
Le filtrage des données était autrefois une simple astuce de base de données. Aujourd’hui, il s’agit d’une capacité commerciale essentielle qui alimente l’IA, vous permet de rester en conformité et vous aide à devancer vos concurrents.
Dans ce guide, vous apprendrez :
- Ce qu’est le filtrage des données.
- Pourquoi le filtrage des données est important.
- Pourquoi vous devriez utiliser le filtrage de données automatisé.
- Comment Deep Lookup facilite le filtrage des données.
Plongeons dans le vif du sujet !
Qu’est-ce que le filtrage de données ?
Le filtrage des données consiste simplement à ne vous montrer que les données qui vous intéressent. C’est comme utiliser un filtre à café qui ne vous donne que les bonnes choses que vous voulez, pas le marc. Le principe est simple : vous définissez des règles (par exemple, montrez-moi les clients de Californie) et le système exclut tout ce qui ne correspond pas aux règles.
Nous utilisons tous le filtrage de données dans notre vie quotidienne. Lorsque vous recherchez “écouteurs sans fil de moins de 100 $” sur Amazon, vous filtrez. Lorsque votre équipe de marketing établit une liste des clients qui n’ont pas acheté depuis six mois, elle procède à un filtrage. Lorsque vous triez votre boîte de réception par expéditeur, vous faites du filtrage.
Bien que le concept soit simple, l’utilisation du filtrage de données à grande échelle dans une organisation nécessite une solide compréhension de vos données et les bons outils. Aujourd’hui, le filtrage des données est essentiel à la réussite de toute organisation, et nous allons vous expliquer pourquoi.
L’importance du filtrage des données
Le filtrage est une nécessité pour donner un sens aux données volumineuses (big data).
La plupart des entreprises sont aujourd’hui assises sur des mines d’or de données qu’elles n’utiliseront jamais. Non pas parce que les données n’ont pas de valeur, mais parce qu’elles ne peuvent pas les analyser efficacement pour trouver ce qui est important.
Pensez-y de la manière suivante. Votre entreprise recueille probablement des centaines de données sur chaque client. Mais lorsque le temps presse et que vous devez identifier vos segments les plus précieux, allez-vous vraiment trier manuellement 50 000 enregistrements de clients ? Bien sûr que non. Vous allez prendre un échantillon, faire des suppositions éclairées et espérer que tout se passe bien.
C’est exactement le problème que le filtrage résout. Voici pourquoi un filtrage efficace des données est essentiel :
- Éliminer le bruit : vos analystes cessent de perdre du temps avec des données non pertinentes et se concentrent sur les schémas qui font réellement avancer l’aiguille.
- Accélérertout : desensembles de donnéesplus petitssignifient des requêtes plus rapides, une compréhension plus rapide et des décisions qui se prennent en quelques jours au lieu de quelques semaines.
- Découvrir des modèles cachés : Lorsque vous éliminez le désordre, les tendances qui étaient invisibles deviennent soudainement évidentes.
- Économiser de l’argent : Moins de données à stocker et à traiter signifie des coûts d’infrastructure réduits. De plus, le temps de votre équipe devient infiniment plus précieux.
- Restez conforme : Filtrez automatiquement les informations sensibles et vous dormirez mieux en sachant que vous n’exposez pas accidentellement les données de vos clients.
En résumé, le filtrage des données est le pont entre les données brutes et la prise de décision éclairée. Nous verrons ensuite comment aborder le filtrage dans la pratique et quelques techniques standard pour un filtrage efficace.
Présentation du filtrage manuel des données à l’aide des données de la place de marché d’Amazon
Laissez-moi vous expliquer ce que font la plupart des équipes lorsqu’elles ont besoin de filtrer des données. Nous utiliserons un véritable ensemble de données de produits Amazon (avec l’aimable autorisation de Bright Data datasets) pour vous montrer exactement comment cela se passe. Cet ensemble de données comprend divers champs tels que les titres des produits, les marques, les prix, les évaluations, etc. dans différentes catégories et régions.
