAs, des limites de débit et des bannissements d’IP. Vous avez besoin d’un déblocage géré, d’une vraie empreinte de navigateur et de proxies, c’est pourquoi la plupart des équipes utilisent Web Unlocker ou l’API Scraper Airbnb.”
}
},
{
“@type”: “Question”,
“name”: “Quelles données l’API Scraper Airbnb peut-elle retourner ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Un seul enregistrement comprend 51 champs : titre et type de listing, tarification par nuit et totale, calendrier de disponibilité, notes et nombre d’avis, signaux hôte et superhôte, équipements, coordonnées, images, et plus encore. Vous le recevez en JSON propre sans analyse requise.”
}
},
{
“@type”: “Question”,
“name”: “Dois-je utiliser l’API Scraper ou le jeu de données prêt à l’emploi ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Utilisez l’API Scraper quand vous avez des URLs de listings ou de recherches spécifiques et souhaitez des données fraîches à la demande. Utilisez le jeu de données quand vous avez besoin d’une couverture historique ou à l’échelle du marché sans fournir d’URLs. Le jeu de données contient plus de 6,5 millions d’enregistrements et commence à 0,0025 $ par enregistrement.”
}
},
{
“@type”: “Question”,
“name”: “Combien cela coûte-t-il pour commencer ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Chaque nouveau compte Bright Data inclut 5 000 enregistrements gratuits par mois sur le Web Scraper API, Web Unlocker et l’API SERP, sans carte de crédit requise. Au-delà, le Web Scraper API commence à partir de 0,70 $ pour 1 000 enregistrements et vous ne payez que pour les données livrées.”
}
},
{
“@type”: “Question”,
“name”: “Un agent IA peut-il collecter des données Airbnb via MCP ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Oui. Le serveur Web MCP de Bright Data connecte n’importe quel LLM compatible MCP (Claude, GPT, Gemini) aux données web en direct. En mode Rapid gratuit, l’agent obtient search_engine et scrape_as_markdown à un crédit par requête, il peut donc extraire des listings Airbnb actuels à la demande sans aucun code de scraping dans votre application. Le mode Pro ajoute 60+ outils de données structurées pour les agents en production.”
}
},
{
“@type”: “Question”,
“name”: “Comment gérer les grands travaux de scraping Airbnb ?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Utilisez le point de terminaison asynchrone : déclenchez une collecte avec votre liste d’URLs, interrogez le point de terminaison de progression jusqu’à ce que le snapshot soit prêt, puis téléchargez en JSON, CSV ou NDJSON. Un seul travail gère des milliers d’URLs, et les snapshots sont disponibles pendant 30 jours.”
}
}
]
}
Questions fréquemment posées
Puis-je scraper Airbnb avec de simples requêtes Python ?
Pas de manière fiable. Airbnb protège ses pages avec la détection de bots DataDome. Une requête par défaut renvoie souvent une page de défi, et même quand une passe, cela échoue à grande échelle avec des CAPTCHAs, des limites de débit et des bannissements d’IP. Vous avez besoin d’un déblocage géré, d’une vraie empreinte de navigateur et de proxies, c’est pourquoi la plupart des équipes utilisent Web Unlocker ou l’API Scraper Airbnb.
Quelles données l’API Scraper Airbnb peut-elle retourner ?
Un seul enregistrement comprend 51 champs : titre et type de listing, tarification par nuit et totale, calendrier de disponibilité, notes et nombre d’avis, signaux hôte et superhôte, équipements, coordonnées, images, et plus encore. Vous le recevez en JSON propre sans analyse requise.
Dois-je utiliser l’API Scraper ou le jeu de données prêt à l’emploi ?
Utilisez l’API Scraper quand vous avez des URLs de listings ou de recherches spécifiques et souhaitez des données fraîches à la demande. Utilisez le jeu de données quand vous avez besoin d’une couverture historique ou à l’échelle du marché sans fournir d’URLs. Le jeu de données contient plus de 6,5 millions d’enregistrements et commence à 0,0025 $ par enregistrement.
Combien cela coûte-t-il pour commencer ?
Chaque nouveau compte Bright Data inclut 5 000 enregistrements gratuits par mois sur le Web Scraper API, Web Unlocker et l’API SERP, sans carte de crédit requise. Au-delà, le Web Scraper API commence à partir de 0,70 $ pour 1 000 enregistrements et vous ne payez que pour les données livrées.
Un agent IA peut-il collecter des données Airbnb via MCP ?
Oui. Le serveur Web MCP de Bright Data connecte n’importe quel LLM compatible MCP (Claude, GPT, Gemini) aux données web en direct. En mode Rapid gratuit, l’agent obtient search_engine et scrape_as_markdown à un crédit par requête, il peut donc extraire des listings Airbnb actuels à la demande sans aucun code de scraping dans votre application. Le mode Pro ajoute 60+ outils de données structurées pour les agents en production.
Comment gérer les grands travaux de scraping Airbnb ?
Utilisez le point de terminaison asynchrone : déclenchez une collecte avec votre liste d’URLs, interrogez le point de terminaison de progression jusqu’à ce que le snapshot soit prêt, puis téléchargez en JSON, CSV ou NDJSON. Un seul travail gère des milliers d’URLs, et les snapshots sont disponibles pendant 30 jours.






