

Dans ce guide, vous apprendrez :
- Ce qu’est GitHub Copilot CLI et ce qu’il offre.
- Pourquoi l’étendre avec un accès web le fait passer au niveau supérieur.
- Comment Bright Data permet l’intégration de GitHub Copilot CLI pour le Scraping web, la recherche, la découverte et l’automatisation du navigateur.
- Comment connecter Bright Data à GitHub Copilot CLI via MCP.
- Comment équiper Copilot CLI avec les connaissances Bright Data via les Agent Skills.
- Ce que l’intégration GitHub Copilot CLI + Bright Data permet, avec un exemple complet.
Plongeons-y !
Qu’est-ce que GitHub Copilot CLI ?
GitHub Copilot CLI est un agent de codage open-source propulsé par l’IA qui intègre Copilot directement dans votre terminal, permettant le codage en langage naturel, le débogage et les interactions GitHub sans quitter la ligne de commande.
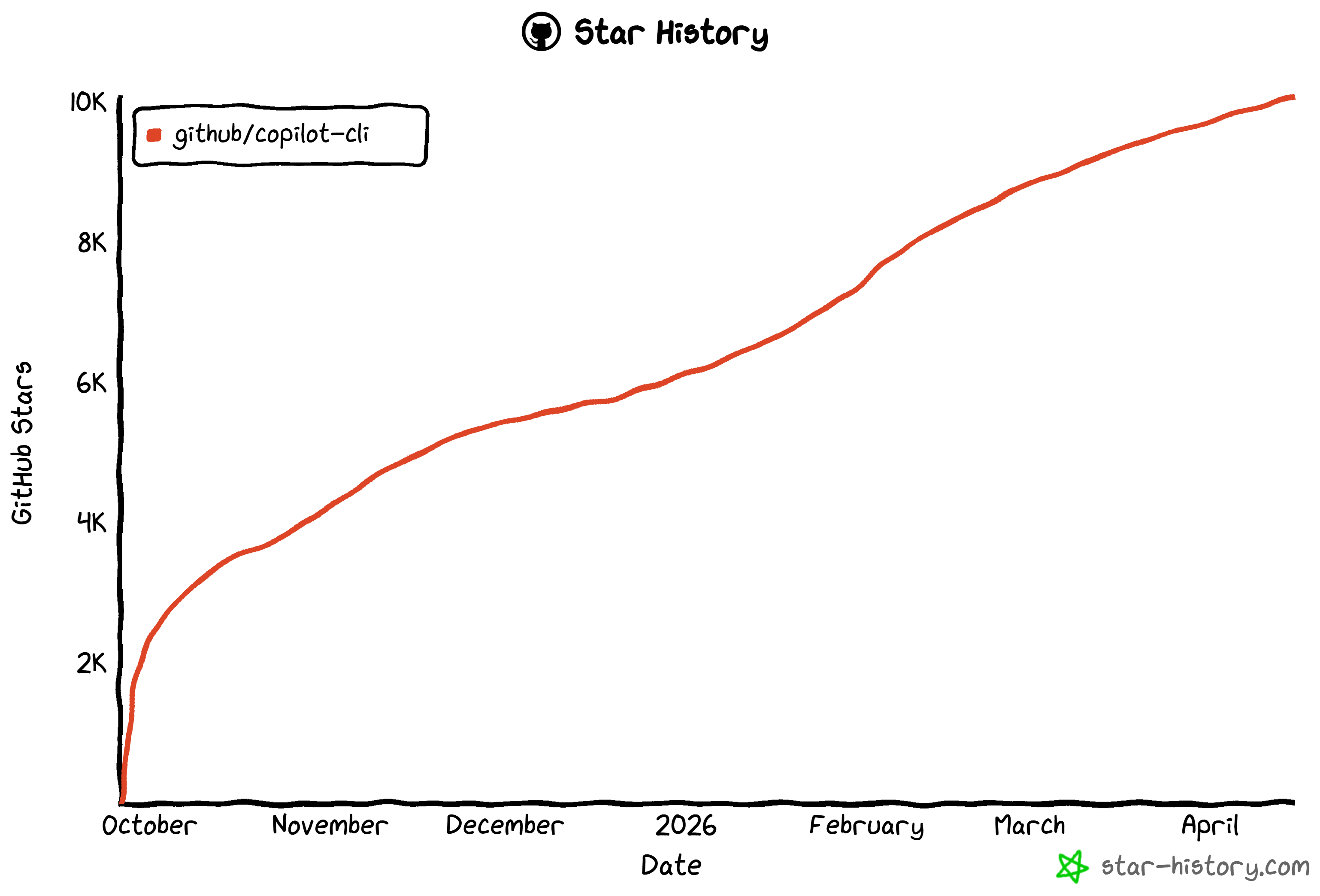
Il compte plus de 10k étoiles sur GitHub, témoignant d’une forte confiance et d’un soutien de la communauté mondiale des développeurs. Notez que le projet est construit et maintenu par l’équipe GitHub.
Les principales fonctionnalités de GitHub Copilot CLI sont :
- Programmation en langage naturel : Permet de décrire des tâches en français courant pour générer, modifier ou déboguer du code directement dans la CLI.
- Intégration GitHub : Fonctionne avec les dépôts, les issues et les pull requests en utilisant le contexte GitHub authentifié.
- Modèle d’exécution agentique : Peut planifier et exécuter des tâches de codage multi-étapes de manière autonome tout en maintenant le contrôle de l’utilisateur.
- Modes interactif et programmatique : Prend en charge les sessions conversationnelles ou l’automatisation par commande unique via des indicateurs CLI.
- Extensibilité MCP : S’intègre avec les serveurs Model Context Protocol pour étendre les capacités avec des outils et sources de données externes.
- Support d’agents personnalisés : Permet des comportements IA spécialisés adaptés à différents workflows ou normes d’ingénierie.
- Système de sécurité et d’approbations : Requiert une autorisation explicite avant d’exécuter ou modifier des fichiers ou d’exécuter des commandes shell.
- Flexibilité des modèles : Permet de basculer entre différents modèles IA ou de connecter des fournisseurs externes (compatibles OpenAI, Azure, Anthropic, modèles locaux).
- Support LSP (Language Server Protocol) : Améliore l’intelligence du code avec des fonctionnalités telles que les diagnostics, les informations au survol et la navigation vers la définition via des serveurs LSP externes.
Pour plus de détails, consultez la documentation.
Pourquoi étendre GitHub Copilot avec la récupération et la découverte dynamiques de données web
Quel que soit la qualité du LLM configuré dans GitHub Copilot CLI, il fait face à une contrainte universelle : la stagnation de l’information. Parce que les grands modèles de langage génèrent des résultats basés sur leurs données d’entraînement, ils opèrent essentiellement dans un instantané statique du passé.
Dans un paysage technique en évolution rapide, ce décalage est un goulot d’étranglement significatif. Un agent CLI hors ligne pourrait suggérer une syntaxe de bibliothèque obsolète ou ne pas tenir compte des correctifs de sécurité récents. Pour surmonter ces obstacles, vos outils IA nécessitent une intégration web en temps réel. C’est là qu’intervient Bright Data !
L’infrastructure prête pour l’IA de Bright Data permet à votre agent GitHub Copilot CLI de dépasser ses données d’entraînement et d’agir de manière autonome pour :
- Exécuter des recherches en direct : Interroger Google ou d’autres moteurs de recherche pour trouver la documentation la plus récente, en s’assurant que les commandes sont compatibles avec les versions logicielles les plus récentes.
- Vérifier l’exactitude : Recouper les solutions avec des fils Stack Overflow ou des issues GitHub pour s’auto-corriger en cas de code halluciné ou obsolète.
- Ingérer des données structurées : Scraper du contenu web en direct pour alimenter des bases de données locales ou générer des données fictives précises pour les tests.
- Enrichir la documentation : Suggérer des liens valides et de haute autorité pour les fichiers
README.mdou les wikis internes. - Et bien plus encore…
Ce qui distingue Bright Data, c’est son vaste réseau mondial de plus de 400 millions d’IPs résidentielles dans 195 pays. Cette base offre une évolutivité illimitée, une disponibilité de 99,99 % et un taux de succès de 99,95 %. Le résultat est un environnement de développement propulsé par l’IA, fiable et robuste, prêt pour la production.
Comment étendre GitHub Copilot CLI avec des capacités de Scraping web et de recherche
Bright Data prend en charge GitHub Copilot CLI via deux intégrations complémentaires :
- Bright Data Web MCP : Le serveur MCP officiel exposant plus de 70 outils pour interagir avec les produits et services basés sur l’API de Bright Data.
- Les skills Bright Data : Un ensemble d’Agent Skills qui apprennent à Copilot comment utiliser correctement les outils Bright Data pour la recherche, le Scraping et l’extraction de données.
Important : Ces deux approches ne sont pas des alternatives, mais sont synergiques. En détail, les skills Bright Data fournissent un skill spécifique pour aider les agents de codage IA à tirer le meilleur parti des outils Web MCP.
Bright Data Web MCP
Le Bright Data Web MCP expose plus de 70 outils pour la collecte automatisée de données web, l’extraction structurée et les interactions avec le navigateur.
Même sur le niveau gratuit, vous avez accès aux outils principaux tels que :
| Outil | Description |
|---|---|
search_engine |
Récupérer les résultats Google, Bing ou Yandex au format JSON ou Markdown |
scrape_as_markdown |
Convertir n’importe quelle page web en Markdown propre tout en contournant la protection anti-bots |
discover |
Effectuer une recherche web propulsée par l’IA avec des résultats classés et pertinents |
Vous obtenez également des versions batch de search_engine et scrape_as_markdown.
Cependant, le [mode Pro](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes) débloque véritablement le plein potentiel du Web MCP. Cela inclut des outils avancés pour l’extraction structurée depuis des plateformes comme GitHub, NPM, Amazon, LinkedIn, Yahoo Finance, YouTube, TikTok, Zillow, Google Maps, et bien d’autres. De plus, vous bénéficiez de capacités d’automatisation du navigateur.
Bright Data Skills
Les skills Bright Data incluent :
| Skill | Description |
|---|---|
search |
Recherche Google structurée avec pagination et sortie JSON propre |
scrape |
Scraper n’importe quelle page web en Markdown avec contournement de bots, gestion des CAPTCHA et rendu JS |
data-feeds |
Jeux de données structurés préconstruits provenant de plus de 40 plateformes (Amazon, LinkedIn, TikTok, YouTube, eBay, Walmart, etc.) |
bright-data-mcp |
Orchestre les outils MCP pour la recherche, le Scraping, l’extraction et l’automatisation |
brightdata-cli |
Utilisation CLI pour le Scraping, la recherche, les Proxys, l’extraction et la surveillance |
scraper-builder |
Guide la création de Scrapers prêts pour la production, de l’analyse à la mise en œuvre |
competitive-intel |
Intelligence compétitive en temps réel (prix, avis, recrutement, signaux SEO) |
design-mirror |
Reproduit les patterns UI, les tokens et les systèmes de design |
bright-data-best-practices |
Meilleures pratiques pour Web Unlocker, API SERP, API Scraper et API Navigateur |
python-sdk-best-practices |
Guide d’utilisation du SDK Bright Data (sync/async, Jeux de données, erreurs, etc.) |
Étapes communes
Dans les deux prochains chapitres, vous verrez comment intégrer Bright Data dans GitHub Copilot CLI en utilisant respectivement MCP et Agent Skills. Pour l’instant, concentrons-nous sur quelques étapes préliminaires communes que vous devez compléter avant de commencer.