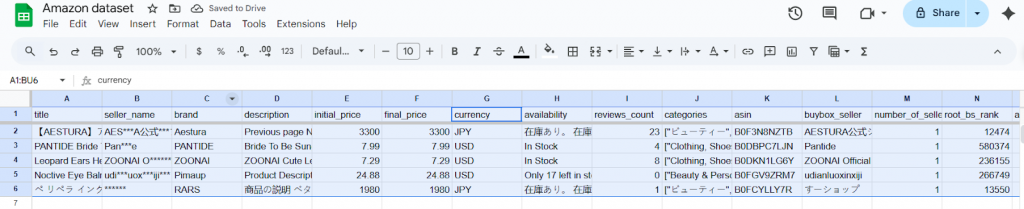
Face à une liste aussi vaste, un professionnel des données devrait isoler uniquement les produits pertinents pour une analyse particulière afin de se concentrer sur les informations utiles. Pour ce faire, il devra suivre les étapes suivantes :
- Commencez par filtrer tous les éléments qui ne répondent pas à vos critères d’intérêt initiaux. Dans la pratique, il s’agit souvent d’exclure les produits qui ne font pas partie de la catégorie ou du champ d’application que vous visez. Par exemple, si nous ne nous intéressons qu’aux produits de beauté, nous supprimerons les entrées appartenant à d’autres catégories.
- À l’aide d’un outil tel que Google Sheet ou Excel, accédez à l’onglet “Données” et cliquez sur “Créer un filtre”.

- Un filtre apparaît alors dans chaque colonne et vous pouvez l’utiliser pour personnaliser l’ensemble de données autant que vous le souhaitez.
- Par exemple, si vous souhaitez filtrer les produits par devise et ne conserver que les produits dont le prix est en USD, vous devez aller dans la colonne “Prix” et appliquer ce filtre.

- Une fois que vous aurez décoché JPY, l’ensemble de données n’affichera que les produits dont le prix est en USD.
La première fois que vous faites cela, vous vous sentez bien. Vous contrôlez la situation, vous voyez exactement ce qui se passe et vous découvrez des modèles intéressants au fur et à mesure. “Oh, regardez, les produits écologiques ont l’air d’être mieux notés !”
Mais voici ce qui se passe en pratique :
- Semaine 1 : C’est génial ! J’adore avoir ce contrôle.
- Semaine 4 : D’accord, cela devient répétitif, mais je trouve toujours de bonnes idées.
- Semaine 12 : J’ai passé toute ma matinée à appliquer les mêmes filtres qu’hier.
- Semaine 24 : Je crois que j’ai oublié d’effacer le filtre précédent… Est-ce que ces chiffres sont justes ?
De nombreux analystes brillants s’épuisent à faire exactement la même chose. Non pas parce que le travail n’est pas utile, mais parce qu’ils consacrent 80 % de leur temps à des tâches mécaniques plutôt qu’à l’analyse proprement dite.
Maintenant que vous savez comment filtrer les données manuellement, examinons les avantages et les inconvénients de cette méthode.
Avantages du filtrage manuel
- Le filtrage manuel vous donne un retour visuel immédiat, ce qui vous permet de voir les résultats instantanément et d’ajuster les filtres de manière itérative. Vous pouvez repérer des modèles inattendus ou des problèmes de qualité des données au fur et à mesure que vous travaillez.
- Vous bénéficiez également d’une intégration du contexte commercial qui vous permet de prendre des décisions nuancées. Lors du filtrage des champs “customers_say” ou “top_review”, le jugement humain identifie les sentiments et les préoccupations que les systèmes automatisés pourraient manquer.
- Il permet une exploration flexible qui prend en charge l’analyse axée sur la découverte. Vous pourriez remarquer que les produits dont la mention “climate_pledge_friendly” = VRAI sont mieux notés, ce qui permettrait d’obtenir de nouvelles informations stratégiques.
- La barrière à l’entrée est faible, ce qui signifie que tout membre de l’équipe familiarisé avec les feuilles de calcul peut effectuer des analyses sans formation technique ni outils spécialisés.
- Les critères documentés garantissent la reproductibilité des analyses et la collaboration au sein de l’équipe.
Inconvénients du filtrage manuel
- Les limites d’échelle deviennent rapidement apparentes. Le filtrage de plus de 10 000 lignes dans Google Sheets entraîne une dégradation notable des performances. Avec des millions de produits Amazon, vous ne voyez qu’un tout petit échantillon.
