
Dans ce guide, vous apprendrez :
- Ce qu’est Pydantic AI et ce qui le rend unique en tant que cadre pour la construction d’agents d’intelligence artificielle.
- Pourquoi Pydantic AI s’associe bien au serveur Web MCP de Bright Data pour créer des agents capables d’accéder au Web.
- Comment intégrer Pydantic avec le Web MCP de Bright Data pour créer un agent d’intelligence artificielle basé sur des données réelles.
Plongeons dans l’aventure !
Qu’est-ce que l’IA pydantique ?
Pydantic AI est un cadre agent Python développé par les créateurs de Pydantic, la bibliothèque de validation de données la plus utilisée pour Python.
Par rapport à d’autres cadres d’agents d’IA, Pydantic AI met l’accent sur la sécurité des types, les résultats structurés et l’intégration avec des données et des outils du monde réel. Voici quelques-unes de ses principales caractéristiques :
- Prise en charge d’OpenAI, Anthropic, Gemini, Cohere, Mistral, Groq, HuggingFace, Deepseek, Ollama et d’autres fournisseurs de LLM.
- Validation des résultats structurés par le biais de modèles pydantiques.
- Débogage et surveillance via Pydantic Logfire.
- Injection de dépendance optionnelle pour les outils, les invites et les validateurs.
- Réponses LLM en continu avec validation des données à la volée.
- Support multi-agent et graphique pour les flux de travail complexes.
- Intégration d’outils via MCP, y compris les appels HTTP.
- Flux Pythonic familier pour construire des agents d’intelligence artificielle comme des applications Python standard.
- Support intégré pour les tests unitaires et le développement itératif.
La bibliothèque est open source et a déjà atteint plus de 11 000 étoiles sur GitHub.
Pourquoi combiner l’IA de Pydantic avec un serveur MCP pour la recherche de données sur le Web ?
Les agents d’IA construits avec Pydantic AI héritent des limitations du LLM sous-jacent. Il s’agit notamment d’un manque d’accès aux informations en temps réel, ce qui peut entraîner des réponses inexactes. Heureusement, ce problème peut être facilement résolu en équipant l’agent de données actualisées et en lui donnant la possibilité d’explorer le web en direct.
C’est là que le MCP Web de Bright Data entre en jeu. Construit sur Node.js, ce serveur MCP s’intègre à la suite d’outils d’extraction de données prêts pour l’IA de Bright Data. Ces outils permettent à votre agent d’accéder au contenu Web, d’interroger des ensembles de données structurées, d’effectuer des recherches sur le Web et d’interagir avec des pages Web à la volée.
A ce jour, les outils MCP du serveur sont les suivants :
| Outil | Description |
|---|---|
scrape_as_markdown |
Récupère le contenu d’une seule URL de page web avec des options d’extraction avancées, renvoyant les résultats sous forme de Markdown. Peut contourner la détection des robots et les CAPTCHA. |
moteur_de_recherche |
Extrait les résultats de recherche de Google, Bing ou Yandex, en renvoyant les données SERP au format markdown (URL, titre, snippet). |
scrape_as_html |
Récupère le contenu d’une page web à partir d’une URL avec des options d’extraction avancées, renvoyant le code HTML complet. Peut contourner la détection des robots et les CAPTCHA. |
session_stats |
Fournir des statistiques sur l’utilisation de l’outil pendant la session en cours. |
scraping_browser_go_back |
Retournez à la page précédente dans la session du navigateur de scraping. |
scraping_browser_go_forward |
Naviguer vers la page suivante dans la session du navigateur de scraping. |
scraping_browser_click |
Effectuer un clic sur un élément spécifique à l’aide d’un sélecteur. |
scraping_browser_links |
Récupère tous les liens, y compris le texte et les sélecteurs, sur la page en cours. |
type_de_navigateur_de_grattage |
Saisir du texte dans un élément spécifié dans le navigateur de scraping. |
scraping_browser_wait_for |
Attendez qu’un élément particulier devienne visible sur la page avant de poursuivre. |
scraping_browser_screenshot |
Effectuer une capture d’écran de la page actuelle du navigateur. |
scraping_browser_get_html |
Récupère le contenu HTML de la page en cours dans le navigateur. |
scraping_browser_get_text |
Extrait le contenu textuel visible de la page en cours. |
Il existe ensuite plus de 40 outils spécialisés permettant de collecter des données structurées à partir d’un large éventail de sites web (par exemple, Amazon, Yahoo Finance, TikTok, LinkedIn, et bien d’autres) à l’aide des API Web Scraper. Par exemple, l’outil web_data_amazon_product recueille des informations détaillées et structurées sur les produits d’Amazon en acceptant en entrée une URL de produit valide.
