

Dans ce tutoriel, vous verrez :
- La définition d’un Scraper de réservation
- Quelles données vous pouvez extraire avec lui
- Comment créer un script de scraping Booking.com avec Python
C’est parti !
Qu’est-ce qu’un Scraper Booking ?
Unscraper Booking.com est un outil permettant d’extraire automatiquement des données des pages Booking.com. Il vous permet de récupérer des informations à partir des pages de listes de propriétés, telles que les noms d’hôtels, les prix, les avis, les notes, les équipements et les disponibilités. Ces données peuvent être utilisées à diverses fins, notamment pour analyser le marché, comparer les prix et créer des Jeux de données liés au voyage.
Données que vous pouvez extraire de Booking.com
Vous trouverez ci-dessous une liste des points de données que vous pouvez récupérer sur Booking.com :
- Détails de l’établissement: nom de l’hôtel, adresse, distance par rapport aux points de repère (par exemple, centre-ville, centre-ville, etc.)
- Informations sur les prix: prix normal, prix réduit (si disponible)
- Avis et notes: note des avis, nombre d’avis, commentaires des clients
- Disponibilité: types de chambres disponibles, options de réservation (par exemple, annulation gratuite, petit-déjeuner inclus), dates disponibles
- Médias: photos de l’établissement, photos des chambres
- Équipements: équipements proposés (par exemple, Wi-Fi, parking, piscine), équipements spécifiques aux chambres
- Promotions: offres spéciales ou réductions, offres à durée limitée
- Politiques: politique d’annulation, heures d’arrivée et de départ
- Détails supplémentaires: description de l’établissement, attractions à proximité, nombre de chambres disponibles pour des dates spécifiques
Scraping de Booking.com en Python : guide étape par étape
Dans cette section guidée, vous apprendrez à créer un Scraper Booking.com.
L’objectif est de créer un script Python qui recueille automatiquement les données de la page de liste des propriétés :
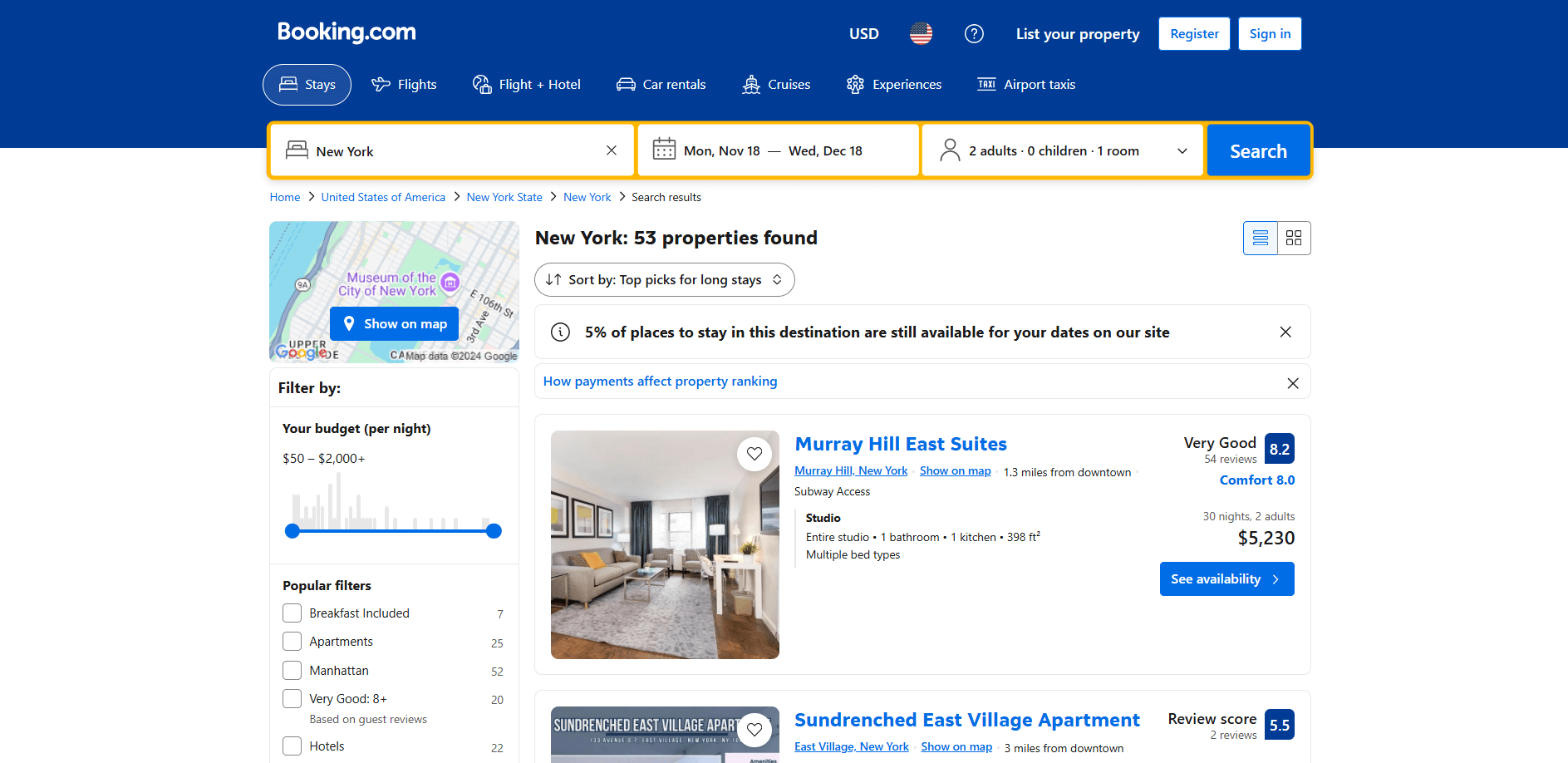
Suivez les étapes ci-dessous !
Étape n° 1 : configuration du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le, lancez le fichier exécutable et suivez l’assistant d’installation.
À présent, utilisez les commandes ci-dessous pour créer un dossier pour votre projet :
mkdir booking-scraper
Le répertoire booking-scraper représente le dossier de projet de votre script Python de scraping de Booking.com.
Entrez-y et initialisez un environnement virtuel à l’intérieur :
cd booking-Scraper
python -m venv env
Chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python et PyCharm Community Edition sont tous deux d’excellents choix.
Créez un fichier scraper.py dans le dossier du projet, qui doit contenir cette structure de fichiers :
scraper.py est actuellement un script Python vide, mais il contiendra bientôt la logique de scraping.
Dans le terminal de l’IDE, activez l’environnement virtuel. Pour ce faire, sous Linux ou macOS, exécutez cette commande :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Incroyable, vous disposez désormais d’un environnement Python pour le Scraping web !
