

Dans ce guide, vous apprendrez :
- Ce qu’est le LlamaIndex.
- Pourquoi les agents d’IA construits avec LlamaIndex devraient être capables d’effectuer des recherches sur le web.
- Comment créer un agent d’intelligence artificielle LlamaIndex doté de capacités de recherche sur le web.
Plongeons dans l’aventure !
Qu’est-ce que LlamaIndex ?
LlamaIndex est un cadre Python open-source pour la construction d’applications alimentées par des LLM. Il sert de pont entre les données non structurées et les LLM. En particulier, il facilite l’orchestration des flux de travail LLM à travers une variété de sources de données.
Avec LlamaIndex, vous pouvez créer des flux de travail et des agents d’IA prêts pour la production. Ceux-ci peuvent rechercher et extraire des informations pertinentes, synthétiser des idées, générer des rapports détaillés, prendre des mesures automatisées, et bien plus encore.
À l’heure où nous écrivons ces lignes, il s’agit de l’une des bibliothèques à la croissance la plus rapide dans l’écosystème de l’IA, avec plus de 42 000 étoiles sur GitHub.
Pourquoi intégrer les données de recherche sur le Web dans votre agent d’intelligence artificielle LlamaIndex ?
Comparé à d’autres cadres d’agents d’IA, LlamaIndex a été créé pour résoudre l’une des plus grandes limitations des LLM. Il s’agit de leur manque de connaissances actualisées du monde réel.
Pour résoudre ce problème, LlamaIndex propose des intégrations avec plusieurs connecteurs de données qui vous permettent d’ingérer du contenu provenant de sources multiples. Vous vous demandez peut-être quelle est la source de données la plus utile pour un agent d’intelligence artificielle ?
Pour répondre à cette question, il est utile d’examiner les sources de données utilisées pour former les LLM. Les LLM qui ont réussi ont reçu la plupart de leurs données de formation du Web, la source de données publiques la plus vaste et la plus diversifiée.
Si vous voulez que votre agent d’IA LlamaIndex dépasse ses données d’entraînement statiques, la capacité clé dont il a besoin est la capacité de rechercher sur le web et d’apprendre à partir de ce qu’il trouve. Votre agent doit donc être capable d’extraire des informations structurées des pages de recherche résultantes (appelées “SERP“). Ensuite, il doit pouvoir les traiter et en tirer des enseignements utiles.
Le problème est que le scraping des SERP est devenu beaucoup plus difficile en raison des récentes mesures prises par Google à l’encontre des scripts de scraping simples. C’est pourquoi vous avez besoin d’un outil qui s’intègre à LlamaIndex et qui simplifie ce processus. C’est là que l ‘intégration de Bright Data de LlamaIndex entre en jeu !
Bright Data prend en charge le travail complexe de raclage des SERP. Grâce à son outil search_engine, il permet à votre agent LlamaIndex d’effectuer des requêtes de recherche et de recevoir des résultats structurés au format Markdown ou JSON.
C’est ce dont votre agent d’intelligence artificielle a besoin pour rester prêt à répondre aux questions, maintenant et à l’avenir. Découvrez comment fonctionne cette intégration dans le chapitre suivant !
Construire un agent LlamaIndex capable d’effectuer des recherches sur le Web à l’aide d’outils Bright Data
Dans ce guide étape par étape, vous verrez comment construire un agent IA en Python avec LlamaIndex qui peut faire des recherches sur le web.
En intégrant Bright Data, vous permettrez à votre agent d’accéder à des données de recherche web fraîches, contextuelles et riches. Pour plus de détails, consultez notre documentation officielle.
Suivez les étapes ci-dessous pour créer votre agent SERP IA alimenté par Bright Data en utilisant LlamaIndex !
Conditions préalables
Pour suivre ce tutoriel, vous avez besoin des éléments suivants :
- Python 3.9 ou plus installé sur votre machine (nous recommandons d’utiliser la dernière version).
- Une clé API Bright Data pour intégrer les API SERP de Bright Data.
