
Dans ce tutoriel, vous apprendrez :
- Ce qu’est Gemini CLI et pourquoi il est si populaire dans la communauté des codeurs.
- Comment l’ajout de capacités d’interaction avec le web et d’extraction de données peut le faire passer à la vitesse supérieure.
- Comment connecter le CLI Gemini au serveur MCP Bright Data Web pour créer un agent de codage AI amélioré.
Plongeons dans l’aventure !
Qu’est-ce que l’interface de programmation Gemini ?
Le CLI Gemini est un agent d’intelligence artificielle développé par Google qui apporte la puissance du modèle de langage large Gemini directement dans votre terminal. Il est conçu pour améliorer la productivité des développeurs et simplifier diverses tâches, en particulier celles liées au codage.
La bibliothèque est open-source et disponible via un package Node.js. À l’heure où nous écrivons ces lignes, elle a déjà recueilli plus de 67 000 étoiles sur GitHub. Bien qu’elle ait été publiée il y a seulement quelques mois, l’enthousiasme de la communauté et son adoption rapide ont été remarquables.
En particulier, les principaux aspects qui font la spécificité de Gemini CLI sont les suivants :
- Interaction directe avec le terminal: Interagir avec les modèles Gemini directement à partir de la ligne de commande.
- Accent sur le codage: Vous aide à déboguer, à créer de nouvelles fonctionnalités, à améliorer la couverture des tests et même à créer de nouvelles applications à partir d’invites ou d’esquisses.
- Intégration d’outils et extensibilité: Exploite une boucle ReAct (“raisonner et agir”) et peut s’intégrer à des outils intégrés (tels que
grep,terminal,lecture/écriture de fichiers) et à des serveurs MCP externes. - Utilisation gratuite: Google propose également un niveau d’utilisation gratuite généreux, ce qui rend l’outil largement accessible.
- Capacités multimodales: Prise en charge de tâches telles que la génération de code à partir d’images ou de croquis.
Pourquoi étendre le CLI de Gemini avec des capacités d’interaction Web et d’extraction de données ?
Quelle que soit la puissance des modèles Gemini intégrés dans l’interface de programmation Gemini, ils sont toujours confrontés à des limitations communes à tous les modules d’apprentissage tout au long de la vie.
Les modèles Gemini ne peuvent répondre qu’en fonction de l’ensemble de données statiques sur lequel ils ont été formés. Mais il s’agit là d’un instantané du passé ! De plus, les LLM ne peuvent pas rendre ou interagir avec des pages web en direct comme le ferait un utilisateur humain. Par conséquent, leur précision et leur champ d’action sont intrinsèquement limités.
Imaginez maintenant que vous donniez à votre assistant de codage Gemini CLI la possibilité d’aller chercher en temps réel des tutoriels, des pages de documentation et des guides, et d’en tirer des enseignements. Imaginez qu’il interagisse avec n’importe quel site web en ligne, tout comme il navigue déjà dans votre système de fichiers. Il s’agit là d’une avancée significative dans ses fonctionnalités, qui est possible grâce à l’intégration avec le serveur MCP Web de Bright Data.
Le serveur Web MCP de Bright Data permet d’accéder à plus de 60 outils prêts pour l’IA afin de collecter des données Web en temps réel et d’interagir avec le Web. Ces outils sont tous alimentés par la riche infrastructure de données d’IA de Bright Data.
Pour obtenir la liste complète des outils exposés par le serveur Bright Data Web MCP, reportez-vous à la documentation.
Voici quelques exemples de ce que vous pouvez réaliser en combinant Gemini CLI et le Web MCP :
- Récupérer les SERP pour insérer automatiquement des liens contextuels dans les rapports ou les articles.
- Demandez à Gemini d’aller chercher des tutoriels ou de la documentation à jour, d’en tirer des enseignements, puis de générer du code ou des modèles de projet en conséquence.
- Récupérez des données sur des sites web réels et enregistrez-les localement à des fins de simulation, de test ou d’analyse.
Voyons un exemple concret de cette intégration en action !
Comment intégrer le serveur Web MCP dans l’interface de programmation Gemini
Apprenez à installer et à configurer localement le CLI Gemini et à l’intégrer au serveur MCP Web de Bright Data. La configuration résultante sera utilisée pour :
- Récupérer une page de produit Amazon.
