Guide étape par étape pour créer un pipeline de scraping sans serveur sur Google Cloud à l’aide de Cloud Run, Firestore, BigQuery, Workflows et Cloud Scheduler.
Dans cet article, vous apprendrez :
- Pourquoi une architecture sans serveur fonctionne bien pour les pipelines de Scraping web.
- Comment configurer l’infrastructure Google Cloud requise à partir de zéro.
- Comment déployer un service de scraping privé et un service API public sur Cloud Run.
- Comment orchestrer les exécutions de scraping avec Cloud Workflows et les automatiser avec Cloud Scheduler.
- Comment stocker et interroger les données scrapées à l’aide de Firestore et BigQuery.
- Comment vérifier que l’ensemble de votre pipeline fonctionne de bout en bout.
C’est parti !
Pourquoi créer un pipeline de scraping sans serveur ?
La plupart des tutoriels sur le scraping s’arrêtent au script. Vous obtenez du code HTML, vous analysez peut-être quelques champs, et c’est tout. Mais lorsqu’il s’agit d’exécuter des Scrapers en production, vous devez répondre à des questions plus complexes : où vont les données ? Comment les exécuter selon un calendrier ? Comment interroger les résultats ultérieurement ? Comment réduire les coûts lorsque le Scraper ne fonctionne pas ?
C’est là que le sans serveur entre en jeu. Google Cloud Run ne vous facture que lorsque vos services traitent des requêtes. Il n’y a pas de serveurs à gérer, pas de calculs inactifs qui coûtent de l’argent pendant la nuit. Associez cela à Firestore pour le suivi des tâches, BigQuery pour l’analyse et Cloud Workflows pour l’orchestration, et vous obtenez une architecture de pipeline de données qui s’adapte à zéro lorsqu’elle est inactive et se met en marche à la demande.
