
Ce guide vous montre comment connecter Bright Data Web MCP à LangGraph afin de créer un agent de recherche IA capable de rechercher, d’extraire et d’analyser des données web en temps réel.
Dans ce guide, vous apprendrez à :
- Créer un agent LangGraph qui contrôle sa propre boucle de raisonnement
- Donner à cet agent un accès web en direct à l’aide du niveau gratuit de Bright Data Web MCP
- Connecter des outils de recherche et d’extraction à un agent fonctionnel
- Mettre à niveau le même agent avec l’automatisation du navigateur à l’aide des outils premium Web MCP
Introduction à LangGraph
LangGraph vous permet de créer des applications LLM dont le flux de contrôle est explicite et facilement inspectable, et non enfoui dans des invites ou des tentatives répétées. Chaque étape devient un nœud. Chaque transition est définie par vous.
L’agent fonctionne en boucle. Le modèle LLM lit l’état actuel et répond ou demande un outil. S’il fait appel à un outil (comme la recherche sur le Web), le résultat est ajouté à l’état et le modèle prend une nouvelle décision. Lorsqu’il dispose de suffisamment d’informations, la boucle se termine.
C’est la différence essentielle entre les workflows et les agents. Un workflow suit des étapes fixes. Un agent fonctionne en boucle : décider, agir, observer, décider à nouveau. Cette boucle est la même base que celle utilisée dans les systèmes RAG agentifs, où la récupération se fait de manière dynamique plutôt qu’à des points fixes.
LangGraph vous offre un moyen structuré de créer cette boucle, avec une mémoire, l’appel d’outils et des conditions d’arrêt explicites. Vous pouvez voir chaque décision prise par l’agent et contrôler quand il s’arrête.
Pourquoi utiliser Bright Data Web MCP avec LangGraph
Les LLM raisonnent bien, mais ils ne peuvent pas voir ce qui se passe actuellement sur le web. Leurs connaissances s’arrêtent au moment de la formation. Ainsi, lorsqu’un agent a besoin de données actuelles, le modèle a tendance à combler cette lacune en faisant des suppositions.
Bright Data Web MCP donne à votre agent un accès direct aux données web en direct grâce à des outils de recherche et d’extraction. Au lieu de deviner, le modèle fonde ses réponses sur des sources réelles et actualisées.
LangGraph est ce qui rend cet accès utilisable dans un contexte d’agent. Un agent doit décider quand il en sait suffisamment et quand il doit rechercher davantage de données.
Avec Web MCP, lorsque l’agent répond à une question, il peut indiquer les sources qu’il a réellement utilisées au lieu de se fier à sa mémoire. Cela rend le résultat plus fiable et plus facile à déboguer.
Comment connecter Bright Data Web MCP à un agent LangGraph
LangGraph contrôle la boucle de l’agent. Bright Data Web MCP donne à l’agent accès à des données web en temps réel. Il ne reste plus qu’à les relier entre eux sans ajouter de complexité.
Dans cette section, vous allez configurer un projet Python minimal, vous connecter au serveur Web MCP et exposer ses outils à un agent LangGraph.
Prérequis
Pour suivre ce tutoriel, vous avez besoin de :
- Python version 3.11+
- d’un compte Bright Data
- d’un compte OpenAI Platform
Étape n° 1 : générer une clé API OpenAI
L’agent a besoin d’une clé API LLM pour raisonner et décider quand utiliser les outils. Dans cette configuration, cette clé provient d’OpenAI.
Créez une clé API à partir du tableau de bord de la plateforme OpenAI. Ouvrez la page « Clés API » et cliquez sur « Créer une nouvelle clé secrète ».
Une nouvelle fenêtre s’ouvrira, dans laquelle vous pourrez configurer votre clé.
Conservez les paramètres par défaut, nommez la clé si vous le souhaitez, puis cliquez sur « Créer une clé secrète ».
Copiez la clé et conservez-la en lieu sûr. Vous l’ajouterez à la variable d’environnement OPENAI_API_KEY dans les étapes suivantes.
Cette clé permet à LangGraph d’appeler le modèle LLM qui peut décider quand invoquer les outils Web MCP.
Étape n° 2 : générer un jeton API Bright Data
Ensuite, vous avez besoin d’un jeton API de Bright Data. Ce jeton authentifie votre agent auprès du serveur Web MCP et lui permet d’appeler les outils de recherche et de scraping.