Étape n° 2 : sélectionner la bibliothèque de scraping
Il est temps de déterminer si Booking.com est un site statique ou dynamique et de sélectionner la bibliothèque de scraping appropriée en conséquence. Pour ce faire, vous pouvez inspecter le comportement du site. Commencez par ouvrir Booking.com dans votre navigateur. Effectuez une recherche et accédez à la page de la propriété :
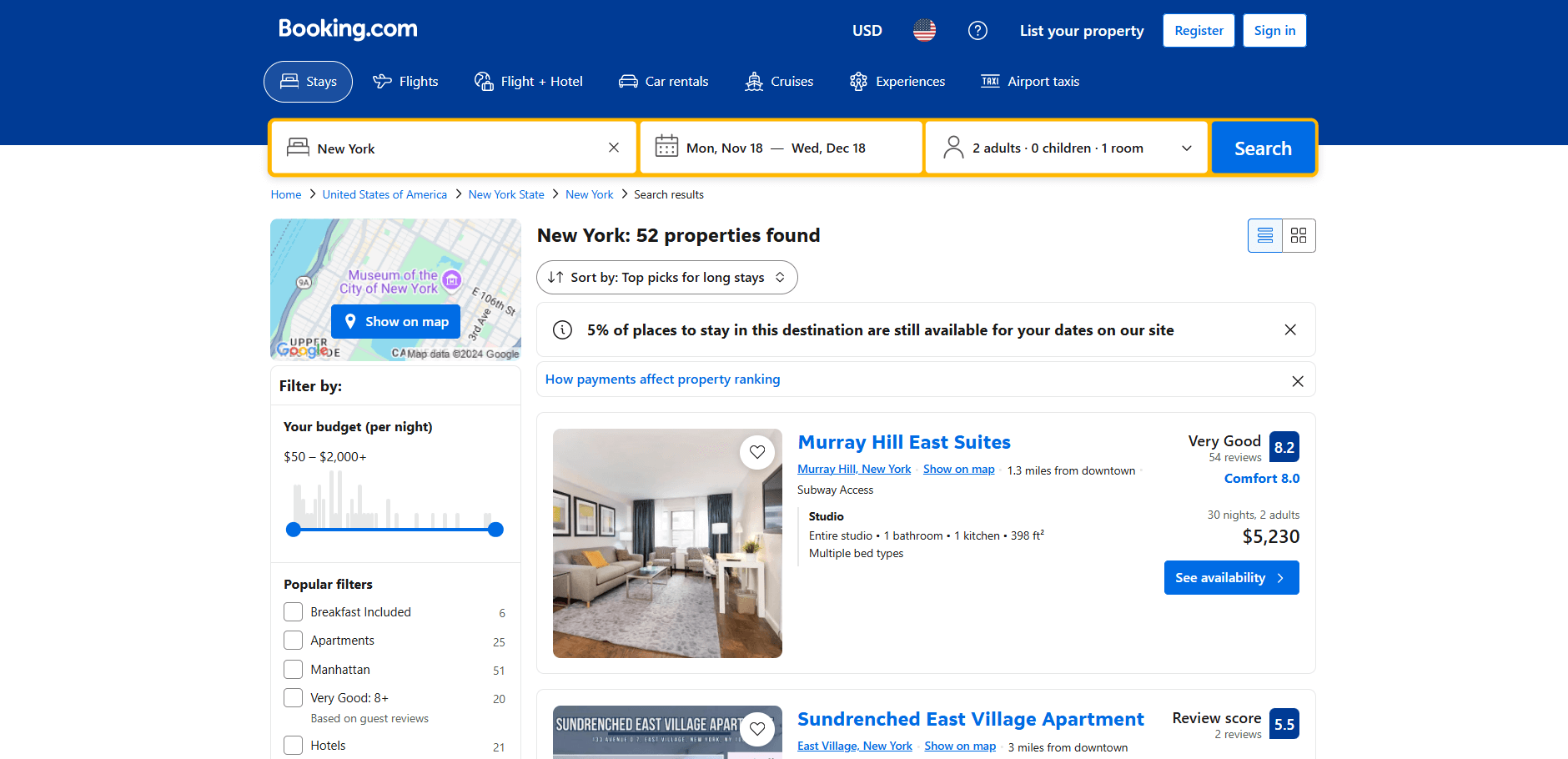
Remarquez que la page charge de nouvelles données de manière dynamique lorsque vous faites défiler vers le bas :
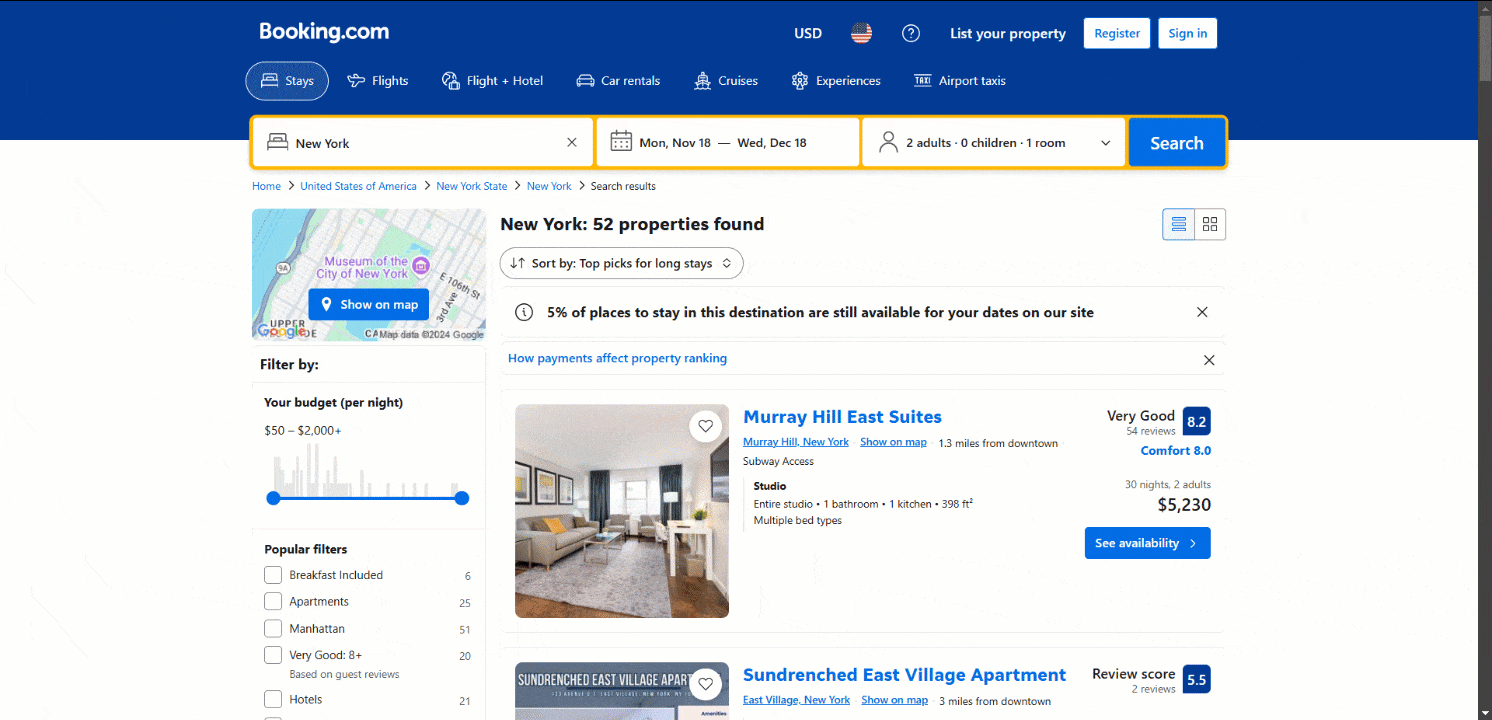
Ce modèle est connu sous le nom de défilement infini et est une caractéristique des sites dynamiques. En savoir plus sur la manière d’effectuer le Scraping web sur des sites dynamiques.
Sans même plonger dans le code HTML du document renvoyé par le serveur ou inspecter l’onglet Réseau dans DevTools (deux étapes courantes pour comprendre si un site est statique ou non), nous pouvons déjà conclure que Booking.com est un site dynamique.
La meilleure approche pour extraire les données d’un site à contenu dynamique consiste à utiliser un outil de scraping du navigateur. Ces solutions vous permettent de contrôler un navigateur et d’effectuer des interactions spécifiques sur la page afin d’extraire efficacement les données.
L’un des outils d’automatisation de navigateur les plus puissants pour Python est Selenium, ce qui en fait un excellent choix pour le scraping de Booking.com. Préparez-vous à l’installer, car ce sera la bibliothèque principale pour cette tâche !
Étape n° 3 : installer et configurer Selenium
En Python, Selenium est disponible via le paquet pip selenium. Dans un environnement virtuel Python activé, installez-le à l’aide de cette commande :
pip install selenium
Pour obtenir des conseils sur l’utilisation de cet outil, consultez notre tutoriel sur le Scraping web avec Selenium.
Importez Selenium dans scraper.py et initialisez un objet WebDriver pour contrôler une instance Chrome :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# créer une instance de pilote Web Chrome
driver = webdriver.Chrome(service=Service())
Le code ci-dessus initialise une instance Chrome WebDriver pour contrôler un navigateur Chrome. Notez que Booking.com semble utiliser une technologie anti-scraping qui bloque les navigateurs sans interface graphique. Évitez donc de définir le drapeau --headless. Comme solution alternative, consultez notre guide sur Playwright Stealth.
À la dernière ligne de votre Scraper, n’oubliez pas de fermer le pilote Web :
driver.quit()
Parfait ! Vous êtes désormais prêt à commencer à scraper Booking.com.
