

Dans ce guide, vous apprendrez :
- Ce qu’est la bibliothèque d’
utilisation du navigateurpour le développement d’agents d’intelligence artificielle - Pourquoi ses capacités sont limitées par le navigateur qu’il contrôle
- Comment surmonter ces limitations à l’aide d’un navigateur de scraping?
- Comment construire un agent d’IA qui fonctionne dans le navigateur et évite les blocages grâce à l’intégration avec Scraping Browser
Plongeons dans l’aventure !
Qu’est-ce que l’utilisation d’un navigateur ?
Browser Use est un projet Python à source ouverte qui rend les sites web accessibles aux agents d’intelligence artificielle. Il identifie tous les éléments interactifs d’une page web, ce qui permet aux agents d’effectuer des interactions significatives avec eux. En bref, la bibliothèque Browser Use permet à l’IA de contrôler et d’interagir avec votre navigateur de manière programmatique.
En détail, les principales caractéristiques qu’il offre sont les suivantes :
- Automatisation puissante du navigateur: Combine l’IA avancée avec une automatisation robuste du navigateur afin de simplifier les interactions web pour les agents d’IA.
- Vision + extraction HTML: Intègre la compréhension visuelle et l’extraction de la structure HTML pour une navigation et une prise de décision plus efficaces.
- Gestion multi-onglets: Peut gérer plusieurs onglets de navigateur, ce qui ouvre la voie à des flux de travail complexes et à des tâches parallèles.
- Suivi des éléments: Trace les éléments cliqués à l’aide de XPath et peut répéter les actions exactes prises par un LLM, garantissant ainsi la cohérence.
- Actions personnalisées: Permet de définir des actions personnalisées telles que l’enregistrement dans des fichiers, l’écriture dans des bases de données, l’envoi de notifications ou le traitement de données humaines.
- Mécanisme d’autocorrection: Il est doté d’un système intégré de traitement des erreurs et de récupération automatique pour un pipeline d’automatisation plus fiable.
- Prise en charge de tous les LLM : compatible avec tous les principaux LLM via LangChain, y compris GPT-4, Claude 3 et Llama 2.
Limites de l’utilisation des navigateurs dans le développement d’agents d’intelligence artificielle
Browser Use est une technologie révolutionnaire qui a eu un impact sans précédent sur la communauté informatique. Il n’est pas surprenant que le projet ait atteint plus de 60 000 étoiles GitHub en quelques mois seulement :

En outre, l’équipe à l’origine de ce projet a obtenu un financement d’amorçage de plus de 17 millions de dollars, ce qui en dit long sur le potentiel et la promesse de ce projet.
Cependant, il est important de reconnaître que les capacités de contrôle du navigateur offertes par Browser Use ne sont pas basées sur la magie. Au contraire, la bibliothèque combine l’entrée visuelle avec le contrôle de l’IA pour automatiser les navigateurs via Playwright, uncadre d’automatisation des navigateurs riche en fonctionnalités, mais qui présente certaines limites.
Comme nous l’avons souligné dans nos articles précédents sur le web scraping Playwright, les limitations ne proviennent pas du cadre d’automatisation lui-même. Au contraire, elles proviennent des navigateurs qu’il contrôle. Plus précisément, des outils comme Playwright lancent des navigateurs avec des configurations et des instruments spéciaux qui permettent l’automatisation. Le problème est que ces paramètres peuvent également les exposer à des systèmes de détection anti-bots.
Cela pose un problème majeur, en particulier lorsqu’il s’agit de créer des agents d’intelligence artificielle qui doivent interagir avec des sites bien protégés. Par exemple, supposons que vous souhaitiez utiliser Browser Use pour créer un agent d’intelligence artificielle qui ajoute pour vous des articles spécifiques à un panier d’achat sur Amazon. Voici le résultat que vous obtiendrez probablement :

Comme vous pouvez le constater, le système anti-bot d’Amazon peut détecter et arrêter votre automatisation de l’IA. En particulier, la plateforme de commerce électronique peut afficher le difficile CAPTCHA d’Amazon ou répondre par la page d’erreur “Désolé, quelque chose s’est mal passé chez nous” :

Dans ce cas, c’est la fin de la partie pour votre agent d’intelligence artificielle. Ainsi, bien que l’utilisation du navigateur soit un outil étonnant et puissant, la réalisation de son plein potentiel nécessite des ajustements réfléchis. L’objectif ultime est d’éviter de déclencher des systèmes anti-bots afin que votre automatisation de l’IA puisse fonctionner comme vous le souhaitez.