Générez le jeton dans le tableau de bord Bright Data. Ouvrez « Paramètres du compte », accédez à « Utilisateurs et clés API », puis cliquez sur « + Ajouter une clé ».
Pour ce guide, conservez simplement les valeurs par défaut et cliquez sur « Enregistrer » :
Copiez la clé et conservez-la en lieu sûr. Vous l’ajouterez à la variable d’environnement BRIGHTDATA_TOKEN dans les étapes suivantes.
Ce jeton permet à votre agent d’accéder aux données Web en direct via Web MCP.
Étape n° 3 : configurer un projet Python simple
Créez un nouveau répertoire de projet et un environnement virtuel :
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv Activez l’environnement virtuel :
source webmcp-langgraph-venv/bin/activateCela permet d’isoler les dépendances et d’éviter les conflits avec d’autres projets. Une fois l’environnement activé, installez uniquement les dépendances requises. Il s’agit des mêmes adaptateurs MCP que ceux utilisés dans les intégrations LangChain et LangGraph de Bright Data, ce qui garantit la cohérence de la configuration à mesure que votre agent se développe :
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvCréez un fichier .env pour stocker vos clés API :
touch .envCollez la clé API OpenAI et la clé Bright Data dans le fichier .env:
OPENAI_API_KEY="votre-clé-API-openai"
BRIGHTDATA_TOKEN="votre-clé-API-brightdata"Ne modifiez pas le nom OPENAI_API_KEY. LangChain le lit automatiquement, vous n’avez donc pas besoin de passer la clé dans le code.
Enfin, créez un fichier Python unique et définissez l’invite système qui définit le rôle de l’agent, ses limites et les règles d’utilisation des outils :
# fichier webmcp-langgraph-demo.py
SYSTEM_PROMPT = """Vous êtes un assistant de recherche sur le web.
Tâche :
- Effectuez des recherches sur le sujet de l'utilisateur à l'aide des résultats de recherche Google et de quelques sources.
- Renvoyez 6 à 10 points simples.
- Ajoutez une courte liste « Sources : » contenant uniquement les URL que vous avez utilisées.
Comment utiliser les outils :
- Commencez par utiliser l'outil de recherche pour obtenir les résultats Google.
- Sélectionnez 3 à 5 résultats fiables et récupérez-les.
- Si la récupération échoue, essayez un autre résultat.
Contraintes :
- Utilisez au maximum 5 sources.
- Privilégiez les documents officiels ou les sources primaires.
- Soyez rapide : pas de recherche approfondie.
"""Étape n° 4 : configurer les nœuds LangGraph
Il s’agit du cœur de l’agent. Une fois que vous comprenez cette boucle, tout le reste n’est que détail de mise en œuvre.
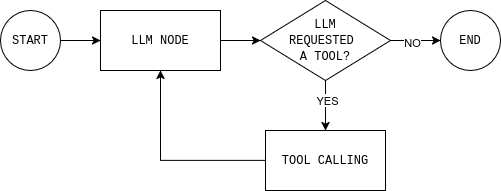
Avant d’écrire du code, il est utile de comprendre la boucle de l’agent que vous vous apprêtez à créer. Le diagramme montre une boucle d’agent LangGraph simple : le modèle lit l’état actuel, décide s’il a besoin de données externes, appelle un outil si nécessaire, observe le résultat et répète l’opération jusqu’à ce qu’il puisse répondre.
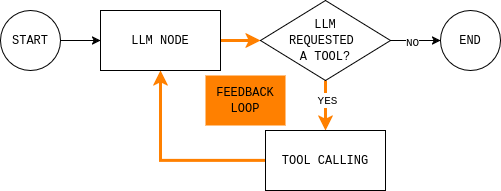
Pour implémenter cette boucle, vous avez besoin de deux nœuds (un nœud LLM et un nœud d’exécution d’outil) et d’une fonction de routage qui décide de continuer ou de terminer et de donner une réponse finale.
Le nœud LLM envoie l’état actuel de la conversation et les règles du système au modèle et renvoie soit une réponse, soit des appels d’outils. Le détail important est que chaque réponse du modèle est ajoutée à MessagesState, afin que les étapes suivantes puissent voir ce que le modèle a décidé et pourquoi.
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_callLe nœud d’exécution des outils exécute tous les outils demandés par le modèle et enregistre les résultats sous forme d’observations. Cette séparation permet de conserver le raisonnement dans le modèle et l’exécution dans le code.
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# Les outils MCP sont généralement asynchrones.
