

Dans cet article, vous apprendrez :
- Ce qu’est Ruflo, ses principales fonctionnalités et capacités, ainsi que ses principales limites.
- Comment contourner ces limites grâce à une solution d’infrastructure de données web compatible avec l’IA, telle que Bright Data.
- Les deux principales façons d’intégrer Bright Data et Ruflo dans une configuration Claude Code ou OpenAI Codex.
- Comment démarrer avec Ruflo en le configurant dans un projet local alimenté par Claude Code.
- Comment ajouter à cette configuration les fonctionnalités de recherche Web, de récupération de données et d’interaction avec les sites Web de niveau entreprise de Bright Data via MCP.
- Comment réaliser la même intégration à l’aide des compétences Bright Data Claude.
- Ce que cette configuration Ruflo + Bright Data permet d’obtenir dans un assistant de codage agentique.
C’est parti !
Présentation de Ruflo : la plateforme d’orchestration d’agents pour Claude
Vous verrez bientôt comment et pourquoi associer Ruflo aux capacités de recherche et de récupération de données Web de Bright Data. Mais avant cela, prenons un moment pour comprendre ce qu’est Ruflo et ce qu’il apporte !
Qu’est-ce que Ruflo ?
Ruflo (anciennement Claude Flow) est un framework d’orchestration IA conçu pour transformer Claude Code (et OpenAI Codex) en un framework d’orchestration multi-agents riche en fonctionnalités.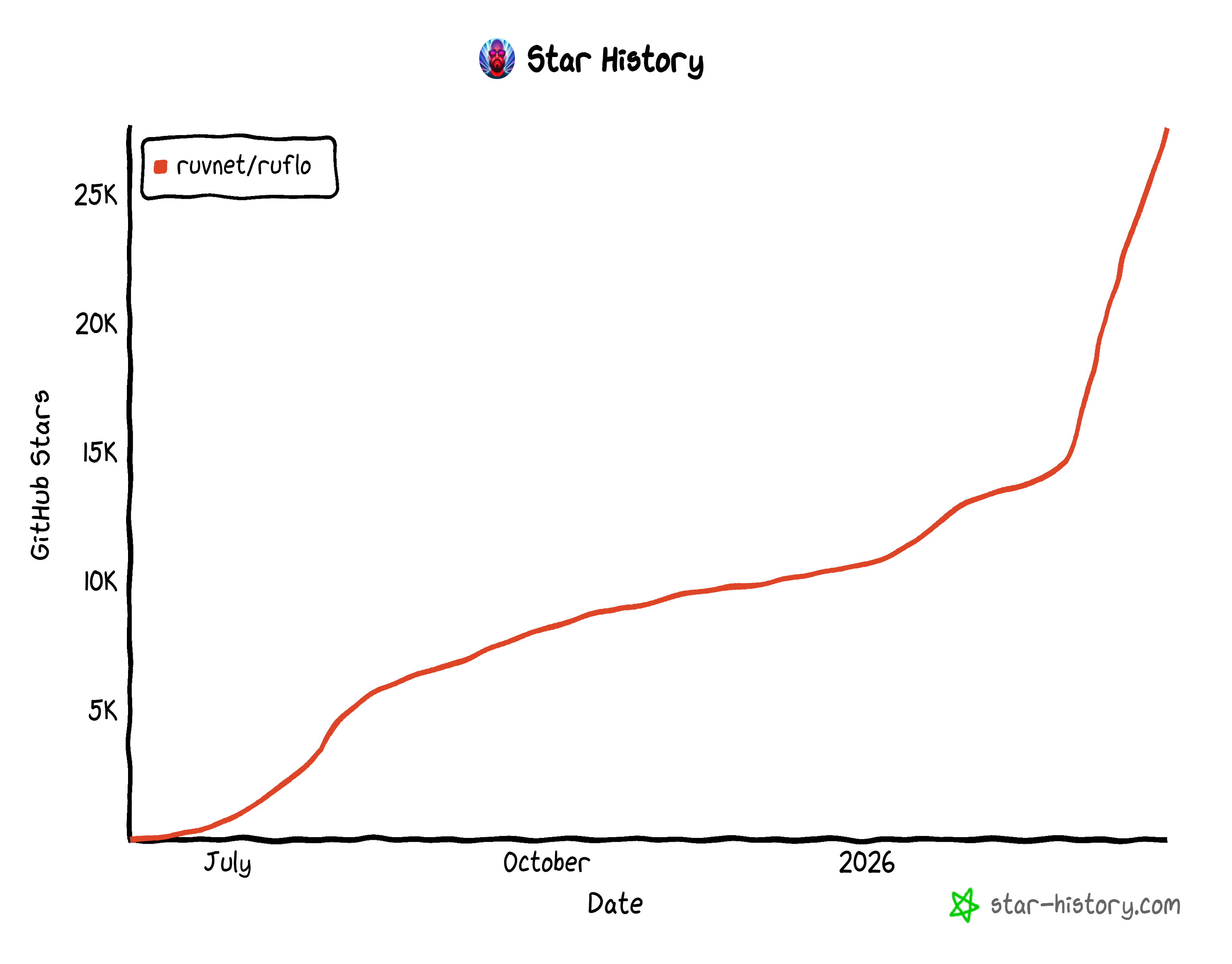
Plus précisément, il dote les assistants de codage agentiques d’un ensemble coordonné d’environ 100 agents IA spécialisés travaillant en parallèle. Cela permet à Claude Code et OpenAI Codex de gérer des tâches logicielles complexes grâce au routage intelligent, à la mémoire partagée et à des workflows d’auto-apprentissage.
En tant que projet open source, Ruflo compte plus de 27 000 étoiles sur GitHub et plus de 6 000 commits. Cette croissance rapide montre à quel point Ruflo a rapidement gagné en popularité au sein de la communauté des développeurs.
Comment Ruflo fait passer les assistants de codage agentique IA au niveau supérieur
À un niveau général, les principales fonctionnalités offertes par Ruflo sont les suivantes :
- Orchestration multi-agents à grande échelle: déployez et coordonnez environ 100 agents IA spécialisés travaillant en parallèle sur des tâches de développement complexes.
