

Dans cet article, vous découvrirez :
- Quels produits Bright Data fournit sur Databricks.
- Comment créer un compte Databricks et récupérer toutes les informations d’identification nécessaires pour la récupération et l’exploration programmatiques des données.
- Comment interroger un jeu de données Bright Data à l’aide de Databricks :
- API REST
- CLI
- Connecteur SQL
C’est parti !
Produits de données Bright Data sur Databricks
Databricks est une plateforme d’analyse ouverte permettant de créer, déployer, partager et gérer à grande échelle des données, des analyses et des solutions d’IA de niveau professionnel. Sur le site web, vous trouverez des produits de données provenant de plusieurs fournisseurs, ce qui en fait l’une des meilleures places de marché de données.
Bright Data a récemment rejoint Databricks en tant que fournisseur de produits de données et propose déjà plus de 40 produits :
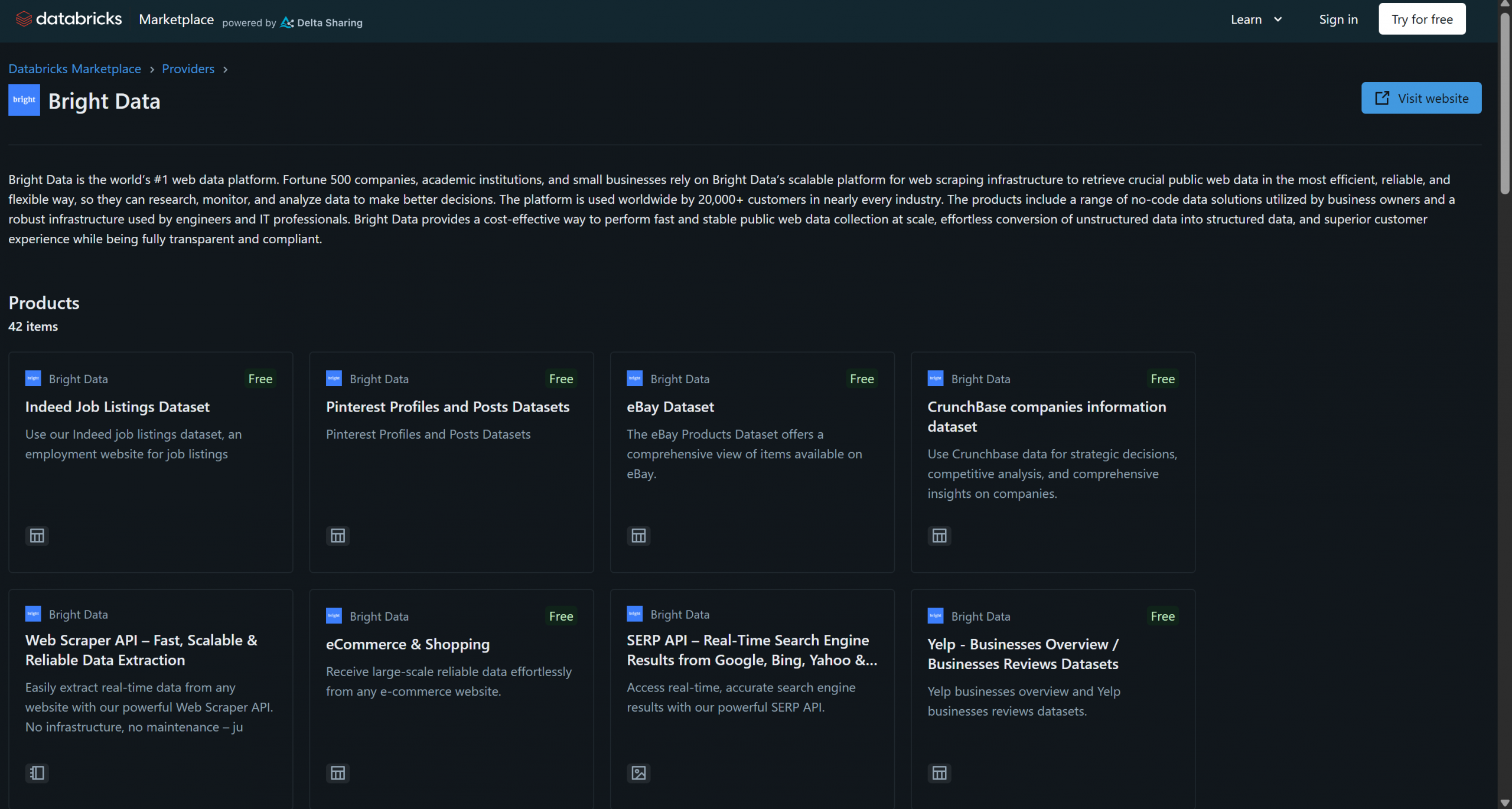
Ces solutions comprennent des jeux de données B2B, des jeux de données d’entreprises, des jeux de données financières, des jeux de données immobilières et bien d’autres encore. En outre, vous avez également accès à des solutions plus générales de récupération de données web et de Scraping web grâce à l’infrastructure de Bright Data, telles que le Navigateur de scraping et l’API Web Scraper.
Dans ce tutoriel, vous apprendrez à interroger par programmation les données de l’un de ces Jeux de données Bright Data à l’aide de l’API Databricks, de l’interface CLI et de la bibliothèque SQL Connector dédiée. C’est parti !
Premiers pas avec Databricks
Pour interroger les jeux de données Bright Data à partir de Databricks via l’API ou l’interface CLI, vous devez d’abord configurer quelques éléments. Suivez les étapes ci-dessous pour configurer votre compte Databricks et récupérer toutes les informations d’identification nécessaires pour accéder aux jeux de données Bright Data et les intégrer.
À la fin de cette section, vous disposerez :
- Un compte Databricks configuré
- Un jeton d’accès Databricks
- Un identifiant d’entrepôt Databricks
- Une chaîne d’hôte Databricks
- Accès à un ou plusieurs Jeux de données Bright Data dans votre compte Databricks
Conditions préalables
Tout d’abord, assurez-vous que vous disposez d’un compte Databricks (un compte gratuit suffit). Si vous n’en avez pas, créez-en un. Sinon, connectez-vous simplement.
Configurez votre jeton d’accès Databricks
Pour autoriser l’accès aux ressources Databricks, vous avez besoin d’un jeton d’accès. Suivez les instructions ci-dessous pour en configurer un.