- Stocker les données localement.
- Créer un script Node.js pour charger et traiter les données.
Suivez les étapes ci-dessous !
Conditions préalables
Pour reproduire les étapes de cette section du tutoriel, assurez-vous que vous disposez des éléments suivants :
- Node.js 20+ installé localement (nous recommandons d’utiliser la dernière version LTS).
- Une clé API Gemini ou Vertex AI (ici, nous allons utiliser une clé API Gemini).
- Un compte Bright Data.
Vous n’avez pas besoin de configurer les clés API pour l’instant. Les étapes ci-dessous vous guideront dans la configuration des clés API de Gemini et de Bright Data le moment venu.
Bien qu’elles ne soient pas strictement nécessaires, les connaissances de base suivantes vous seront utiles :
- Une compréhension générale du fonctionnement du programme MCP.
- Une certaine familiarité avec le serveur MCP de Bright Data Web et ses outils disponibles.
Étape 1 : Installer l’interface de programmation Gemini
Pour commencer à utiliser l’interface de programmation Gemini, vous devez d’abord générer une clé API à partir de Google AI Studio. Suivez les instructions officielles pour récupérer votre clé API Gemini.
Remarque: si vous disposez déjà d’une clé API Vertex AI ou si vous préférez l’utiliser, consultez plutôt la documentation officielle.
Une fois que vous avez votre clé API Gemini, ouvrez votre terminal et définissez-la comme variable d’environnement avec cette commande Bash :
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Ou, alternativement, avec cette commande PowerShell sous Windows :
$env:GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Remplacez la par la clé que vous avez générée.
Ensuite, installez globalement le CLI Gemini via le paquetage officiel @google/gemini-cli:
npm install -g @google/gemini-cliDans la même session de terminal où vous avez défini la clé GEMINI_API_KEY (ou VERTEX_API_KEY), lancez le CLI Gemini avec :
geminiVoici ce que vous devriez voir :
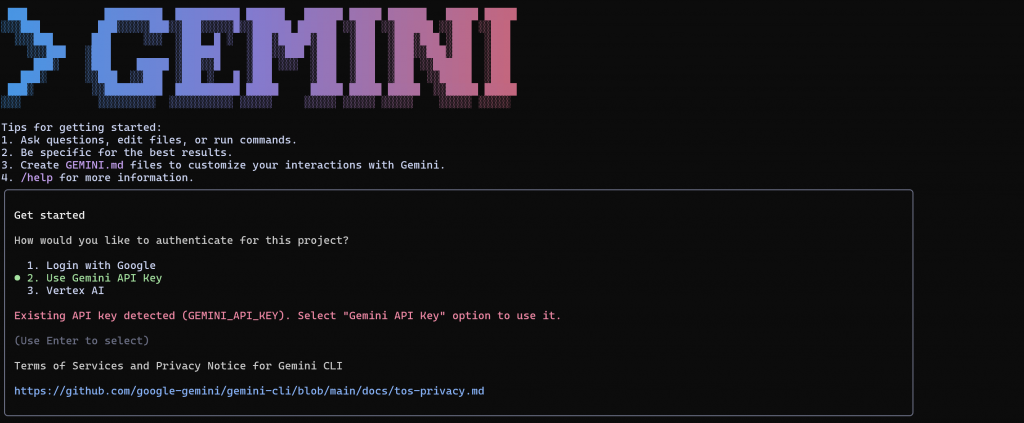
Appuyez sur Enter pour sélectionner l’option 2 (“Use Gemini API key”). L’interface de programmation devrait automatiquement détecter votre clé API et passer à l’affichage de l’invite :
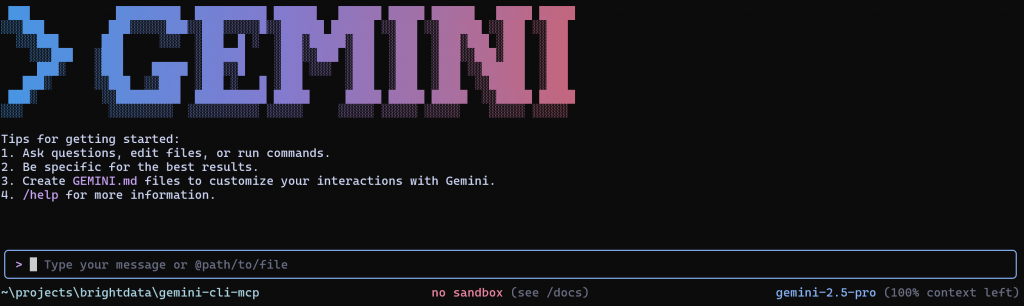
Dans la section “Type your message or @path/to/file”, vous pouvez écrire votre invite directement ou référencer un fichier à envoyer au CLI Gemini pour exécution.