Maintenant, regardez comment vous pouvez utiliser ces outils MCP dans Pydantic AI !
Comment intégrer Pydantic AI avec le serveur Bright MCP en Python
Dans cette section, vous apprendrez à utiliser Pydantic AI pour construire un agent d’intelligence artificielle. L’agent sera équipé de capacités de récupération de données en direct, d’extraction et d’interaction à partir du serveur Web MCP.
À titre d’exemple, nous allons montrer comment l’agent peut récupérer à la volée des données sur les produits en provenance d’Amazon. N’oubliez pas qu’il ne s’agit là que d’un des nombreux cas d’utilisation possibles. L’agent d’intelligence artificielle peut utiliser n’importe lequel des plus de 50 outils disponibles via le serveur MCP pour effectuer un large éventail de tâches.
Suivez cette procédure guidée pour construire votre agent d’IA alimenté par Gemini + Bright Data MCP en utilisant Pydantic AI !
Conditions préalables
Pour reproduire l’exemple de code, assurez-vous que les éléments suivants sont installés localement :
- Python 3.10 ou supérieur.
- Node.js (nous recommandons la dernière version LTS).
Vous aurez également besoin de :
- Un compte Bright Data.
- Une clé API Gemini (ou une clé API pour un autre fournisseur LLM pris en charge, tel que OpenAI, Anthropic, Deepseek, Ollama, Groq, Cohere et Mistral).
Ne vous préoccupez pas encore de la configuration des clés API. Les étapes ci-dessous vous guideront dans la configuration des identifiants Bright Data et Gemini le moment venu.
Bien qu’elles ne soient pas strictement nécessaires, ces connaissances de base vous aideront à suivre le tutoriel :
- Une compréhension générale du fonctionnement du programme MCP.
- Connaissance de base du fonctionnement des agents d’intelligence artificielle.
- Une certaine connaissance du serveur Web MCP et des outils disponibles.
- Connaissance de base de la programmation asynchrone en Python.
Étape 1 : Créer votre projet Python
Ouvrez votre terminal et créez un nouveau dossier pour votre projet :
mkdir pydantic-ai-mcp-agentLe dossier pydantic-ai-mcp-agent contiendra tout le code de votre agent IA Python.
Naviguez dans le dossier nouvellement créé et mettez en place un environnement virtuel à l’intérieur de celui-ci :
cd pydantic-ai-mcp-agent
python -m venv venvOuvrez ensuite le dossier du projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un fichier nommé agent.py à la racine de votre projet. À ce stade, la structure de votre dossier devrait ressembler à ceci :
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyLe fichier agent.py est actuellement vide, mais il contiendra bientôt la logique d’intégration de Pydantic AI avec le serveur MCP de Bright Data Web.
Activez l’environnement virtuel en utilisant le terminal de votre IDE. Sous Linux ou macOS, exécutez cette commande :
source venv/bin/activateDe manière équivalente, sous Windows, lancez :
venv/Scripts/activateVous êtes prêt ! Vous disposez maintenant d’un environnement Python prêt à construire un agent d’intelligence artificielle avec un accès aux données web.
Étape 2 : Installer Pydantic AI
Dans votre environnement virtuel activé, installez tous les paquets Pydantic AI requis avec :
pip install "pydantic-ai-slim[google,mcp]" Ceci installe pydantic-ai-slim, une version légère du paquetage complet pydantic-ai qui évite de tirer des dépendances inutiles.
Dans ce cas, comme vous prévoyez d’intégrer votre agent au serveur MCP de Bright Data Web, vous aurez besoin de l’extension mcp. Et comme nous allons intégrer Gemini en tant que fournisseur LLM, vous aurez également besoin de l’extension google.
Note: Pour d’autres modèles ou fournisseurs, se référer à la documentation du modèle pour voir quelles dépendances optionnelles sont nécessaires.
Ensuite, ajoutez ces importations dans votre fichier agent.py :
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderCool ! Vous pouvez désormais utiliser Pydantic AI pour la création d’agents.
Étape 3 : Configurer les variables d’environnement Lecture
Votre agent d’IA interagira avec des services tiers tels que Bright Data et Gemini via une API. Ne codifiez pas en dur vos clés d’API dans votre code Python. Chargez-les plutôt à partir de variables d’environnement pour plus de sécurité et de facilité de maintenance.