- Une clé API d’un LLM pris en charge. (Dans ce guide, nous utiliserons Gemini, qui supporte l’intégration via API gratuitement. En même temps, vous pouvez utiliser n’importe quel fournisseur LLM supporté par LlamaIndex).
Ne vous inquiétez pas si vous n’avez pas encore de clé API Gemini ou Bright Data. Nous vous montrerons comment les créer dans les prochaines étapes.
Étape 1 : Initialiser votre projet Python
Commencez par lancer votre terminal et créez un nouveau dossier pour votre projet d’agent d’intelligence artificielle LlamaIndex :
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/ contiendra tout le code de votre agent d’intelligence artificielle avec des capacités de recherche sur le web alimentées par Bright Data.
Ensuite, naviguez dans le répertoire du projet et créez-y un environnement virtuel Python:
cd llamaindex-bright-data-serp-agent
python -m venv venvMaintenant, ouvrez le dossier du projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un nouveau fichier nommé agent.py à la racine du répertoire de votre projet. La structure de votre projet devrait ressembler à ceci :
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.pyDans le terminal, activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateDans les étapes suivantes, vous serez guidé dans l’installation des paquets nécessaires. Cependant, si vous souhaitez tout installer d’emblée, exécutez :
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-indexNote: Nous installons llama-index-llms-google-genai parce que ce tutoriel utilise Gemini comme fournisseur LLM de LlamaIndex. Si vous prévoyez d’utiliser un fournisseur différent, assurez-vous d’installer l’intégration LLM correspondante à la place.
Bonne pioche ! Votre environnement de développement Python est prêt à construire un agent d’IA avec l’intégration SERP de Bright Data à l’aide de LlamaIndex.
Étape 2 : Intégrer la lecture des variables d’environnement
Votre agent LlamaIndex se connectera à des services externes tels que Gemini et Bright Data via l’API. Pour des raisons de sécurité, vous ne devriez jamais coder en dur les clés API directement dans votre code Python. Au lieu de cela, utilisez des variables d’environnement pour les garder privées.
Installez la bibliothèque python-dotenv pour faciliter la gestion des variables d’environnement. Dans votre environnement virtuel activé, lancez :
pip install python-dotenvEnsuite, ouvrez votre fichier agent.py et ajoutez les lignes suivantes en haut pour charger les envs à partir d’un fichier .env :
from dotenv import load_dotenv
load_dotenv()load_dotenv() recherche un fichier .env dans le répertoire racine de votre projet et charge ses valeurs dans l’environnement.
Maintenant, créez un fichier .env à côté de votre fichier agent.py. La structure de votre nouveau projet devrait ressembler à ceci :
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.pyGénial ! Vous venez de mettre en place un moyen sécurisé de gérer les identifiants API sensibles pour les services tiers.
Poursuivez la configuration initiale en remplissant votre fichier .env avec les variables d’environnement requises !
Étape 3 : Configurer Bright Data
Pour vous connecter aux API SERP de Bright Data dans LlamaIndex via le package d’intégration officiel, vous devez tout d’abord :
- Activez la solution Web Unlocker dans votre tableau de bord Bright Data.
- Récupérez votre clé API Bright Data.
Suivez les étapes ci-dessous pour terminer l’installation !
