

Dans ce tutoriel, vous apprendrez :
- Ce qu’est Haystack et pourquoi l’intégration de Bright Data fait passer ses pipelines et agents IA au niveau supérieur.
- Comment commencer.
- Comment intégrer Haystack à Bright Data à l’aide d’outils personnalisés.
- Comment connecter Haystack à plus de 60 outils disponibles via Web MCP.
C’est parti !
Haystack : qu’est-ce que c’est et pourquoi a-t-on besoin d’outils de récupération de données Web ?
Haystack est un framework IA open source permettant de créer des applications prêtes à l’emploi avec des LLM. Il vous permet de créer des systèmes RAG, des agents IA et des pipelines de données avancés en connectant des composants tels que des modèles, des bases de données vectorielles et des outils dans des workflows modulaires.
Haystack offre la flexibilité, la personnalisation et l’évolutivité nécessaires pour mener à bien des projets d’IA, de la conception au déploiement. Tout cela dans une bibliothèque open source avec plus de 23 000 étoiles GitHub.
Cependant, quelle que soit la sophistication de votre application Haystack, elle reste confrontée aux limitations fondamentales des LLM : des connaissances obsolètes provenant de données d’entraînement statiques et l’absence d’accès en direct au web !
La solution consiste à s’intégrer à un fournisseur de données web pour l’IA tel que Bright Data, qui propose des outils de Scraping web, de recherche, d’automatisation des navigateurs et bien plus encore, libérant ainsi tout le potentiel de votre système d’IA !
Prérequis
Pour suivre ce tutoriel, vous devez disposer des éléments suivants :
- Python 3.9+ installé localement.
- Un compte Bright Data avec une clé API configurée.
- Une clé API OpenAI (ou une clé API de tout autre LLM pris en charge par Haystack).
Si vous ne l’avez pas encore fait, suivez le guide officiel pour créer votre compte et générer une clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin sous peu.
Il sera également utile d’avoir une certaine connaissance des produits et services de Bright Data, ainsi qu’une compréhension de base du fonctionnement des outils et de l’intégration MCP dans Haystack.
Pour simplifier, nous supposerons que vous disposez déjà d’un projet Python avec un environnement virtuel configuré. Installez Haystack à l’aide de la commande suivante :
pip install haystack-iaVous disposez désormais de tout ce dont vous avez besoin pour commencer l’intégration de Bright Data dans Haystack. Nous allons ici explorer deux approches :
- Définir des outils personnalisés à l’aide de l’annotation
@tool. - Charger un
MCPToolà partir du serveur Web MCP de Bright Data.
Définition d’outils personnalisés alimentés par Bright Data dans Haystack
Une façon d’accéder aux fonctionnalités de Bright Data dans Haystack consiste à définir des outils personnalisés. Ces outils s’intègrent aux produits Bright Data via une API dans des fonctions personnalisées.
Pour simplifier ce processus, nous nous appuierons sur le SDK Python de Bright Data, qui fournit une API Python facile à appeler :
- API Web Unlocker: récupérez le contenu de n’importe quel site web à l’aide d’une seule requête et recevez un code HTML ou JSON propre, tandis que la gestion des Proxy, du déblocage, des en-têtes et des CAPTCHA est automatisée.
- API SERP: collectez les résultats des moteurs de recherche Google, Bing et bien d’autres à grande échelle sans vous soucier des blocages.
- API Scraping web: récupérez des données structurées et analysées à partir de sites populaires tels qu’Amazon, Instagram, LinkedIn, Yahoo Finance, etc.
- Et d’autres solutions Bright Data…
Nous transformerons les principales méthodes SDK en outils compatibles avec Haystack, permettant à tout agent ou pipeline d’IA de bénéficier de la récupération de données web optimisée par Bright Data !
Étape n° 1 : installer et configurer le SDK Python de Bright Data
Commencez par installer le SDK Python Bright Data via le package PyPI brightdata-sdk:
pip install brightdata-sdkImportez la bibliothèque et initialisez une instance BrightDataClient:
import os
from brightdata import BrightDataClient
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Remplacez-le par votre clé API Bright Data.
# Initialisez le client Bright Data Python SDK.
client = BrightDataClient(
token=BRIGHT_DATA_API_KEY,
)Remplacez l’espace réservé <VOTRE_CLÉ_API_BRIGHT_DATA> par la clé API que vous avez générée dans la section « Prérequis ».
Pour un code prêt à être utilisé en production, évitez de coder en dur votre clé API dans le script. Le SDK Python Bright Data l’attend dans la variable d’environnement BRIGHTDATA_API_TOKEN. Définissez donc votre variable d’environnement sur votre clé API Bright Data de manière globale, ou chargez-la à partir d’un fichier .env à l’aide du package python-dotenv.