À la fin de ce guide, vous disposerez :
- Un
service de scraperprivé sur Cloud Run qui effectue le scraping proprement dit. - Un
service APIpublic sur Cloud Run qui expose vos données. - Des collections Firestore qui suivent l’état et les résultats des tâches.
- Une table BigQuery que vous pouvez interroger à des fins d’analyse.
- Un Cloud Workflow qui orchestre l’ensemble du processus de scraping.
- Une tâche Cloud Scheduler qui le déclenche sur un cron.
Comprendre l’architecture
Avant de commencer à exécuter des commandes, il est utile de voir comment tous les éléments s’articulent entre eux. Nous avons passé beaucoup de temps à déterminer la bonne architecture lorsque nous avons créé ce système, alors laissez-nous vous expliquer comment il fonctionne.
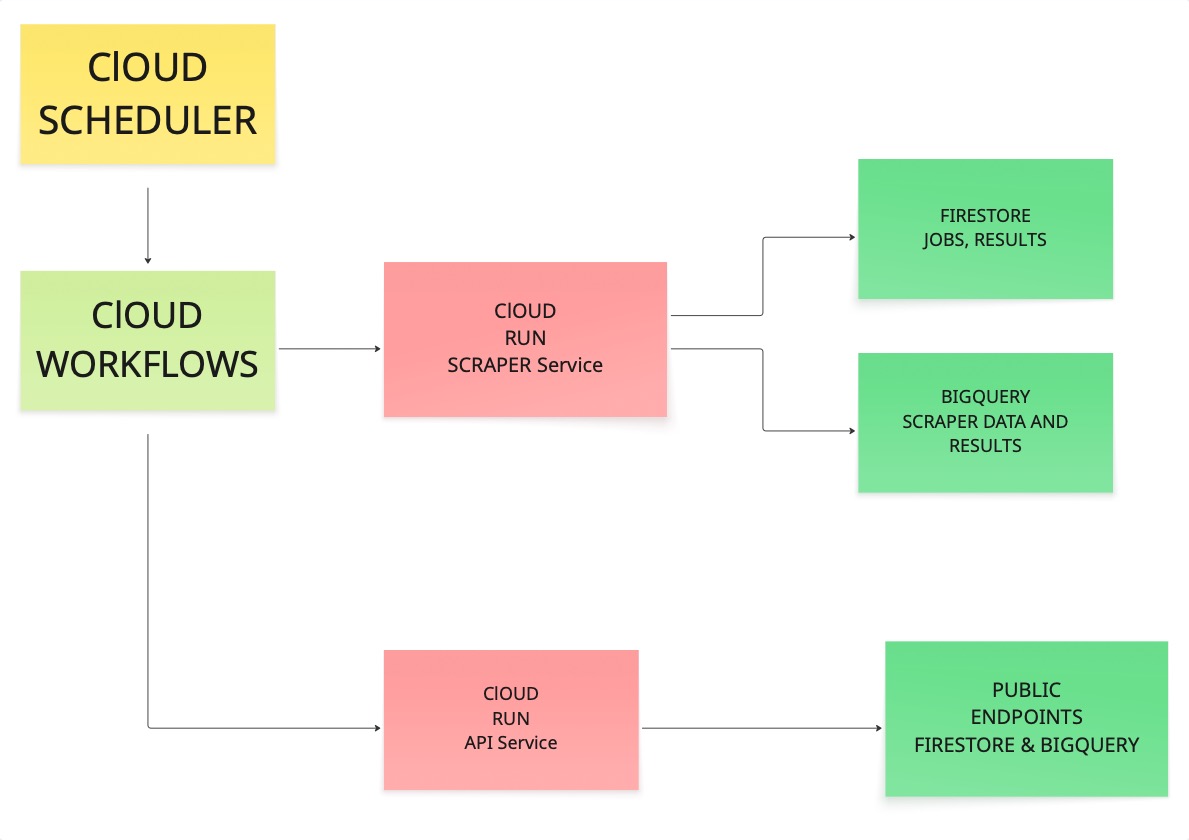
Le planificateur déclenche un workflow. Le workflow appelle le Scraper. Le Scraper visite les URL, extrait le contenu et écrit les résultats à la fois dans Firestore et BigQuery. Ensuite, le service API lit ces magasins et expose les données via des points de terminaison publics.
Si chaque maillon de cette chaîne fonctionne, vous disposez d’un outil fiable en production.
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Un compte Google.
- Un projet GCP avec la facturation activée (les coûts seront minimes, mais la facturation doit être active).