Dans le coin inférieur droit, vous remarquerez que le CLI Gemini utilise le modèle gemini-2.5-pro. Il s’agit du modèle configuré dans la boîte. Heureusement, l’API Gemini offre un niveau gratuit avec jusqu’à 100 requêtes par jour utilisant le modèle gemini-2.5-pro, de sorte que vous pouvez le tester même sans plan payant.
Si vous préférez un modèle avec des limites de débit plus élevées, comme gemini-2.5-flash, vous pouvez le définir avant de lancer l’interface de programmation en définissant la variable d’environnement GEMINI_MODEL. Sous Linux ou macOS, exécutez :
export GEMINI_MODEL="gemini-2.5-flash"Ou, de manière équivalente, sous Windows :
$env:GEMINI_MODEL="gemini-2.5-flash"Lancez ensuite le CLI Gemini comme d’habitude avec la commande gemini.
C’est génial ! Le CLI de Gemini est maintenant configuré et prêt à être utilisé.
Étape 2 : Démarrer avec le serveur MCP Web de Bright Data
Si vous ne l’avez pas encore fait, inscrivez-vous à Bright Data. Si vous avez déjà un compte, il vous suffit de vous connecter.
Ensuite, suivez les instructions officielles pour générer votre clé d’API Bright Data. Pour plus de simplicité, cette étape suppose que vous utilisez un jeton avec des autorisations d’administrateur.
Installez le serveur MCP Bright Data Web globalement à l’aide de cette commande :
npm install -g @brightdata/mcpEnsuite, testez que tout fonctionne avec la commande Bash ci-dessous :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, sous Windows, la commande PowerShell équivalente est la suivante :
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpVeillez à remplacer le caractère générique par le jeton API que vous avez récupéré plus tôt. Les deux commandes définissent la variable d’environnement API_TOKEN requise et lancent le serveur MCP via le paquetage npm @brightdata/mcp.
Si tout fonctionne correctement, vous devriez voir les journaux suivants :

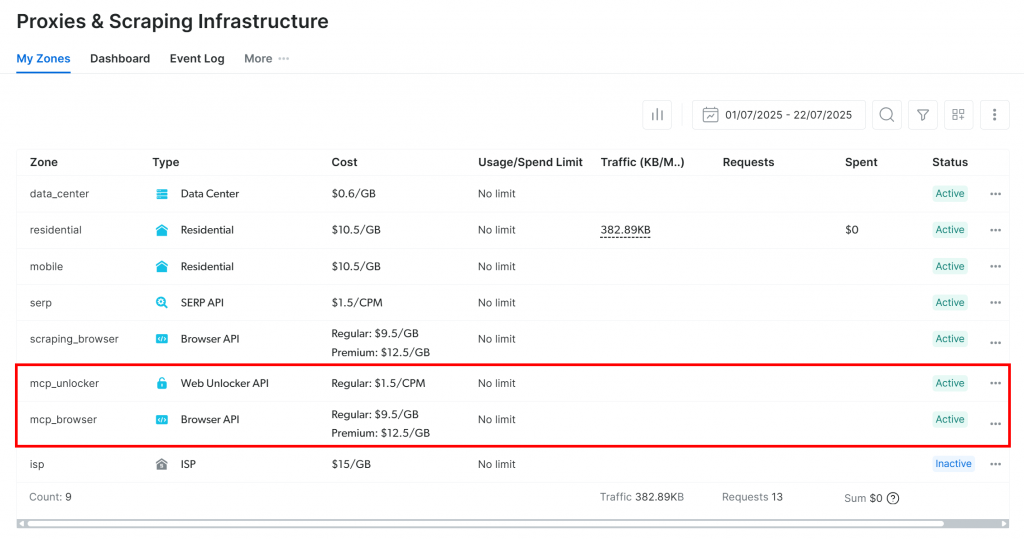
Lors du premier lancement, le serveur MCP crée automatiquement deux zones de proxy par défaut dans votre compte Bright Data :
mcp_unlocker: Une zone pour Web Unlocker.mcp_browser: Une zone pour l’API du navigateur.