Pourquoi un navigateur de scraping est-il la solution ?
Vous vous dites peut-être : “Pourquoi ne pas simplement modifier le navigateur que l’utilisateur contrôle via Playwright ? “Pourquoi ne pas simplement modifier le navigateur que l’utilisation du navigateur contrôle via Playwright, en utilisant des drapeaux spéciaux pour réduire les chances de détection ?” C’est en effet possible, et cela fait partie de la stratégie utilisée par des bibliothèques comme Playwright Stealth.
Cependant, contourner la détection anti-bot est bien plus complexe que de faire basculer quelques drapeaux…
Elle fait intervenir des facteurs tels que la réputation IP, la limitation du débit, l’empreinte digitale du navigateur et d’autres aspects avancés. Vous ne pouvez pas simplement déjouer les systèmes anti-bots sophistiqués avec quelques astuces manuelles. Ce dont vous avez vraiment besoin, c’est d’une solution conçue dès le départ pour être indétectable par les défenses anti-bots et anti-scraping. Et c’est là qu’un navigateur de scraping entre en jeu !
Les solutions de navigation pour le scraping offrent des fonctions anti-détection incroyablement efficaces. Quel est donc le meilleur navigateur anti-détection du marché ? Le navigateur de scraping de Bright Data !
En particulier, Scraping Browser est un navigateur web de nouvelle génération, basé sur l’informatique dématérialisée, qui offre les avantages suivants
- Empreintes TLS fiables pour se fondre dans la réalité des utilisateurs
- Évolutivité illimitée pour le scraping à haut volume
- Rotation automatique de l’IP, soutenue par un réseau de proxy IP de plus de 150 millions d’adresses.
- Logique de réessai intégrée pour traiter les demandes échouées de manière élégante
- Capacités de résolution des CAPTCHA, prêtes à l’emploi
- Une boîte à outils complète pour le contournement des robots
Scraping Browser s’intègre à toutes les principales bibliothèques d’automatisation des navigateurs, y compris Playwright, Puppeteer et Selenium. Elle est donc entièrement compatible avec l’utilisation des navigateurs, car cette bibliothèque s’appuie sur Playwright.
En intégrant Scraping Browser dans Browser Use, vous pouvez contourner les blocages d’Amazon que vous avez rencontrés précédemment – ou éviter des blocages similaires sur n’importe quel autre site.
Comment intégrer l’utilisation d’un navigateur avec un navigateur de scraping ?
Dans cette section du tutoriel, vous apprendrez à intégrer l’utilisation du navigateur avec le navigateur de scraping de Bright Data. Nous construirons un agent IA alimenté par OpenAI qui peut ajouter des articles au panier Amazon.
Ce n’est qu’un exemple qui démontre la puissance de l’automatisation du navigateur par l’IA. Notez que l’agent d’IA peut interagir avec d’autres sites, en fonction de vos besoins et de vos objectifs. Ce qui compte, c’est qu’il vous permet d’économiser beaucoup de temps et d’efforts en effectuant des opérations fastidieuses à votre place.
En détail, l’agent Amazon AI que nous sommes sur le point de construire sera capable de.. :
- Connectez-vous à Amazon en utilisant une instance distante de Scraping Browser pour éviter la détection et les blocages.
- Lire une liste d’éléments à partir de l’invite.
- Recherchez, sélectionnez les bons produits et ajoutez-les automatiquement à votre panier.
- Visitez le panier et fournissez un résumé de l’ensemble de la commande.
Suivez les étapes ci-dessous pour savoir comment utiliser Browser Use with Scraping Browser !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir les éléments suivants :
- Un compte Bright Data.
- Une clé API d’un fournisseur d’IA pris en charge tel que OpenAI, Anthropic, Gemini, DeepSeek, Grok ou Novita.
- Connaissance de base de la programmation asynchrone Python et de l’automatisation des navigateurs.
Si vous n’avez pas encore de compte Bright Data ou AI, ne vous inquiétez pas. Nous vous expliquons comment les créer dans les étapes ci-dessous.
Étape 1 : Configuration du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre système. Sinon, téléchargez-le sur le site officiel et suivez les instructions d’installation.