Étape n° 4 : visitez la page cible
Les pages de Booking.com offrent de nombreuses fonctionnalités interactives pour affiner votre recherche :
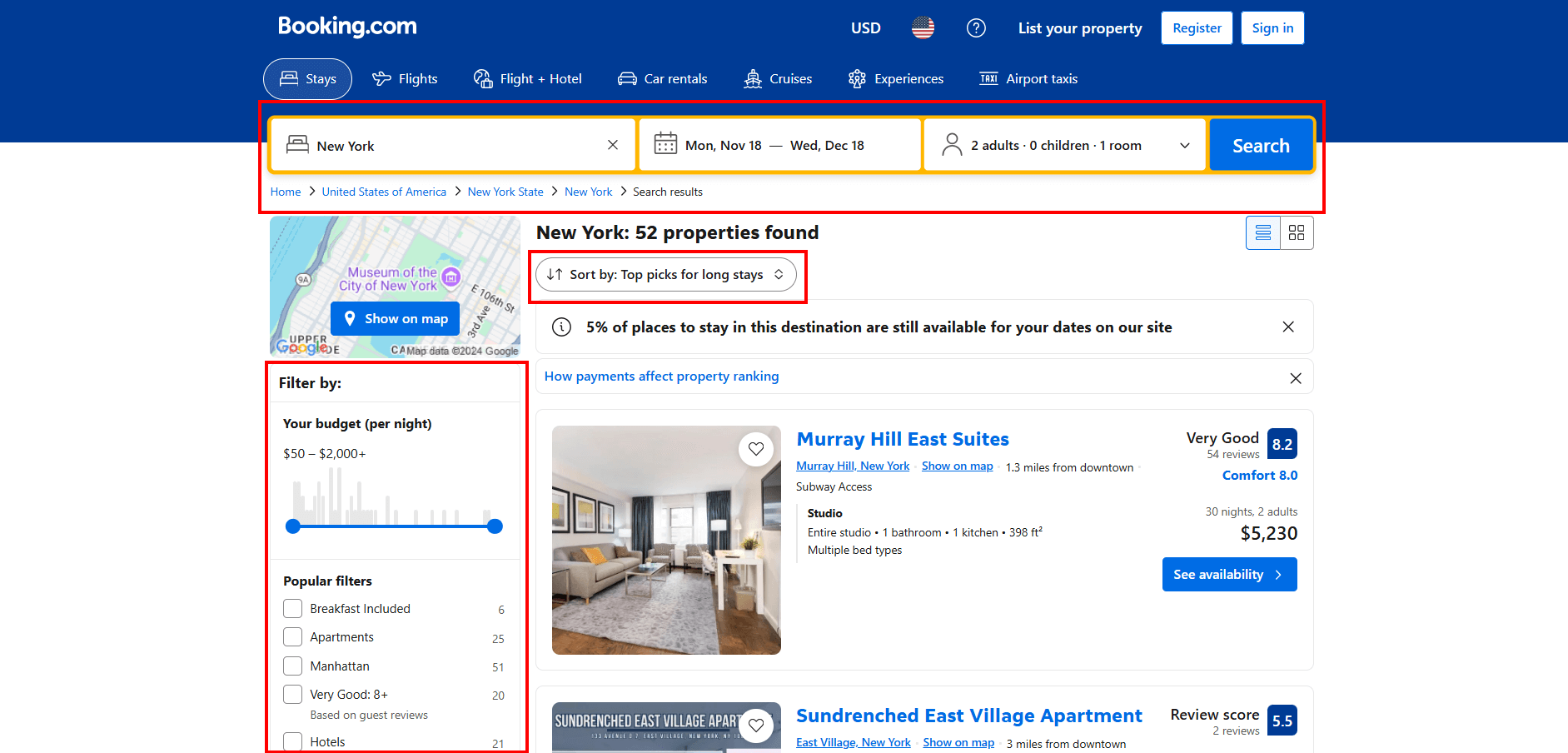
Simuler toutes ces interactions de manière programmatique avec Selenium serait complexe et fastidieux. Pour simplifier et accélérer le processus, effectuez d’abord les interactions manuellement dans votre navigateur.
Une fois que vous avez configuré une requête de recherche qui vous intéresse, copiez l’URL de la page résultante à partir de la barre d’adresse de votre navigateur.
Par exemple, l’URL ci-dessus correspond à une recherche d’appartements à New York du 18 novembre au 18 décembre pour deux adultes.
Copiez l’URL et insérez-la dans la méthode get() proposée par Selenium :
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
Votre script de scraping se connectera automatiquement à la page Booking.com souhaitée.
Le fichier scraper.py contiendra désormais les lignes de code suivantes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# créer une instance de pilote web Chrome
driver = webdriver.Chrome(service=Service())
# se connecter à la page cible
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# logique de scraping...
# fermer le pilote web et libérer ses ressources
driver.quit()
Placez un point d’arrêt de débogage sur la dernière ligne et exécutez le script. Voici ce que vous devriez voir :
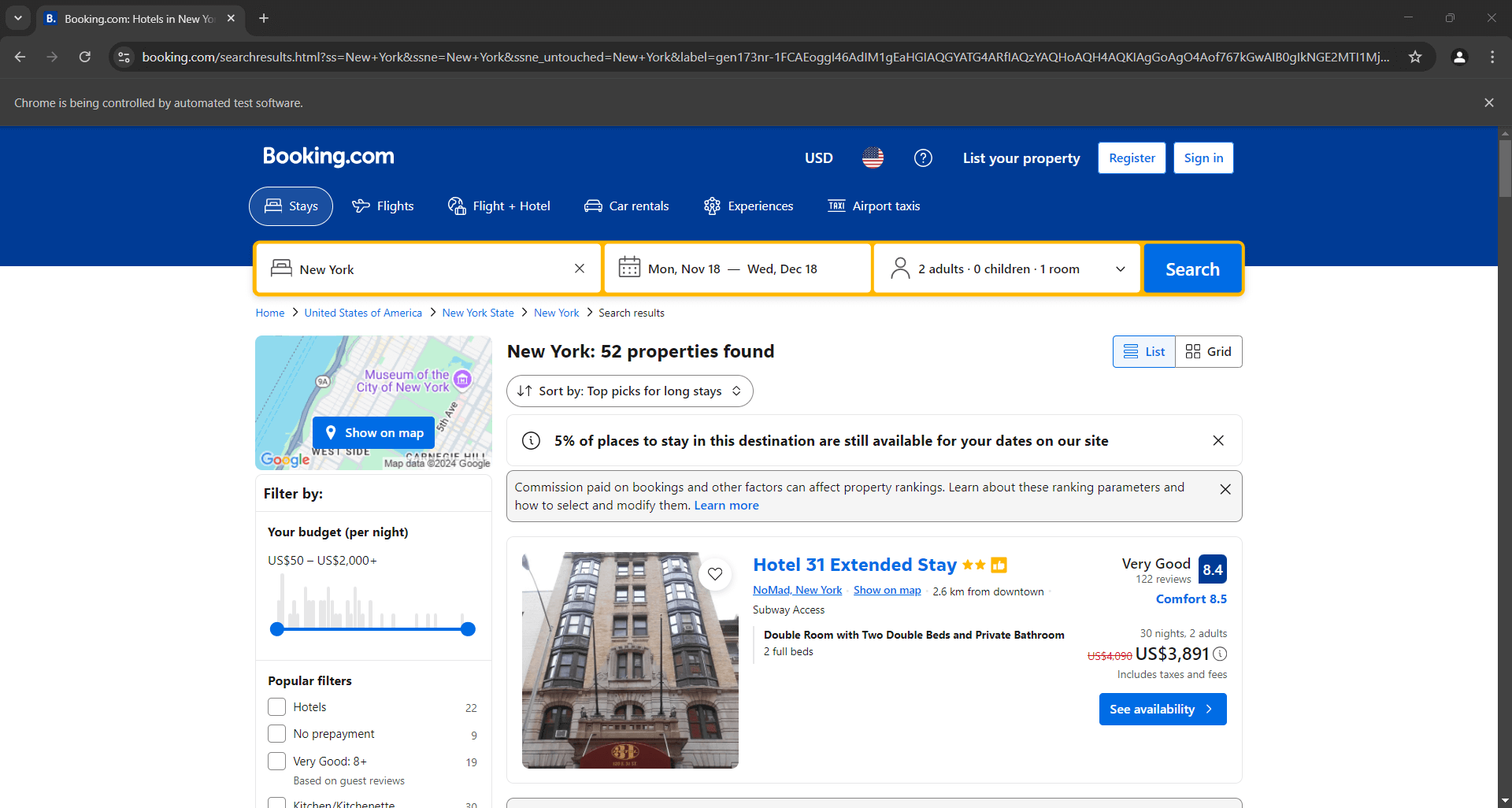
Le message « Chrome est contrôlé par un logiciel de test automatisé » certifie que Selenium fonctionne comme prévu sur Chrome. Bravo !
