

Dans cet article de blog, vous apprendrez :
- Ce qu’est Amazon SageMaker et la valeur qu’il apporte au machine learning.
- Pourquoi les données web sont essentielles pour réussir le feature engineering.
- Où récupérer des données web de haute qualité pour le feature engineering et d’autres scénarios de machine learning.
- Comment effectuer le feature engineering dans Amazon SageMaker à l’aide de jeux de données contenant des données web.
Plongeons dans le vif du sujet !
Qu’est-ce qu’Amazon SageMaker ?
Amazon SageMaker est un service entièrement géré conçu pour vous aider à créer, entraîner et déployer des modèles de machine learning et des applications IA à grande échelle. Il offre un environnement unifié de bout en bout pour l’analytique et l’IA.
Il vous permet d’accéder à des données provenant de plusieurs sources, qu’elles soient stockées dans des data lakes Amazon S3, des entrepôts de données Redshift, ou des systèmes tiers et fédérés. Tout cela en garantissant une sécurité et une gouvernance de niveau entreprise.
En résumé, SageMaker simplifie les workflows ML et accélère le développement de modèles, du feature engineering au déploiement. Voici les principales fonctionnalités et capacités qu’il vous offre :
- SageMaker Unified Studio : Un environnement de développement unique pour créer, entraîner et déployer des modèles ML et d’IA générative avec une infrastructure entièrement gérée et des outils intégrés.
- Développement de modèles et MLOps : Inclut des modèles préconstruits, HyperPod et JumpStart pour le prototypage rapide, l’entraînement et l’opérationnalisation des modèles.
- Support de l’IA générative : Créez et faites évoluer des applications avec Amazon Bedrock et exploitez des assistants IA intégrés comme Amazon Q Developer.
- Traitement des données et analytique SQL : Préparez, analysez et intégrez des données à l’aide de frameworks open source sur Amazon Athena, EMR, Glue et Redshift.
- Architecture Lakehouse : Unifie l’accès aux données cloisonnées dans différents systèmes de stockage pour soutenir une analytique et une IA complètes.
Introduction au Feature Engineering avec des données web
Le feature engineering est le processus de transformation de données brutes en variables significatives, appelées « features », que les modèles de machine learning peuvent utiliser plus efficacement. Plutôt que d’alimenter un modèle avec des données non traitées, l’idée est de créer des métriques dérivées qui capturent mieux les patterns du jeu de données source.
Les exemples incluent l’agrégation de valeurs, la normalisation de scores, la combinaison de variables liées, ou la création de ratios qui mettent en évidence les relations entre différents champs. Un bon feature engineering peut même avoir un impact plus important sur la performance du modèle que le choix de l’algorithme lui-même. C’est parce que des features bien conçues aident les modèles à identifier des signaux qui resteraient autrement cachés.
Les données web sont particulièrement précieuses pour le feature engineering car elles reflètent l’activité du monde réel à grande échelle. Les sites web publics contiennent de grandes quantités d’informations sur les entreprises, les produits, les emplois, les avis, les prix et le comportement des utilisateurs. Ces signaux peuvent être transformés en features telles que des indicateurs de popularité, des métriques de demande du marché, des scores de sentiment ou des tendances de recrutement. De telles features peuvent améliorer significativement les performances de vos pipelines de machine learning.
Cependant, travailler avec des données web présente également plusieurs défis. Les données peuvent être bruitées, incomplètes ou incohérentes. Cela peut grandement affecter la qualité des données d’entrée. De plus, de nombreux sites web adoptent des mesures anti-bot.
Ainsi, utiliser le Scraping web pour alimenter le machine learning est délicat. Les données collectées doivent être nettoyées, validées et préparées avant de pouvoir être utilisées dans un pipeline ML.
Où récupérer des données web de haute qualité en grande quantité
Comme vous l’avez compris, les données web jouent un rôle central dans le feature engineering. En même temps, les récupérer de manière fiable et pour une utilisation en entreprise est difficile. Collecter des données depuis quelques pages peut sembler simple si vous suivez une feuille de route de Scraping web, mais le faire de manière cohérente sur de nombreux domaines ou un grand site est bien plus complexe.
Les sites web modifient fréquemment leur structure, appliquent des limites de débit et déploient des protections anti-bot qui bloquent les requêtes automatisées. De plus, même lorsque vous parvenez à collecter les données, s’assurer qu’elles sont de haute qualité, complètes et à jour peut être difficile.
Pour cette raison, de nombreuses organisations s’appuient sur des entreprises de jeux de données web et des fournisseurs de données web comme Bright Data. Ces plateformes vous donnent accès à de grandes quantités de données web, sans avoir à construire et maintenir une Infrastructure de scraping.
Bright Data propose des centaines de jeux de données provenant de plus de 215 domaines web populaires, avec plus de 17 milliards d’enregistrements au total. Ces jeux de données contiennent des données web continuellement mises à jour, structurées, prêtes à l’emploi et optimisées pour les applications ML et IA. Explorez le marché des jeux de données !
Si les jeux de données précollectés ne répondent pas à vos besoins, Bright Data propose également des API de Scraping web et d’autres outils de collecte de données. Ceux-ci vous permettent de récupérer des données fraîches depuis des sites web à la demande sans gérer vous-même les défis du scraping.
Ce qui distingue Bright Data, c’est son infrastructure de collecte de données. Elle repose sur un réseau de Proxy mondial avec plus de 150 millions d’IPs dans plus de 195 pays, atteignant 99,99 % de disponibilité et 99,95 % de taux de succès. Cette base facilite la création d’applications orientées données et de pipelines ML alimentés par des données web fiables.
Comment effectuer le Feature Engineering sur des données web dans Amazon SageMaker
Dans cette section pas à pas, vous serez guidé tout au long du processus de feature engineering dans Amazon SageMaker.
Vous commencerez avec un jeu de données Glassdoor de Bright Data, le téléchargerez sur Amazon S3, le chargerez dans un notebook SageMaker et appliquerez le feature engineering pour créer des métriques significatives. Une fois les features préparées, vous les utiliserez pour entraîner un modèle de machine learning prédictif pour la satisfaction élevée des employés.
Gardez à l’esprit qu’il ne s’agit que d’un exemple, et que de nombreux autres cas d’usage sont possibles.
Suivez les instructions !
Prérequis
Pour suivre ce guide, assurez-vous d’avoir :
- Un compte AWS (même en essai gratuit).
- Un compte Bright Data.
- Un bucket S3 défini dans votre compte AWS.
- Des connaissances de base en Python, notamment en développement de machine learning et en data science.
À partir de maintenant, nous supposerons que votre bucket S3 s’appelle bright-data-sagemaker :
Étape 1 : Récupérer le jeu de données d’entrée depuis Bright Data
La première étape consiste à obtenir les données web d’entrée. Pour le feature engineering, il est préférable de commencer avec un jeu de données large et de haute qualité. Dans cet exemple, nous allons exploiter les vastes collections de jeux de données de Bright Data, en nous concentrant sur un jeu de données Glassdoor comme prévu.
Alternative : Si vous préférez collecter de nouvelles données, vous pouvez utiliser l’une des API de Scraping web de Bright Data pour rassembler des jeux de données frais, structurés et prêts pour le ML. Ces API offrent une option de livraison qui peut envoyer les données directement vers votre compte Amazon S3, rendant l’intégration avec SageMaker transparente.
Si vous n’avez pas encore de compte Bright Data, commencez par en créer un. Sinon, connectez-vous simplement.
Dans le panneau de contrôle Bright Data, sélectionnez l’option de menu « Web Datasets ». Naviguez vers l’onglet « Dataset marketplace » pour parcourir les jeux de données disponibles :
Ici, vous pouvez explorer plus de 200 jeux de données scrapés provenant de plus de 155 domaines, contenant des milliards d’enregistrements.