Ces deux zones sont nécessaires pour activer l’ensemble des outils du serveur MCP.
Pour confirmer la création des zones, connectez-vous à votre tableau de bord Bright Data et accédez à la page“Proxies & Scraping Infrastructure“. Les deux zones doivent être répertoriées :
Remarque: si vous n’utilisez pas un jeton API avec des autorisations d’administrateur, ces zones ne seront pas créées automatiquement. Dans ce cas, vous devez les créer manuellement et spécifier leurs noms à l’aide de variables d’environnement, comme expliqué dans la documentation officielle.
Par défaut, le serveur MCP n’expose que les outils search_engine et scrape_as_markdown. Pour débloquer des fonctionnalités avancées telles que l’automatisation du navigateur et l’extraction de données structurées, activez le mode Pro en définissant la variable d’environnement PRO_MODE=true avant de lancer le serveur MCP :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpEt sur Windows :
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $env:PRO_MODE="true"; npx -y @brightdata/mcpC’est fantastique ! Vous venez de vérifier que le serveur Bright Data Web MCP fonctionne correctement sur votre machine. Vous pouvez maintenant tuer le processus du serveur, car vous êtes sur le point de configurer le CLI Gemini pour qu’il démarre pour vous.
Étape 3 : Configurer le serveur Web MCP dans l’interface de gestion Gemini
Le CLI Gemini prend en charge l’intégration MCP via un fichier de configuration situé dans ~/.gemini/settings.json, où ~ représente votre répertoire personnel. Ou, sous Windows, $HOME/.gemini/settings.json.
Vous pouvez ouvrir le fichier dans Visual Studio Code avec :
code "~/.gemini/settings.json"Ou, sous Windows :
code "$HOME/.gemini/settings.json"Note: Si le fichier settings.json n’existe pas encore, vous devrez peut-être le créer manuellement.
Dans settings.json, configurez le CLI Gemini pour qu’il démarre automatiquement le serveur Bright Data Web MCP en tant que sous-processus et qu’il s’y connecte. Assurez-vous que le fichier settings.json contient les éléments suivants
{
"mcpServers": {
"brightData": {
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Dans la configuration ci-dessus :
- L’objet
mcpServersindique à Gemini CLI comment démarrer les serveurs MCP externes. - L’entrée
brightDatadéfinit la commande et les variables d’environnement requises pour exécuter le serveur MCP Web de Bright Data (l’activation dePRO_MODEest facultative mais recommandée). Notez qu’elle exécute exactement la même commande que vous avez testée précédemment, mais que Gemini CLI l’exécutera automatiquement pour vous dans les coulisses.
Important: Remplacez le caractère générique par votre clé d’API Bright Data pour permettre l’authentification.
Une fois que vous avez ajouté la configuration du serveur MCP, enregistrez le fichier. Vous êtes maintenant prêt à tester l’intégration de MCP dans le CLI Gemini !
Étape 4 : Vérifier la connexion MCP
Si le CLI Gemini est toujours en cours d’exécution, quittez-le à l’aide de la commande /quit, puis relancez-le. Il devrait maintenant se connecter automatiquement au serveur MCP de Bright Data Web.