Étape n° 5 : gérer l’alerte de connexion
Lorsque vous visitez Booking.com pour la première fois dans un navigateur, le site affiche souvent une alerte de connexion dans les 20 premières secondes. Cela bloque l’accès au contenu de la page, ce qui rend le Scraping web plus difficile :
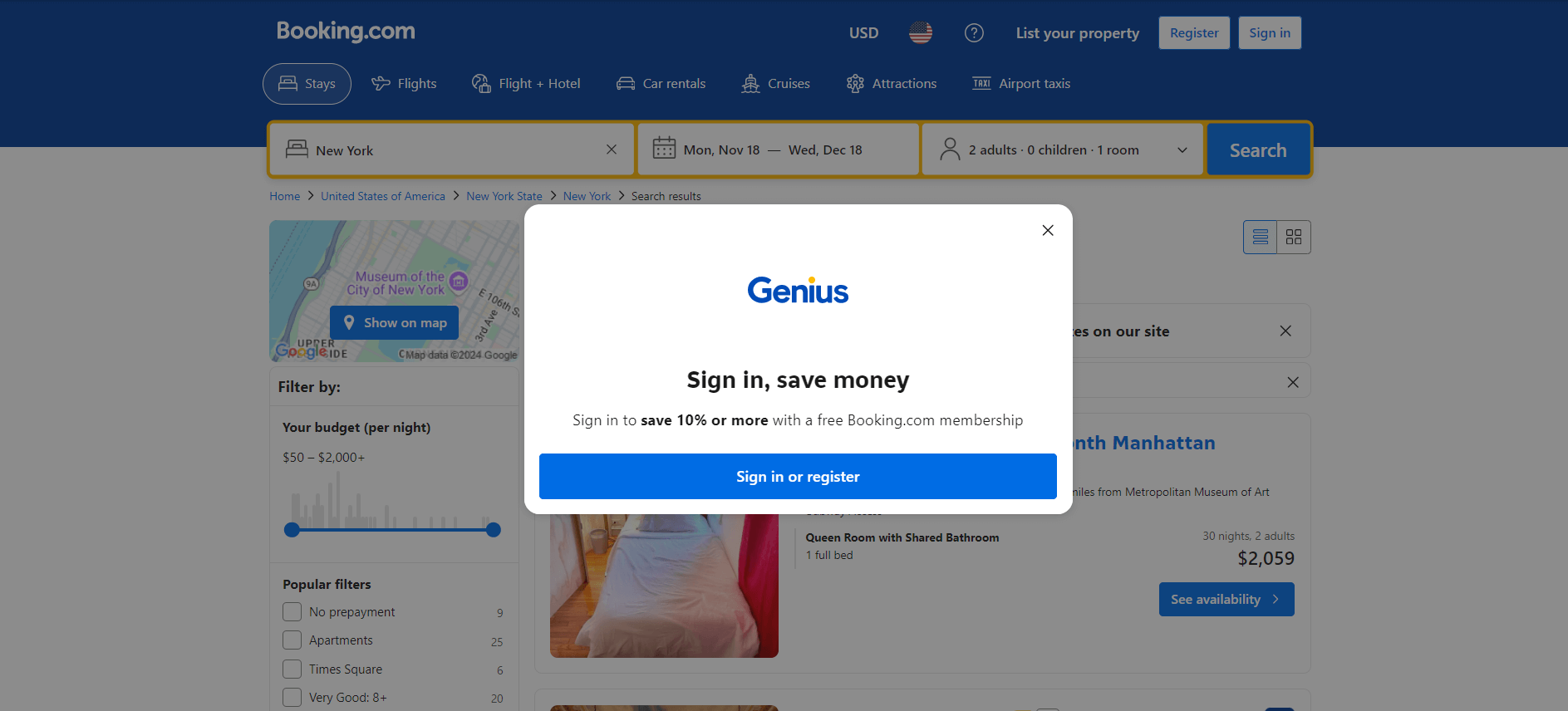
Tant que vous n’interagissez pas avec cette alerte, vous ne pouvez pas accéder au contenu de la page sous-jacente.
Pour gérer l’alerte, fermez-la à l’aide de Selenium. Cliquez avec le bouton droit de la souris sur le bouton Fermer et sélectionnez l’option « Inspecter » dans le menu contextuel :
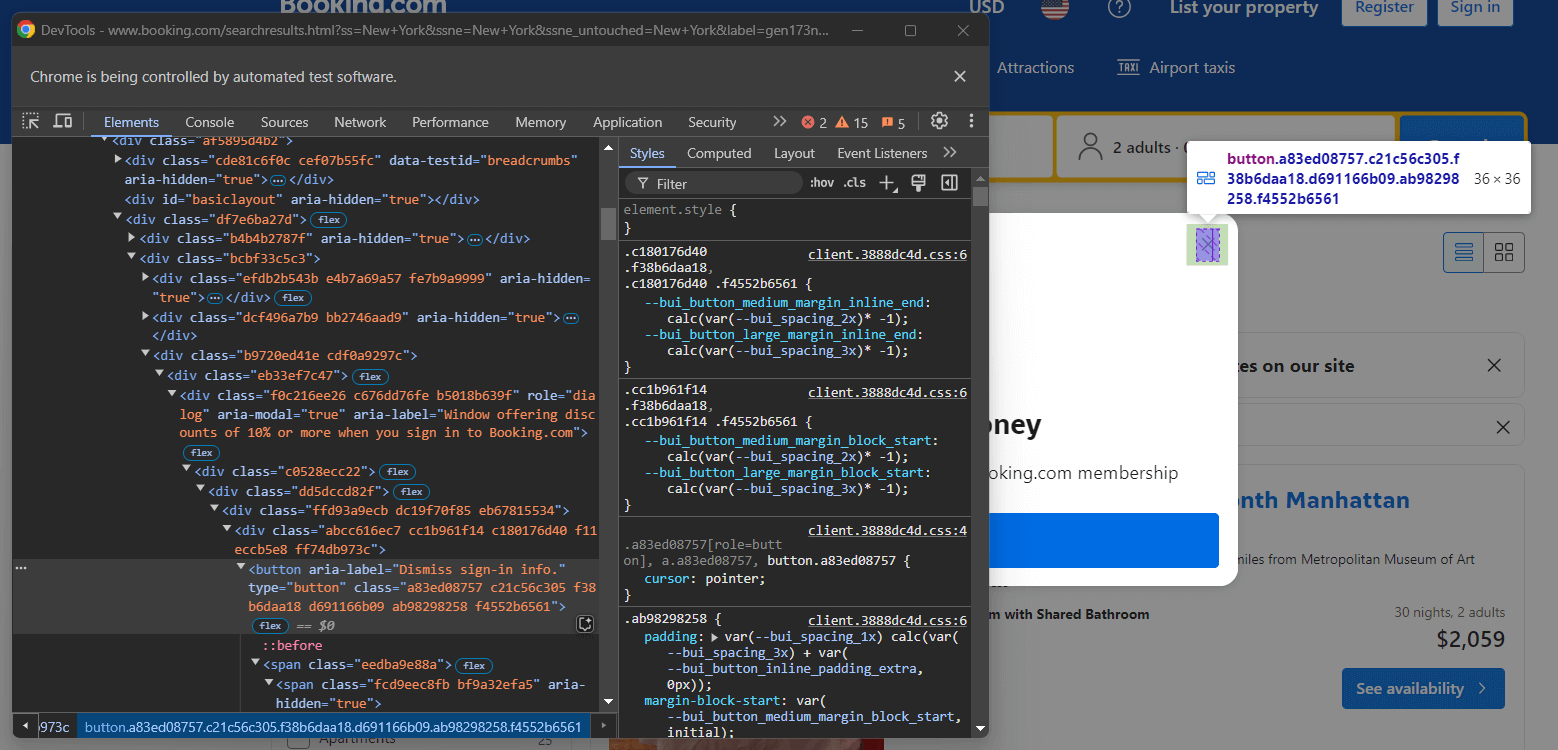
Notez que vous pouvez fermer la fenêtre modale en sélectionnant le bouton avec le sélecteur CSS suivant :
[role="dialog"] button[aria-label="Ignorer les informations de connexion."]
Demandez maintenant à Selenium d’attendre jusqu’à 10 secondes que l’alerte apparaisse. Une fois qu’elle s’affiche, fermez-la en cliquant sur le bouton « Ignorer ». Comme la fenêtre modale n’apparaît pas toujours, il est judicieux d’encapsuler cette logique dans un bloc try...except:
try:
# attendre jusqu'à 20 secondes que l'alerte de connexion apparaisse
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# cliquer sur le bouton Fermer
close_button.click()
except TimeoutException:
print("La fenêtre modale de connexion ne s'est pas affichée, continuation...")
WebDriverWait est une classe Selenium spécialisée qui met le script en pause jusqu’à ce qu’une condition spécifiée sur la page soit remplie. Dans l’exemple ci-dessus, elle attend jusqu’à 10 secondes que le bouton de fermeture de l’alerte apparaisse sur la page.