- Node.js 18 ou version supérieure.
- L’interface CLI
gcloudinstallée sur votre machine.
Effectuez une vérification rapide :
node --version
npm --version
gcloud --versionSi les trois affichent leur numéro de version, vous êtes prêt à continuer.
Configuration de votre projet Google Cloud
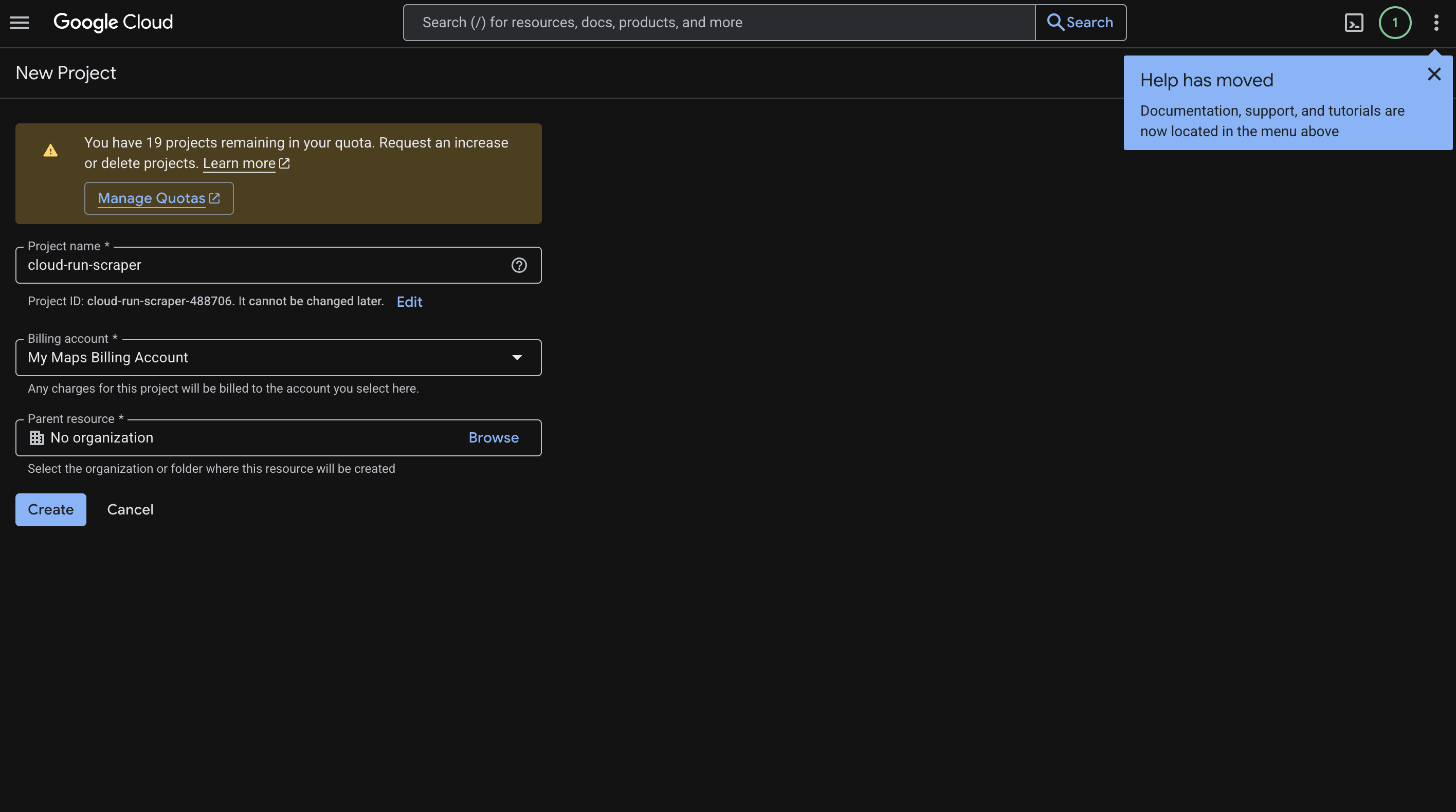
Rendez-vous dans la console Cloud et créez un nouveau projet. Nous avons appelé le nôtre « cloud-run-scraper », mais vous pouvez lui donner le nom qui vous convient le mieux.
Voici la marche à suivre :
- Saisissez le nom de votre projet.
- Cliquez sur Créer.
- Copiez l’ID de projet généré (par exemple,
cloud-run-scraper-123456). Vous en aurez besoin tout au long du guide. - Accédez à Facturation et associez un compte de facturation au projet.
Voici à quoi ressemble cet écran :
Configuration de votre shell
Nous vous recommandons de définir quelques variables d’environnement à l’avance afin de ne pas avoir à copier-coller les identifiants de projet partout. Cela permet de garder vos commandes propres et réutilisables :
export PROJECT_ID="VOTRE_ID_DE_PROJET"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"Ensuite, pointez gcloud vers votre projet :
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"Et authentifiez-vous (cela ouvrira votre navigateur) :
gcloud auth login
gcloud auth application-default loginActivation des API requises