Dans votre tableau de bord Databricks, cliquez sur votre image de profil et sélectionnez l’option « Paramètres » :
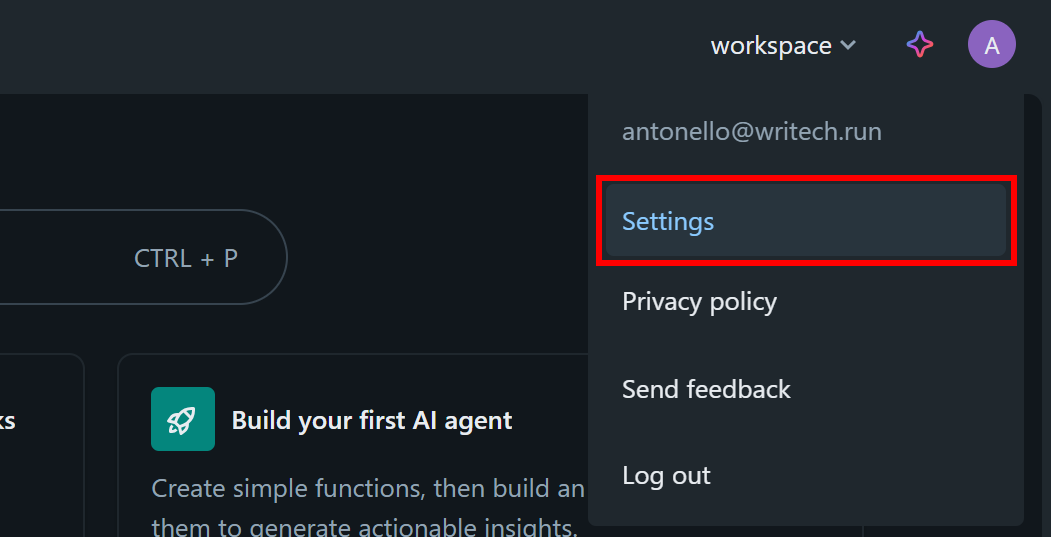
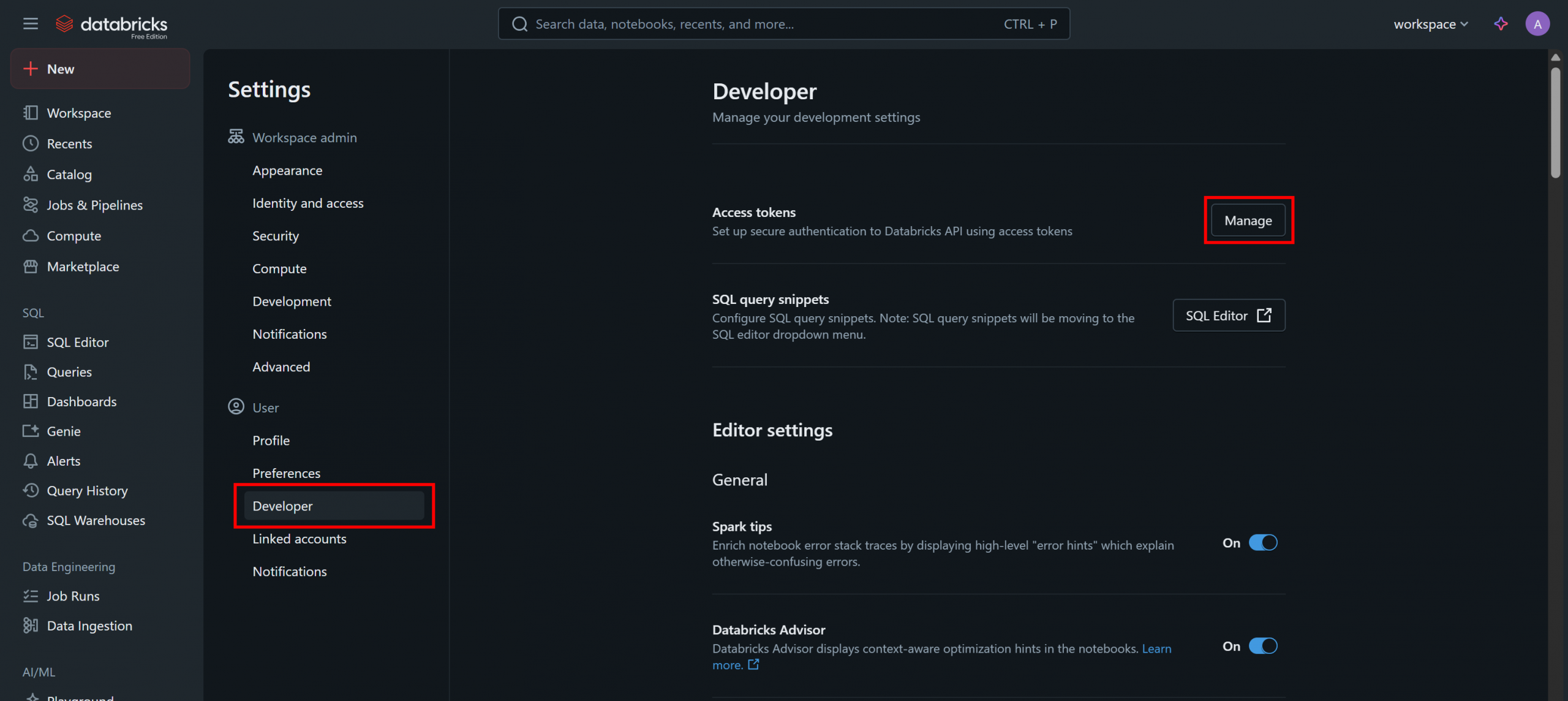
Sur la page « Paramètres », sélectionnez l’option « Développeur », puis cliquez sur le bouton « Gérer » dans la section « Jetons d’accès » :
Sur la page « Jetons d’accès », cliquez sur « Générer un nouveau jeton » et suivez les instructions dans la fenêtre modale :
Vous recevrez un jeton d’accès à l’API Databricks. Conservez-le en lieu sûr, car vous en aurez bientôt besoin.
Récupérez votre ID d’entrepôt Databricks
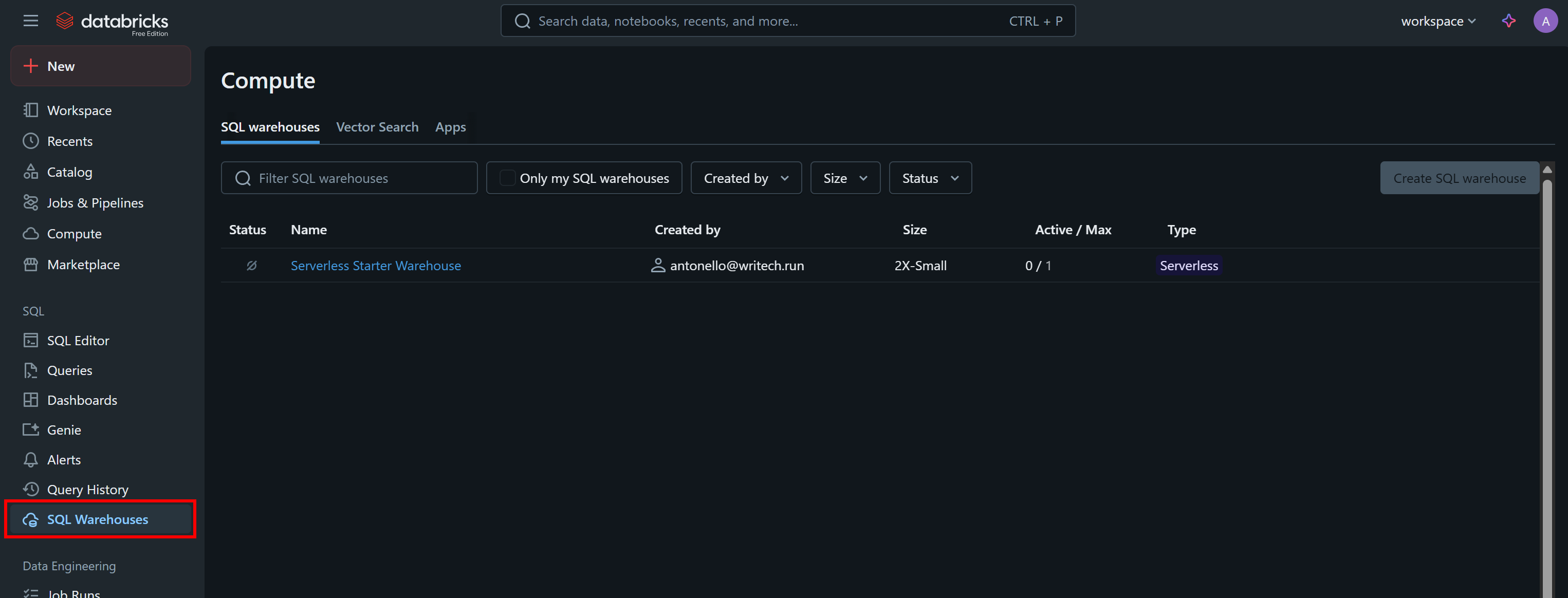
Une autre information dont vous avez besoin pour appeler l’API par programmation ou interroger les Jeux de données via l’interface CLI est votre ID d’entrepôt Databricks. Pour le récupérer, sélectionnez l’option « Entrepôts SQL » dans le menu :
Cliquez sur l’entrepôt disponible (dans cet exemple, « Serverless Starter Warehouse ») et accédez à l’onglet « Overview » (Aperçu) :
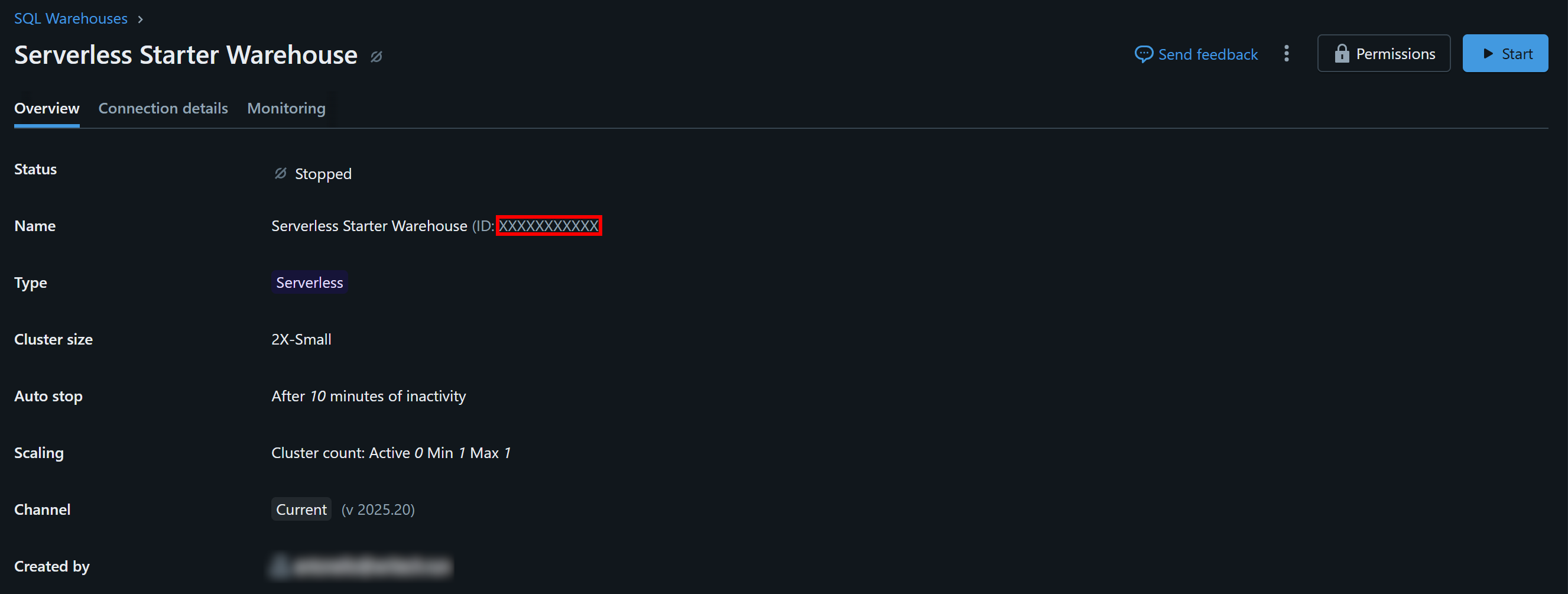