Si l’alerte n’apparaît pas, Selenium déclenche l’exception TimeoutException. Importez-la avec WebDriverWait, EC et By comme ci-dessous :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
Parfait ! L’alerte de connexion n’est plus un problème.
Étape n° 6 : sélectionnez les éléments Booking.com
Notez que la page Booking.com à scraper contient plusieurs éléments. Comme vous souhaitez tous les scraper, initialisez un tableau dans lequel stocker les données scrapées :
items = []
Vous devez maintenant comprendre comment sélectionner les éléments HTML associés à ces éléments. Ouvrez Booking.com dans votre navigateur, effectuez une recherche et inspectez l’un des éléments de propriété :
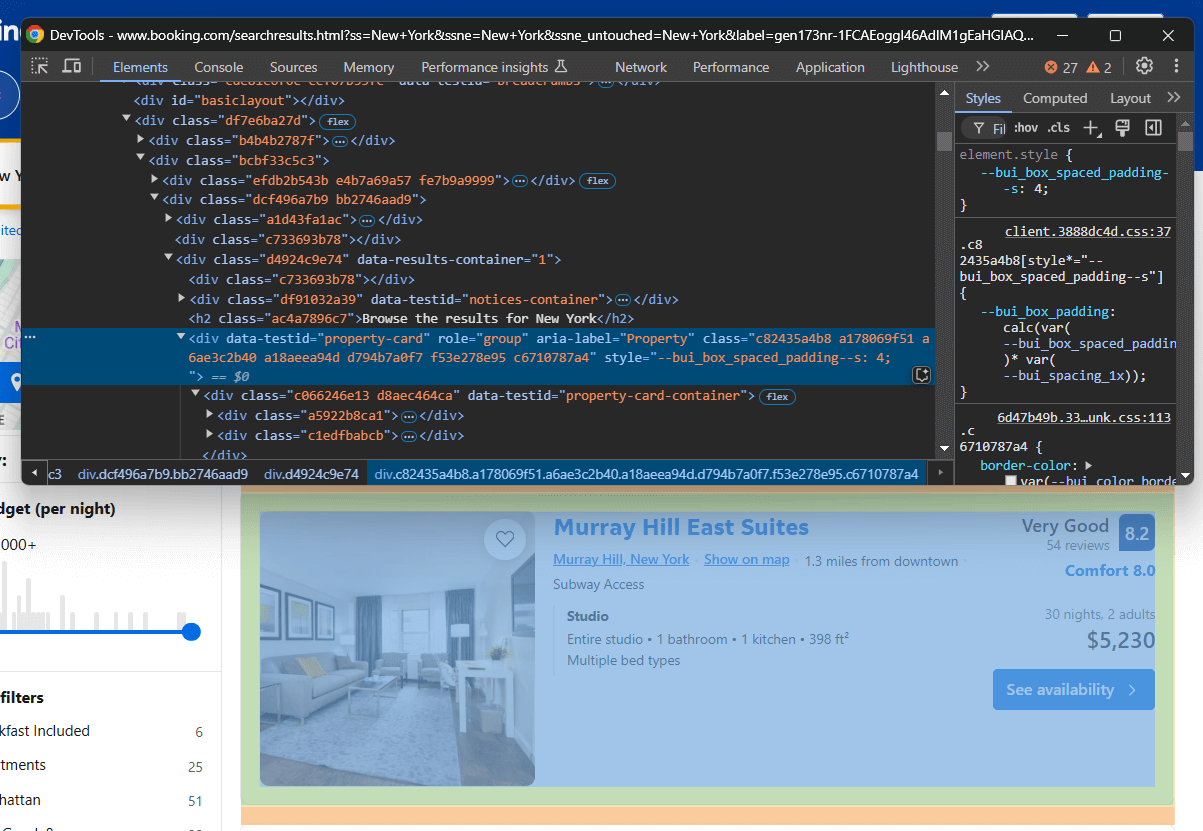
Notez que les classes des éléments HTML semblent être générées de manière aléatoire. Cela signifie qu’elles sont susceptibles de changer à chaque déploiement du site, ce qui les rend peu fiables pour la sélection des éléments. Concentrez-vous plutôt sur des attributs plus stables tels que data-testid.
Les attributsdata-* sont d’excellentes cibles pour le Scraping web.
Utilisez la méthode Selenium find_elements() pour appliquer un sélecteur CSS à la page et sélectionner les éléments qui vous intéressent :
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
Parcourez les éléments de propriété et préparez votre Scraper Booking.com pour extraire certaines données :
for property_item in property_items:
# logique de scraping...
Super ! L’étape suivante consiste à extraire les données de ces éléments.
Étape n° 7 : extraire les éléments de Booking.com
Examinez les éléments de propriété sur la page et remarquez que les éléments qu’ils contiennent ne sont pas cohérents :
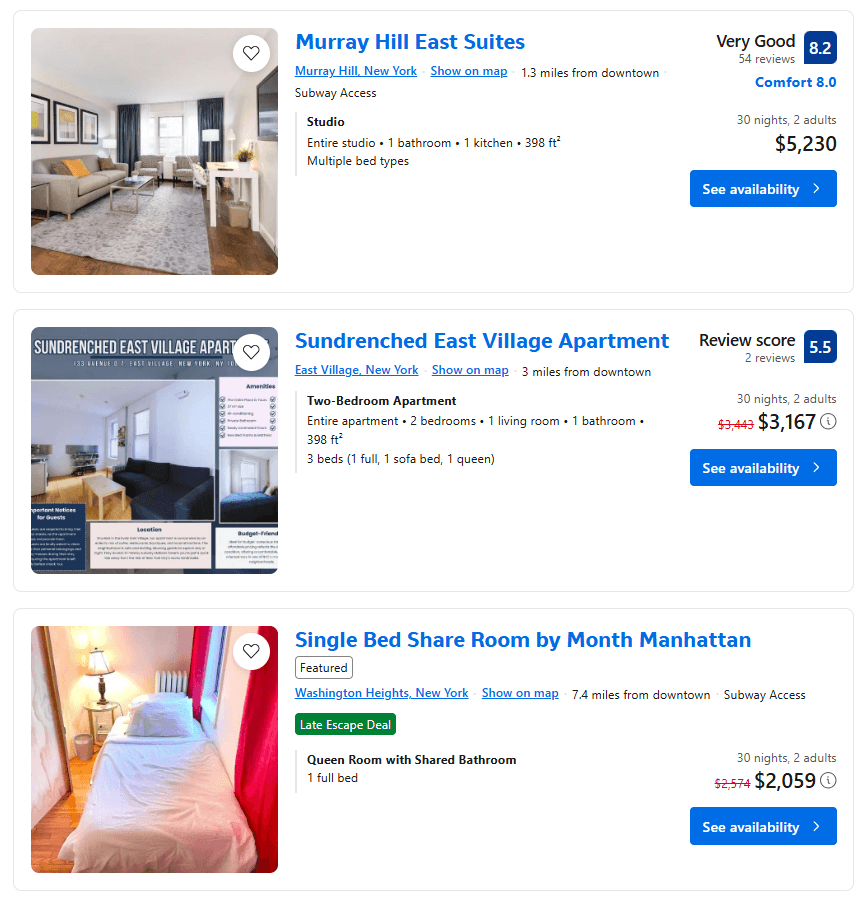
Certains ont une note d’évaluation, d’autres non. De même, certains ont un prix réduit, d’autres non.
Ces différences rendent difficile l’écriture d’une logique de scraping cohérente pour tous les éléments de propriété. Lorsque vous essayez de sélectionner un élément qui ne se trouve pas sur la page, Selenium génère une exception NoSuchElementException. Il est donc logique de définir une fonction pour gérer ce scénario :
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
La fonction ci-dessus accepte une fonction lambda et tente de l’exécuter. Si elle génère une exception NoSuchElementException, elle intercepte l’exception et renvoie None. Cela permet à votre script de scraping Booking.com de continuer sans interruption.