- L’intensité du temps augmente avec la complexité. L’application du processus de filtrage en 8 étapes ci-dessus prend 15 à 20 minutes pour une analyse. Répéter cette opération quotidiennement ou pour plusieurs catégories devient insoutenable.
- La probabilité d’une erreur humaine augmente avec la répétition. La sélection accidentelle des mauvais opérateurs (plus grand que ou moins grand que) ou l’oubli d’effacer les filtres précédents conduisent à des analyses incorrectes.
- L’incohérence entre les utilisateurs crée des idées contradictoires. Deux analystes peuvent interpréter différemment l’expression “vendeur de haute qualité”, en filtrant le “nom du vendeur” ou l'”évaluation” avec des seuils différents.
- La reproductibilité limitée rend l’automatisation impossible. Chaque session de filtrage manuel nécessite une intervention humaine, ce qui empêche la production de rapports programmés ou de tableaux de bord en temps réel.
- Le coût d’opportunité est important. Alors que les analystes passent des heures à filtrer les données, les concurrents qui utilisent des solutions automatisées agissent déjà sur les informations. Le temps consacré au filtrage mécanique pourrait être investi dans l’analyse stratégique et la prise de décision.
Dans l’ensemble, le filtrage manuel des données offre un degré élevé de contrôle et de clarté à l’analyste, ce qui le rend bien adapté à l’analyse exploratoire ou aux ensembles de données à petite échelle pour lesquels il est important de comprendre les nuances. Cependant, son inefficacité et les risques d’erreur sur les données à grande échelle le rendent moins adapté aux big data ou aux flux de travail de routine.
Dans ces cas-là, il est préférable de passer à des méthodes ou des outils de filtrage automatisés, et nous allons vous expliquer pourquoi.
Pourquoi le filtrage automatisé des données est-il plus intelligent, plus rapide et plus évolutif ?
Lorsque nous parlons de filtrage automatisé, il ne s’agit pas seulement de vitesse. L’automatisation ne se contente pas de faire plus rapidement ce que vous faisiez auparavant, elle fait des choses que vous ne pouviez littéralement pas faire manuellement.
Vous vous souvenez de cet ensemble de données Amazon avec 73 champs différents ? Manuellement, vous pourriez explorer 5 à 10 combinaisons de ces champs. Avec l’automatisation, vous pouvez tester des milliers de combinaisons en parallèle. Vous pourriez découvrir que les produits portant des badges respectueux du climat ont en fait un taux de rétention de la clientèle supérieur de 23 %, mais seulement dans certaines gammes de prix, et seulement lorsqu’ils sont vendus par des types de vendeurs spécifiques.
Il ne s’agit pas d’informations que l’on découvre par hasard. Ce sont des informations qui émergent lorsque l’on peut explorer systématiquement tous les angles, ce qui n’est possible que grâce au filtrage automatisé des données.
Le filtrage automatisé change fondamentalement ce qui est possible pour un analyste ou une entreprise en traitant des millions d’enregistrements en quelques secondes, tout en appliquant des centaines de combinaisons de filtres simultanément. Pour ce faire, il codifie vos critères sous forme de règles exécutables par une machine et les exécute en continu à grande échelle.
Au lieu de cliquer sur les colonnes, vous pouvez définir des filtres déclaratifs, pousser ces filtres aussi près que possible de la source et obtenir rapidement des données réutilisables. Grâce au filtrage automatisé des données, vous pouvez explorer de manière exhaustive des milliers d’interactions sur le terrain en parallèle, en mettant en évidence des schémas qui n’entreraient jamais dans le budget d’exploration limité d’un être humain, puis les reproduire autant que vous le souhaitez.
| Dimension | Manuel | Automatisé |
|---|---|---|
| Vitesse/Latence | Rythme humain ; quelques minutes à quelques heures par exécution | Rythme machine ; secondes à minutes à l’échelle |
| Évolutivité | Limitée par l’interface utilisateur et la mémoire | Mise à l’échelle horizontale (calcul distribué, pushdown) |
| Fiabilité | Susceptible d’erreur humaine | Déterministe, testable, idempotent |
| Fraîcheur | Par lots, ad hoc | Programmée ou en continu ; possibilité de temps quasi réel |
| Cohérence | Varie selon l’opérateur | Logique de contrôle des versions ; résultats reproductibles |
| Coût | Coût caché de la main-d’œuvre ; reprise du travail | Optimisation des calculs ; cache et poussée des prédicats |
| Gouvernance | Difficile à auditer | Lignage, journalisation, approbations, contrôles d’accès |
L’un des meilleurs outils de filtrage automatisé des données est Deep Lookup de Brightdata, dont nous allons parler maintenant.