Ouvrez votre terminal et créez un nouveau dossier pour votre projet d’agent d’intelligence artificielle :
mkdir browser-use-amazon-agentLe dossier browser-use-amazon-agent contiendra tout le code de votre agent IA basé sur Python.
Naviguez dans le dossier du projet et créez un environnement virtuel à l’intérieur de celui-ci :
cd browser-use-amazon-agent
python -m venv venvOuvrez maintenant le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux choix valables.
Dans le dossier browser-use-amazon-agent, créez un nouveau fichier Python nommé agent.py. La structure de votre projet devrait maintenant ressembler à ceci :
À ce stade, agent.py n’est qu’un script vide, mais il contiendra bientôt toute la logique d’automatisation de votre navigateur IA.
Dans le terminal de votre IDE, activez l’environnement virtuel. Sous Linux/macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateVous êtes prêts ! Votre environnement Python est maintenant prêt à construire un agent d’intelligence artificielle avec Browser Use et Scraping Browser.
Étape 2 : Configurer les variables d’environnement Lecture
Votre projet s’intégrera à des services tiers tels que Bright Data et le fournisseur d’IA que vous avez choisi. Au lieu de coder en dur les clés d’API et les secrets de connexion directement dans votre code Python, la meilleure pratique consiste à les charger à partir de variables d’environnement.
Pour simplifier cette tâche, nous utiliserons la bibliothèque python-dotenv. Dans l’environnement virtuel activé, installez-la avec :
pip install python-dotenvDans votre fichier agent.py, importez la bibliothèque et chargez les variables d’environnement avec load_dotenv() :
from dotenv import load_dotenv
load_dotenv()Vous serez maintenant en mesure de lire des variables à partir d’un fichier .env local. Ajoutez-le à votre projet :

Vous pouvez maintenant accéder à ces variables d’environnement dans votre code avec cette ligne de code :
env_value = os.getenv("<ENV_NAME>")N’oubliez pas d’importer os de la bibliothèque standard de Python :
import osC’est très bien ! Vous êtes maintenant prêt à lire en toute sécurité les secrets pour l’intégration avec des services tiers à partir des envs.
Étape 3 : Démarrer avec l’utilisation du navigateur
Une fois votre environnement virtuel activé, installez browser-use:
pip install browser-useComme la bibliothèque repose sur plusieurs dépendances, cela peut prendre quelques minutes. Soyez donc patient.
Puisque l 'utilisation du navigateur utilise Playwright sous le capot, il se peut que vous deviez également installer les dépendances du navigateur Playwright. Pour ce faire, exécutez la commande suivante :
python -m playwright installCette opération permet de télécharger les binaires nécessaires au navigateur et de mettre en place tout ce dont Playwright a besoin pour fonctionner correctement.
Importez maintenant les classes requises à partir de l’utilisation du navigateur :
from browser_use import Agent, Browser, BrowserConfigNous utiliserons ces classes pour construire la logique d’automatisation du navigateur de l’agent AI.
Puisque browser-use fournit une API asynchrone, vous devez initialiser votre agent.py avec un point d’entrée asynchrone :
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())L’extrait ci-dessus utilise la bibliothèque asyncio de Python pour exécuter des tâches asynchrones, ce qui est nécessaire pour travailler avec l’utilisation du navigateur.
C’est fait ! L’étape suivante consiste à configurer le Scraping Browser et à l’intégrer dans votre script.
Étape 4 : Démarrer avec le navigateur de scraping
Pour des instructions générales sur l’intégration, reportez-vous à la documentation officielle de Scraping Browser. Sinon, suivez les étapes ci-dessous.