Importez NoSuchElementException:
from selenium.common import NoSuchElementException
Inspectez un élément de propriété qui contient tous les éléments (note d’évaluation, prix réduit, etc.) :
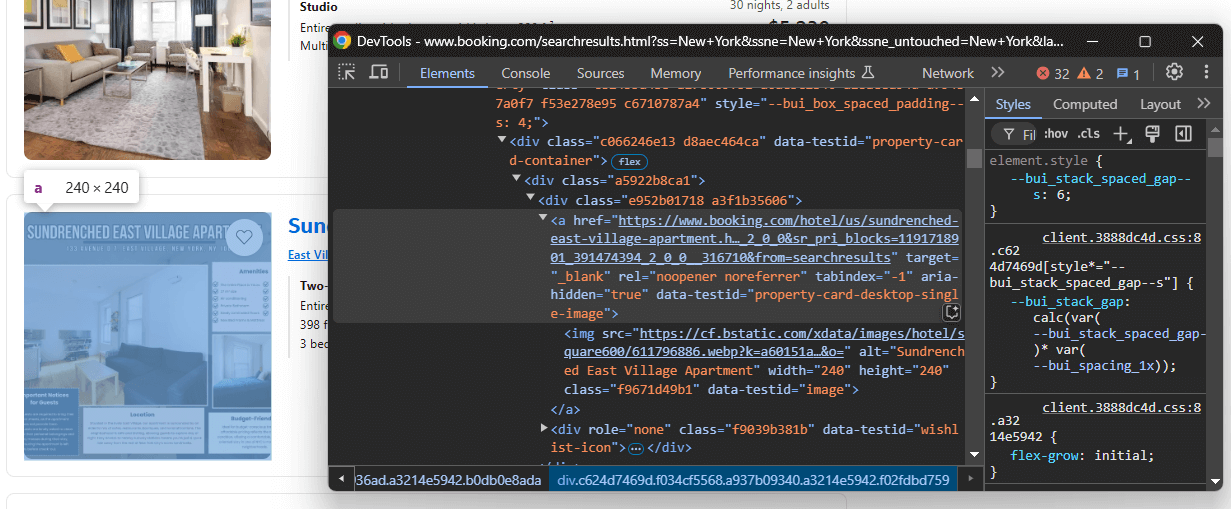
Notez que vous pouvez extraire :
- Le lien vers la propriété à partir de
a[data-testid="property-card-desktop-single-image"] - L’image de la propriété à partir de
img[data-testid=image]
Dans la boucle for, appliquez la logique actuelle pour sélectionner ces éléments et en extraire les données :
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
find_element() sélectionne un seul nœud sur la page, tandis que get_attribute() récupère le contenu à l’intérieur de l’attribut HTML spécifié. Notez que les instructions d’extraction de données sont encapsulées dans handle_no_such_element_exception afin de gérer les exceptions NoSuchElementExceptions.
De même, concentrez-vous sur les informations dans la section titre et juste en dessous :
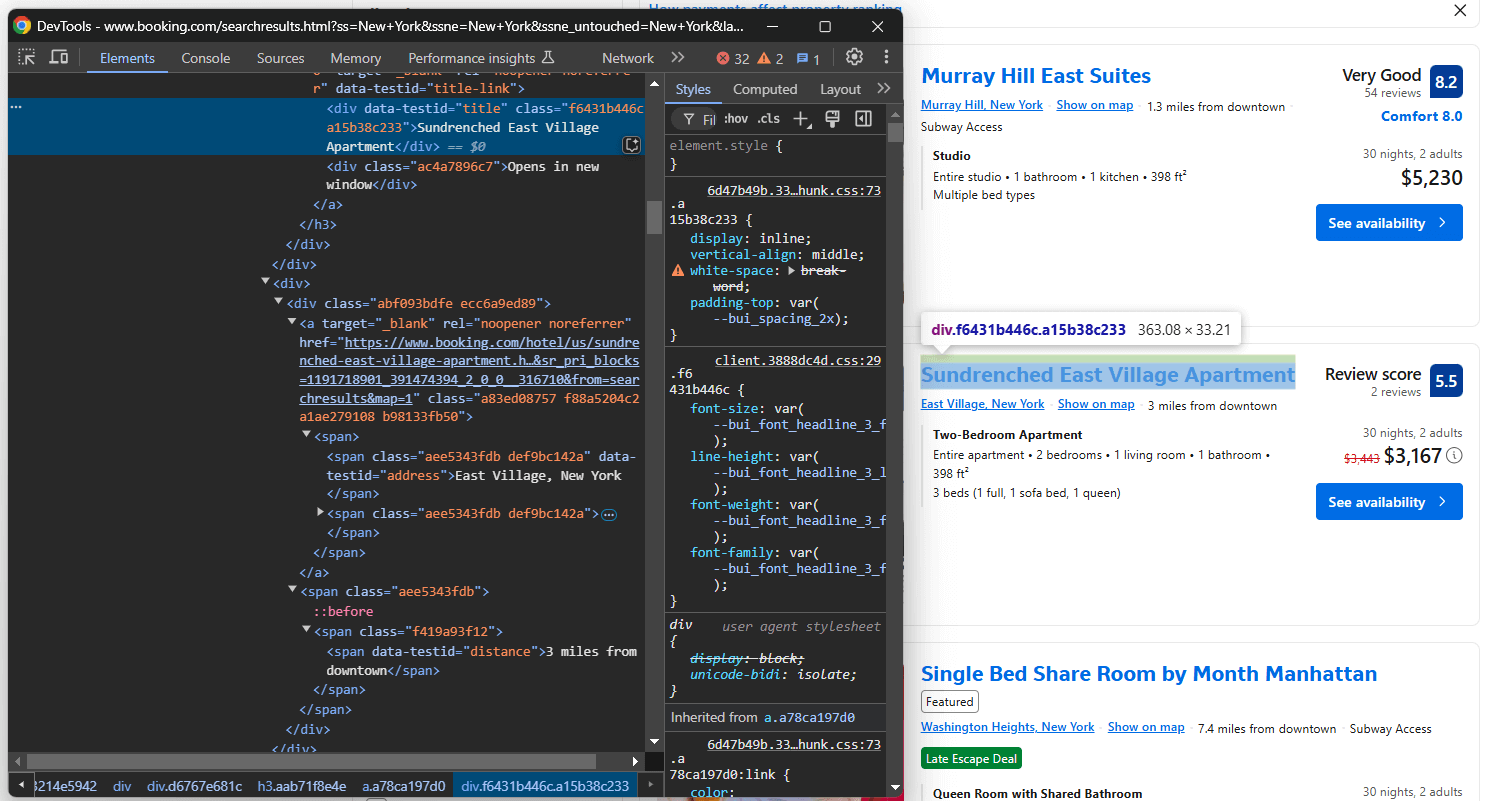
Ici, vous pouvez obtenir :
- Le titre de la propriété à partir de
[data-testid="title"] - La propriété address à partir de
[data-testid="address"] - La propriété distance à partir de
[data-testid="distance"]
Récupérez toutes ces informations à l’aide de :
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
L’attribut text contient le texte à l’intérieur des éléments sélectionnés.