- Collaboration en essaim: les agents opèrent au sein d’« essaims » structurés, avec une coordination hiérarchique, des mécanismes de consensus et des objectifs communs.
- Auto-apprentissage et routage adaptatif: apprend des exécutions passées et achemine dynamiquement les tâches vers les agents les plus efficaces à l’aide de la reconnaissance de formes.
- Mémoire persistante et graphes de connaissances : combine la recherche vectorielle (HNSW), la mémoire partagée et les graphes de connaissances pour conserver le contexte d’une session à l’autre.
- Optimisation intelligente des coûts et des performances: utilise un routage à plusieurs niveaux (WASM + LLM) pour réduire la latence et diminuer les coûts des API jusqu’à environ 75 %.
- Prise en charge multi-LLM avec basculement: fonctionne avec Claude, GPT, Gemini et les modèles locaux, en sélectionnant automatiquement le meilleur fournisseur pour chaque tâche.
- Sécurité et extensibilité prêtes pour la production: protections intégrées (injection de prompts, validation) ainsi qu’un système de plugins pour étendre les agents, les hooks et les workflows.
Cela se traduit par une différence majeure lorsque l’on compare Claude Code avec et sans Ruflo :
| Claude Code seul | Claude Code + Ruflo | |
|---|---|---|
| Collaboration entre agents | Les agents travaillent de manière indépendante | Les agents collaborent grâce à une mémoire partagée |
| Coordination | Gestion manuelle des tâches | Hiérarchie dirigée par une reine avec coordination automatisée |
| Esprit collectif | Non disponible | Intelligence collective entre agents |
| Consensus | Pas de décisions multi-agents | Vote tolérant aux pannes avec règles de majorité |
| Mémoire | Session uniquement | Mémoire vectorielle persistante + graphe de connaissances |
| Base de données vectorielle | Aucune | RuVector PostgreSQL, recherche rapide et QPS élevé |
| Graphique de connaissances | Listes plates | Mise en évidence des informations clés à l’aide du PageRank et de la détection de communautés |
| Mémoire collective | Pas de connaissances partagées | Base de connaissances partagée entre les agents |
| Apprentissage | Statique, sans adaptation | Auto-apprentissage avec adaptation rapide et transfert de connaissances |
| Portée de l’agent | Un seul projet | Mémoire à plusieurs niveaux (projet/local/utilisateur) avec transfert inter-agents |
| Routage des tâches | Sélection manuelle des agents | Routage intelligent basé sur des modèles appris |
| Tâches complexes | Décomposition manuelle requise | Décomposition automatique sur plusieurs domaines |
| Travailleurs en arrière-plan | Aucun | Distribution automatique en fonction de déclencheurs tels que des modifications de fichiers ou des modèles |
| Fournisseur de LLM | Anthropic uniquement | Plusieurs fournisseurs avec basculement et optimisation des coûts |
| Sécurité | Protections standard | Renforcées : validation, chiffrement, atténuation des vulnérabilités CVE |
| Performances | Référence | Plus rapide grâce à des essaims parallèles et un routage intelligent |
Principales limites et comment y remédier
Quelle que soit la richesse et l’ingéniosité des quelque 100 agents et des capacités globales de Ruflo, il existe une limitation fondamentale. Celle-ci réside dans la nature même des LLM. Ces modèles sont entraînés sur des Jeux de données statiques qui s’arrêtent à un moment précis, ce qui limite intrinsèquement leurs connaissances.
Certes, Ruflo intègre un agent dédié à l’automatisation du navigateur pour la recherche Web, l’interaction et l’extraction de données. Le problème est que la plupart des sites Web disposent aujourd’hui de systèmes anti-bots qui bloquent les requêtes automatisées. Cela inclut les requêtes provenant d’agents de navigateur pilotés par l’IA. Ainsi, la récupération des connaissances par Ruflo peut échouer ou n’accéder qu’à une partie du contenu dont il a besoin.
Il s’agit d’un problème critique, car ce sont des connaissances précises, récentes et contextuelles qui rendent les systèmes multi-agents véritablement efficaces. Pour surmonter ce problème, votre assistant de codage IA a besoin d’outils spécialement conçus pour la recherche Web en temps réel, l’extraction de données et l’interaction Web sans restriction.
C’est exactement ce que propose Bright Data!
Les outils de données Web de Bright Data : la solution
En tant que plateforme de données Web leader sur le marché, Bright Data propose des outils adaptés aux agents IA, tels que :
- API SERP: recueille les résultats des moteurs de recherche Google, Bing et autres pour alimenter des réponses éclairées.
- API Web Unlocker: accédez au code HTML brut ou Markdown de n’importe quel site, en contournant les CAPTCHA, les interdictions d’IP et les mesures anti-bot.
- API Browser: contrôlez par programmation un navigateur distant pour une interaction automatisée et sans restriction avec n’importe quel site.
- API de Scraping web: collectez des données structurées à partir de plateformes telles qu’Amazon, Instagram, LinkedIn, Yahoo Finance et bien d’autres.
- API Crawl: Convertissez des sites web entiers en Jeux de données structurés pour les workflows d’IA en aval.
Ce qui distingue Bright Data, c’est son infrastructure de niveau entreprise. Reposant sur un réseau mondial de Proxies de plus de 400 millions d’adresses IP réparties dans 195 pays, elle offre une évolutivité illimitée tout en garantissant une disponibilité de 99,99 % et un taux de réussite de 99,95 %.
Bright Data s’associe à Ruflo pour doter votre système de codage agentique de la capacité d’explorer, de récupérer et d’analyser des données Web en temps réel. Tout cela, à grande échelle et sans rencontrer de blocages !
Comment combiner Bright Data et Ruflo : deux approches
Techniquement, vous pouvez intégrer Bright Data directement dans Ruflo à l’aide du SDK du plugin. Vous devrez définir des outils personnalisés qui se connectent à chaque produit Bright Data que vous souhaitez utiliser. Cependant, ce n’est pas l’approche la plus rapide !
Au lieu de réinventer la roue, il est bien plus simple de s’appuyer sur :
- Bright Data Web MCP: un serveur open source tout-en-un proposant plus de 60 outils pour la recherche Web, la navigation, l’extraction de données et l’interaction sans blocage.