Dans la section « Name », vous verrez votre identifiant Databricks Warehouse (entre parenthèses, après ID:). Copiez-le et conservez-le en lieu sûr, car vous en aurez besoin rapidement.
Trouvez votre hôte Databricks
Pour vous connecter à une ressource de calcul Databricks, vous devez spécifier votre nom d’hôte Databricks. Celui-ci correspond à l’URL de base associée à votre compte Databricks et se présente sous la forme suivante :
https://<chaîne aléatoire>.cloud.databricks.comVous pouvez trouver cette information directement en la copiant depuis l’URL de votre tableau de bord Databricks :

Accédez aux jeux de données Bright Data
Vous devez maintenant ajouter un ou plusieurs Jeux de données Bright Data à votre compte Databricks afin de pouvoir les interroger via l’API, l’interface CLI ou le connecteur SQL.
Accédez à la page « Marketplace », cliquez sur le bouton « Settings » (Paramètres) à gauche et sélectionnez « Bright Data » comme seul fournisseur qui vous intéresse :
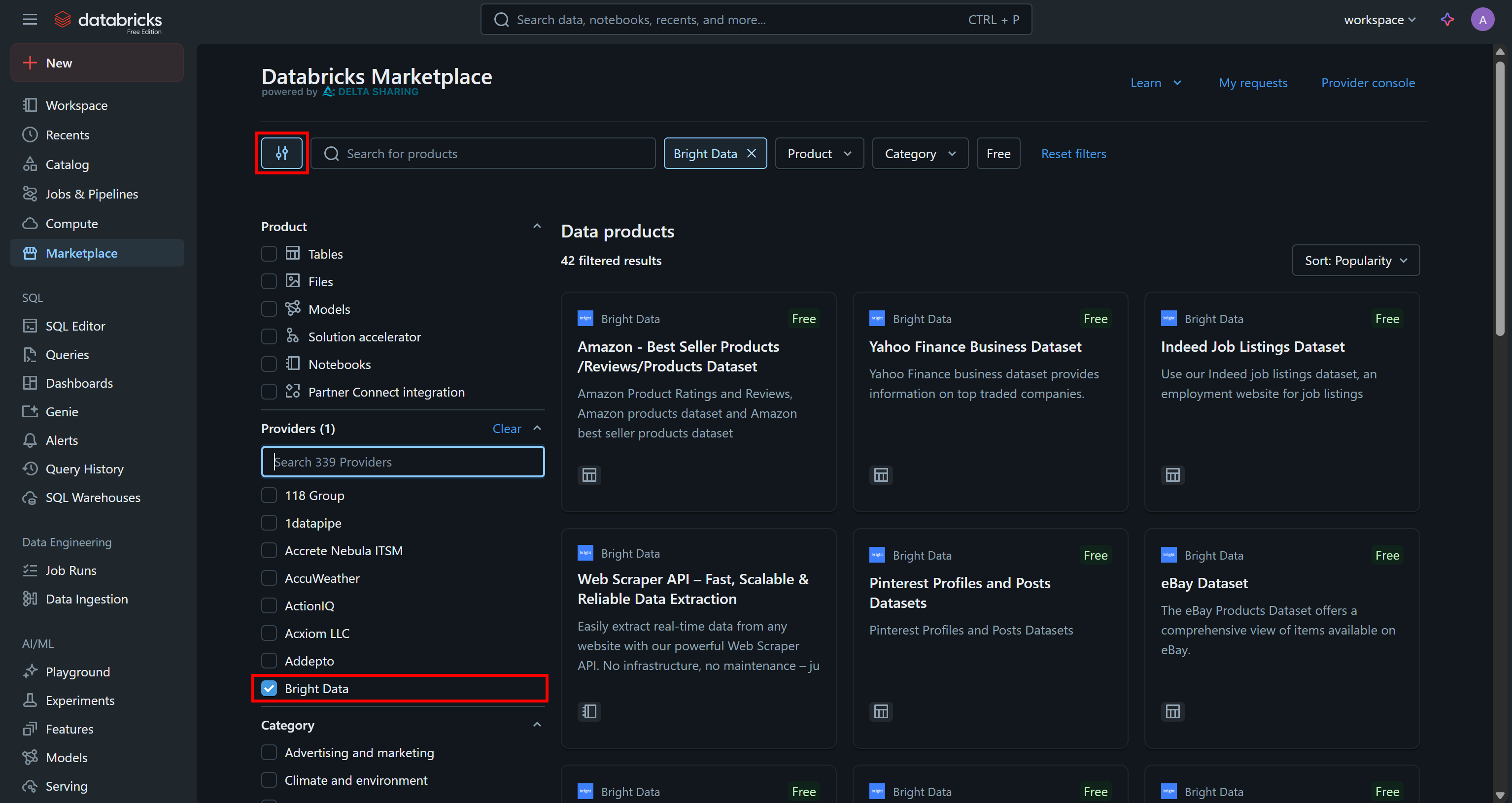
Cela filtrera les produits de données disponibles pour n’afficher que ceux fournis par Bright Data et accessibles via Databricks.