Pour commencer, si vous ne l’avez pas encore fait, créez un compte Bright Data. Connectez-vous, accédez au tableau de bord de l’utilisateur et cliquez sur le bouton “Get proxy products” :
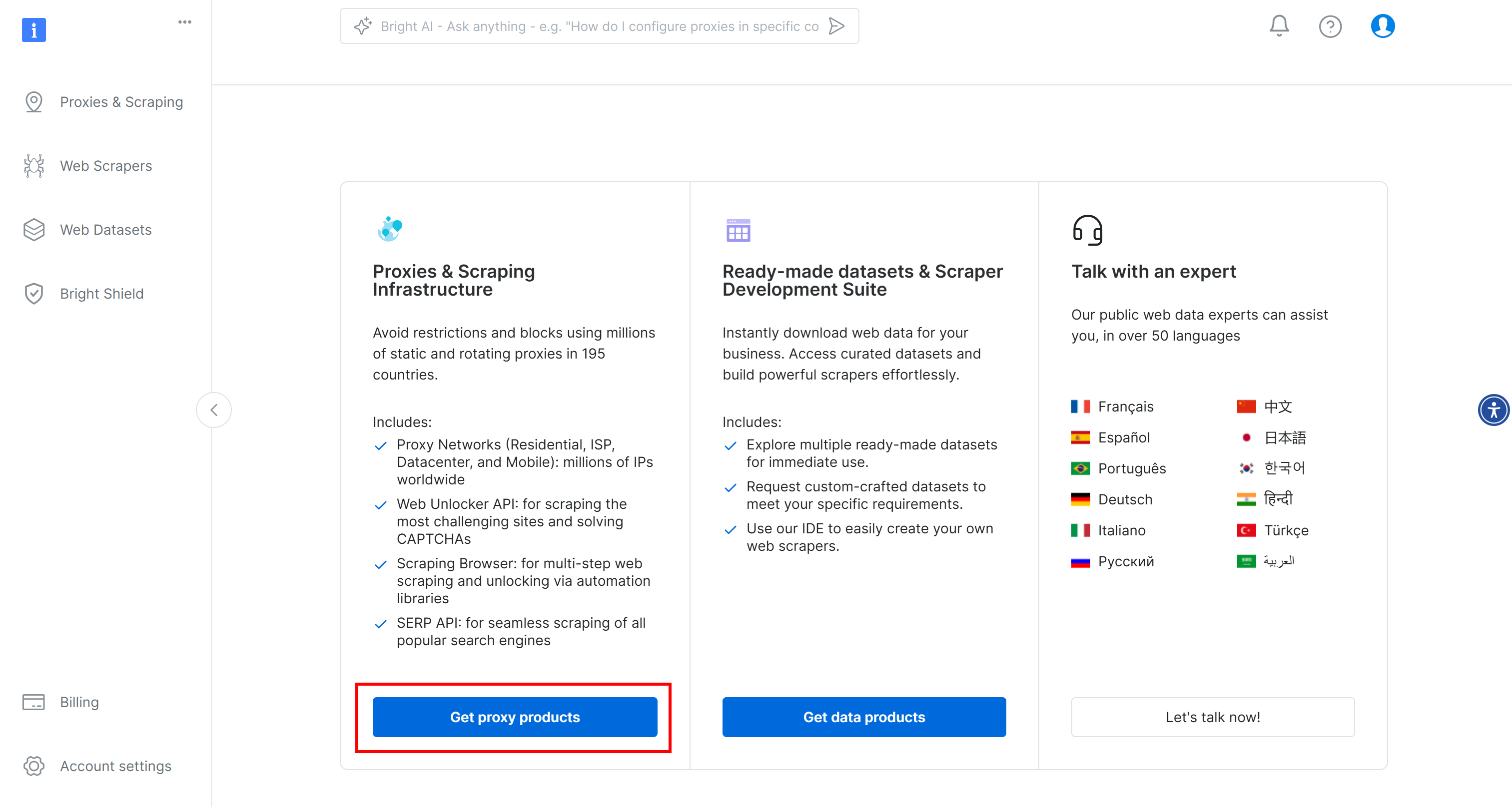
Sur la page “Proxies & Scraping Infrastructure”, recherchez le tableau “My Zones” et sélectionnez la ligne correspondant au type “Scraping Browser” :

Si vous ne voyez pas une telle ligne, cela signifie que vous n’avez pas encore configuré la zone du navigateur de capture. Dans ce cas, faites défiler vers le bas jusqu’à ce que vous trouviez la carte “Browser API” et appuyez sur le bouton “Get Started” :

Ensuite, suivez les instructions pour configurer le Scraping Browser pour la première fois.
Une fois que vous avez atteint la page du produit, activez-le en basculant l’interrupteur marche/arrêt :

Allez maintenant dans l’onglet “Configuration” et assurez-vous que les options “Domaines Premium” et “CAPTCHA Solver” sont activées pour une efficacité maximale :

Passez à l’onglet “Overview” et copiez la chaîne de connexion du navigateur Playwright Scraping Browser :

Ajoutez cette chaîne de connexion à votre fichier .env :
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Remplacez par la valeur que vous venez de copier.