- Les compétences Bright Data: des fonctionnalités prêtes à l’emploi qui enseignent à votre agent de codage comment effectuer du scraping web, des recherches et la récupération de données structurées grâce à l’IA. Elles incluent une connexion au Web MCP.
Celles-ci peuvent être ajoutées directement à Claude Code (ou OpenAI Codex), ce qui permet d’obtenir une configuration de codage unifiée combinant à la fois Ruflo et Bright Data. Le LLM sous-jacent peut alors utiliser les outils des deux solutions de manière coordonnée et synergique.
Remarque: les exemples ci-dessous utilisent Claude Code, mais vous pouvez facilement les adapter à OpenAI Codex.
Voyons maintenant comment étendre Claude Code avec Bright Data et Ruflo en utilisant soit le MCP, soit des compétences. Mais avant tout, configurez Ruflo !
Premiers pas avec Ruflo
Suivez les instructions ci-dessous pour apprendre à configurer Ruflo dans votre projet de codage.
Prérequis
Pour suivre cette section, assurez-vous d’avoir :
- Claude Code installé et configuré localement.
- Node.js 20+ installé localement (la dernière version LTS est recommandée).
Étape n° 1 : Configurer Ruflo
Créez un nouveau dossier pour votre projet de codage (par exemple, bright-data-ruflo-project). C’est là que vous initialiserez Ruflo. Ensuite, accédez à ce dossier dans votre terminal :
mkdir bright-data-ruflo-project
cd bright-data-ruflo-projectRemarque: vous pouvez également partir d’un dossier de projet existant. Dans la plupart des cas, c’est ce que vous ferez. Vous ajouterez Ruflo à votre projet pour profiter de ses fonctionnalités.
Lancez la commande suivante dans votre terminal pour démarrer l’assistant d’installation de Ruflo via npm :
npx ruflo@latest init --wizardL’installation du paquet ruflo peut prendre quelques minutes, veuillez donc patienter.
Voici le résultat que vous devriez obtenir :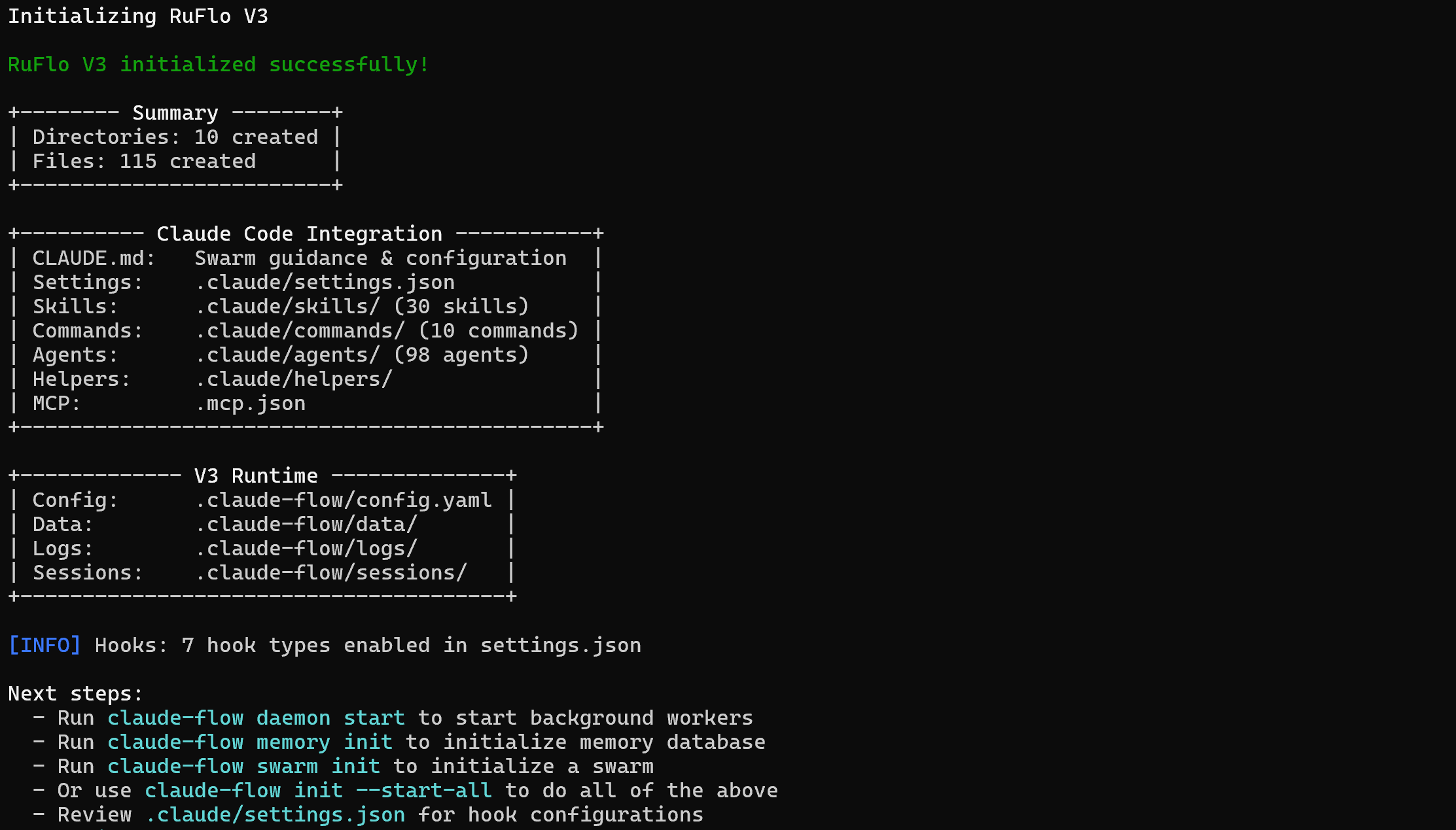
Remarque: le résultat affiché dans l’interface CLI peut suggérer d’utiliser les commandes claude-flow pour initialiser les services backend, les bases de données en mémoire ou les swarms. Cependant, cela n’est pas exact. Lors de l’installation de Ruflo via npm, la commande de base correcte est :
npx ruflo@latestLe dossier de votre projet contiendra désormais :
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.mdEn résumé, le répertoire bright-data-ruflo-project contient tous les fichiers dont Claude Code a besoin pour accéder, au niveau du projet, aux nouvelles compétences, commandes et agents. En d’autres termes, Ruflo s’est entièrement intégré à votre configuration locale de Claude Code. Bravo !