Pour vérifier la connexion, tapez la commande /mcp dans le CLI de Gemini :
Ensuite, sélectionnez l’option de liste pour afficher les serveurs MCP configurés et les outils disponibles. Appuyez sur Entrée, et vous devriez voir quelque chose comme ceci :
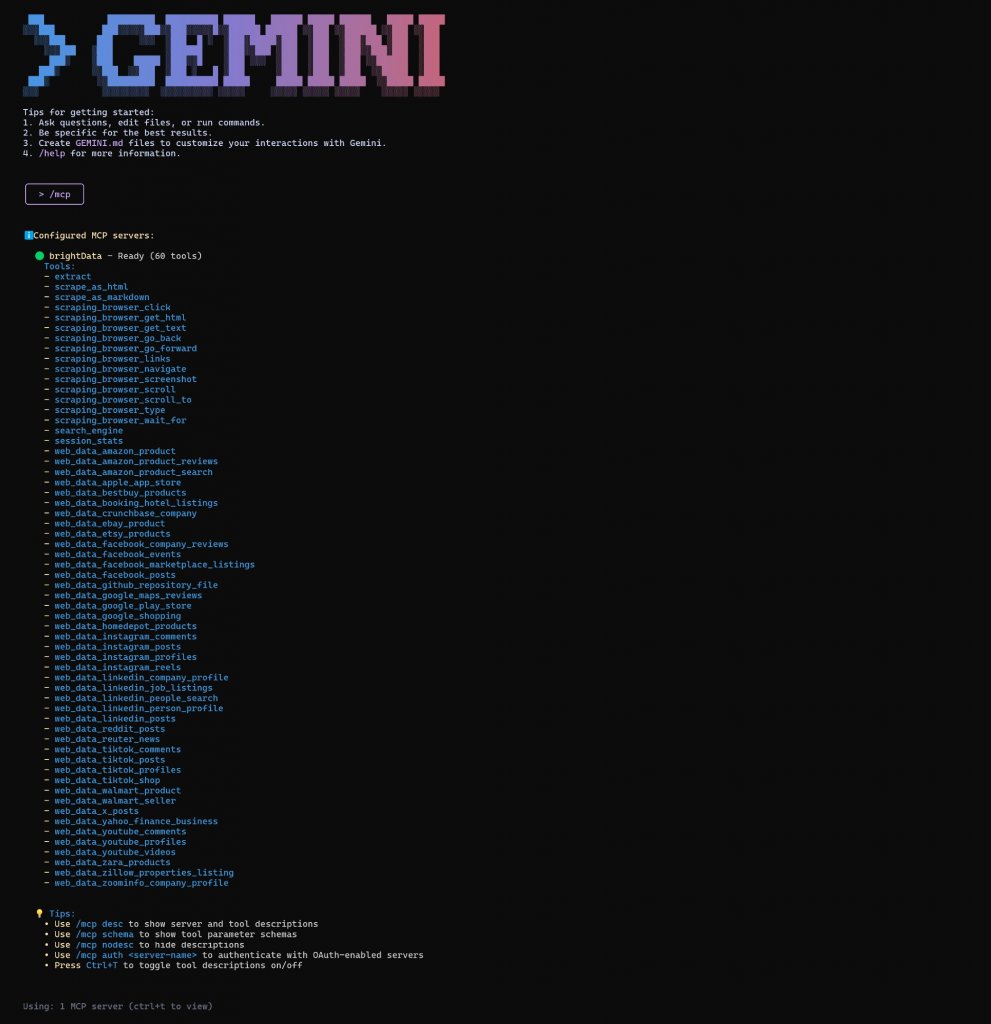
Comme vous pouvez le voir, le CLI Gemini s’est connecté au serveur MCP Web de Bright Data et peut maintenant accéder à plus de 60 outils qu’il fournit. C’est très bien !
Astuce: Découvrez toutes les autres commandes de l’interface CLI de Gemini dans la documentation.
Étape 5 : Exécuter une tâche dans l’interface de programmation Gemini
Pour tester les capacités web de votre installation Gemini CLI, vous pouvez utiliser une invite comme la suivante :
Scrape data from "https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/" and store the resulting JSON data in a local data.json file. Then, create a Node.js index.js script to load and print its contents.Il s’agit d’un cas d’utilisation réel, utile pour collecter des données en direct à des fins d’analyse, de simulation d’API ou de test.