Maintenant, dans votre fichier agent.py, chargez la variable d’environnement avec :
SBR_CDP_URL = os.getenv("SBR_CDP_URL")C’est incroyable ! Vous pouvez maintenant utiliser Scraping Browser à l’intérieur de browser-use. Avant de nous y plonger, complétons les intégrations tierces en ajoutant OpenAI à votre script.
Étape 5 : Démarrer avec OpenAI
Avertissement : L’étape suivante se concentre sur l’intégration d’OpenAI, mais vous pouvez facilement adapter les instructions ci-dessous à tout autre fournisseur d’IA pris en charge par Browser Use.
Pour activer les capacités d’IA dans le navigateur, vous avez besoin d’une clé API valide d’un fournisseur d’IA externe. Dans le cas présent, nous utiliserons OpenAI. Si vous n’avez pas encore généré de clé API, suivez le guide officiel d’OpenAI pour en créer une.
Une fois que vous avez votre clé, ajoutez-la à votre fichier .env :
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Veillez à remplacer par votre véritable clé API.
Ensuite, importez la classe ChatOpenAI de langchain_openai dans agent.py :
from langchain_openai import ChatOpenAINotez que Browser Use s’appuie sur LangChain pour gérer les intégrations d’IA. Ainsi, même si vous n’avez pas explicitement installé langchain_openai dans votre projet, il est déjà disponible. Pour plus d’informations, lisez notre tutoriel sur l’intégration de Bright Data dans les flux de travail LangChain.
Configurer l’intégration OpenAI en utilisant le modèle gpt-4o avec :
llm = ChatOpenAI(model="gpt-4o")Aucune configuration supplémentaire n’est nécessaire. En effet, langchain_openai lira automatiquement la clé API à partir de la variable d’environnement OPENAI_API_KEY.
Pour l’intégration avec d’autres modèles ou fournisseurs d’IA, voir la documentation officielle sur l’utilisation du navigateur.
Étape n° 6 : Intégrer le navigateur de capture dans l’utilisation du navigateur
Pour se connecter à un navigateur distant dans l’utilisation du navigateur, il faut utiliser l’objetBrowserConfig comme suit :
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)Cette configuration indique à Playwright de se connecter à l’instance distante du navigateur d’extraction de données Bright.
Étape n° 7 : Définir la tâche à automatiser
Il est maintenant temps de définir la tâche que vous souhaitez que votre agent d’intelligence artificielle exécute dans le navigateur en utilisant le langage naturel.
Avant de le faire, assurez-vous que l’objectif est clairement défini dans votre esprit. Dans le cas présent, supposons que vous souhaitiez que l’agent d’intelligence artificielle.. :
- Se connecter à Amazon.com.
- Ajouter la console PlayStation 5 et le jeu Astro Bot PS5 au panier.
- Accéder à la page du panier et générer un résumé de la commande en cours.
Si vous ne donnez que ces instructions de base à Browser Use, il se peut que les choses ne se passent pas comme prévu. En effet, certains produits ont plusieurs versions, certaines pages peuvent vous inviter à souscrire une assurance supplémentaire, certains articles peuvent être indisponibles, etc.
Il est donc logique d’ajouter des notes supplémentaires pour guider les décisions de l’agent IA dans ces situations.
En outre, pour améliorer les performances, il est utile de décrire clairement les étapes les plus importantes.
Dans cette optique, la tâche que votre agent d’intelligence artificielle doit accomplir dans le navigateur peut être décrite comme suit :
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""Cette version est suffisamment détaillée pour guider l’agent IA dans les scénarios les plus courants et éviter qu’il ne se retrouve bloqué.
Magnifique ! Voir comment lancer cette tâche.
Étape n° 8 : Lancer la tâche d’IA
Initialiser un objet Agent utilisé par le navigateur à l' aide de la définition des tâches de votre agent d’intelligence artificielle :
agent = Agent(
task=task,
llm=llm,
browser=browser,
)Vous pouvez maintenant exécuter l’agent avec :
await agent.run()N’oubliez pas non plus de fermer le navigateur contrôlé par Playwright lorsque la tâche est terminée afin de libérer ses ressources :
await browser.close()Parfait ! L’intégration Browser Use + Bright Data Scraping Browser est maintenant complètement configurée. Il ne reste plus qu’à assembler le tout et à exécuter le code complet.