Si vous n’avez pas encore de compte Bright Data, [créez-en un](). Si vous avez déjà un compte, connectez-vous. Dans le tableau de bord, cliquez sur le bouton “Obtenir des produits proxy” :
Vous serez dirigé vers la page “Proxies & Scraping Infrastructure” :
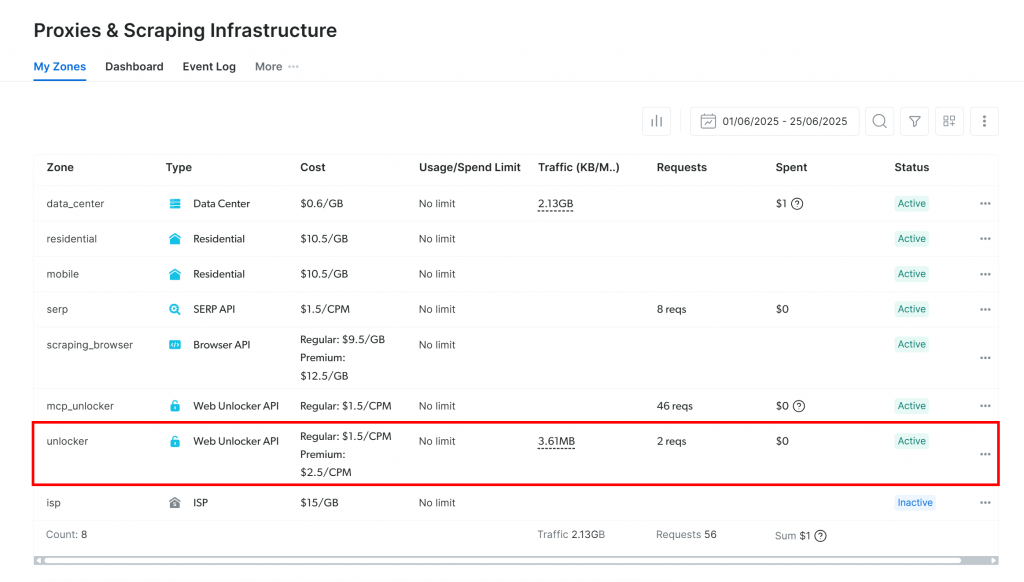
Si vous voyez déjà une zone API Web Unlocker active (comme dans l’image ci-dessus), vous êtes prêt. Notez le nom de la zone (par exemple, unlocker), car vous l’utiliserez plus tard dans votre code.
Si vous n’avez pas encore de zone Web Unlocker, faites défiler la page jusqu’à la section “Web Unlocker API” et cliquez sur le bouton “Créer une zone” :
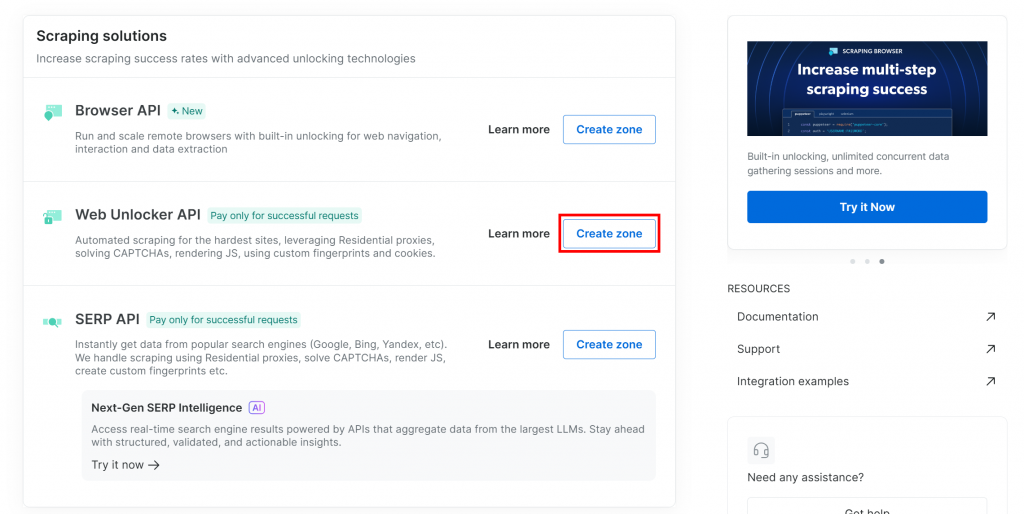
Pourquoi utiliser l’API Web Unlocker plutôt que l’API SERP dédiée ?
L’intégration SERP de LlamaIndex de Bright Data fonctionne via l’API Web Unlocker. Plus précisément, lorsqu’il est configuré correctement, Web Unlocker fonctionne de la même manière que les API SERP dédiées. En bref, en configurant une zone API Web Unlocker avec l’intégration LlamaIndex Bright Data, vous obtenez automatiquement l’accès aux API SERP également.