Pour simplifier le processus, utilisez la bibliothèque python-dotenv. Avec votre environnement virtuel activé, installez-la en exécutant :
pip install python-dotenvEnsuite, dans votre fichier agent.py, importez la bibliothèque et chargez les variables d’environnement avec load_dotenv() :
from dotenv import load_dotenv
load_dotenv()Cela permet au script de lire les variables d’environnement à partir d’un fichier .env local. Créez donc un fichier .env dans le dossier de votre projet :
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------Vous pouvez maintenant accéder aux variables d’environnement comme suit :
env_value = os.getenv("<ENV_NAME>")N’oubliez pas d’importer le module os de la bibliothèque standard de Python :
import osNous y voilà ! Vous êtes maintenant prêt à charger de manière sécurisée les clés Api depuis le fichier .env.
Étape 4 : Démarrer avec le serveur MCP de Bright Data
Si vous ne l’avez pas encore fait, créez un compte Bright Data. Si vous en avez déjà un, il vous suffit de vous connecter.
Ensuite, suivez les instructions officielles pour configurer votre clé d’API Bright Data. Pour plus de simplicité, nous supposons que vous utilisez un jeton avec des autorisations d’administrateur dans cette section.
Installez globalement le MCP Web de Bright Data via npm:
npm install -g @brightdata/mcpEnsuite, testez que tout fonctionne avec la commande Bash ci-dessous :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, sous Windows, la commande PowerShell équivalente est la suivante :
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpDans la commande ci-dessus, remplacez le caractère générique par l’API Bright Data que vous avez récupérée précédemment. Les deux commandes définissent la variable d’environnement API_TOKEN requise et démarrent le serveur MCP via le package @brightdata/mcp npm.
Si tout fonctionne correctement, votre terminal affichera des journaux similaires à ceux-ci :

La première fois que vous lancez le serveur MCP, il crée automatiquement deux zones par défaut dans votre compte Bright Data :
mcp_unlocker: Une zone pour Web Unlocker.mcp_browser: Une zone pour l’API du navigateur.
Ces deux zones permettent au serveur MCP d’exécuter tous les outils qu’il expose.
Pour le vérifier, connectez-vous à votre tableau de bord Bright Data et accédez à la page“Proxies & Scraping Infrastructure“. Vous verrez que les zones suivantes ont été créées automatiquement :
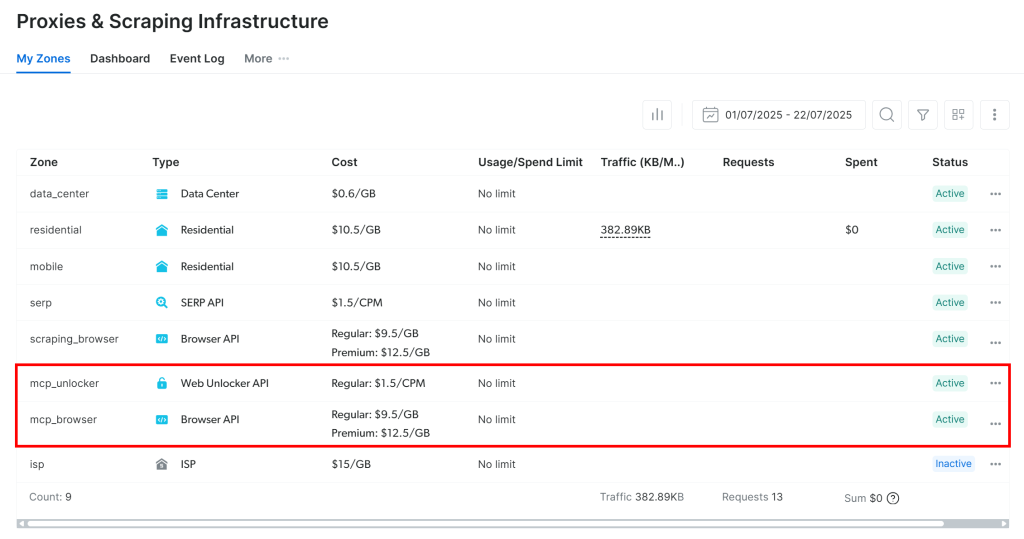
Remarque: si vous n’utilisez pas un jeton API avec des droits d’administrateur, vous devrez créer les zones manuellement. Quoi qu’il en soit, vous pouvez toujours spécifier les noms de zones dans les envs comme expliqué dans la documentation officielle.