Étape n° 9 : Assembler le tout
Votre fichier agent.py doit contenir :
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Et voilà ! En moins de 100 lignes de code, vous avez construit un puissant agent d’IA qui combine l’utilisation du navigateur avec le navigateur de scraping de Bright Data.
Pour exécuter votre agent d’IA, exécutez :
python agent.pyUne fois lancé, le navigateur enregistre tout ce qu’il fait. Étant donné que le navigateur s’exécute dans le nuage et qu’il n’y a pas d’interface visuelle, ces journaux sont essentiels pour comprendre ce que fait l’agent.
Voici un court extrait de ce à quoi les journaux pourraient ressembler :
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.Comme vous pouvez le voir, l’agent IA a réussi à trouver les articles souhaités, à les ajouter au panier et à générer un résumé clair. Tout cela sans blocage ni interdiction de la part d’Amazon, grâce au Scraping Browser !
browser-use comprend également des fonctionnalités permettant d’enregistrer la session du navigateur à des fins de débogage. Bien que cela ne fonctionne pas encore avec le navigateur distant, si c’était le cas, vous verriez une lecture hypnotique de l’agent d’intelligence artificielle en action :
Vraiment hypnotique, et un aperçu passionnant de l’évolution de la navigation assistée par l’IA.
Étape n° 10 : Prochaines étapes
L’agent Amazon AI que nous avons construit ici n’est qu’un point de départ – une preuve de concept pour montrer ce qui est possible. Pour qu’il soit prêt pour la production, voici quelques idées d’amélioration :
- Connectez-vous à votre compte Amazon: Autorisez l’agent à se connecter, afin qu’il puisse accéder à des fonctions personnalisées telles que l’historique des commandes et les recommandations.
- Mettre en place un flux de travail pour les achats: Étendez l’agent pour qu’il puisse effectuer des achats. Cela inclut la sélection des options d’expédition, l’application de codes promotionnels ou de cartes-cadeaux, et la confirmation du paiement.
- Envoyer une confirmation ou un rapport par courrier électronique: Avant de finaliser une transaction de paiement, l’agent peut envoyer par courrier électronique un résumé détaillé du panier et des actions prévues pour approbation par l’utilisateur. Vous gardez ainsi le contrôle et ajoutez une couche de responsabilité.
- Lire des éléments à partir d’une liste de souhaits ou d’une liste d’entrée: Demander à l’agent de charger dynamiquement des éléments à partir d’une liste de souhaits Amazon enregistrée, d’un fichier local (JSON ou CSV, par exemple) ou d’un point d’extrémité API distant.
Conclusion
Dans cet article de blog, vous avez appris à utiliser la bibliothèque populaire browse-use en combinaison avec une API de scraping de navigateur pour construire un agent d’IA très efficace en Python.
Comme nous l’avons démontré, la combinaison de Browse Use avec le navigateur de capture de Bright Data vous permet de créer des agents d’IA capables d’interagir de manière fiable avec pratiquement n’importe quel site Web. Ce n’est qu’un exemple de la façon dont les outils et les services de Bright Data peuvent permettre une automatisation avancée basée sur l’IA.
Découvrez nos solutions pour le développement d’agents d’IA :
- Agents d’intelligence artificielle autonomes: Recherchez, accédez et interagissez avec n’importe quel site web en temps réel à l’aide d’un puissant ensemble d’API.
- Apps d’IA verticales: créez des pipelines de données fiables et personnalisés pour extraire des données web à partir de sources spécifiques à votre secteur d’activité.
- Modèles de base: Accédez à des ensembles de données conformes à l’échelle du web pour faciliter le pré-entraînement, l’évaluation et la mise au point.
- IA multimodale: exploitez le plus grand référentiel d’images, de vidéos et d’audios au monde, optimisé pour l’IA.
- Fournisseurs de données: Connectez-vous avec des fournisseurs de confiance pour obtenir des ensembles de données de haute qualité, prêts pour l’IA, à grande échelle.
- Paquets de données: Obtenez des ensembles de données curatées, prêtes à l’emploi, structurées, enrichies et annotées.
Pour plus d’informations, consultez notre centre d’information sur l’IA.
Créez un compte Bright Data et essayez tous nos produits et services pour le développement d’agents d’IA !