Pour cet exemple, supposons que vous soyez intéressé par l’«ensemble de données Zillow Properties Information» :
Cliquez sur la fiche du jeu de données, puis sur la page « Zillow Properties Information Dataset », appuyez sur « Get Instances Access » pour l’ajouter à votre compte Databricks :
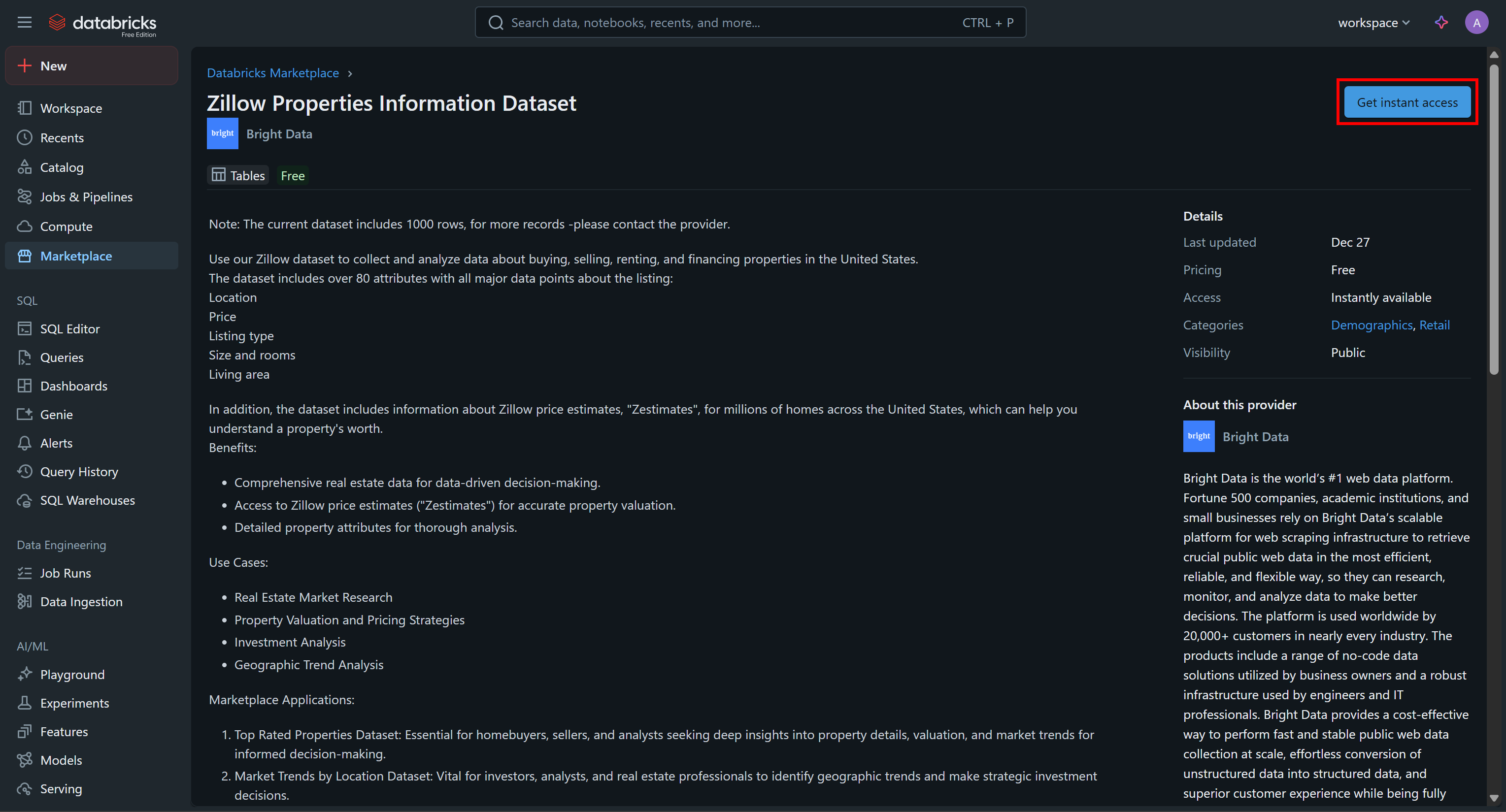
Le jeu de données sera ajouté à votre compte et vous pourrez désormais l’interroger via Databricks SQL. Si vous vous demandez d’où proviennent ces données, la réponse est : les Jeux de données Zillow de Bright Data.