Prérequis
Pour suivre ce tutoriel, assurez-vous d’avoir :
- Node.js 22+ installé localement.
- Un compte GitHub, idéalement avec un plan Copilot déjà configuré (le plan gratuit fonctionne également).
- Un compte Bright Data avec une clé API configurée.
Pour générer une clé API Bright Data, suivez le guide officiel.
Étape n°1 : Installer GitHub Copilot CLI
Exécutez la commande suivante pour installer GitHub Copilot CLI via le package npm @github/copilot :
npm install -g @github/copilotNote : Vous pouvez également installer GitHub Copilot CLI via Homebrew et WinGet, comme expliqué dans la documentation.
Une fois l’installation terminée, vous pouvez exécuter Copilot CLI avec :
copilotC’est tout ! GitHub Copilot CLI est maintenant installé avec succès sur votre système.
Étape n°2 : Compléter la configuration
Créez un dossier pour votre projet (ou naviguez vers un dossier existant) depuis le terminal. Dans cet exemple, nous utiliserons un répertoire appelé github-copilot-cli-bright-data-example :
mkdir github-copilot-cli-bright-data-example
cd github-copilot-cli-bright-data-exampleDans votre dossier de projet, démarrez GitHub Copilot CLI :
copilotLa première fois que vous exécutez l’outil, vous devriez voir quelque chose comme ceci :
Pour compléter le démarrage rapide, exécutez :
/loginCela connectera votre GitHub Copilot CLI local à votre compte GitHub. Commencez par sélectionner le compte GitHub auquel vous souhaitez vous connecter :

Une page GitHub s’ouvrira dans votre navigateur, où vous serez invité à entrer un code pour autoriser votre appareil. Ensuite, il vous sera demandé de connecter Copilot CLI à votre compte GitHub et d’accorder les autorisations requises :
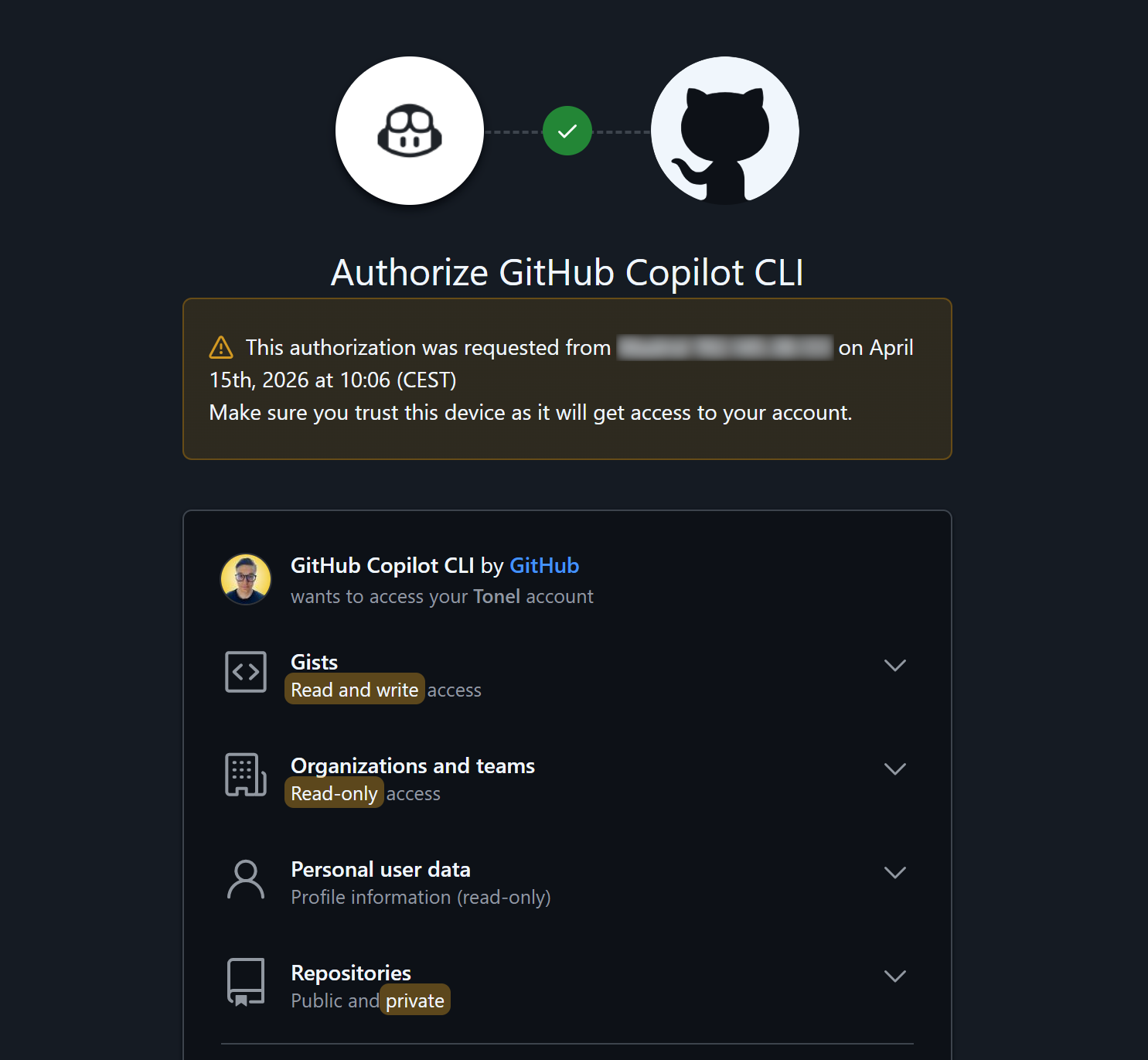
Vérifiez les autorisations et appuyez sur “Authorize github” pour confirmer.
Si vous avez déjà un plan Copilot, vous êtes prêt. Sinon, vous serez invité à démarrer un plan Copilot gratuit :

Acceptez-le, et vous devriez maintenant voir :
À ce stade, un message de succès confirmera que vous êtes connecté et que votre plan Copilot est actif.
Bien joué ! Vous avez configuré GitHub Copilot CLI avec succès.
Connecter Bright Data à GitHub Copilot CLI via le Web MCP
Dans cette section, vous verrez comment configurer une instance locale du Bright Data Web MCP dans GitHub Copilot CLI.
Prérequis
Pour suivre plus facilement, il est recommandé d’avoir :
- Une compréhension de base de comment fonctionne MCP.
- Une familiarité avec les outils exposés par le Bright Data Web MCP.
Gardez également à l’esprit que les prérequis listés dans le chapitre “Étapes communes” s’appliquent ici aussi.
Étape n°1 : Configurer le Web MCP de Bright Data
Avant d’ajouter le Web MCP de Bright Data à votre projet Copilot CLI, vous devez d’abord vérifier que le serveur MCP fonctionne correctement sur votre machine. Ignorez cette étape si vous prévoyez de configurer une connexion distante au Bright Data Web MCP.
Commencez par vous connecter à votre compte Bright Data. Pour une configuration rapide, suivez l’assistant dans la section “MCP” du panneau de contrôle :
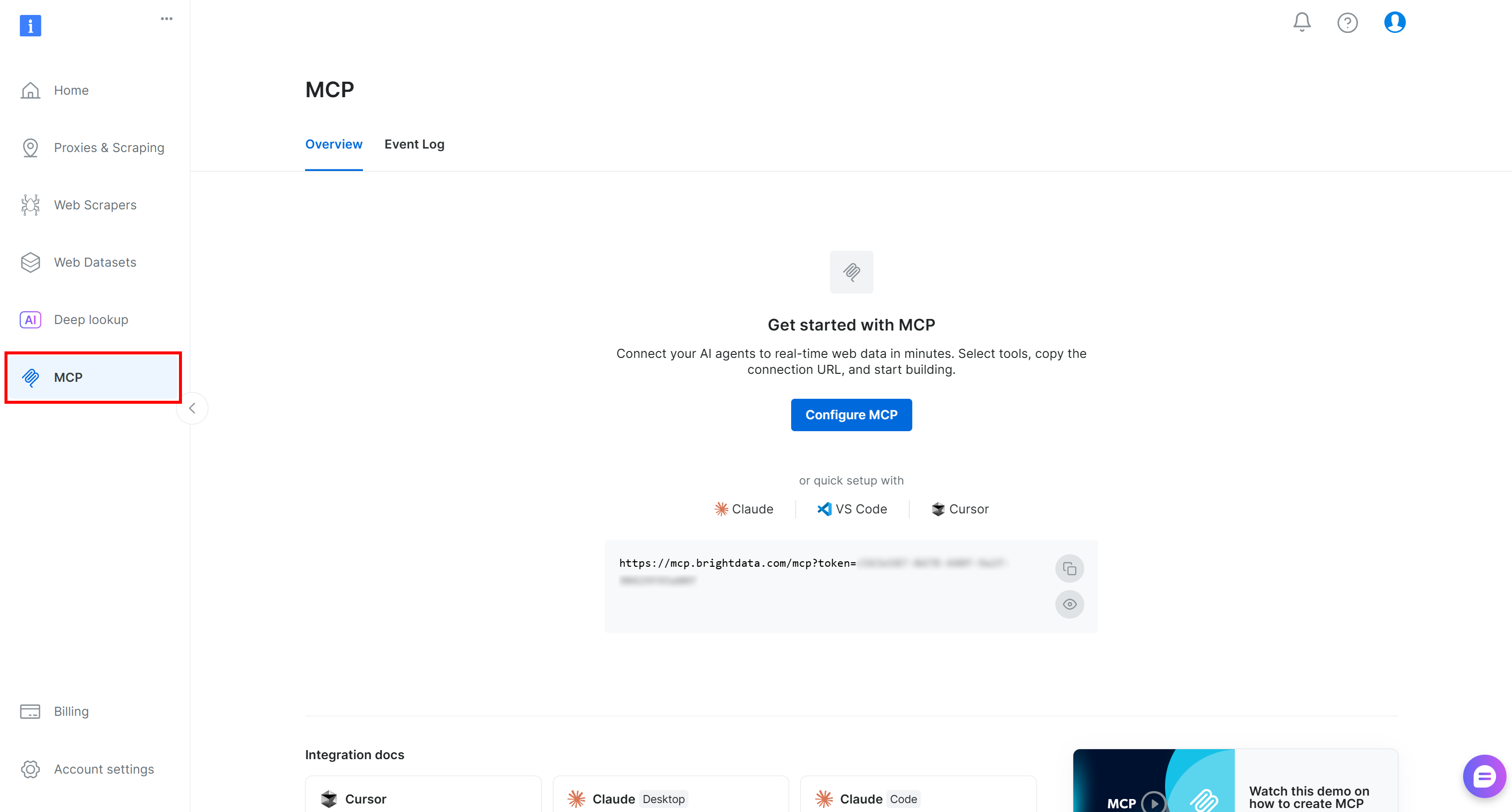
Sinon, suivez les étapes ci-dessous.