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_nodeEnfin, la règle de routage décide si le graphe doit continuer à boucler ou s’arrêter. En pratique, elle répond à une seule question : le modèle a-t-il demandé des outils ?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return ENDÉtape n° 5 : tout connecter
Tout ce qui concerne cette étape se trouve dans la fonction main(). C’est là que vous configurez les informations d’identification, vous connectez à Web MCP, liez les outils, construisez le graphe et exécutez une requête.
Commencez par charger les variables d’environnement et lire BRIGHTDATA_TOKEN. Cela permet de ne pas inclure les identifiants dans le code source et d’échouer rapidement si le jeton est manquant.
# Charger les variables d'environnement à partir de .env
load_dotenv()
# Lire le jeton Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")Ensuite, créez un MultiServerMCPClient et pointez-le vers le point de terminaison Web MCP. Ce client connecte l’agent aux données Web en direct.
# Se connecter au serveur Bright Data Web MCP
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})Remarque : Web MCP utilise Streamable HTTP comme transport par défaut, ce qui simplifie la diffusion et les nouvelles tentatives de l’outil par rapport aux anciennes configurations basées sur SSE. C’est pourquoi la plupart des intégrations MCP récentes standardisent ce transport.
Récupérez ensuite les outils MCP disponibles et indexez-les par nom. Le nœud d’exécution de l’outil utilise cette carte pour acheminer les appels.
# Récupérer tous les outils MCP disponibles (recherche, scraping, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}Initialisez le LLM et liez-y les outils MCP. Cela permet d’appeler les outils.
# Initialiser le LLM et lui permettre d'appeler les outils MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)Construisez maintenant l’agent LangGraph présenté précédemment. Créez un StateGraph(MessagesState), ajoutez les nœuds LLM et tool, puis connectez les arêtes pour faire correspondre la boucle.
# Construire l'agent LangGraph
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Flux du graphe :
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()Enfin, exécutez l’agent avec une invite réelle. Définissez une limite de récursivité (recursion_limit) pour éviter les boucles infinies.
# Exemple de requête de recherche
topic = « Qu'est-ce que Bright Data Web MCP ? »
# Exécutez l'agent
result = await agent.ainvoke(
{
« messages » : [
HumanMessage(content=f« Recherchez ce sujet :n{topic} »)
]
},
# Empêcher les boucles infinies
config={"recursion_limit": 12})
# Imprimer la réponse finale
print(result["messages"][-1].content)Voici à quoi cela ressemble dans main():
async def main():
# Charger les variables d'environnement depuis .env
load_dotenv()
# Lire le jeton Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")
# Connexion au serveur Web MCP de Bright Data
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# Récupérer tous les outils MCP disponibles (recherche, scraping, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# Initialiser le LLM et lui permettre d'appeler les outils MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# Construire l'agent LangGraph
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Flux du graphe :
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# Exemple de requête de recherche
topic = « Qu'est-ce que le protocole MCP (Model Context Protocol) et comment l'utiliser avec LangGraph ? »
# Exécuter l'agent
result = await agent.ainvoke(
{
« messages » : [
HumanMessage(content=f« Rechercher ce sujet :n{topic} »)
]
},
# Empêcher les boucles infinies
config={"recursion_limit": 12}
)
# Imprimer la réponse finale
print(result["messages"][-1].content)Remarque : vous trouverez une version complète et exécutable de cet agent dans ce référentiel GitHub. Clonez le référentiel, ajoutez vos clés API à un fichier
.envet exécutez le script pour voir la boucle complète LangGraph + Web MCP en action.
Utilisation des outils payants Web MCP pour surmonter les défis du scraping web avec l’automatisation des navigateurs
Le scraping statique ne fonctionne plus dès que vous dépassez les pages rendues par le serveur et que vous accédez à des sites riches en JavaScript ou axés sur l’interaction. Il s’agit de la même distinction entre statique et dynamique qui détermine quand vous avez besoin d’un véritable navigateur plutôt que du HTML brut.
Il échoue également sur les pages qui nécessitent une véritable interaction de l’utilisateur (défilement infini, pagination par boutons), où l’automatisation du navigateur devient la seule option fiable.
Web MCP propose l’automatisation du navigateur de scraping et le scraping avancé comme outils MCP. Pour l’agent, il s’agit simplement d’options supplémentaires lorsque les outils plus simples ne suffisent pas.
Activer les outils d’automatisation du navigateur dans Web MCP
Étant donné que les outils d’automatisation du navigateur Web MCP ne sont pas inclus dans l’offre gratuite, vous devez d’abord ajouter des fonds à votre compte Bright Data dans le menu « Facturation » dans la barre latérale gauche.