BrightDataClient configurera automatiquement les zones Web Unlocker et API SERP par défaut dans votre compte Bright Data :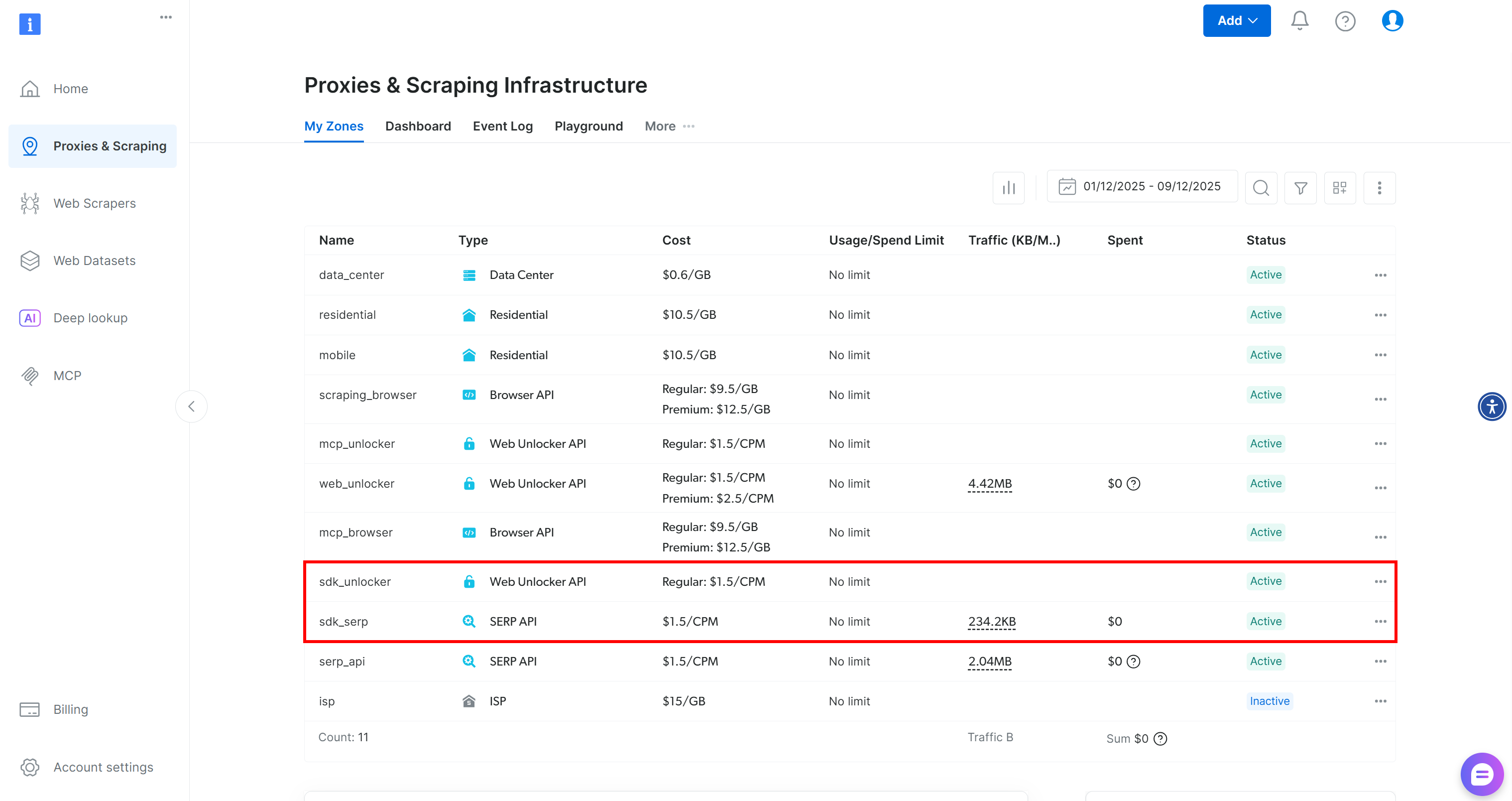
Ces deux zones sont requises par le SDK pour exposer ses plus de 60 outils.
Si vous disposez déjà de zones personnalisées, spécifiez-les comme expliqué dans la documentation:
client = BrightDataClient(
serp_zone="serp_api", # Remplacez par le nom de votre zone API SERP.
web_unlocker_zone="web_unlocker", # Remplacez par le nom de votre zone Web Unlocker API.
)Fantastique ! Vous êtes maintenant prêt à transformer les méthodes du SDK Python de Bright Data en outils Haystack.
Étape n° 2 : transformer les fonctions SDK en outils
Cette section guidée vous montrera comment convertir les méthodes API SERP et Web Unlocker du SDK Python Bright Data en outils Haystack. Après avoir appris cela, vous serez en mesure de transformer facilement toute autre méthode SDK ou appel API direct en un outil Haystack.
Commencez par transformer la méthode API SERP pour qu’elle s’exécute comme un outil compatible avec l’IA à l’aide de :
from brightdata import SearchResult
from typing import Union, List
import json
from haystack.tools import Tool
parameters = {
« type » : « object »,
« properties » : {
« query » : {
« type » : [« string », « array »],
« items » : {« type » : « string »},
« description » : « La requête de recherche ou une liste de requêtes à exécuter sur Google. »
},
"kwargs": {
"type": "object",
"description": "Paramètres optionnels supplémentaires pour la recherche (par exemple, emplacement, langue, appareil, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Traiter une liste d'instances SearchResult
output = [result.data for result in results]
else:
# Traiter un seul SearchResult
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Appelle l'API SERP de Bright Data pour effectuer des recherches sur le Web et récupérer les données SERP de Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
}
)L’extrait ci-dessus définit un outil Haystack pour l’API SERP de Bright Data. La construction de l’outil nécessite un nom, une description, un schéma JSON correspondant aux paramètres d’entrée et la fonction à convertir en outil.
À présent, client.search.google() renvoie un objet spécial. Vous avez donc besoin d’un gestionnaire de sortie personnalisé pour transformer la sortie de la fonction en une chaîne. Ce gestionnaire convertit les résultats en JSON et les mappe à la fois à une sortie de chaîne et à l’état de l’agent.
L'outil que vous venez de définir peut désormais être utilisé par des agents IA ou des pipelines pour effectuer des recherches Google et récupérer des données SERP structurées.
De même, créez un outil pour appeler la méthode Web Unlocker :
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "L'URL ou la liste d'URL à extraire."
},
"country": {
"type": "string",
"description": "Code pays facultatif pour localiser le scraping."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Traiter une liste d'instances ScrapeResult
output = [result.data for result in results]
else:
# Traiter un seul ScrapeResult
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Appelle l'API Bright Data Web Unlocker pour extraire des pages Web et récupérer leur contenu.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)Ce nouvel outil permet aux agents IA de scraper des pages web et d’accéder à leur contenu, même si elles sont protégées par des solutions anti-scraping ou anti-bot.
Génial ! Vous disposez désormais de deux outils Bright Data Haystack.
Étape n° 3 : transmettre les outils à un agent IA Haystack
Les outils ci-dessus peuvent être appelés directement, transmis à des générateurs de chat, utilisés dans des pipelines Haystack ou intégrés à des agents IA. Nous allons vous montrer l’approche de l’agent IA, mais vous pouvez facilement tester les trois autres méthodes en suivant la documentation.
Tout d’abord, un agent Haystack IA nécessite un moteur LLM. Dans cet exemple, nous utiliserons un modèle OpenAI, mais tout autre LLM pris en charge convient :
from haystack.components.generators.chat import OpenAIChatGenerator
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Remplacez par votre clé API OpenAI
# Initialisez le moteur LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini"
)Comme souligné précédemment, chargez la clé API OpenAI à partir de l’environnement dans un script de production. Ici, nous avons configuré le modèle gpt-5-mini, mais tout modèle OpenAI prenant en charge l’appel d’outils fonctionnera. D’autres générateurs pris en charge sont également compatibles.