Étape n° 2 : Lancer Ruflo
Ruflo a ajouté plusieurs agents, commandes et compétences. Cependant, pour que Claude Code puisse les exécuter, vous devez d’abord démarrer Ruflo. Pour ce faire, utilisez :
npx ruflo@latest startVous devriez voir s’afficher un résultat similaire à celui-ci :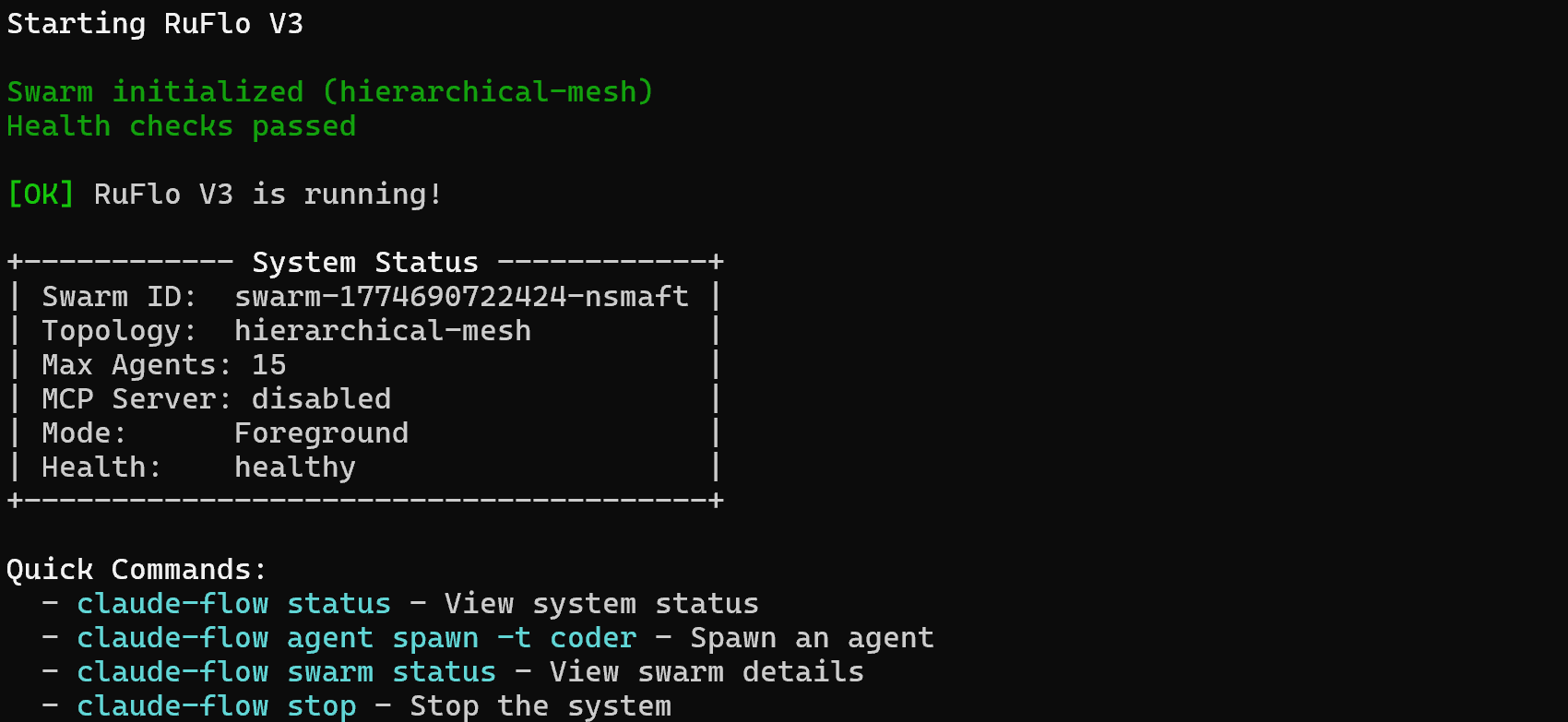
Super ! Votre configuration Claude Code peut désormais tirer parti des fonctionnalités étendues fournies par Ruflo.
Étape n° 3 : Vérifiez l’intégration
Dans le répertoire de votre projet, lancez Claude Code :
claudeVous pourriez recevoir un message comme celui-ci :
Sélectionnez l’option 1 ou l’option 2. Ainsi, Claude Code démarrera le serveur Ruflo MCP et s’y connectera au lancement.
Ensuite, vous verrez des journaux indiquant clairement que Ruflo est disponible dans Claude Code :
Tapez « /agent » et vous devriez voir s’afficher certaines des commandes Ruflo supplémentaires :
Génial ! Claude Code s’est connecté avec succès à Ruflo, confirmant que l’intégration fonctionne.
Approche d’intégration n° 1 : Ruflo MCP + Bright Data MCP
Dans cette section, vous apprendrez comment ajouter les fonctionnalités Ruflo et Bright Data à votre configuration Claude Code via MCP.
Prérequis
Pour que cette section reste concise, nous partons du principe que vous avez déjà intégré Bright Data Web MCP à votre configuration Claude Code.
Si ce n’est pas encore le cas, suivez le tutoriel détaillé «Intégration de Claude Code avec le Web MCP de Bright Data »ou le guide de documentation «Intégration du serveur MCP de Claude Code ». Veillez simplement à ajouter la configuration requise au fichier .mcp.json local créé par Ruflo lors de la commande init.
Une bonne connaissance du fonctionnement de MCP et de la manière de connecter des serveurs MCP à Claude Code est également un prérequis essentiel.