Tout d’abord, installez le Web MCP globalement en ajoutant le package @brightdata/mcp :
npm install -g @brightdata/mcpEnsuite, vérifiez que le serveur MCP démarre localement avec :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, de manière équivalente, dans PowerShell :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpRemplacez le placeholder <YOUR_BRIGHT_DATA_API> par votre clé API Bright Data réelle. Cette commande définit la variable d’environnement API_TOKEN requise et lance le serveur Web MCP localement.
Si tout fonctionne correctement, vous devriez voir une sortie similaire à :

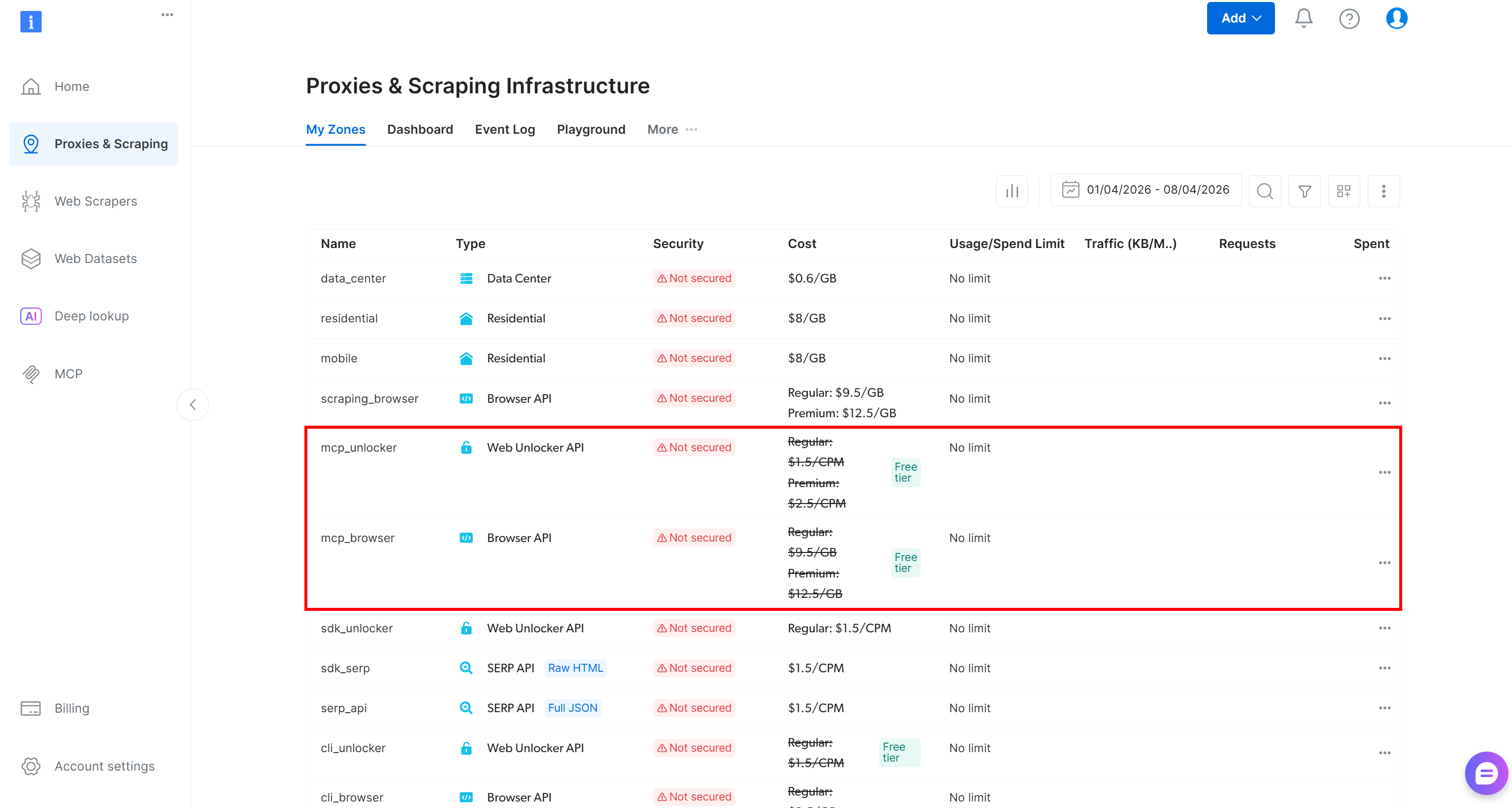
Lors du premier démarrage, le package @brightdata/mcp crée automatiquement deux Zones dans votre compte Bright Data :
mcp_unlocker: Une Zone pour Web Unlocker.mcp_browser: Une Zone pour Browser API.
Ces Zones alimentent les plus de 60 outils disponibles dans le Web MCP. Vous pouvez également configurer des Zones personnalisées si nécessaire, comme décrit dans la documentation.
Pour confirmer que les Zones par défaut ont été créées, naviguez vers la page “Proxies & Scraping Infrastructure” dans le panneau de contrôle Bright Data. Vous devriez voir les deux Zones listées :
Sur le niveau gratuit du Web MCP, seul un ensemble limité d’outils est disponible : search_engine, scrape_as_markdown (et leurs versions batch), ainsi que l’outil discover.
Pour débloquer tous les 60+ outils, activez le mode Pro en définissant la variable d’environnement PRO_MODE="true" :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, sur Windows :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpNote : Le mode Pro n’est pas inclus dans le niveau gratuit et [entraîne des frais supplémentaires](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes).
Bon travail ! Vous venez de vous assurer que le Bright Data Web MCP fonctionne sur votre machine. Ensuite, vous configurerez GitHub Copilot CLI pour démarrer le serveur automatiquement et s’y connecter.
Étape n°2 : Ajouter le Web MCP
Pour ajouter une connexion de serveur MCP à GitHub Copilot CLI, lancez cette commande :
/mcp addVous serez invité à entrer les détails de connexion requis. Utilisez Tab pour naviguer entre les champs et remplissez les informations comme suit :
- Nom MCP :
bright-data-web-mcp(Note : le nom ne peut pas contenir d’espaces) - Commande :
npx @brightdata/mcp - Variables d’environnement :
{"API_TOKEN":"<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE":"true"}(doit être fourni sous forme d’objet JSON clé-valeur) - Outils :
*(pour activer tous les outils)
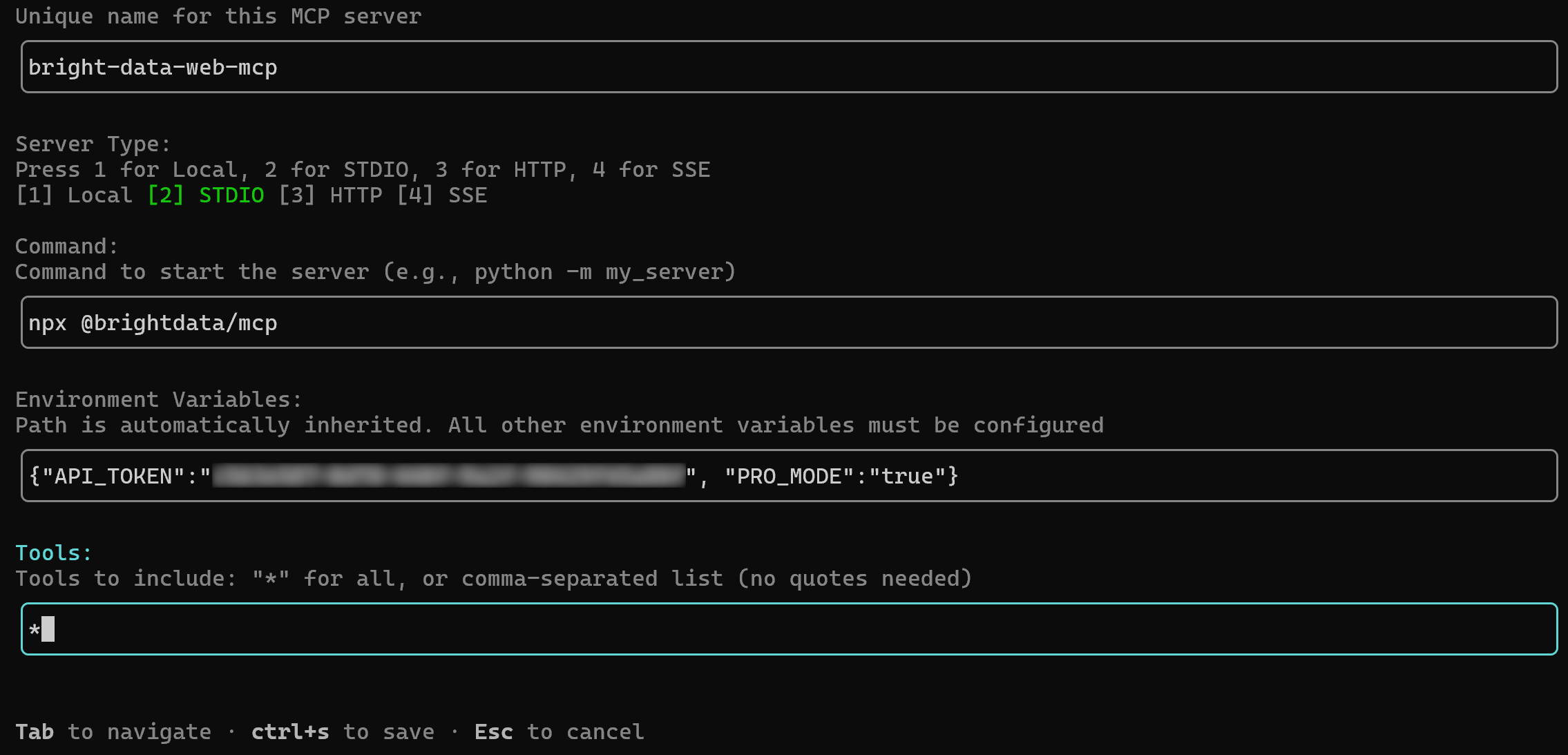
Une fois terminé, appuyez sur Ctrl+S pour sauvegarder.
La configuration ci-dessus reflète la commande npx que vous avez testée précédemment, en utilisant des variables d’environnement pour les identifiants et la configuration :
API_TOKEN: Requis. Définissez-le sur votre clé API Bright Data.PRO_MODE: Optionnel. Supprimez-le (ou définissez-le sur"false") si vous ne souhaitez pas activer le mode Pro.
GitHub Copilot CLI démarrera maintenant le serveur MCP en utilisant la commande npx spécifiée et s’y connectera automatiquement. Vous devriez voir deux messages de confirmation :

Notez que vous verrez au moins deux serveurs mentionnés. (L’un est le github-mcp-server intégré, et l’autre est le Bright Data Web MCP nouvellement configuré.)
La configuration du serveur MCP est stockée dans le fichier de configuration global ~/.copilot/mcp-config.json.