Présentation de Deep Lookup : Filtrer les données en langage clair
Deep Lookup est l’outil de recherche de Bright Data alimenté par l’IA qui transforme les questions en anglais simple en ensembles de données structurés et précis. Avec Deep Lookup, vous pouvez demander exactement ce dont vous avez besoin et l’obtenir sous la forme d’un tableau utilisable.
Au lieu d’assembler des sources ou de rédiger des requêtes complexes, vous décrivez les entités que vous souhaitez (entreprises, produits, personnes, actualités, propriétés), les filtres auxquels elles doivent répondre et les colonnes que vous voulez voir. Deep Lookup se charge du filtrage, de l’enrichissement et de la structuration en coulisses pour fournir des résultats prêts à être analysés.
Fonctionnement de Deep Lookup
Deep Lookup encourage l’utilisation d’un format d’invite de deux lignes, comme celui-ci :
- Rechercher tous … <entités et conditions>
- Afficher : <colonnes souhaitées>
Par exemple, un exemple de Deep Lookup ressemblerait à ceci :
***Trouver tous les produits Amazon Beauty & Personal Care dont le prix est ≤ $25 avec une note ≥ 4 et en stock.***
***Afficher : le nom du produit, la marque, le prix actuel, l'évaluation, le nombre d'avis, l'URL du produit***.
Deep Lookup prend cette description et :
- identifie les sources de données dont elle a besoin
- applique vos filtres au niveau de la base de données (et non après avoir tout téléchargé)
- Enrichit les résultats avec un contexte supplémentaire
- renvoie un ensemble de données propre et structuré que vous pouvez utiliser immédiatement.
Pour les requêtes plus complexes, vous pouvez utiliser une approche plus structurée :
TROUVER TOUT : [types d'entités]
FILTRES :
- Condition n° 1
- Condition n°2
SHOW :
- Colonne #1 [Enrichissement ou contrainte]
- Colonne n°2 [Enrichissement ou contrainte]
La différence essentielle réside dans le fait que vous décrivez une logique commerciale, et non une mise en œuvre technique. Vous n’avez pas besoin de savoir quels points d’extrémité de l’API utiliser, comment gérer la pagination ou où trouver les données sur les prix des concurrents.
Les ensembles de données que vous obtenez en retour de Deep Lookup sont sélectionnés, structurés et livrés sous forme de Websets. Les Websets sont vérifiés et entièrement cités, personnalisables (choisissez les champs exacts) et conçus pour rester à jour au fur et à mesure que Deep Lookup scanne de nouvelles sources.
En pratique, le flux est le suivant :
- Posez votre question
- Recherche et raisonnement
- Obtenir des résultats exploitables.
Vous pouvez personnaliser Websets en fonction de l’entité, du secteur, de la géographie et des champs de données pour répondre à votre cas d’utilisation.
Récapitulation
Vous avez maintenant compris que le filtrage des données est le moyen de transformer des informations désordonnées en décisions claires. Le filtrage manuel développe l’intuition, mais l’automatisation apporte la rapidité, la cohérence et la capacité de faire apparaître des modèles que personne ne peut trouver une colonne à la fois.
C’est exactement là que Bright Data intervient. Avec Deep Lookup, vous énoncez vos critères en langage clair et vous obtenez un ensemble de données propre, structuré et toujours frais que vous pouvez intégrer dans des tableaux de bord, des carnets de notes ou des modèles. Associé aux ensembles de données de Bright Data (comme l’ensemble de données Amazon de ce guide), vous passez de l’idée à la compréhension et à la production sans avoir à maintenir des pipelines fragiles.
Prêt à voir ce que le filtrage automatisé peut faire pour vos données ? Essayez Deep Lookup avec un compte Bright Data gratuit. Prenez les règles de filtrage que vous avez appliquées manuellement et découvrez les informations qui vous ont échappé.