Recherchez maintenant le jeu de données « Glassdoor companies overview information » et ouvrez sa page :
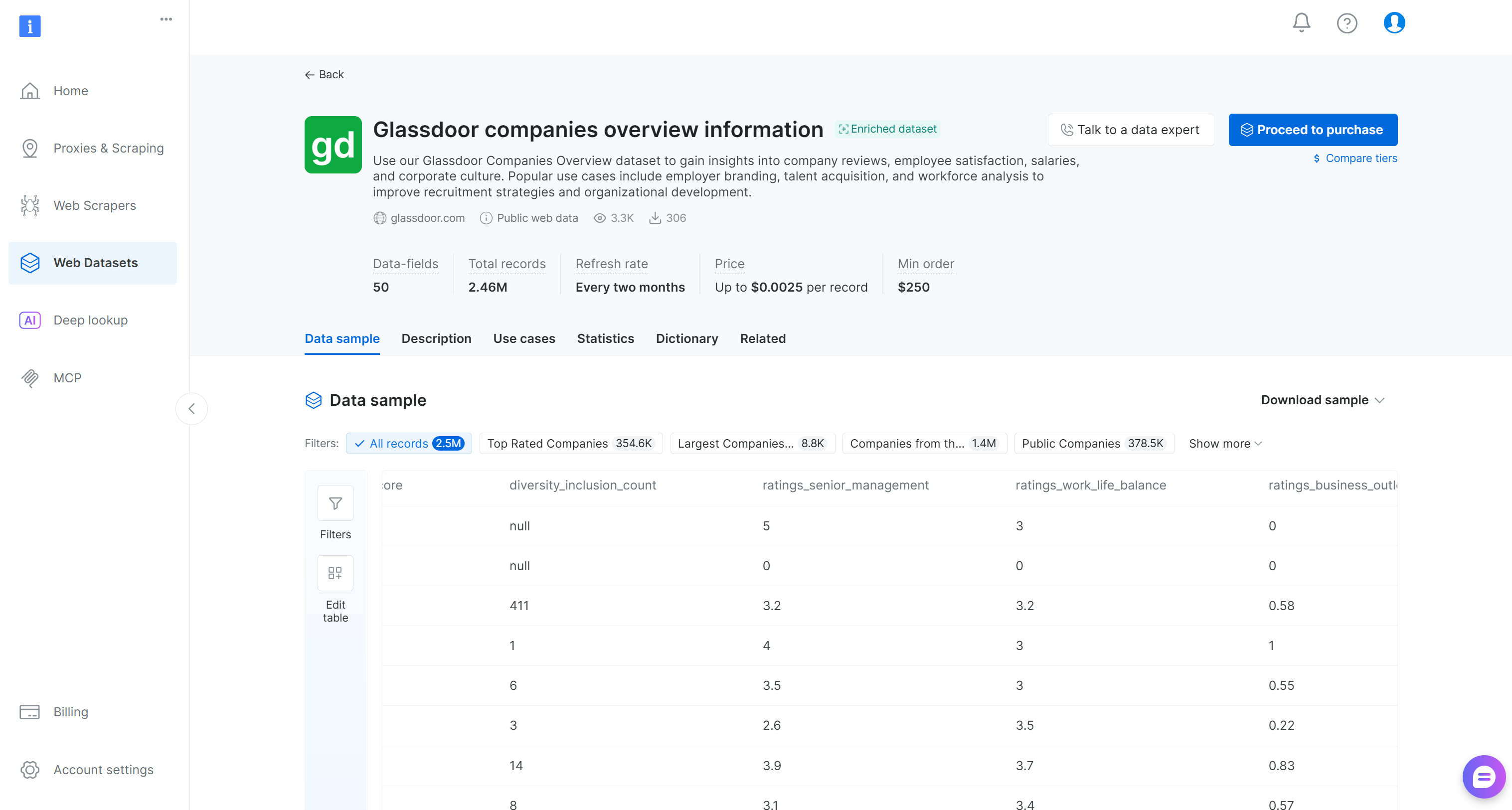
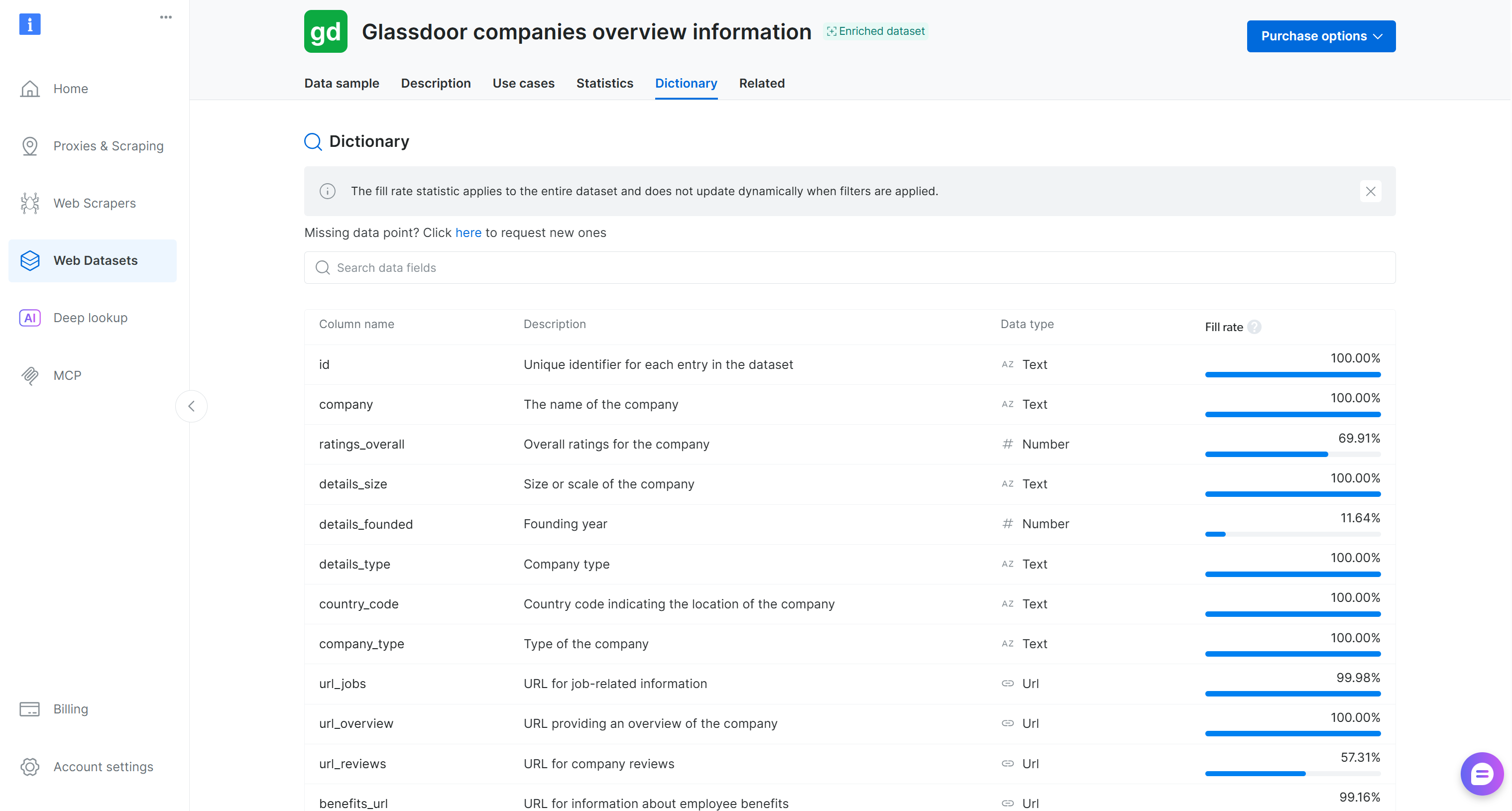
Ce jeu de données comprend des avis d’entreprises, des scores de satisfaction des employés, des salaires et des informations sur la culture d’entreprise. Les cas d’usage populaires incluent l’image employeur, l’acquisition de talents et l’analyse de la main-d’œuvre. Il contient plus de 2,46 millions d’entrées avec 50 champs de données.