Collez l’invite dans l’interface CLI de Gemini :

Appuyez ensuite sur la touche Entrée pour l’exécuter. C’est ainsi que l’agent doit aborder votre tâche :
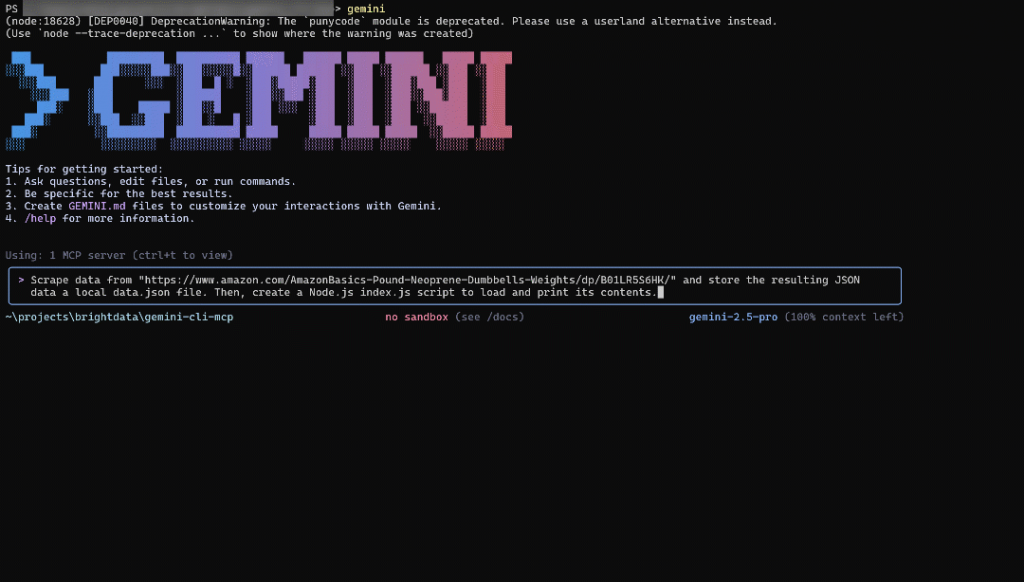
Le GIF ci-dessus a été accéléré, mais c’est ce qui devrait se passer :
- Gemini CLI envoie votre invite au LLM configuré (c’est-à-dire
gemini-2.5-pro). - Le LLM sélectionne l’outil MCP approprié
(web_data_amazon_product, dans ce cas). - Il vous est demandé de confirmer que l’outil peut être exécuté via Web MCP, en utilisant l’URL du produit Amazon fourni.
- Une fois approuvée, la tâche de scraping est lancée via l’intégration MCP.
- Les données produit résultantes sont affichées dans leur format brut (c’est-à-dire JSON).
- Gemini CLI demande s’il peut enregistrer ces données dans un fichier local nommé
data.json. - Après approbation, le fichier est créé et alimenté.
- Gemini CLI vous montre ensuite la logique JavaScript pour
index.js, qui charge et imprime les données JSON - Après votre approbation, le fichier
index.jsest créé. - On vous demande l’autorisation d’exécuter le script Node.js.
- Une fois l’autorisation accordée,
index.jsest exécuté et les données dedata.jsonsont imprimées sur le terminal comme décrit dans la tâche. - Gemini CLI vous demande si vous souhaitez supprimer les fichiers générés.
- Gardez-les pour mettre fin à l’exécution.
Notez que le CLI Gemini a demandé l’exécution du script même si vous ne l’avez pas explicitement demandé dans la tâche. Néanmoins, c’est utile pour les tests, donc c’est logique et c’est un bon ajout à votre tâche.
À la fin de l’interaction, votre répertoire de travail contiendra ces deux fichiers :
├── data.json
└── index.jsOuvrez data.json dans VS Code, et vous verrez :
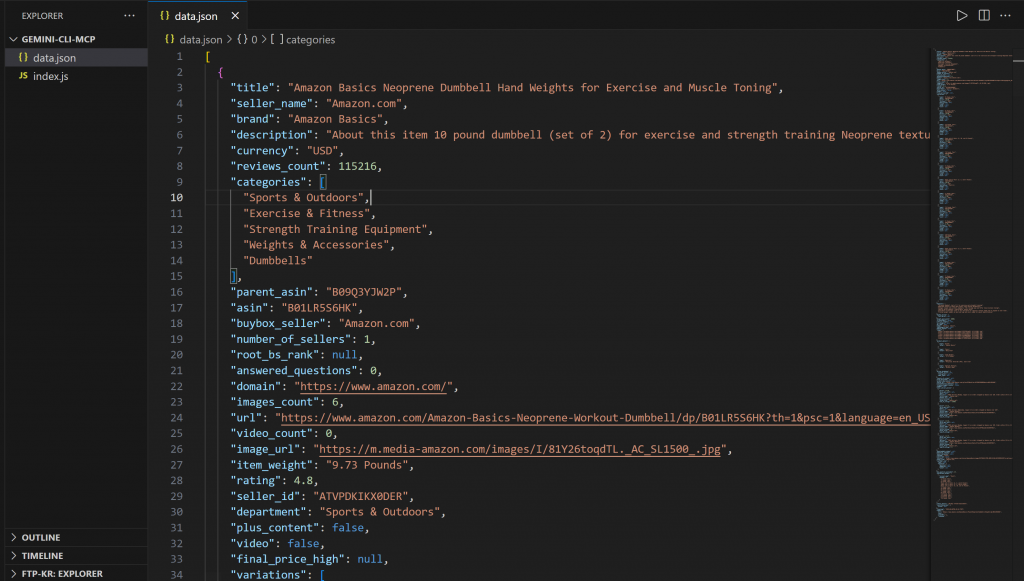
Ce fichier contient des données de produits réelles extraites d’Amazon à l’aide de l’intégration Bright Data Web MCP.