Ensuite, utilisez le moteur LLM avec les outils pour créer un agent IA Haystack:
from haystack.components.agents import Agent
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Les outils Bright Data
)Notez comment les deux outils Bright Data sont transmis à l’entrée des outils de l’agent. Cela permet à l’agent IA, alimenté par OpenAI GPT-5 Mini, d’appeler les outils Bright Data personnalisés. Mission accomplie !
Étape n° 4 : Exécuter l’agent IA
Pour tester l’intégration Haystack + Bright Data, envisagez une tâche qui implique une recherche et du Scraping web. Par exemple, utilisez cette invite :
Identifiez les 3 dernières actualités boursières les plus importantes concernant la société Google sur différents sujets, accédez aux articles et fournissez un bref résumé pour chacun d'entre eux. Cela donne un aperçu rapide à toute personne intéressée par un investissement dans Google.
Utilisez l’extrait ci-dessous pour exécuter cette invite dans votre agent Haystack alimenté par Bright Data :
from haystack.dataclasses import ChatMessage
agent.warm_up()
prompt = """
Identifiez les 3 dernières actualités boursières les plus importantes concernant la société Google sur différents sujets, accédez aux articles et fournissez un bref résumé pour chacun d'entre eux.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])Ensuite, imprimez la réponse produite par l’agent IA, ainsi que les détails sur l’utilisation de l’outil, à l’aide de :
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Log tool outputs
for content in msg._content:
print("=== Tool Output ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant" :
# Enregistrer les messages finaux de l'assistant
for content in msg._content :
if hasattr(content, "text") :
print("=== Réponse de l'assistant ===")
print(content.text)Parfait ! Il ne reste plus qu’à voir le code complet et à l’exécuter pour vérifier qu’il fonctionne.
Étape n° 5 : code complet
Le code final pour votre agent Haystack IA connecté aux outils Bright Data est le suivant :
# pip install haystack-ai brightdata-sdk
import os
from brightdata import BrightDataClient, SearchResult, ScrapeResult
from typing import Union, List
import json
from haystack.tools import Tool
from haystack.components.generators.chat import OpenIAChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
# Définissez les variables d'environnement requises
os.environ["BRIGHTDATA_API_TOKEN"] = "<VOTRE_CLÉ_API_BRIGHT_DATA>" # Remplacez-la par votre clé API Bright Data
os.environ["OPENAI_API_KEY"] = "<VOTRE_CLÉ_API_OPENAI>" # Remplacez-la par votre clé API OpenAI
# Initialiser le client Bright Data Python SDK
client = BrightDataClient(
serp_zone="serp_api", # Remplacer par le nom de votre zone API SERP
web_unlocker_zone="web_unlocker", # Remplacer par le nom de votre zone API Web Unlocker
)
# Transformez client.search.google() du SDK Python Bright Data en un outil Haystack
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "La requête de recherche ou une liste de requêtes à exécuter sur Google."
},
"kwargs": {
"type": "object",
"description": "Paramètres optionnels supplémentaires pour la recherche (par exemple, emplacement, langue, appareil, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Traiter une liste d'instances SearchResult
output = [result.data for result in results]
else:
# Traiter un seul SearchResult
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Appelle l'API SERP de Bright Data pour effectuer des recherches sur le Web et récupérer les données SERP de Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
})
# Transforme client.scrape.generic.url() du SDK Python Bright Data en un outil Haystack.
parameters = {
« type » : « object »,
« properties » : {
« url » : {
« type » : [« string », « array »],
« items » : {« type » : « string »},
« description » : « L'URL ou la liste d'URL à scraper. »
},
"country": {
"type": "string",
"description": "Code pays facultatif pour localiser le scraping."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Traiter une liste d'instances ScrapeResult
output = [result.data for result in results]
else:
# Traiter un seul ScrapeResult
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Appelle l'API Bright Data Web Unlocker pour extraire des pages Web et récupérer leur contenu.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)
# Initialise le moteur LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Initialise un agent Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Les outils Bright Data
)
## Exécuter l'agent
agent.warm_up()
prompt = """
Identifiez les 3 dernières actualités boursières les plus importantes concernant la société Google sur différents sujets, accédez aux articles et fournissez un bref résumé pour chacun d'entre eux.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Imprimer la sortie dans un format structuré, avec des informations sur l'utilisation de l'outil
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Enregistrer les sorties de l'outil
for content in msg._content:
print("=== Sortie de l'outil ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant" :
# Enregistrer les messages finaux de l'assistant
for content in msg._content :
if hasattr(content, "text") :
print("=== Assistant Response ===")
print(content.text)Et voilà ! En seulement 130 lignes de code, vous venez de créer un agent IA capable de rechercher et d’extraire des informations sur le Web, accomplissant ainsi un large éventail de tâches et couvrant de multiples cas d’utilisation.