Ensuite, activez le groupe d’outils d’automatisation du navigateur pour votre configuration MCP. Ouvrez la section « MCP » et cliquez sur « Modifier » :
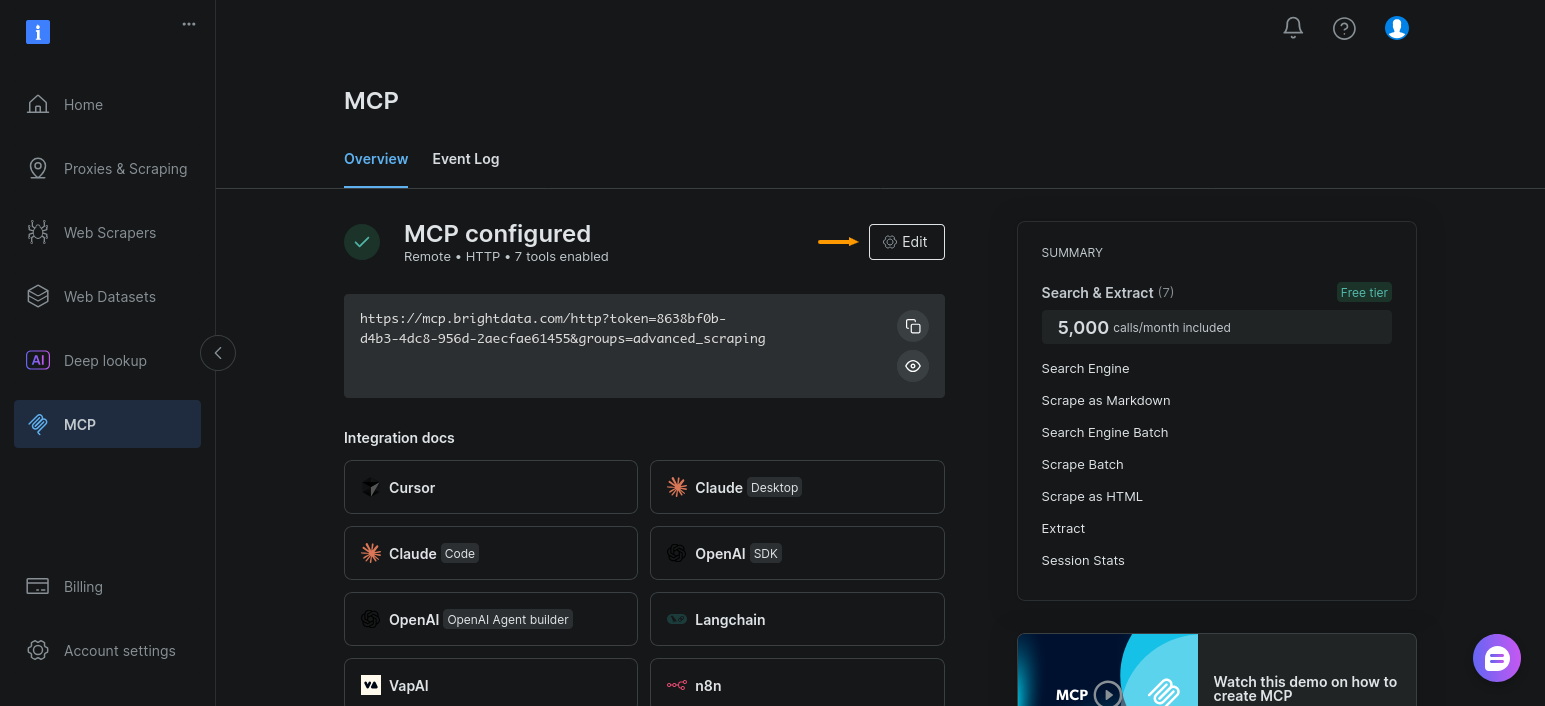
Il ne vous reste plus qu’à activer « Automatisation du navigateur » et à cliquer sur « Continuer la configuration » :
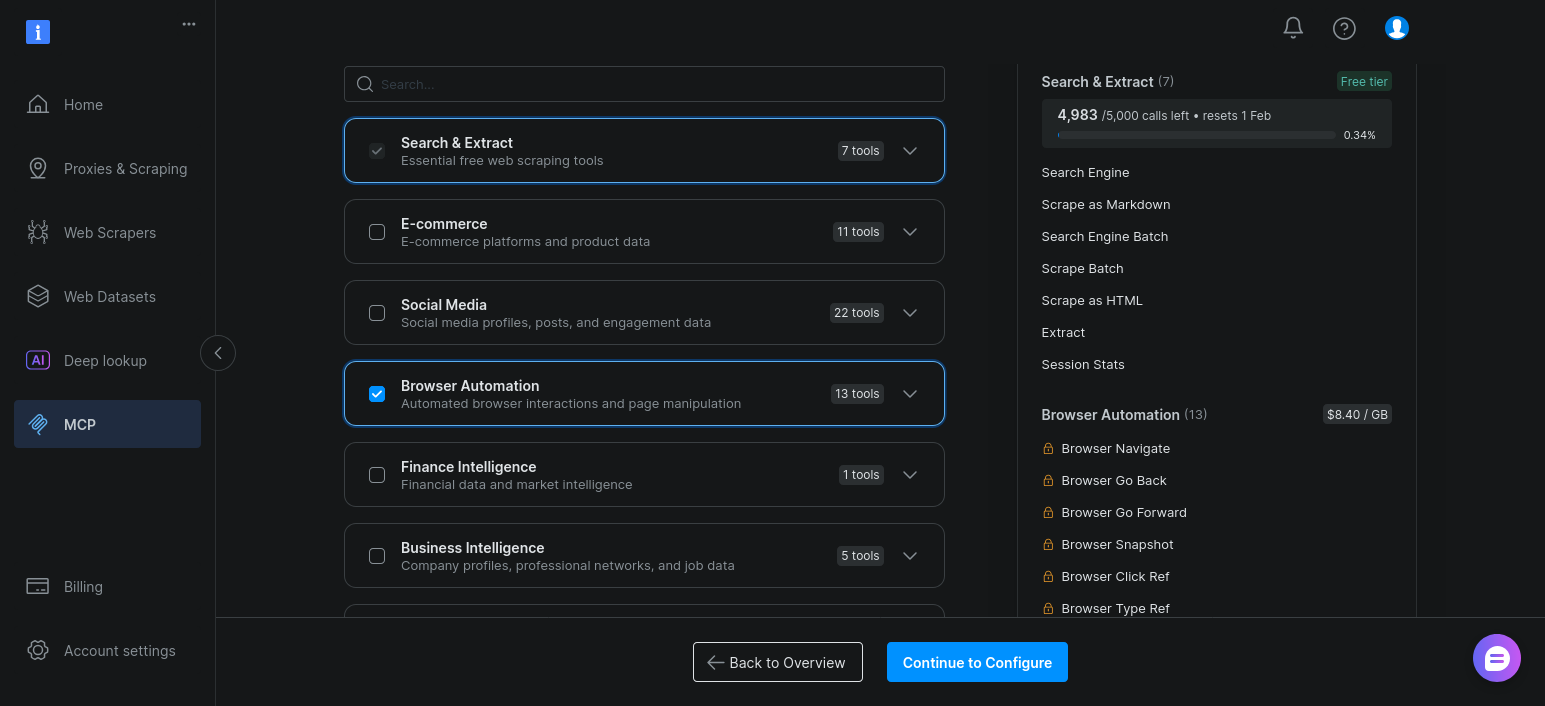
Conservez les paramètres par défaut et cliquez sur « Copier et fermer » :
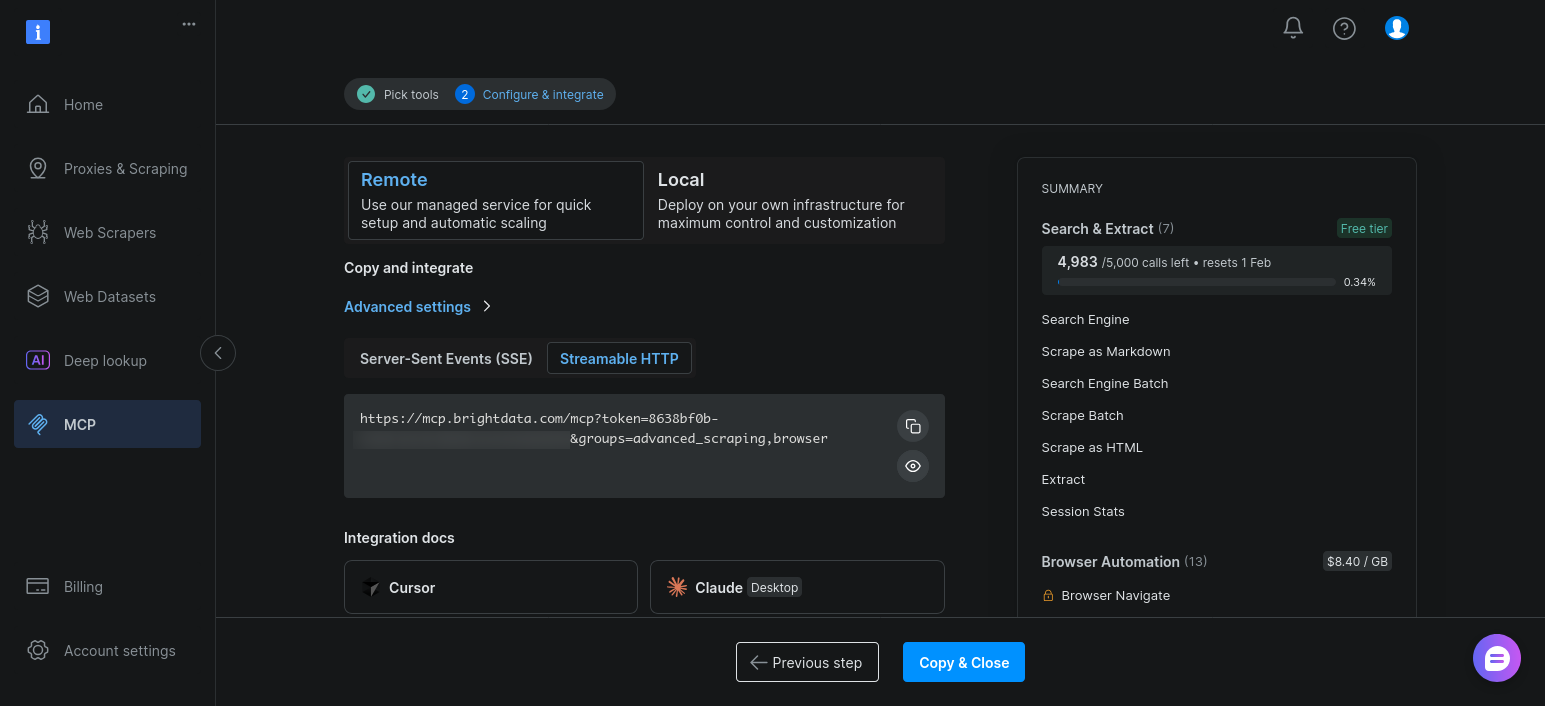
Une fois activés, ces outils apparaissent à côté des outils de recherche et de scraping lorsque l’agent appelle client.get_tools().
Étendre l’agent LangGraph existant pour les outils d’automatisation du navigateur
Le point essentiel ici est simple : vous ne modifiez pas votre architecture LangGraph.
Votre agent est déjà capable de :
- Découvre les outils de manière dynamique