Vous pouvez choisir d’acheter un sous-ensemble filtré ou de télécharger un échantillon gratuit. Dans un scénario de production, plus le jeu de données d’entrée est grand, plus vos résultats de feature engineering seront fiables.
Pour ce tutoriel, comme il s’agit simplement d’un exemple, nous utiliserons l’échantillon gratuit. Pour l’obtenir, cliquez sur le menu déroulant « Download sample » et sélectionnez l’option « Download as JSON » :
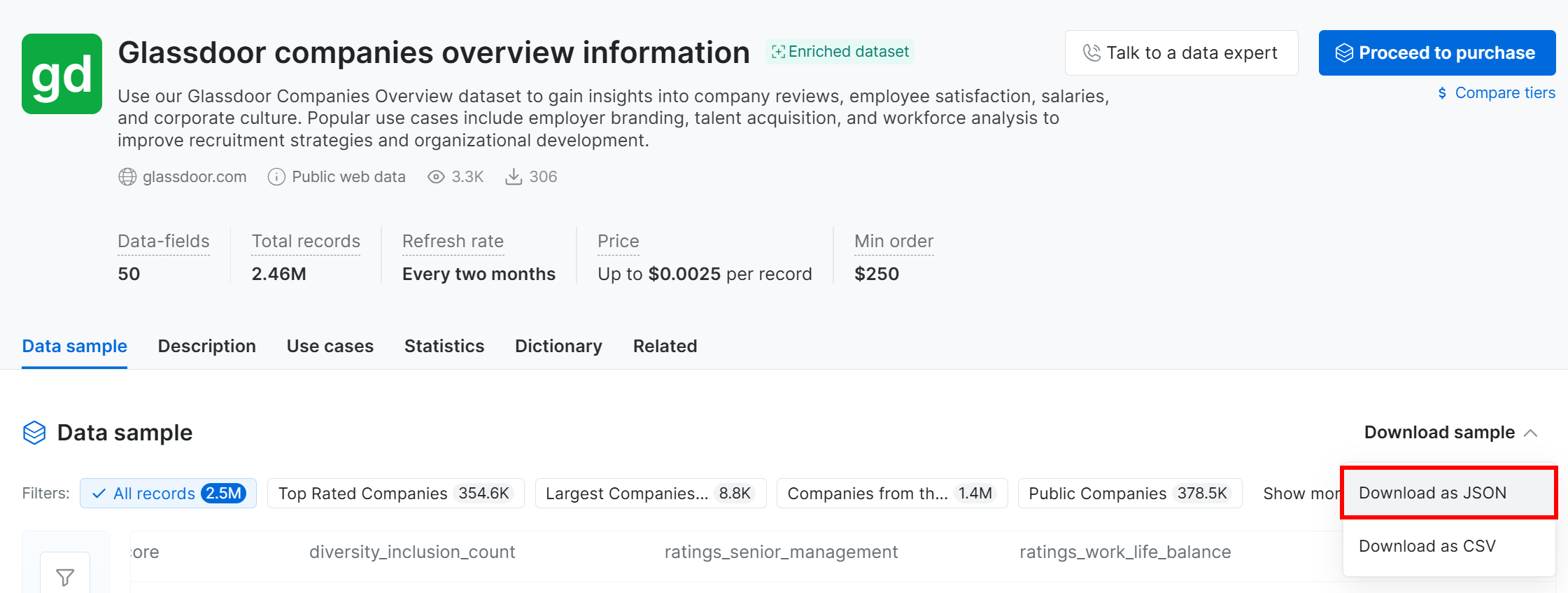
Vous recevrez un fichier d’exemple nommé Glassdoor companies overview information.json. Ce fichier contient 1 000 enregistrements d’entreprises, chacun avec 50 champs.
Renommez le fichier en glassdoor-companies.json et préparez-vous à le télécharger dans votre bucket S3. Il sera utilisé comme entrée pour votre notebook de feature engineering SageMaker. Bien joué !
Étape 2 : Télécharger les données web dans votre bucket S3
Accédez à la page de votre bucket Amazon S3 et cliquez sur le bouton « Upload » pour ajouter le fichier glassdoor-companies.json. Une fois téléchargé, il apparaîtra dans votre bucket comme ceci :

Vous pouvez également utiliser l’un des nombreux clients Amazon S3 pour télécharger le fichier.
Rappel : Avec les API de Scraping web de Bright Data, vous pouvez envoyer les données scrapées directement vers Amazon S3.
Parfait ! Vous disposez maintenant de données web d’entrée pour le feature engineering dans Amazon SageMaker.
Étape 3 : Démarrer avec Amazon SageMaker
Connectez-vous à la console AWS et recherchez « SageMaker ». Sélectionnez le service pour ouvrir sa page principale :
Cliquez sur le bouton « Get started » pour démarrer votre expérience Amazon SageMaker.
Sur la page de configuration, pour une configuration IAM automatique, vérifiez que « Auto-create a new role with admin permissions » est sélectionné. Continuez en appuyant sur le bouton « Set up » :
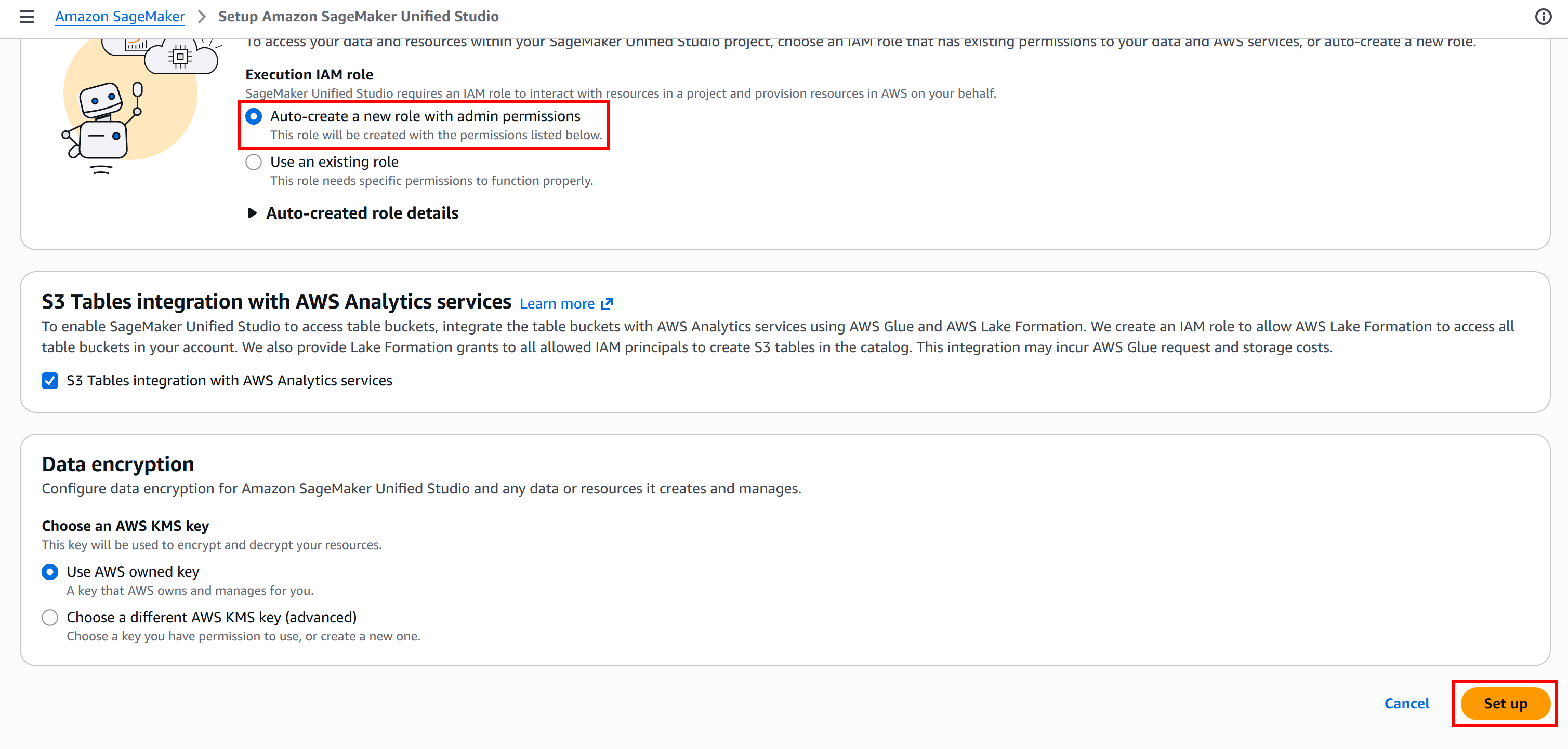
Le processus d’initialisation peut prendre quelques minutes, soyez patient. Pendant son exécution, vous verrez un message « Setting up Amazon SageMaker Unified Studio… ».