Approche alternative : Modifiez directement le fichier ~/.copilot/mcp-config.json pour qu’il inclue :
{
"mcpServers": {
"bright-data-web-mcp": {
"type": "stdio",
"command": "npx",
"tools": [
"*"
],
"args": [
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Après avoir sauvegardé le fichier, exécutez la commande suivante dans vos sessions GitHub Copilot CLI :
/mcp reloadDans tous les cas, votre configuration GitHub Copilot CLI devrait maintenant être connectée à une instance locale du Bright Data Web MCP. Super !
Étape n°3 : Vérifier que la connexion fonctionne
Juste après avoir exécuté la commande /mcp add et vu le message de succès, vous devriez atteindre cette vue :
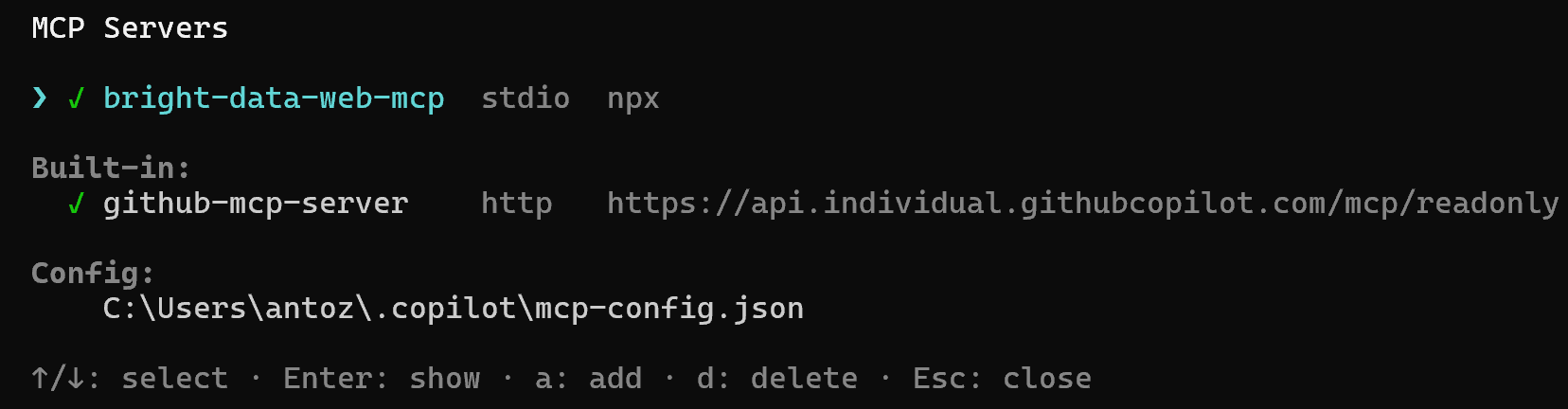
Note : Cette vue correspond à la sortie de la commande /mcp show. Donc, si elle n’apparaît pas, accédez-y via la commande.
Sélectionnez l’option bright-data-web-mcp et appuyez sur Entrée. Vous recevrez ensuite une liste de tous les outils disponibles. En mode Pro, cela inclura plus de 70 outils :
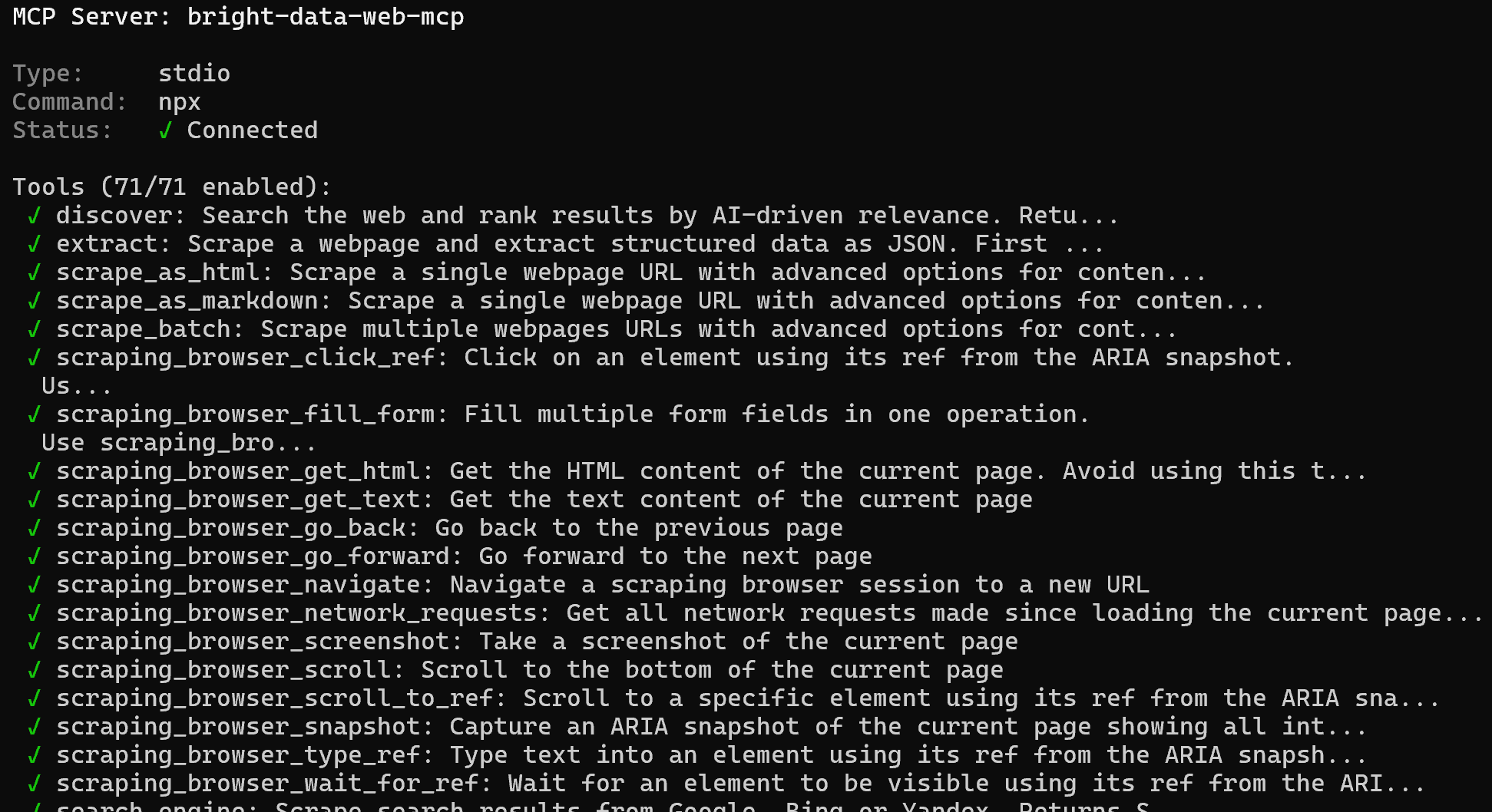
Félicitations ! Cela confirme que le Bright Data Web MCP expose correctement des outils à GitHub Copilot CLI. Plus loin dans cet article, vous découvrirez le Web MCP en action avec les skills Bright Data.
Ajouter les Bright Data Skills à GitHub Copilot CLI
Dans ce chapitre, vous serez guidé pour ajouter les skills Bright Data à votre projet GitHub Copilot CLI. Cela sera réalisé en utilisant le workflow guidé fourni par l’outil skills de Vercel.
Configuration manuelle rapide : Si vous préférez une configuration manuelle, clonez le dépôt Bright Data Skills. Ensuite, copiez simplement le contenu du dossier skills/skills/ dans le répertoire ~/.copilot/skills (ou ~/.agents/skills/skills/) de votre projet :
git clone https://github.com/brightdata/skills
cp -r skills/skills/* ~/.copilot/skills/Cependant, l’approche guidée ci-dessous est plus simple et plus fiable, alors allons-y !
Prérequis
Pour compléter cette section, assurez-vous d’avoir :
- Un système d’exploitation basé sur Unix, tel que Linux, macOS ou WSL sur Windows. (Note : Au moment de la rédaction, c’est encore une exigence, mais la prise en charge Windows pour les skills Bright Data arrive bientôt.)
- Une compréhension de base du standard Agent Skills.
- Une familiarité avec l’outil CLI
skillsde Vercel pour gérer les skills d’agents IA. - Une connaissance de base des skills Bright Data.
En plus des prérequis du chapitre “Étapes communes”, vous aurez également besoin de :
- Une Zone Web Unlocker API configurée dans votre compte Bright Data.
- Le package
jqinstallé localement.
Pour installer jq (un processeur JSON léger similaire à sed) sur les systèmes d’exploitation basés sur Debian, exécutez :
sudo apt-get install curl jqDe manière équivalente, sur macOS, exécutez :
brew install curl jqMaintenant, pour une configuration rapide de la Zone Web Unlocker API, consultez le guide “Créez votre première API Unlocker“. Sinon, continuez avec l’étape ci-dessous.