Ensuite, concentrez-vous sur le nœud de la note d’évaluation :
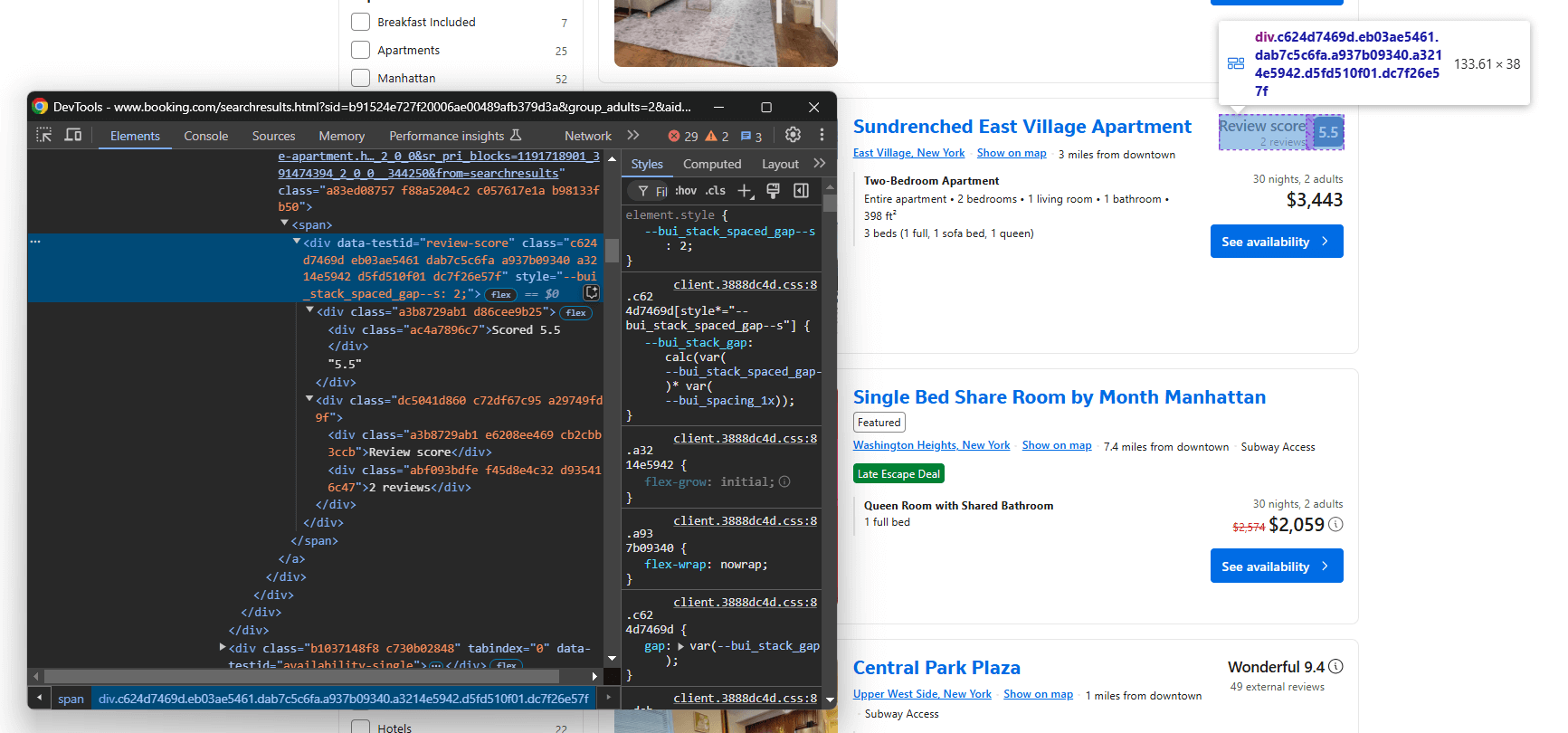
Sélectionnez-le avec data-testid="review-score" et extrayez son texte. Notez que le texte a un format spécial, comme dans cet exemple :
« Note : 8,4n8,4nTrès bonn120 avis »
À l’aide d’une logique personnalisée, vous pouvez en extraire la note et le nombre d’avis :
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# diviser la chaîne d'avis par n
parts = review_text.split("n")
# traiter chaque partie
for part in parts:
part = part.strip()
# vérifier si cette partie est un nombre (note potentielle de l'avis)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# vérifier s'il contient la chaîne « reviews »
elif « reviews » in part :
# extraire le nombre avant « reviews »
review_count = int(part.split(" ")[0].replace(«,», «»))
Ciblez l’élément description :
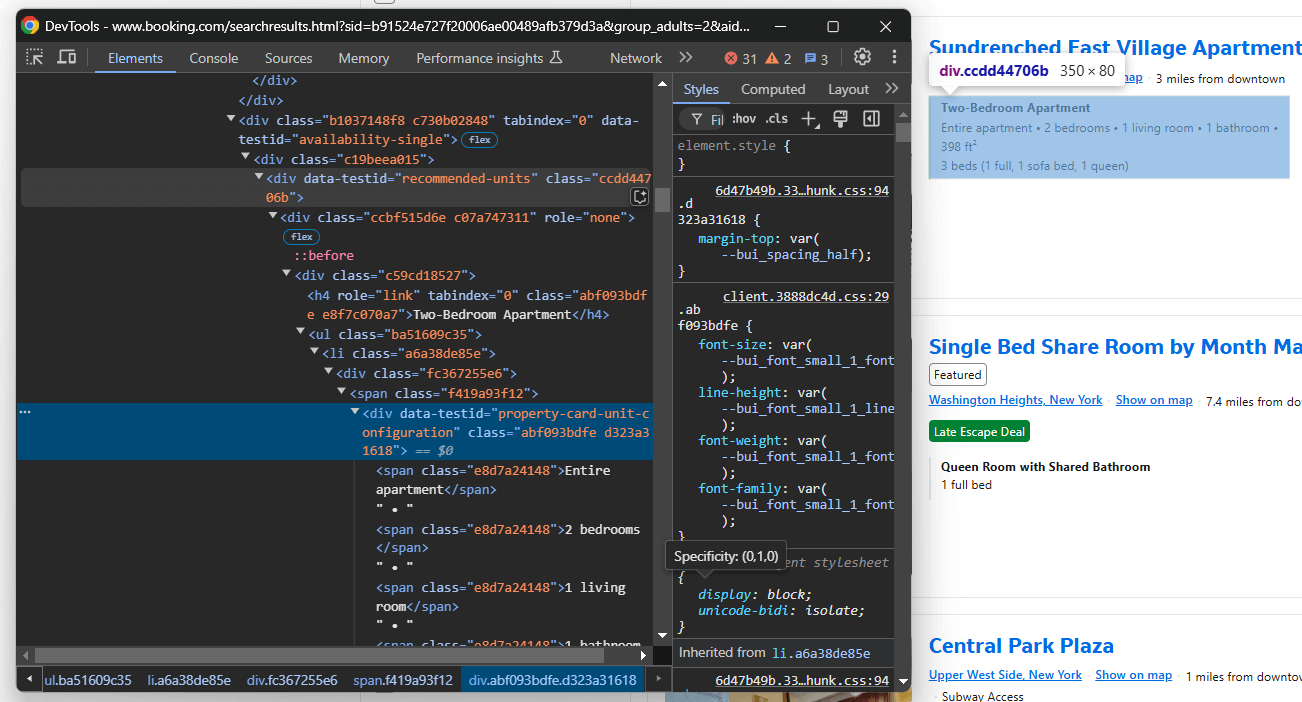
Sélectionnez-le avec data-testid="recommended-units" et récupérez la description :
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
Enfin, concentrez-vous sur les éléments de prix :
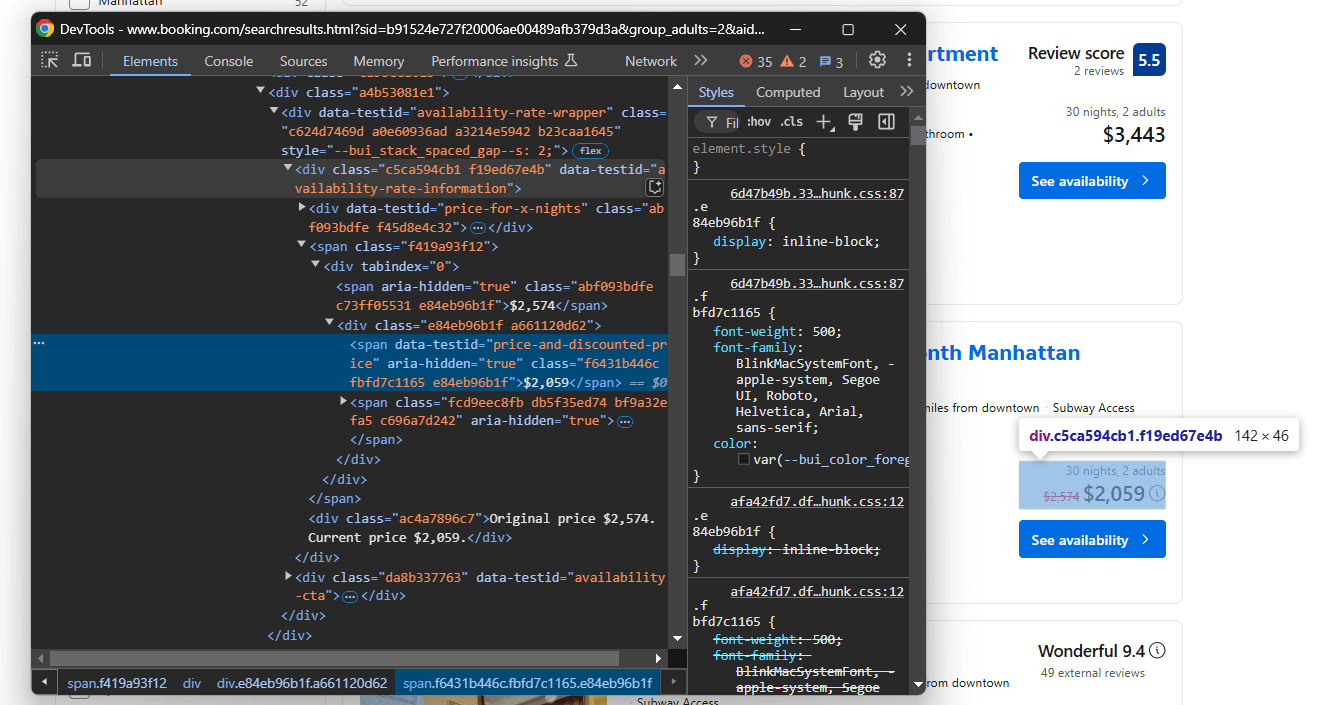
À partir de l’élément data-testid="availability-rate-information", sélectionnez :
- Le prix d’origine à partir du nœud qui possède l’attribut
aria-hidden="true"et qui ne possède pas l’attributdata-testid - Le prix réduit/actuel à partir de
data-testid="price-and-discounted-price"
Écrivez la logique d’extraction du prix comme suit :
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
Waouh ! La logique de scraping de Booking.com est presque terminée.