Une fois la configuration terminée, vous atteindrez la page suivante :
Cliquez sur « Open » pour lancer Amazon SageMaker Unified Studio :
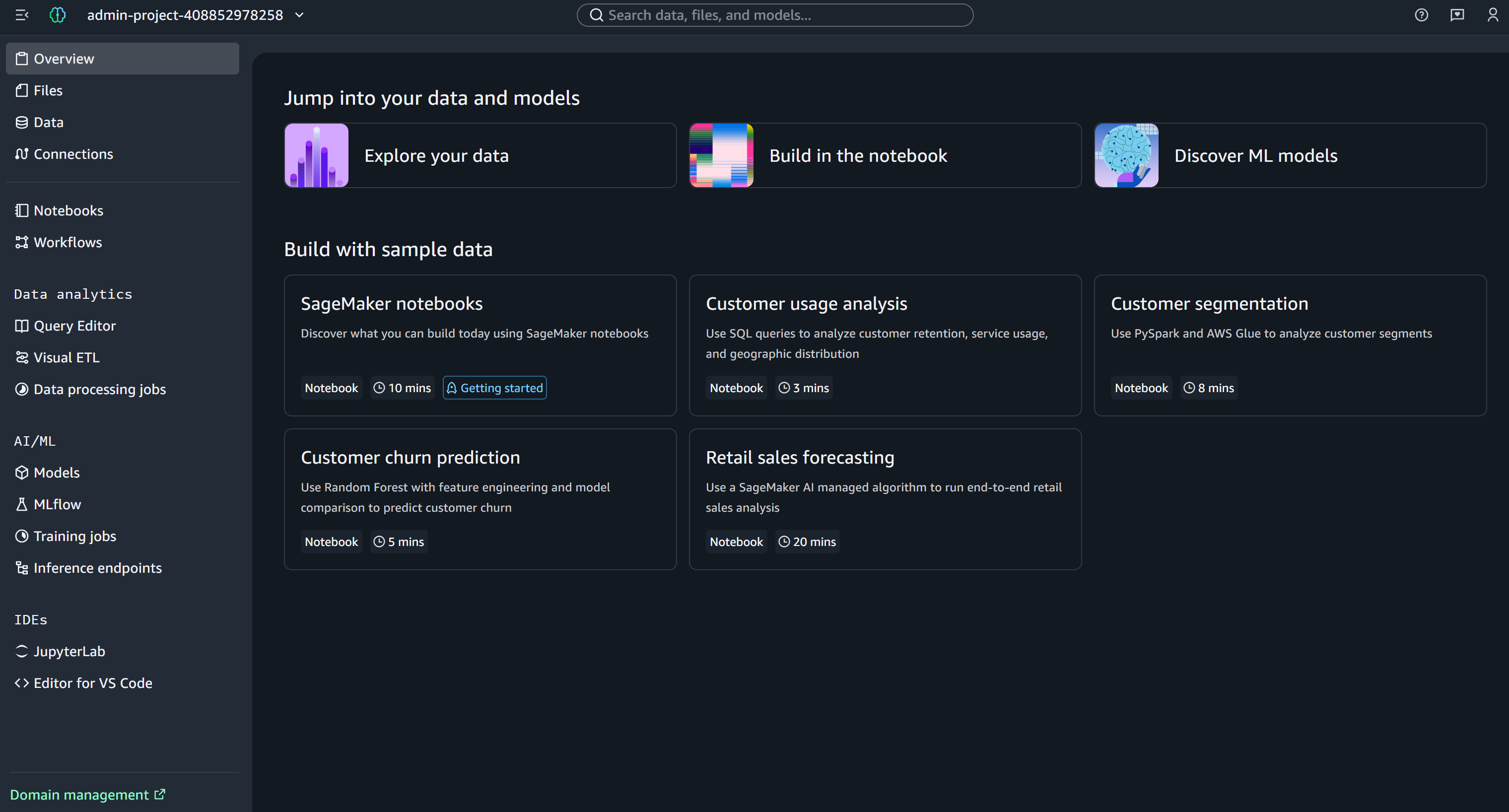
À partir de là, vous pouvez explorer et gérer votre environnement SageMaker, notamment développer et exécuter des notebooks. Super !
Étape 4 : Créer un nouveau notebook
Dans Amazon SageMaker Unified Studio, cliquez sur le bouton « Build in the notebook » pour créer un nouveau notebook :

Voici à quoi devrait ressembler votre nouveau notebook SageMaker :
Pensez à donner à votre notebook un nom descriptif, comme « Company Data Feature Engineering ».
Un notebook Amazon SageMaker est une instance de calcul de machine learning gérée exécutant Jupyter Notebook. Il vous fournit tout ce dont vous avez besoin pour préparer et traiter les données, écrire et tester le code d’entraînement, déployer des modèles sur l’hébergement SageMaker et valider vos modèles.
Excellent ! Vous disposez maintenant de tous les éléments nécessaires pour implémenter la logique de feature engineering SageMaker.
Étape 5 : Charger les données web d’entrée
La première étape consiste à charger vos données web Glassdoor d’entrée de Bright Data dans votre notebook SageMaker.
Dans le panneau « Data Explorer » sur la gauche, développez le menu déroulant « Buckets ». Localisez votre bucket S3 et trouvez le fichier glassdoor-companies.json. Cliquez sur le menu burger à côté du fichier et sélectionnez l’option « Read as dataframe » :
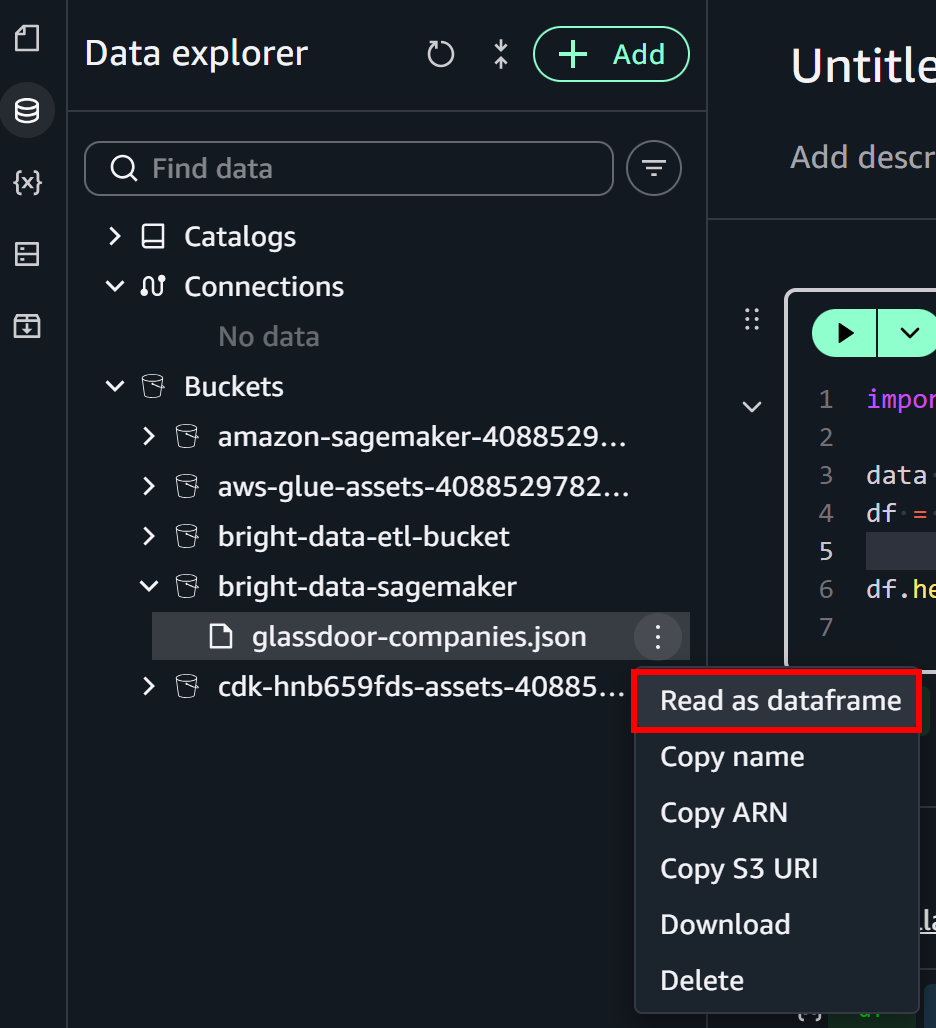
Cela remplira la cellule initiale du notebook avec la logique pour charger le fichier depuis S3 :
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")Remarque : Remplacez bright-data-sagemaker par le nom de votre bucket S3.