Étape n°1 : Ajouter une Zone Web Unlocker API
Connectez-vous à votre compte Bright Data et accédez à la page “Proxies & Scraping Infrastructure”. Vérifiez ensuite le tableau “My Zones” :
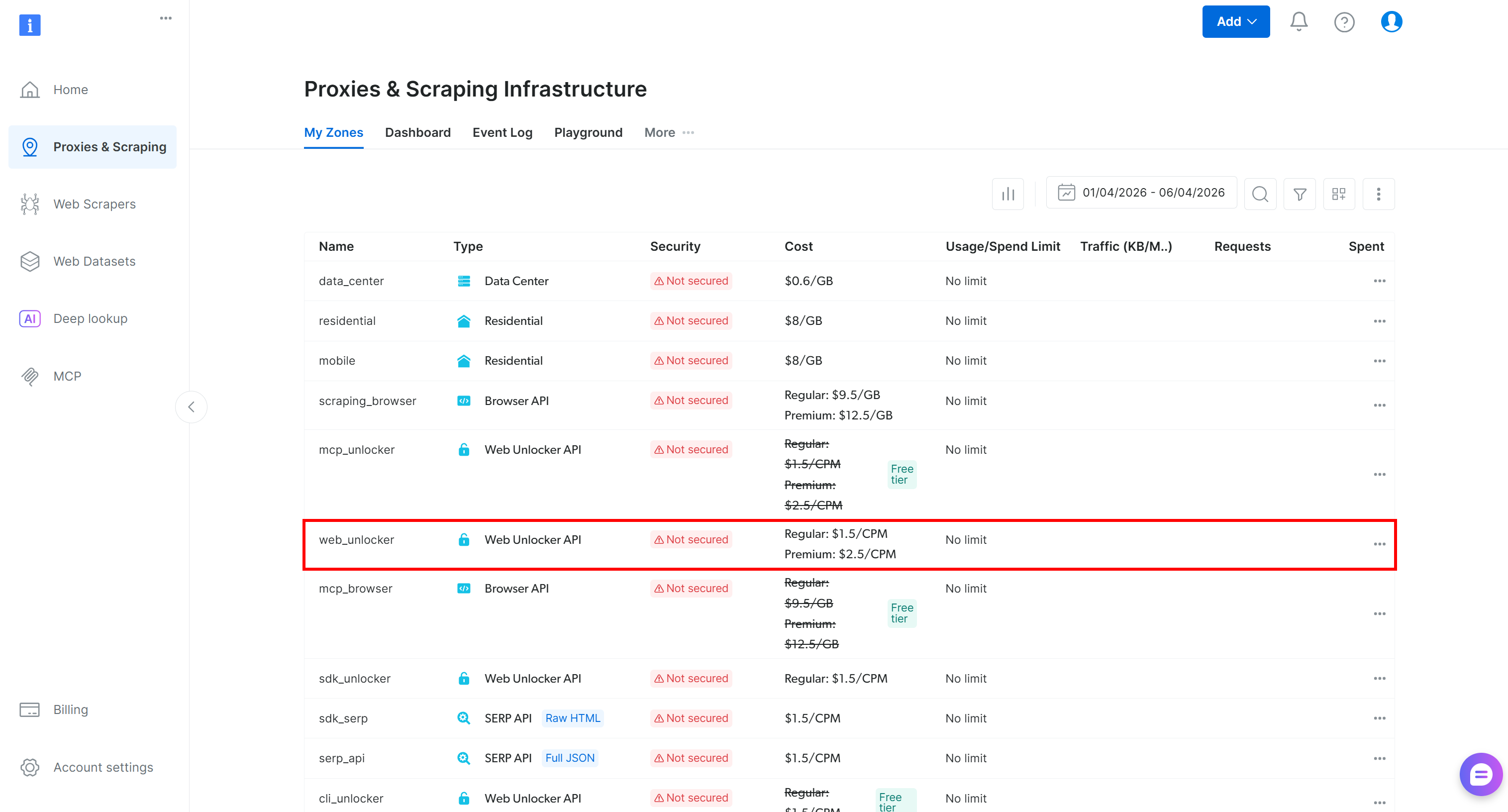
Si une Zone Web Unlocker (par exemple, web_unlocker) existe déjà, vous pouvez ignorer cette étape.
Sinon, créez-en une en faisant défiler jusqu’à la carte “Unblocker API” et en cliquant sur “Create zone” :
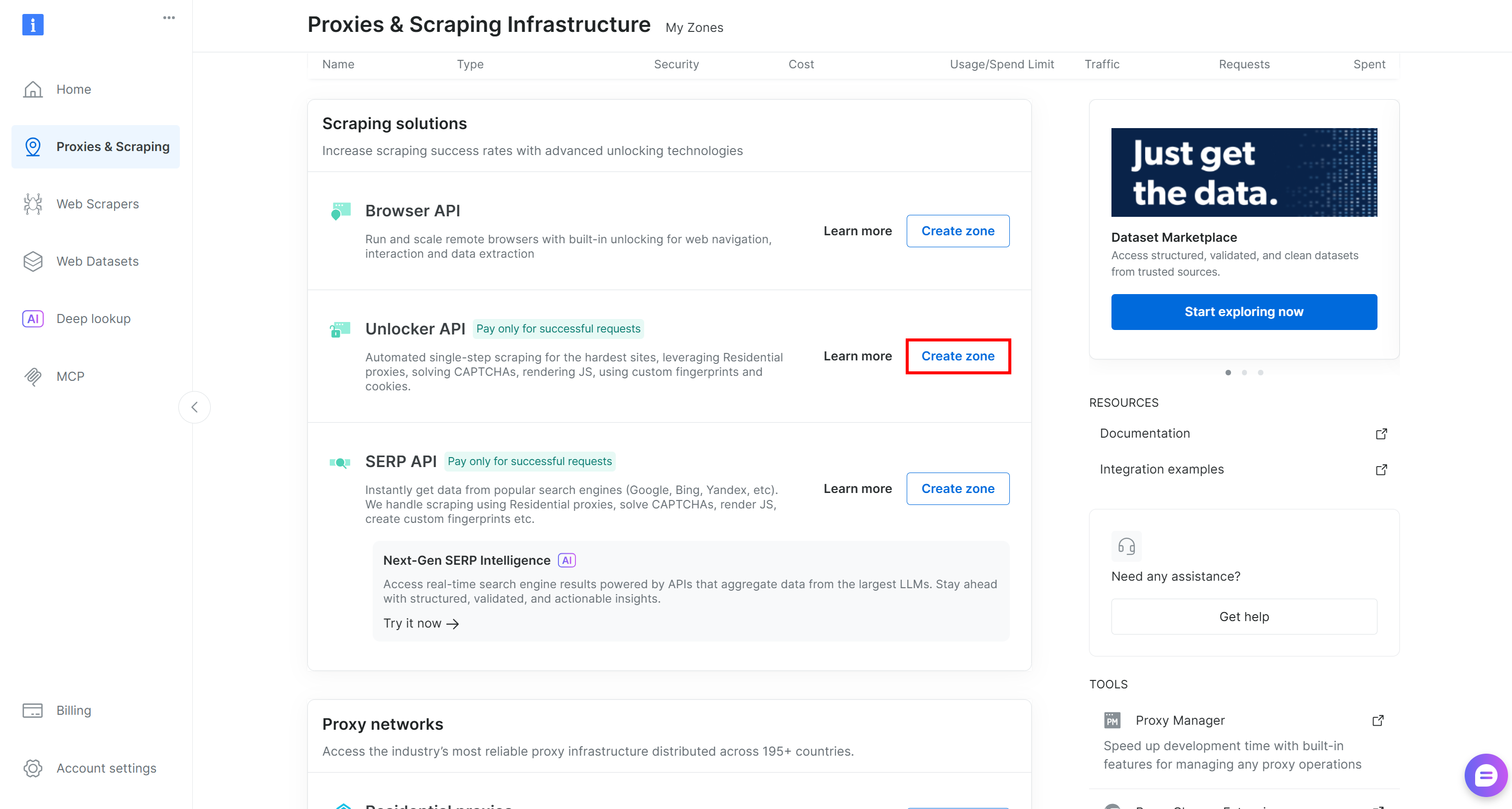
Choisissez un nom clair pour votre Zone et complétez l’assistant de configuration jusqu’à ce que la Zone devienne active. Parfait !
Étape n°2 : Compléter la configuration
Les skills Bright Data nécessitent ces deux variables d’environnement pour fonctionner :
BRIGHTDATA_API_KEY: Utilisé pour authentifier les requêtes aux APIs Bright Data.BRIGHTDATA_UNLOCKER_ZONE: Spécifie votre Zone Web Unlocker API, activant les capacités de Scraping web et de recherche (car elle peut également agir comme une API SERP).
Définissez les variables d’environnement requises dans votre terminal comme suit :
export BRIGHTDATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>"Remplacez les placeholders par vos valeurs réelles. Une fois définies, vous êtes prêt à utiliser les skills Bright Data !
Étape n°3 : Installer les Bright Data Skills
Pour installer les skills Bright Data dans GitHub Copilot CLI, exécutez la commande suivante :
npx skills add brightdata/skills -a github-copilotCette commande installe le package skills et démarre le processus de configuration, qui va :
- Télécharger les skills Bright Data depuis le répertoire officiel Agent Skills.
- Les configurer pour une utilisation dans GitHub Copilot CLI.
Vous verrez d’abord un écran où vous pouvez choisir quels skills installer :
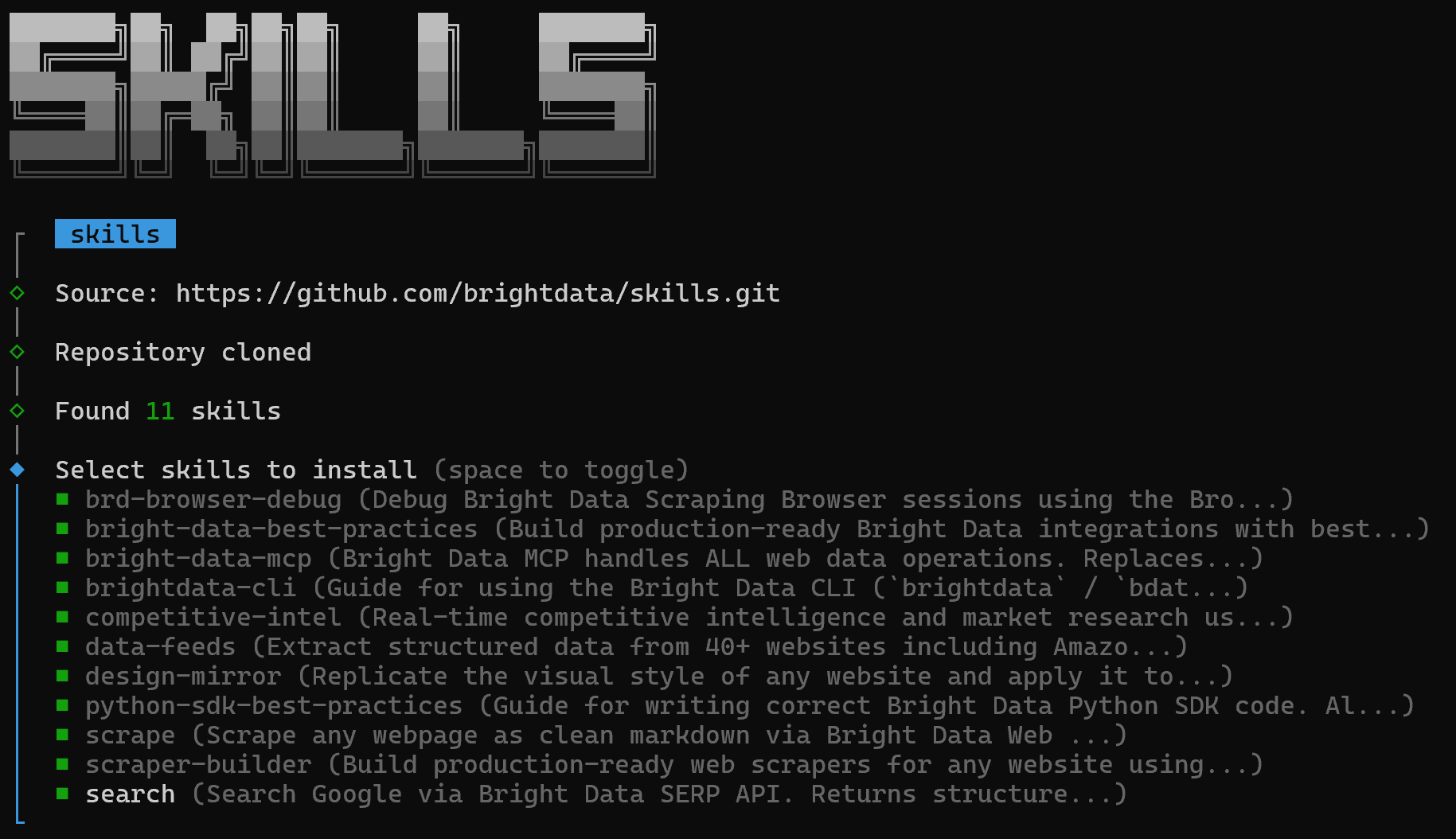
Pour tous les installer, utilisez la barre d’espace pour sélectionner chaque skill, puis appuyez sur Entrée.