Étape n° 1 : Vérifiez les serveurs MCP disponibles
Par défaut, le serveur MCP Ruflo est configuré dans le fichier .mcp.json local. Ce fichier doit également contenir la configuration permettant de se connecter au Web MCP de Bright Data.
Normalement, Claude Code détecte automatiquement les deux serveurs MCP et s’y connecte. Pour vérifier cela, lancez Claude Code dans le dossier de votre projet et exécutez la commande /mcp:
Vous devriez voir :
bright-data-web-mcp(ou le nom que vous avez donné au MCP Web de Bright Data dans la configuration.mcp.json).claude-flow(le nom du serveur MCP Ruflo).
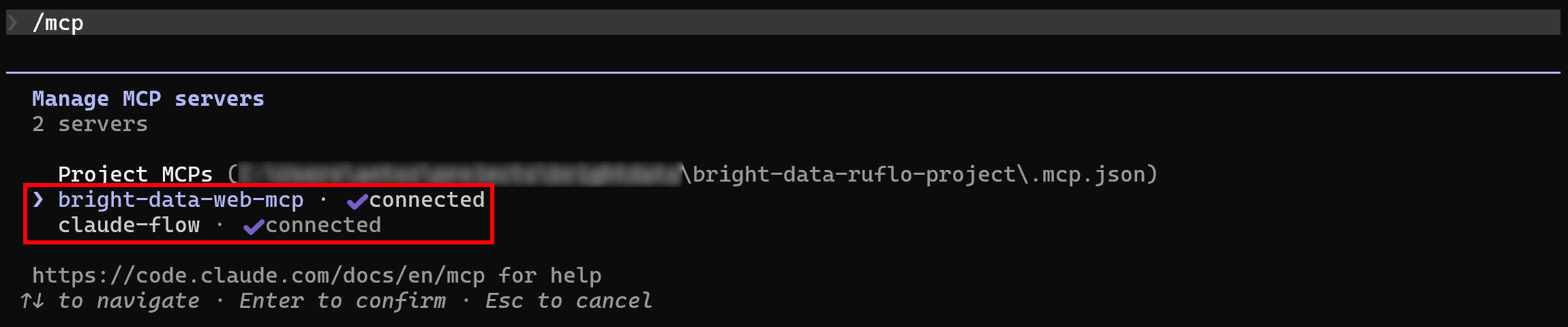
Parfait ! Claude Code est désormais connecté aux deux serveurs MCP comme prévu.
Étape n° 2 : inspecter le serveur MCP Web de Bright Data
Sélectionnez l’entrée bright-data-web-mcp (ou le nom que vous lui avez donné) :
Choisissez l’option « Afficher les outils » pour voir tous les outils disponibles. Si vous l’avez configuré en mode Pro, vous obtiendrez plus de 65 outils:
Sinon, vous ne verrez que 4 outils (scrape_as_markdown, search_engine et leurs 2 versions par lots).
Parfait ! Le serveur MCP Web de Bright Data expose ses outils comme prévu.
Étape n° 3 : inspecter le serveur MCP Ruflo
Répétez la même procédure que ci-dessus, mais pour le MCP claude-flow. Vous devriez voir :
Remarquez que le MCP Ruflo expose un nombre impressionnant de 254 outils. Waouh !
Approche d’intégration n° 2 : compétences Ruflo + compétences Bright Data
Ici, vous serez guidé tout au long du processus d’ajout des fonctionnalités Ruflo et Bright Data à votre configuration Claude Code via des compétences.
Prérequis
Pour suivre cette section, assurez-vous de disposer :
- Claude Code configuré sur un système d’exploitation basé sur Unix (macOS, Linux ou WSL).
- Git installé localement.
- Un compte Bright Data avec une zone Web Unlocker configurée et une clé API définie.
- Une compréhension de base des compétences Claude et de la manière de les configurer dans Claude Code.
- Une bonne connaissance des compétences disponibles dans le référentiel officiel des compétences Claude de Bright Data.
Remarque: ne vous inquiétez pas pour la création d’un compte Bright Data pour l’instant, car vous serez guidé tout au long de cette étape dans la suite.
Ensuite, installez curl et jq, les deux prérequis requis par les compétences Claude de Bright Data. Sur macOS, exécutez :
brew install curl jqDe même, sous Linux, exécutez :
sudo apt-get install curl jqPar défaut, une fois Ruflo configuré dans votre projet local, Claude Code répertorie déjà ses 118 compétences. Vérifiez-le en exécutant la commande /skills: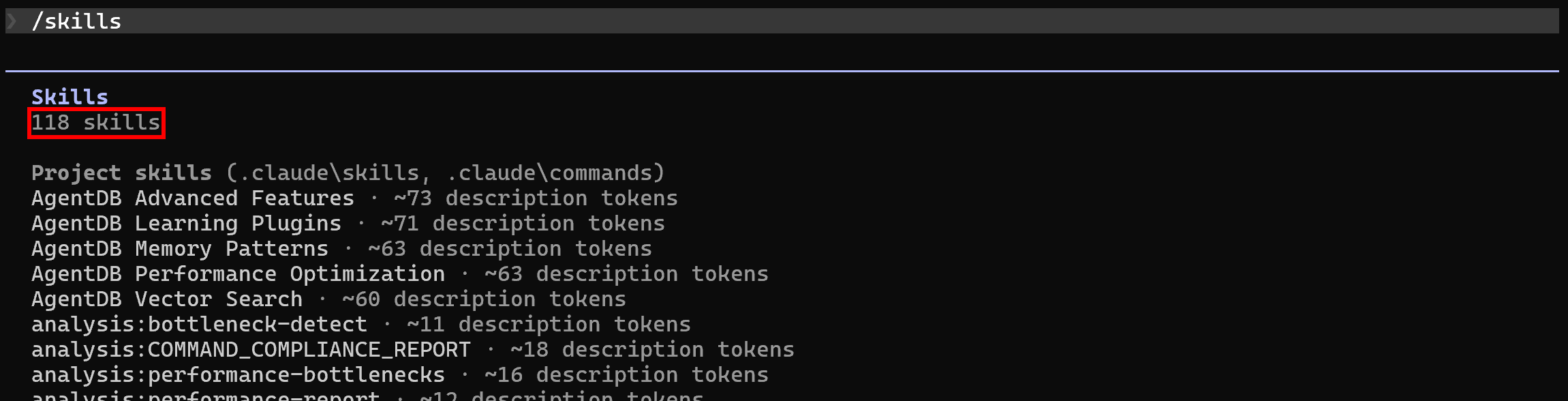
Étape n° 1 : Configurez votre compte Bright Data
Comme expliqué dans la documentation, les compétences Bright Data Claude nécessitent que les deux secrets suivants soient définis en tant que variables d’environnement globales :
BRIGHTDATA_API_KEY: votre clé API Bright Data.BRIGHTDATA_UNLOCKER_ZONE: le nom de la zone Web Unlocker configurée dans votre compte.