Étape n° 6 : tester l’intégration
Lancez votre script et vous devriez obtenir un résultat similaire à celui-ci :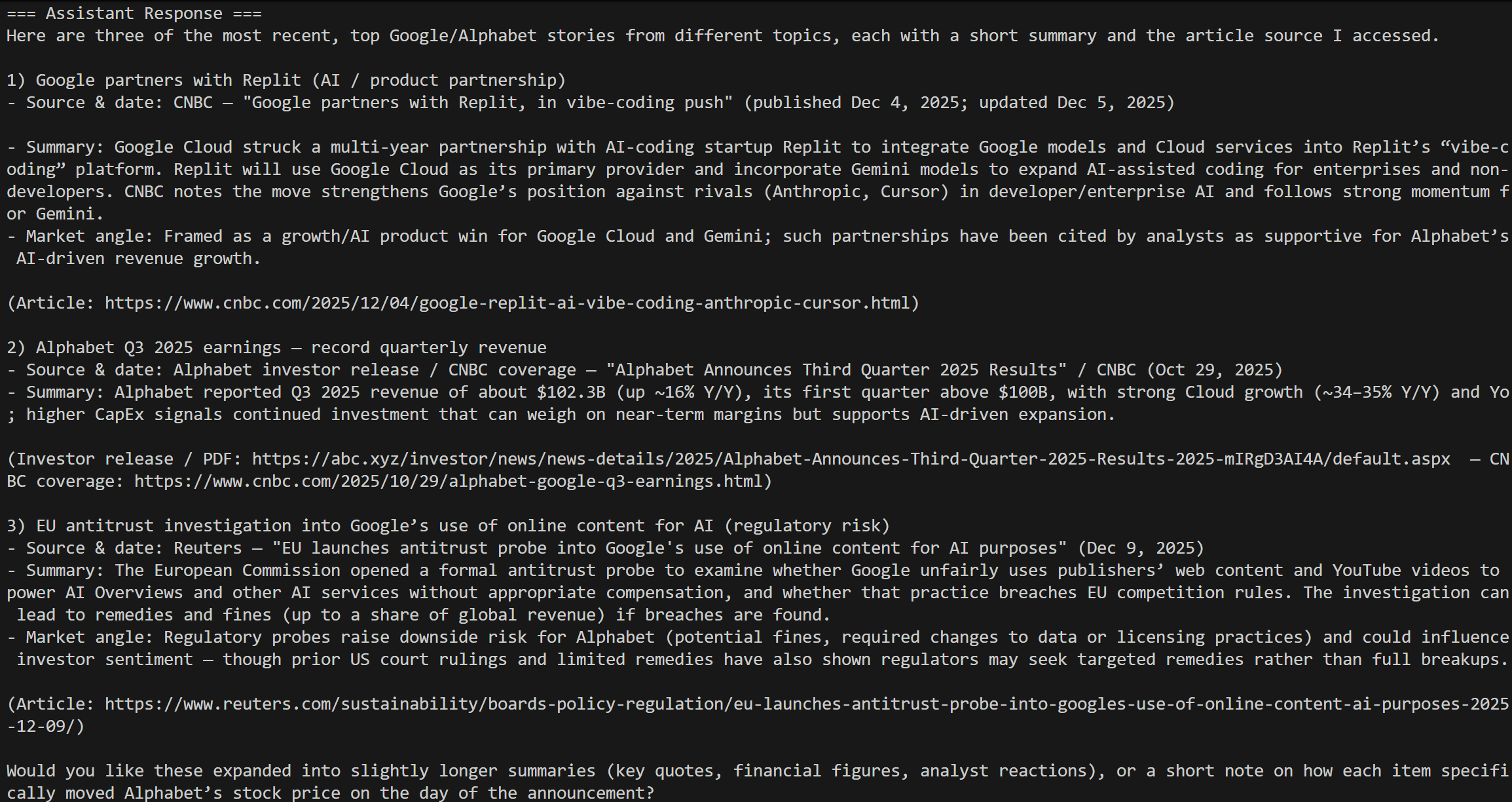
Cela correspond aux résultats de la requête « actualités boursières Google » d’aujourd’hui, exactement comme prévu !
Notez qu’un agent IA standard ne peut pas accomplir cela seul. Les LLM classiques n’ont pas d’accès direct au Web et aux moteurs de recherche en temps réel sans outils externes. Même les outils intégrés sont généralement limités, lents et ne peuvent pas s’adapter pour accéder à n’importe quel site Web comme le fait Bright Data.
Les journaux contiennent tous les détails des appels API SERP :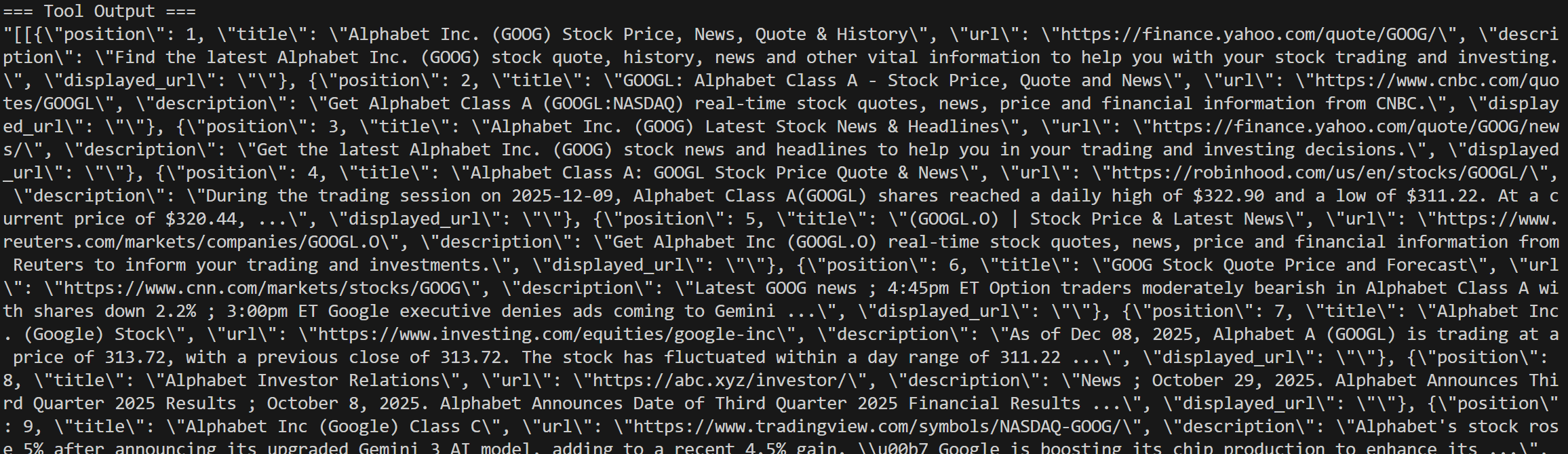
Vous verrez également les appels Web Unlocker pour les articles d’actualité sélectionnés dans les résultats de recherche Google :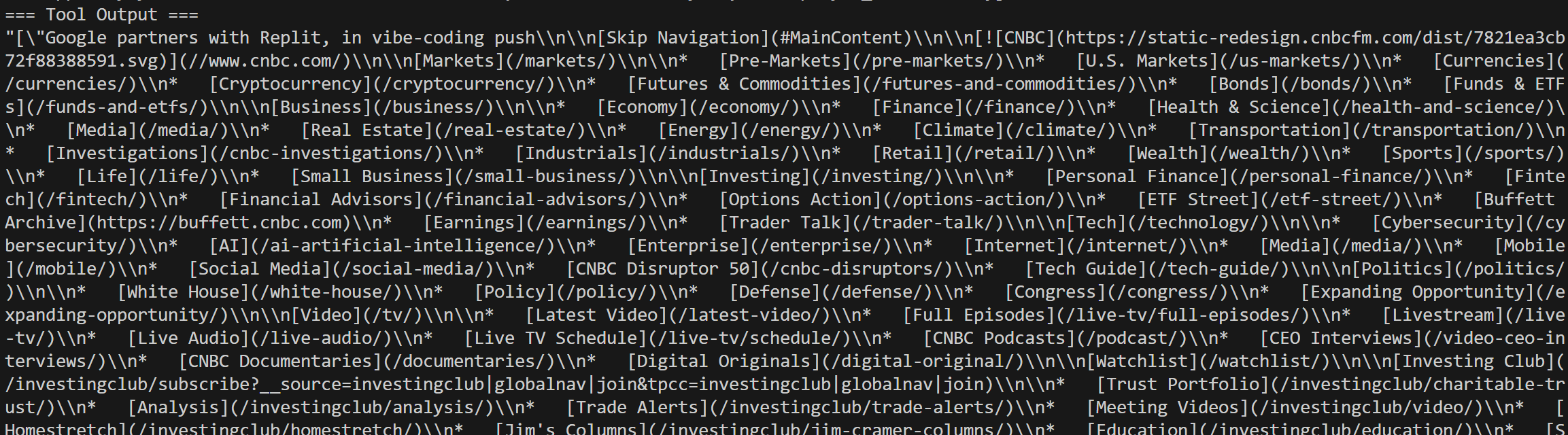
Et voilà ! Vous disposez désormais d’un agent Haystack IA entièrement intégré aux outils Bright Data.