Ensuite, vous serez invité à sélectionner la portée d’installation. Puisque l’intégration Web MCP a été configurée globalement, il est logique d’installer également les skills Bright Data globalement. Ainsi, sélectionnez l’option “Global” :

Vous verrez ensuite les sections “Installation Summary” et “Security Risk Assessment”. Vérifiez les deux attentivement et appuyez sur Entrée pour confirmer. Enfin, vous recevrez un message de confirmation comme celui-ci :
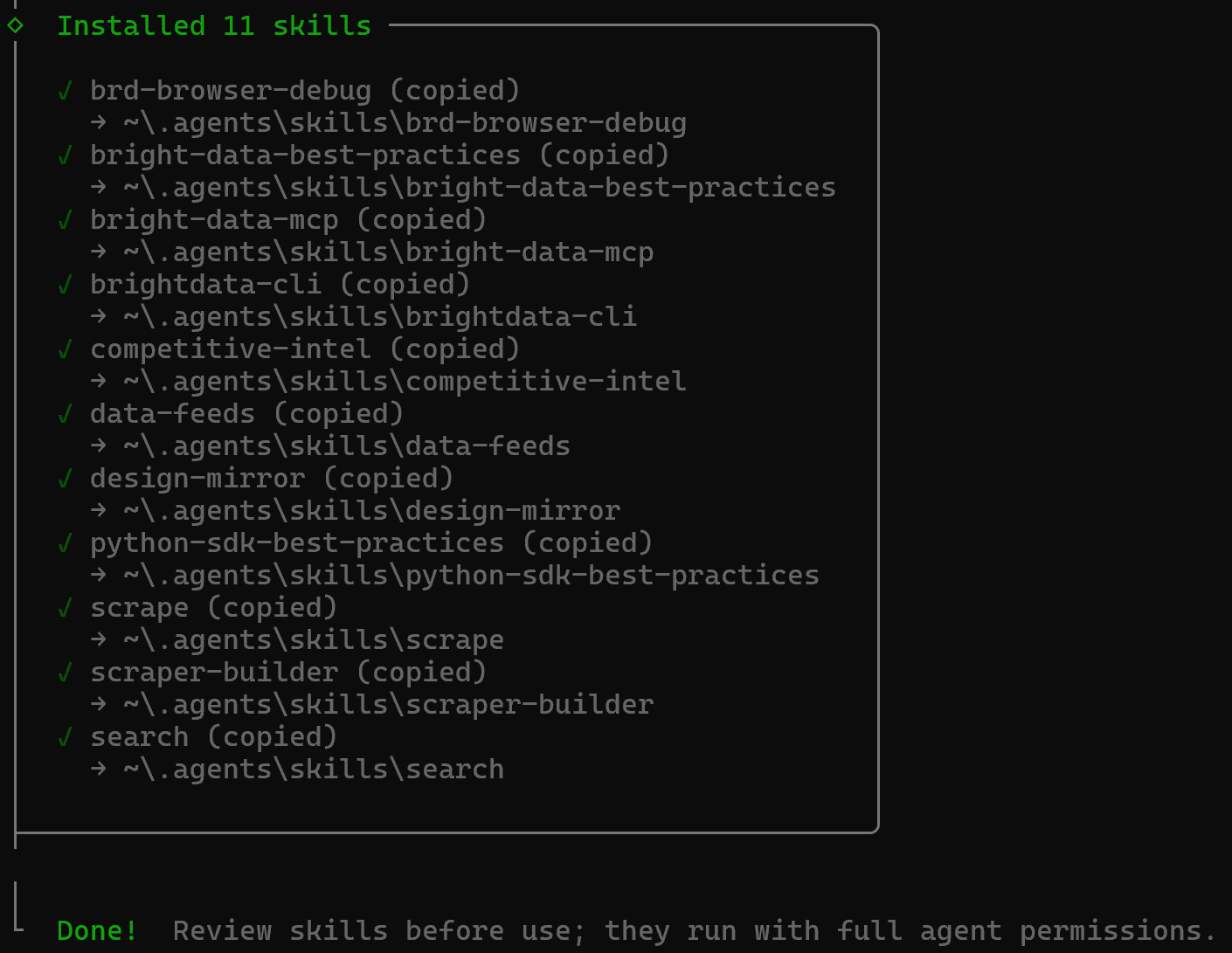
Les Bright Data Skills seront copiées dans le répertoire ~/.agents/skills (ou ~/.copilot/skills, ou ~/.claude/skills).
Excellent ! Les skills Bright Data sont maintenant installées et disponibles dans Copilot CLI.
Étape n°4 : Vérifier que les skills sont disponibles
Dans votre session GitHub Copilot CLI, rechargez tous les skills avec :
/skills reloadVoici le résultat que vous devriez voir :

Notez que le nombre total de skills est de 12 (11 skills Bright Data + le skill intégré customize-cloud-agent).
Ensuite, listez tous les skills disponibles avec :
/skills listLa sortie ressemblera à ceci :

Les skills listées correspondent aux noms des skills Bright Data, confirmant qu’elles ont été installées correctement.
Mission accomplie ! Dans le prochain chapitre, vous découvrirez comment exploiter pleinement le Bright Data Web MCP et la configuration des Agent Skills dans GitHub Copilot CLI.
GitHub Copilot CLI + Bright Data : Assistance au codage IA de niveau supérieur
Maintenant que vous avez intégré Bright Data dans Copilot CLI via MCP et les skills, il est temps d’explorer ce que cette configuration permet. Nous allons parcourir un exemple pratique et concret, bien que de nombreux autres cas d’usage soient possibles.