Donnez un nom à votre nouvelle zone, par exemple débloqueur, activez les fonctions avancées pour améliorer les performances, et cliquez sur “Ajouter” :
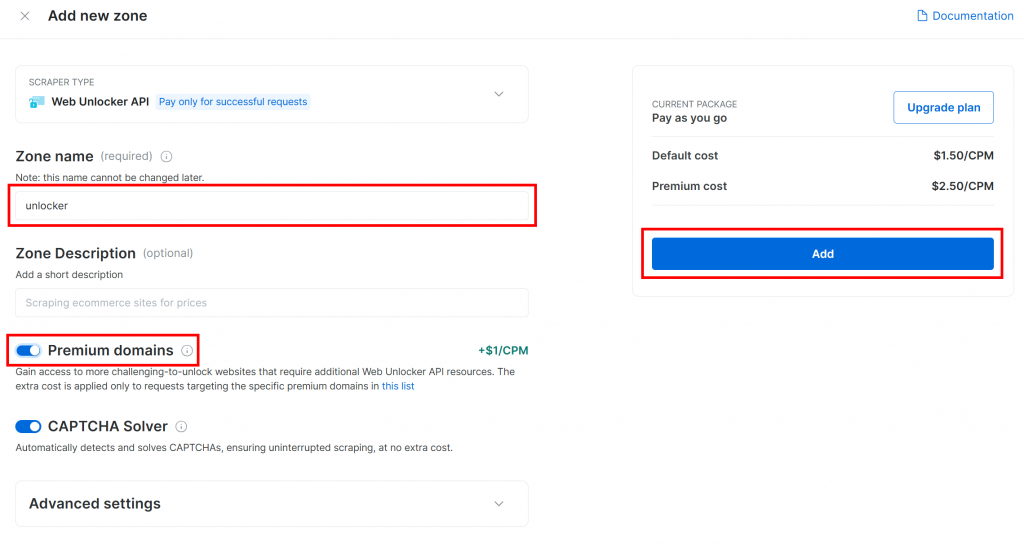
Une fois la zone créée, vous serez redirigé vers la page de configuration de la zone :
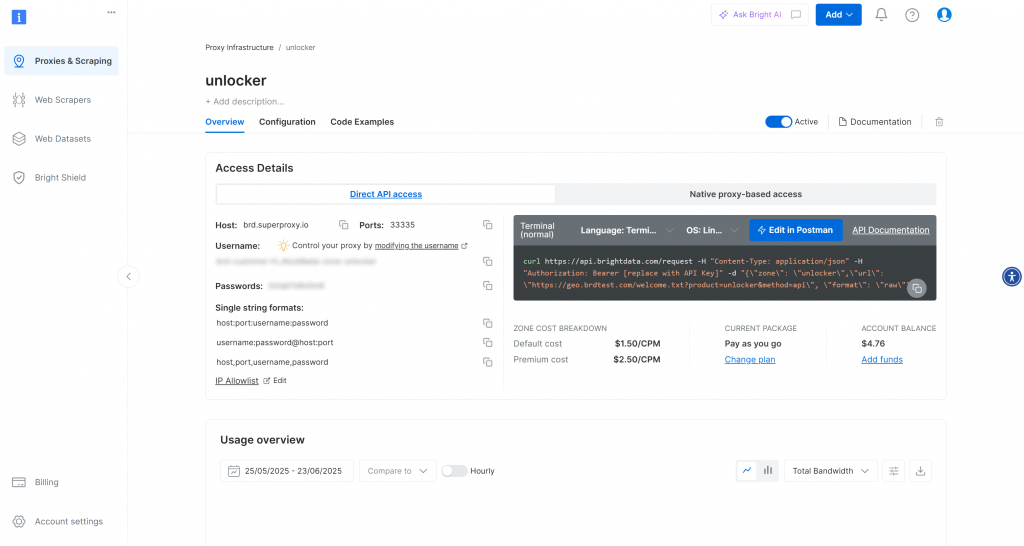
Assurez-vous que la bascule d’activation est réglée sur l’état “Actif”. Cela confirme que votre zone est prête à être utilisée.