Vérifiez-le en accédant à la page « SQL Editor » (Éditeur SQL) et interrogez l’ensemble de données à l’aide d’une requête SQL comme celle-ci :
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Le résultat devrait être similaire à celui-ci :
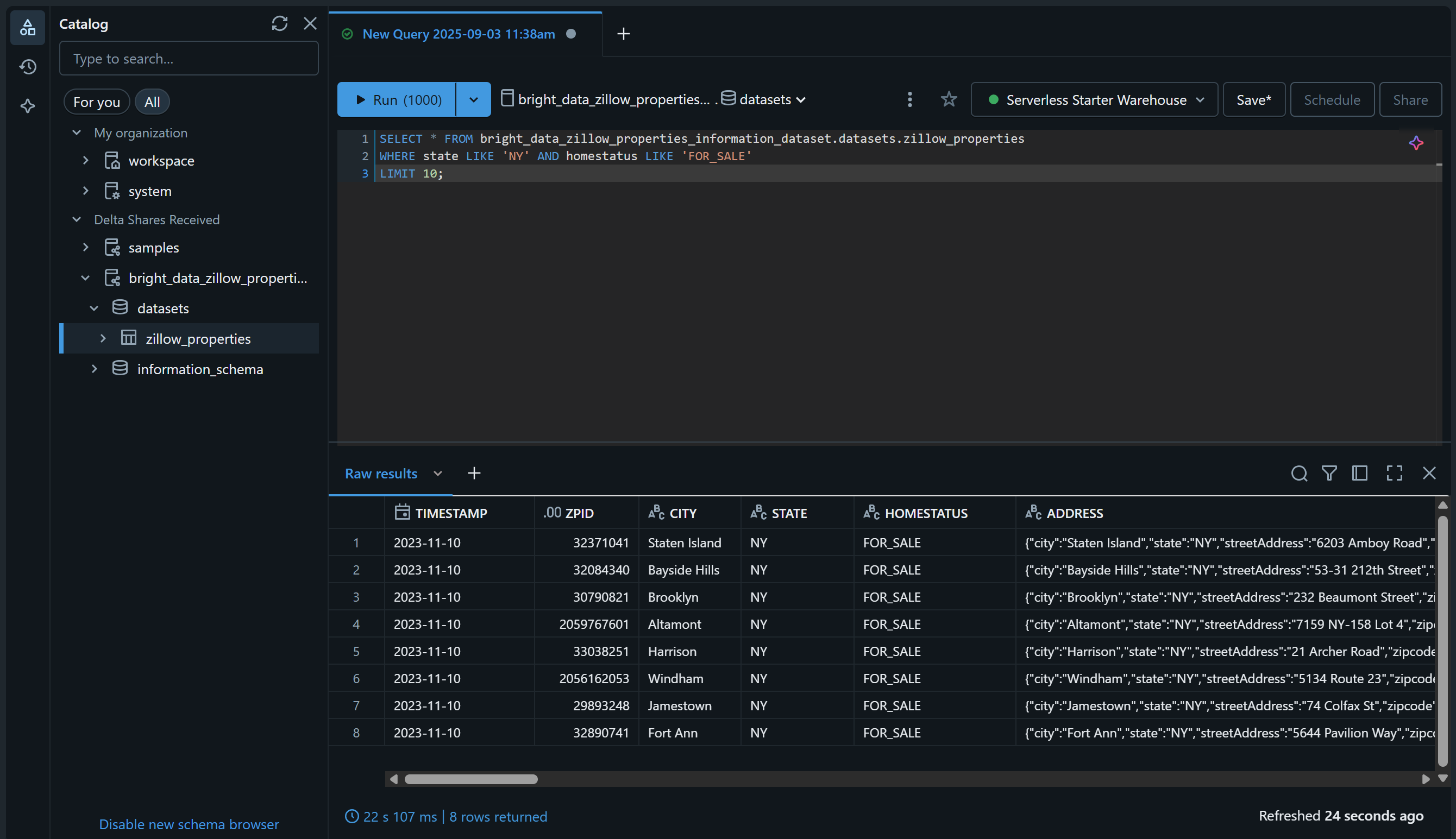
Parfait ! Vous avez ajouté avec succès le jeu de données Bright Data choisi et l’avez rendu interrogeable via Databricks. Vous pouvez suivre les mêmes étapes pour ajouter d’autres jeux de données Bright Data.
Dans les sections suivantes, vous apprendrez comment interroger cet ensemble de données :
- Via l’API REST Databricks
- Avec le connecteur SQL Databricks pour Python
- Via l’interface CLI Databricks
Comment interroger un jeu de données Bright Data via l’API REST Databricks
Databricks expose certaines de ses fonctionnalités via une API REST, notamment la possibilité d’interroger les Jeux de données disponibles dans votre compte. Suivez les étapes ci-dessous pour découvrir comment interroger par programmation l’ensemble de données « Zillow Properties Information Dataset » fourni par Bright Data.
Remarque: le code ci-dessous est écrit en Python, mais il peut être facilement adapté à d’autres langages de programmation ou appelé directement dans Bash via cURL.
Étape n° 1 : installer les bibliothèques requises
Pour exécuter des requêtes SQL sur des entrepôts Databricks distants, le point de terminaison de l’API REST à utiliser est /api/2.0/sql/statements. Vous pouvez l’appeler via une requête POST à l’aide de n’importe quel client HTTP. Dans cet exemple, nous utiliserons la bibliothèque Python Requests.
Installez-la avec :
pip install requestsEnsuite, importez-la dans votre script avec :
import requestsPour en savoir plus, consultez notre guide dédié à Python Requests.
Étape n° 2 : préparez vos identifiants et secrets Databricks
Pour appeler le point de terminaison de l’API REST Databricks /api/2.0/sql/statements à l’aide d’un client HTTP, vous devez spécifier :
- Votre jeton d’accès Databricks: pour l’authentification.
- Votre hôte Databricks: pour créer l’URL API complète.
- Votre ID d’entrepôt Databricks: pour interroger la table correcte dans l’entrepôt correct.
Ajoutez les secrets que vous avez récupérés précédemment à votre script comme suit :
databricks_access_token = "<VOTRE_JETON_D'ACCÈS_DATABRICKS>"
databricks_warehouse_id = "<VOTRE_ID_D'ENTREPÔT_DATABRICKS>"
databricks_host = "<VOTRE_HÔTE_DATABRICKS>"Conseil: en production, évitez de coder en dur ces secrets dans votre script. Envisagez plutôt de stocker ces informations d’identification dans des variables d’environnement et de les charger à l’aide de python-dotenv pour une meilleure sécurité.
Étape n° 3 : appeler l’API d’exécution des instructions SQL
Effectuez un appel HTTP POST vers le point de terminaison /api/2.0/sql/statements avec les en-têtes et le corps appropriés à l’aide de Requests :
# La requête SQL paramétrée à exécuter sur l'ensemble de données donné
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# Le paramètre à remplir dans la requête SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Effectuer la requête POST et interroger l'ensemble de données
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Pour l'authentification dans Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)Comme vous pouvez le constater, l’extrait ci-dessus repose sur une instruction SQL préparée. Comme souligné dans la documentation, Databricks recommande vivement d’utiliser des requêtes paramétrées comme meilleure pratique pour vos instructions SQL.
En d’autres termes, l’exécution du script ci-dessus équivaut à exécuter la requête suivante sur la table bright_data_zillow_properties_information_dataset.datasets.zillow_properties, comme nous l’avons fait précédemment :
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Fantastique ! Il ne reste plus qu’à gérer les données de sortie
Étape n° 4 : exporter les résultats de la requête
Traitez la réponse et exportez les données récupérées à l’aide de cette logique Python :
if response.status_code == 200:
# Accéder aux données JSON de sortie
result = response.json()
# Exporter les données récupérées vers un fichier JSON
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Requête réussie ! Résultats enregistrés dans '{output_file}'")
else:
print(f"Erreur {response.status_code}: {response.text}")Si la requête aboutit, l’extrait de code créera un fichier zillow_properties.json contenant les résultats de la requête.
Étape n° 5 : assembler le tout
Votre script final doit contenir :
import requests
import json
# Vos identifiants Databricks (remplacez-les par les valeurs correctes)
databricks_access_token = "<VOTRE_TOKEN_D'ACCÈS_DATABRICKS>"
databricks_warehouse_id = "<VOTRE_ID_DATABRICKS_WAREHOUSE>"
databricks_host = "<VOTRE_HÔTE_DATABRICKS>"
# La requête SQL paramétrée à exécuter sur l'ensemble de données donné
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# Le paramètre à remplir dans la requête SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Effectuer la requête POST et interroger l'ensemble de données
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Pour l'authentification dans Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Traiter la réponse
if response.status_code == 200:
# Accéder aux données JSON en sortie
result = response.json()
# Exporter les données récupérées vers un fichier JSON
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Requête réussie ! Résultats enregistrés dans '{output_file}'")
else:
print(f"Erreur {response.status_code}: {response.text}")Exécutez-le, et cela devrait générer un fichier zillow_properties.json dans le répertoire de votre projet.