Imaginez que vous souhaitez apprendre à tirer le meilleur parti de GitHub Copilot CLI (techniques de prompting, meilleures pratiques, etc.), ainsi que des ressources sur comment l’étendre (via des agents, des skills, etc.). Au lieu de rechercher et d’examiner manuellement des dizaines de sources, demandez simplement à votre assistant de codage de générer un rapport Markdown avec :
Search online for the best GitHub Copilot repositories and official GitHub Copilot CLI best practices. Scrape the top pages and generate a `.md` file containing the main instructions on how to get the most out of GitHub Copilot CLI, along with useful resources for extensions (agents, skills, etc.). Include contextual links discovered from the scraped pages.Clairement, un agent de codage IA standard aurait du mal avec cette tâche, car elle nécessite des outils pour la recherche web, la découverte et les capacités de Scraping.
Exécutez le prompt, et vous obtiendrez quelque chose comme ceci :
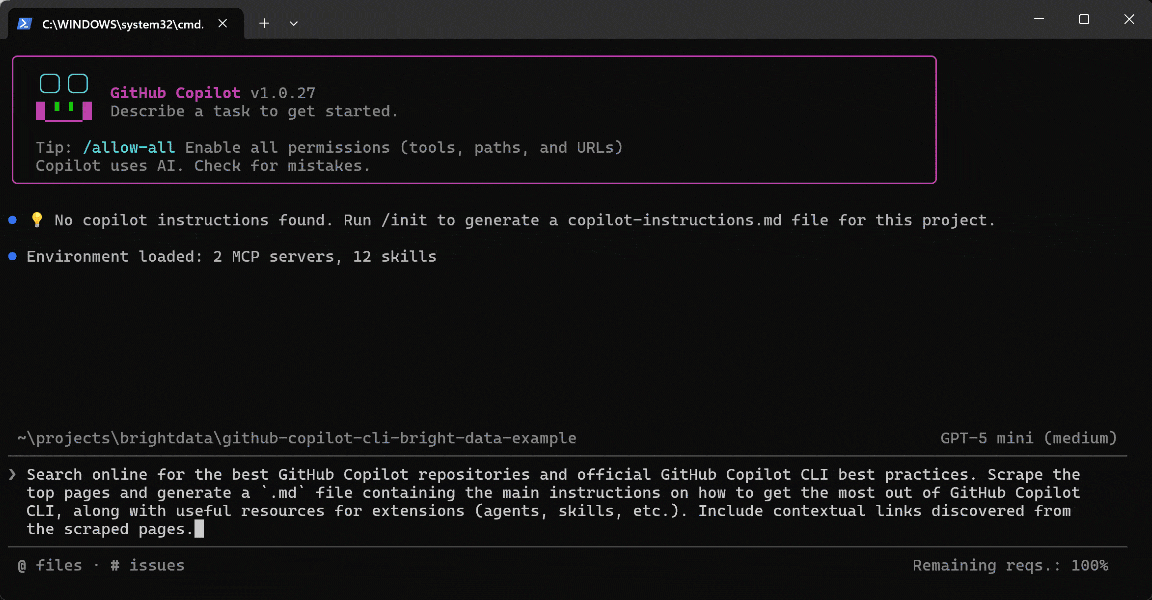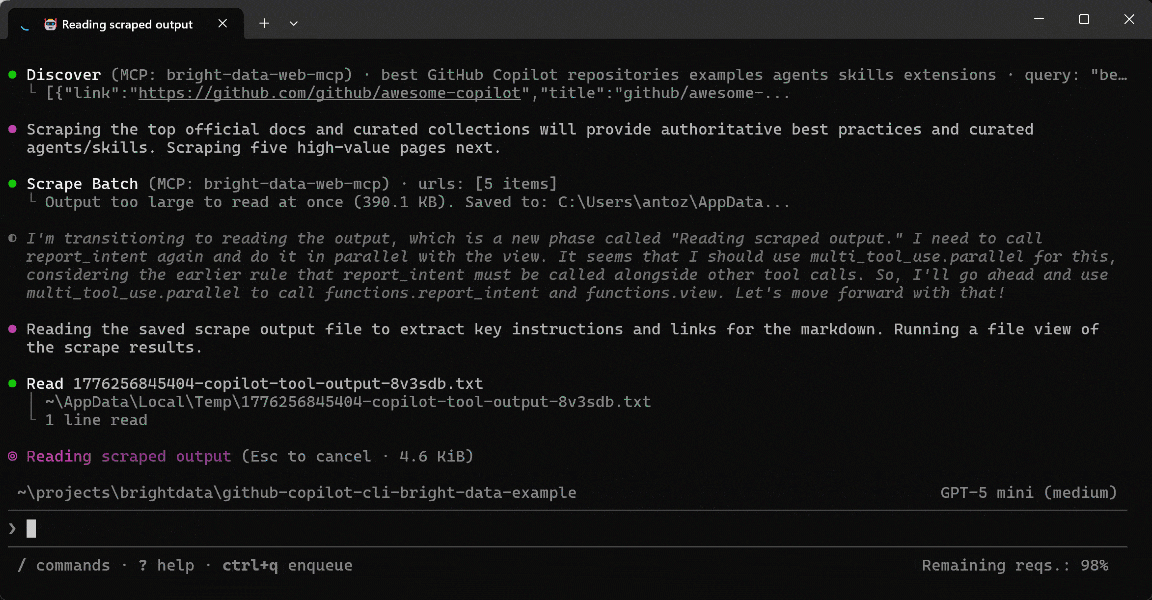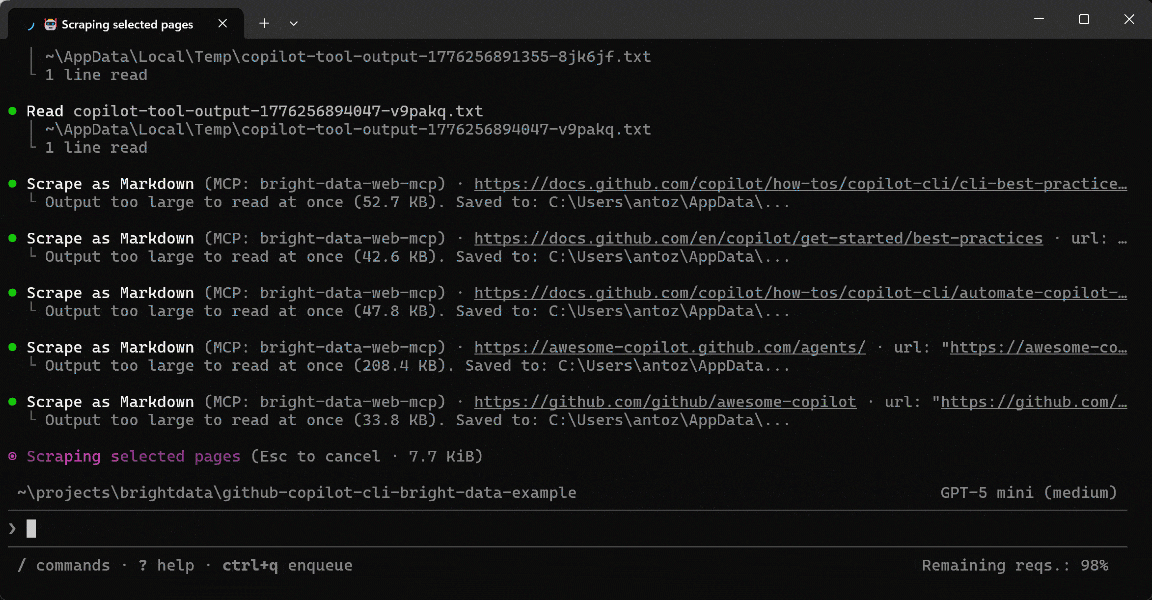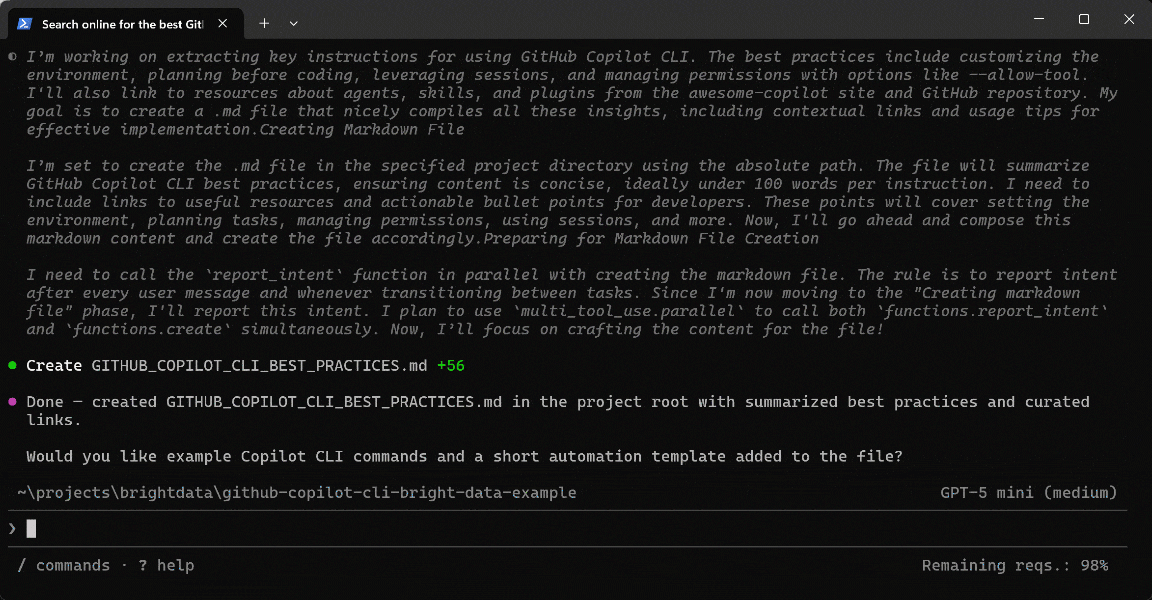
Voici ce que l’agent GitHub Copilot CLI a réellement fait :
- Appelé l’outil
discoverpour exécuter plusieurs requêtes et récupérer des pages classées et pertinentes pour les meilleures pratiques et les dépôts (via l’API Web Discovery de Bright Data). - Sélectionné les URLs les plus pertinentes pour prioriser les sources faisant autorité et à fort signal.
- Utilisé
scrape_batch(propulsé par Web Unlocker API) pour extraire efficacement le contenu de plusieurs pages en une seule requête. - Traité la sortie scrapée localement pour identifier les sections clés sans appels réseau supplémentaires.
- Appliqué des recherches ciblées (par exemple,
grep) pour isoler les meilleures pratiques pertinentes et affiner les pages à analyser davantage. - Utilisé l’outil