Ensuite, suivez le guide officiel de Bright Data pour générer votre clé API. Une fois que vous avez votre clé, stockez-la en toute sécurité dans votre fichier .env comme suit :
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Remplacez le par la valeur réelle de votre clé API.
Génial ! Configurez l’outil SERP de Bright Data dans votre script d’agent LlamaIndex.
Étape 4 : Accéder à l’outil SERP de Bright Data LlamaIndex
Dans agent.py, commencez par charger votre clé d’API Bright Data dans l’environnement :
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Veillez à importer os de la bibliothèque standard de Python :
import osDans votre environnement virtuel activé, installez le paquet d’outils LlamaIndex Bright Data:
pip install llama-index-tools-brightdataEnsuite, importez la classe BrightDataToolSpec dans votre fichier agent.py :
from llama_index.tools.brightdata import BrightDataToolSpecCréez une instance de BrightDataToolSpec, en fournissant votre clé API et le nom de la zone Web Unlocker :
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)Remplacez la valeur zone par le nom de la zone de l’API Web Unlocker que vous avez définie précédemment (dans ce cas, il s’agit de unlocker).
Notez qu’il est utile de définir verbose=True lors du développement. Ainsi, la bibliothèque affichera des journaux utiles lorsque votre agent LlamaIndex effectuera des requêtes via Bright Data.
BrightDataToolSpec propose plusieurs outils, mais nous nous concentrons ici sur l’outil search_engine. Cet outil peut interroger Google, Bing, Yandex et d’autres, en renvoyant les résultats en Markdown ou en JSON.
Pour extraire cet outil, écrivez :
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])Le tableau passé à to_tool_list() agit comme un filtre, n’incluant que l’outil nommé search_engine.
Note: Par défaut, LlamaIndex choisira l’outil le plus approprié pour une demande d’utilisateur donnée. Le filtrage des outils n’est donc pas strictement nécessaire. Comme ce tutoriel porte spécifiquement sur l’intégration des capacités SERP de Bright Data, il est logique de le limiter à l’outil search_engine pour plus de clarté.
Génial ! Bright Data est maintenant intégré et prêt à alimenter votre agent LlamaIndex avec des capacités de recherche sur le web.
Étape 5 : Connecter un modèle LLM
Les instructions de cette étape utilisent Gemini comme fournisseur LLM pour cette intégration. Une bonne raison de choisir Gemini est qu’il offre un accès API gratuit à certains de ses modèles.
Pour commencer à utiliser Gemini dans LlamaIndex, installez le paquet d’intégration requis :
pip install llama-index-llms-google-genaiEnsuite, importez la classe GoogleGenAI dans agent.py :
from llama_index.llms.google_genai import GoogleGenAIMaintenant, initialisez le Gemini LLM comme suit :
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)Dans cet exemple, nous utilisons le modèle gemini-2.5-flash. N’hésitez pas à choisir tout autre modèle Gemini pris en charge.
En coulisses, la classe GoogleGenAI recherche automatiquement une variable d’environnement nommée GEMINI_API_KEY. Elle utilise la clé API lue dans cette variable pour se connecter aux API Gemini.
Configurez-le en ouvrant votre fichier .env et en ajoutant :
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Remplacez le par votre véritable clé API Gemini. Si vous n’en avez pas encore, vous pouvez l’obtenir gratuitement en suivant le guide officiel de récupération de l’API Gemini.
Note: Si vous souhaitez utiliser un fournisseur LLM différent, LlamaIndex supporte de nombreuses options. Référez-vous à la documentation officielle de LlamaIndex pour les instructions d’installation.
Bravo ! Vous avez maintenant toutes les pièces maîtresses en place pour construire un agent d’IA LlamaIndex capable de faire des recherches sur le web.