Intégration de Bright Data Web MCP dans Haystack
Une autre façon de connecter Haystack à Bright Data est d’utiliser Web MCP. Ce serveur MCP expose bon nombre des fonctionnalités les plus puissantes de Bright Data sous la forme d’une vaste collection d’outils prêts pour l’IA.
Web MCP comprend plus de 60 outils basés sur l’infrastructure d’automatisation web et de collecte de données de Bright Data. Même avec la version gratuite, vous avez accès à deux outils très utiles :
| Outil | Description |
|---|---|
search_engine |
Récupérez les résultats de Google, Bing ou Yandex au format JSON ou Markdown. |
scrape_as_markdown |
Récupérez n’importe quelle page web au format Markdown propre tout en contournant les mesures anti-bot. |
Ensuite, avec le niveau premium (mode Pro) activé, Web MCP débloque l’extraction de données structurées pour les principales plateformes, telles qu’Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps et bien d’autres. De plus, il est livré avec des outils pour automatiser les actions du navigateur.
Voyons comment utiliser Web MCP de Bright Data dans Haystack !
Prérequis
Le package open source Web MCP est basé sur Node.js. Cela signifie que si vous souhaitez exécuter Web MCP localement et y connecter votre agent IA Haystack, vous devez installer Node.js sur votre machine.
Vous pouvez également vous connecter à l’instance Web MCP à distance, ce qui ne nécessite aucune configuration locale.
Étape n° 1 : installer l’intégration MCP-Haystack
Dans votre projet Python, exécutez la commande suivante pour installer l’intégration MCP-Haystack :
pip install mcp-haystackCe package est nécessaire pour accéder aux classes qui vous permettent de vous connecter à un serveur MCP local ou distant.
Étape n° 2 : tester Web MCP localement
Avant de connecter Haystack au Web MCP de Bright Data, assurez-vous que votre machine locale peut exécuter le serveur MCP localement.
Remarque: Web MCP est également disponible en tant que serveur distant (via SSE et Streamable HTTP). Cette option est mieux adaptée aux scénarios de niveau entreprise.
Commencez par créer un compte Bright Data. Si vous en avez déjà un, connectez-vous simplement. Pour une configuration rapide, suivez les instructions de la section «MCP »de votre tableau de bord :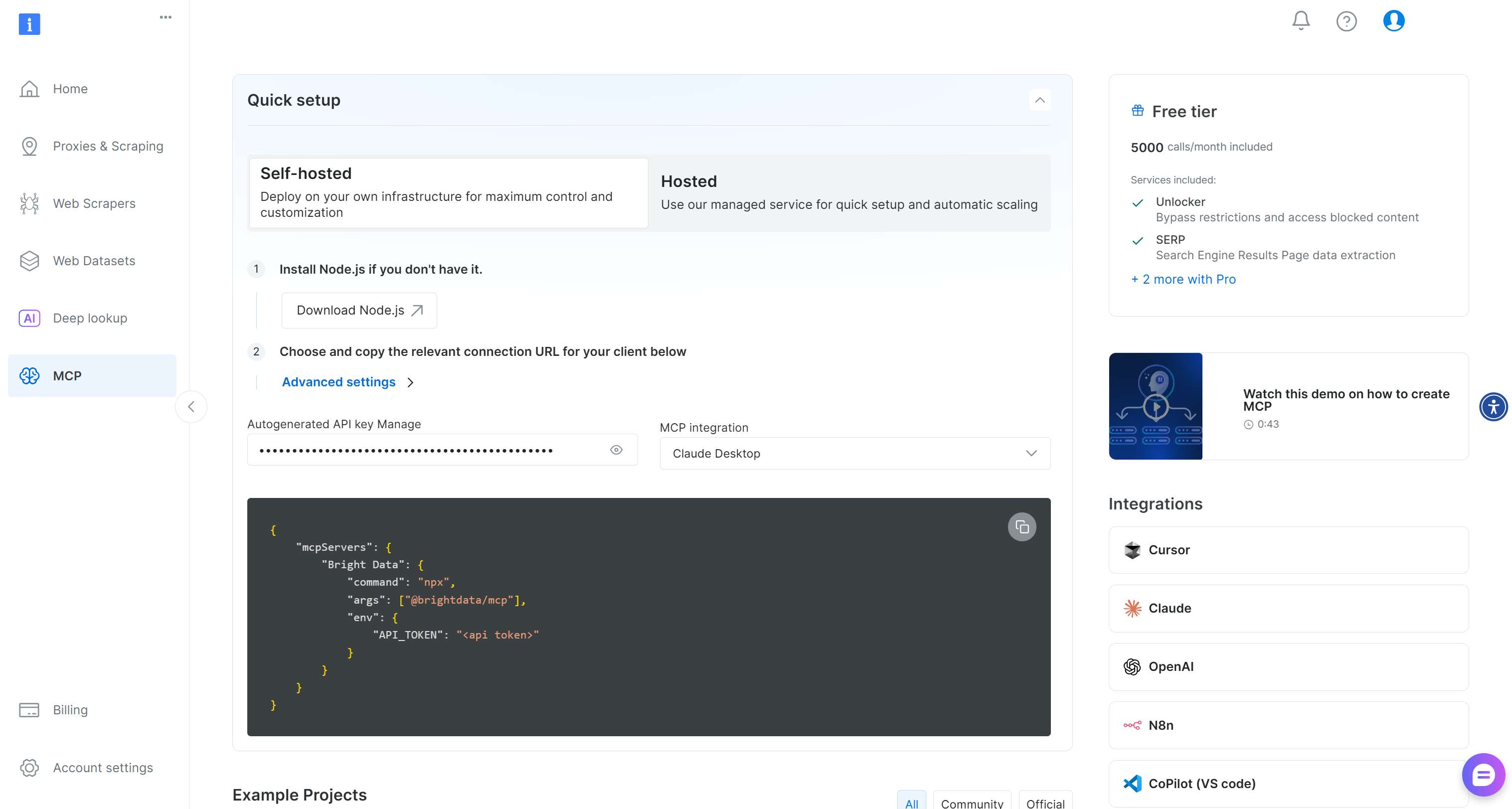
Sinon, pour obtenir des conseils supplémentaires, reportez-vous aux instructions ci-dessous.