L’une des choses qui déconcerte les utilisateurs de Google Cloud, c’est que rien ne fonctionne tant que vous n’avez pas explicitement activé les API dont vous avez besoin. Considérez cela comme si vous actionniez des disjoncteurs. Exécutez cette commande une seule fois et le tour est joué :
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.comVous pouvez vérifier qu’ils sont tous activés à l’aide de la commande suivante :
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"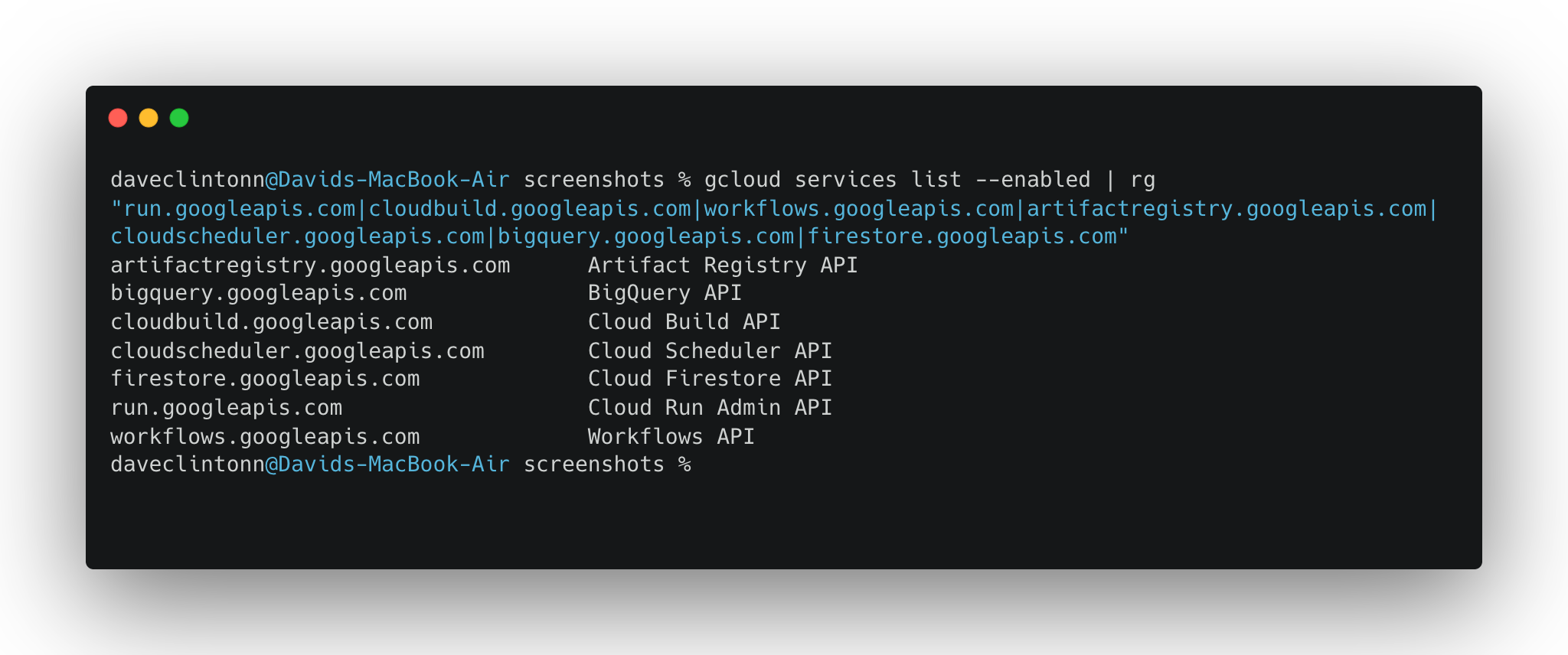
Configuration de Firestore
Nous avons besoin de Firestore en mode natif pour stocker les données de suivi des tâches et récupérer les résultats :
gcloud firestore databases create --location="$REGION" --type=firestore-nativeSi vous avez déjà configuré Firestore dans ce projet, vous pouvez ignorer cette étape. Une erreur indiquant que la base de données existe déjà s’affichera.
Création du registre d’artefacts
Le registre d’artefacts est l’endroit où vos images Docker seront stockées. Considérez-le comme un registre de conteneurs privé sur GCP :
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="Images Docker pour cloud-run-Scraper"Indiquez ensuite à Docker comment s’authentifier auprès de celui-ci :
gcloud auth configure-docker "$REGION-docker.pkg.dev"Configuration de BigQuery
Nous allons maintenant créer l’ensemble de données et la table BigQuery où les données extraites seront stockées. C’est ce qui rend l’ensemble du pipeline utile : un flux ETL bien structuré vous permet d’exécuter des requêtes SQL sur toutes vos données extraites afin de mettre en évidence des tendances, de filtrer par source ou de créer des tableaux de bord.