Complétez la logique d’importation des données dans la première cellule comme suit :
import pandas as pd
# Load the input data from the S3 bucket
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# Normalize the structured JSON fields
df = pd.json_normalize(data.to_dict(orient="records"))
# Print the first 10 lines
df.head(10)Ce snippet de code charge et prétraite un jeu de données JSON depuis un bucket S3 pour l’analyse en Python. Il utilise pd.read_json() pour lire le fichier, puis pd.json_normalize() pour aplatir les champs JSON imbriqués en un DataFrame tabulaire. Enfin, df.head(10) affiche les 10 premières lignes, offrant un aperçu rapide des données structurées.
Exécutez la cellule en appuyant sur le bouton « ▶ ». Vous devriez voir un aperçu comme celui-ci :
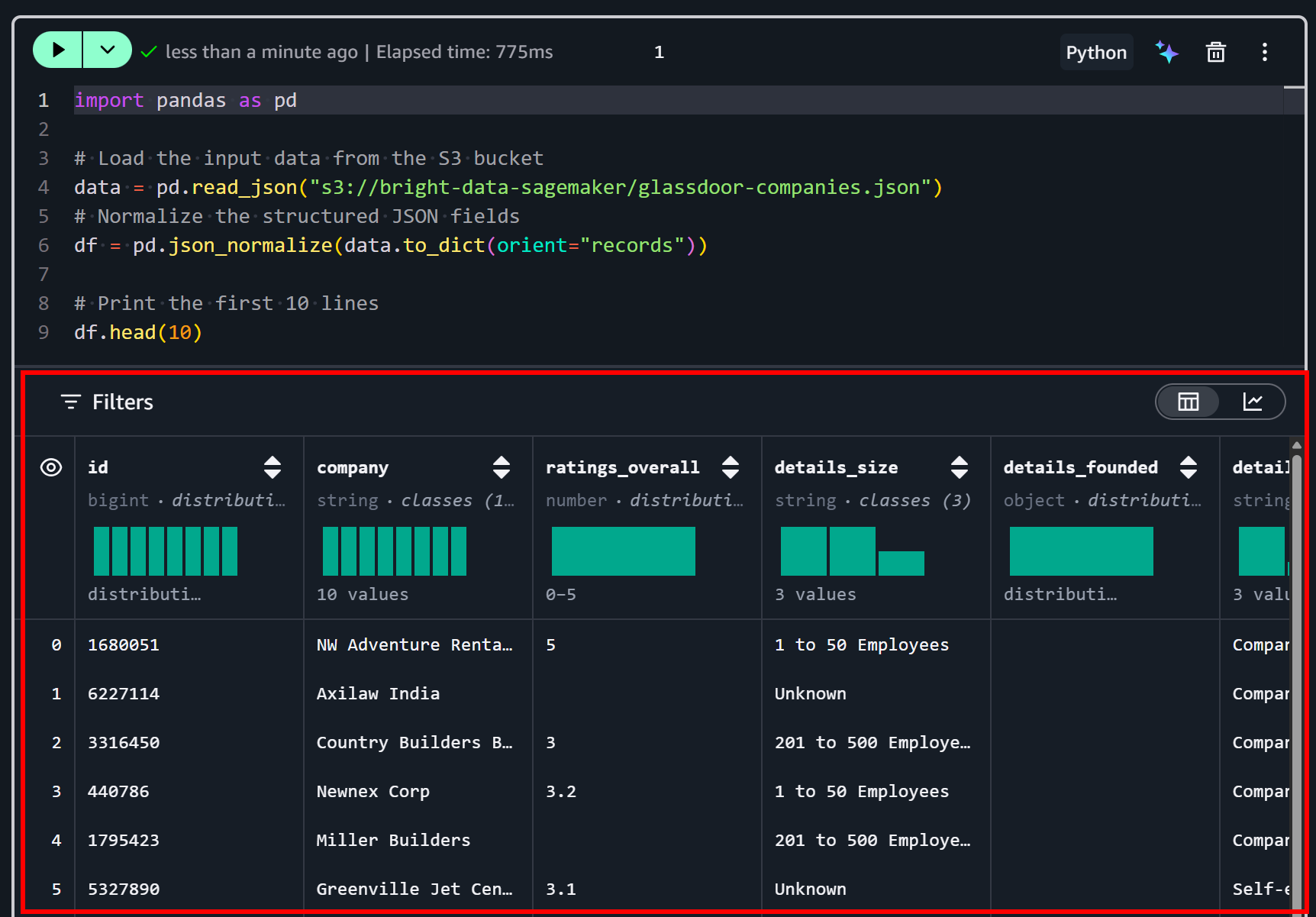
Comme vous pouvez le constater, le jeu de données a été chargé correctement. Il contient 50 champs de données, comme indiqué dans l’onglet « Dictionary » sur la page du jeu de données Bright Data :
Vous avez des données web d’entrée prêtes pour le feature engineering. Fantastique !
Étape 6 : Prétraiter les données d’entrée
Maintenant que vous avez importé votre jeu de données dans le notebook, l’étape suivante consiste à le nettoyer et à le préparer pour le feature engineering.
Ajoutez une nouvelle cellule dans votre notebook SageMaker et saisissez le code suivant :
# Select only the columns of interest
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# Remove all rows containing missing values
df = df.dropna()Ce snippet sélectionne uniquement les colonnes d’intérêt, en gardant votre jeu de données focalisé sur les métriques et identifiants pertinents. Ensuite, il utilise df.dropna() pour supprimer toutes les lignes contenant des valeurs manquantes dans les colonnes sélectionnées. Cela garantit que vos données sont propres et cohérentes pour le feature engineering.