Par défaut, le MCP Web n’expose que les outils search_engine et scrape_as_markdown. Pour débloquer des fonctionnalités avancées telles que l’automatisation du navigateur et l’extraction de données structurées, vous devez activer le mode Pro en définissant la variable d’environnement PRO_MODE=true.
Génial ! Le Web MCP fonctionne comme un charme.
Étape 5 : Connexion au MCP Web
Maintenant que vous avez confirmé que votre machine peut exécuter le Web MCP, connectez-vous à elle !
Commencez par ajouter votre clé d’API Bright Data au fichier .env :
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Remplacez le par la clé d’API Bright Data que vous avez obtenue précédemment.
Ensuite, lisez-le dans le fichier agent.py avec :
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")N’oubliez pas que Pydantic AI prend en charge trois méthodes de connexion à un serveur MCP:
- Utilisation du transport Streamable HTTP.
- Utilisation du transport HTTP SSE.
- Exécution du serveur en tant que sous-processus et connexion via
stdio.
Si les deux premières méthodes ne vous sont pas familières, lisez notre guide SSE vs Streamable HTTP pour une explication plus approfondie.
Dans ce cas, vous souhaitez exécuter le serveur en tant que sous-processus (troisième méthode). Pour ce faire, initialisez une instance MCPServerStdio comme indiqué ci-dessous :
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)Ces lignes de code lancent essentiellement le MCP Web à l’aide de la même commande npx que celle que vous avez exécutée précédemment. Elles définissent la variable d’environnement API_TOKEN en utilisant votre clé d’API Bright Data pour l’authentification. De plus, il active le PRO_MODE pour que vous ayez accès à tous les outils disponibles, y compris les outils avancés.
C’est très bien ! Vous avez maintenant configuré avec succès la connexion à votre MCP Web local dans le code.
Étape n° 6 : Configuration du LLM
Note: Cette section se réfère à Gemini, le LLM choisi pour le tutoriel. Cependant, vous pouvez facilement l’adapter à OpenAI ou à tout autre LLM supporté en suivant la documentation officielle.
Commencez par récupérer votre clé API Gemini et ajoutez-la à votre fichier .env comme suit :
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Remplacez le par votre clé API réelle.
Ensuite, il faut importer les bibliothèques Pydantic AI nécessaires à l’intégration de Gemini :
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderCes importations vous permettent de vous connecter aux API de Google et de configurer un modèle Gemini. Remarquez que vous n’avez pas besoin de lire manuellement la clé GOOGLE_API_KEY dans le fichier .env. La raison est que GoogleProvider utilise google-genai sous le capot, qui lit automatiquement la clé API depuis le fichier env GOOGLE_API_KEY.
Il faut maintenant initialiser les instances du fournisseur et du modèle :
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)C’est incroyable ! Cela permettra à l’agent d’intelligence artificielle Pydantic de se connecter au modèle Gemini-2.5-flash via l’API de Google, dont l’utilisation est gratuite.
Étape 7 : Définir l’agent d’intelligence artificielle Pydantic
Définir un agent Pydantic AI qui utilise le LLM précédemment configuré et se connecte au serveur Web MCP :
agent = Agent(model, toolsets=[server])C’est parfait ! En une seule ligne de code, vous venez d’instancier un objet Agent. Cet objet représente un agent d’intelligence artificielle capable de gérer vos tâches à l’aide des outils exposés par le serveur Web MCP.
Étape n° 8 : Lancer votre agent
Pour tester votre agent d’IA, vous devez écrire une invite qui implique une tâche d’extraction de données web (sur interaction). Cela vous permet de vérifier si l’agent utilise les outils Bright Data comme prévu.
Un bon point de départ consiste à lui demander de récupérer les données d’un produit à partir d’une page Amazon, comme ceci :
“Donnez-moi des données sur les produits à partir de https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”
Normalement, si vous envoyez une demande de ce type directement à Gemini, l’une des deux choses suivantes se produira :
- La demande échouerait en raison des systèmes anti-bots d’Amazon (par exemple, le CAPTCHA d’Amazon), qui empêchent Gemini d’accéder au contenu de la page.
- Il renverrait des informations hallucinées ou inventées sur les produits, puisqu’il ne peut pas accéder à la page en direct.
Essayez l’invite directement dans Gemini. Vous obtiendrez probablement un message indiquant qu’il n’a pas pu accéder à la page Amazon, suivi des détails du produit fabriqué, comme ci-dessous :

Grâce à l’intégration avec le serveur Web MCP, cela ne devrait pas se produire dans votre configuration. Au lieu d’échouer ou de deviner, votre agent devrait utiliser l’outil web_data_amazon_product pour récupérer en temps réel des données structurées sur le produit à partir de la page Amazon et les renvoyer dans un format propre et lisible.