Étape n° 7 : collecter les données extraites
Vous disposez désormais des données extraites réparties dans plusieurs variables au sein de la boucle « for ». Créez un nouvel objet « item », remplissez-le avec ces données et ajoutez-le au tableau « items »:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
« review_score » : review_score,
« review_count » : review_count,
« description » : description,
« original_price » : original_price,
« price » : price
}
items.append(item)
À la fin de la boucle for, items contiendra toutes vos données récupérées. Vérifiez cela en affichant items :
print(items)
Cela produira le résultat suivant :
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'Murray Hill East Suites', 'address': 'Murray Hill, New York', 'distance': « 1,3 mile du centre-ville », « review_score » : 8,2, « review_count » : 54, « description » : « StudioStudio entier • 1 salle de bain • 1 cuisine • 398 ft²nPlusieurs types de lits », « original_price » : Aucun, « price » : « 5230 $ »},
# omis pour plus de concision...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': « Manhattan, New York », « distance » : « 0,6 mile du centre-ville », « review_score » : 8,4, « review_count » : 2209, « description » : « Chambre King avec 1 lit king size », « original_price » : « 20060 $ », « price » : « 18054 $ »}]
Fantastique ! Il ne reste plus qu’à exporter ces informations vers un fichier lisible par l’utilisateur, tel qu’un fichier CSV.
Étape n° 8 : Exporter vers CSV
Importez le package csv depuis la bibliothèque standard Python :
import csv
Ensuite, utilisez-le pour exporter les éléments vers un fichier CSV :
# spécifiez le nom du fichier CSV de sortie
output_file = "properties.csv"
# exportez la liste des éléments vers un fichier CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
#créer un objet d'écriture CSV
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# écrire la ligne d'en-tête
writer.writeheader()
# écrire chaque élément sous forme de ligne dans le CSV
writer.writerows(items)
Cet extrait remplit un fichier CSV nommé properties.csv à l’aide des données provenant des tableaux d'éléments. Les fonctions clés utilisées ci-dessus sont les suivantes :
open(): ouvre le fichier spécifié en mode écriture avec un encodage UTF-8.csv.DictWriter(): crée un éditeur CSV avec les noms de champs donnés.writeheader(): Écrit la ligne d’en-tête dans le fichier CSV en fonction des noms de champs spécifiés.writer.writerow(): Écrit chaque élément du dictionnaire sous forme de ligne dans le fichier CSV.
Étape n° 9 : assembler le tout
scraper.py devrait maintenant contenir ces lignes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# créer une instance de pilote Web Chrome
driver = webdriver.Chrome(service=Service())
# se connecter à la page cible
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# gérer l'alerte de connexion
try:
# attendre jusqu'à 20 secondes que l'alerte de connexion apparaisse
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# cliquer sur le bouton Fermer
close_button.click()
except e:
print("La fenêtre modale de connexion ne s'est pas affichée, continuer...")
# où stocker les données récupérées
items = []
# sélectionner tous les éléments de propriété sur la page
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# parcourir les éléments de propriété et
# en extraire les données
for property_item in property_items:
# logique de récupération...
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# diviser la chaîne d'avis par n
parts = review_text.split("n")
# traiter chaque partie
for part in parts:
part = part.strip()
# vérifier si cette partie est un nombre (note potentielle de l'avis)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# vérifier si elle contient la chaîne « reviews »
elif "reviews" in part:
# extraire le nombre avant « reviews »
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
# remplir un nouvel élément avec les données récupérées
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
« review_score » : review_score,
« review_count » : review_count,
« decription » : decription,
« original_price » : original_price,
« price » : price
}
# ajouter le nouvel élément à la liste des éléments récupérés
items.append(item)
# spécifier le nom du fichier CSV de sortie
output_file = "properties.csv"
# exporter la liste des éléments vers un fichier CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
#créer un objet CSV writer
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# écrire la ligne d'en-tête
writer.writeheader()
# écrire chaque élément sous forme de ligne dans le CSV
writer.writerows(items)
# fermer le pilote Web et libérer ses ressources
driver.quit()
Incroyable, non ? En seulement 110 lignes, vous venez de créer un Scraper Python pour Booking.com.
Vérifiez qu’il fonctionne en exécutant le script de scraping. Sous Windows, lancez le Scraper avec :
python Scraper.py
De manière équivalente, sous Linux ou macOS, exécutez :
python3 Scraper.py
Attendez que le script ait fini de s’exécuter. Un fichier properties.csv apparaîtra dans le répertoire racine de votre projet. Ouvrez le fichier pour afficher les données extraites :
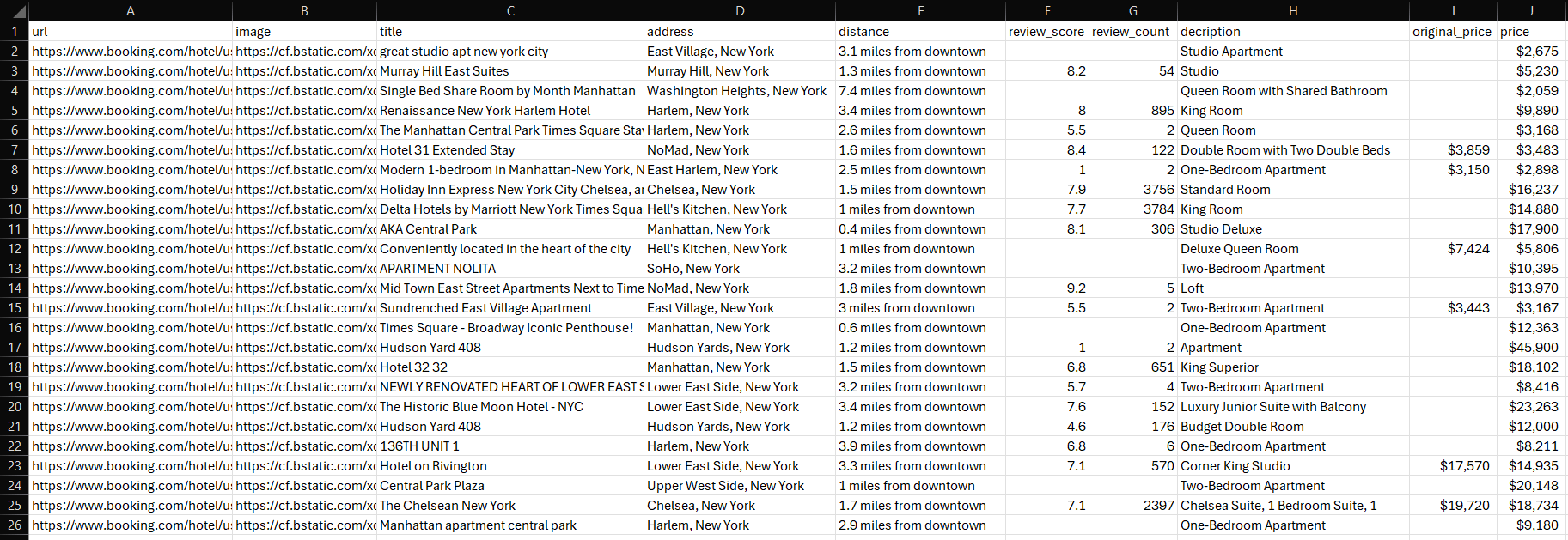
Félicitations, mission accomplie !
Conclusion
Dans ce tutoriel, vous avez appris ce qu’est un Scraper Booking.com et comment en créer un à l’aide de Python. Comme vous l’avez vu, la création d’un script de base pour récupérer automatiquement des données depuis Booking.com ne nécessite que quelques lignes de code.
Cependant, l’exemple présenté ici n’aborde pas la plupart des difficultés que vous pourriez rencontrer lors du scraping de Booking.com. Des problèmes tels que les mesures anti-navigateurs headless, la gestion des interactions utilisateur pour générer des résultats de recherche et le défilement infini peuvent rapidement compliquer vos opérations de scraping.
Vous recherchez une solution de scraping plus simple, complète et puissante ? Essayez l’API Booking Scraper de Bright Data!
L’API Booking Scraper fournit des points de terminaison puissants pour extraire les données publiques des hôtels, les avis, les notes et bien plus encore. Grâce à des appels API simples, vous pouvez récupérer des données aux formats JSON ou HTML.
Vous préférez les solutions prêtes à l’emploi ? Bright Data propose également des Jeux de données Booking.com prêts à l’emploi!
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données.