Votre nouvelle cellule ressemblera à ceci :
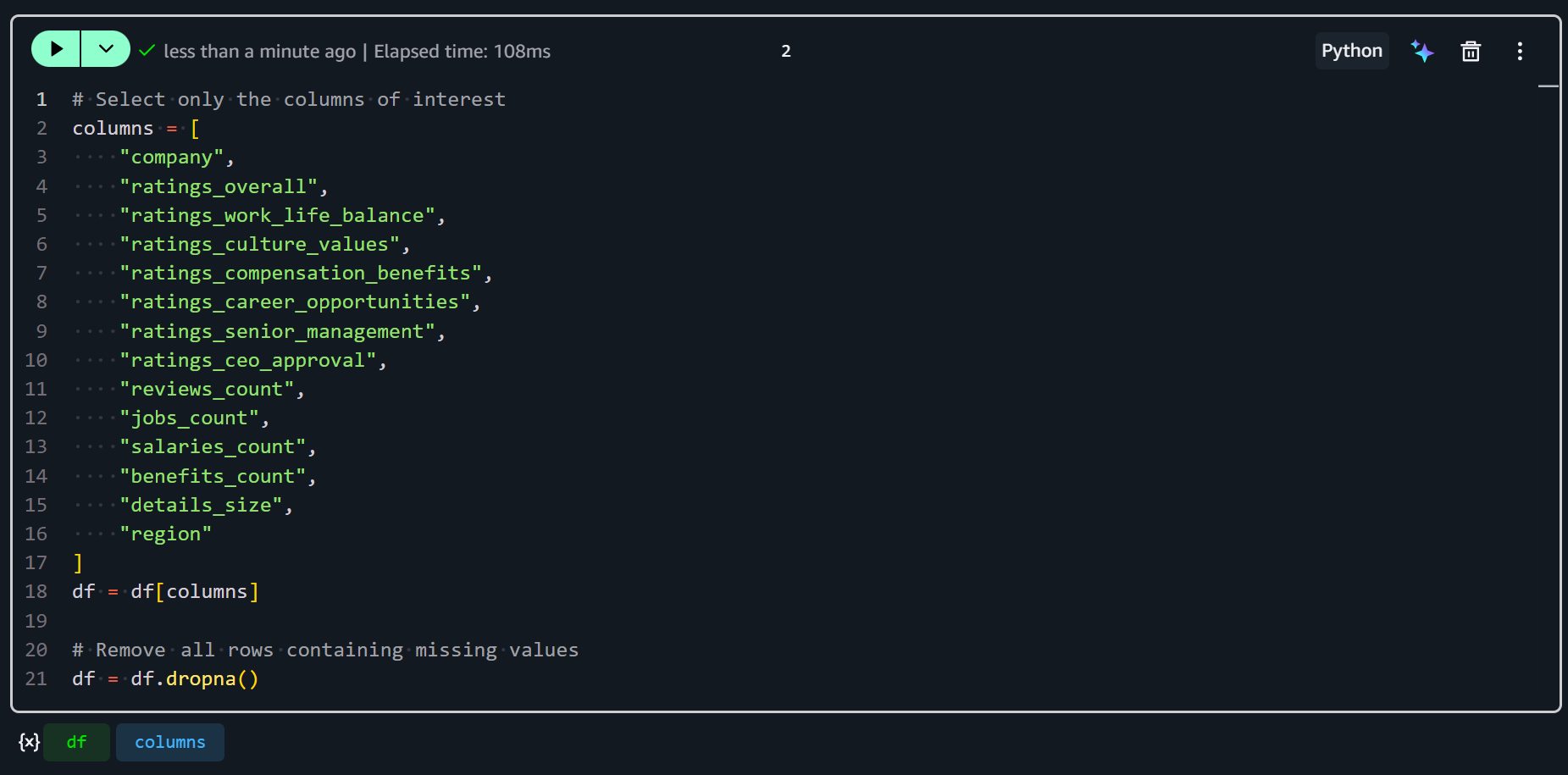
Parfait ! Votre jeu de données d’entrée est maintenant prêt pour le feature engineering dans SageMaker.
Étape 7 : Définir les features
Il est temps de définir les features que vous utiliserez pour le machine learning. Rappelons que les features sont des colonnes dérivées qui résument ou transforment des données brutes en métriques significatives représentant mieux les patterns sous-jacents.
Dans cet exemple, vous ajouterez des features qui capturent la culture d’entreprise, la rémunération, la popularité et l’activité de croissance.
Premièrement, la feature culture_score combine plusieurs notes connexes en une seule métrique représentant l’environnement culturel global d’une entreprise :
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 3Elle fait la moyenne de trois colonnes de notes :
ratings_culture_values: Décrit dans quelle mesure l’entreprise incarne ses valeurs déclarées.ratings_work_life_balance: Note la perception des employés sur l’équilibre vie professionnelle-vie personnelle.ratings_senior_management: Suit la perception du leadership et du management.
La somme des trois notes divisée par 3 produit un score normalisé. Le score résultant conserve la même échelle que les notes d’origine et accorde un poids égal à chaque aspect de la culture.
Deuxièmement, la feature compensation_score représente une vue combinée de la satisfaction des employés concernant la rémunération et l’évolution de carrière :
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2Elle implique :
ratings_compensation_benefits: Mesure la satisfaction des employés concernant la rémunération et les avantages.ratings_career_opportunities: Suit la satisfaction des employés concernant les opportunités d’avancement professionnel.
En faisant la moyenne, la feature sera mise à l’échelle de manière cohérente avec les autres scores pour équilibrer les deux aspects de façon égale.
Troisièmement, la feature review_popularity mesure la fréquence à laquelle une entreprise est évaluée sur Glassdoor :
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)Elle est obtenue en appliquant une transformation racine carrée au nombre d’avis. Pourquoi la racine carrée ? Parce que les nombres d’avis sont souvent très asymétriques (certaines entreprises ont des milliers d’avis, beaucoup en ont très peu). Prendre la racine carrée réduit l’impact des valeurs extrêmement élevées et stabilise la variance, facilitant ainsi le traitement et l’analyse.
Quatrièmement, la feature hiring_intensity estime à quel point une entreprise recrute activement par rapport à son activité d’évaluation :
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)Elle est calculée en divisant le nombre d’offres d’emploi ouvertes (jobs_count) par le nombre d’avis plus 1 (pour éviter la division par zéro pour les entreprises sans avis).
Des valeurs plus élevées indiquent des entreprises qui recrutent activement par rapport au nombre d’employés laissant des avis. Cela peut servir d’indicateur d’activité de croissance ou d’expansion.
En rassemblant tout cela, vous obtiendrez :
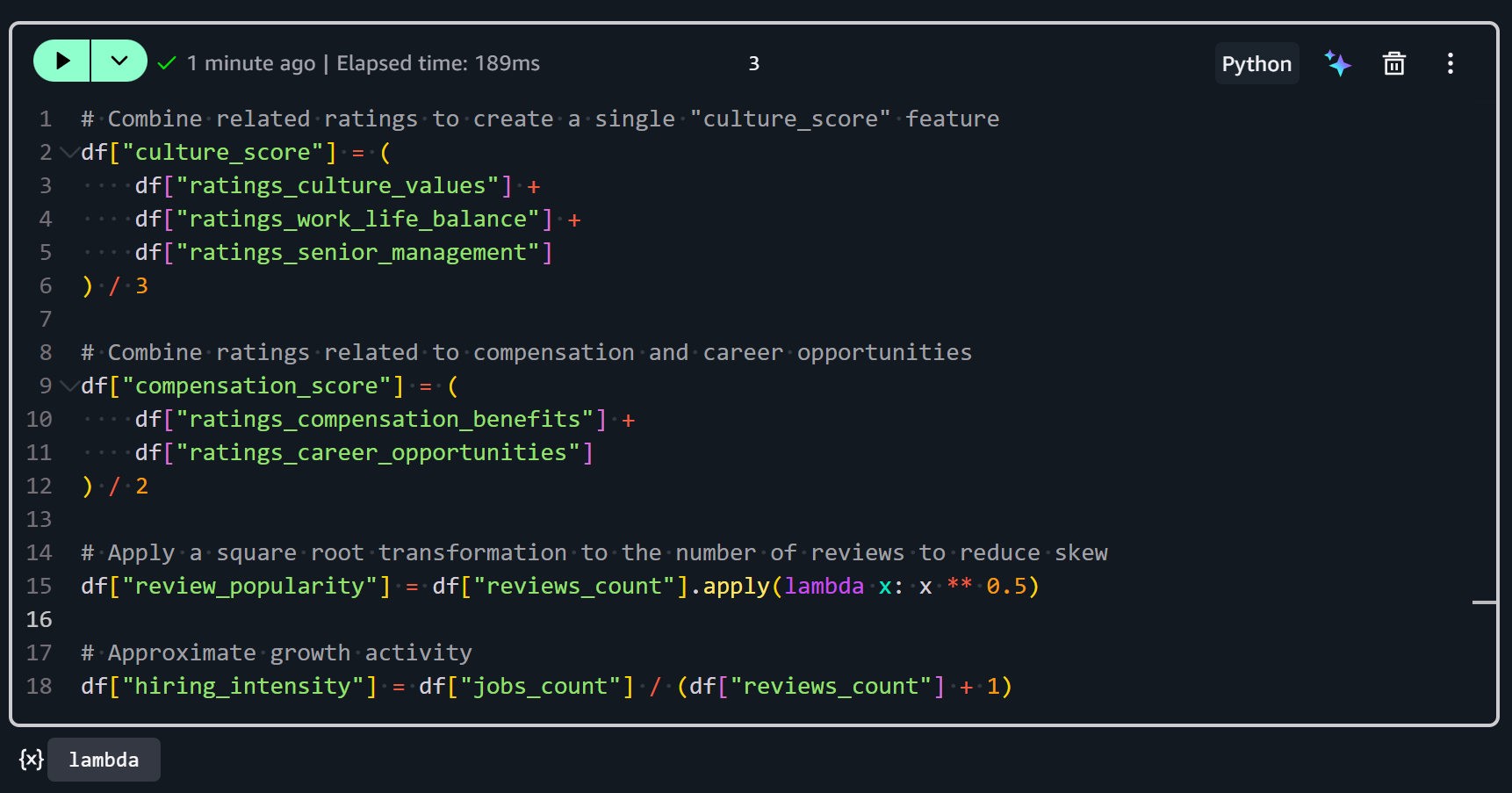
Après avoir exécuté ces transformations, votre jeu de données contient maintenant des features dérivées qui combinent des notes et des comptages bruts en métriques plus informatives. Excellent !