Créez l’ensemble de données :
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"Créez ensuite la table avec le schéma utilisé par le Scraper :
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRINGVérifiez rapidement que cela a fonctionné :
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"Obtenir les autorisations IAM appropriées
Cette partie n’est pas la plus passionnante, mais elle est essentielle. Vos services Cloud Run ont besoin d’autorisations pour communiquer avec Firestore, BigQuery et entre eux. Sans ces liaisons IAM, vous obtiendrez des erreurs 403 mystérieuses sans explication claire.
Commencez par récupérer votre compte de service de calcul :
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"Ensuite, attribuez-lui les rôles nécessaires :
gcloud projects add-iam-policy-binding « $PROJECT_ID »
--member=« serviceAccount:${COMPUTE_SA} »
--role=« roles/datastore.user »
gcloud projects add-iam-policy-binding « $PROJECT_ID »
--member=« serviceAccount:${COMPUTE_SA} »
--role=« roles/bigquery.dataEditor »
gcloud projects add-iam-policy-binding « $PROJECT_ID »
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"Cela représente cinq liaisons de rôles. Chacune d’entre elles permet au compte de service d’effectuer une tâche spécifique : lire/écrire dans Firestore, insérer dans BigQuery, invoquer des services Cloud Run et déclencher des workflows.
Installation des dépendances
À partir de la racine du référentiel, installez les dépendances pour les deux services :
npm --prefix scraper-service install
npm --prefix api-service installDéploiement du service Scraper
Il s’agit du moteur de l’ensemble du pipeline. C’est le service qui visite les URL, extrait le contenu et écrit les résultats dans Firestore et BigQuery. Si vous souhaitez gérer des scénarios anti-bot plus complexes dans votre Scraper, des outils tels que le Navigateur de scraping de Bright Data méritent d’être explorés pour l’automatisation à grande échelle des navigateurs basés sur le cloud.
Nous le déployons en tant que service privé. Notez le drapeau --no-allow-unauthenticated. Seules les requêtes authentifiées, comme celles provenant de notre flux de travail, peuvent l’appeler :
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=productionRécupérez l’URL une fois qu’elle est déployée :
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"Enregistrez cette URL. Vous en aurez besoin pour la configuration du workflow.
Déploiement du service API
Le service API est la partie publique du pipeline. Il lit depuis Firestore et BigQuery et expose des points de terminaison afin que vous ou votre interface utilisateur puissiez accéder aux données récupérées :
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionObtenir l’URL :
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"Tester vos services déployés
Voici maintenant la partie la plus intéressante : accéder à vos services en ligne et vérifier que tout fonctionne correctement. N’oubliez pas que les défis courants liés au Scraping web, tels que le blocage d’IP et la limitation de débit, peuvent affecter votre Scraper même dans une configuration sans serveur. Il est donc utile de prévoir une stratégie pour y faire face dès le départ.
Essayez ces commandes sur votre service API :
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"Pour le Scraper, vous devez passer un jeton d’authentification, car il s’agit d’un service privé :
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"Vous pouvez également transmettre des sélecteurs CSS personnalisés si vous souhaitez cibler des éléments spécifiques d’une page :
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H « Content-Type : application/json »
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
« $SCRAPER_URL/scrape »Configuration du flux de travail
Le workflow est ce qui relie le Scraper à un calendrier. Il s’agit d’un fichier YAML qui indique à Cloud Workflows d’appeler le Scraper pour chaque URL de la liste.
Ouvrez workflows/scrape-pipeline.yaml et définissez scraper_url sur l’URL que vous avez obtenue lors de l’étape de déploiement du Scraper.