Pour plus d’informations, vous pouvez consulter la page de documentation« Guide de démarrage rapide de l’API Web Unlocker de Bright Data ».Vous pouvez également suivre les instructions ci-dessous.
Si vous n’avez pas de compte Bright Data, créez-en un. Sinon, connectez-vous simplement. Accédez au panneau de configuration et rendez-vous sur la page « Proxies & Scraping ». Consultez le tableau « My Zones » :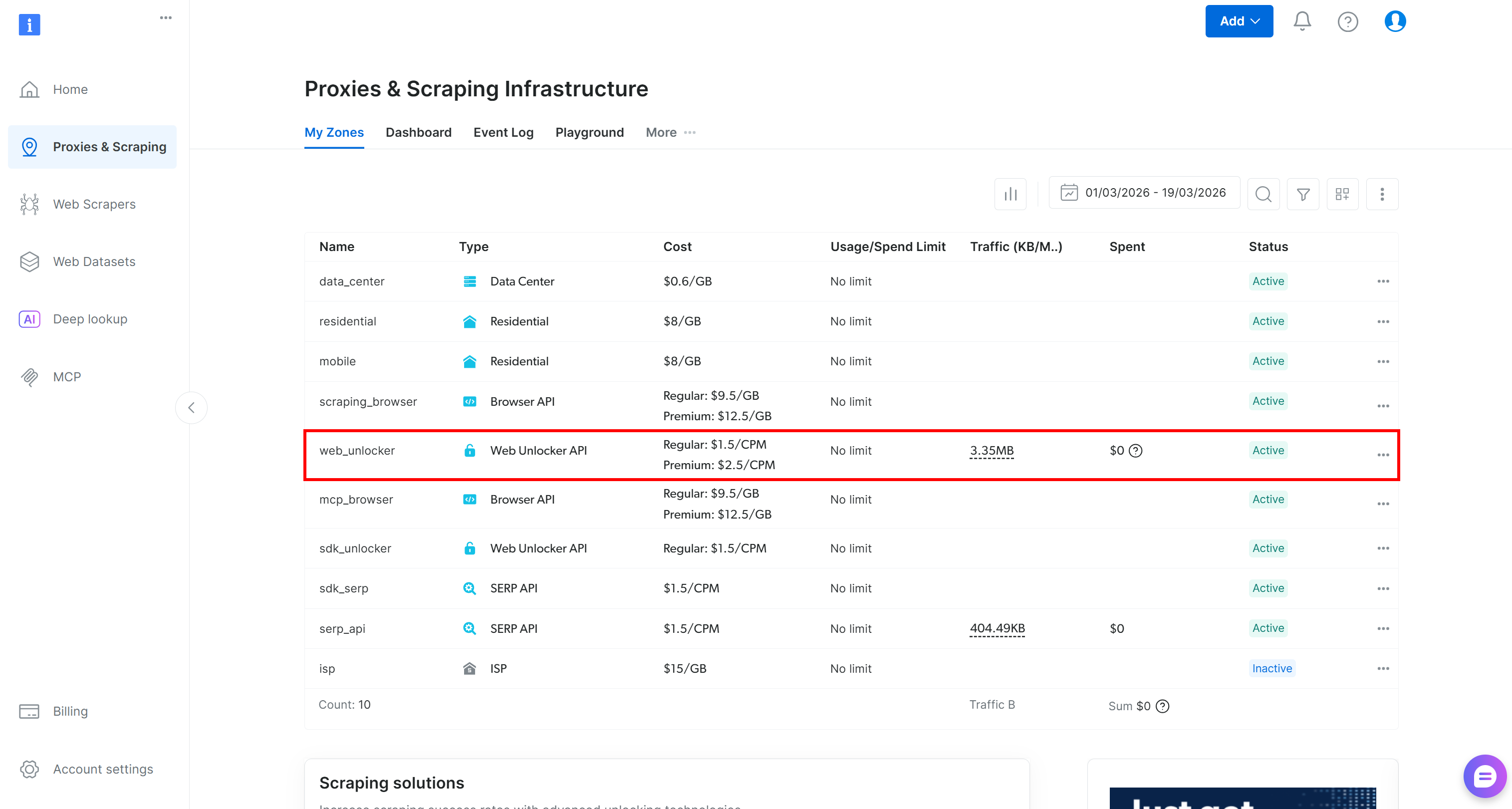
Si une zone Web Unlocker API (par exemple, web_unlocker) existe, vous pouvez passer à la définition de la clé API.