Puisque la méthode d’interrogation de l’agent IA Pydantic est asynchrone, enveloppez la logique d’exécution dans une fonction asynchrone comme suit :
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())N’oubliez pas d’importer asyncio depuis la bibliothèque standard de Python :
import asyncioMission accomplie ! Il ne reste plus qu’à exécuter le code complet et à voir si l’agent répond aux attentes.
Étape n° 9 : Assembler le tout
C’est le code final de agent.py :
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Ouah ! Grâce à Pydantic AI et Bright Data, vous venez de construire un puissant agent d’IA alimenté par MCP en une cinquantaine de lignes de code.
Exécuter l’agent AI avec :
python agent.pyDans le terminal, vous devriez voir une sortie comme suit :

Comme vous pouvez le constater en consultant la page du produit Amazon mentionnée dans l’invite, les informations renvoyées par l’agent IA sont exactes :
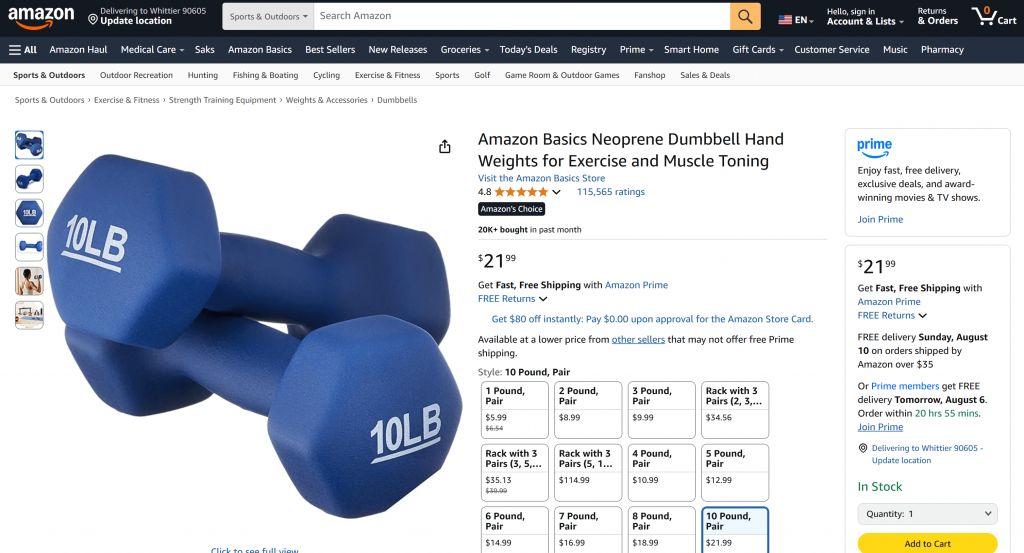
En effet, l’agent a utilisé l’outil web_data_amazon_product fourni par le serveur Web MCP pour récupérer des données fraîches et structurées sur les produits d’Amazon au format JSON.
Et voilà ! Les attentes ont été satisfaites et l’intégration de Pydantic AI + MCP a fonctionné exactement comme prévu.
Prochaines étapes
L’agent d’intelligence artificielle construit ici est fonctionnel, mais il ne constitue qu’un point de départ. Envisagez de le faire passer au niveau supérieur en.. :
- Mise en œuvre d’une boucle REPL pour dialoguer avec l’agent dans le CLI ou intégration avec des outils de dialogue en ligne comme Gradio.
- Étendre les outils MCP de Bright Data en définissant vos propres outils personnalisés.
- Ajout du débogage et de la surveillance à l’aide de Pydantic Logfire.
- Transformer votre agent en un agent autonome RAG dans le cadre d’un flux de travail multi-agents.
- Définition de validateurs de fonctions personnalisés pour l’intégrité des données de sortie.
Conclusion
Dans cet article, vous avez appris comment intégrer Pydantic AI avec le serveur Web MCP de Bright Data pour construire un agent IA capable d’accéder au web. Cette intégration est rendue possible par le support intégré de Pydantic AI pour MCP.
Pour créer des agents plus sophistiqués, explorez la gamme complète de services disponibles dans l’infrastructure d’IA de Bright Data. Ces solutions peuvent alimenter une grande variété de scénarios d’agents.
Créez gratuitement un compte Bright Data et commencez à expérimenter avec nos outils de données web prêts pour l’IA !