La sortie contient d’abord la structure des colonnes pour vous aider à comprendre les colonnes disponibles. Ensuite, dans le champ data_array, vous pouvez voir les données de requête résultantes sous forme de chaîne JSON :
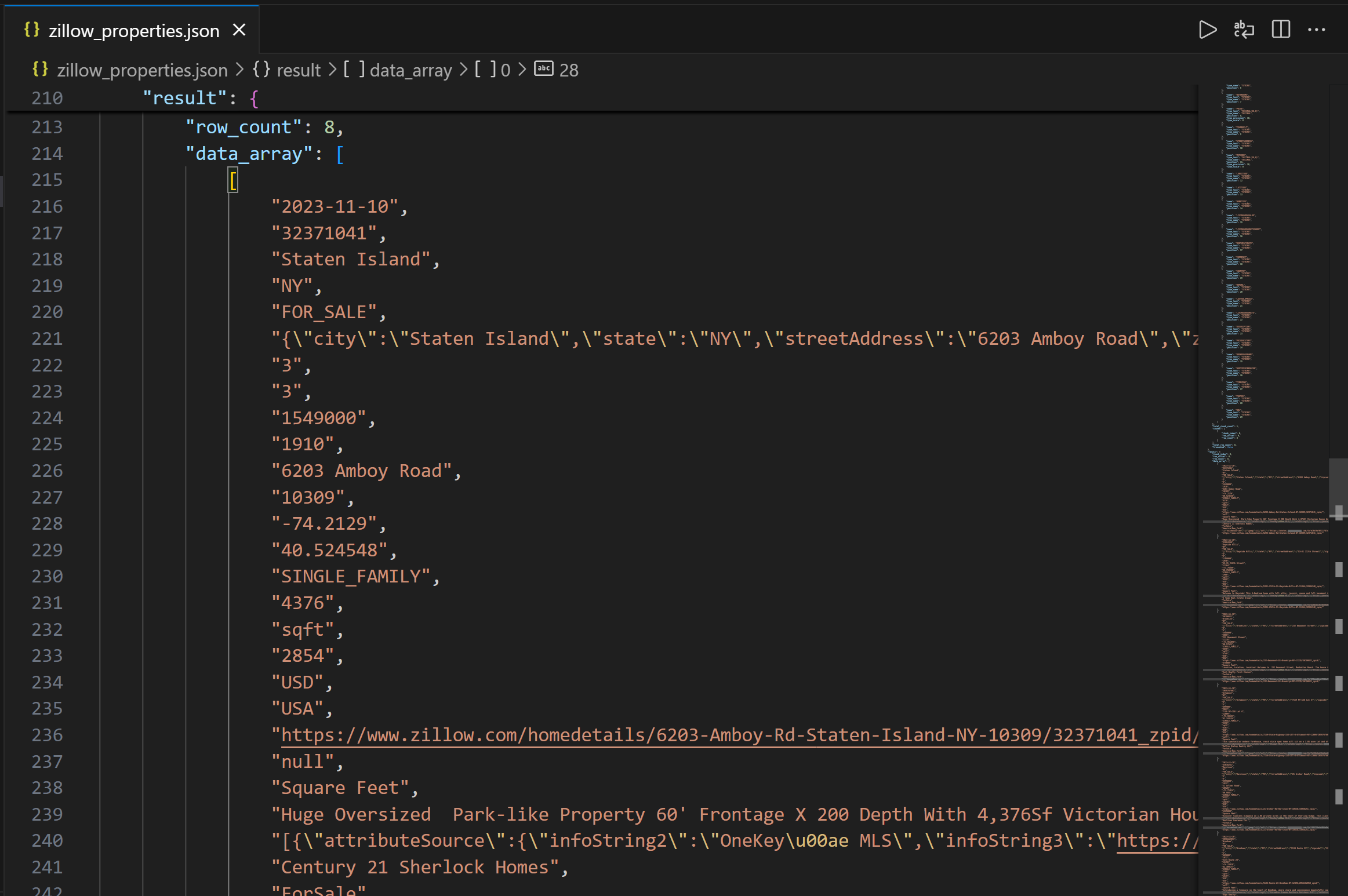
Mission accomplie ! Vous venez de collecter les données immobilières Zillow fournies par Bright Data via l’API REST Databricks.
Comment accéder aux jeux de données Bright Data à l’aide de l’interface CLI Databricks
Databricks vous permet également d’interroger les données d’un entrepôt via l’interface CLI Databricks, qui s’appuie sur l’API REST. Découvrez comment l’utiliser !
Étape n° 1 : installer l’interface CLI Databricks
L’interface CLI Databricks est un outil en ligne de commande open source qui vous permet d’interagir avec la plateforme Databricks directement depuis votre terminal.
Pour l’installer, suivez le guide d’installation correspondant à votre système d’exploitation. Si tout est correctement configuré, l’exécution de la commande databricks -v devrait afficher quelque chose comme ceci :
Parfait !
Étape n° 2 : définir un profil de configuration pour l’authentification
Utilisez l’interface CLI Databricks pour créer un profil de configuration nommé DEFAULT qui vous authentifie à l’aide de votre jeton d’accès personnel Databricks. Pour ce faire, exécutez la commande ci-dessous :
databricks configure --profile DEFAULTVous serez alors invité à fournir :
- Votre hôte Databricks
- Votre jeton d’accès Databricks
Collez les deux valeurs et appuyez sur Entrée pour terminer la configuration :

Vous pouvez désormais authentifier les commandes API CLI en spécifiant l’option --profile DEFAULT.
Étape n° 3 : interroger votre jeu de données
Utilisez la commande CLI suivante pour exécuter une requête paramétrée via la commande API post:
databricks API post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
« parameters » : [
{ « name » : « state », « value » : « NY », « type » : « STRING » },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
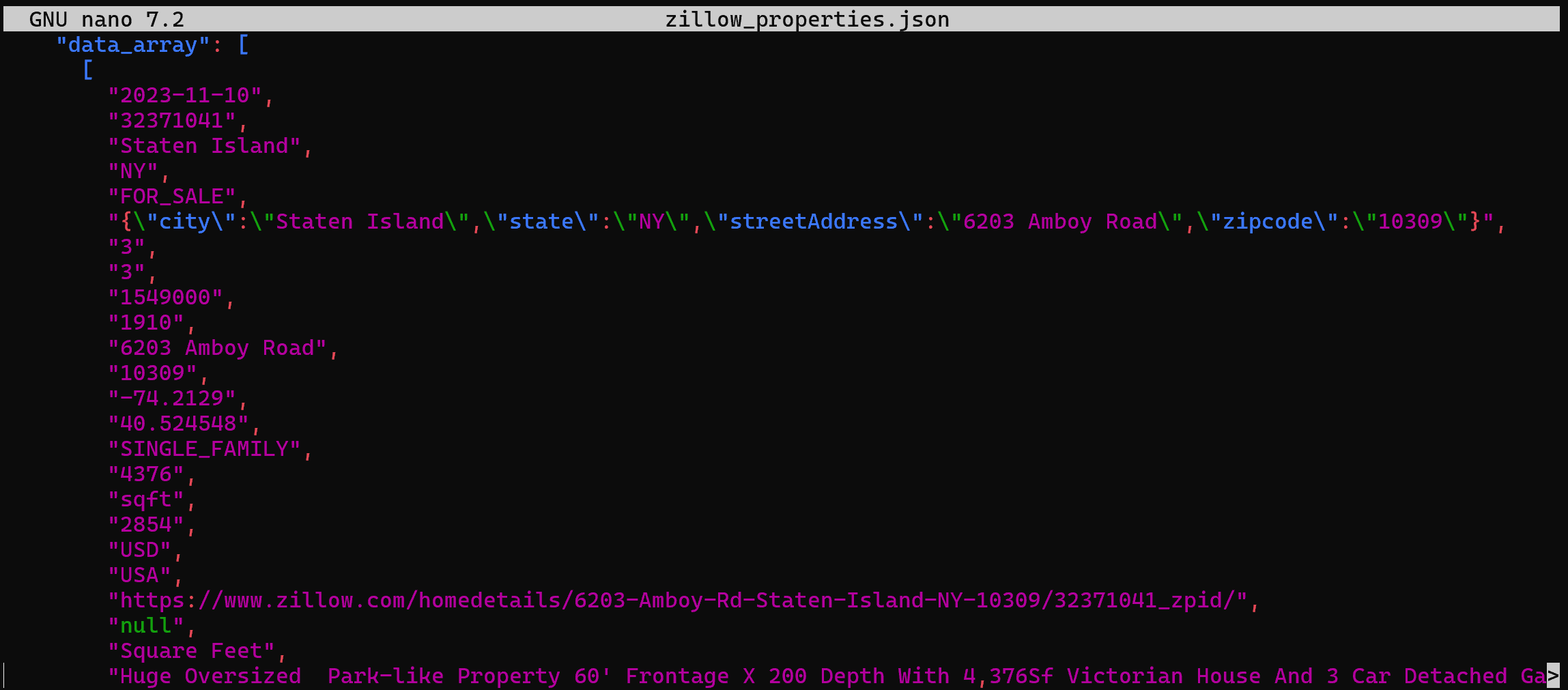
> zillow_properties.jsonRemplacez l’espace réservé <YOUR_DATABRICKS_WAREHOUSE_ID> par l’ID réel de votre entrepôt SQL Databricks.