Commencez par générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin rapidement pour authentifier votre instance Web MCP locale.
Ensuite, installez Web MCP globalement sur votre machine via le package @brightdata/mcp:
npm install -g @brightdata/mcpVérifiez que le serveur MCP fonctionne en exécutant :
API_TOKEN="<VOTRE_API_BRIGHT_DATA>" npx -y @brightdata/mcpOu, de manière équivalente, dans PowerShell :
$Env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; npx -y @brightdata/mcpRemplacez l’espace réservé <YOUR_BRIGHT_DATA_API> par votre clé API Bright Data. Les deux commandes (équivalentes) définissent la variable d’environnement API_TOKEN requise et lancent le serveur Web MCP.
Si l’opération réussit, vous devriez voir des journaux similaires à ceux-ci :
Lors du premier lancement, Web MCP crée deux zones dans votre compte Bright Data :
mcp_unlocker: une zone pour Web Unlocker.mcp_browser: une zone pour Browser API.
Ces deux services sont requis par Web MCP pour alimenter ses plus de 60 outils.
Pour vérifier que les zones ont bien été créées, accédez à la page «Proxies & Infrastructure de scraping »(Proxys et infrastructure de scraping) de votre tableau de bord. Vous devriez voir les deux zones répertoriées dans le tableau :
Gardez à l’esprit que la version gratuite de Web MCP ne vous donne accès qu’aux outils search_engine et scrape_as_markdown.
Pour débloquer tous les outils, activez le mode Pro en définissant la variable d’environnement PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, sous Windows :
$Env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpLe mode Pro débloque plus de 60 outils, mais il n’est pas inclus dans l’offre gratuite et peut entraîner des frais supplémentaires.
Bravo ! Vous avez maintenant confirmé que le serveur Web MCP fonctionne correctement sur votre machine. Arrêtez le processus, car vous allez configurer Haystack pour lancer le serveur localement et vous y connecter.
Étape n° 3 : se connecter à Web MCP dans Haystack
Utilisez les lignes de code suivantes pour vous connecter à Web MCP :
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Remplacez-le par votre clé API Bright Data
# Configuration pour se connecter au serveur Web MCP via STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Activer les outils Pro (facultatif)
}