Étape 8 : Définir la variable cible
Maintenant que vos features sont définies, l’étape suivante consiste à définir la variable cible pour votre tâche de machine learning. La variable cible représente le résultat que vous souhaitez que votre modèle prédise. Dans ce cas, vous prédirez si une entreprise a une satisfaction élevée des employés.
Pour définir la cible, ajoutez une nouvelle cellule dans votre notebook avec ce code :
# Define the target variable
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)Cela crée un champ booléen où les entreprises avec une note globale de 4 ou plus sont marquées comme True (satisfaction élevée), et les autres comme False (satisfaction faible).

De nombreux algorithmes de machine learning nécessitent une variable cible numérique. En convertissant les notes de satisfaction en une étiquette booléenne binaire 0/1, vous pouvez entraîner des modèles pour des tâches de classification. Cela vous aide à prédire si une entreprise aura probablement des employés très satisfaits en fonction des features que vous avez créées. Réalisez cela à l’étape suivante !
Étape 9 : Entraîner le modèle ML pour la prédiction de satisfaction
Avec vos features et votre variable cible définies, vous pouvez maintenant entraîner un modèle de machine learning pour prédire la satisfaction élevée des employés.
Le modèle ML choisi est XGBoost, un algorithme de gradient boosting qui fonctionne exceptionnellement bien sur les données tabulaires et les tâches de classification. Il est adapté pour prédire la variable high_satisfaction sur la base d’un mélange de features numériques et dérivées.
Ajoutez une nouvelle cellule dans votre notebook et ajoutez la logique pour entraîner votre modèle avec :
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# Define the features to use for prediction
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# Separate input features (X) and target variable (y)
X = df[features]
y = df["high_satisfaction"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize the XGBoost classifier with some reasonable hyperparameters
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# Train the model on the training data
model.fit(X_train, y_train)Le snippet ci-dessus prépare et entraîne un modèle de machine learning pour prédire la satisfaction élevée des employés. Il sélectionne les features engineered et divise les données en ensembles d’entraînement et de test. Ensuite, il initialise un classificateur XGBoost avec des hyperparamètres ajustés. Enfin, il ajuste le modèle aux données d’entraînement.
Exécutez la cellule pour entraîner effectivement le modèle prédictif :
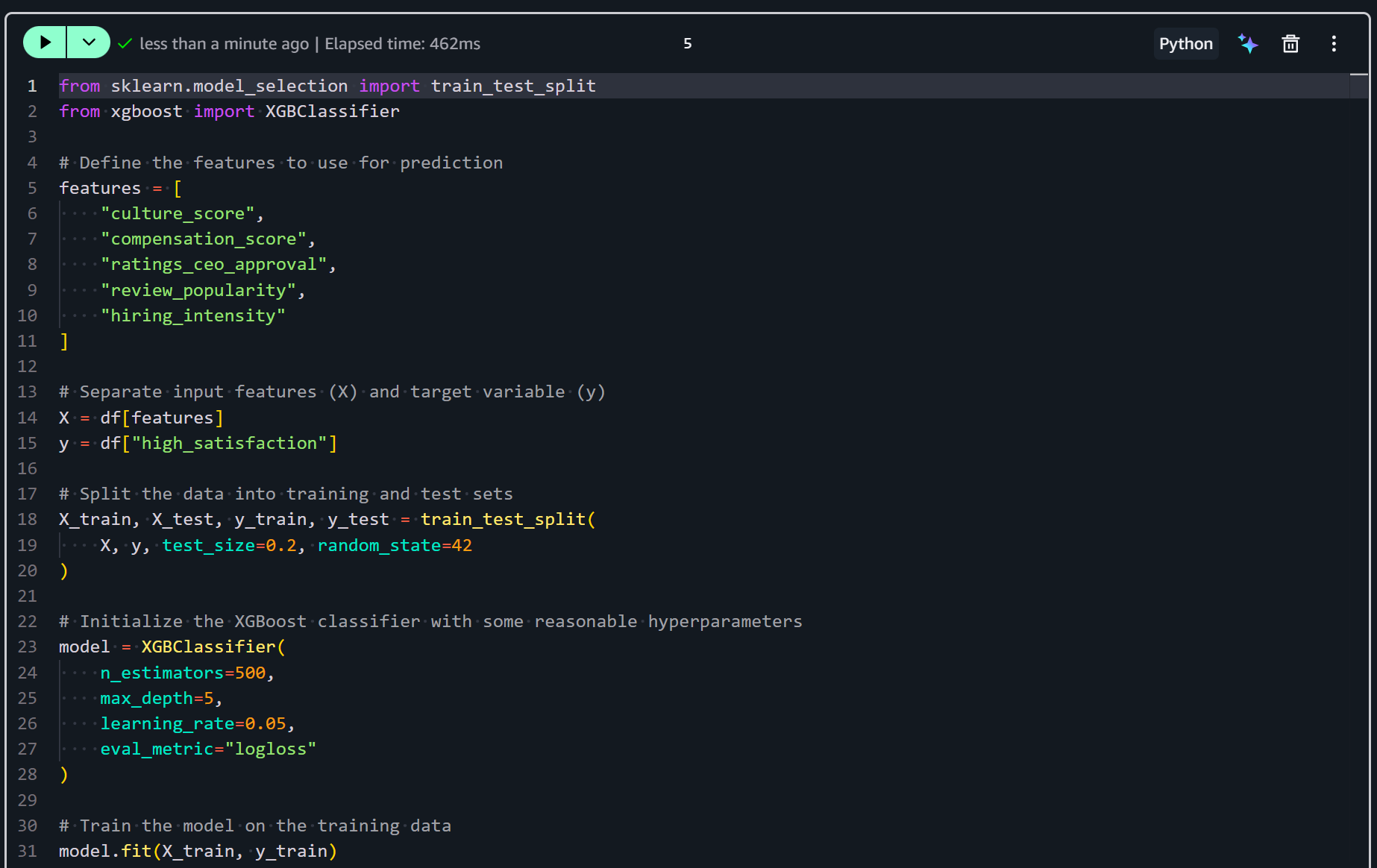
Après cette étape, votre classificateur XGBoost est entraîné et prêt pour l’évaluation et la prédiction. L’étape suivante consiste à évaluer ses performances !