Puis déployez-le :
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"Création de la tâche du planificateur
C’est à ce stade que le pipeline devient entièrement automatique. Nous configurons une tâche cron qui exécute le workflow tous les jours à 6 h 00 UTC :
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope « https://www.googleapis.com/auth/cloud-platform »
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Si la tâche existe déjà et que vous souhaitez simplement la mettre à jour :
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope « https://www.googleapis.com/auth/cloud-platform »
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Exécution de votre premier test complet
N’attendez pas le planificateur. Déclenchez le workflow manuellement et observez l’exécution de l’ensemble du pipeline :
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'Vous pouvez surveiller l’exécution à l’aide de :
gcloud workflows executions list scrape-pipeline --location "$REGION"Patientez une minute ou deux. Une fois que l’exécution affiche SUCCEEDED, vos données devraient être transférées vers Firestore et BigQuery.
Vérification des données
Vérifions maintenant que les données ont bien été transférées là où elles devaient l’être.
Vérifiez le nombre de lignes dans BigQuery :
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"Consultez les derniers résultats récupérés :
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"Vérifiez Firestore dans la console. Vous devriez voir deux collections : jobs et results.
Appuyez ensuite sur l’API pour confirmer qu’elle peut tout lire :
curl -s "$API_URL/jobs?limit=1"Récupérez un jobId dans la réponse et approfondissez votre recherche :
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"Si toutes ces opérations renvoient des données, votre pipeline fonctionne de bout en bout.
CI/CD avec Cloud Build
Le dépôt comprend un fichier cloudbuild.yaml qui gère la création et le déploiement des deux services en une seule fois. Lorsque vous souhaitez envoyer des modifications, il vous suffit d’exécuter :
gcloud builds submit --config cloudbuild.yaml .Cette commande unique permettra de créer les deux images Docker, de les envoyer vers Artifact Registry et de déployer les deux services Cloud Run. Si vous souhaitez aller au-delà d’un pipeline unique, consultez cette présentation des meilleurs outils de Scraping web pour découvrir comment différentes solutions peuvent compléter une configuration cloud comme celle-ci.
Liste de contrôle finale
Avant de considérer que vous avez terminé, effectuez les étapes de vérification suivantes :
gcloud run services list --region us-central1devrait afficher les deux services.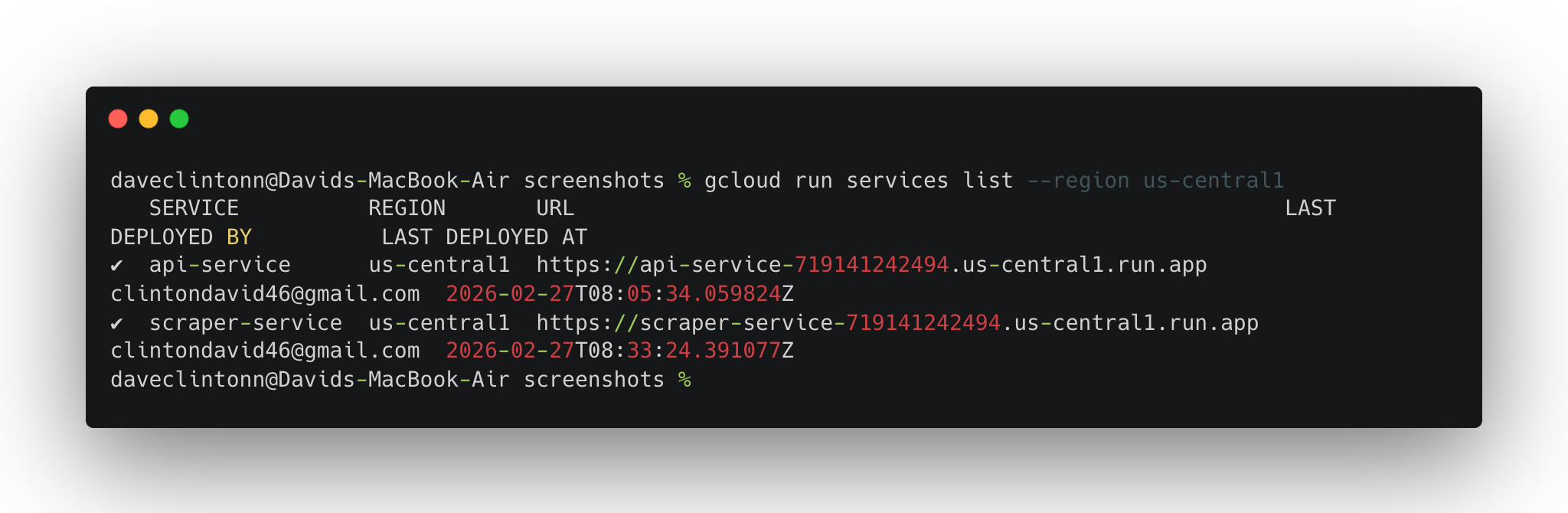
gcloud workflows describe scrape-pipeline --location us-central1devrait renvoyer les détails du workflow.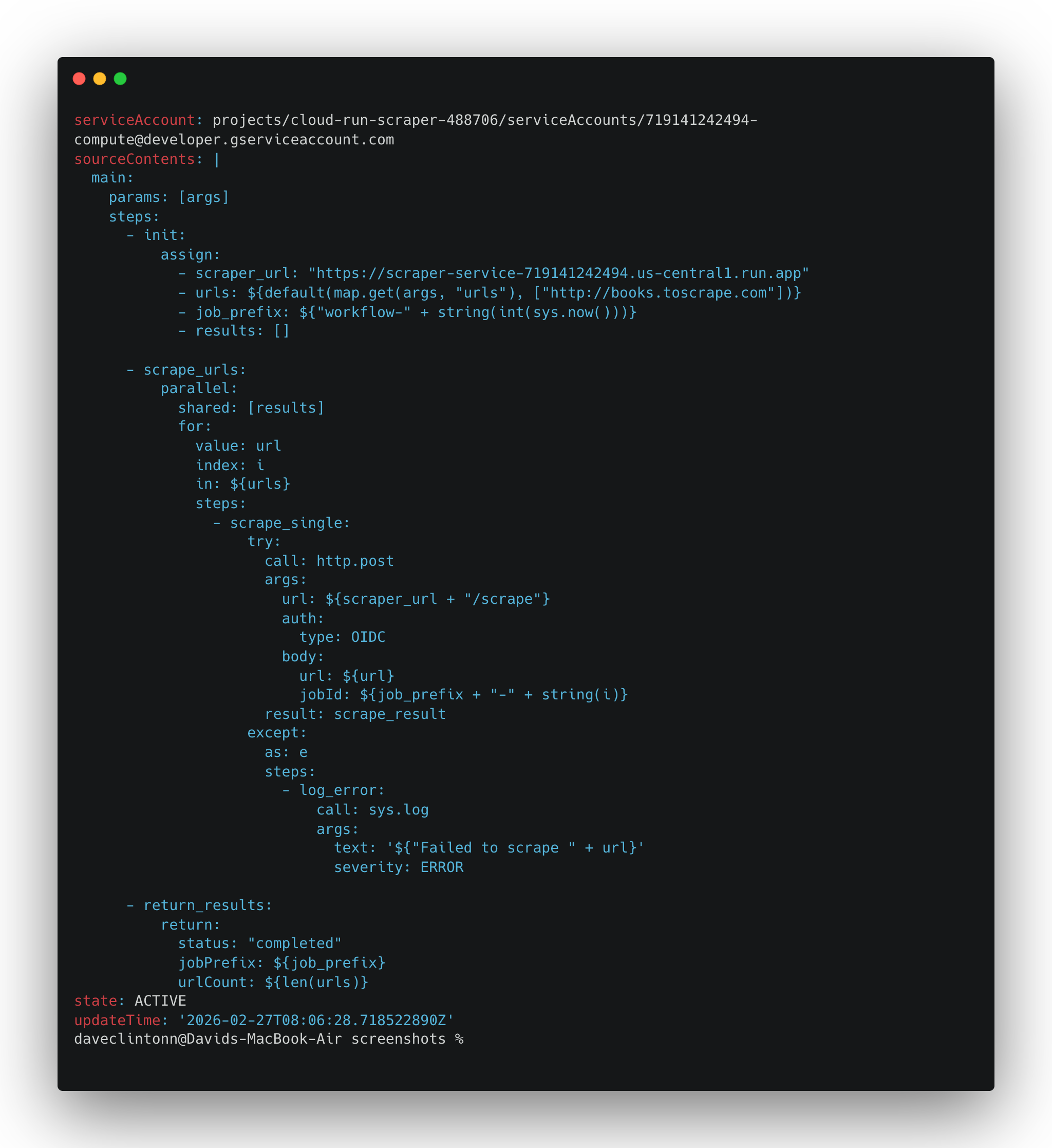