Étape 6 : Définir l’agent LlamaIndex
Tout d’abord, installez le paquetage principal de LlamaIndex:
pip install llama-indexEnsuite, dans votre fichier agent.py, importez la classe FunctionAgent :
from llama_index.core.agent.workflow import FunctionAgentFunctionAgent est un agent IA spécialisé de LlamaIndex qui peut interagir avec des outils externes, tels que l’outil SERP de Bright Data que vous avez mis en place plus tôt.
Initialisez l’agent avec votre LLM et l’outil SERP de Bright Data comme suit :
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)Cela crée un agent d’intelligence artificielle qui traite les entrées de l’utilisateur via votre LLM et peut appeler les outils SERP de Bright Data pour effectuer des recherches en temps réel sur le Web lorsque cela est nécessaire. Notez l’argument system_prompt, qui définit le rôle et le comportement de l’agent. Une fois de plus, l’option verbose=True est utile pour inspecter l’activité interne.
Merveilleux ! L’intégration LlamaIndex + Bright Data SERP est terminée. La prochaine étape est d’implémenter le REPL pour une utilisation interactive.
Étape 7 : Construire le REPL
REPL, abréviation de “Read-Eval-Print Loop“, est un modèle de programmation interactive dans lequel vous entrez des commandes, les faites évaluer et voyez les résultats.
Dans ce contexte, le REPL fonctionne de la manière suivante :
- Vous décrivez la tâche que vous souhaitez confier à l’agent d’intelligence artificielle.
- L’agent d’intelligence artificielle exécute la tâche, en effectuant des recherches en ligne si nécessaire.
- La réponse est imprimée dans le terminal.
Cette boucle se poursuit indéfiniment jusqu’à ce que vous tapiez "exit".
Dans agent.py, ajoutez cette fonction asynchrone pour gérer la logique REPL :
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Cette fonction REPL :
- Accepte les données de l’utilisateur provenant de la ligne de commande via
input(). - Traite l’entrée en utilisant l’agent LlamaIndex alimenté par Gemini et Bright Data via
agent.run(). - Affiche la réponse à la console.
Parce que agent.run() est asynchrone, la logique REPL doit être à l’intérieur d’une fonction asynchrone. Exécutez-la comme ceci au bas de votre fichier :
if __name__ == "__main__":
asyncio.run(main())N’oubliez pas d’importer asyncio:
import asyncioC’est parti ! L’agent LlamaIndex AI avec les outils de SERP scraping est prêt.
Étape n° 8 : Assembler le tout et faire fonctionner l’agent d’intelligence artificielle
C’est ce que doit contenir votre fichier agent.py :
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())Exécutez votre agent SERP LlamaIndex avec :
python agent.pyLorsque le script démarre, vous verrez une invite comme celle-ci dans votre terminal :

Essayez de demander à votre agent quelque chose qui nécessite de nouvelles informations, par exemple :
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.Pour accomplir cette tâche efficacement, l’agent d’intelligence artificielle doit rechercher des informations actualisées sur le web.
Le résultat sera le suivant :
C’est allé très vite, alors voyons ce qui s’est passé :
- L’agent détecte la nécessité de rechercher de “nouveaux protocoles d’IA” et appelle l’API SERP de Bright Data via l’outil search_engine à l’aide de l’URL d’entrée suivante
: https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1. - L’outil récupère de manière asynchrone les données SERP au format JSON à partir de l’API Google Search de Bright Data.
- L’agent transmet la réponse JSON au LLM Gemini.
- Gemini traite les nouvelles données et génère un rapport Markdown clair et précis avec des liens pertinents.
Dans ce cas, l’agent IA est revenu :
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.Remarquez que la réponse de l’agent IA comprend des protocoles récents et des liens actualisés publiés après la dernière mise à jour de la formation de Gemini. Cela souligne l’intérêt d’intégrer des capacités de recherche en direct sur le web.