De même, l’ouverture du fichier index.js révèle :
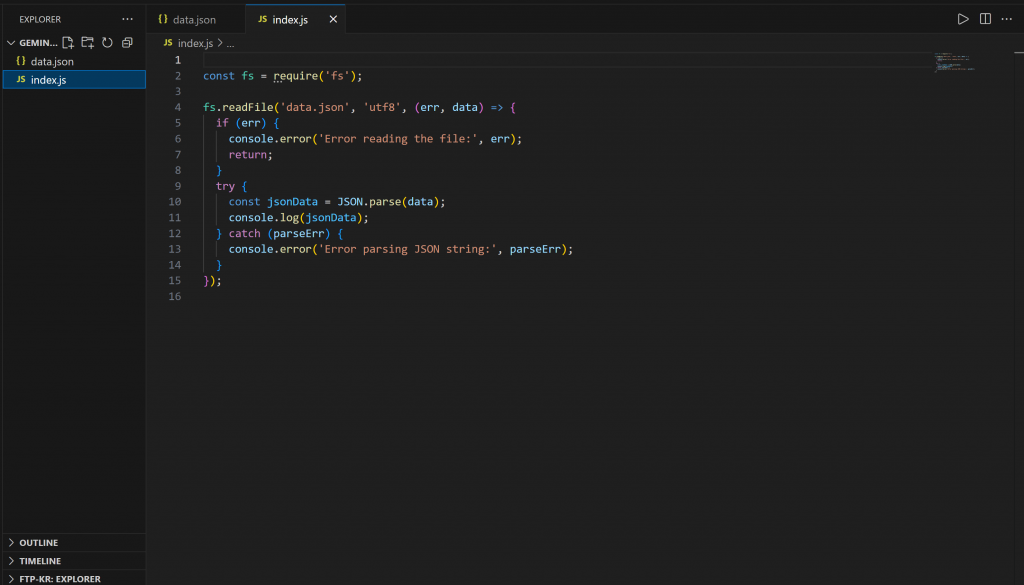
Ce script inclut la logique Node.js pour charger et afficher le contenu de data.json.
Exécutez le script Node.js index.js avec :
node index.jsLe résultat sera le suivant :

Et voilà ! Le flux de travail s’est achevé avec succès.
Plus précisément, le contenu chargé à partir de data.json et imprimé dans le terminal correspond aux données réelles de la page produit originale d’Amazon :

Gardez à l’esprit que data.json contient de vraies données récupérées, et non du contenu halluciné ou inventé généré par l’IA. N’oubliez pas non plus qu’il est notoirement difficile de pirater Amazon en raison de ses solides protections anti-bots (telles que l’Amazon CAPTCHA). Un LLM ordinaire ne pourrait pas faire cela !
Cet exemple démontre la puissance de la combinaison du CLI Gemini avec le serveur Web MCP de Bright Data. Maintenant, essayez d’autres invites et explorez les flux de données avancés pilotés par LLM directement dans le CLI !
Conclusion
Dans cet article, vous avez appris à connecter Gemini CLI au serveur Bright Data Web MCP pour créer un agent de codage IA capable d’accéder au Web. Cette intégration est rendue possible par la prise en charge intégrée de MCP par Gemini CLI.
Pour créer des agents plus complexes, explorez la gamme complète de services disponibles dans l’infrastructure d’IA de Bright Data. Ces solutions peuvent prendre en charge une grande variété de scénarios d’agents.
Créez gratuitement un compte Bright Data et commencez à expérimenter avec nos outils de données web prêts pour l’IA !