)L’objet StdioServerInfo ci-dessus reflète la commande npx que vous avez testée précédemment, mais l’intègre dans un format utilisable par Haystack. Il comprend également les variables d’environnement nécessaires à la configuration du serveur Web MCP :
API_TOKEN: obligatoire. Définissez cette variable sur la clé API Bright Data que vous avez générée précédemment.PRO_MODE: facultatif. Supprimez-le si vous souhaitez rester sur le niveau gratuit et accéder uniquement aux outilssearch_engineetscrape_as_markdown.
Ensuite, accédez à tous les outils exposés par Web MCP avec :
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180 # 3 minutes
)Vérifiez que l’intégration fonctionne en chargeant tous les outils et en affichant leurs informations :
web_mcp_toolset.warm_up()
for tool in web_mcp_toolset.tools:
print(f"Name: {tool.name}")
print(f"Description: {tool.name}n")Si vous utilisez le mode Pro, vous devriez voir les 60 outils disponibles :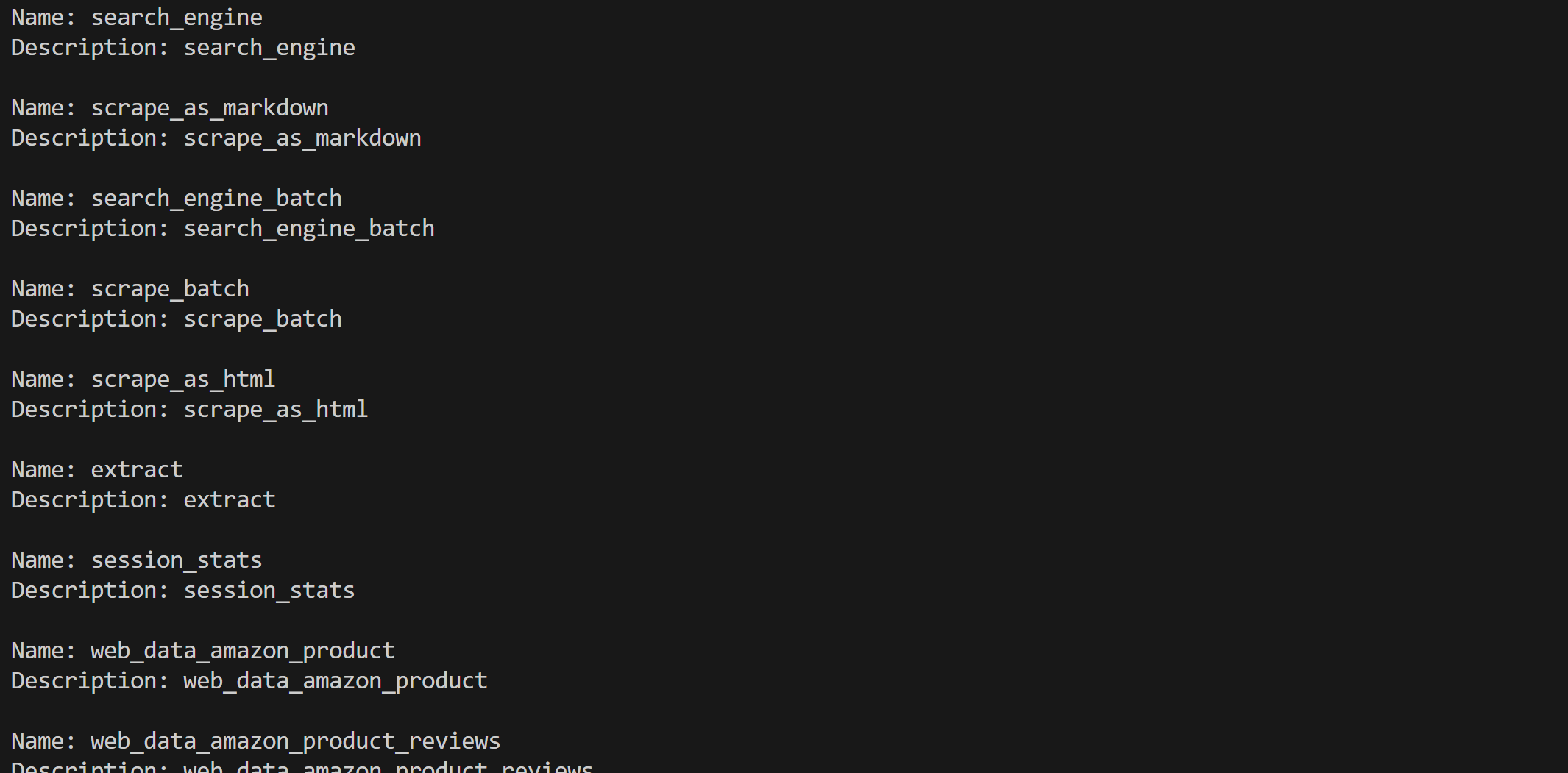
Et voilà ! L’intégration Bright Data Web MCP dans Haystack fonctionne parfaitement.
Étape n° 4 : tester l’intégration
Une fois tous les outils configurés, utilisez-les dans un agent IA (comme démontré précédemment) ou dans un pipeline Haystack. Par exemple, supposons que vous souhaitiez qu’un agent IA traite cette invite :
Renvoyer un rapport Markdown contenant des informations utiles à partir de l'URL suivante de la société Crunchbase :
« https://www.crunchbase.com/organization/apple »Il s’agit d’un exemple de tâche qui nécessite des outils Web MCP.
Exécutez-la dans un agent avec :
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Les outils Bright Data Web MCP
)
## Exécutez l'agent
agent.warm_up()
prompt = """
Renvoyez un rapport Markdown contenant des informations utiles provenant de l'URL suivante de la société Crunchbase :
« https://www.crunchbase.com/organization/apple »
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])Le résultat serait :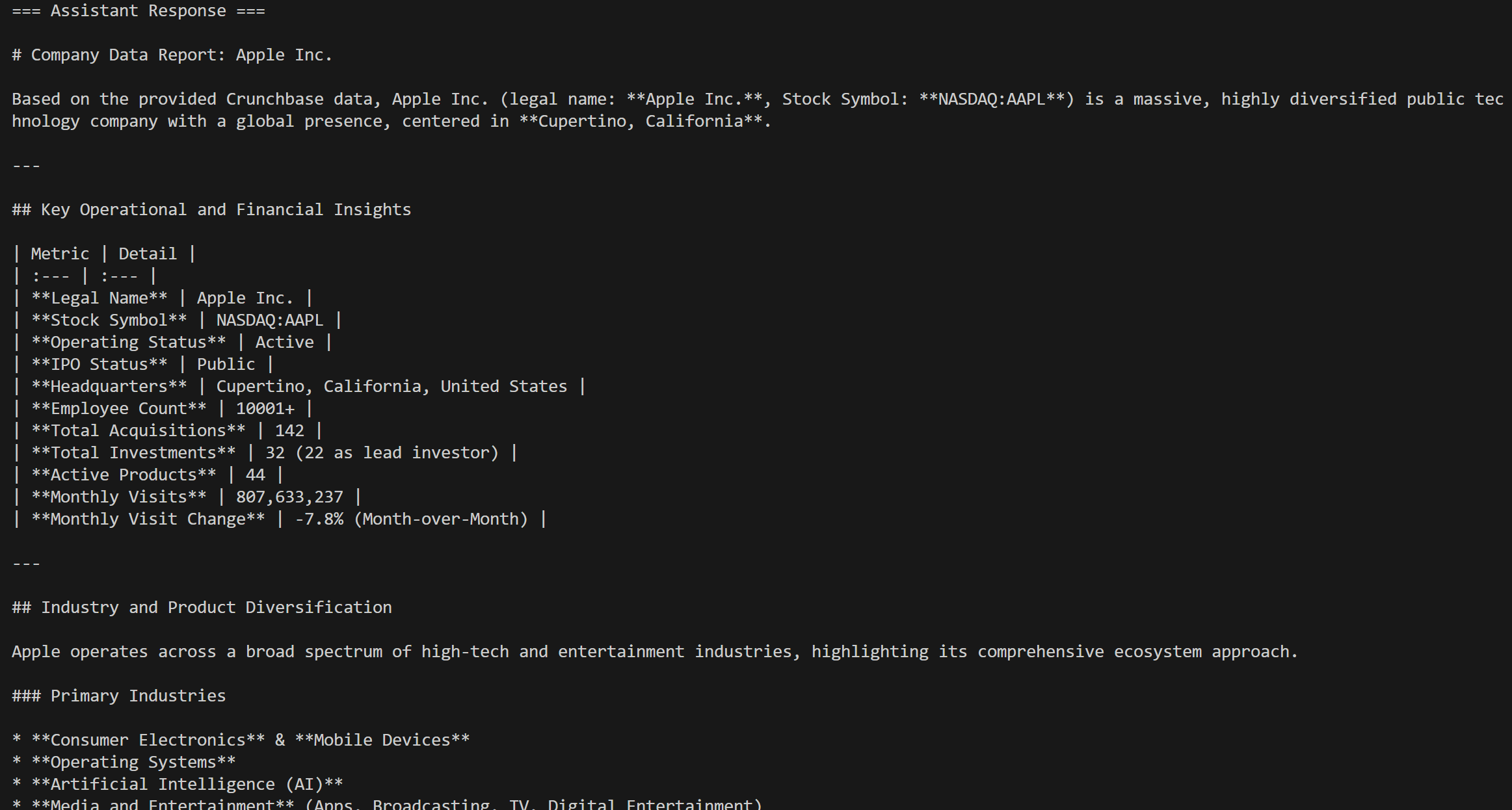
L’outil appelé sera l’outil Pro web_data_crunchbase_company: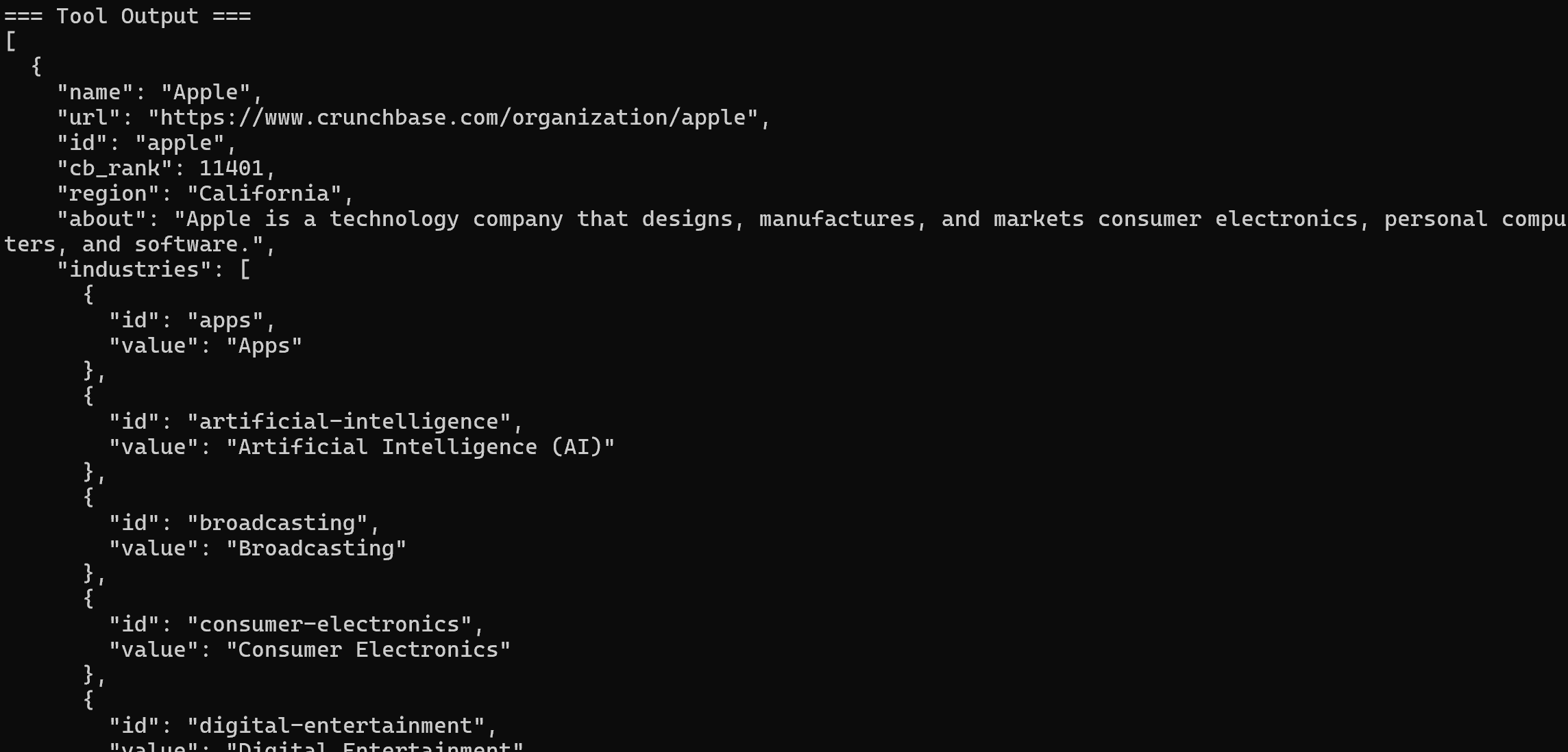
En coulisses, cet outil s’appuie sur le Bright Data Crunchbase Scraper pour extraire des informations structurées de la page Crunchbase spécifiée.
Le scraping de Crunchbase est sans aucun doute une tâche qu’un LLM classique ne peut pas gérer seul ! Cela prouve la puissance de l’intégration Web MCP dans Haystack, qui prend en charge une longue liste de cas d’utilisation.