Plus précisément, la réponse comprend des liens contextuels qui correspondent étroitement à ce que vous trouveriez en recherchant “new ai protocols” sur Google :
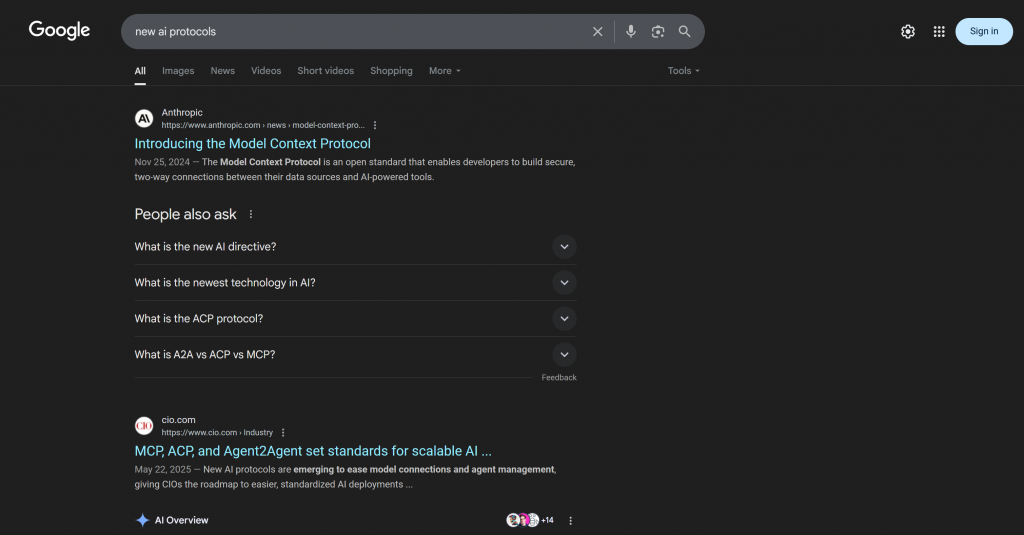
Vous remarquerez que la réponse comprend un grand nombre de liens identiques à ceux que vous trouveriez dans le SERP “nouveaux protocoles d’IA” (au moment de la rédaction de ce document, du moins).
Et voilà ! Vous avez maintenant un agent LlamaIndex AI avec des capacités de scraping de moteurs de recherche, alimenté par Bright Data.
Étape 9 : Prochaines étapes
L’agent SERP AI actuel de LlamaIndex n’est qu’un simple exemple qui utilise uniquement l’outil search_engine de Bright Data.
Dans les scénarios plus avancés, vous ne voudrez probablement pas limiter votre agent à un seul outil. Il est préférable de lui donner accès à tous les outils disponibles et de rédiger une invite système claire qui aide le MLD à décider lesquels utiliser pour chaque objectif.
Vous pouvez, par exemple, aller plus loin et demander à votre interlocuteur de vous envoyer un message :
- Effectuer des recherches multiples.
- Sélectionnez les N premiers liens dans les résultats des SERP.
- Visitez ces pages et récupérez leur contenu en Markdown.
- Tirer des enseignements de ces informations pour produire un résultat plus riche et plus détaillé.
Pour plus d’informations sur l’intégration avec tous les outils disponibles, consultez notre tutoriel sur la création d’agents d’intelligence artificielle avec LlamaIndex et Bright Data.
Conclusion
Dans cet article, vous avez appris à utiliser LlamaIndex pour construire un agent d’intelligence artificielle capable d’effectuer des recherches sur le web via Bright Data. Cette intégration permet à votre agent d’exécuter des requêtes sur les principaux moteurs de recherche, notamment Google, Bing, Yandex et bien d’autres.
N’oubliez pas que l’exemple présenté ici n’est qu’un point de départ. Si vous envisagez de développer des agents plus avancés, vous aurez besoin d’outils robustes pour récupérer, valider et transformer les données Web en direct. C’est exactement ce que propose l’infrastructure d’IA pour agents de Bright Data.
Créez un compte Bright Data gratuit et commencez à explorer nos outils de données d’IA agentique dès aujourd’hui !