gcloud scheduler jobs list --location us-central1devrait afficher la tâche du planificateur.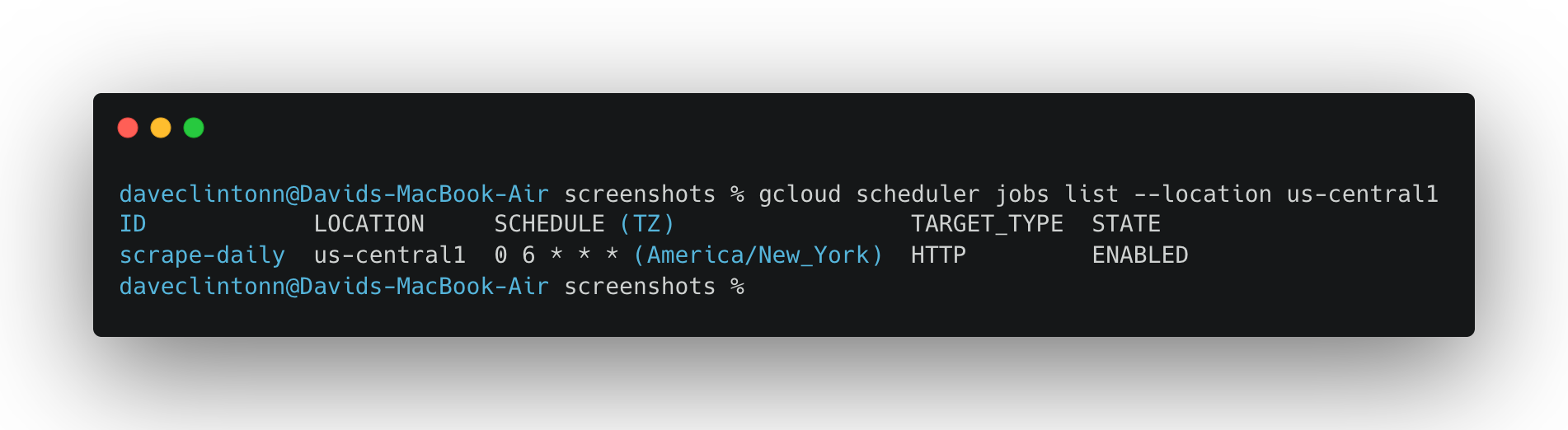
- Firestore doit contenir les collections
de tâchesetde résultats. - La table BigQuery doit contenir des lignes.
- Le point de terminaison API
/jobsdevrait renvoyer les enregistrements réels.
Si les six points sont vérifiés, vous n’êtes plus en mode démo. Vous disposez d’un véritable pipeline qui effectue le scraping selon le calendrier prévu, stocke les données à deux endroits et les fournit via une API publique.
Conclusion
Dans ce guide, nous avons décrit la création d’un pipeline complet de Scraping web sans serveur sur Google Cloud. Nous avons abordé la configuration de l’infrastructure, le déploiement de deux services Cloud Run, l’orchestration des opérations de scraping avec Cloud Workflows et l’automatisation de l’ensemble avec Cloud Scheduler.
Si vous préférez une approche gérée plutôt que de maintenir votre propre infrastructure, vous pouvez explorer les Jeux de données pré-collectés de Bright Data ou le Scraper Studio pour transformer n’importe quel site web en un pipeline de données prêt à l’emploi. Vous pouvez également lire notre guide sur le scraping sans serveur avec Scrapy et AWS pour voir à quoi ressemble une architecture similaire chez un autre fournisseur de cloud. Clonez le projet, remplacez les URL cibles par les vôtres, et vous disposerez d’un pipeline de scraping opérationnel.