- Les lie au modèle
- Achemine l’exécution via la même boucle
LLM -> outil -> observation
L’ajout d’outils d’automatisation du navigateur ne modifie que les outils disponibles.
En pratique, le seul changement concerne l’URL de connexion MCP. Au lieu de vous connecter au point de terminaison de base, demandez les groupes d’outils avancés de scraping et d’automatisation du navigateur :
# Activer le scraping avancé et l'automatisation du navigateur de scraping
« url » : f« https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser »Lorsque vous réexécutez le script, client.get_tools() renvoie des outils supplémentaires basés sur le navigateur. Le modèle peut les choisir lorsque le scraping statique renvoie des résultats maigres ou incomplets.
Conclusion
LangGraph vous offre une boucle d’agent claire et inspectable avec des conditions d’état, de routage et d’arrêt que vous contrôlez. Web MCP donne à cette boucle un accès fiable à des données web réelles sans intégrer la logique de scraping dans des invites ou du code.
Il en résulte une séparation claire des préoccupations. Le modèle décide quoi faire. LangGraph décide comment la boucle fonctionne. Bright Data gère les problèmes de recherche, d’extraction et de blocage. En cas d’échec, vous pouvez voir où et pourquoi cela s’est produit.
Tout aussi important, cette configuration ne vous enferme pas dans une impasse. Vous pouvez commencer avec les outils Web MCP de base pour une recherche rapide, puis passer aux outils Web MCP payants lorsque le Scraping web ne fonctionne plus. L’architecture de l’agent reste la même. Seule la portée de l’agent s’étend.