En arrière-plan, cela fait la même chose que ce que nous avons fait précédemment en Python. Plus précisément, cela envoie une requête POST à l’API REST SQL de Databricks. Le résultat sera un fichier zillow_properties.json contenant les mêmes données que celles vues précédemment :
Comment interroger un jeu de données à partir de Bright Data via le connecteur SQL Databricks
Le connecteur SQL Databricks est une bibliothèque Python qui vous permet de vous connecter aux clusters Databricks et aux entrepôts SQL. Il fournit notamment une API simplifiée pour vous connecter à l’infrastructure Databricks et explorer vos données.
Dans cette section du guide, vous apprendrez à l’utiliser pour interroger l’ensemble de données « Zillow Properties Information Dataset » de Bright Data.
Étape n° 1 : installer le connecteur SQL Databricks pour Python
Le connecteur SQL Databricks est disponible via la bibliothèque Python databricks-sql-connector. Installez-le à l’aide de la commande suivante :
pip install databricks-sql-connectorEnsuite, importez-le dans votre script avec :
from databricks import sqlÉtape n° 2 : commencer à utiliser le connecteur SQL Databricks
Le connecteur SQL Databricks nécessite des informations d’identification différentes de celles requises pour l’API REST et l’interface CLI. Plus précisément, il nécessite :
server_hostname: votre nom d’hôte Databricks (sans la partiehttps://).http_path: une URL spéciale pour se connecter à votre entrepôt.access_token: votre jeton d’accès Databricks.
Vous trouverez les valeurs d’authentification nécessaires, ainsi qu’un exemple de snippet de démarrage, dans l’onglet « Connection Details » (Détails de connexion) de votre entrepôt SQL :
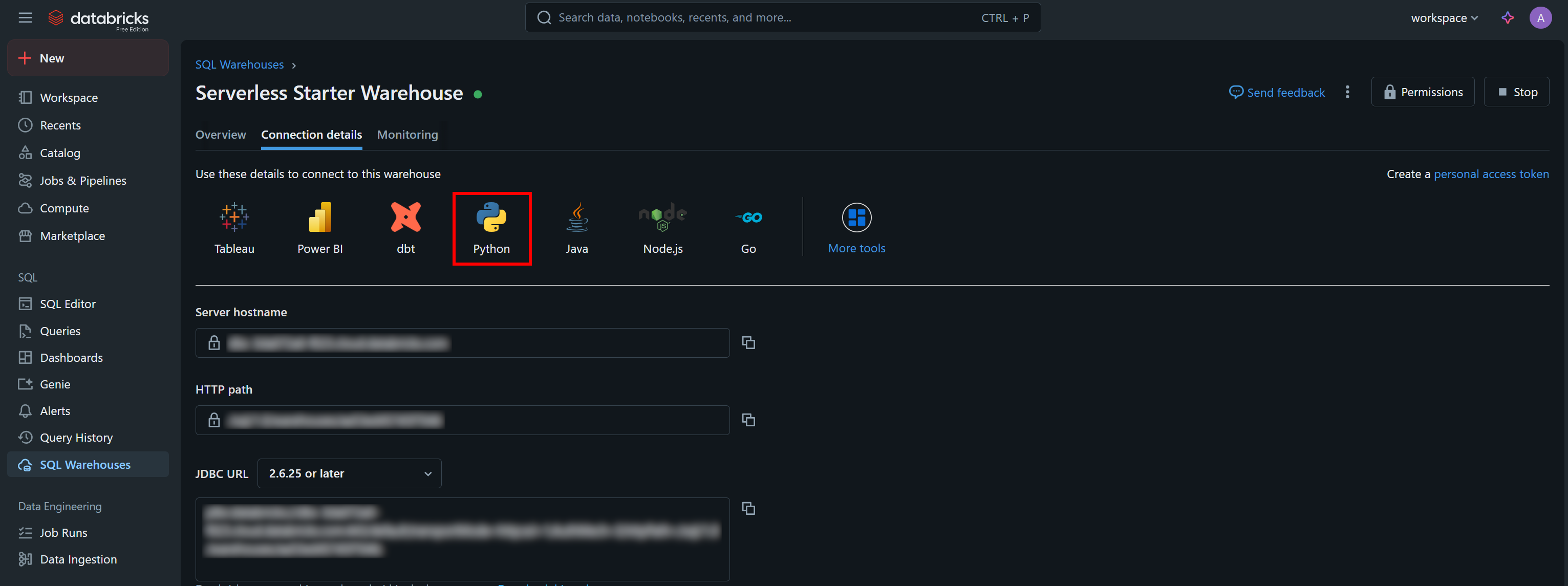
Appuyez sur le bouton « Python » pour obtenir :
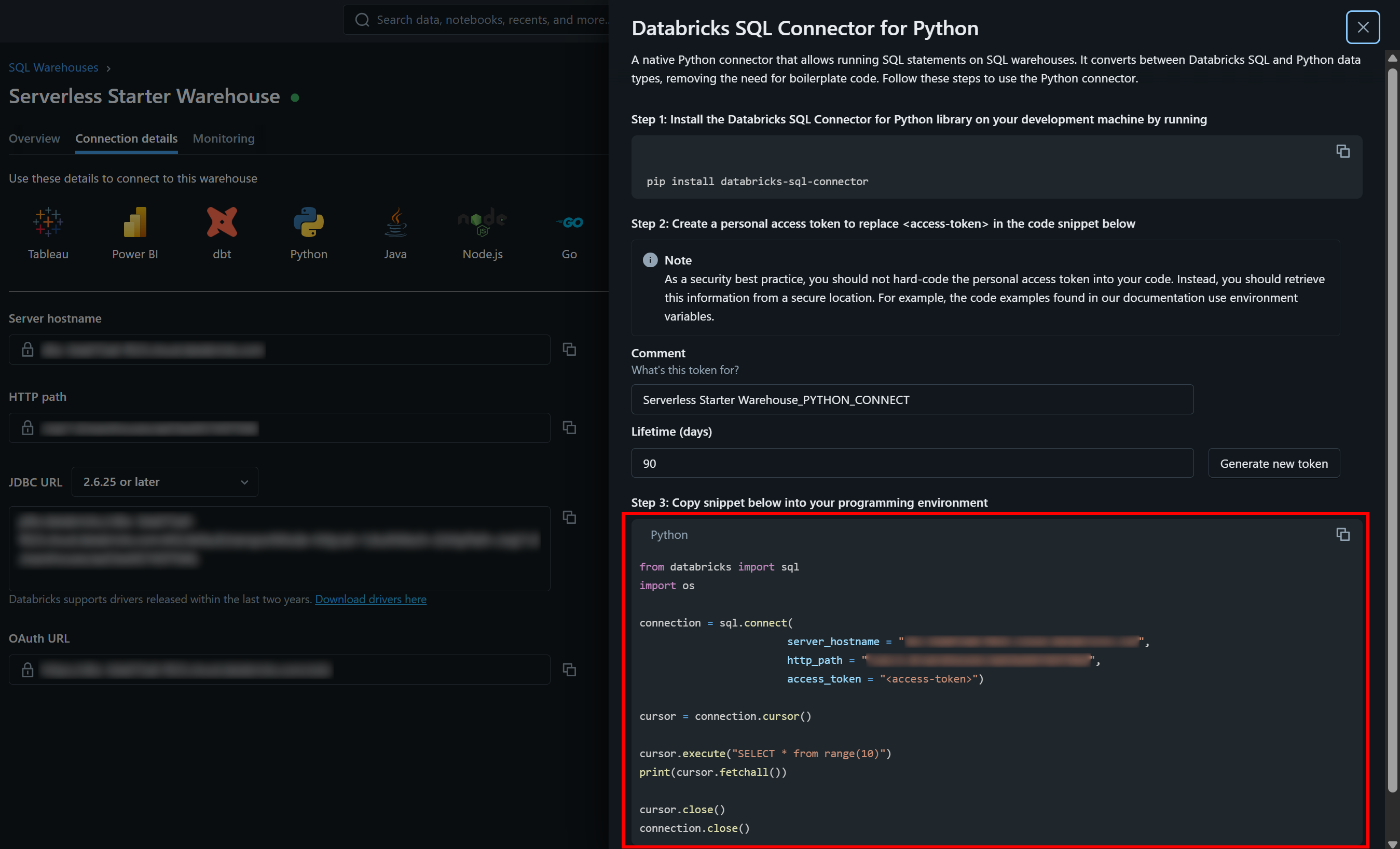
Voici toutes les instructions dont vous avez besoin pour commencer à utiliser le connecteur databricks-sql-connector.
Étape n° 3 : tout assembler