scrape_as_markdownpour convertir les pages sélectionnées en Markdown propre et structuré. - Agrégé les insights et les liens contextuels dans un ensemble de données structuré pour la documentation.
- Généré un fichier
.mdfinal avec les meilleures pratiques, les ressources et les liens.
Note : Copilot CLI a automatiquement sélectionné les outils Bright Data les plus appropriés pour chaque étape. Ceci est rendu possible par les skills Bright Data, qui guident la prise de décision de l’agent.
La sortie générée est le fichier GITHUB_COPILOT_CLI_BEST_PRACTICES.md ci-dessous :
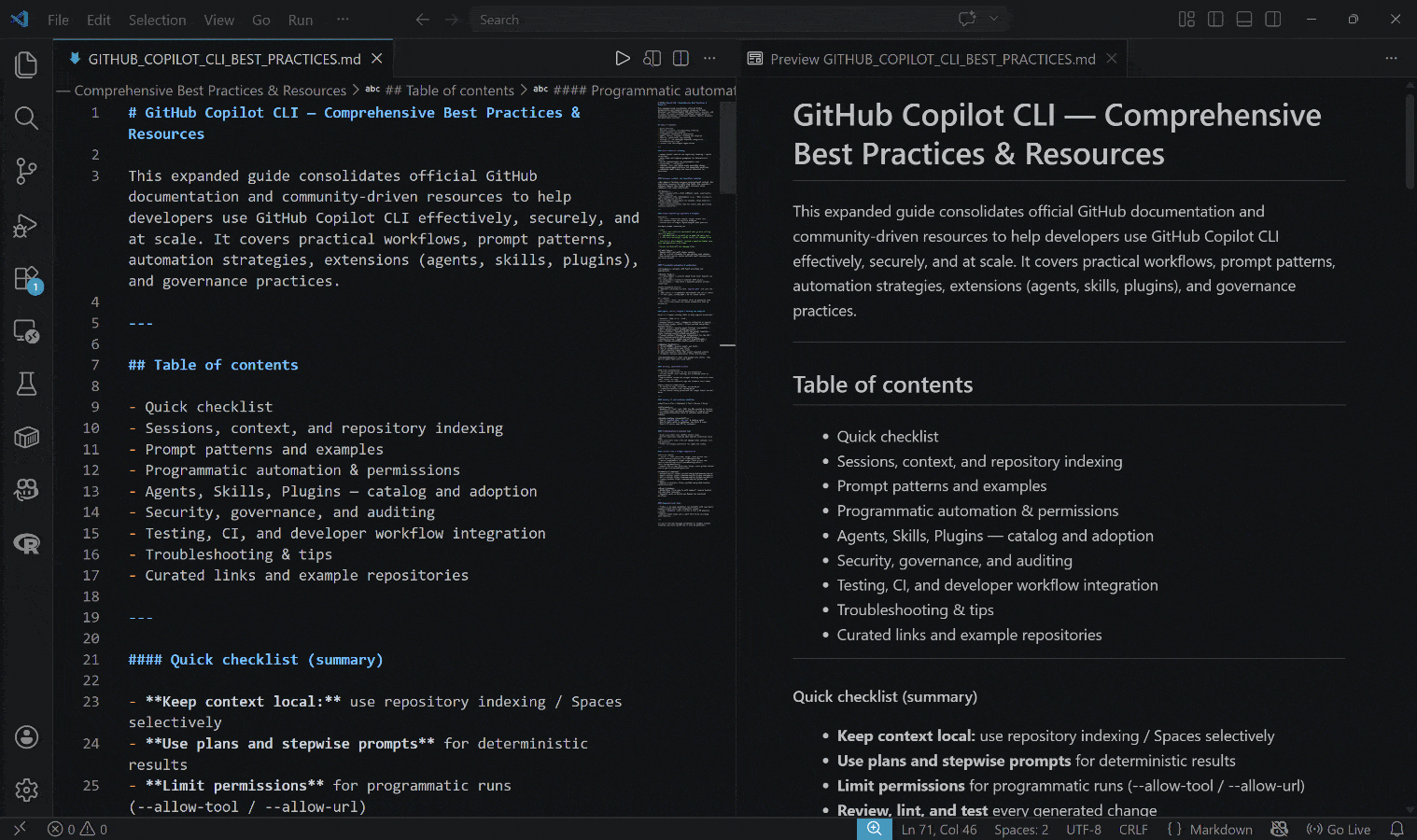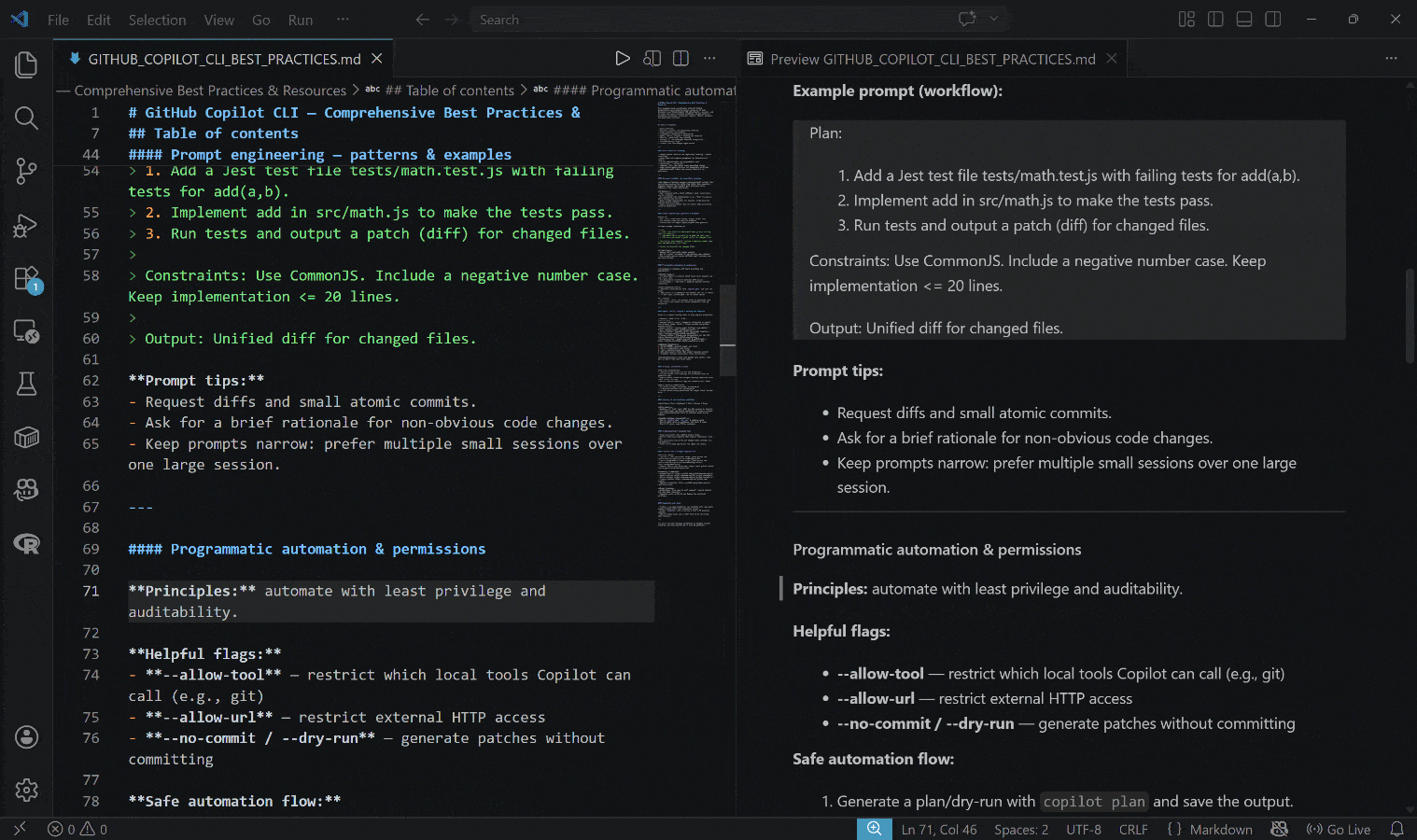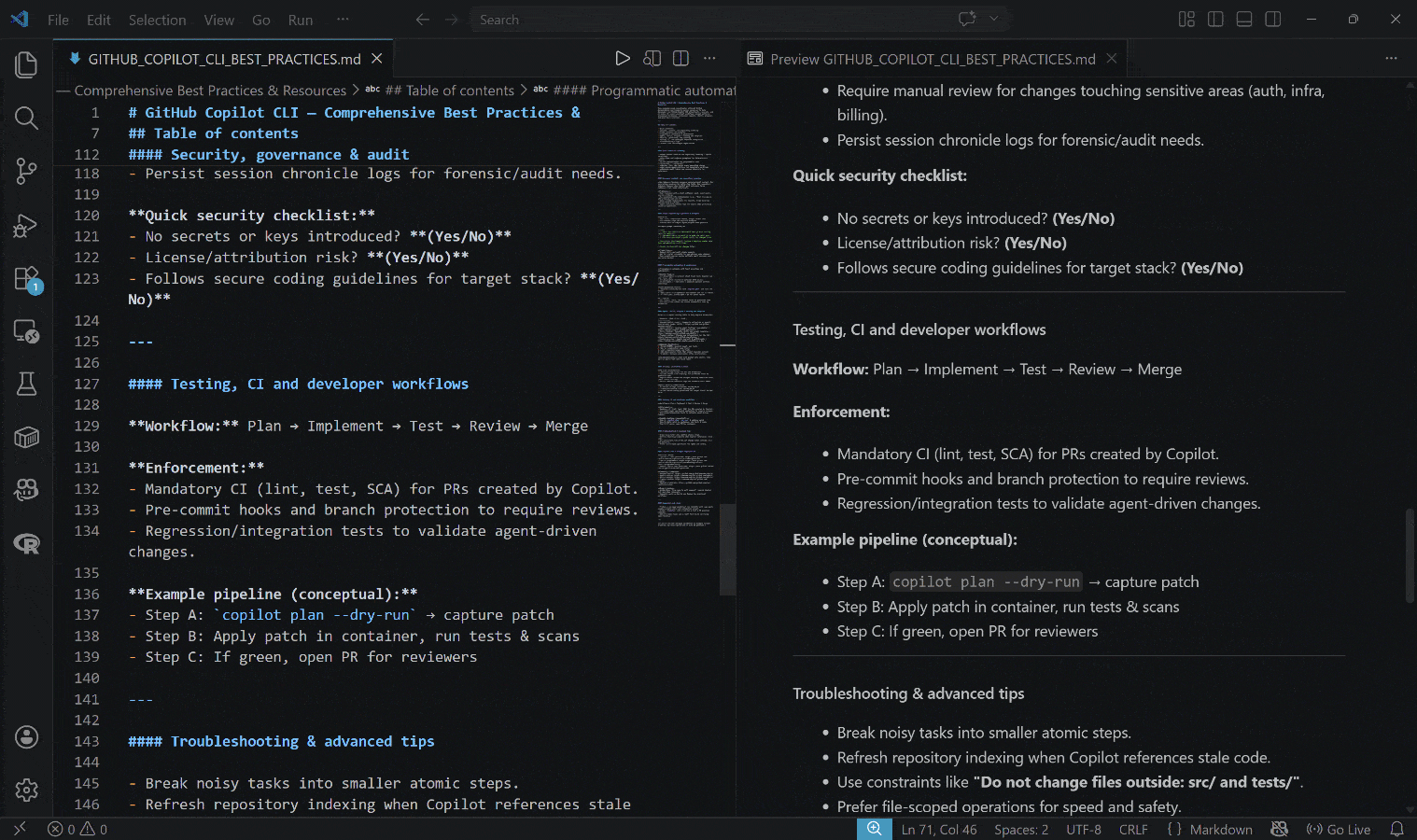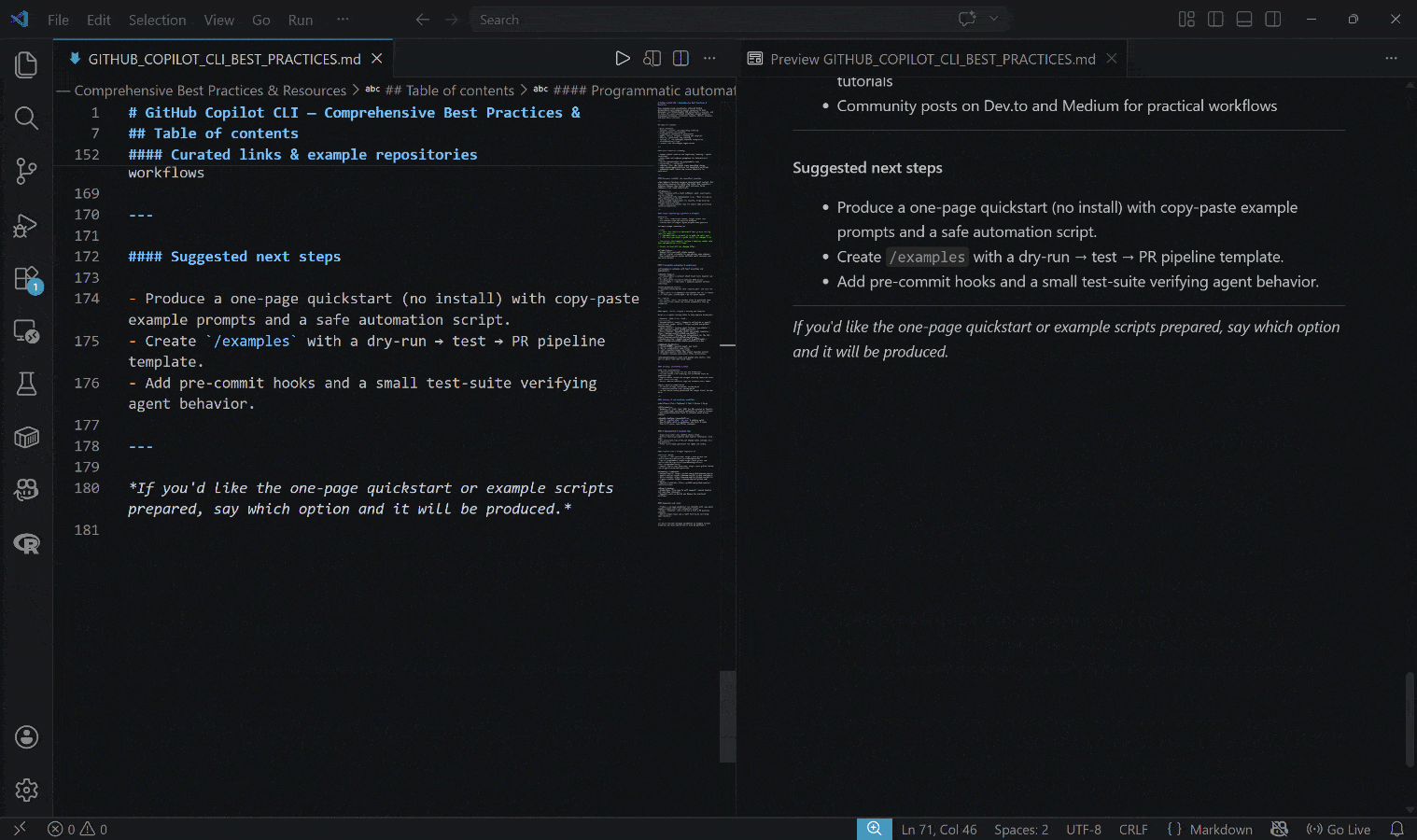
Remarquez comment le résultat inclut des informations réelles, à jour et contextuelles, soutenues par des liens réels et des exemples pratiques.
Et voilà ! Cet exemple simple met en évidence la puissance de l’intégration de Bright Data avec GitHub Copilot CLI. Vous pouvez maintenant expérimenter avec d’autres prompts, laissant votre agent de codage interagir activement avec le web pour des résultats plus précis.
Conclusion
Dans cet article, vous avez compris ce qu’est GitHub Copilot CLI et ce qu’il apporte. Plus précisément, vous avez vu pourquoi et comment l’étendre en le connectant à Bright Data via Web MCP et les skills officielles.
Cette intégration élève l’expérience de codage Copilot CLI à un tout nouveau niveau. C’est parce que l’agent de codage IA sous-jacent acquiert de nouvelles capacités puissantes telles que la recherche web, la découverte web, l’extraction de données structurées et les interactions web automatisées.
Pour des workflows encore plus avancés, jetez un œil à la gamme complète de services prêts pour l’IA dans l’écosystème Bright Data.
Créez un compte Bright Data gratuitement dès aujourd’hui et mettez la main sur nos outils de données web !