Si elle n’existe pas, créez-en une nouvelle. Pour ce faire, faites défiler jusqu’à la fiche « Unblocker API », cliquez sur « Créer une zone » et suivez l’assistant.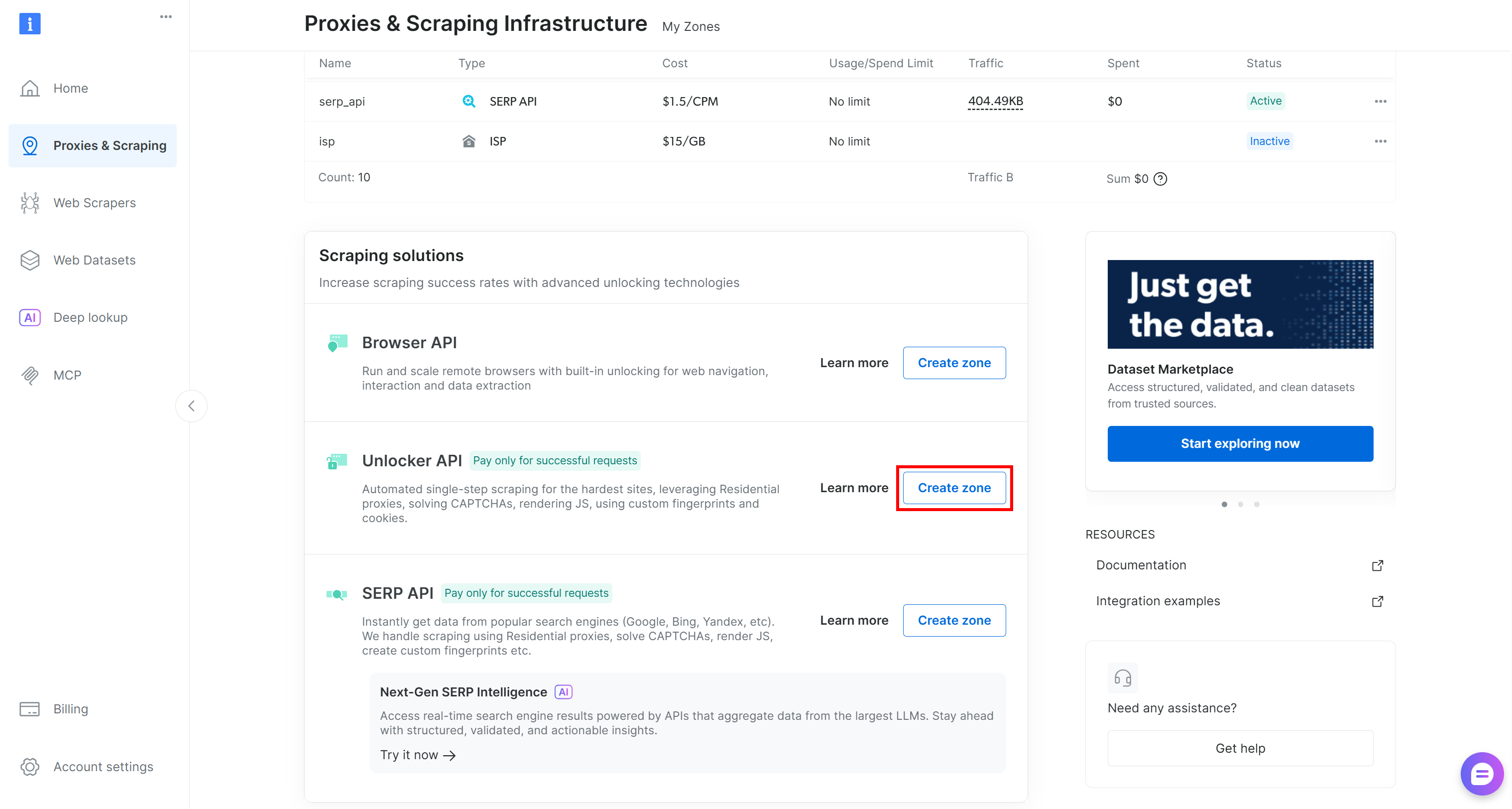
Suivez les instructions de l’assistant et donnez à votre zone un nom significatif (par exemple, web_unlocker).
Enfin, générez votre clé API Bright Data. À présent, à l’aide de votre jeton API et du nom de votre zone, définissez deux variables d’environnement globales comme suit :
export BRIGHTDATA_API_KEY="<VOTRE_CLÉ_API_BRIGHTDATA>"
export BRIGHTDATA_UNLOCKER_ZONE="<VOTRE_ZONE_UNLOCKER_BRIGHTDATA>"Parfait ! Les compétences Bright Data Claude peuvent désormais se connecter à votre compte et fonctionner correctement.
Étape n° 2 : récupérer les compétences Bright Data
Pour ajouter de nouvelles compétences à votre configuration, copiez leurs dossiers dans le répertoire local .claude/skills.
Commencez par cloner le référentiel des compétences Bright Data Claude dans un dossier de votre choix :
git clone https://github.com/brightdata/skillsLa structure clonée devrait ressembler à ceci :
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdLes compétences Claude de Bright Data sont les suivantes :
search: interroge Google et renvoie des résultats JSON structurés comprenant des titres, des liens et des descriptions.scrape: extrait n’importe quelle page web sous forme de Markdown propre tout en contournant automatiquement la détection des bots.data-feeds: extrait des données structurées de plus de 40 sites web grâce à un sondage et des mises à jour automatisés.bright-data-mcp: Orchestre plus de 60 outils Bright Data MCP pour la recherche, le scraping, l’extraction structurée et l’automatisation du navigateur.scraper-builder: Créez des scrapers prêts à l’emploi, incluant l’analyse de sites, la sélection d’API, les sélecteurs, la pagination et la mise en œuvre.bright-data-best-practices: référence pour Web Unlocker, SERP, Web Scraper et les API de navigateur.python-sdk-best-practices: Guide du package Pythonbrightdata-sdk: clients asynchrones/synchrones, Scrapers, Jeux de données, gestion des erreurs et modèles.brightdata-cli: Guide du terminal pour Bright Data CLI : scraper, rechercher, extraire des données, gérer les zones de Proxy et vérifier le compte.design-mirror: reproduisez les jetons et composants du système de conception pour une implémentation cohérente et de haute qualité de l’interface utilisateur.
Copiez les dossiers contenus dans skills/ (bright-data-best-practices/, bright-data-mcp/, etc.) dans le répertoire local .claude/skills de votre projet. Effectuez cette opération manuellement ou à l’aide de la commande suivante :
cp -r skills/skills/* <CHEMIN_VERS_VOTRE_PROJET>/.claude/skills/Parfait ! Les compétences Bright Data Claude ont été ajoutées à votre projet.