Adaptez le code de l’exemple de snippet dans la section « Databricks SQL Connector for Python » à votre entrepôt afin d’exécuter la requête paramétrée qui vous intéresse. Vous devriez obtenir un script similaire à celui-ci :
from databricks import sql
# Connectez-vous à votre entrepôt SQL dans Databricks (remplacez les informations d'identification par vos valeurs)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Exécutez la requête SQL paramétrée et obtenez les résultats dans un curseur
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Exécuter la requête
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Imprimer tous les résultats ligne par ligne
for row in result[:2]:
print(row)
# Fermer le curseur et la connexion à l'entrepôt SQL
cursor.close()
connection.close()Exécutez le script, qui générera un résultat similaire à celui-ci :
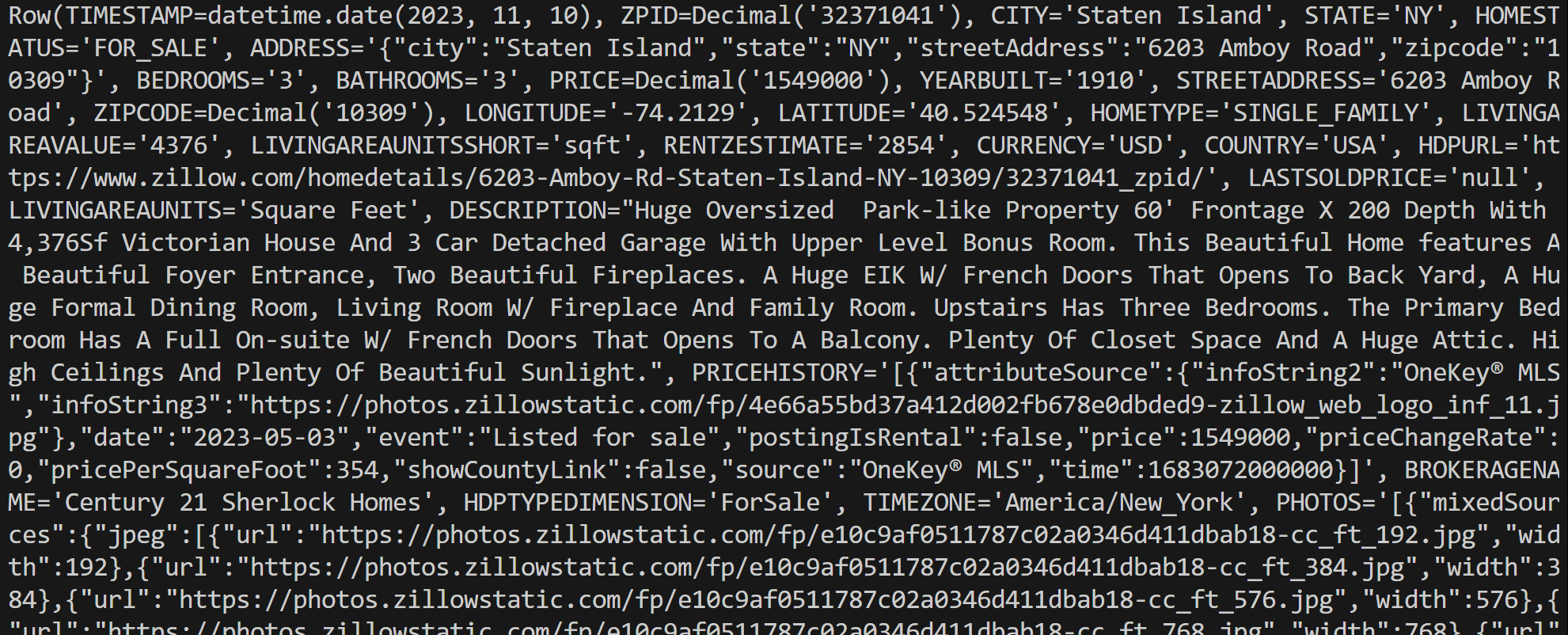
Notez que chaque objet row est une instance Row, représentant un seul enregistrement issu des résultats de la requête. Vous pouvez ensuite traiter ces données directement dans votre script Python.
N’oubliez pas que vous pouvez convertir une instance Row en dictionnaire Python à l’aide de la méthode asDict():
row_data = row.asDict()Et voilà ! Vous savez désormais comment interagir avec vos jeux de données Bright Data dans Databricks et les interroger de plusieurs façons.
Conclusion
Dans cet article, vous avez appris à interroger les Jeux de données de Bright Data à partir de Databricks à l’aide de son API REST, de son interface CLI ou de sa bibliothèque SQL Connector dédiée. Comme démontré, Databricks offre plusieurs façons d’interagir avec les produits proposés par ses fournisseurs de données, dont Bright Data fait désormais partie.
Avec plus de 40 produits disponibles, vous pouvez explorer la richesse des Jeux de données de Bright Data directement dans Databricks et accéder à leurs données de différentes manières.
Créez gratuitement un compte Bright Data et commencez dès aujourd’hui à tester nos solutions de données !