Étape 10 : Évaluer les performances du modèle
La dernière étape consiste à évaluer les performances de votre modèle sur des données non vues. Ajoutez une nouvelle cellule dans votre notebook avec ce code :
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# Use the trained model to predict labels on the test set
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# Confusion matrix
cm = confusion_matrix(y_test, pred)
print("\nConfusion Matrix:\n", cm)
# ROC-AUC score
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)Appuyez sur le bouton « Run All » pour exécuter toutes les étapes et calculer les métriques :

Après l’exécution de la dernière cellule, vous devriez voir une sortie similaire à celle-ci :
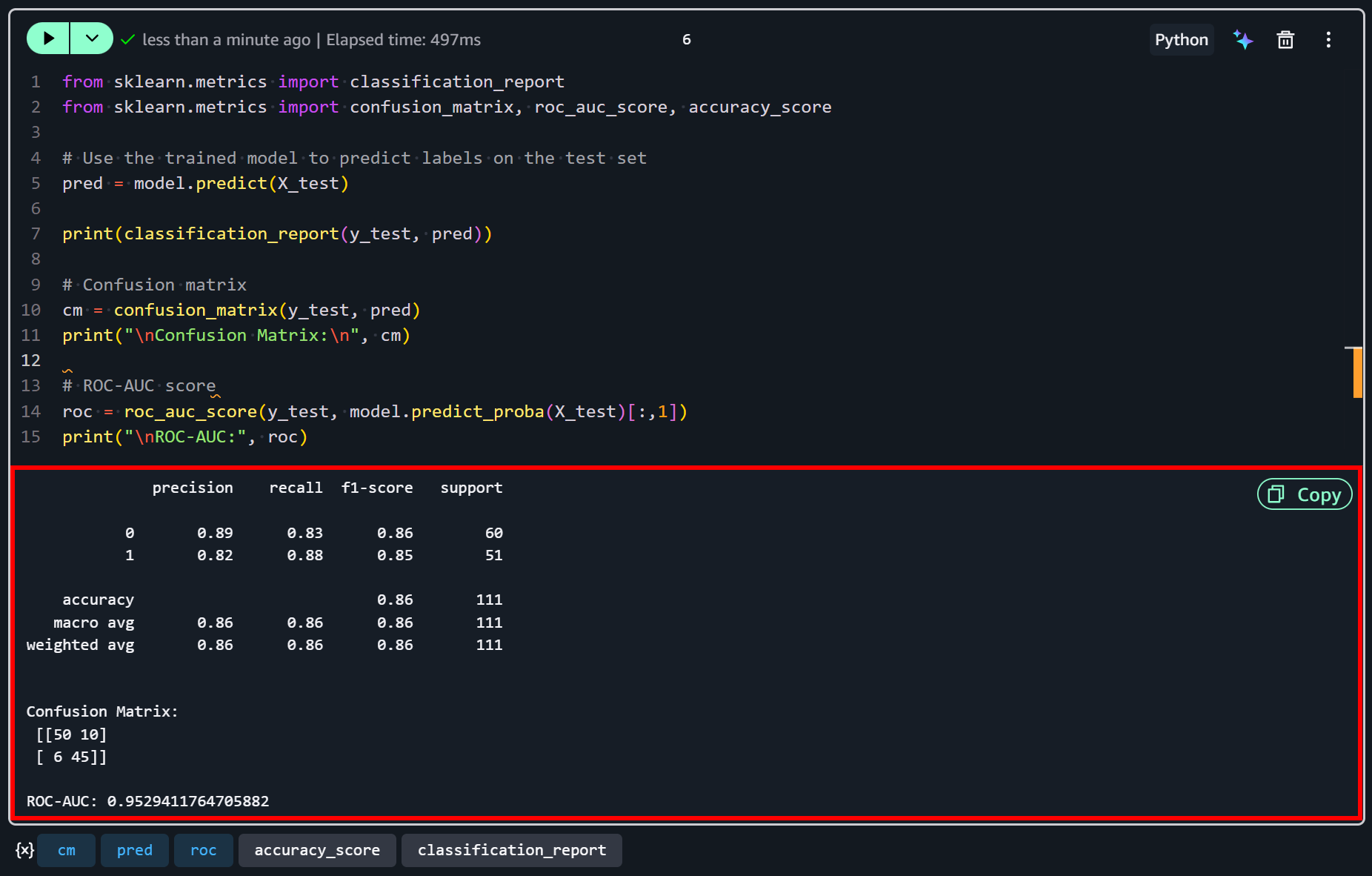
Ces résultats suggèrent que le modèle fonctionne raisonnablement bien pour ce jeu de données d’exemple. Avec une précision de 86 % et un ROC-AUC de 0,95, il démontre une forte capacité à distinguer les entreprises à satisfaction élevée de celles à satisfaction faible.
Les deux classes montrent une précision et un rappel équilibrés, ce qui signifie que le modèle est tout aussi efficace pour identifier correctement les entreprises à satisfaction élevée (1) et celles à satisfaction plus faible (0).
Cependant, certaines erreurs de classification subsistent… Comme le montre la matrice de confusion, 10 entreprises à faible satisfaction ont été incorrectement prédites comme ayant une satisfaction élevée, et 6 entreprises à satisfaction élevée ont été incorrectement prédites comme ayant une satisfaction faible.
Cela indique que si le modèle capture les principaux patterns des données, il n’est pas parfait et pourrait être amélioré avec des features supplémentaires (ou davantage de données).
Et voilà ! Grâce au jeu de données web d’entrée de Bright Data, vous avez pu effectuer le feature engineering et entraîner un modèle prédictif dans Amazon SageMaker. Ce n’est qu’un des nombreux cas d’usage que vous pourriez explorer, grâce à la grande variété de jeux de données web structurés proposés par Bright Data.
Prochaines étapes
Le modèle actuel, qui prédit la satisfaction élevée des employés en utilisant des champs dérivés via le feature engineering, obtient des résultats corrects. Il reste néanmoins des possibilités d’amélioration. Plusieurs façons d’améliorer ses performances existent, notamment :
- Créer davantage de features dérivées : Combinez les notes existantes de nouvelles façons. Par exemple, vous pourriez calculer un
leadership_scoreà partir deratings_senior_managementetratings_ceo_approval, ou unwork_life_compensation_ratiopour capturer les compromis entre rémunération et équilibre vie professionnelle-vie personnelle. Explorez les ratios, les différences ou les interactions entre features, qui peuvent révéler des patterns cachés. - Transformer les distributions asymétriques : Des features comme
reviews_countoujobs_countsont souvent asymétriques. Nous avons déjà appliqué une transformation racine carrée, mais envisagez des transformations logarithmiques ou de Box-Cox pour stabiliser davantage la variance. - Incorporer des features catégorielles : Actuellement,
regionetdetails_sizene sont pas numériques. Les encoder avec un encodage one-hot ou par cible pourrait fournir un signal prédictif supplémentaire. - Agréger plusieurs Points de données : Si vous pouvez obtenir des tendances historiques d’avis ou de recrutement, créer des features comme la croissance moyenne de
jobs_countau fil du temps ou l’évolution duculture_scorepourrait capturer le comportement dynamique des entreprises. - Sélection de features et analyse d’importance : Après l’entraînement, inspectez l’importance des features XGBoost pour identifier celles qui contribuent le plus aux prédictions. Vous pourrez créer de nouvelles features inspirées des plus prédictives.
- Enrichissement par des données externes : Envisagez de fusionner d’autres jeux de données Bright Data pour créer des features plus riches et contextuelles.
Conclusion
Dans ce tutoriel, vous avez découvert ce qu’Amazon SageMaker apporte aux scénarios de machine learning. Plus précisément, vous avez appris pourquoi les jeux de données scrapés sont d’excellentes sources pour le feature engineering et comment ils peuvent être utilisés pour entraîner des modèles ML prédictifs.
Comme démontré, Bright Data propose un riche marché de jeux de données couvrant des centaines de domaines et des milliards d’enregistrements de données web. Ces jeux de données sont continuellement mis à jour via le Scraping web, ce qui les rend idéaux pour soutenir les workflows de machine learning et d’IA. Ils s’intègrent parfaitement avec Amazon SageMaker, comme illustré dans ce guide.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à explorer nos solutions de données web !