Étape n° 3 : Vérifier les compétences disponibles
Lancez à nouveau Claude Code dans le dossier de votre projet et exécutez la commande /skills: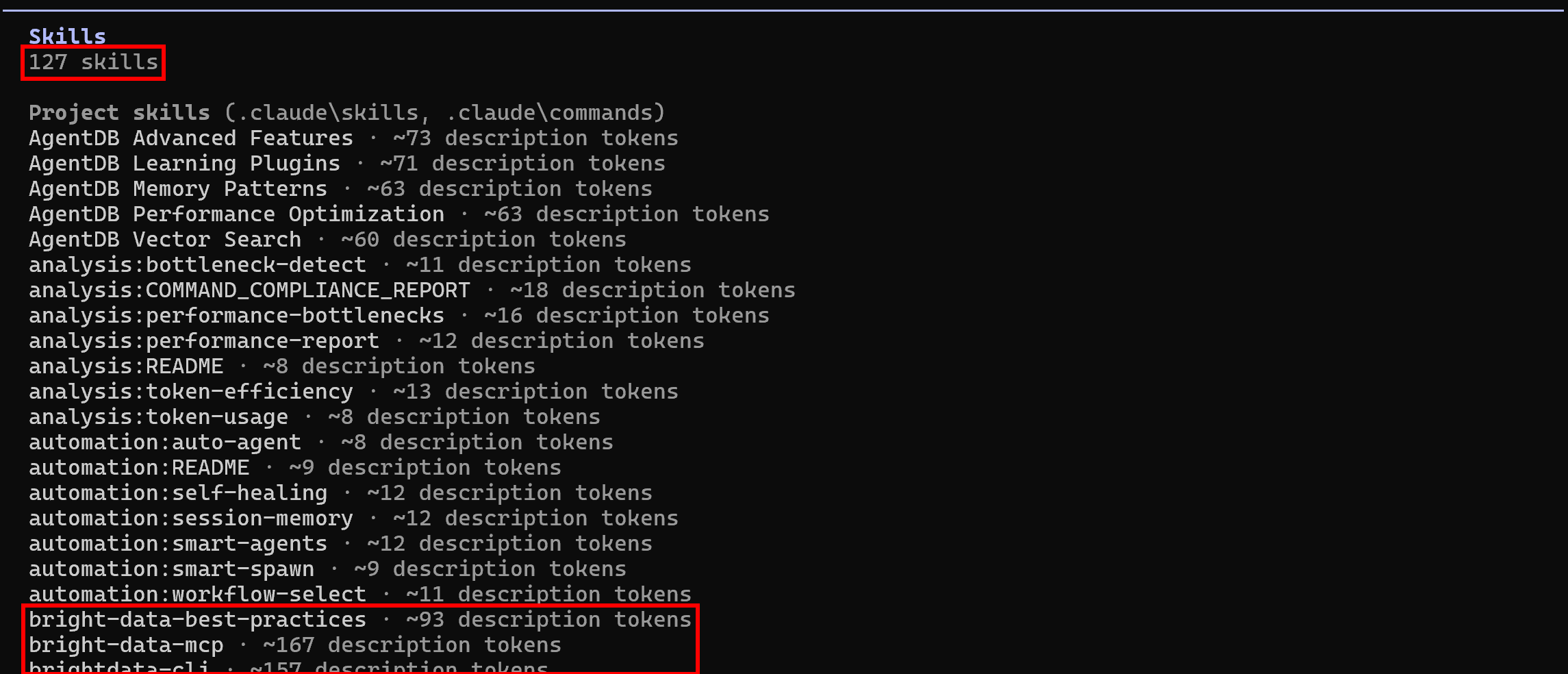
Cette fois-ci, le nombre de compétences disponibles devrait être de 127 (contre 118 initialement), ce qui indique que les compétences Bright Data sont lues avec succès. Mission accomplie ! Votre système de codage agentique peut désormais exploiter les compétences Bright Data pour l’extraction programmatique de données Web, l’exploration du Web et bien plus encore.
Ruflo + Bright Data : tout mettre en place
Votre configuration Claude Code a désormais accès à plus de 300 outils MCP ou plus de 125 compétences. Celles-ci permettent de coordonner les efforts de codage tout en laissant les agents rechercher de manière autonome sur le Web, extraire des données et interagir avec des pages Web, le tout sans blocages ni limitations d’évolutivité.
Cela ouvre de nombreuses nouvelles possibilités, notamment :
- Récupérer les résultats en temps réel des moteurs de recherche (SERP) et intégrer des liens contextuels dans
README.mdet d’autres pages de documentation. - La découverte de tutoriels ou de documentation pertinents en fonction de vos tâches de codage actuelles afin d’améliorer efficacement votre base de code.
- L’extraction de données publiques récentes à partir de sites web et leur enregistrement local pour la simulation, l’analyse ou un traitement ultérieur.
Ces exemples illustrent l’avantage synergique de l’utilisation de Bright Data avec Ruflo dans votre configuration Claude Code / OpenAI Codex. Cette intégration étend encore davantage l’ensemble de fonctionnalités déjà impressionnant de Ruflo, tout en prenant en charge des cas d’utilisation de niveau entreprise grâce à l’infrastructure de Bright Data.
Conclusion
Dans cet article de blog, vous avez compris ce qu’est Ruflo (anciennement connu sous le nom de Claude Flow) et comment il transforme l’expérience des agents dans Claude Code et OpenAI Codex. Grâce à une infrastructure de niveau entreprise comprenant environ 100 agents travaillant en parallèle, Ruflo améliore considérablement les performances, notamment la vitesse, l’efficacité des tokens et la qualité des résultats.
Cependant, ces outils ne disposent pas d’une solution prête à l’emploi pour l’extraction de données Web, la recherche sur le Web et l’interaction programmatique avec les sites Web. C’est là qu’intervient Bright Data, grâce à un serveur Web MCP dédié et à un ensemble officiel de compétences Claude. Ceux-ci facilitent la connexion à la suite complète d’outils, de services et d’infrastructures de Bright Data conçus pour l’IA.
Vous avez ainsi appris à configurer une puissante installation Ruflo + Bright Data dans Claude Code afin de maximiser l’efficacité et l’efficience de l’aide au codage.
Créez gratuitement un compte Bright Data dès aujourd’hui et commencez à explorer des solutions de données Web prêtes pour l’IA !