Étape n° 5 : code complet
Le code complet pour connecter Bright Data Web MCP dans Haystack est le suivant :
# pip install haystack-ai mcp-haystack
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
import os
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
import json
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Remplacez-le par votre clé API Bright Data.
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Remplacez-le par votre clé API Bright Data.
# Configuration pour se connecter au serveur Web MCP via STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Activer les outils Pro (facultatif)
})
# Chargement des outils MCP disponibles exposés par le serveur Web MCP
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180, # 3 minutes
tool_names=["web_data_crunchbase_company"]
)
# Initialiser le moteur LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Initialiser un agent Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Les outils Bright Data Web MCP
)
## Exécuter l'agent
agent.warm_up()
prompt = """
Renvoyer un rapport Markdown contenant des informations utiles à partir de l'URL suivante de la société Crunchbase :
« https://www.crunchbase.com/organization/apple »
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Imprimer la sortie dans un format structuré, avec des informations sur l'utilisation de l'outil
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Enregistrer les sorties de l'outil
for content in msg._content:
print("=== Sortie de l'outil ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant" :
# Enregistrer les messages finaux de l'assistant
for content in msg._content :
if hasattr(content, "text") :
print("=== Réponse de l'assistant ===")
print(content.text)Conclusion
Dans ce guide, vous avez appris à tirer parti de l’intégration de Bright Data dans Haystack, que ce soit via des outils personnalisés ou via MCP.
Cette configuration permet aux modèles d’IA des agents et des pipelines Haystack d’effectuer des recherches sur le Web, d’extraire des données structurées, d’accéder à des flux de données Web en direct et d’automatiser les interactions Web. Tout cela est rendu possible grâce à la suite complète de services de l’écosystème Bright Data pour l’IA.
Créez gratuitement un compte Bright Data et commencez à explorer nos puissants outils de données web prêts pour l’IA !






